Fraudulent claim detection¶
This page outlines the use case to improve the accuracy in predicting which insurance claims are fraudulent. It is captured below as a UI-based walkthrough. It is also available as a Jupyter notebook that you can download and execute.
Business problem¶
Because, on average, it takes roughly 20 days to process an auto insurance claim (which often frustrates policyholders), insurance companies look for ways to increase the efficiency of their claims workflows. Increasing the number of claim handlers is expensive, so companies have increasingly relied on automation to accelerate the process of paying or denying claims. Automation can increase Straight-Through Processing (STP) by more than 20%, resulting in faster claims processing and improved customer satisfaction.
However, as insurance companies increase the speed by which they process claims, they also increase their risk of exposure to fraudulent claims. Unfortunately, most of the systems widely used to prevent fraudulent claims from being processed either require high amounts of manual labor or rely on static rules.
Solution value¶
While Business Rule Management Systems (BRMS) will always be required—they implement mandatory rules related to compliance—you can supplement these systems by improving the accuracy of predicting which incoming claims are fraudulent.
Using historical cases of fraud and their associated features, AI can apply learnings to new claims to assess whether they share characteristics of the learned fraudulent patterns. Unlike BRMS, which are static and have hard-coded rules, AI generates a probabilistic prediction and provides transparency on the unique drivers of fraud for each suspicious claim. This allows investigators to not only route and triage claims by their likelihood of fraud, but also enables them to accelerate the review process as they know which vectors of a claim they should evaluate. The probabilistic predictions also allow investigators to set thresholds that automatically approve or reject claims.
Problem framing¶
Work with stakeholders to identify and prioritize the decisions for which automation will offer the greatest business value. In this example, stakeholders agreed that achieving over 20% STP in claims payment was a critical success factor and that minimizing fraud was a top priority. Working with subject matter experts, the team developed a shared understanding of STP in claims payment and built decision logic for claims processing:
| Step | Best practice |
|---|---|
| Determine which decisions to automate. | Automate simple claims and send the more complex claims to a human claims processor. |
| Determine which decisions will be based on business rules and which will be based on machine learning. | Mange decisions that rely on compliance and business strategy by rules. Use machine learning for decisions that rely on experiences, including whether a claim is fraudulent and how much the payment will be. |
Once the decision logic is in good shape, it is time to build business rules and machine learning models. Clarifying the decision logic reveals the true data needs, which helps decision owners see exactly what data and analytics drive decisions.
ROI estimation¶
One way to frame the problem is to determine how to measure ROI. Consider:
For ROI, multiple AI models are involved in an STP use case. For example, fraud detection, claims severity prediction, and litigation likelihood prediction are common use cases for models that can augment business rules and human judgment. Insurers implementing fraud detection models have reduced payments to fraud by 15% to 25% annually, saving $1 million to $3 million.
To measure:
- Identify the number of fraudulent claims that models detected but manual processing failed to identify (false negatives).
-
Calculate the monetary amount that would have been paid on these fraudulent claims if machine learning had not flagged them as fraud.
100 fraudulent claims * $20,000 each on average = $2 million per year -
Identify fraudulent claims that manual investigation detected but machine learning failed to detect.
-
Calculate the monetary amount that would have been paid without manual investigation.
40 fraudulent claims * $5,000 each on average = $0.2 million per year
The difference between these two numbers would be the ROI.
$2 million – $0.2 million = $1.8 million per year
Working with data¶
For illustrative purposes, this guide uses a simulated dataset that resembles insurance company data. The dataset consists of 10,746 rows and 45 columns.
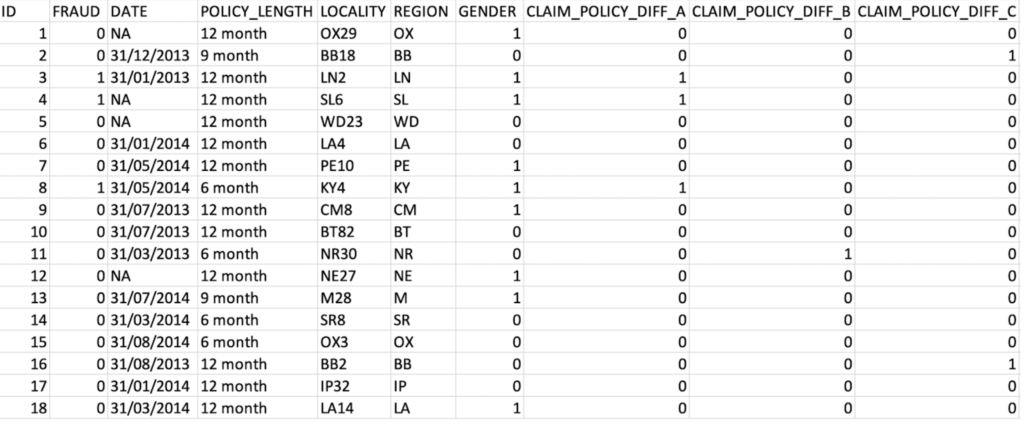
Features and sample data¶
The target variable for this use case is whether or not a claim submitted is fraudulent. It is a binary classification problem. In this dataset 1,746 of 10,746 claims (16%) are fraudulent.
The target variable:
FRAUD
Data preparation¶
Below are examples of 44 features that can be used to train a model to identify fraud. They consist of historical data on customer policy details, claims data including free-text description, and internal business rules from national databases. These features help DataRobot extract relevant patterns to detect fraudulent claims.
Beyond the features listed below, it might help to incorporate any additional data your organization collects that could be relevant to detecting fraudulent claims. For example, DataRobot is able to process image data as a feature together with numeric, categorical, and text features. Images of vehicles after an accident may be useful to detect fraud and help predict severity.
Data from the claim table, policy table, customer table, and vehicle table are merged with customer ID as a key. Only data known before or at the time of the claim creation is used, except for the target variable. Each record in the dataset is a claim.
Sample feature list¶
| Feature name | Data type | Description | Data source | Example |
|---|---|---|---|---|
| ID | Numeric | Claim ID | Claim | 156843 |
| FRAUD | Numeric | Target | Claim | 0 |
| DATE | Date | Date of Policy | Policy | 31/01/2013 |
| POLICY_LENGTH | Categorical | Length of Policy | Policy | 12 month |
| LOCALITY | Categorical | Customer’s locality | Customer | OX29 |
| REGION | Categorical | Customer’s region | Customer | OX |
| GENDER | Numeric | Customer’s gender | Customer | 1 |
| CLAIM_POLICY_DIFF_A | Numeric | Internal | Policy | 0 |
| CLAIM_POLICY_DIFF_B | Numeric | Internal | Policy | Policy |
| CLAIM_POLICY_DIFF_C | Numeric | Internal | Policy | Policy |
| CLAIM_POLICY_DIFF_D | Numeric | Internal | Policy | Policy |
| CLAIM_POLICY_DIFF_E | Numeric | Internal | Policy | Policy |
| POLICY_CLAIM_DAY_DIFF | Numeric | Number of days since policy taken | Policy, Claim | 94 |
| DISTINCT_PARTIES_ON_CLAIM | Numeric | Number of people on claim | Claim | 4 |
| CLM_AFTER_RNWL | Numeric | Renewal | History | Policy |
| NOTIF_AFT_RENEWAL | Numeric | Renewal | History | Policy |
| CLM_DURING_CAX | Numeric | Cancellation claim | Policy | 0 |
| COMPLAINT | Numeric | Customer complaint | Policy | 0 |
| CLM_before_PAYMENT | Numeric | Claim before premium paid | Policy, Claim | 0 |
| PROP_before_CLM | Numeric | Claim History | Claim | 0 |
| NCD_REC_before_CLM | Numeric | Claim History | Claim | 1 |
| NOTIF_DELAY | Numeric | Delay in notification | Claim | 0 |
| ACCIDENT_NIGHT | Numeric | Night time accident | Claim | 0 |
| NUM_PI_CLAIM | Numeric | Number of personal injury claims | Claim | 0 |
| NEW_VEHICLE_BEFORE_CLAIM | Numeric | Vehicle History | Vehicle, Claim | 0 |
| PERSONAL_INJURY_INDICATOR | Numeric | Personal Injury flag | Claim | 0 |
| CLAIM_TYPE_ACCIDENT | Numeric | Claim details | Claim | 1 |
| CLAIM_TYPE_FIRE | Numeric | Claim details | Claim | 0 |
| CLAIM_TYPE_MOTOR_THEFT | Numeric | Claim details | Claim | 0 |
| CLAIM_TYPE_OTHER | Numeric | Claim details | Claim | 0 |
| CLAIM_TYPE_WINDSCREEN | Numeric | Claim details | Claim | 0 |
| LOCAL_TEL_MATCH | Numeric | Internal Rule Matching | Claim | 0 |
| LOCAL_M_CLM_ADD_MATCH | Numeric | Internal Rule Matching | Claim | 0 |
| LOCAL_M_CLM_PERS_MATCH | Numeric | Internal Rule Matching | Claim | 0 |
| LOCAL_\NON\_CLM\_ADD\_MATCH\t | Numeric | Internal Rule Matching | Claim | 0 |
| LOCAL_NON_CLM_PERS_MATCH | Numeric | Internal Rule Matching | Claim | 0 |
| federal_TEL_MATCH | Numeric | Internal Rule Matching | Claim | 0 |
| federal_CLM_ADD_MATCH | Numeric | Internal Rule Matching | Claim | 0 |
| federal_CLM_PERS_MATCH | Numeric | Internal Rule Matching | Claim | 0 |
| federal_NON_CLM_ADD_MATCH | Numeric | Internal Rule Matching | Claim | 0 |
| federal_NON_CLM_PERS_MATCH | Numeric | Internal Rule Matching | Claim | 0 |
| SCR_LOCAL_RULE_COUNT | Numeric | Internal Rule Matching | Claim | 0 |
| SCR_NAT_RULE_COUNT | Numeric | Internal Rule Matching | Claim | 0 |
| RULE MATCHES | Numeric | Internal Rule Matching | Claim | 0 |
| CLAIM_DESCRIPTION | Text | Customer Claim Text | Claim | this via others themselves inc become within ours slow parking lot fast vehicle roundabout mall not indicating car caravan neck emergency |
Modeling and insights¶
DataRobot automates many parts of the modeling pipeline, including processing and partitioning the dataset, as described here. That activity is not described here and instead the following describes model interpretation. Reference the DataRobot documentation to see how to use DataRobot from start to finish and how to understand the data science methodologies embedded in its automation.
Feature Impact¶
Feature Impact reveals that the number of past personal injury claims (NUM_PI_CLAIM) and internal rule matches (LOCAL_M_CLM_PERS_MATCH, RULE_MATCHES, SCR_LOCAL_RULE_COUNT) are among the most influential features in detecting fraudulent claims.
Feature Effects/partial dependence¶
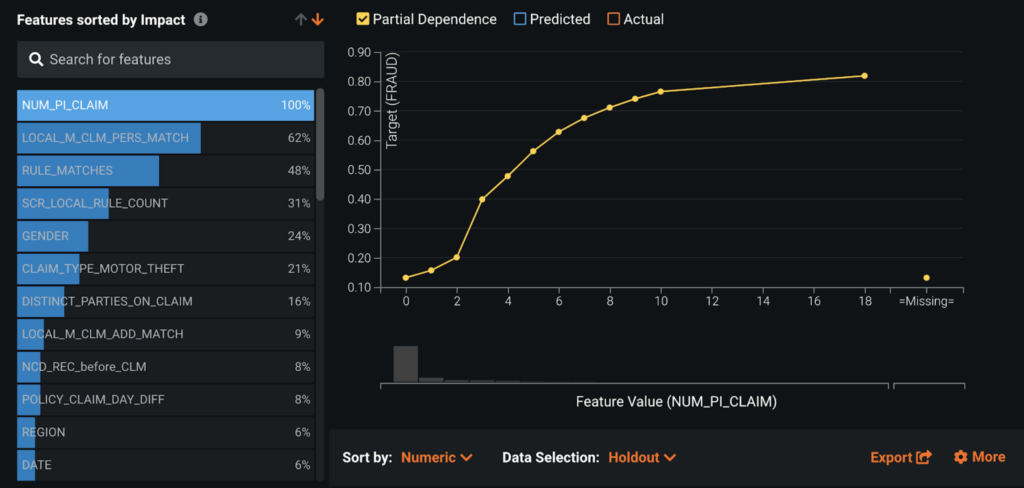
The partial dependence plot in Feature Effects shows that the larger the number of personal injury claims (NUM_PI_CLAIM), the higher the likelihood of fraud. As expected, when a claim matches internal red flag rules, its likelihood of being fraud increases greatly. Interestingly, GENDER and CLAIM_TYPE_MOTOR_THEFT (car theft) are also strong features.
Word Cloud¶

The current data includes CLAIM_DESCRIPTION as text. A Word Cloud reveals that customers who use the term "roundabout," for example, are more likely to be committing fraud than those who use the term "emergency." (The size of a word indicates how many rows include the word; the deeper red indicates the higher association it has to claims scored as fraudulent. Blue words are terms associated with claims scored as non-fraudulent.)
Prediction Explanations¶
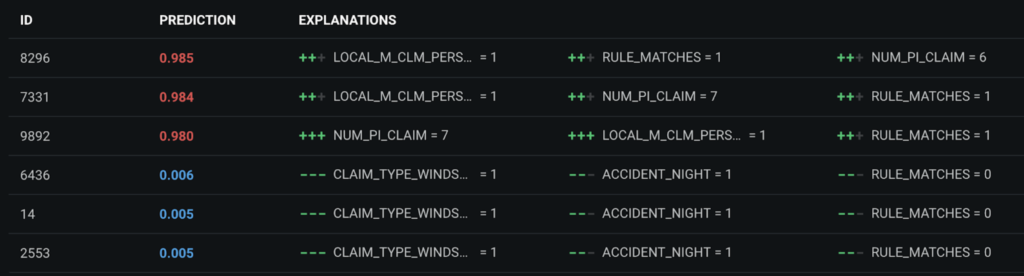
Prediction Explanations provide up to 10 reasons for each prediction score. Explanations provide Send directly to Special Investigation Unit (SIU) agents and claim handlers with useful information to check during investigation. For example, DataRobot not only predicts that Claim ID 8296 has a 98.5% chance of being fraudulent, but it also explains that this high score is due to a specific internal rule match (LOCAL_M_CLM_PERS_MATCH, RULE_MATCHES) and the policyholder’s six previous personal injury claims (NUM_PI_CLAIM). When claim advisors need to deny a claim, they can provide the reasons why by consulting Prediction Explanations.
Evaluate accuracy¶
There are several vizualizations that help to evaluate accuracy.
Leaderboard¶
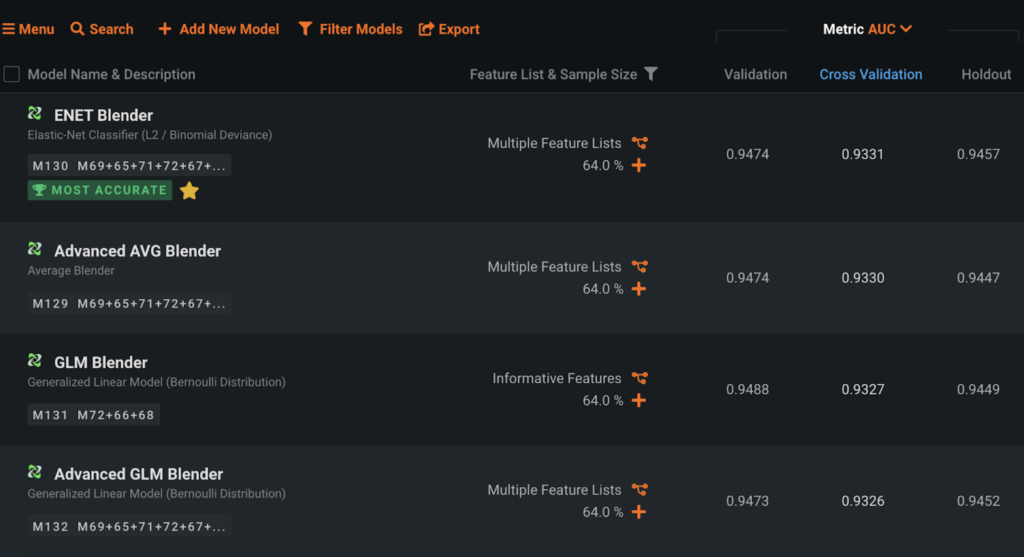
Modeling results show that the ENET Blender is the most accurate model, with 0.93 AUC on cross validation. This is an ensemble of eight single models. The high accuracy indicates that the model has learned signals to distinguish fraudulent from non-fraudulent claims. Keep in mind, however, that blenders take longer to score compared to single models and so may not be ideal for real-time scoring.
The Leaderboard shows that the modeling accuracy is stable across Validation, Cross Validation, and Holdout. Thus, you can expect to see similar results when you deploy the selected model.
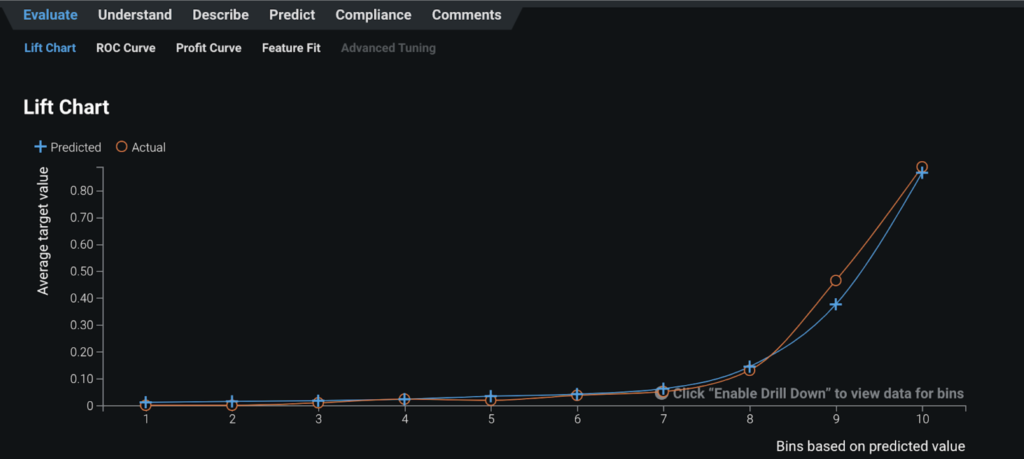
Lift Chart¶
The steep increase in the average target value in the right side of the Lift Chart reveals that, when the model predicts that a claim has a high probability of being fraudulent (blue line), the claim tends to actually be fraudulent (orange line).
Confusion matrix¶
The confusion matrix shows:
- Of 2,149 claims in the holdout partition, the model predicted 372 claims as fraudulent and 1,777 claims as legitimate.
- Of the 372 claims predicted as fraud, 275 were actually fraudulent (true positives), and 97 were not (false positives).
- Of 1,777 claims predicted as non-fraud, 1,703 were actually not fraudulent (true negatives) and 74 were fraudulent (false negatives).
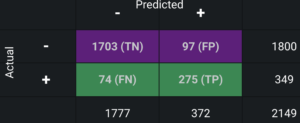
Analysts can examine this table to determine if the model is accurate enough for business implementation.
Post-processing¶
To convert model predictions into decisions, you determine the best thresholds to classify a whether a claim is fraudulent.
ROC Curve¶
Set the ROC Curve threshold depending on how you want to use model predictions and business constraints. Some examples:
| If... | Then... |
|---|---|
| ...the main use of the fraud detection model is to automate payment | ...minimize the false negatives (the number of fraudulent claims mistakenly predicted as not fraudulent) by adjusting the threshold to classify prediction scores into fraud or not. |
| ...the main use is to automate the transfer of the suspicious claims to SIU | ...minimize false positives (the number of non-fraudulent claims mistakenly predicted as fraudulent). |
| ...you want to minimize the false negatives, but you do not want false positives to go over 100 claims because of the limited resources of SIU agents | ...lower the threshold just to the point where the number of false positives becomes 100. |
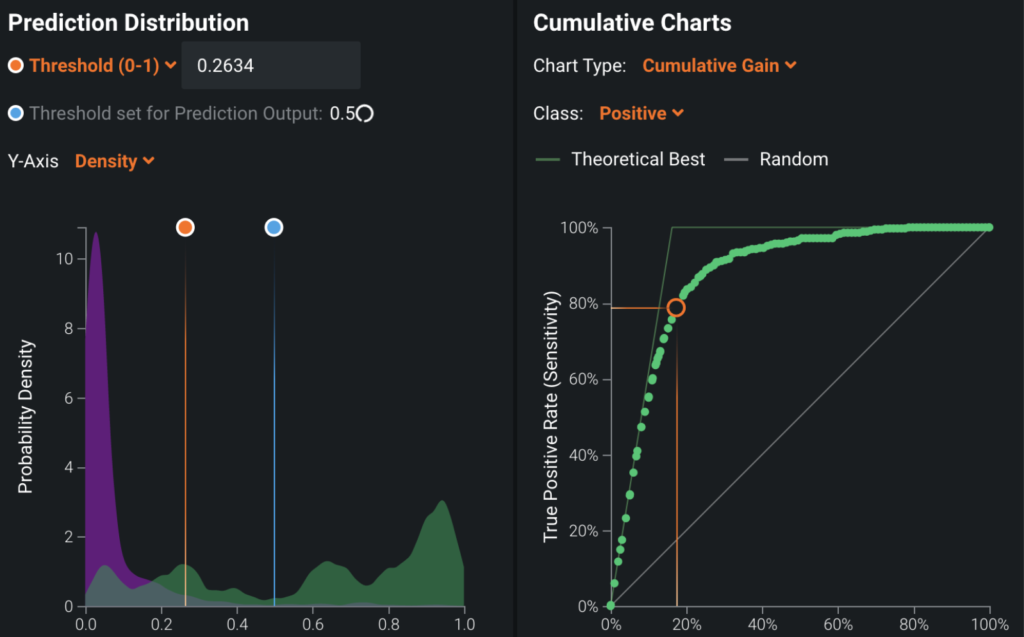
Payoff matrix¶
From the Profit Curve tab, use the Payoff Matrix to set thresholds based on simulated profit. For example:
| Payoff value | Description |
|---|---|
| True positive = $20,000 | Average payment associated with a fraudulent claim. |
| False positive = -$20,000 | This is assuming that a false positive means that a human investigator will not be able to spend time detecting a real fraudulent claim. |
| True negative = $100 | Leads to auto pay of claim and saves by eliminating manual claim processing. |
| False negative = -$20,000 | Cost of missing fraudulent claims. |
DataRobot then automatically calculates the threshold that maximizes profit. You can also measure DataRobot ROI by creating the same payoff matrix for your existing business process and subtracting the max profit of the existing process from that calculated by DataRobot.

Once the threshold is set, model predictions are converted into fraud or non-fraud according to the threshold. These classification results are integrated into BRMS and become one of the many factors that determine the final decision.
Predict and deploy¶
After selecting the model that best learns patterns to predict fraud, you can deploy it into your desired decision environment. Decision environments are the ways in which the predictions generated by the model will be consumed by the appropriate organizational stakeholders, and how these stakeholders will make decisions using the predictions to impact the overall process.
Decision stakeholders¶
The following table lists potential decision stakeholders:
| Stakeholder | Description |
|---|---|
| Decision executors | The decision logic assigns claims that require manual investigation to claim handlers (executors) and SIU agents based claim complexity. They investigate the claims referring to insights provided by DataRobot and decide whether to pay or deny. They report to decision authors the summary of claims received and their decisions each week. |
| Decision managers | Managers monitor the KPI dashboard, which visualizes the results of following the decision logic. For example, they track the number of fraudulent claims identified and missed. They can discuss with decision authors how to improve the decision logic each week. |
| Decision authors | Senior managers in the claims department examine the performance of the decision logic by receiving input from decision executors and decision managers. For example, decision executors will inform whether or not the fraudulent claims they receive are reasonable, and decision managers will inform whether or not the rate of fraud is as expected. Based on the inputs, decision authors update the decision logic each week. |
Decision process¶
This use case blends augmentation and automation for decisions. Instead of claim handlers manually investigating every claim, business rules and machine learning will identify simple claims that should be automatically paid and problematic claims that should be automatically denied. Fraud likelihood scores are sent to BRMS through the API and post-processed into high, medium, and low risk, based on set thresholds, and arrive at one of the following final decisions:
| Action | Degree of risk |
|---|---|
| SIU | High |
| Assign to claim handlers | Medium |
| Auto pay | Low |
| Auto deny | Low |
Routing to claims handlers includes an intelligent triage, in which claims handlers receive fewer claims and just those which are better tailored to their skills and experience. For example, more complex claims can be identified and sent to more experienced claims handlers. SIU agents and claim handlers will decide whether to pay or deny the claims after investigation.
Model deployment¶
Predictions are deployed through the API and sent to the BRMS.
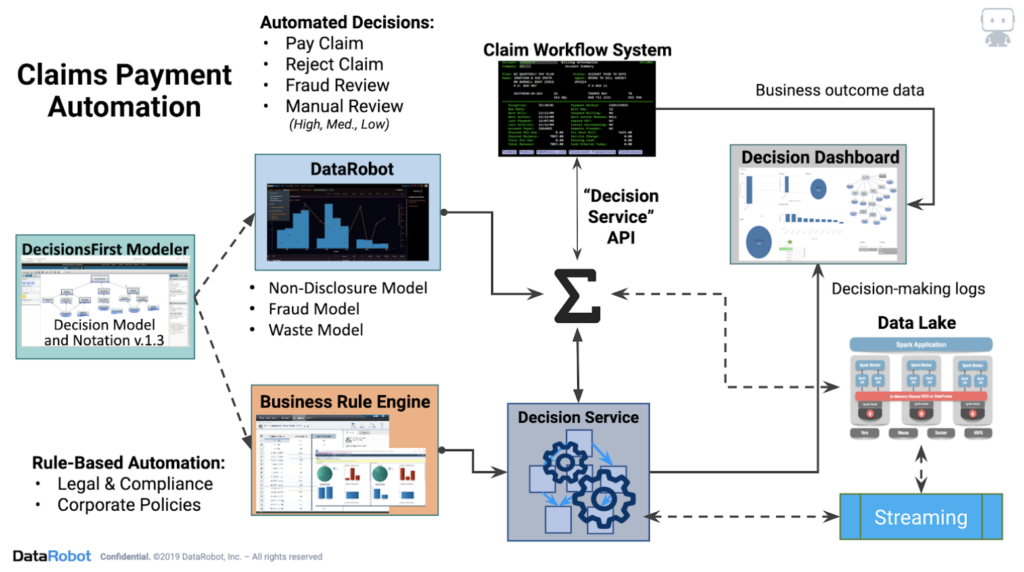
Model monitoring¶
Using DataRobot MLOps, you can monitor, maintain, and update models within a single platform.
Each week, decision authors monitor the fraud detection model and retrain the model if data drift reaches a certain threshold. In addition, along with investigators, decision authors can regularly review the model decisions to ensure that data are available for future retraining of the fraud detection model. Based on the review of the model's decisions, the decision authors can also update the decision logic. For example, they might add a repair shop to the red flags list and improve the threshold to convert fraud scores into high, medium, or low risk.
DataRobot provides tools for managing and monitoring the deployments, including accuracy and data drift.
Implementation considerations¶
Business goals should determine decision logic, not data. The project begins with business users building decision logic to improve business processes. Once decision logic is ready, true data needs will become clear.
Integrating business rules and machine learning to production systems can be problematic. Business rules and machine learning models need to be updated frequently. Externalizing the rules engine and machine learning allows decision authors to make frequent improvements to decision logic. When the rules engine and machine learning are integrated into production systems, updating decision logic becomes difficult because it will require changes to production systems.
Trying to automate all decisions will not work. It is important to decide which decisions to automate and which decisions to assign to humans. For example, business rules and machine learning cannot identify fraud 100% of the time; human involvement is still necessary for more complex claim cases.
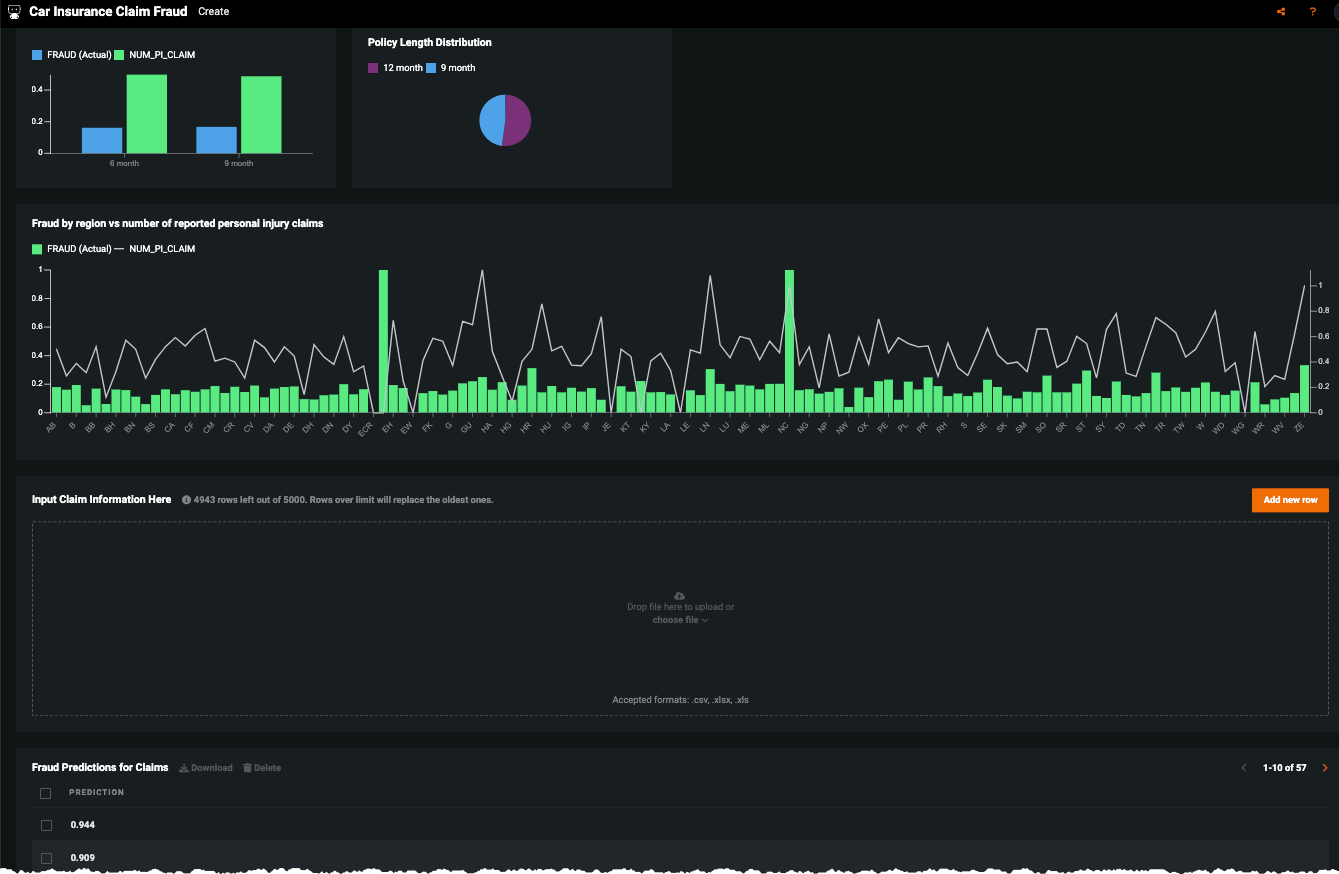
No-Code AI Apps¶
Consider building a custom application where stakeholders can interact with the predictions and record the outcomes of the investigation. Once the model is deployed, predictions can be consumed for use in the decision process. For example, this No-Code AI App is an easily shareable, AI-powered application using a no-code interface:
Notebook demo¶
See the notebook version of this accelerator here.