MLOpsへのAWS Lambdaレポート¶
このトピックでは、予測項目の結果が出たら、サーバーレスで実測値データをDataRobotに報告する方法について説明します。 実行ファイルにはPython 3.7を使用しています。
アーキテクチャ¶
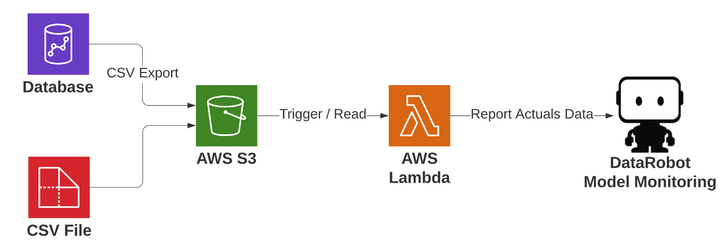
プロセスは次のように機能します。
- DataRobotに報告する結果を含むCSVファイルがAWS S3に到着します。 これらは、任意のプロセスから作成されたファイルです。 上記の例には、S3に結果を書き込むデータベースや、S3にCSVファイルを送信するプロセスが含まれます。
- 監視対象のディレクトリに到着すると、サーバーレスコンピューティングのAWS Lambda関数がトリガーされます。
- DataRobotでの関連デプロイは、CSVファイルへのS3バケットパス名で指定されるため、Lambdaはあらゆるデプロイで汎用的に機能します。
-
Lambdaはデプロイを解析し、CSVファイルを読み取り、結果をDataRobotに報告して処理します。 その後、プラットフォーム内でさまざまな角度から結果を調べることができます。
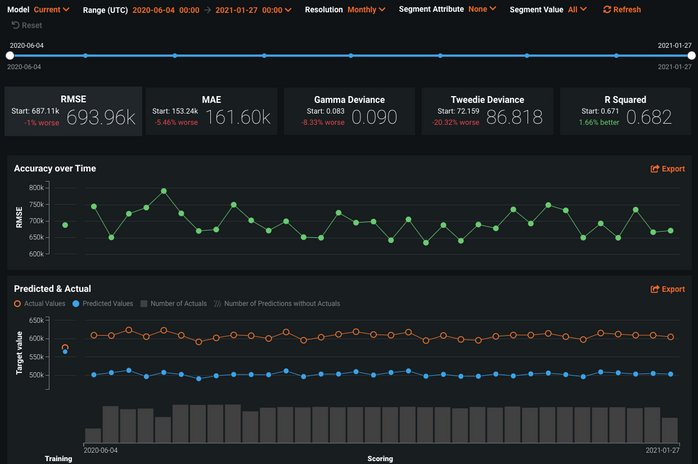
S3バケットを作成、または既存のものを使用¶
実際のCSV予測結果は、AWS S3バケットの監視領域に書き込まれます。 存在しない場合は、結果を受け取るための領域を新規に作成します。 サーバー、プログラム、データベースなどの外部ソースから、ファイルがこのバケットにコピーされることが想定されます。 バケットを作成するには、AWSコンソール内でS3サービスに移動し、バケットを作成するをクリックします。 バケットの名前(datarobot-actualbucketなど)とリージョンを指定し、バケットを作成をクリックします。 組織の方針で必要な場合は、デフォルトを変更します。
Lambda用IAMロールの作成¶
Identity and Access Management(IAM)に移動します。 ロールで、ロールの作成を選択します。 ユースケースとしてAWSサービスとLambdaを選択し、次のステップ:アクセス権限に移動します。 AWSLambdaBasicExecutionRoleポリシーを検索して追加します。 次の手順に進み、ロール名lambda_upload_actuals_roleを指定します。 ロールの作成をクリックしてタスクを完了します。
このロールには、次の2つのポリシーを関連付ける必要があります。
- AWS管理ポリシー「AWSLambdaBasicExecutionRole」
- このLambdaに関連付けられたS3オブジェクト/ファイルへのアクセスと管理に使用するインラインポリシー。 次のように、S3バケット監視用のインラインポリシーを指定します:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::datarobot-actualbucket",
"arn:aws:s3:::datarobot-actualbucket/*"
]
}
]
}
Lambdaの作成¶
GUIコンソールでAWS Lambdaサービスに移動し、ダッシュボードから関数の作成をクリックします。 lambda_upload_actualsなどの名前を指定します。 ランタイム環境セクションで、Python 3.7を選択します。実行ロールセクションを展開し、既存のロールを使用するを選択し、上で作成したlambda_upload_actuals_roleを選択します。
Lambdaトリガーの追加¶
このLambdaは、監視しているパスにCSVファイルが到着するたびに実行されます。 デザイナー画面から、+トリガーを追加を選択し、ドロップダウンリストからS3を選択します。 バケットには、上で作成したIAMロールポリシーで指定されたものを選択します。 (オプション)バケットを他の目的で使用する場合はプレフィックスを指定します。 たとえば、s3://datarobot-actualbucket/upload_actuals/に到着するオブジェクトのみを監視する場合は、値upload_actuals/をプレフィックスとして使用します。
(この例のデータは、s3://datarobot-actualbucket/upload_actuals/2f5e3433_DEPLOYMENT_ID_123/actuals.csvと同様に到着すると想定されています。)追加をクリックし、トリガーを保存します。
Lambdaレイヤーの作成および追加¶
Lambdaレイヤーを使用すると、ライブラリの上にLambdaコードを構築し、そのコードを配信パッケージから分離できます。 ライブラリを分離する必要はありませんが、レイヤーを使用すると、必要なパッケージを取り込んでコードを維持するプロセスが簡素化されます。 このコードには、リクエストとpandasライブラリが必要になりますが、Lambdaが実行されるAmazon Linuxのベースイメージには含まれていません。そのため、レイヤーを介してこれらを追加する必要があります。 これを行うには、仮想環境を作成します。 この例では、以下のコードを実行するためにAmazon Linux EC2ボックス環境を使用します。 (こちらのAmazon LinuxにPython 3をインストールする手順を参照してください。)
レイヤーのZIPファイルを作成するには、以下を実行します。
python3 -m venv my_app/env
source ~/my_app/env/bin/activate
pip install requests
pip install pandas
deactivate
Amazonのドキュメントによると、pythonまたはsite-packagesディレクトリにこれを配置し、/optで展開する必要があります。
cd ~/my_app/env
mkdir -p python/lib/python3.7/site-packages
cp -r lib/python3.7/site-packages/* python/lib/python3.7/site-packages/.
zip -r9 ~/layer.zip python
layer.zipファイルをS3上の場所にコピーします。これは、Lambdaレイヤーが10MBを超える場合に必要です。
aws s3 cp layer.zip s3://datarobot-bucket/layers/layer.zip
Lambdaサービス > レイヤー > レイヤーの作成に移動します。 名前とS3のファイルへのリンクを指定します。これは、アップロードされたZIPオブジェクトのURLになります。 互換性のある環境を設定することをお勧めしますが、必須ではありません。 これにより、Lambdaに追加するときに、ドロップダウンメニューでより簡単にアクセスできるようになります。 選択して、レイヤーとそのARNを保存します。
Lambdaに戻り、レイヤー(Lambdaタイトルの下)をクリックします。 レイヤーを追加し、前の手順のARNを指定します。
Lambdaコードの定義¶
import boto3
import os
import os.path
import urllib.parse
import pandas as pd
import requests
import json
# 10,000 maximum allowed payload
REPORT_ROWS = int(os.environ["REPORT_ROWS"])
DR_API_TOKEN = os.environ["DR_API_TOKEN"]
DR_INSTANCE = os.environ["DR_INSTANCE"]
s3 = boto3.resource("s3")
def report_rows(list_to_report, url, total):
print("reporting " + str(len(list_to_report)) + " records!")
df = pd.DataFrame(list_to_report)
# this must be provided as a string
df["associationId"] = df["associationId"].apply(str)
report_json = json.dumps({"data": df.to_dict("records")})
response = requests.post(
url,
data=report_json,
headers={
"Authorization": "Bearer " + DR_API_TOKEN,
"Content-Type": "application/json",
},
)
print("response status code: " + str(response.status_code))
if response.status_code == 202:
print("success! reported " + str(total) + " total records!")
else:
print("error reporting!")
print("response content: " + str(response.content))
def lambda_handler(event, context):
# get the object that triggered lambda
bucket = event["Records"][0]["s3"]["bucket"]["name"]
key = urllib.parse.unquote_plus(event["Records"][0]["s3"]["object"]["key"], encoding="utf-8")
filenm = os.path.basename(key)
fulldir = os.path.dirname(key)
deployment = os.path.basename(fulldir)
print("bucket is " + bucket)
print("key is " + key)
print("filenm is " + filenm)
print("fulldir is " + fulldir)
print("deployment is " + deployment)
url = DR_INSTANCE + "/api/v2/deployments/" + deployment + "/actuals/fromJSON/"
session = boto3.session.Session()
client = session.client("s3")
line_no = -1
total = 0
rows_list = []
for lines in client.get_object(Bucket=bucket, Key=key)["Body"].iter_lines():
# if the header, make sure the case sensitive required fields are present
if line_no == -1:
header = lines.decode("utf-8").split(",")
col1 = header[0]
col2 = header[1]
expectedHeaders = ["associationId", "actualValue"]
if col1 not in expectedHeaders or col2 not in expectedHeaders:
print("ERROR: data must be csv with 2 columns, headers case sensitive: associationId and actualValue")
break
else:
line_no = 0
else:
input_dict = {}
input_row = lines.decode("utf-8").split(",")
input_dict.update({col1: input_row[0]})
input_dict.update({col2: input_row[1]})
rows_list.append(input_dict)
line_no += 1
total += 1
if line_no == REPORT_ROWS:
report_rows(rows_list, url, total)
rows_list = []
line_no = 0
if line_no > 0:
report_rows(rows_list, url, total)
# delete the processed input
s3.Object(bucket, key).delete()
Lambda環境変数の設定¶
Lambdaには3つの環境変数を設定する必要があります。
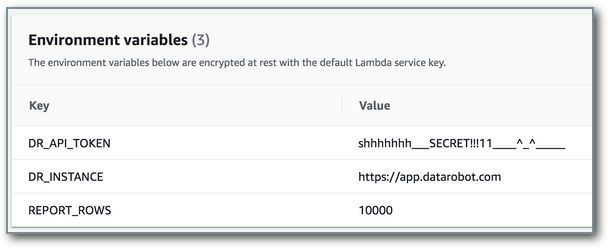
DR_API_TOKENはデプロイへのアクセス権を持つアカウントのAPIトークンで、DataRobot環境に実測値を送信するために使用されます。 この設定には、個人のユーザーアカウントではなく、サービスアカウントを使用することをお勧めします。DR_INSTANCEは使用されているDataRobotインスタンスのアプリケーションサーバーです。REPORT_ROWSはペイロードでアップロードする実測値レコード数です。最大値は10000です。
Lambdaのリソース設定¶
基本設定を編集して、Lambdaの設定項目を設定します。 入力データを読み取ってペイロードをバッファリングおよび送信する場合、Lambdaはローカルコンピューティングとメモリーをあまり必要としません。 512MBのメモリー設定で十分であり、それに応じて半分のvCPUが割り当てられます。 タイムアウトとは、Lambdaが出力を提供せず、AWSがLambdaを終了させるまでの許容時間です。 これが最も発生しやすいのは、ペイロードの送信後に応答を待っているときです。 特に最大サイズの10,000レコードのペイロードを使用する場合には、デフォルトの3秒は短すぎる可能性があります。 5~6秒で十分ですが、この例でテストした設定では30秒に設定されています。
Lambdaの実行¶
Lambdaは、レポート対応のデータ列のペアを想定してコーディングされています。 ヘッダーと、大文字小文字を区別する列associationIdとactualValueを含むCSVファイルが必要です。 タイタニック号の乗客について、スコアリングモデルのサンプルファイルの内容を以下に示します。
associationId,actualValue
892,1
893,0
894,0
895,1
896,1
以下は、S3サービスを活用し、ローカルファイルを監視対象ディレクトリにコピーするAWS CLIコマンドです。
aws s3 cp actuals.csv s3://datarobot-actualbucket/upload_actuals/deploy/ 5aa1a4e24eaaa003b4caa4 /actuals.csv
デプロイIDがパスの一部として含まれていることに注意してください(上に赤で表示)。 これは、実測値が関連付けられるDataRobotデプロイです。 同様に、プロセスやデータベースのエクスポートからのファイルも、S3に直接書き込むことができます。
Lambdaの実行時間は最大で15分であるとします。 この記事のテストにおいて、この設定時間は100万レコードには十分でした。 本番環境での使用では、より少ないレコード数でより多くのファイルを含むアプローチを検討するとよいでしょう。 また、複数のデプロイの実測値を同時に報告することもできます。 これらの値を報告する、関連付けられたAPIトークン/サービスアカウントのAPIレート制限を無効にすることをお勧めします。
メールの送信、キューデータメッセージの送信、環境に適合するカスタムコードの作成、S3ファイルの移動など、追加のエラー処理を具体化します。このLambdaは、処理が成功すると入力ファイルを削除し、失敗した場合はログにエラーを書き込みます。
まとめ¶
この時点で、Lambdaは完成し、フィードされた実測値データを報告する準備ができています(つまり、定義されたS3の場所で想定される形式のファイルを受信します)。 実際の結果が得られたらこの操作を実行するプロセスを設定し、DataRobot MLOpsでモデルを監視および管理することで、ユースケースでのパフォーマンスを把握できます。