Snowflakeの外部関数とストリーム¶
Snowflakeを使用すると、ユーザー定義関数(UDF)から外部APIを呼び出すことができます。 Snowflakeスコアリングパイプラインを使用すると、これらの外部API関数を利用できます。Snowflakeストリームとタスクを活用して、DataRobotがホストするモデルを組み込んだストリーミングマイクロバッチ取込みフローを作成します。
このアプローチを検討する際には、要件と考慮事項がいくつかあります。
- すべてのAPIは、信頼できるクラウドネイティブAPIサービス(AWSの場合はAWS API Gateway)によりフロントエンドで使用される必要があります。
- スケーリング、同時実行、信頼性に関する考慮事項があります。
- 同期リクエストの最大ペイロードサイズは、APIゲートウェイの場合は10MB、Lambdaの場合は6MBです(クラウドプロバイダーに応じて制限値は異なります)。
モデルのスコアリング方法を決定する際は、次の問題を考慮してください。 10行、10,000行、1,000万行をスコアリングした場合、インフラストラクチャ全体はどのように反応しますか? 小規模な2つのノードクラスターが大規模な8つのノードクラスターに垂直方向にスケーリングされる場合、または2つか3つのインスタンスに水平方向にスケーリングされる場合、どのような負荷がかかりますか? リクエストがタイムアウトしたり、リソースが利用できない場合はどうなりますか?
Snowflakeで大規模なバッチスコアリングジョブを簡単かつ効率的に実行するための代替手段については、クライアントリクエストとサーバー側のスコアリングの例で説明されています。 一般的に言えば、このタイプのスコアリングは、ETLまたはELTパイプラインの一部として行うのが最適です。 Snowflake内部ストリーミングを使用した少量のストリーミングインジェストは、UDFで外部機能を活用するのに適したアプリケーションです。
以下は、Snowflake内でSnowpipe、ストリーム、およびタスクを使用するETLパイプラインを示しています。 この例では、Kaggleのタイタニックデータセットを使用して、DataRobotがホストするモデルからレコードをスコアリングします。 STGスキーマ内のオブジェクトを使用してストリーミングパイプライン経由でデータを取込み、モデルに対してスコアリングしてから、PUBLICスキーマプレゼンテーションレイヤーにロードします。
使用テクノロジー¶
この例では、次のテクノロジーを使用しています。
Snowflake:
- ストレージ統合
- 段階
- Snowpipe
- ストリーム
- タスク、 テーブル、および 外部関数UDF オブジェクト(取り込まれるデータのストリーミングスコアリングパイプラインを組み立てるため)
AWS:
- Lambda(SnowflakeとDataRobotの間の仲介者として機能するサーバーレスコンピューティングサービス(現在、外部関数を使用するための要件))
- APIゲートウェイ(Lambda関数をフロントエンドで使用するためのエンドポイントを提供)
- IAM ポリシー(必要なコンポーネントにロールと権限を付与)
- S3オブジェクトストアバケットに配置される受信データ
- SQSキュー
DataRobot:
- モデルはAutoMLプラットフォーム上で構築およびデプロイされ、DataRobot予測APIを介してリクエストのスコアリングに使用できます。 この場合、モデルは水平方向にスケーラブルなDataRobotクラスターメンバーハードウェアで提供され、これらのリクエストに対応することのみを目的とします。
外部UDFアーキテクチャ¶
以下は、Snowflake外部API UDFアーキテクチャを示しています。
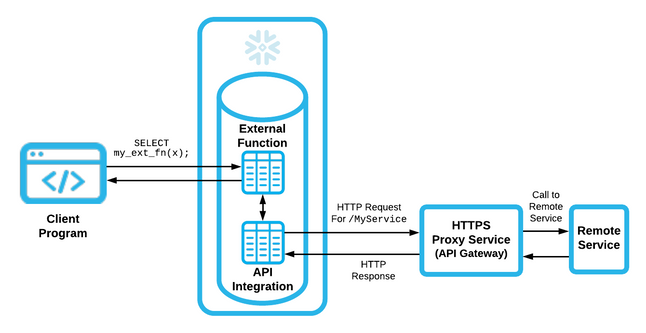
SnowflakeのネイティブUDFはJavaScriptで記述されていますが、外部関数はリモートで実行され、リモートインフラストラクチャがサポートする任意の言語でコーディングできます。 次に、SnowflakeのAPI連携と結合して、外部UDFとして公開します。 この統合により、操作対象のペイロードがAPIプロキシサービス(この場合はAWS API Gateway)に送信されます。 その後、ゲートウェイはコンテナまたはLambdaコードによってサポートされるマイクロサービスの背後にあるリモートサービスを使用して、このリクエストに応えます。
リモートサービス(AWS Lambda)の作成¶
AWS Lambda内でDataRobotモデルをホストすると、AWSのスケーラビリティ機能を利用できます。 以下の例を参照してください。
- [AWS LambdaでのDataRobot Primeの使用](prime-lambda)
- AWS Lambdaでのスコアリングコードの使用
- [モデルをDataRobotの外部にDockerコンテナとしてエクスポートする](aks-deploy-and-monitor)
このセクションでは、ゲートウェイを完全なパススルーと送信のプロキシとして扱い、DataRobotがホストする予測エンジンにスコアリングリクエストを送信する例を紹介します。 このアプローチでは、スケーラビリティには、DataRobotクラスターでの予測エンジンの水平方向のスケーリングも含まれます。
環境とプロセスに慣れるための追加のLambda作成ワークフローについては、上記の記事を参照してください。 Python 3.7ランタイム環境でproxy_titanicという名前のLambdaを作成します。 既存のIAMロールを活用するか、デフォルトの実行権限を持つ新しいロールを作成します。
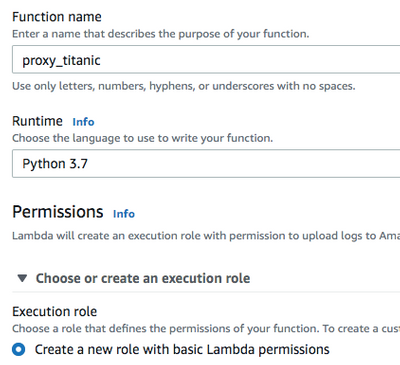
DataRobotクラスターに接続するには、いくつかの機微情報が必要です。
- DataRobot Prediction Engine(DPE)クラスターの前にある負荷分散ホスト名
- ユーザーのAPIトークン
- スコアリングされるモデルのデプロイ
- DataRobotキー(マネージドAIプラットフォームユーザーのみ)
Lambda環境変数セクションにこれらの値を保存できます。
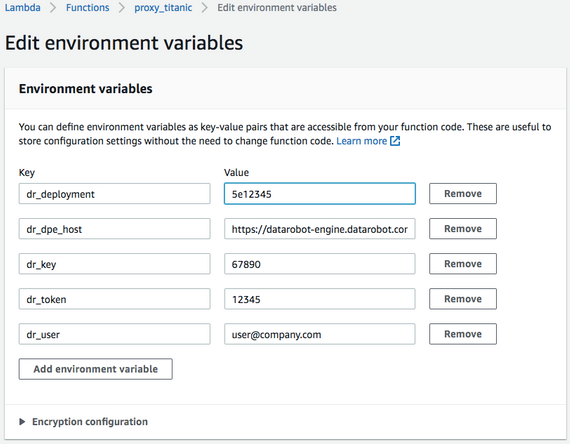
Lambdaレイヤーを使用すると、ライブラリの上にLambdaコードを構築し、そのコードを配信パッケージから分離できます。 レイヤーを使用すると、必要なパッケージを取り込んでコードを維持するプロセスが簡素化されるため、ライブラリを分離する必要はありません。 この例では、Amazon Linuxベースイメージの一部ではないrequestsおよびpandasライブラリが必要であり、レイヤーを介して(仮想環境を作成することにより)追加する必要があります。 この例では、Amazon Linux EC2ボックス環境を使用します。 Amazon LinuxにPython 3をインストールする手順はこちらです。
次のように、レイヤーのZIPファイルを作成します。
python3 -m venv my_app/env
source ~/my_app/env/bin/activate
pip install requests
pip install pandas
deactivate
Amazonのドキュメントによると、pythonまたはsite-packagesディレクトリにこれを配置し、/optで展開する必要があります。
cd ~/my_app/env
mkdir -p python/lib/python3.7/site-packages
cp -r lib/python3.7/site-packages/* python/lib/python3.7/site-packages/.
zip -r9 ~/layer.zip python
layer.zipファイルをS3上にコピーします。これは、Lambdaレイヤーが10MBを超える場合に必要です。
aws s3 cp layer.zip s3://datarobot-bucket/layers/layer.zip
Lambdaサービス > レイヤー > レイヤーの作成タブに移動します。 S3のファイルへの名前とリンクを指定します。これは、アップロードされたZIPのオブジェクトURLになります。 必須ではありませんが、互換性のある環境を設定することをお勧めします。これにより、Lambdaに追加する際にドロップダウンメニューから簡単にアクセスできるようになります。 選択して、レイヤーとそのAmazonリソースネーム(ARN)を保存します。
Lambdaに戻り、Lambdaタイトルの下にあるレイヤーをクリックし、前の手順のARNを指定します。
Lambdaコードに戻ります。 次のPythonコードは以下のようになります。
- Snowflakeからペイロードを受け入れます。
- スコアリング用のペイロードをDataRobotの予測APIに渡します。
- Snowflake互換の応答を返します。
import os
import json
#from pandas.io.json import json_normalize
import requests
import pandas as pd
import csv
def lambda_handler(event, context):
# set default status to OK, no DR API error
status_code = 200
dr_error = ""
# The return value will contain an array of arrays (one inner array per input row).
array_of_rows_to_return = [ ]
try:
# obtain secure environment variables to reach out to DataRobot API
DR_DPE_HOST = os.environ['dr_dpe_host']
DR_USER = os.environ['dr_user']
DR_TOKEN = os.environ['dr_token']
DR_DEPLOYMENT = os.environ['dr_deployment']
DR_KEY = os.environ['dr_key']
# retrieve body containing input rows
event_body = event["body"]
# retrieve payload from body
payload = json.loads(event_body)
# retrieve row data from payload
payload_data = payload["data"]
# map list of lists to expected inputs
cols = ['row', 'NAME', 'SEX', 'PCLASS', 'FARE', 'CABIN', 'SIBSP', 'EMBARKED', 'PARCH', 'AGE']
df = pd.DataFrame(payload_data, columns=cols)
print("record count is: " + str(len(df.index)))
# assemble and send scoring request
headers = {'Content-Type': 'text/csv; charset=UTF-8', 'Accept': 'text/csv', 'datarobot-key': DR_KEY}
response = requests.post(DR_DPE_HOST + '/predApi/v1.0/deployments/%s/predictions' % (DR_DEPLOYMENT),
auth=(DR_USER, DR_TOKEN), data=df.to_csv(), headers=headers)
# bail if anything other than a successful response occurred
if response.status_code != 200:
dr_error = str(response.status_code) + " - " + str(response.content)
print("dr_error: " + dr_error)
raise
array_of_rows_to_return = []
row = 0
wrapper = csv.reader(response.text.strip().split('\n'))
header = next(wrapper)
idx = header.index('SURVIVED_1_PREDICTION')
for record in wrapper:
array_of_rows_to_return.append([row, record[idx]])
row += 1
# send data back in required snowflake format
json_compatible_string_to_return = json.dumps({"data" : array_of_rows_to_return})
except Exception as err:
# 400 implies some type of error.
status_code = 400
# Tell caller what this function could not handle.
json_compatible_string_to_return = 'failed'
# if the API call failed, update the error message with what happened
if len(dr_error) > 0:
print("error")
json_compatible_string_to_return = 'failed; DataRobot API call request error: ' + dr_error
# Return the return value and HTTP status code.
return {
'statusCode': status_code,
'body': json_compatible_string_to_return
}
この例のLambdaコードはGitHubで入手できます。 テストイベントを設定して、Lambdaが想定どおりに動作することを確認できます。 このモデルのDataRobotペイロードは、次の形式のいくつかのJSONレコードで表示されます。
{
"body": "{\"data\": [[0, \"test one\", \"male\", 3, 7.8292, null, 0, \"Q\", 0, 34.5 ], [1, \"test two\", \"female\",
3, 7, null, 1, \"S\", 0, 47 ] ] }"
}
このイベントが作成されたら、テストドロップダウンから選択し、テストをクリックします。 テストは、JSONでカプセル化されたリストを含む200レベルの成功応答を返します。これには、0から始まる行番号と返されたモデル値が含まれます。 この場合、そのモデル値はラベル1の正のクラスに対するスコアです(たとえば、二値分類モデルからのタイタニック号乗客の生存率)。
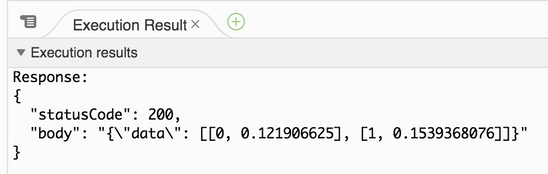
基本設定で追加のLambda設定を行えます。 Lambdaサーバーレスのコストは、RAMの「使用秒数」期間に基づいています。 より多くのRAMが使用されるほど、より多くの仮想CPUが割り当てられます。 これにより、大規模な入力負荷の処理と操作が可能になり、Lambda内での処理がより迅速に行われるようになります。 このLambdaは、負荷の高い作業についてはDataRobotに依存します。 データの移動に対応する必要があるだけです。リソースの超過が原因でLambdaが途中で終了する場合は、これらの値を編集する必要がある場合があります。 デフォルトのタイムアウトは3秒です。Lambdaが担当するレコードのマイクロバッチに対するDataRobotからの応答が、デフォルト値よりも処理に時間がかかる場合、Lambdaはアクティビティを検出せず、シャットダウンします。 DataRobotではテスト済みの次の値を推奨しています。256MBおよび10秒のタイムアウト。 実行された各Lambdaの実際の使用状況は、関連するCloudWatchログで確認できます。これはLambdaの監視タブで利用できます。
プロキシサービスの設定¶
以下では、AWS API Gatewayプロキシサービスを作成します。
IAMロールの作成¶
Snowflakeが所有するIAMユーザーにアクセス許可を付与するには、ユーザーがAWSアカウント内で引き継ぐことができるロールを作成する必要があります。 コンソールで、IAM > ロール > ロールを作成に移動します。 信頼できるエンティティの種類を選択するように求められたら、別のAWSアカウントを選択し、アカウントIDボックスに現在ログインしているアカウントのAWSアカウントIDを入力します。 これは、マイアカウントメニューまたはその他のさまざまな場所から、他のロールのARNで見つけることができます。 アカウントのSnowflake外部IDは後で適用されます。
次の画面に進み、このロールをsnowflake_external_function_roleとして保存します。 ロールをAmazonリソースネーム(ARN)として保存します。
API Gatewayエントリーの作成¶
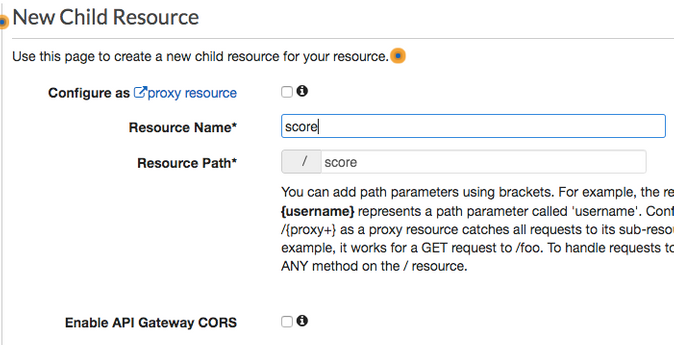
API Gatewayサービスコンソールに移動し、APIを作成をクリックします。 REST APIの構築を選択し、RESTプロトコルを選択します。 新しいAPIを作成を選択します。 わかりやすい名前を付けて、APIを作成をクリックします。 次の画面で、アクション > リソースを作成を選択します。 スコアへのリソース名とパスを設定します。
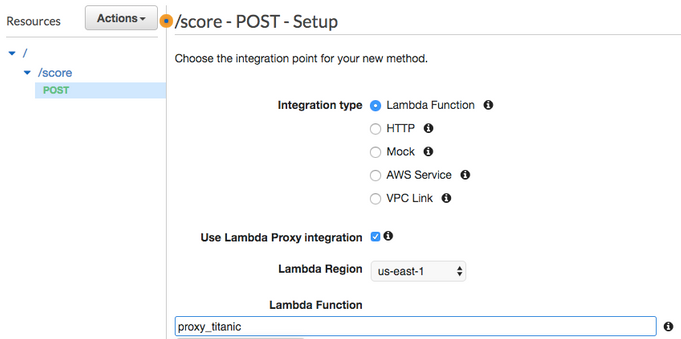
次に、アクション > メソッドを作成を選択します。 エンドポイントの下のドロップダウンメニューで、POSTを選択します。 Lambdaプロキシ統合を使用するの横にあるチェックボックスを選択し、前に作成したLambdaを選択して保存します。
最後に、アクション > APIをデプロイを選択します。 ステージ(テストなど)を作成し、フォームに入力したらデプロイをクリックします。
備考
後続のエディターページの呼び出しURLフィールドは、後でSnowflakeとの統合を作成する際に使用されます。
API Gatewayエンドポイントの保護¶
作成したAPIのリソースに戻ります(ステージの上の左側のメニュー)。 エンドポイントの下にあるPOSTをクリックして、メソッドの実行を表示します。 メソッドリクエストをクリックし、承認ドロップダウンをAWS_IAMに切り替えてから、チェックマークをクリックして保存します。 メソッドの実行に戻り、メソッドリクエスト内のARNをメモします。
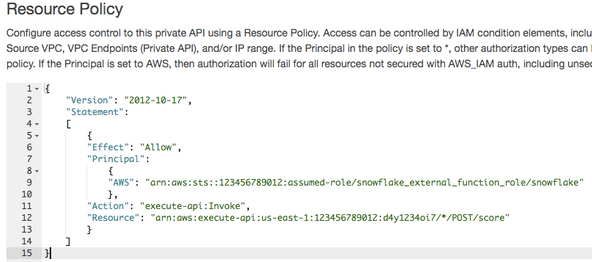
左側のメニューのリソースポリシーに移動します。 AWSアカウント番号と、上記で作成したIAMロールの名前が入力されたポリシーを追加します(Snowflakeのドキュメントで説明されています)。
SnowflakeでのAPI連携オブジェクトの作成¶
API連携オブジェクトは、SnowflakeをAWSアカウントロールにマッピングします。 ロールARNを提供し、許可されたプレフィックスを設定して、上記のステージから呼び出しURLを含めます(アカウント管理者レベルの特権がAPI連携の作成に必要です)。
use role accountadmin;
create or replace api integration titanic_external_api_integration
api_provider=aws_api_gateway
api_aws_role_arn='arn:aws:iam::123456789012:role/snowflake_external_function_role'
api_allowed_prefixes=('https://76abcdefg.execute-api.us-east-1.amazonaws.com/test/')
enabled=true;
連携について説明します。
describe integration titanic_external_api_integration;
次の値をコピーします。
API_AWS_IAM_USER_ARN and API_AWS_EXTERNAL_ID
SnowflakeとIAMロールの信頼関係の設定¶
AWS IAMサービス > ロールに戻り、snowflake_external_function_roleロールに移動します。
サマリーページの下部で、信頼関係タブを選択し、信頼関係を編集ボタンをクリックします。 これにより、編集するポリシードキュメントが開きます。 Snowflakeのドキュメントに従って、既存の値をSnowflakeのAPI_AWS_IAM_USER_ARNに置き換えて、プリンシパル属性のAWSキーを編集します。 sts:AssumeRoleアクションの横には、中括弧の間に空の値を持つ条件キーがあります。 中括弧の内側に、次を貼り付け、API_AWS_EXTERNAL_IDをSnowflakeの値に置き換えます。
"StringEquals": { "sts:ExternalId": "API_AWS_EXTERNAL_ID" }
信頼ポリシーを更新をクリックして、この画面を保存します。
外部関数の作成¶
Snowflake内で外部関数を作成できるようになりました。 信頼できるエンドポイントを参照して、以前に構築されたAPI連携を介して呼び出します。 関数定義で予期されるパラメーター値を、Lambdaが予期している関数と必ず一致させてください。
create or replace external function
udf_titanic_score(name string, sex string, pclass int, fare numeric(10,5),
cabin string, sibsp int, embarked string, parch int, age numeric(5,2))
returns variant
api_integration = titanic_external_api_integration
as 'https://76abcdefg.execute-api.us-east-1.amazonaws.com/test/score';
関数が使用できるようになりました。
外部関数の呼び出し¶
予想どおりに関数を呼び出すことができます。 このコードは、100,000件のタイタニック号の乗客記録をスコアリングします。
select passengerid
, udf_titanic_score(name, sex, pclass, fare, cabin, sibsp, embarked, parch, age) as score
from passengers_100k;
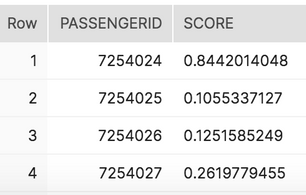
上記の予測では、7254024人のタイタニック号乗客の生存率は84.4%です。
外部関数のパフォーマンスに関する考慮事項¶
考察:
- この場合、完全に受信されたペイロードには、最大1860のレコードが含まれていました。 ペイロードのサイズはおよそ0.029MBでした(Snowflakeではそれらを0.03MBに制限しています)。
- Snowflake上の超小規模、小規模、中規模のコンピューティングウェアハウスからスコアリングするかどうかに関係なく、Lambda同時実行CloudWatchメトリクスダッシュボードは常に8つの同時実行ピークを表示しました。全体として、これはスコアリングインフラストラクチャの負荷がかなり低いことを表しています。
- モデルがLambda自体で実行されている場合でも、DataRobot予測エンジンにオフセットされている場合でも、満足できるパフォーマンスが期待できます。 大規模なバッチジョブと最大スループットの場合は、他の方法の方が時間とリソースの点でより効率的です。
- DataRobotのr4.xlarge専用予測エンジンに対するテストでは、この特定のデータセットとモデルに対して約13,800件のレコードが生成されました。
- Snowflakeは、因子数に基づいてペイロードサイズと同時実行を決定します。 制御可能なペイロードの上限は、外部関数の作成中に
MAX_BATCH_ROWS値で指定できます。 今後のオプションでは、ペイロードサイズ、同時実行性、およびウェアハウスのアップサイジングによるスケーリングを、より詳細に制御できるようになる可能性があります。
ストリームとタスクによるストリーミング取込み¶
ストリーミングを使用してSnowflakeにデータを取り込むには、複数のオプションがあります。 オプションの1つは、SnowpipeでSnowflakeネイティブの定期的なデータ読み込み機能を使用することです。 Snowflakeストリームとタスクを使用することで、外部の駆動ETL/ELTなしで到着時に新しいレコードを処理できます。
取込みパイプラインアーキテクチャ¶
以下は、この取込みアーキテクチャを示しています。
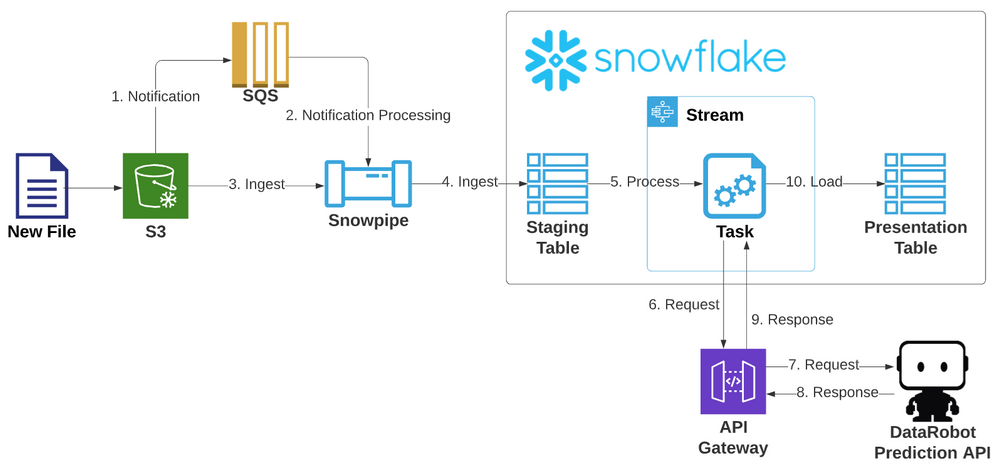
ステージングテーブルとプレゼンテーションテーブルの作成¶
Snowpipeから読み込まれた新しく到着したレコードを保持し、レポート用に処理およびスコアリングされたレコードを保持するテーブルを作成する必要があります。 この例では、元の乗客テーブルがSTGスキーマで作成され、スコアリングされた乗客テーブルがPUBLICスキーマに表示されます。
create or replace TABLE TITANIC.STG.PASSENGERS (
PASSENGERID int,
PCLASS int,
NAME VARCHAR(100),
SEX VARCHAR(10),
AGE NUMBER(5,2),
SIBSP int,
PARCH int,
TICKET VARCHAR(30),
FARE NUMBER(10,5),
CABIN VARCHAR(25),
EMBARKED VARCHAR(5)
);
create or replace TABLE TITANIC.PUBLIC.PASSENGERS_SCORED (
PASSENGERID int,
PCLASS int,
NAME VARCHAR(100),
SEX VARCHAR(10),
AGE NUMBER(5,2),
SIBSP int,
PARCH int,
TICKET VARCHAR(30),
FARE NUMBER(10,5),
CABIN VARCHAR(25),
EMBARKED VARCHAR(5),
SURVIVAL_SCORE NUMBER(11,10)
);
Snowpipeの作成¶
Snowflakeは、外部ステージオブジェクトに接続する必要があります。 Snowflakeのドキュメントを使用して、AWSおよびIAMとのストレージ統合を設定します。
use role accountadmin;
--note a replace will break all existing associated stage objects!
create or replace storage integration SNOWPIPE_INTEGRATION
type = EXTERNAL_STAGE
STORAGE_PROVIDER = S3
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::123456789:role/snowflake_lc_role'
enabled = true
STORAGE_ALLOWED_LOCATIONS = ('s3://bucket');
統合が利用可能になったら、それを使用してS3にマッピングするステージを作成し、統合を使用してセキュリティを適用できます。
CREATE or replace STAGE titanic.stg.snowpipe_passengers
URL = 's3://bucket/snowpipe/input/passengers'
storage_integration = SNOWPIPE_INTEGRATION;
最後に、Snowpipeを作成して、このステージをテーブルにマッピングします。 そのためのファイル形式も以下に作成されます。
CREATE OR REPLACE FILE FORMAT TITANIC.STG.DEFAULT_CSV TYPE = 'CSV' COMPRESSION = 'AUTO' FIELD_DELIMITER = ','
RECORD_DELIMITER = '\n' SKIP_HEADER = 1 FIELD_OPTIONALLY_ENCLOSED_BY = '\042' TRIM_SPACE = FALSE
ERROR_ON_COLUMN_COUNT_MISMATCH = TRUE ESCAPE = 'NONE' ESCAPE_UNENCLOSED_FIELD = '\134' DATE_FORMAT = 'AUTO'
TIMESTAMP_FORMAT = 'AUTO' NULL_IF = ('');
create or replace pipe titanic.stg.snowpipe auto_ingest=true as
copy into titanic.stg.passengers
from @titanic.stg.snowpipe_passengers
file_format = TITANIC.STG.DEFAULT_CSV;
Snowpipeの読み込みの自動化¶
Snowflakeは、到着した新しいデータを読み込むためのオプションを提供します。 この例では、オプション1(Snowflakeのドキュメントで説明されています)を適用して、Snowflake SQSキューを直接使用します。 ファイルイベント通知を新規作成する手順4が必要です。
Snowpipeを有効にするには、S3バケットに移動し、プロパティタブ > イベントタイルをクリックし、通知を追加をクリックします。 新しいファイルが到着するたびに、Snowflakeパイプから取得した指定済みSQSキューにメッセージを追加する通知を作成します。
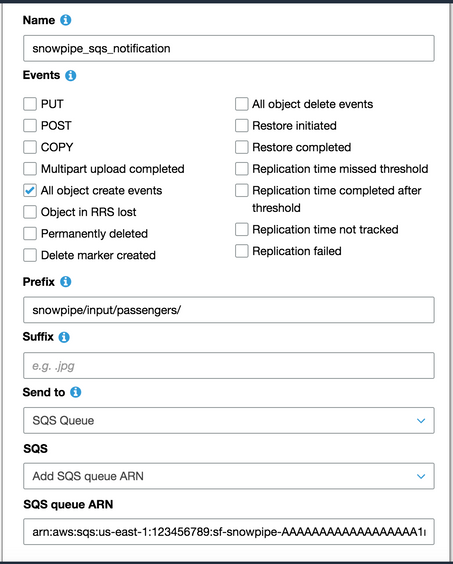
パイプでデータを受け入れて読み込む準備が整いました。
ストリームの作成¶
Snowflakeでは2種類のストリームオブジェクト(標準と追加のみ)を作成できます。 標準ストリームオブジェクトは、テーブルに対するあらゆる種類の変更をキャプチャします。追加専用ストリームオブジェクトは、挿入された行をキャプチャします。 前者は、一般的な変更データキャプチャ(CDC)処理に使用します。 単純な新しい行の取込み処理には、後者(この例で使用)を使用します。
追加のみのアプローチでは、ストリームを、最後にデータが選択されてからの新しいレコードのみを含むテーブルと考えてください。 ストリームをソースとするDMLクエリが作成されると、返された行は使用済みと見なされ、ストリームは空になります。 プログラミング用語では、これはキューに似ています。
create or replace stream TITANIC.STG.new_passengers_stream
on table TITANIC.STG.PASSENGERS append_only=true;
タスクの作成¶
タスクとは、ELT操作の実行に構築できるステップまたは一連のカスケードステップです。 タスクはcronジョブと同様にスケジュールを設定し、日、時間、または定期的な間隔で実行するように設定できます。
次の基本的なタスクは、UDFを介してタイタニック号の乗客をスコアリングし、スコアリングされたデータをプレゼンテーションレイヤーに読み込みます。 5分ごとに新しいレコードがストリームに存在するかどうかを確認します。レコードが見つかった場合、タスクが実行されます。 中断状態でタスクが作成されます。タスクを再開して有効にします。 曜日、時間、または期間に基づくスケジューリングには、多くのタイミングオプションを利用できます。
CREATE or replace TASK TITANIC.STG.score_passengers_task
WAREHOUSE = COMPUTE_WH
SCHEDULE = '5 minute'
WHEN
SYSTEM$STREAM_HAS_DATA('TITANIC.STG.NEW_PASSENGERS_STREAM')
AS
INSERT INTO TITANIC.PUBLIC.PASSENGERS_SCORED
select passengerid, pclass, name, sex, age, sibsp, parch, ticket, fare, cabin, embarked,
udf_titanic_score(name, sex, pclass, fare, cabin, sibsp, embarked, parch, age) as score
from TITANIC.STG.new_passengers_stream;
ALTER TASK score_passengers_task RESUME;
取込みとスコアリングパイプラインの完了¶
エンドツーエンドのパイプラインが完成しました。 PASSENGERS.csvファイル(GitHubで入手可能)はパイプラインを実行して、それを監視対象のバケットにコピーできます。 ファイルプレフィックスにより、データがステージングスキーマに取り込まれ、DataRobotモデルによってスコアリングされ、プレゼンテーションスキーマに読み込まれます。外部のETLツールは一切必要ありません。
aws s3 cp PASSENGERS.csv s3://bucket/snowpipe/input/passengers/PASSENGERS.csv