データの取込みとプロジェクトの作成¶
DataRobotでプロジェクトを作成するには、まずトレーニングデータセットを取り込む必要があります。 このデータセットは、モデリングに使用される前に、データエンジニアリングまたは特徴量エンジニアリングプロセスを経る場合と経ない場合があります。
備考
指定されている使用例はSnowflakeに限定されたものではなく、他のデータベースに部分的または全体的に適用できます。
このデータをDataRobotに取り込むには、大きく分けて2つの方法があります。
-
プッシュ
DataRobotにデータを送信し、それを使用してプロジェクトを作成します。 たとえば、サポート可能なファイルタイプをGUIにドラッグしたり、DataRobot APIを利用したりすることができます。
-
プル
どこか(データセットへのURLなど)からデータを取得するか、データベース接続を介して、プロジェクトを作成します。
以下に両方の例を示します。 よく知られているKaggleのタイタニック号生存率データセットを使用して、1つの表形式データセットを、特徴量エンジニアリングされた新規列1つで作成します。具体的には、次のとおりです。
total_family_size = sibsp + parch + 1
プッシュ:DataRobotのモデリングAPI¶
DataRobotの操作は、UI経由で行うことも、REST APIを使用してプログラムで行うこともできます。 APIは利用可能なR SDKまたはPython SDKを使用して、一般的なマルチステップおよび非同期プロセスで呼び出しとワークフローを簡素化します。 以下のプロセスでは、プロジェクトの作成にPython 3およびDataRobot Python SDKパッケージを利用します。
これらの例で使用されるデータは、Python用Snowflakeコネクターから取得されます。 データ操作を容易にするために、Pandas互換のドライバーインストールオプションを使用して、データフレームを使用した特徴量エンジニアリングに対応します。
まず、必要なライブラリと認証情報をインポートします。便宜上、この例ではスクリプトにハードコードされています。
import snowflake.connector
import datetime
import datarobot as dr
import pandas as pd
# snowflake parameters
SNOW_ACCOUNT = 'my_creds.SNOW_ACCOUNT'
SNOW_USER = 'my_creds.SNOW_USER'
SNOW_PASS = 'my_creds.SNOW_PASS'
SNOW_DB = 'TITANIC'
SNOW_SCHEMA = 'PUBLIC'
# datarobot parameters
DR_API_TOKEN = 'YOUR API TOKEN'
# replace app.datarobot.com with application host of your cluster if installed locally
DR_ENDPOINT = 'https://app.datarobot.com/api/v2'
DR_HEADERS = {'Content-Type': 'application/json', 'Authorization': 'token %s' % DR_API_TOKEN}
以下では、トレーニングデータセットがテーブルTITANIC.PUBLIC.PASSENGERS_TRAININGに読み込まれ、取得されてpandasデータフレームに取り込まれます。
# create a connection
ctx = snowflake.connector.connect(
user=SNOW_USER,
password=SNOW_PASS,
account=SNOW_ACCOUNT,
database=SNOW_DB,
schema=SNOW_SCHEMA,
protocol='https',
application='DATAROBOT',
)
# create a cursor
cur = ctx.cursor()
# execute sql
sql = "select * from titanic.public.passengers_training"
cur.execute(sql)
# fetch results into dataframe
df = cur.fetch_pandas_all()
df.head()

その後、Python内で特徴量エンジニアリングを実行できます(この場合は、Pandasライブラリを使用)。
備考
Snowflakeでは特徴量名を大文字にします。引用されていない限り、列名を大文字にし、大文字と小文字を区別しないというANSI標準のSQL規則に従っているためです。
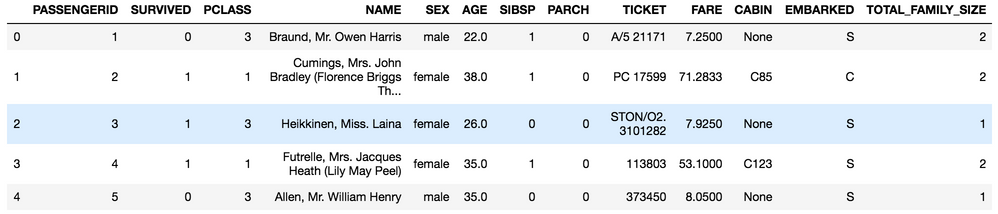
# feature engineering a new column for total family size
df['TOTAL_FAMILY_SIZE'] = df['SIBSP'] + df['PARCH'] + 1
df.head()
その後、DataRobotにデータが送信され、新しいモデリングプロジェクトが開始されます。
# create a connection to datarobot
dr.Client(token=DR_API_TOKEN, endpoint=DR_MODELING_ENDPOINT)
# create project
now = datetime.datetime.now().strftime('%Y-%m-%dT%H:%M')
project_name = 'Titanic_Survival_{}'.format(now)
proj = dr.Project.create(sourcedata=df,
project_name=project_name)
# further work with project via the python API, or work in GUI (link to project printed below)
print(DR_MODELING_ENDPOINT[:-6] + 'projects/{}'.format(proj.id))
SDKを使用して、プロジェクトをさらに操作できます。
プル:Snowflake JDBC SQL¶
Snowflakeはクラウドネイティブであり、デフォルトで公開されています。 DataRobotプラットフォームは、データベース接続を確立するためのJDBCドライバーのインストールをサポートしています。 ローカルでホストされているデータベースから接続するには、ファイアウォールポートを開いてDataRobotへのアクセスを提供し、着信トラフィックのIPアドレスをホワイトリストに登録する必要があります。 AWS PrivateLinkのようなサービスがSnowflakeインスタンスの前で利用されている場合は、同様の追加手順を実行する必要がある場合があります。
備考
特定のIPアドレスからの接続のみを許可するネットワークポリシーでデータベースが保護されている場合は、管理者がネットワークポリシー(ホワイトリスト)に追加する必要があるアドレスのリストについてDataRobotサポートにお問い合わせください。
DataRobotマネージドAIプラットフォームにはJDBCドライバーがインストールされており、利用可能です。セルフマネージドAIプラットフォームインストールのお客様は、ドライバーを追加する必要があります(必要に応じて、DataRobotサポートにお問い合わせください)。
JDBC接続を確立し、AIカタログを使用してSQL経由でソースからプロジェクトを開始できます。 JDBC接続を使用して、Snowflakeに接続されたオブジェクトを設定します。
-
DataRobotでSnowflakeデータ接続を作成します。
JDBCドライバー接続文字列の形式は、Snowflakeのドキュメントに記載されています。 この例では、データベースの名前は
titanicです。パラメーターが指定されていない場合、Snowflakeアカウントのログインに関連付けられたデフォルト値が使用されます。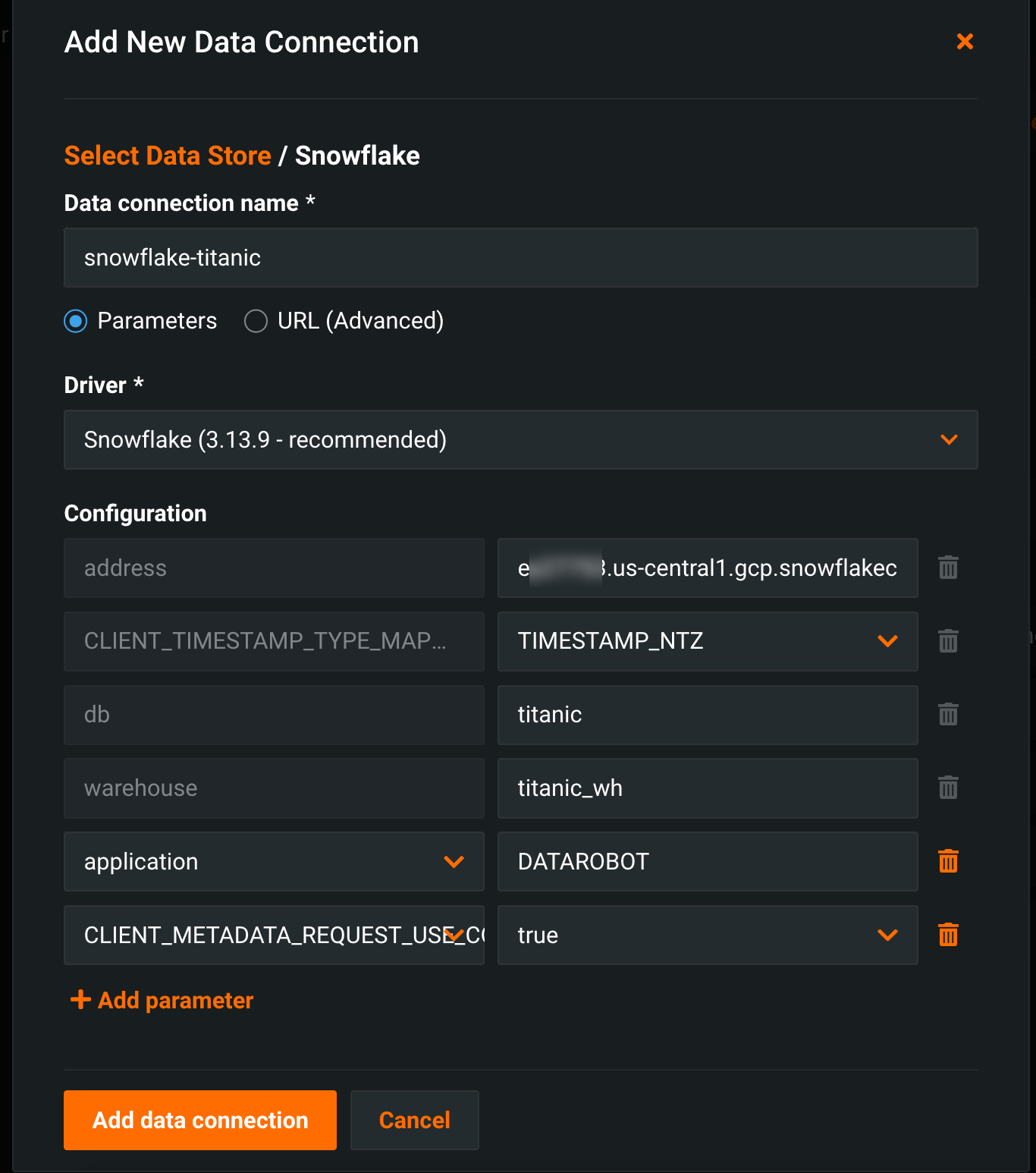
-
データ接続が作成されたことで、AIカタログにアセットをインポートできるようになりました。 AIカタログで、カタログに追加 > 既存のデータ接続をクリックし、新しく作成した接続を選択して、資格情報のプロンプトに応答します。 以前にデータベースに接続したことがある場合、DataRobotは、保存した資格情報から選択するオプションを提供します。
接続が成功すると、DataRobotはアクセス可能なオブジェクトのメタデータを表示します。 この例では、新しい列の特徴量エンジニアリングはSQLで行われます。
-
オブジェクト参照オプションではなく、SQLクエリを選択します。 新しい特徴量を抽出して作成するためのSQLは、ここで記述してテストできます。
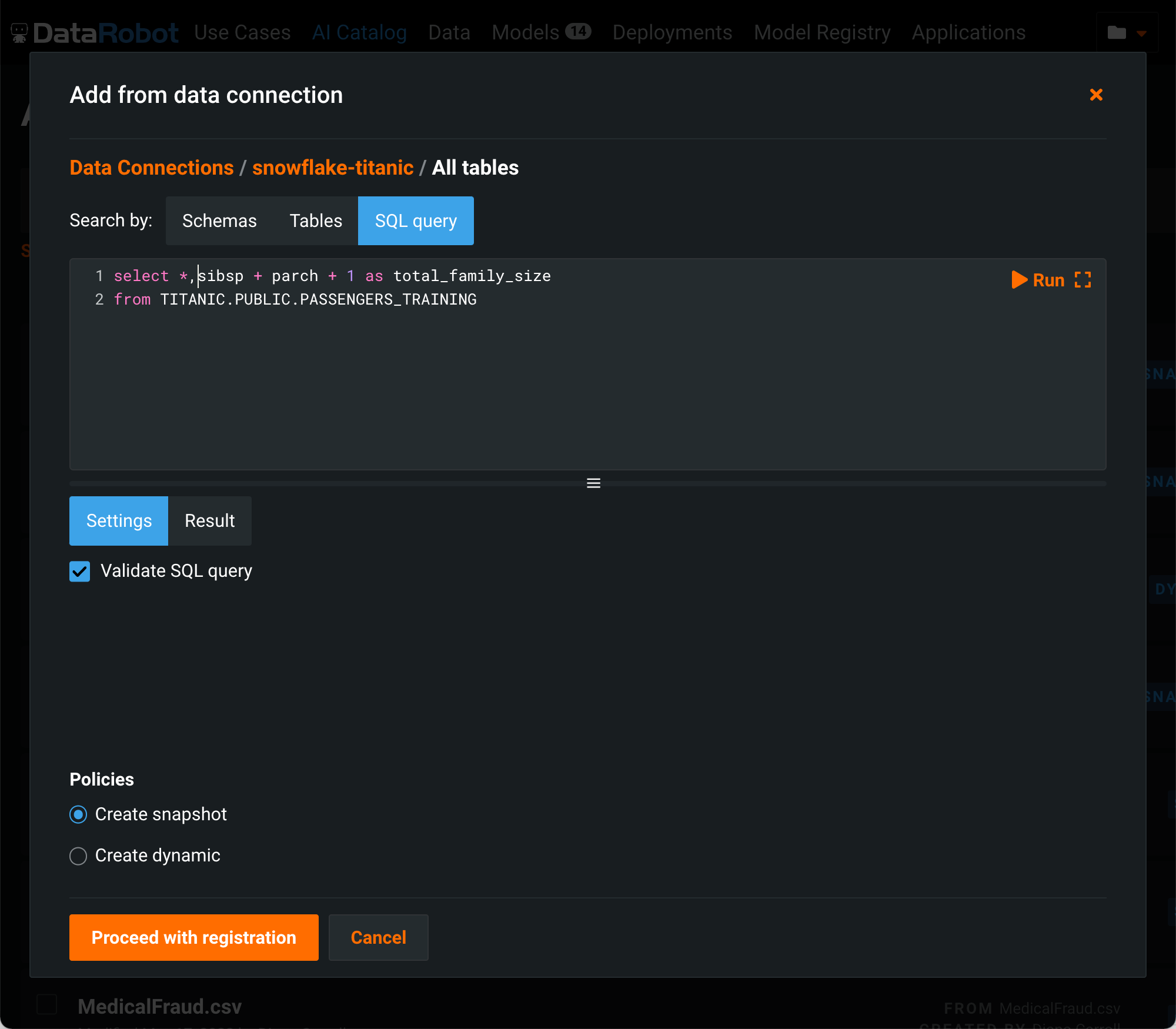
スナップショットを作成オプションに注意してください。 チェックをオンにすると、DataRobotはデータを抽出し、カタログ内のデータセットを具体化します(また、スナップショットラベルをカタログリストへ追加します)。 スナップショットはユーザー間で共有でき、プロジェクトの作成に使用できますが、データセットの新しいスナップショットを作成して具体化されたデータを最新のデータセットで更新しない限り、データベースから再度更新されることはありません。 または、動的データセットを追加することもできます。 動的な場合、後続の使用ごとにDataRobotがデータベースに対してクエリを再実行し、最新のデータを取得します。 登録が正常に完了すると、データセットがパブリッシュされ、使用できるようになります。
この方法に関するいくつかの追加の考慮事項:
- 動的データセットのSQLは編集できません。
- あるプロジェクトから次のプロジェクトへのトレーニングデータセットのパーティションに影響を与える可能性があるため、データを並べ替えたい場合があります。
- 動的データセットのベストプラクティスは、すべての列に「*」を使用するのではなく、対象の各列をリストすることです。
- 時系列データセットの場合、データを並べ替えるにはデータをグループ化し、時間要素で並べ替えます。
- プロジェクトの反復中に変更できる基本的なロジックを使用して、ビューに接続したい場合があります。 このワークフローを実装すると、抽出時にプロジェクトインスタンスを特定のビューロジックに関連付けるのが難しくなる可能性があります。
DataRobotとSnowflakeを使用したこのモデルのスコアリング手法については、リアルタイム予測を参照してください。