DataRobot MLOpsを使用したSparkモデルのデプロイおよび監視¶
このページでは、DataRobotの監視エージェント(MLOpsエージェント)を使用して、モデルをMLOps内にデプロイせずに、一元化されたダッシュボードからモデルを管理および監視する方法を説明します。
リモートモデル(独自のインフラストラクチャにデプロイされた、DataRobot MLOps内で実行されていないモデル)を管理および監視する方法について説明します。 一般的な例は、サーバーレスデプロイ(AWS Lambda、Azure Functions)またはSparkクラスター(Hadoop、Databricks、AWS EMR)でのデプロイです。

以下のセクションでは、DataRobotモデルをDatabricksクラスターにデプロイし、一元化されたダッシュボードでDataRobot MLOpsを使用して、このモデルを監視する方法を説明します。 このダッシュボードは、モデルが開発またはデプロイされた場所に関係なく、すべてのモデルを表示します。 このアプローチは、Sparkクラスター内で実行されるすべてのモデルで機能します。
モデルの作成¶
このセクションでは、DataRobot AutoMLでモデルを作成し、Lending Clubのデータセットを使用してそれをDatabricksクラスターにインポートします。
備考
Sparkクラスターで実行される連続値モデルが既にある場合は、この手順をスキップしてMLOps監視エージェントとライブラリのインストールに進むことができます。
-
トレーニングデータをDataRobotにアップロードするには、次のいずれかを行います。
-
ローカルファイルをクリックし、ローカルファイルシステムからLendingClubデータセットCSVファイルを選択します。
-
URLをクリックし、URLをインポートダイアログボックスを開き、上記のLendingClubデータセットのURLをコピーします。
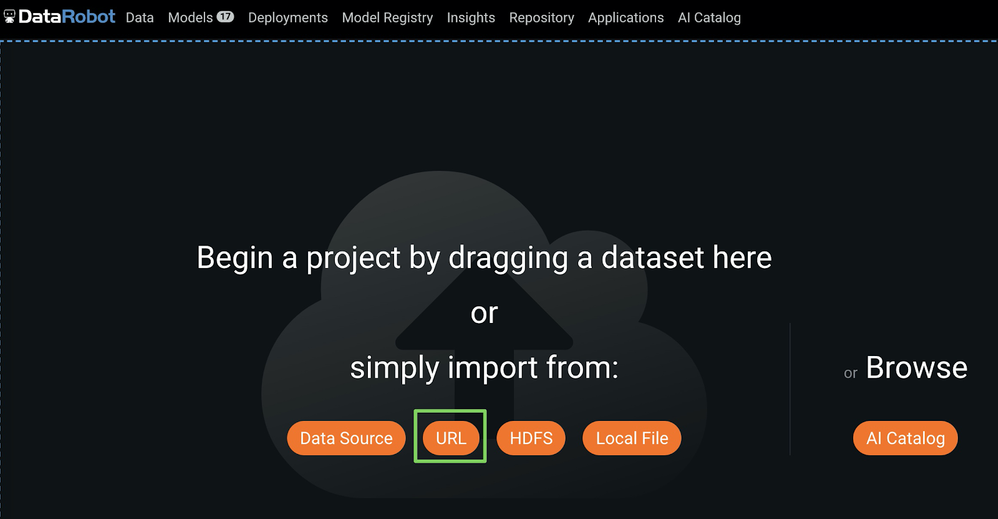
In the Import URL dialog box, paste the LendingClub dataset URL and click Import from URL:
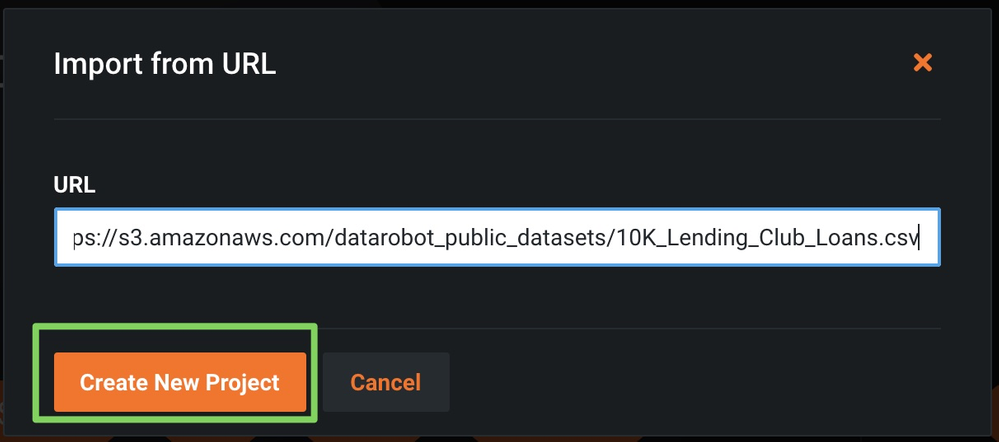
-
-
ターゲット(1)(予測対象)として
loan_amtを入力し、開始(2)をクリックしてオートパイロットを実行します。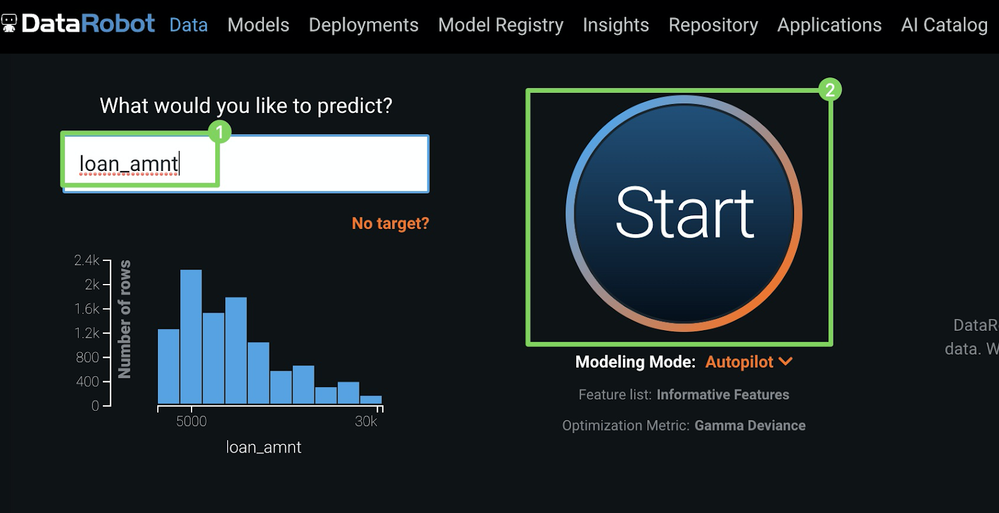
-
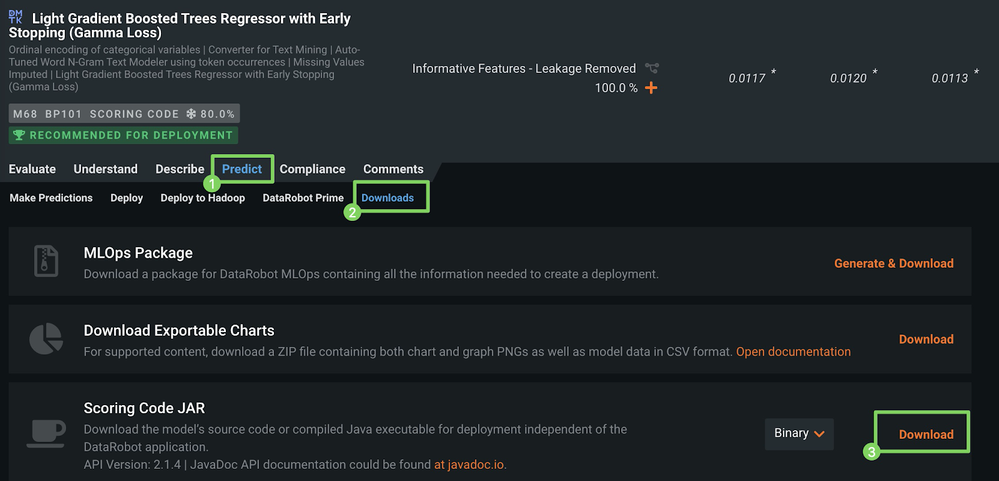
オートパイロットが終了したら、モデル(1)をクリックしリーダーボードの上部(3)にあるスコアリングコードラベル(2)付きモデルを選択します。
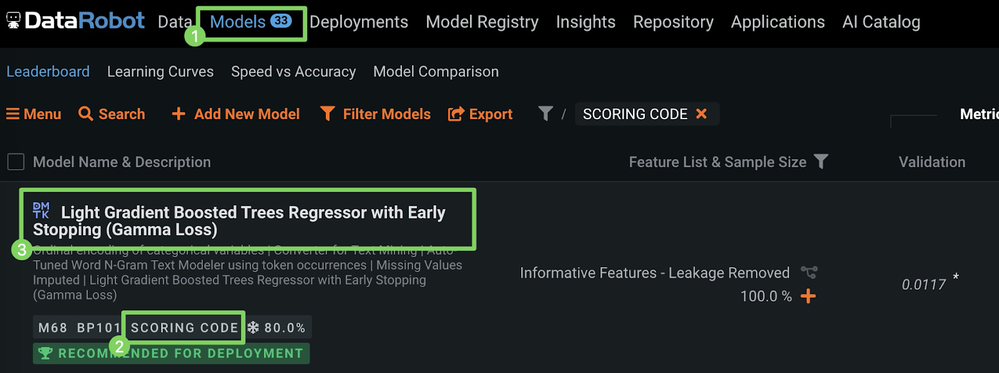
-
選択したモデルの下で、予測(1)をクリックし、ダウンロード(2)をクリックして、スコアリングコードJARのダウンロードにアクセスします。
備考
リーダーボードからモデルのスコアリングコードをダウンロードできるかどうかは、組織のMLOps設定によって異なります。
-
ダウンロード(3)をクリックし、JARファイルのダウンロードを開始します。
詳細については、スコアリングコードに関するドキュメントを参照してください。
モデルのデプロイ¶
スコアリングコードをインストールするには、以下に示すように、以前にダウンロードしたJARファイルをDataRobotのSpark Wrapperと共に、Databricksクラスターにインストールできます。
-
クラスターをクリックしてクラスター設定を開きます。
-
DataRobotモデルをデプロイするクラスターを選択します。
-
ライブラリタブをクリックします。
-
新規インストールをクリックします。
-
ライブラリのインストールダイアログボックスで、ライブラリソースをアップロードに設定し、ライブラリタイプをJARに設定して、スコアリングコードJARファイル(例:
5ed68d70455df33366ce0508.jar)をドラッグアンドドロップします。 -
インストールをクリックします。
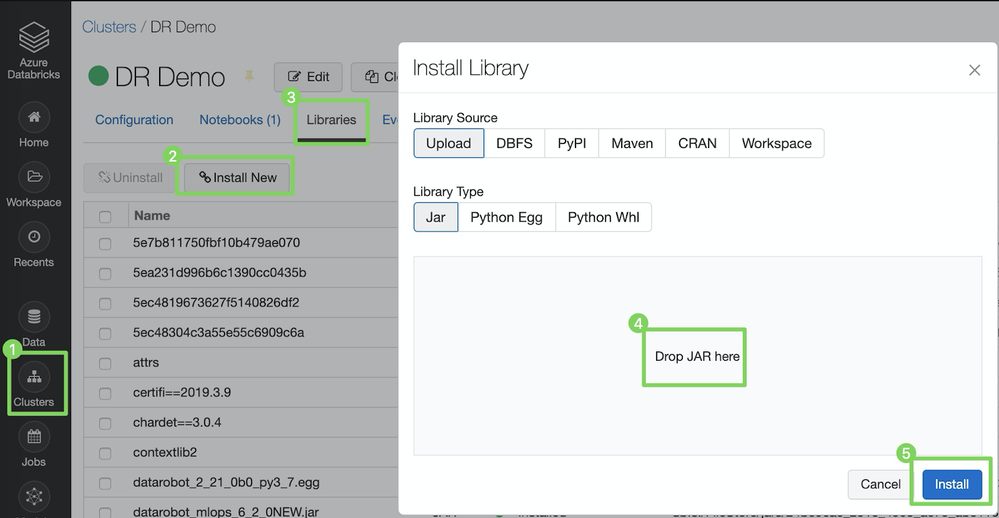
インストールが完了したら、同じ手順を繰り返してSpark Wrapperをインストールします。ここからダウンロードするか、最新バージョンをMavenから直接プルします。
MLOps監視エージェントとライブラリのインストール¶
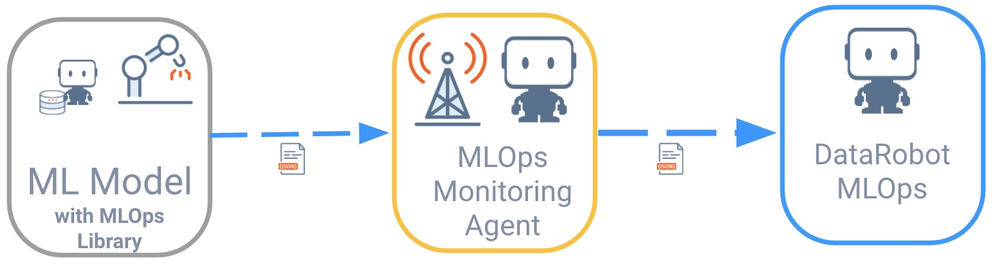
リモートモデルはDataRobot MLOpsと直接通信しません。 代わりに、多くのスプーリングメカニズム(例:フラットファイル、AWS SQS、RabbitMQ)をサポートする、DataRobot MLOps監視エージェントを介して通信を行います。 これらのエージェントは通常、モデルが実行されている外部環境にデプロイされます。
DataRobot MLOps監視エージェントとの通信を簡素化するために、一般的なすべてのプログラミング言語でライブラリを利用できます。 モデルは、MLOpsライブラリを使用してエージェントと対話するように指示されます。 その後、エージェントはモデルからすべての指標を収集し、それらをMLOpsサーバーとダッシュボードに中継します。
この例では、ランタイム環境はSparkです。 そのため、以前にモデル自体をインストールしたのと同じ方法で(モデルのデプロイで)、MLOpsライブラリをSparkクラスター(Databricks)にインストールします。 また、MLOps監視エージェントを、キューシステムとして使用するRabbitMQと共にAzure Kubernetes Service(AKS)クラスターにインストールします。
このプロセスは、Azure Kubernetes ServiceとAzure CLIに精通していることを前提としています。 詳細については、Microsoftのクイックスタートチュートリアルを参照してください。
AKSクラスターの作成¶
-
実行中のAKSクラスターがない場合は、以下のように作成します。
RESOURCE_GROUP=ai_success_eng CLUSTER_NAME=AIEngineeringDemo az aks create \ --resource-group $RESOURCE_GROUP \ --name $CLUSTER_NAME \ -s Standard_B2s \ --node-count 1 \ --generate-ssh-keys \ --service-principal XXXXXX \ --client-secret XXXX \ --enable-cluster-autoscaler \ --min-count 1 \ --max-count 2 -
Kubernetesダッシュボードを起動します。
az aks browse --resource-group $RESOURCE_GROUP --name $CLUSTER_NAME
RabbitMQのインストール¶
アプリケーションをデプロイするには、多数の方法があります。 最も直接的な方法は、Kubernetesダッシュボードを使用することです。
RabbitMQをインストールするには:
-
作成 > アプリを作成(1)をクリックします。
-
アプリの作成ページ(2)で、以下を指定します。
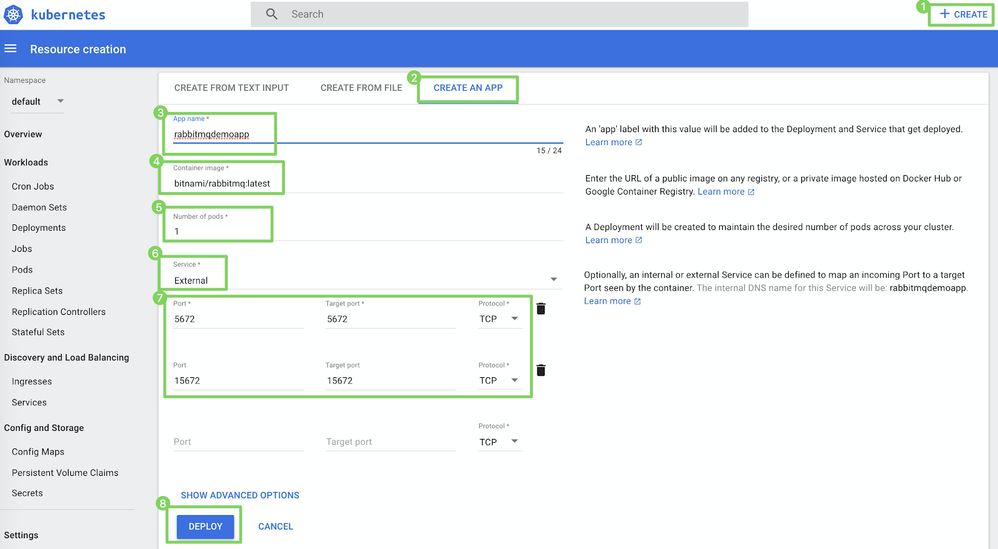
フィールド 値 3 アプリ名 たとえば、 rabbitmqdemo4 コンテナイメージ たとえば、 rabbitmq:latest5 ポッドの数 たとえば、 16 サービス External7 ポートとターゲットポート 5672と5672
15672と15672 -
デプロイ(8)をクリックします。
MLOps監視エージェントのダウンロード¶
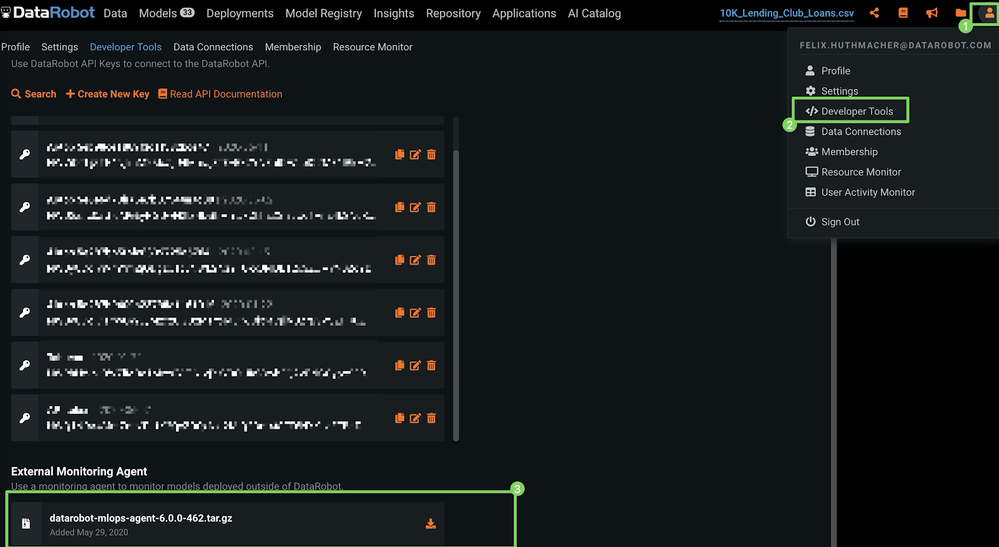
MLOps監視エージェントをDataRobotクラスターから直接ダウンロードするには:
-
DataRobotの右上隅にある自分のプロフィールアイコン(またはデフォルトのアバター
 )をクリックします。
)をクリックします。 -
開発者ツールをクリックします。
-
外部監視エージェントの下で、ダウンロードアイコンをクリックします。
MLOps監視エージェントのインストール¶
エージェントはどこにでもインストールできます。ただし、このプロセスではRabbitMQと一緒にインストールします。
-
前のセクションでダウンロードした監視エージェントのtarballを、RabbitMQが実行されているコンテナにコピーします。 これを行うには、次のコマンドを実行します。
備考
以下の例では、tarballのファイル名を置き換える必要がある場合があります。
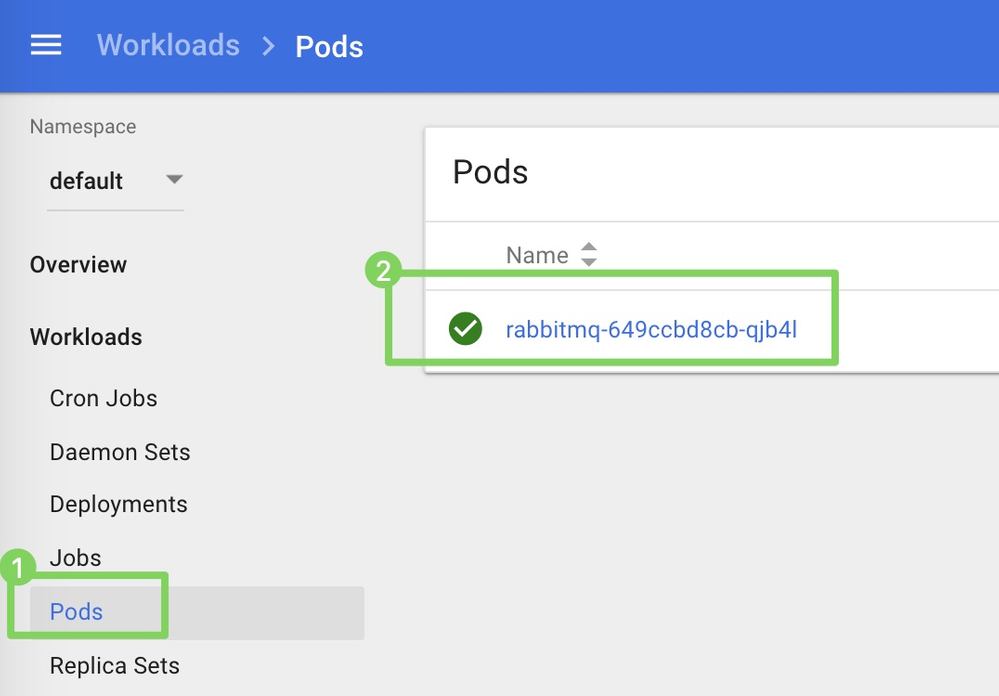
kubectl cp datarobot-mlops-agent-6.1.0.tar.gz default/rabbitmq-649ccbd8cb-qjb4l:/opt -
ポッド(1)をクリックし、コンテナ名(2)をクリックして、コンテナのCLIに接続します。
-
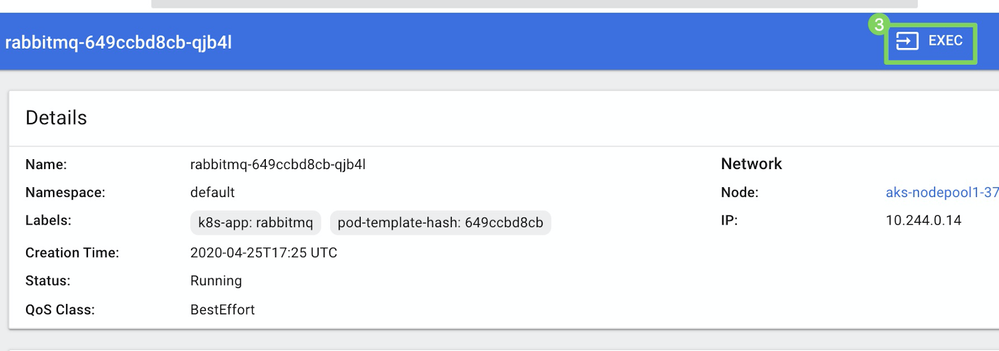
実行(3)をクリックし、コンテナを起動します。
-
コンテナのCLIで、エージェントの設定を開始します。 tarball名を確認し、必要に応じて、次のコマンドでファイル名を更新してから実行します。
cd /opt && tar -xvzf mlops-agent-6.1.0.tar && cd mlops-agent-6.1.0/conf -
ディレクトリで、
mlops.agent.conf.yaml設定ファイルを変更して、DataRobot MLOpsインスタンスとメッセージキューを指定します。 -
設定を更新してエージェントを実行するには、次のコマンドを使用してVimとJavaをインストールする必要があります。
apt-get update && apt-get install vim && apt-get install default-jdk -
この例では、RabbitMQとDataRobotマネージドAIプラットフォームソリューションを使用しているため、以下に示すように
mlopsURLとapiToken(1)、およびchannelConfigs(2)を設定する必要があります。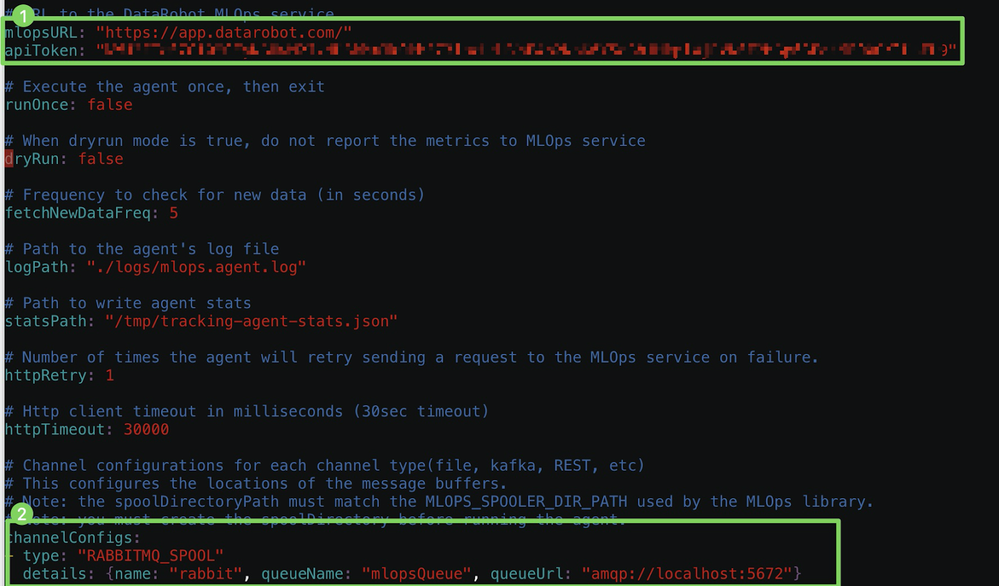
備考
開発者ツールから
apiTokenを取得できます。 -
エージェントを開始する前に、RabbitMQ管理UIを有効にして、キューを監視するユーザーを新規作成できます。
### Enable the RabbitMQ UI rabbitmq-plugins enable rabbitmq_management && ### Add a user via the CLI rabbitmqctl add_user <username> <your password> && rabbitmqctl set_user_tags <username> administrator && rabbitmqctl set_permissions -p / <username> ".*" ".*" ".*" -
RabbitMQが設定され、更新された設定が保存されたので、
/binディレクトリに切り替えてエージェントを開始します。cd ../bin && ./start-agent.sh -
ステータスを確認して、エージェントが正しく実行されていることを確認します。
./status-agent.sh -
すべてが期待どおりに実行されていることを確認するには、
/logsディレクトリにあるログを確認してください。
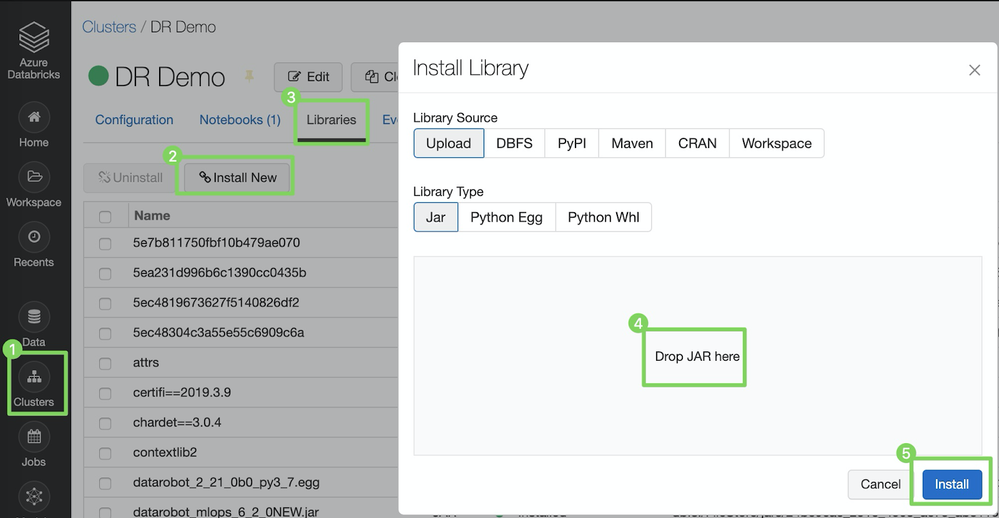
MLOpsライブラリをSparkクラスターにインストールする¶
まず、ここからライブラリをダウンロードします。
ライブラリをSparkクラスター(Databricks)にインストールするには:
-
クラスターをクリックしてクラスター設定を開きます。
-
DataRobotモデルをデプロイするクラスターを選択します。
-
ライブラリタブをクリックします。
-
ライブラリのインストールダイアログボックスで、ライブラリソースをアップロードに設定し、ライブラリタイプをJARに設定して、MLOps JARファイル(例:
MLOps.jar)をドラッグアンドドロップします。 -
インストールをクリックします。
モデルの実行¶
前提条件がすべて整ったので、モデルを実行して予測を行います。
// Scala example (see also PySpark example in notebook references at the bottom)
// 1) Use local DataRobot Model for Scoring
import com.datarobot.prediction.spark.Predictors
// referencing model_id, which is the same as the generated filename of the JAR file
val DataRobotModel = com.datarobot.prediction.spark.Predictors.getPredictor("5ed68d70455df33366ce0508")
// 2) read the scoring data
val scoringDF = sql("select * from 10k_lending_club_loans_with_id_csv")
// 3) Score the data and save results to spark dataframe
val output = DataRobotModel.transform(scoringDF)
// 4) Review/consume scoring results
output.show(1,false)
実際のスコアリング時間を追跡するには、スコアリングコマンドをラップして、更新コードが次のようになるようにします。
// to track the actual scoring time
def time[A](f: => A): Double = {
val s = System.nanoTime
val ret = f
val scoreTime = (System.nanoTime-s)/1e6 * 0.001
println("time: "+ scoreTime+"s")
return scoreTime
}
// 1) Use local DataRobot Model for Scoring
import com.datarobot.prediction.spark.Predictors
// referencing model_id, which is the same as the generated filename of the JAR file
val DataRobotModel = com.datarobot.prediction.spark.Predictors.getPredictor("5ed708a8fca6a1433abddbcb")
// 2) read the scoring data
val scoringDF = sql("select * from 10k_lending_club_loans_with_id_csv")
val scoreTime = time {
// Score the data and save results to spark dataframe
val scoring_output = DataRobotModel.transform(scoringDF)
scoring_output.show(1,false)
scoring_output.createOrReplaceTempView("scoring_output")
}
監視エージェントを介してMLOpsに使用状況を報告する¶
モデルを使用してアプリケーションのローン額を予測した後、これらの予測に関するテレメトリクスをDataRobot MLOpsサーバーとダッシュボードに報告できます。 これを行うには、次のセクションのコマンドを参照してください。
外部デプロイの作成¶
スコアリングの詳細をレポートする前に、DataRobot MLOps内に外部デプロイを作成する必要があります。 一度だけこれを実行する必要があり、DataRobot MLOpsのUIから実行できます。
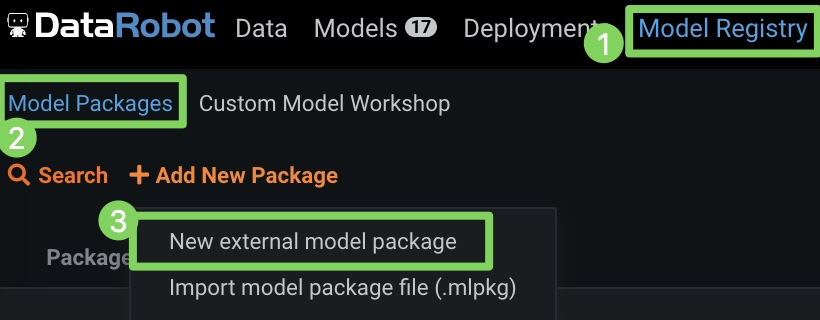
-
モデルレジストリ(1)、モデルパッケージ(2)の順にクリックし、新しい外部モデルパッケージ(3)をクリックします。
-
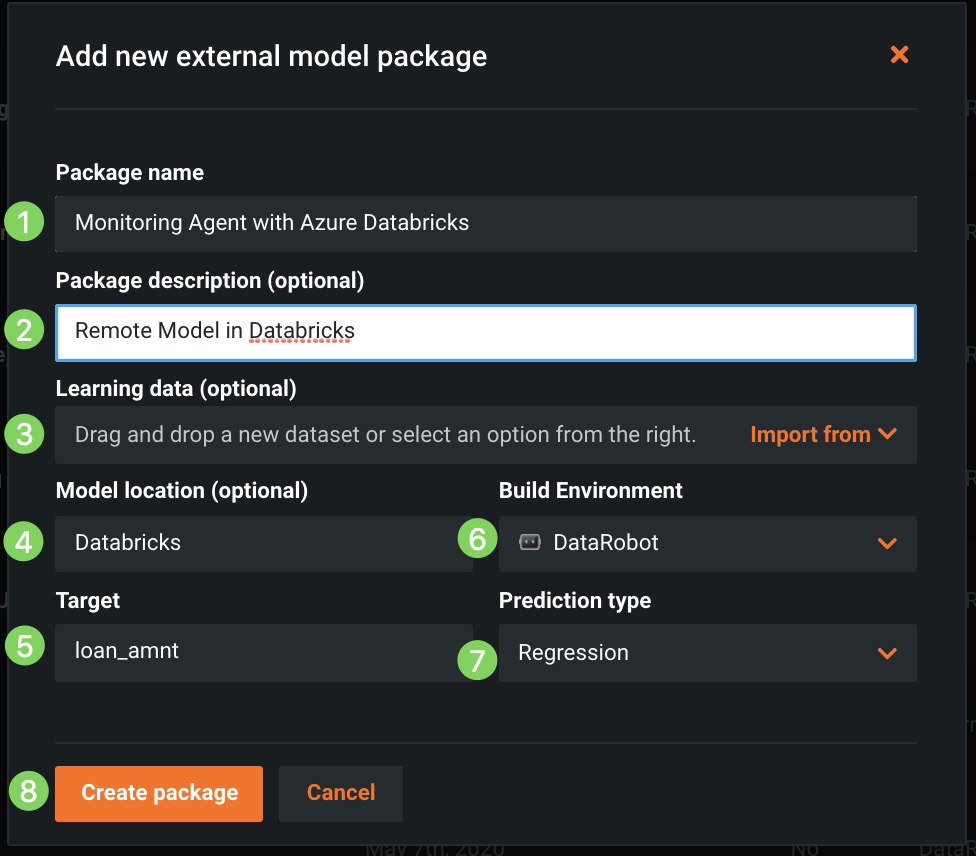
パッケージ名と説明(1と2)を指定し、ドリフト追跡用の対応するトレーニングデータ(3)をアップロードし、モデルの場所(4)、ターゲット(5)、環境(6)、予測タイプ(7)を特定します。次に、パッケージを作成(8)をクリックします。
-
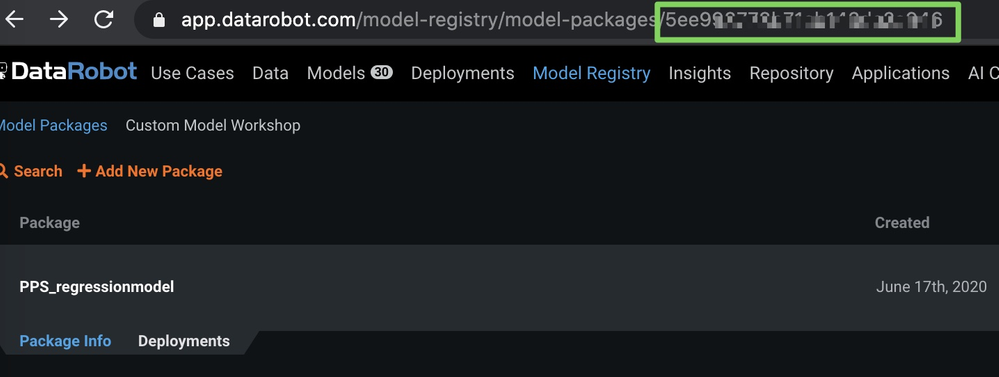
外部モデルパッケージを作成したら、以下に示すようにURLのモデルIDをメモします(セキュリティ上の理由から、画像にぼかしを入れています)。
-
デプロイ(1)をクリックし、新しいデプロイを作成(2)をクリックします。
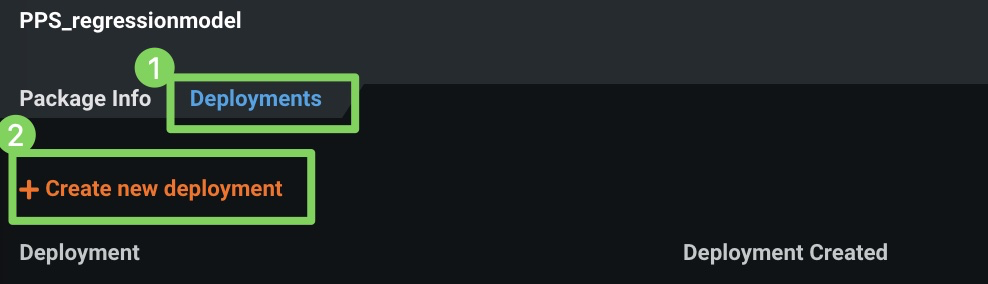
デプロイが作成されると、デプロイ > 概要ページが表示されます。
-
概要ページで、デプロイIDを(URLから)コピーします。
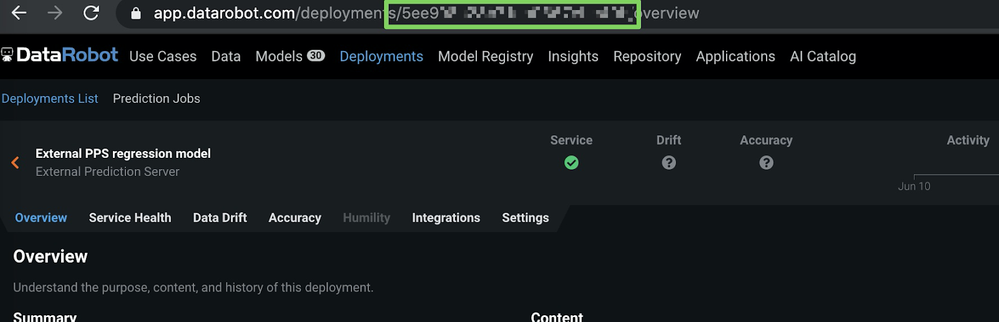
モデルIDとデプロイIDを取得したので、次のセクションで予測を報告できます。
予測の詳細の報告¶
予測の詳細をDataRobotに報告するには、Spark環境で次のコードを実行します。 入力パラメーターを必ず更新してください。
import com.datarobot.mlops.spark.MLOpsSparkUtils
val channelConfig = "OUTPUT_TYPE=RABBITMQ;RABBITMQ_URL=amqp://<<RABBIT HOSTNAME>>:5672;RABBITMQ_QUEUE_NAME=mlopsQueue"
MLOpsSparkUtils.reportPredictions(
scoringDF, // spark dataframe with actual scoring data
"5ec3313XXXXXXXXX", // external DeploymentId
"5ec3313XXXXXXXXX", // external ModelId
channelConfig, // rabbitMQ config
scoringTime, // actual scoring time
Array("PREDICTION"), //target column
"id" // AssociationId
)
実測値の報告¶
実測値を取得したら、それらを報告して時系列の精度を追跡できます。
以下の関数を使用して実測値を報告します。
import com.datarobot.mlops.spark.MLOpsSparkUtils
val actualsDF = spark.sql("select id as associationId, loan_amnt as actualValue, null as timestamp from actuals")
MLOpsSparkUtils.reportActuals(
actualsDF,
deploymentId,
ModelId,
channelConfig
)
モデルをSparkクラスター(Databricks)上のDataRobot外部にデプロイした場合でも、他のモデルと同様に監視し、一元化されたダッシュボードでサービスの正常性、データドリフトおよび実測値を追跡できます。
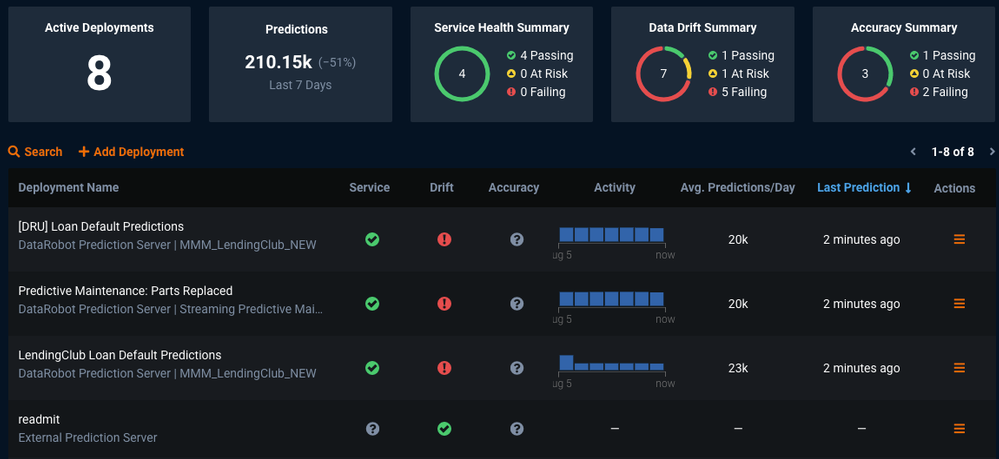
ScalaとPySparkのコードスニペットを含む完全なサンプルノートブックについては、DataRobotコミュニティGitHubにアクセスしてください。