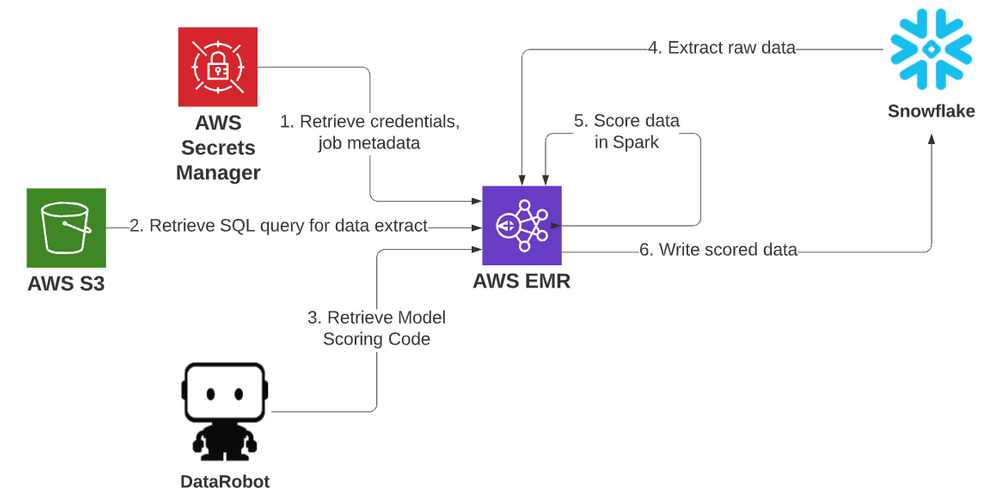
AWS EMR SparkでのSnowflakeデータのスコアリング¶
DataRobotには、Sparkで数百万のレコードをスコアリングするために使用できる、エクスポート可能なスコアリングコードが用意されています。 このトピックでは、Snowflakeをデータソースおよびターゲットとして使用する方法を説明します。 これらの手順はテンプレートとして使用でき、変更してさまざまなソースとターゲットを持つSparkスコアリングジョブを作成できます。
テクノロジーについて¶
タブをクリックして、このトピックで説明されているテクノロジーについて学びます。
Apache Sparkは、「ビッグデータ」テクノロジーファミリーと見なされているオープンソースのクラスターコンピューティングフレームワークです。 Sparkは、ストリーミングモードまたはバッチモードで、構造化または半構造化形式の大量のデータに使用されます。 Sparkには、独自の永続的なストレージレイヤーはありません。 HDFSなどのファイルシステム、AWS S3などのオブジェクトストレージ、およびデータ用のJDBCインターフェイスに依存しています。
一般的なSparkプラットフォームには、DatabricksとAWS Elastic Map Reduce(EMR)が含まれます。 このトピックの例では、EMR Sparkを使用してスコアリングする方法を説明します。 これはSparkクラスターです。必要に応じて作業用にスピンアップし、作業完了後にシャットダウンできます。
S3はAWSのオブジェクトストレージサービスです。 この例では、ジョブのデータベースクエリを動的に格納および取得するために使用されます。 S3は、ジョブの完了ターゲットとして書き込むこともできます。 さらに、クラスターログファイルがS3に書き込まれます。
資格情報のハードコーディングは、開発中またはアドホックジョブで行うことができますが、ベストプラクティスとして、開発中であっても安全な方法で資格情報を保存することが理想的です。 これは、本番のスコアリングジョブでそれらを安全に保護するための要件です。 Secrets Managerサービスでは、信頼できるユーザーまたはロールのみが、安全に保存されたシークレット情報にアクセスできます。
簡潔で使いやすいAWS CLIを使用して、この記事全体でAWSアクティビティに関連するいくつかのコマンドライン操作を実行します。 これらのアクティビティは、GUIを介して手動で実行することもできます。 CLIの設定の詳細については、AWSコマンドラインインターフェイスのドキュメントを参照してください。
Snowflakeは、データウェアハウスおよび分析ワークロード用に設計されたクラウドベースのデータベースプラットフォームです。 大規模なデータボリュームのユースケースに対応できるようスケールアップやスケールアウトが簡単に実行でき、すべての主要なクラウドプラットフォームでサービスとして利用できます。 このトピックのスコアリングの例では、Snowflakeがソースとターゲットですが、どちらもSparkスコアリングジョブの他のデータベースやストレージプラットフォームに交換できます。
プラットフォーム内のAPIホスト用に、モデルをDataRobotにすばやく簡単にデプロイできます。 場合によっては、APIでデータをモデルに取り込むよりも、モデルをデータに取り込む方が有益な場合があります。たとえば、非常に大規模なスコアリングジョブの場合です。 次の例では、拡大されたKaggleデータセットから、タイタニック号の乗客300万人の生存確率をスコアリングしています。 通常、APIでSparkの使用を検討するほどではありませんが、ここでは優れた技術的なデモンストレーションとして紹介します。
DataRobotのモデルをDataRobot RuleFitモデルのルールベースの近似としてJavaやPythonでエクスポートすることができます。 エクスポートオプションはスコアリングコードで、ソースコードと、選択した正確なモデルを保持するコンパイル済みのJavaバイナリJARを提供します。
データベースには構造化照会言語(SQL)を使用し、Scala for Sparkを使用します。 Python/PySparkを利用して、Sparkでジョブを実行することもできます。
アーキテクチャ¶
開発環境¶
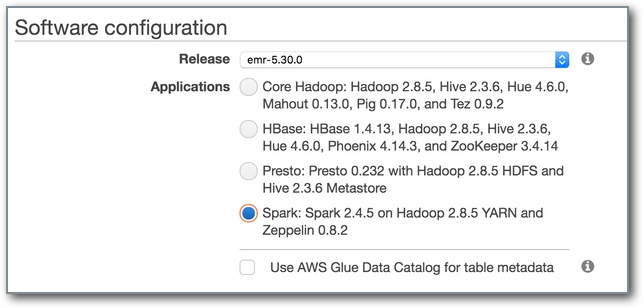
AWS EMRには、Sparkコードのインタラクティブな開発を可能にするZeppelin Notebookサービスが含まれています。 開発環境を設定するには、まずEMRクラスターを作成します。 これは、AWSのGUIオプションから行うことができます。デフォルト値を利用できます。 必ずSparkオプションを選択してください。 詳細設定を使用すると、ソフトウェアのインストールをより細かく選択できます。
作成が成功すると、クラスターの[概要]タブを表示して、AWS CLIのエクスポートボタンでインスタンスを再作成するためのCLIスクリプトが提供されます。このスクリプトは、後で保存して編集することができます。 例は次のとおりです。
aws emr create-cluster \
--applications Name=Spark Name=Zeppelin \
--configurations '[{"Classification":"spark","Properties":{}}]' \
--service-role EMR_DefaultRole \
--enable-debugging \
--release-label emr-5.30.0 \
--log-uri 's3n://mybucket/emr_logs/' \
--name 'Dev' \
--scale-down-behavior TERMINATE_AT_TASK_COMPLETION \ --region us-east-1 \
--tags "owner=doyouevendata" "environment=development" "cost_center=comm" \
--ec2-attributes '{"KeyName":"creds","InstanceProfile":"EMR_EC2_DefaultRole","SubnetId":"subnet-0e12345","EmrManaged
SlaveSecurityGroup":"sg-123456","EmrManagedMasterSecurityGroup":"sg-01234567"}' \
--instance-groups '[{"InstanceCount":1,"EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"SizeInGB"
:32,"VolumeType":"gp2"},"VolumesPerInstance":2}]},"InstanceGroupType":"MASTER","InstanceType":"m5.xlarge","Name":"Master
Instance Group"},{"InstanceCount":2,"EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"SizeInGB":32,"
VolumeType":"gp2"},"VolumesPerInstance":2}]},"InstanceGroupType":"CORE","InstanceType":"m5.xlarge","Name":"Core Instance
Group"}]'
GUIでクラスターに関する接続の詳細を確認できます。 サーバーにログオンして、追加の設定アイテムを指定します。 SSH経由で端末にアクセスできます。これには、公開IPまたはDNSアドレスが必要であり、EC2クラスターマスターインスタンスに適用されるVPCインバウンドルールセットで、SSHポート22への受信接続を許可する必要があります。マシンに到達できないために接続が拒否された場合は、ソースIP/サブネットをセキュリティグループに追加します。
ssh -i ~/creds.pem hadoop@ec2-54-121-207-147.compute-1.amazonaws.com
いくつかのパッケージを使用して、データベース接続とモデルのスコアリングをサポートします。 環境内で使用できるように、クラスターの作成時にこれらのJARをクラスターノードに読み込むことができます。 また、ジョブの送信用にJARにコンパイルすることも、実行時にリポジトリからダウンロードすることもできます。 この例では、最後のオプションを使用しています。
この記事で使用するAWS環境は、EWS EMR 5.30とSpark 2.11に基づいています。参照されている環境とパッケージの新しいバージョンがリリースされると、変更がいくつか生じる場合があります。 AWSによって既に提供されているものに加えて、2つのSnowflakeパッケージと2つのDataRobotパッケージが使用されます。
これらのパッケージをZeppelinノートブック環境で利用するには、zeppelin-envファイルを編集して、インタープリターが呼び出されたときにパッケージを追加します。 マスターノードでこのファイルを編集します。
sudo vi /usr/lib/zeppelin/conf/zeppelin-env.sh
ファイルの下部にあるexport SPARK_SUBMIT_OPTIONS行を編集し、パッケージフラグを文字列値に追加します。
--packages net.snowflake:snowflake-jdbc:3.12.5,net.snowflake:spark-
snowflake_2.11:2.7.1-spark_2.4,com.datarobot:scoring-code-spark-api_2.4.3:0.0.19,com.datarobot:datarobot-
prediction:2.1.4
Zeppelinでの作業中にさらに編集を行う場合は、編集を有効にするにはZeppelin環境内でインタープリターを再起動する必要があります。
SSHトンネルを確立して、ローカルブラウザーからZeppelinリモートサーバーにアクセスできるようになりました。 次のコマンドは、マスターノードのポート8890をローカルマシンに転送します。 パブリックDNSエントリーを使用しないと、追加のプロキシ設定が必要になる場合があります。 このステートメントは、次のトピックの「オプション1」を利用しています。 2番目のオプションのプロキシ、および追加のポートとサービスはここにあります。
ssh -i ~/creds.pem -L 8890:ec2-54-121-207-147.compute-1.amazonaws.com:8890
hadoop@ec2-54-121-207-147.compute-1.amazonaws.com -Nv
ローカルマシンのポート8890に移動すると、環境シェルスクリプトで定義されているように、パッケージと共に新しいメモを作成できるZeppelinインスタンスが表示されるようになりました。
GitHubで提供されているいくつかのヘルパーツールにより、ローカルマシンからAWS CLIを介してこのプロセス(およびこの記事で説明するその他のプロセス)をプログラムですばやく実行するのに役立ちます。
env_config.shには、プロファイル(使用されている場合)、タグ、VPC、セキュリティグループ、およびクラスター指定に使用するその他の要素などのAWS環境変数が含まれています。
snow_bootstrap.shはオプションファイルでSparkなどのアプリケーションがインストールされる前に、EMRクラスターノードを割り当てた後、タスクを実行できます。
create_dev_cluster.shは上記を使用してクラスターを作成し、接続文字列を指定します。 引数は必要ありません。
シークレットの作成¶
開発中に資格情報を環境変数にコーディングできますが、このトピックでは、完了時に自動終了するEMRの本番ジョブを作成する方法を説明します。 データベースのユーザー名やパスワードなどのシークレットの値を信頼できる環境に保存することをお勧めします。 この場合、EC2インスタンスに適用されるIAMロールには、AWS Secrets Managerサービスと対話する権限が付与されています。
シークレットの最も単純な形式には、文字列参照名と格納する値の文字列が含まれます。 これはAWS GUIで簡単に作成でき、JSONで指定されたキーと値を表す文字列を使用して、シークレットの作成をガイドします。 CLIでこれを行うために、いくつかのヘルパーファイルを使用できます。
secrets.propertiesは保存するシークレットのJSONリストです。
内容例:
{
"dr_host":"https://app.datarobot.com",
"dr_token":"N1234567890",
"dr_project":"5ec1234567890",
"dr_model":"5ec123456789012345",
"db_host":"dp12345.us-east-1.snowflakecomputing.com",
"db_user":"snowuser",
"db_pass":"snow_password",
"db_db":"TITANIC",
"db_schema":"PUBLIC",
"db_query_file":"s3://bucket/ybspark/snow.query",
"db_output_table":"PASSENGERS_SCORED",
"s3_output_loc":"s3a://bucket/ybspark/output/",
"output_type":"s3"
}
create_secrets.shはCLIを利用して、スクリプト内で指定されたシークレット名を、プロパティファイルで作成(または更新)するスクリプトです。
ソースSQLクエリ¶
SQL抽出ステートメントをコードに入れる代わりに、実行時に動的に指定することができます。 これは必ずしもシークレットである必要はなく、その潜在的な長さと複雑さを考慮すると、S3での単純なファイルの方が適しています。シークレットの1つは、この場所、db_query_fileエントリーを指しています。 S3上のこのファイルの内容—s3://bucket/ybspark/snow.queryは、300万件の旅客レコードを持つテーブルに対する単純なSQLステートメントです。
select * from passengers_3m
Sparkコード(Scala)¶
サポートコンポーネントを配置したら、モデルのスコアリングパイプラインを構築するコードを開始できます。 run_spark-shell.shとspark_env.shで必要なパッケージを含めるヘルパーを使用して、マシン上のspark-shellインスタンスで直接実行できます。 いくつかの迅速なデバッグに、この対話型セッションが役立つ場合がありますが、マスターノードのみを使用するため、コード開発を反復するのに適した環境ではありません。 より使いやすい環境のZeppelinノートブックでは、使用可能な複数のワーカーノードを活用して、yarn-clusterモードでコードを実行します。 以下のコードをコピーするか、このプロジェクトのGitHubリポジトリのsnowflake_scala_note.jsonからメモをインポートするだけです。
パッケージの依存関係のインポート¶
import org.apache.spark.sql.functions.{col}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
import org.apache.spark.sql.SaveMode
import java.time.LocalDateTime
import com.amazonaws.regions.Regions
import com.amazonaws.services.secretsmanager.AWSSecretsManagerClientBuilder
import com.amazonaws.services.secretsmanager.model.GetSecretValueRequest
import org.json4s.{DefaultFormats, MappingException}
import org.json4s.jackson.JsonMethods._
import com.datarobot.prediction.spark.Predictors.{getPredictorFromServer, getPredictor}
プロセスを簡素化するヘルパー関数の作成¶
/* get secret string from secrets manager */
def getSecret(secretName: String): (String) = {
val region = Regions.US_EAST_1
val client = AWSSecretsManagerClientBuilder.standard()
.withRegion(region)
.build()
val getSecretValueRequest = new GetSecretValueRequest()
.withSecretId(secretName)
val res = client.getSecretValue(getSecretValueRequest)
val secret = res.getSecretString
return secret
}
/* get secret value from secrets string once provided key */
def getSecretKeyValue(jsonString: String, keyString: String): (String) = {
implicit val formats = DefaultFormats
val parsedJson = parse(jsonString)
val keyValue = (parsedJson \ keyString).extract[String]
return keyValue
}
/* run sql and extract sql into spark dataframe */
def snowflakedf(defaultOptions: Map[String, String], sql: String) = {
val spark = SparkSession.builder.getOrCreate()
spark.read
.format("net.snowflake.spark.snowflake")
.options(defaultOptions)
.option("query", sql)
.load()
}
シークレットの取得および解析¶
次に、AWSに保存されているシークレットデータを取得し解析して、スコアリングジョブをサポートします。
val SECRET_NAME = "snow/titanic"
printMsg("db_log: " + "START")
printMsg("db_log: " + "Creating SparkSession...")
val spark = SparkSession.builder.appName("Score2main").getOrCreate();
printMsg("db_log: " + "Obtaining secrets...")
val secret = getSecret(SECRET_NAME)
printMsg("db_log: " + "Parsing secrets...")
val dr_host = getSecretKeyValue(secret, "dr_host")
val dr_project = getSecretKeyValue(secret, "dr_project")
val dr_model = getSecretKeyValue(secret, "dr_model")
val dr_token = getSecretKeyValue(secret, "dr_token")
val db_host = getSecretKeyValue(secret, "db_host")
val db_db = getSecretKeyValue(secret, "db_db")
val db_schema = getSecretKeyValue(secret, "db_schema")
val db_user = getSecretKeyValue(secret, "db_user")
val db_pass = getSecretKeyValue(secret, "db_pass")
val db_query_file = getSecretKeyValue(secret, "db_query_file")
val output_type = getSecretKeyValue(secret, "output_type")
クエリの環境変数への読み込み¶
次に、S3でホストされ、db_query_fileで指定されたクエリを環境変数に読み込みます。
printMsg("db_log: " + "Retrieving db query...")
val df_query = spark.read.text(db_query_file)
val query = df_query.select(col("value")).first.getString(0)
スコアリングコードの取得¶
次に、モデルのスコアリングコードをDataRobotから取得します。 これはローカルのJARから実行できますが、ここのコードではDataRobotからその場で取得します。 このモデルは、シークレットで参照されるdr_model値を変更することで、簡単に別のモデルに交換できます。
printMsg("db_log: " + "Loading Model...")
val spark_compatible_model = getPredictorFromServer(host=dr_host, projectId=dr_project, modelId=dr_model, token=dr_token)
SQLの実行¶
次に、取得したSQLをデータベースに対して実行し、Sparkデータフレームに取り込みます。
printMsg("db_log: " + "Extracting data from database...")
val defaultOptions = Map(
"sfURL" -> db_host,
"sfAccount" -> db_host.split('.')(0),
"sfUser" -> db_user,
"sfPassword" -> db_pass,
"sfDatabase" -> db_db,
"sfSchema" -> db_schema
)
val df = snowflakedf(defaultOptions, query)

データフレームのスコアリング¶
以下の例では、取得したDataRobotモデルを通じてデータフレームをスコアリングします。 これは、識別列(乗客ID)と正のクラスラベル1の確率、つまり乗客の生存確率のみを含む出力のサブセットを作成します。
printMsg("db_log: " + "Scoring Model...")
val result_df = spark_compatible_model.transform(df)
val subset_df = result_df.select("PASSENGERID", "target_1_PREDICTION")
subset_df.cache()

結果の書き込み¶
値output_typeは、スコアリングされたデータがデータベース内のテーブル、またはS3内の場所に書き戻されるかを決定します。
if(output_type == "s3") {
val s3_output_loc = getSecretKeyValue(secret, "s3_output_loc")
printMsg("db_log: " + "Writing to S3...")
subset_df.write.format("csv").option("header","true").mode("Overwrite").save(s3_output_loc)
}
else if(output_type == "table") {
val db_output_table = getSecretKeyValue(secret, "db_output_table")
subset_df.write
.format("net.snowflake.spark.snowflake")
.options(defaultOptions)
.option("dbtable", db_output_table)
.mode(SaveMode.Overwrite)
.save()
}
else {
printMsg("db_log: " + "Results not written to S3 or database; output_type value must be either 's3' or 'table'.")
}
printMsg("db_log: " + "Written record count - " + subset_df.count())
printMsg("db_log: " + "FINISH")
このアプローチは、開発、手動やアドホックのスコアリングニーズに適しています。 すべての作業が完了したら、EMRクラスターを終了できます。 AWS EMRを活用して、スケジュールに従って定期的に実行される本番ジョブを作成することもできます。
パイプラインの本番化¶
本番ジョブを作成して、このジョブを定期的に実行できます。 EMRインスタンスを作成するプロセスは似ています。ただし、インスタンスを、オンラインになった後にジョブ手順をいくつか実行するように設定します。 手順が完了すると、クラスターも自動終了します。
ただし、Scalaコードはスクリプト化された手順として実行できません。 送信するには、JARにコンパイルする必要があります。 オープンソースのビルドツールsbtは、ScalaおよびJavaコードのコンパイルに使用されます。 リポジトリでは、sbtは既にインストールされています(snow_bootstrap.shスクリプトのコマンドを使用)。 これは、開発でJARをコンパイルする場合にのみ必要であり、本番ジョブの実行から削除できることに注意してください。 コードは実際のEMRマスターノードで開発する必要はありませんが、コードが最終的に実行される場所であるため、開発に適した環境を用意してください。 プロジェクトの主な対象ファイルは次のとおりです。
snowscore/build.sbt
snowscore/create_jar_package.sh
snowscore/spark_env.sh
snowscore/run_spark-submit.sh
snowscore/src/main/scala/com/comm_demo/SnowScore.scala
-
build.sbtには、SnowflakeとDataRobotの以前に参照されたパッケージが含まれており、AWSリソースを操作するための2つの追加パッケージが含まれています。 -
create_jar_package.sh、spark_env.sh、およびrun_spark-submit.shはヘルパー関数です。 最初の関数は、プロジェクトのクリーンパッケージビルドを実行し、後の2つの関数を使用すると、ビルドされたパッケージJARのSparkクラスターにコマンドラインから簡単に送信できます。 -
SnowScore.scalaには上記と同じコードが含まれており、実行のためにクラスター送信時に呼び出されるメインクラスに配置されています。
create_jar_package.shを実行し、sbt cleanとsbt packageを呼び出す出力パッケージJARを作成します。 これにより、ジョブ送信の準備が整ったJAR、target/scala-2.11/score_2.11-0.1.0-SNAPSHOT.jarが作成されます。
JARは、run_spark-submit.shスクリプトで送信できます。ただし、自己終了クラスターで使用するには、S3でホストする必要があります。
この例では、s3://bucket/ybspark/score_2.11-0.1.0-SNAPSHOT.jarにコピーされています。
開発用EMRインスタンスの場合、JARがS3にコピーされると、インスタンスを終了できます。
最後に、run_emr_prod_job.shスクリプトを実行して、AWS CLIを使用したEMRジョブの呼び出し、EMRインスタンスの作成、ブートストラップスクリプトの実行、必要なアプリケーションのインストール、ステップ関数の実行、S3ホストパッケージJARのメインクラスの呼び出しを行うことができます。 スクリプトの--steps引数は、クラスターでspark-submitジョブを呼び出す手順を作成します。 --packages引数は、実行時にこの属性で指定されたスナップショットJARとメインクラスを送信します。 JARが完了すると、EMRインスタンスは自己終了します。
本番ジョブが作成できました。 これは、さまざまなトリガーまたはスケジューリングツールによって実行される場合があります。 S3でホストされているsnow.queryファイルを更新すると、入力を変更できます。 さらに、S3上のデータベースやオブジェクトストレージ内のテーブルの出力ターゲットも変更できます。DataRobotのさまざまな機械学習モデルも簡単に交換でき、追加のコンパイルやコーディングは必要ありません。
パフォーマンスとコストに関する考慮事項¶
次の例を参考にしてください。i5-7360U CPU@2.30GHzを搭載したMacBookで、ローカル(デフォルトオプション)スコアリングコードCSVジョブを実行すると、5,660レコード/秒のレートでスコアリングされました。 MASTERおよびCORE EMRノードにm5.xlarge(4つのvCPU 16GB RAM)を搭載したシステムを使用する場合、300〜2,800万の乗客レコードでいくつかのテストを実行すると、COREノードあたり12,000~22,000レコード/秒で実行されました。
EMRクラスターの構築には起動時間が必要です。これはさまざまで、7分以上かかります。 単純にSparkジョブを実行すると、追加のオーバーヘッドが発生します。 パイプライン全体で、2-COREノードシステム上の418件のレコードをスコアリングした場合、合計512秒かかりました。 一方、4-COREノードシステム上の2,800万をスコアリングした場合は、合計671秒でした。 別の考慮事項である価格は、EC2コンピューティングおよびEMRサービスのインスタンス時間に基づいています。
コードを微調整せずにコード化されたままのスコアリングパイプラインジョブのみを調べると、Spark(EMR)が2,800万レコードのスケーリングを示しています(2つのCOREノードで694秒から4つのCOREノードで308秒)。
AWS EMRのコスト計算は、正規化インスタンス時間で測定される方法と、クラスター支払い用の時計が刻み始めるタイミングが原因で、少し難しい場合があります。 GitHubプロジェクトを使用して、特定の期間や特定のクラスターIDが与えられた場合のリソースのおおよそのコストを作成できます。 このプロジェクトは、GitHubにあります。
4つのCOREサーバーを使用した、2,800万人の乗客のスコアリングジョブの推定値は次のとおりです。
$ ./aws-emr-cost-calculator cluster --cluster_id=j-1D4QGJXOAAAAA
CORE.EC2 : 0.16
CORE.EMR : 0.04
MASTER.EC2 : 0.04
MASTER.EMR : 0.01
TOTAL : 0.25
スコアリングパイプラインには追加の前処理および後処理ステップが含まれる場合があるため、このツールをさまざまなクラスターオプションと併用して、ユースケースごとに構築された各スコアリングパイプラインのコスト対パフォーマンスの最適化を決定することをお勧めします。
この記事の関連コードは、DataRobotコミュニティGitHubにあります。