特徴量とデータ¶
データセット、データソース、データストア、データベースの比較¶
データストア:データが保存されるリモートの場所を表す一般的な用語。 データストアには、1つ以上のデータベース、またはさまざまな形式の1つ以上のファイルを含めることができます。
データソース:データストア内でデータがある場所。 データベースのテーブル/ビュー、またはデータに関する追加のメタデータ(データの形式や、データの処理に必要なことがある形式特有の情報など)を含んだファイルへのパスです。
データベース:一連の関連データを含む特定のタイプのデータストアと、そのデータを管理および操作できるシステム。 管理システムによって、データの操作、データの保存方法の要件、データの管理に役立つツールが異なります。 たとえば、MySQLなどのリレーショナルデータベースでは、データは列が定義されたテーブルに保存されますが、MongoDBなどの非リレーショナルデータベースでは、保存されるデータの形式に柔軟性があります。
データセット: 特定の時点におけるデータ(1つのファイルまたは1つのデータソースのコンテンツ)。
ELI5の例
- データストア/データベース = おもちゃをしまう箱
- データソース = おもちゃ箱の中の場所
- データセット = 仕分けして片付けたおもちゃ
構造化データセット vs. 非構造化データセット¶
構造化データはきちんと整理されており、DataRobotにそのままアップロードすることができます。 構造化データとは、CSVファイルや1つの表できれいに整理されたExcelファイルのことです。
非構造化データは乱雑で整理されていないため、Datarobotにアップロードする前に、何らかの構造を追加する必要があります。 非構造化データとは、さまざまなPDFファイルに含まれる表の集まりのことです。
ELI5の例
新しいWikipediaのページ(芸術、歴史、政治、科学、猫、犬、有名人など)のカテゴリーを予測するタスクがあるとします。
必要な情報はすべて手元にあります。wikipedia.comにアクセスすれば、各ページですべてのカテゴリーを確認できます。 しかし、現在の情報構造では、新しいページのカテゴリーを予測するのには適していません。 このデータから何らかの知見を抽出するのは難しいでしょう。 一方、Wikipediaのデータベースにクエリを実行して、各列は記事の特徴(タイトル、内容、掲載年数、閲覧数、編集回数、編集者数)を表し、1行につき1つの記事を示すファイルを作成すると、構造化データセットとなります。機械学習の手法を用いてそこから隠れた価値を引き出すほうががより適切です。
テキストは常に構造化されていないわけではありません。 たとえば、1000の短編小説があり、その中には気に入ったものもあれば、そうでないものもあるとします。 1000個の別々のファイルであると考えると、構造化されていない問題になります。 しかし、それらを1つのCSVファイルにまとめると、問題が構造化されるので、DataRobotで解決することができます。
大規模なデータセットでのトレーニング¶
Robot 1
より大規模なデータセットでAutoMLとEDAの処理方法に関するベストプラクティスにはどのようなものがあるのでしょうか?
みなさん、データ取込み制限に関して、顧客からいくつかの質問があります。 回答をいただくか、正しい方向を示していただけるとうれしいです。
より大規模なデータセットでAutoMLとEDAの処理方法に関するベストプラクティスにはどのようなものがあるのでしょうか?
Robot 2
私のR&D業務に基づいて、このプレゼンテーションを引き続き使用しています。
プレゼンテーションのサマリー
背景情報
SASモデルから変換された元のトレーニングデータには、6425特徴量の2100万件のレコードがあり、物理データのサイズはCSV形式で約260 GBです。 960以上の特徴量を含む2100万件のレコードをすべてフィードしたいと考えています。CSV形式の推定データサイズは約40 GBです。
100 GB:99 GB(トレーニング)+ 1 GB(外部ホールドアウト)
セルフマネージド:96 CPU、3 TB RAM、50 TB HDD
SaaS:20のモデリングワーカーを含むクラウドアカウント
問題の記述
大規模なデータセットで本当にモデルをトレーニングする必要がありますか?
分割して征服するアプローチ
- 元のデータセットをNGBのサンプルに、ランダムにサンプリングします。
- オートパイロットの実行。
- 推奨デプロイモデルをデプロイします(サンプリングされたデータセットの100%でトレーニングされたもの)。
- すべての特徴量を含むNGBサンプルを取得します。
- オートパイロットの実行。
- 推奨デプロイモデルで特徴量のインパクトを実行します(サンプリングされたデータセットの100%でトレーニングされたもの)。
- 特徴量のインパクトを使用して、インパクトが1%以上の特徴量を選択します。
- データセット全体からこれらの特徴量(>= 1%)を選択し、結果が10 GB未満の場合、すべての行をモデル化します。
- 結果が > 10 GBの場合、ステップ5から10 GBのデータセットをランダムにサンプリングします。
結果
- 分割アプローチと征服アプローチ(データセットサンプリングと特徴量サンプリング)の両方が、フルサイズのデータセットでトレーニングされたモデルにチャレンジできます。
- フルサイズのトレーニング済みモデルとデータセットサンプリングの比較:+1.5%(最悪ケース)および+15.2%(最良ケース)。
- フルサイズのトレーニング済みモデルと特徴量サンプリングの比較:-0.7%(最悪ケース)および+8.7%(最良ケース)。
- 特徴量のサンプリングは、数百の特徴量(またはそれ以上)を含むデータセットに適しています。完全なデータセットでトレーニングされたモデルと比較した場合、すべての指標(精度、トレーニング/スコアリング時間)に対して類似または優れたモデルになる可能性があります。
集計され、順序が付けられたカテゴリー特徴量¶
食料品を買いに店に行ったとしましょう。 店内を歩きながら、さまざまな種類の商品を1つずつカートに入れます。 すると、電話がかかってきて、カートの中身を聞かれたので、 「スープ6缶、シリアル2箱、ピーナツバター1瓶、ピクルス7瓶、ブドウ2房」 などと答えます。
集計されたカテゴリー型特徴量の詳細を参照してください。
Robot 1
DataRobotは、評判が悪いレンディングクラブデータのグレードなど、順序付けられたカテゴリーを認識していますか。
これは顧客からの質問です。
モデルをより正規化するために、
A < B < Cをモデルに指示できますか。
順序を活用するには、数値機能として使うというのが答えだと思います。 ブースティングモデルが、トップにある可能性が高いので、いずれにしても順序付けられた特徴量として使用されます。 そのままにしておけば、当社のモデルが解決してくれます。
Generalized Linear Model(GLM)を使用する場合、モデルに必要な自由度が少なくなるため、この情報を活用したいと思うでしょう。ただし、ここで聞いているのは、私が見落としている点がないかどうかということです。
Robot 2
実際には、これらの特徴量は、XGBoostモデルに対して順序付けられます。 デフォルトは頻度順ですが、語彙的に並べ替えることもできます。
Robot 1
オーディナルエンコーディングのことですか? それとも、XGBoostで直接エンコーディングすることですか?
Robot 2
ええ、オーディナルエンコーディングはデータを順番に並べます。
Robot 1
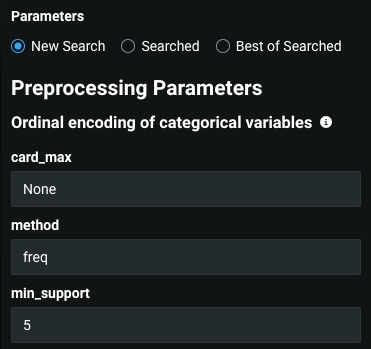
Robot 2
頻度をlexicalに変更して試してみてください。
Robot 3
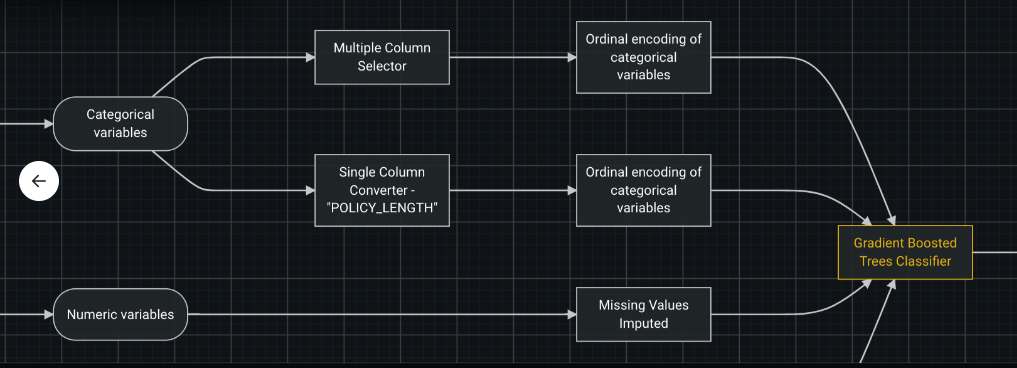
独自のブループリントを構築し、明確に設定されたfreq/lex列を選択します。
Robot 2
GLMを使用している場合は、(DR外で)順序付けられた方法で、特徴量を手動でエンコードすることも可能です。
以下の3つの列を使用します。
A: 0, 0, 1
B: 0, 1, 1
C: 1, 1, 1
Lexicalは、多くの場合、正常に機能します。すべての特徴量に対してのみ実行します。 mpickを使用して、異なる列に対して異なるエンコーディングを選択できます。
Robot 1
ACEスコアと行の順序¶
ACEとは?
ACEスコア(交替条件付き期待値)は、特徴量とターゲットの相関関係を示す一変量の指標です。 ACEスコアは、非線形関係性を検出できますが、単変量であるため、交互作用効果は検出しません。
Robot 1
ACEスコアは行の順序に依存しますか?
ACEスコアを計算する際にEDA2でサンプリングが行われることがありますか? このケースは、行の順序だけが異なる2つのデータセットで、同じOTV設定(パーティションについて同じ日付範囲、各パーティションで同じ行数)で別個に実行され、ACEスコアに視覚的な違いがあります。 ACEスコアは行の順序に依存しますか?
Robot 2
EDA1サンプルは、行の順序によって確実に異なります。 EDA2はEDA1で始まり、それからホールドアウトにも含まれる行が削除されるため、プロジェクト設定も重要になることがあります。
Robot 1
8,000行と70の特徴量があり、かなり小規模なデータセットです。
Robot 2
ACEには大規模なサンプルは必要ありません。1000あるいは100であるかもしれません。データセットが500MB未満の場合には、すべての行がサンプルに含まれることもありますが、順序は異なる場合があります。
ニューラルネットワークと表形式データ¶
Robot 1
表形式データにニューラルネットワークが必要ない理由に関する研究を誰かと共有できますか?
こんにちは、クオンツチームと話して、表形式データにニューラルネットワークが必要ない理由を説明します。 一般的に「従来の」機械学習はニューラルネットワークと同等かそれ以上のパフォーマンスがあると言われましたが、どなたかこの点を裏付ける研究論文を指摘できる人はいますか?
Robot 2および Robot 3
以下にいくつかの例を示します。
- 表形式データ:必要なのはディープラーニングだけではありません
- [表形式データでツリーベースのモデルがディープラーニングをまだ上回っている理由](https://arxiv.org/abs/2207.08815){ target=_blank }
- ディープニューラルネットワークと表形式データ:調査
Robot 1
素晴らしいです。 ありがとう
Robot 3
まだ完了していません...
この記事(「Another Deceptive NN for Tabular Data — The Wild, Unsubstantiated Claims about Constrained Monotonic Neural Networks」)と、それにBojan Tunguzによる一連のメディア投稿を読んだばかりです。実際の論文を読むほど優秀ではありませんから¯\\_(ツ)_/¯。 また、これらは:
彼は、これらのうちの1つを月に1回作成し、多くの場合、ランダムフォレストまたはチューニングされていないGBMで、基本的にニューラルネットに勝ります。
Robot 3
表形式データでのLolディープラーニングは。 Robot 3も、それほどスマートではありませんか? いずれか1つを書き込むことができます。 TwitterのBojan Tunguzをポイントします。
Robot 3
検索中...
Robot 4
彼はここにも登場します(これは上記のブログ記事を作成したスレッドです)。 基本的に、この人物は、表形式データのニューラルネットに関するすべての論文で自己反証することで有名になりました。
社内の分析では、勾配ブーストされた木がプロジェクトの40%で最良のモデルであり、線形モデルがプロジェクトの20%、Keras / ディープラーニングモデルはプロジェクトの5%未満であることを示しています。
基本的に、Xgboostは表形式データのディープラーニングよりも約10倍は有用です。
クオンツであれば、データで納得させることができます!
Robot 4
Robot 1、表形式データ手法に関するディープラーニングについて、少なくとも2件の特許を取得しています。 当社は、最先端のモデルを構築するために2年間を費やしました。これには、標準的なMLP、独自の特許取得済みの表形式データ用の残差アーキテクチャ、表形式データ「ディープCTRモデル」(Neural Factorizationマシン、AutoIntなど)があります。
2年相当の経験があり、これまで協働してきた最高のデータサイエンスチームであっても、「プロジェクトの5%でディープラーニングモデルを最高のモデルにする」までに至ることができませんでした。
インライアとは?¶
Robot 2
インライアは、統計分布の内部に位置し、エラーであるデータ値のことです。
Robot 3
これは、他の観測された値の一般的な分布内にある観測値であり、一般的に結果を乱すものではありません。ただし、不適合であり、異常なデータ値です。 インライアは、良好なデータ値と区別するのが難しい場合があります。
例
インライアは、間違った単位(たとえば、摂氏(°C)ではなく華氏(°F))でレポートされるレコードに含まれる場合があります。
Robot 1
データセットにそのような値があると、何が危険なのでしょうか?
Robot 3
一般的に統計結果には影響しませんが、 インライアの識別は、誤った測定を示すことがあるため、データ品質の向上に役立ちます。
Robot 1
それらを見ただけで識別できますか?
Robot 2
分離された単一の特徴量の場合、インライアの識別は事実上不可能です。 しかし、特徴量間の関係性がある多変量データでは、インライアを識別できます。 ここに良い参考資料があります。
複数DR削減済み特徴量セット¶
Robot 1
1つのプロジェクトに複数の削減済み特徴量セットを含めることができますか?
こんにちは、チームの皆さん。1つのプロジェクトに複数の DR削減済み特徴量セットを含めることはできますか? オートパイロットが完了した後、特徴量セットに基づいてDR削減済み特徴量を作成します。 しかし、「モデリングの設定をする」によって新しい特徴量セットについてモデルを再トレーニングしても、DR削減済み特徴量は作成されません。
Robot 2
新しい削減済み特徴量セットを取得できますが、最も精度の高い新しいモデルがある場合にのみ使用できます。 推奨ステージは、特定のオートパイロットの実行に基づくものではありません。 新しい最良のモデルを取得し、デプロイタブで デプロイ用に準備をします。 これは、削減済み特徴量セットステージを含むすべてのステージで実行されます。 すべての特徴量セットを減らすことはできないため、このステージはスキップされる可能性があることに注意してください。
Robot 3
Robot 1、任意のモデルの 特徴量のインパクトから削減された特徴量セットを手動で作成できます。
- 特徴量のインパクトを実行します。
- "特徴量セットを作成"をクリックします
- 必要な特徴量の数を選択します。
- 「冗長な特徴量を除外」オプションをチェックします(冗長な特徴量がある場合にのみ表示されます。
- 特徴量セットに名前を付けます。
- クリックして作成します。
冗長な特徴量の定義¶
Robot 1
特徴量が冗長になる理由
ドキュメントによれば、
2つの特徴量によって予測が同様に変化する場合、DataRobotでは、その2つの特徴量のインパクトが相関するものとして認識され、低い特徴量のインパクトの特徴量が冗長として識別されます
「同様」をどのように数値化または測定しますか?
Robot 2
2つの特徴量の相関性が高い場合、2つの特徴量の予測の違い(特徴量シャッフル前の予測 / 特徴量シャッフル後の予測)も相関性があるはずです。 予測の違いを使用して、ペア単位の特徴量相関を評価できます。 たとえば、相関性の高い2つの特徴量がまず選択されます。 特徴量のインパクトが低い特徴量は、冗長な特徴量として識別されます。
Robot 1
予測の違いが同じ場合 / -x%と+x%の間の場合、2つの特徴量は冗長と見なされますか?
Robot 2
予測の違いの相関係数を調べて、特定のしきい値を超える場合は、(モデルの特徴量のインパクトに応じて)有用性の低い方の係数を冗長と呼びます。
以下に具体例を示します。
-
特徴量シャッフルの前後の予測の違いを計算します。
(pred_diff[i] = pred_before[i] - pred_after[i]) -
ペア単位の特徴量相関(モデルの特徴量のインパクトに応じて上位50の特徴量)を
pred_diffに基づいて計算します。 -
冗長な特徴量(しきい値に基づく相関性が高い)を特定してから、削除が精度に大きく影響しないことをテストします。
ターゲットリーケージとは?¶
ターゲットリーケージとは、すでに雨が降っていても、いつ雨が降るかを予測できるようなものです。 つまり、モデルの構築に使用された特徴量の1つは、実際にはターゲットから派生しているか、密接に関連しています。
ELI5の例
友人と一緒に、スーパーボウルの結果を予想するとします。
二人で過去のスーパーボウルについて情報収集を始めました。 すると、友人が「ちょっと待った! そうだ、スーパーボウルの翌日の新聞の見出しを見ればいいんだよ! 過去のスーパーボウルでは、翌日の新聞を読めばどっちが勝ったかすぐわかるよ。」と言いました。
そこで、過去のスーパーボウルについての新聞記事をすべて集めたら、過去の勝敗を予想するのが得意になりました。
そして、今度のスーパーボウルでどちらが勝つかを予想しようとしました。ところが、何か変です。「どちらが勝つかを教えてくれる新聞はどこにもない」。
過去の勝敗を高い精度で予測するのに役立つターゲットリーケージを使っていましたが、その方法は未来の勝敗を予測するのには役に立ちませんでした。 新聞の見出しはターゲットリーケージの例で、ターゲットの情報が過去に「漏れて」いたからです。
注目すべきリンク:
DataRobotでの ターゲットリーケージの処理方法について説明します。
断続的なターゲットリーケージ¶
Robot 1
ターゲットリーケージが断続的に表示される可能性があるのはなぜですか?
こんにちは、チームの皆さん!DataRobot for Data Scientistsクラスの学生は、標準クラス「fastiron 100k data.csv.zip」ファイルからModelIDカテゴリー整数特徴量を作成し、手動での最初の実行で ターゲットリーケージとしてフラグ付けしました。
再実行を試みたとき、プラットフォームはターゲットリーケージに黄色の三角形は表示されませんでしたが、データ品質評価ボックスはターゲットリーケージ特徴量にフラグを立てました。
彼の質問は次のとおりです。
-
DataRobotでターゲットリーケージが断続的に表示されるのはなぜですか?
-
整数値としての元のModelIDは、ターゲットリーケージのフラグ付けを引き起こさず、子特徴量を含む親特徴量(カテゴリー整数としてのModelID)を含めた時も、ターゲットリーケージとしてフラグ付けされませんでした。それはなぜでしょうか?
Robot 2
一目見たところでは、ユーザーが特徴量の型変換を介して新しい特徴量ModelID (Categorical Int)を作成してから、作成された特徴量が計算されたACE有用性スコアを受け取る手動モードを開始したようです。 有用性スコアがターゲットリーケージしきい値を超えたため、データ品質評価によって、特徴量が潜在的なリーケージとしてタグ付けされました。
Robot 2
プロジェクトを調べた結果、「有用な特徴量 - リーケージ除去済」という特徴量セットが作成されていなかったことがわかります。つまり、これは「高リスク」のリーケージしきい値を満たさないため、「中程度のリスク」のリーケージ特徴量としてタグ付けされました。
特定の特徴量ModelId (Categorical Int)のプロジェクトのネットワークコンソールから/eda/profile/値が見つかりました。 その作成された特徴量に対して計算されたACE有用性スコア(正規化ジニ指標)は約0.8501です:
target_leakage_metadata: {importance: {impact: "moderate", reason: "importance score", value: 0.8501722785995578}}
そして、コード内にハードコードされた中程度のリスクのしきい値は、実際には0.85です。
Robot 2
数値特徴量をカテゴリー型に変更すると、データページの有用性スコアの計算に関して、一変量の分析結果が異なる可能性があることをユーザーに知らせることができます。 有用性スコアが、中程度のリスクが検出されたターゲットリーケージのしきい値をかろうじて超えました。 それが役立つことを願っています。