サーバー側でのスコアリング¶
以下では、UIから、または直接DataRobotバッチ予測APIを利用して、Snowflakeをクラウドネイティブデータベースとして使用する高度なスコアリングオプションについて説明します。 UIからのアプローチは、アドホックなユースケースや小規模なテーブルのサンドボックススコアリングジョブに適しています。 それより複雑な場合、APIを使用すると、より複雑な多段階のパイプラインジョブを柔軟に実行できます。 また、データ量が多い場合、S3を中間層として利用することは、リソースの使用量を厳密に管理し、コスト効率を最適化するための1つの選択肢となります。
- DataRobot UI:テーブルのスコアリング(APIが「バックグラウンドで」JDBCをサポート)
- DataRobot API:Query-as-Source(JDBC、API)
- DataRobot API:pre-SQLまたはpost-SQLを使用したS3スコアリング(S3、API)
各オプションには、ビジネス要件を満たすため、シンプルさとパフォーマンスの間でトレードオフの関係があります。 以下は、バッチ予測APIの概要と、すべてのスコアリングアプローチに共通の前提条件です。
バッチ予測API¶
バッチ予測APIを使用すると、スコアリング用に任意のサイズのデータセットをDataRobotに送信できます。 このデータは個々のHTTPリクエストに分割され、並列スレッドで送信されるため、利用可能な専用予測サーバー(DPS)がいっぱいになり、スコアリングのスループットが最大化されます。 ソースデータとターゲットデータは、ローカルファイル、S3/オブジェクトストレージ、またはJDBCデータ接続であり、組み合わせて使用することもできます。
詳細については、バッチ予測ドキュメントを参照してください。
注意事項¶
備考
デプロイとプロジェクトでは、アクセス権や権限が異なる場合があります。 たとえば、あるアカウントはモデルをスコアリングすることができても、そのモデルの作成に使用されたプロジェクトやデータを見ることができないかもしれません。 ベストプラクティスとして、運用ワークフローを特定の従業員ではなくサービスアカウントに関連付けて、運用スコアリングパイプラインから従業員を抽出します。
- DataRobotセルフマネージドAIプラットフォームのユーザーは、SnowflakeアカウントとDataRobot環境の間ですでに接続を確立している場合があります。 追加のネットワークアクセスが必要な場合は、インフラストラクチャチームがネットワーク接続を完全に制御できます。
- DataRobotがSnowflakeインスタンスにアクセスすることを希望するDataRobotマネージドAIプラットフォームユーザーには、追加のインフラストラクチャ設定が必要になる場合があります。サポートが必要な場合は、DataRobotサポートにお問い合わせください。 Snowflakeはデフォルトでパブリックアクセス可能です。 お客様はDataRobotが解決できない簡単なローカルDNSエントリー(customer.snowflakecomputing.com)を設定したり、パブリックIPをブロックするオプションを使用してAWS PrivateLinkを利用したりしている場合があります。
- Snowflake書き戻しアカウントには、ユースケースとワークフローに応じて、
CREATE TABLE、INSERT、UPDATEの権限が必要です。 さらに、JDBCドライバーには通常の配列バインディング挿入よりも高速なステージ一括挿入をCREATE STAGE実行する権限が必要です。 これにより、JDBCセッション中に使用できる一時ステージオブジェクトが作成されます。
DataRobot UI¶
テーブルのスコアリング¶
DataRobotアプリケーション内で、すばやく簡単なバッチスコアリングジョブを直接設定できます。 アドホックにジョブを実行することも、スケジュールすることもできます。 一般的に言えば、このスコアリングアプローチは、適度に小さいサイズのテーブルのスコアリングのみを必要とするユースケースに最適なオプションです。 これにより、スコアリングを実行し、サンドボックス/分析領域などのデータベースに書き戻すことができます。
外部データソースとしてSnowflakeを使用するJDBCコネクター、または外部ステージを使用するSnowflakeアダプターのいずれかを使用した、Snowflakeのバッチ予測ジョブ定義を設定する詳細なワークフローについては、Snowflake予測ジョブの例に関するドキュメントを参照してください。
DataRobot API¶
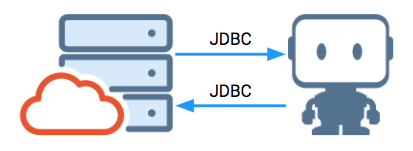
DataRobotのバッチ予測APIは、プログラムで使用することもできます。 UIではなくAPIを使用する利点は次のとおりです。
- 任意の運用パイプラインに要求コードを挿入して、スコアリング前とスコアリング後の手順間に配置できます。
- 既存のスケジューラーによって、または発生したイベントに応答して、コードをトリガーできます。
- AIカタログエントリーを作成する必要はありません。APIは、テーブル、ビュー、またはクエリーを受け入れます。
ソースとしてのクエリー¶
APIを使用する場合は、次の点に注意してください。
- バッチ予測ジョブは、初期化してからジョブキューに追加する必要があります。
- ローカルファイルからのジョブは、データがアップロードされるまで開始されません。
- SnowflakeからSnowflakeへのジョブの場合、パイプラインの両端にSnowflakeソースとターゲットを設定する必要があります。
ジョブに関する追加の詳細(デプロイ、予測ホスト、パススルー列)も指定できます(使用可能なオプションの完全なリストについては、バッチ予測APIのドキュメントを参照してください)。
以下は、DataRobotのバッチ予測APIを使用して、基本的なJDBC接続を介してSnowflakeデータをスコアリングする方法の例です。
import pandas as pd
import requests
import time
from pandas.io.json import json_normalize
import json
import my_creds
# datarobot parameters
API_KEY = my_creds.API_KEY
USERNAME = my_creds.USERNAME
DEPLOYMENT_ID = my_creds.DEPLOYMENT_ID
DATAROBOT_KEY = my_creds.DATAROBOT_KEY
# replace with the load balancer for your prediction instance(s)
DR_PREDICTION_HOST = my_creds.DR_PREDICTION_HOST
DR_APP_HOST = 'https://app.datarobot.com'
DR_MODELING_HEADERS = {'Content-Type': 'application/json', 'Authorization': 'token %s' % API_KEY}
headers = {'Content-Type': 'text/plain; charset=UTF-8', 'datarobot-key': DATAROBOT_KEY}
url = '{dr_prediction_host}/predApi/v1.0/deployments/{deployment_id}/'\
'predictions'.format(dr_prediction_host=DR_PREDICTION_HOST, deployment_id=DEPLOYMENT_ID)
# snowflake parameters
SNOW_USER = my_creds.SNOW_USER
SNOW_PASS = my_creds.SNOW_PASS
既存のデータ接続を利用してデータベースに接続できます(データ取込みページUIを使用した例)。 以下の例では、データ接続は名前検索を使用しています。
"""
get a data connection by name, return None if not found
"""
def dr_get_data_connection(name):
data_connection_id = None
response = requests.get(
DR_APP_HOST + '/api/v2/externalDataStores/',
headers=DR_MODELING_HEADERS,
)
if response.status_code == 200:
df = pd.io.json.json_normalize(response.json()['data'])[['id', 'canonicalName']]
if df[df['canonicalName'] == name]['id'].size > 0:
data_connection_id = df[df['canonicalName'] == name]['id'].iloc[0]
else:
print('Request failed; http error {code}: {content}'.format(code=response.status_code, content=response.content))
return data_connection_id
data_connection_id = dr_get_data_connection('snow_3_12_0_titanic')
バッチ予測ジョブには資格情報を指定する必要があります。Snowflakeユーザー資格情報をサーバーに安全に保存して、ジョブを実行できます。 適用されるDataRobot権限は、リクエストまたはセッションのヘッダーレベルでDataRobot APIトークンを介して確立されます。 これらの権限では、作成された予測ジョブを「所有」し、デプロイされたモデルにアクセスできる必要があります。 次のコードスニペットを使用して、データベースの資格情報を作成または検索できます。
# get a saved credential set, return None if not found
def dr_get_catalog_credentials(name, cred_type):
if cred_type not in ['basic', 's3']:
print('credentials type must be: basic, s3 - value passed was {ct}'.format(ct=cred_type))
return None
credentials_id = None
response = requests.get(
DR_APP_HOST + '/api/v2/credentials/',
headers=DR_MODELING_HEADERS,
)
if response.status_code == 200:
df = pd.io.json.json_normalize(response.json()['data'])[['credentialId', 'name', 'credentialType']]
if df[(df['name'] == name) & (df['credentialType'] == cred_type)]['credentialId'].size > 0:
credentials_id = df[(df['name'] == name) & (df['credentialType'] == cred_type)]['credentialId'].iloc[0]
else:
print('Request failed; http error {code}: {content}'.format(code=response.status_code, content=response.content))
return credentials_id
# create credentials set
def dr_create_catalog_credentials(name, cred_type, user, password, token=None):
if cred_type not in ['basic', 's3']:
print('credentials type must be: basic, s3 - value passed was {ct}'.format(ct=cred_type))
return None
if cred_type == 'basic':
json = {
"credentialType": cred_type,
"user": user,
"password": password,
"name": name
}
elif cred_type == 's3' and token != None:
json = {
"credentialType": cred_type,
"awsAccessKeyId": user,
"awsSecretAccessKey": password,
"awsSessionToken": token,
"name": name
}
elif cred_type == 's3' and token == None:
json = {
"credentialType": cred_type,
"awsAccessKeyId": user,
"awsSecretAccessKey": password,
"name": name
}
response = requests.post(
url = DR_APP_HOST + '/api/v2/credentials/',
headers=DR_MODELING_HEADERS,
json=json
)
if response.status_code == 201:
return response.json()['credentialId']
else:
print('Request failed; http error {code}: {content}'.format(code=response.status_code, content=response.content))
# get or create a credential set
def dr_get_or_create_catalog_credentials(name, cred_type, user, password, token=None):
cred_id = dr_get_catalog_credentials(name, cred_type)
if cred_id == None:
return dr_create_catalog_credentials(name, cred_type, user, password, token=None)
else:
return cred_id
credentials_id = dr_get_or_create_catalog_credentials('snow_community_credentials',
'basic', my_creds.SNOW_USER, my_creds.SNOW_PASS)
ジョブを定義するセッションを作成します。次に、ジョブを送信し、非同期で実行するようスロットに入れます。 送信が成功すると、DataRobotはHTTP 202ステータスコードを返します。 ジョブの現在の状態をAPIに照会することで、ジョブの状態を取得できます。
session = requests.Session()
session.headers = {
'Authorization': 'Bearer {}'.format(API_KEY)
}
結果を保持するテーブルは、以下の構造を反映して、次のSQLステートメントを使用してSnowflakeに作成されます。
create or replace TABLE PASSENGERS_SCORED_BATCH_API (
SURVIVED_1_PREDICTION NUMBER(10,9),
SURVIVED_0_PREDICTION NUMBER(10,9),
SURVIVED_PREDICTION NUMBER(38,0),
THRESHOLD NUMBER(6,5),
POSITIVE_CLASS NUMBER(38,0),
PASSENGERID NUMBER(38,0)
);
ジョブは次のパラメーターを指定します。
| 名前 | 説明 |
|---|---|
| ソース | Snowflake JDBC |
| ソースデータ | クエリー結果(乗客からの単純な選択) |
| ソース取得サイズ | 100,000(最大取得データサイズ) |
| ジョブの同時実行 | 4つの予測コアスレッドが要求されました |
| パススルー列 | 代理キーを保持する PASSENGERID |
| ターゲットテーブル | PUBLIC.PASSENGERS_SCORED_BATCH_API |
statementType |
挿入 (データはテーブルに挿入されます) |
job_details = {
"deploymentId": DEPLOYMENT_ID,
"numConcurrent": 4,
"passthroughColumns": ["PASSENGERID"],
"includeProbabilities": True,
"predictionInstance" : {
"hostName": DR_PREDICTION_HOST,
"sslEnabled": false,
"apiKey": API_KEY,
"datarobotKey": DATAROBOT_KEY,
},
"intakeSettings": {
"type": "jdbc",
"fetchSize": 100000,
"dataStoreId": data_connection_id,
"credentialId": credentials_id,
#"table": "PASSENGERS_500K",
#"schema": "PUBLIC",
"query": "select * from PASSENGERS"
},
'outputSettings': {
"type": "jdbc",
"table": "PASSENGERS_SCORED_BATCH_API",
"schema": "PUBLIC",
"statementType": "insert",
"dataStoreId": data_connection_id,
"credentialId": credentials_id
}
}
ジョブの送信が成功すると、DataRobotの応答で、ジョブの状態と詳細を確認するためのリンクが提供されます。
response = session.post(
DR_APP_HOST + '/api/v2/batchPredictions',
json=job_details
)
他のジョブがキューの前にあるかどうかに応じて、ジョブがキューにある場合とない場合があります。 起動すると、初期化に進み、中止または完了するまでステージを実行します。 ループを作成して、非同期ジョブの状態を繰り返しチェックし、ジョブがABORTEDまたはCOMPLETEDのステータスで完了するまでプロセスの制御を保持できます。
if response.status_code == 202:
job = response.json()
print('queued batch job: {}'.format(job['links']['self']))
while job['status'] == 'INITIALIZING':
time.sleep(3)
response = session.get(job['links']['self'])
response.raise_for_status()
job = response.json()
print('completed INITIALIZING')
if job['status'] == 'RUNNING':
while job['status'] == 'RUNNING':
time.sleep(3)
response = session.get(job['links']['self'])
response.raise_for_status()
job = response.json()
print('completed RUNNING')
print('status is now {status}'.format(status=job['status']))
if job['status'] != 'COMPLETED':
for i in job['logs']:
print(i)
else:
print('Job submission failed; http error {code}: {content}'.format(code=response.status_code, content=response.content))
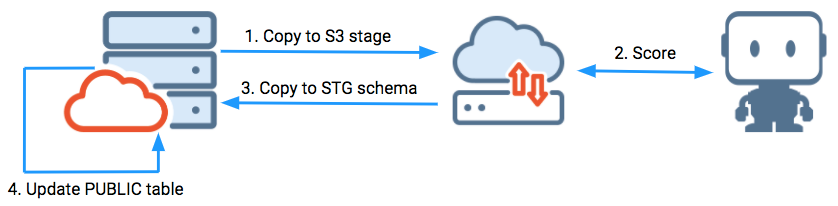
pre/post SQL(新しいレコード)によるS3スコアリング¶
この例では、Snowflakeのソースとターゲットの間でS3パイプラインを使用しています。 SQLでの前処理または後処理は必要ありません。
この例は、以下を示しています。
-
最後に成功したスコアリング実行前の取得に基づく、新しいレコードのスコアリングの変更。
-
ターゲットテーブルにデータを入力し、成功したETL実行履歴を更新するスコアリング後のプロセス。
この例では、ETL/ELTパイプラインをサポートするために存在するSnowflakeのSTGスキーマにデータが読み込まれます。 その後、一括更新によってPUBLICスキーマのターゲットプレゼンテーションテーブルに更新されます。 個々の更新ステートメントは、Snowflakeやその他の分析データベースと従来の行ストア運用データベースでは非常に遅くなるため一括更新を使用します。
ターゲットプレゼンテーションテーブルには、スコアリングされた結果のテーブル(SURVIVALフィールド)から目的の単一フィールドが含まれています。 S3を使用すると、データの抽出と読み込みでステージオブジェクトを使用できます。 スコアリングとは別に個別の操作を使用すると、パイプライン操作中にETLコンピューティングウェアハウスが稼働している時間を最小限に抑えることができます。
S3がスコアリングパイプラインの一部になる可能性がある考慮事項には、次のようなものがあります。
- Snowflakeのネイティブ設計を活用してS3に書き込みます(場合によっては、データを複数のファイルに分割します)。
- ネイティブの一括挿入機能を使用します。
- 現在、Snowflakeコンピューティングウェアハウスは、クラスターのスピンアップの最初の60秒に基づいて課金され、その後は1秒ごとに課金されます。 以前の方法(上記)は、JDBCを介してデータをストリーミングし、スコアリングプロセス全体でクラスターをアクティブに保ちます。 抽出、スコアリング、取込みの手順を個別に分離すると、コンピューティングウェアハウスが実際に実行している時間が短縮され、コストの削減につながります。
- S3入力とスコアセットを使用して、データの特定の時点でのアーカイブを簡単に作成できます。
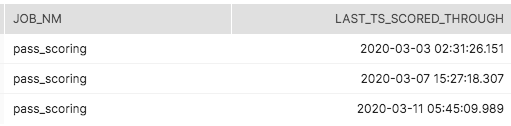
この例では、単純なETL_HISTORYテーブルは、スコアリングジョブの履歴を表示しています。 ジョブの名前はpass_scoringで、最後の3回は3月3日、7日、11日に実行されました。
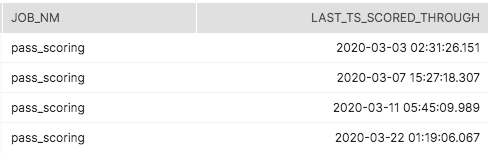
次のジョブは、前回の実行以降、もしくは現在のジョブ実行のタイムスタンプより前に変更されたすべてのレコードをスコアリングします。 ジョブが正常に完了すると、このテーブルに新しいレコードが配置されます。

このテーブルでスコアリングされた50万件のレコード:
- この例の1列目はスコアリングされません。11日に成功した前回のETL実行以来、変更されていません。
- 2列目は20日に更新されたため、再スコアリングの対象となります。
- 3列目は19日に新しく作成されたため、最初のスコアリングになります。
以下は、DataRobot、Snowflake、AWS S3の初期インポートとさまざまな環境変数です。
import pandas as pd
import requests
import time
from pandas.io.json import json_normalize
import snowflake.connector
import my_creds
# datarobot parameters
API_KEY = my_creds.API_KEY
USERNAME = my_creds.USERNAME
DEPLOYMENT_ID = my_creds.DEPLOYMENT_ID
DATAROBOT_KEY = my_creds.DATAROBOT_KEY
# replace with the load balancer for your prediction instance(s)
DR_PREDICTION_HOST = my_creds.DR_PREDICTION_HOST
DR_APP_HOST = 'https://app.datarobot.com'
DR_MODELING_HEADERS = {'Content-Type': 'application/json', 'Authorization': 'token %s' % API_KEY}
# snowflake parameters
SNOW_ACCOUNT = my_creds.SNOW_ACCOUNT
SNOW_USER = my_creds.SNOW_USER
SNOW_PASS = my_creds.SNOW_PASS
SNOW_DB = 'TITANIC'
SNOW_SCHEMA = 'PUBLIC'
# ETL parameters
JOB_NAME = 'pass_scoring'
前の例と同様に、S3を利用するには資格情報を指定する必要があります。次のコードスニペットを使用して、S3アクセスの資格情報を作成、保存、検索できます。 アカウントには、Snowflakeステージオブジェクトがデータの読み取り/書き込みに使用しているのと同じ領域にアクセスする権限が必要です(詳細については、Snowflakeのステージの作成に関する記事を参照してください)。
# get a saved credential set, return None if not found
def dr_get_catalog_credentials(name, cred_type):
if cred_type not in ['basic', 's3']:
print('credentials type must be: basic, s3 - value passed was {ct}'.format(ct=cred_type))
return None
credentials_id = None
response = requests.get(
DR_APP_HOST + '/api/v2/credentials/',
headers=DR_MODELING_HEADERS,
)
if response.status_code == 200:
df = pd.io.json.json_normalize(response.json()['data'])[['credentialId', 'name', 'credentialType']]
if df[(df['name'] == name) & (df['credentialType'] == cred_type)]['credentialId'].size > 0:
credentials_id = df[(df['name'] == name) & (df['credentialType'] == cred_type)]['credentialId'].iloc[0]
else:
print('Request failed; http error {code}: {content}'.format(code=response.status_code, content=response.content))
return credentials_id
# create credentials set
def dr_create_catalog_credentials(name, cred_type, user, password, token=None):
if cred_type not in ['basic', 's3']:
print('credentials type must be: basic, s3 - value passed was {ct}'.format(ct=cred_type))
return None
if cred_type == 'basic':
json = {
"credentialType": cred_type,
"user": user,
"password": password,
"name": name
}
elif cred_type == 's3' and token != None:
json = {
"credentialType": cred_type,
"awsAccessKeyId": user,
"awsSecretAccessKey": password,
"awsSessionToken": token,
"name": name
}
elif cred_type == 's3' and token == None:
json = {
"credentialType": cred_type,
"awsAccessKeyId": user,
"awsSecretAccessKey": password,
"name": name
}
response = requests.post(
url = DR_APP_HOST + '/api/v2/credentials/',
headers=DR_MODELING_HEADERS,
json=json
)
if response.status_code == 201:
return response.json()['credentialId']
else:
print('Request failed; http error {code}: {content}'.format(code=response.status_code, content=response.content))
# get or create a credential set
def dr_get_or_create_catalog_credentials(name, cred_type, user, password, token=None):
cred_id = dr_get_catalog_credentials(name, cred_type)
if cred_id == None:
return dr_create_catalog_credentials(name, cred_type, user, password, token=None)
else:
return cred_id
credentials_id = dr_get_or_create_catalog_credentials('s3_community',
's3', my_creds.SNOW_USER, my_creds.SNOW_PASS)
次に、Snowflakeへの接続を作成し、最後に成功した実行時間と現在の時間を使用して、境界を作成し、スコアリングする必要がある新規作成された行や最近更新された行を決定します。
# create a connection
ctx = snowflake.connector.connect(
user=SNOW_USER,
password=SNOW_PASS,
account=SNOW_ACCOUNT,
database=SNOW_DB,
schema=SNOW_SCHEMA,
protocol='https',
application='DATAROBOT',
)
# create a cursor
cur = ctx.cursor()
# execute sql to get start/end timestamps to use
sql = "select last_ts_scored_through, current_timestamp::TIMESTAMP_NTZ cur_ts " \
"from etl_history " \
"where job_nm = '{job}' " \
"order by last_ts_scored_through desc " \
"limit 1 ".format(job=JOB_NAME)
cur.execute(sql)
# fetch results into dataframe
df = cur.fetch_pandas_all()
start_ts = df['LAST_TS_SCORED_THROUGH'][0]
end_ts = df['CUR_TS'][0]
データをS3にダンプします。
# execute sql to dump data into a single file in S3 stage bucket
# AWS single file snowflake limit 5 GB
sql = "COPY INTO @S3_SUPPORT/titanic/community/" + JOB_NAME + ".csv " \
"from " \
"( " \
" select passengerid, pclass, name, sex, age, sibsp, parch, ticket, fare, cabin, embarked " \
" from passengers_500k_ts " \
" where nvl(updt_ts, crt_ts) >= '{start}' " \
" and nvl(updt_ts, crt_ts) < '{end}' " \
") " \
"file_format = (format_name='default_csv' compression='none') header=true overwrite=true single=true;".format(start=start_ts, end=end_ts)
cur.execute(sql)
次に、DataRobotバッチ予測APIスコアリングジョブの送信を実行し、その進行状況を監視するためのセッションを作成します。
session = requests.Session()
session.headers = {
'Authorization': 'Bearer {}'.format(API_KEY)
}
ジョブは、Snowflakeからファイルダンプを入力として取得し、同じS3パスに_scoredが追加されたファイルを作成するように定義されています。 この例では、後で結合される代理キーPASSENGERIDのパススルーを使用して、4つの予測コアの同時実行を指定しています。
INPUT_FILE = 's3://'+ my_creds.S3_BUCKET + '/titanic/community/' + JOB_NAME + '.csv'
OUTPUT_FILE = 's3://'+ my_creds.S3_BUCKET + '/titanic/community/' + JOB_NAME + '_scored.csv'
job_details = {
'deploymentId': DEPLOYMENT_ID,
'passthroughColumns': ['PASSENGERID'],
'numConcurrent': 4,
"predictionInstance" : {
"hostName": DR_PREDICTION_HOST,
"datarobotKey": DATAROBOT_KEY
},
'intakeSettings': {
'type': 's3',
'url': INPUT_FILE,
'credentialId': credentials_id
},
'outputSettings': {
'type': 's3',
'url': OUTPUT_FILE,
'credentialId': credentials_id
}
}
処理用ジョブを送信し、監視用のURLを取得します。
response = session.post(
DR_APP_HOST + '/api/v2/batchPredictions',
json=job_details
)
ジョブが完了するまで制御します。
if response.status_code == 202:
job = response.json()
print('queued batch job: {}'.format(job['links']['self']))
while job['status'] == 'INITIALIZING':
time.sleep(3)
response = session.get(job['links']['self'])
response.raise_for_status()
job = response.json()
print('completed INITIALIZING')
if job['status'] == 'RUNNING':
while job['status'] == 'RUNNING':
time.sleep(3)
response = session.get(job['links']['self'])
response.raise_for_status()
job = response.json()
print('completed RUNNING')
print('status is now {status}'.format(status=job['status']))
if job['status'] != 'COMPLETED':
for log in job['logs']:
print(log)
else:
print('Job submission failed; http error {code}: {content}'.format(code=response.status_code, content=response.content))
完了したら、ステージングテーブルをSTGスキーマテーブルPASSENGERS_SCORED_BATCH_APIに読み込み、切り捨ておよび一括読み込み操作による予測結果を読み込みます。
# multi-statement executions
# https://docs.snowflake.com/ja/user-guide/python-connector-api.html#execute_string
# truncate and load STG schema table with scored results
sql = "truncate titanic.stg.PASSENGERS_SCORED_BATCH_API; " \
" copy into titanic.stg.PASSENGERS_SCORED_BATCH_API from @S3_SUPPORT/titanic/community/" + JOB_NAME + "_scored.csv" \
" FILE_FORMAT = 'DEFAULT_CSV' ON_ERROR = 'ABORT_STATEMENT' PURGE = FALSE;"
ctx.execute_string(sql)
最後に、生存の正のクラスラベル1に向けた最新の生存率スコアでプレゼンテーションテーブルを更新するトランザクションを作成します。 すべてのタスクが正常に完了すると、ETL履歴が更新されます。
# update target presentation table and ETL history table in transaction
sql = \
"begin; " \
"update titanic.public.passengers_500k_ts trg " \
"set trg.survival = src.survived_1_prediction " \
"from titanic.stg.PASSENGERS_SCORED_BATCH_API src " \
"where src.passengerid = trg.passengerid; " \
"insert into etl_history values ('{job}', '{run_through_ts}'); " \
"commit; ".format(job=JOB_NAME, run_through_ts=end_ts)
ctx.execute_string(sql)
2列目と3列目は、予想どおりに新しい生存率スコアで更新されます。

ETL履歴が更新され、後続の実行は(最新の)成功したタイムスタンプに基づいています。
考慮すべき機能強化:
- ワークフローとツールセットに適したエラー処理、スコアリングなどを追加します。
- AWS Lambdaなどのサーバーレステクノロジーをスコアリングワークフローに組み込み、S3オブジェクトの作成などのイベントに基づいてジョブを開始します。
- データボリュームが増大するにつれて、次の点を考慮してください。 Snowflakeの単一ステートメントのダンプと取込みは、クラスターノードあたり約8つのスレッドで最高のパフォーマンスを発揮します。 ノード2のSmallは、ノード1のXSmallインスタンスよりも速く1つのファイルを取り込むことはありません。XSmallは、8つ以上のファイルスレッドで最適なパフォーマンスを発揮する可能性があります。