モデリング¶
モデリング方法¶
パーティション特徴量とグループ分割の比較¶
分割手法の名前が、NextGenで変更されていることにご注意ください。
| DataRobot Classic名 | NextGen名 |
|---|---|
| パーティション特徴量 | ユーザー定義のグループ化 |
| グループ分割 | 自動グループ化 |
Robot 1
グループ分割とパーティション特徴量の違いとは? 例を挙げていただけますか? 25個の一意の値に対するTVH分割はどのようになりますか。?
Robot 2
通常、交差検定では、レコードはデータの分割にランダムに割り当てられます。 グループ分割およびパーティション特徴量では、レコードは選択した特徴量によって分割に割り当てられます。 例:
たとえば、米国の州を分割するとしましょう。 米国には50の州があります。
- グループ分割:私は、4分割交差検定を選択します。 テキサスが州である列はすべて同じ分割内にあります。 他の一部の州もこの分割にあります。
- パーティション特徴量:各州には独自の分割があり、50分割の交差検定です。
実際、米国を地域別に見ることは、グループ分割に類似しています。
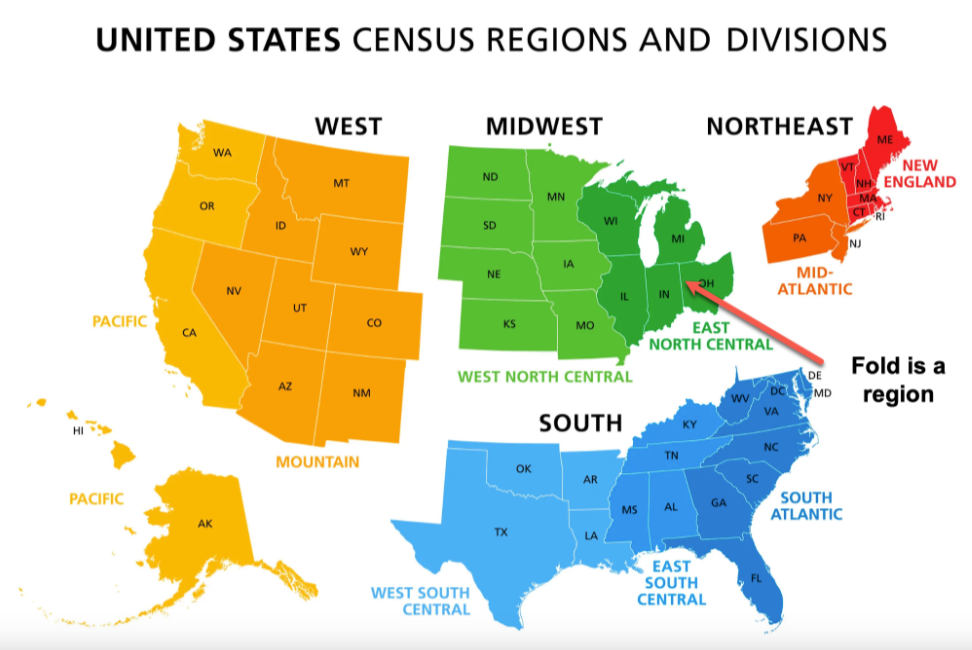
一方、州ごとの見方は、パーティション特徴量に類似しています。
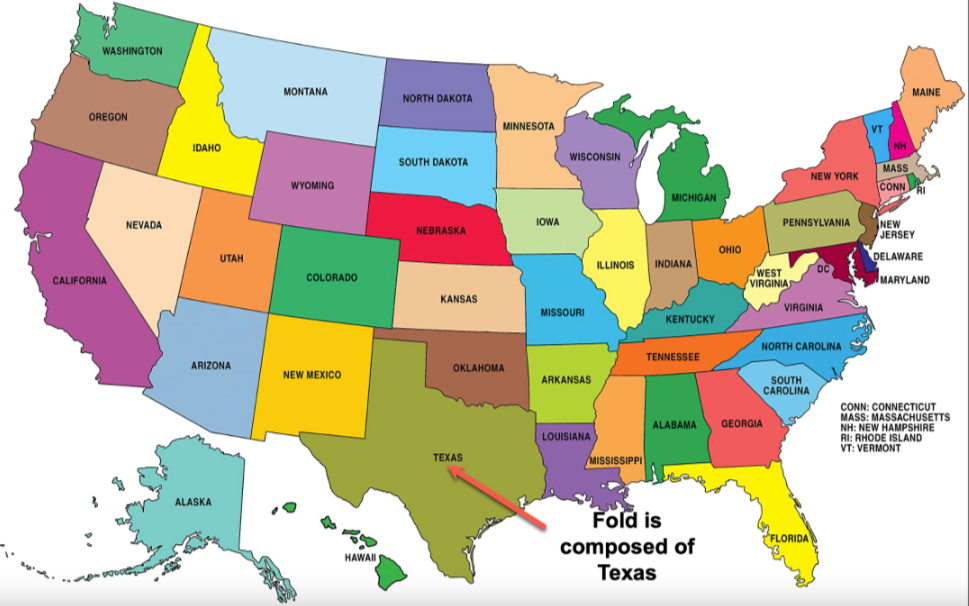
50分割は現実的ではないことが多いため、DataRobotでは、一意の値の数が25を超える特徴量に対してグループ分割を推奨しています。
DataRobotでの最適なビニング¶
Robot 1
DataRobotは最適なビニング(数値特徴量)を行うのに役立ちますか?
DataRobotのGAMモデルでは、DataRobotがXGBoostモデルからの部分依存に基づいて各数値特徴量をビニングします。 していることで私が気づいていないことが他にありますか?
Robot 2
決定木を使用してビニングを見つけます。 これは本当に最適です。 完全に最適ではないかもしれませんが、適切なビニングを見つけるために良い仕事をします。
Robot 3
単一の特徴量の単一の決定木では、少なくとも最小数のターゲット値を持つ葉が生成されます。 したがって、ビニングは可変サイズであり、葉ごとに十分なターゲット統計を持つように設計されています。 境界は単なるソートされた分割です。 XGBoostモデルはターゲットを平滑化するために使用され、決定木はXGB予測で動作します。
異常検知とその他の機械学習の問題¶
異常検知は教師なし学習の問題です。
つまり、DataRobotの問題の多くが該当する教師あり学習とは異なり、ターゲットを使わず、ラベルもありません。 教師あり学習には「正しい」答えがあり、モデルは特徴量を用いたトレーニングによって、その答えを可能な限り近い形で予測します。
教師あり = 自分が何を探しているかわかっています。
教師なし = 何か面白いものを見せてください。
異常検知の手法は多数ありますが、どのようなやり方で検知しても、異常であるかどうかに対する本当の 「正解」 はありません。ただ、共通する行をグループ化して、 「ちょっと待て、この新しいデータは古いデータとは違うようだ、調べたほうがいいかもしれない」 というヒューリスティックな方法を見つけようとしているだけです。
異常検知のユースケースの中には、数百万件の取引があっても、ラベルの割り当てを手作業で行わなければならないものがあります。 1日に何千件もの取引がある場合、人間には不可能です。したがって、ラベルのないデータが大量に存在することになります。 異常検知は、異常な取引やネットワークアクセスを検知するために使用されます。 ランク付けされたリストを受け取れるので、手作業での調査にそれを利用すれば、時間を節約することができます。
ELI5の例
親が幼い子どもに食事を与えていたとき、子どもが食べ物を床に投げつけるので、親は怒りました。 翌日も同じことが起こりました。 次の日、親が子どもに食事を与えていたとき、子供はちゃんと食べたので、親は喜びました。 子どもは親の反応を特に意識しており、それが学習を促す (学習を監督する) 結果となります。つまり、子どもは自分の行動と親の反応の関連性を学習します。これが教師あり学習です。
親が子どもに食事を与えていたとき、子どもは食べ物を冷たいものと熱いものに分けました。 後日、子どもは豆、ニンジン、トウモロコシを別々にしました。 子どもは食べ物の中に何らかの構造を発見していますが、彼らの観察を導き出す結果(親の反応など)があったわけではありません。
教師なし学習の詳細を参照してください。
API vs. SDK¶
API:「こうやって話します。」
SDK: 「これらは、私と話すためのツールです。」
API: 「このチューブに向かって話してください。」
SDK: 「これは拡声器と、チューブを適切な位置に固定するための専用工具です。」
例
DataRobotのREST APIはAPIですが、PythonとRのパッケージは、APIとやり取りする簡単な方法を提供するため、SDKの一部になっています。
API: ボルトとナット
SDK:ドライバーとレンチ
APIとSDKの詳細を参照してください。
モデルの整合性とセキュリティ¶
Robot 1
AIモデルの整合性とセキュリティを保証するために、プラットフォームはどのような手段をサポートしていますか?
たとえば、敵対的トレーニングを提供し、セキュリティコントロール、モデルの改ざん検知、モデルの出所保証によってアタックサーフェスを減らしていますか?
Robot 2
さまざまなアプローチがあります。
-
敵対的トレーニングを明示的に使用しているわけではありませんが、外れ値や好ましくない例に対して非常に堅牢なXGBoostなどのツリーベースのモデルを多用しています。 これらのモデルは外挿を行いません。DataRobotでは、元の未処理のデータに当てはめます。 さらに、XGBoostはデータの元の値ではなく順番のみを使用するため、大きな外れ値は、たとえ何桁であっても結果に影響を与えません。 私達が社内で行ったテストでは、XGBoostはラベル付けに誤りのあるデータに対しても非常に堅牢であることがわかりました。 元のトレーニングデータに外れ値や好ましくない例が含まれている場合、XGBoostはそれらの処理方法を学習します。
-
DataRobotのAPIはすべてAPIキーで保護されています。 予測であっても、一般的なアクセスは許可していません。 これにより、権限のないユーザーは、DataRobotのモデルに関するすべての情報にアクセスできません。
-
モデル内部へのユーザーアクセスを直接許可していないため、モデルの改ざんを防ぐことができます。 モデルを改ざんする唯一の方法は、ポイント1を通じてであり、XGBoostは好ましくない例に対して堅牢です。 (格付表モデルとカスタムモデルでは、ユーザーがモデルを指定できるため、この場合は使用しないでください。 ただし、格付表モデルは非常に単純です。また、カスタムモデルにおいては、後で確認できるように元のソースコードを保持しています)。
-
MLOpsでは、モデル置換の完全な履歴を提供し、各モデルとそれを作成したプロジェクト(トレーニングデータ、モデル、チューニングパラメーターなど)を結び付けることができます。
Robot 1
外挿を行わないのですか?
Robot 2
これは、有害な攻撃を防ぐ上で非常に大きな役割を果たします。 DataRobotのほとんどのモデルは外挿を行いません。
バイアスと公平性に関する資料もご覧ください。 モデルのバイアスを評価することは、有害な攻撃からの保護と非常に密接に関連しています。 バイアスと公平性の機能に関するドキュメントには、プロジェクト開始時の設定、モデルインサイト、およびデプロイ監視の各オプションについての説明があります。
Poisson最適化指標¶
Robot 1
こんにちは。プロジェクトを連続値問題として設定するほかに、以下について何か提案はありますか?
- DRはカウントデータのモデリングを明示的にサポートする予定はありますか?
- DRは、顧客がこのプラットフォームを使用したい場合、どのようにカウントをモデル化するよう提案しますか?
これは何度か出てきました(昨日の別のプロジェクトでも、回答がカウントであるにもかかわらず、これを無視してアップロードし、連続値としてモデリングしていました)。
Robot 1
私が本当に疑問に思っているのは、カウントのモデル化を示唆しているブループリントの中に、実際にカウントをモデル化しているものがあるのかということです。XGB + Poisson損失はそうだと思います。 また、GLMベースのブループリント(Elastic Netなど)は、当然Poisson/NB分布を本来サポートしていますが、DataRobotがそれらをサポートしているかどうかはわかりませんでした。
Robot 2
プロジェクト指標としてPoissonを使用します。DataRobotはカウントデータにも対応しています。 データのログについて心配する必要はありません。ユーザーに代わってリンク関数が処理されます。
カウントデータをモデリングするためのPoisson GLM、Poisson XGBoost、Poissonニューラルネットワークがあります。それらはうまく機能します。

Robot 2
また、モデルカウントを行うプロジェクト(Poisson損失を使用するプロジェクトなど)の加重、オフセット、エクスポージャーもサポートします。

Robot 3
データをプラットフォームにロードしてスタートを打つだけで、10回のうち9回うまくいくと考えています。 ターゲットのEDA分析に基づいて、推奨される最適化指標が既に設定されている場合があります。
KerasまたはTFのインポート¶
Robot 1
.tfモデルまたは.kerasモデルをインポートする方法はありますか?
Robot 2
カスタムモデルを除いて、モデルのインポート(.pmml、.tf、.keras、.h5、.jsonなど)は許可されていません。 とは言え、カスタムモデルを使用して、何でも欲しいものをインポートするなど、何でもやりたいことをすることができます。
Robot 1
カスタム推論を実行しようとしている顧客がいます。 これは使えるのでしょうか? それとも.h5だけなのでしょうか? あるバージョンのモデルオブジェクトと別のバージョンのモデルオブジェクトのトレードオフがよくわかりません。 .h5とJSONのみを使用しました。 私は、JSON加重のインポートがサポートされているかどうかを彼が知りたがっていると思います。
Robot 2
モデルファイルのインポートは、カスタムモデルを除いてサポートしていません。カスタムモデルの場合、ファイルをロードしてデータをスコアリングするためにカスタム推論モデルを記述する必要があります。 はい、カスタム推論モデルをサポートしています。 カスタム推論モデルでは、文字通り何でもできます。
Robot 1
ありがとうございます。鈍感だったり、混乱していたらすみません。カスタム推論では、.pb、.tf、.kerasファイルの読み込みができるはずです。
Robot 2
はい。 彼は自分のPythonコードを書く必要があります。 したがって、Pythonスクリプトを記述して、.pd、.tf、.keras、または.whateverファイルとスコアリングデータをロードできる場合、そのスクリプトをカスタム推論モデルにすることができます。
Robot 1
もちろんです:) これでわかりました。 Robot 1に決まってます。ありがとう
日本語でのデフォルト言語の変更¶
Robot 1
日本語のテキスト特徴量をモデリングする際にデフォルトの言語が変更されたのはなぜですか?
こんにちは、これは顧客からの質問です。
日本語のテキスト特徴量でモデリングするとき、デフォルトで「言語」は「英語」に設定されていました。ところが、最近同じデータを使用してモデリングを実行したとき、設定は「language=japanese」に変更されました。基本的に、これまではデフォルトで「language=english」に設定されていましたが、今後、日本語を入力した場合、「language=japanese」に自動的に設定されますか?
このイベントを自分のデータで再現できました。 2022年7月19日に作成されたモデルにはlanguage=englishがありましたが、今日同じ設定でモデルを作成したときには、language=japaneseがありました。 これは、デフォルトが「Word N-Gram」から「Char N-Gram」に変更されたときに更新された設定ですか?
Robot 2
以前は、すべてのデータセットについて「英語」が表示されていましたが、これは間違っています。 NLPヒューリスティック改善の後、データセットの言語を動的に検出して設定するようになりました。
さらに、日本語データセットのchar-gramのパフォーマンスがword-gramよりも優れていることがわかったため、速度と精度を向上させるためにchar-gramに切り替えました。 しかし、Text AIワードクラウドインサイトを良好な状態に維持するために、char-gramとword-gramの両方のWCを検査できるように、1 word-gramベースのブループリントもトレーニングします。
他に質問があれば、お気軽にお問い合わせください。
Robot 1
Robot 2、コメントありがとうございます。 NLPが改善され、言語が適切に設定されるようになったことを顧客に説明します。 また、あなたの言及のとおり、word-gramベースのBPモデルが作成されていることを確認できました。 ありがとう
ビジュアライゼーション¶
リフトチャートは何を示していますか?¶
リフトチャートは、モデルがどの程度「適切に調整されているか」を理解するのに役立ちます。これは、「モデルが、同様の出力値を持つ観測値のグループに対して予測を行う場合、モデルの予測は、実際に発生した結果とどの程度一致しているか?」ということです。
ELI5の例
たとえば、100個の石を持っているとします。 友人がそれぞれの石の大きさを予想し、あなたは実際に測ってみます。 次に、(実際の大きさではなく、友人の予想に従って)石を小さい順に並べます。 石を10個のグループに分け、それぞれのグループの平均的な大きさを求めます。 そして、友人が予想した大きさと、自分で測定した大きさを比較します。 これで、友人がどれだけ石の大きさを当てるのが上手かを判断できます。
たとえば、顧客の解約モデルを構築し、顧客の10%を対象としたキャンペーンを実施するとします。 解約の可能性が高い10%をターゲットにするモデルを使えば、モデルを使わずランダムにキャンペーンを実施するよりも、解約の可能性がある顧客をターゲットにできる可能性が高くなります。 累積リフトチャートは、これをより明確に示します。
TVの天気予報によると、今後5日間の降水確率は80%です。 もし、そのうちの1日しか雨が降らなかったら、彼らが伝えた降水確率が、あなたが思っている降水確率と合わず、気象予報士に腹を立てるかもしれません。 リフトチャートは、モデルの降水確率を視覚化するのに役立ちます。 モデルが予測をする場合、それらの予測は現実に起きている事象と一致するのでしょうか? さらに、それらの予測は何を意味するのでしょうか?
より技術的な機能:雨が降るかどうかを予測するモデルを構築します。 100日間にわたって、モデルでは毎日80%の確率で雨が降ると予報しています。 実際のデータで、これらの100日のうち80日雨が降れば、そのモデルは良好です。 この100日間のうち40日雨が降っただけでは、モデルはあまり良好ではありません。
リフトチャートでは、観測値をグループに分け、予測値が実際の発生とどの程度一致しているかを確認するものです。 ここで、「モデルがX%と予測する場合、その予測は人間によるX%の解釈と一致しますか?」という質問に答えるのに、リフトチャートは役立ちます。
リフトチャートの「予測」ラインと「実測」ラインがほぼ一致する場合、人間として理にかなっている方法で、モデルが優れた予測を行っているということです。 「予測」ラインが「実測」ラインよりもはるかに上にある場合、モデルの予測は高すぎます(モデルは80%の降水確率と考えていますが、実際には40%しか降っていません)。
「実測」ラインが「予測」ラインよりもはるかに上にある場合、モデルの予測は低すぎます(モデルは80%の降水確率と考えていますが、実際には99%降りました)。
測定しようとしている内容の本質を捉えた、面白いジョークがあります。オーブンの中に頭を入れ、冷凍庫の中に足を入れている人は、平均して快適だと言います。
リフトチャートの詳細を参照してください。
ROC曲線とは?¶
ROC曲線は、優れたモデルがデータをどの程度適切に分類できるかを示す尺度であり、2つのモデルを比較するための既成の手法としても優れています。 通常、数種類のモデルから選択するため、比較する方法が必要です。 もし、ROC曲線が非常に良いモデル、つまり真陽性率が100%に近く、偽陽性率が0%の分類モデルを見つけることができれば、そのモデルがおそらく最適なモデルであると言えます。
ELI5の例
「宇宙人は存在するのか?」という疑問に対する答えを得たいとします。この疑問に対する答えを得るための最善の方法は、知らない人に「昨晩、何か変なものを見ませんでしたか?」と尋ねることです。もし「はい」と答えたら、宇宙人は存在すると結論づけます。 もし「いいえ」と答えたら、宇宙人は存在しないと結論づけます。 ありがたいことに、軍隊にいる友人がレーダー技術を使えるので、宇宙人が現れたか現れなかったかを判断できます。 ただし、その友人には来週まで会えないので、今はインタビュー実験をするのがベストな選択です。
さて、どの人にインタビューするかを決めなければなりません。 宇宙人の存在を今すぐ結論づけるべきか、それとも軍人の友人を待つべきか、どうしても天秤にかけなければなりません。 100人くらい集めて、明日、それぞれの人を相手にインタビュー実験を行います。 ROC曲線は、視覚に障害がある人、お酒を飲む人、人見知りな人など、どういう人にインタビューすればいいかを決める方法です。ROC曲線は、各人のランキングと、その人がどの程度実験に適しているかを表すので、最後に「最適な」人を選べます。「最適な」人が十分最適である場合は、実験に進みます。
ROC曲線のY軸は真陽性率で、X軸は偽陽性率です。 お酒をたくさん飲む人は、曲線の右上にランクされていることは想像できますね。 彼らは何でも宇宙人だと思うので、真陽性率は100%です。 宇宙人が存在していれば、彼らは宇宙人を判別できますが、偽陽性率も100%です。何でもかんでも宇宙人だと言っていると、実際には宇宙人が存在しない場合、完全に間違っていることになります。左下にランクされている人は宇宙人を信じていません。 宇宙人は存在しないので、彼らは何を見ても宇宙人だと思いません。 偽陽性率、真陽性率とも0%です。 繰り返しますが、何を見ても宇宙人だと思わないので、宇宙人が存在するかどうかを確認できません。
必要なのは、真陽性率が100%で偽陽性率が0%の人です。 彼らは、宇宙人が存在する場合にのみ、宇宙人を正しく判別できます。 したがって、手順としては、100人を対象に、真陽性と偽陽性の領域でランク付けします。
ROC曲線の詳細を参照してください。
ホットスポットとは?¶
ホットスポットは、その後のDataRobotプロジェクトで特徴量エンジニアリングのアイデアを与えてくれるでしょう。 ホットスポットは単純なIF文として機能するため、追加することでモデルがより良い結果を得られるかどうかを簡単に確認できます。 また、ホットスポットによって、データの中で変数が連携しているクラスターを見つけ出し、それらの変数同士のやり取りを確認することもできます。
ELI5の例
もし、ホットスポットがユーザーと会話することができたら:「このモデルは、裏でかなりの計算をしていますが、簡単なコードで記憶したり実装したりすることができて、精度をあまり落とすことのないif-then-elseのルールにまとめてみましょう。 有望に見えるルールもあれば、そうでないルールもあるので、それらを調べ、あなたの専門知識に基づいて役に立つかどうかを確認してください。」
"Age > 65 & discharge_type = 'discharged to home'"のような大まかで極端なルールの場合、退院して自宅に戻った65歳以上の人が糖尿病で再入院する確率が高いと結論づけることができるかもしれません。 そうすると、全く非科学的なアプローチではありますが、対象者の再入院を防ぐための治療を行うという新しいビジネスも考えられるでしょう。
ホットスポットの視覚化の詳細を参照してください。
Nグラムと予測の信頼度¶
Robot 1
どのwords/n-gramsが予測の信頼性を高めるかを知るにはどうすればよいですか?
Robot 2
ワードクラウドがこれに役立ちます!
Robot 3
n-gramを含む線形モデルでは、 係数を直接確認することもできます。
Robot 2
最後に、テキスト特徴量の 予測の説明です。
Robot 1
お返事ありがとうございます。 これらは大好きで、理に適っています。 ワードクラウドを推奨しましたが、彼女は、それが信頼性ではなく強度であることを示しました(私にとっては関連性が高い)。
Robot 2
線形モデルは正規化されているので、信頼性の低い単語は削除されます。
ワードクラウドのリピート¶
Robot 1
ワードクラウドで、用語が複数回出現する理由
そのような場合、係数が異なるのはなぜでしょうか。
Robot 2
ワードクラウドは、複数のテキスト列を組み合わせていますか。
Robot 1
はい、それは間違いありません、ありがとう。1つの特徴量だけでワードクラウドを表示する方法はありますか。
Robot 2
最もシンプルな解決策は、特徴量セットを使用し、関心のある1つのテキスト特徴量だけで、モデルをトレーニングすることです。
Robot 1
^^ 結局、私がやったのはまさにそれです。 迅速な回答をいただき、ありがとうございました。
ペイオフ行列の代替使用¶
Robot 1
こんにちは、チームの皆さん。 クライアントと私は ペイオフ行列の数値をまとめ、別の方法で事態を調べていました。 目標は、ユースケースからコスト削減の正当化と利益要因の特定をすることです。
例:
-
True Positive(メリット):これは、キャンセル済みとして正しく予測された注文からのメリットです。 メリットは、在庫コストなし / 限定的です。 たとえば、アイテムの保存に通常100ドルの費用がかかる場合でも、キャンセルによって、追加コストはありません(ここに0を入力します)。 メリットは、積極的なリーチアウトによって得られる追加的な収益から得られる可能性があります
-
True Negative(メリット):これは、キャンセルされていないと正しく予測された注文からのメリットです。 顧客はこのアイテムをキャンセルせず、出荷を継続しているため、追加のメリット / コストは0です(平均で1000ドルの利益、または注文あたり-100の在庫コスト)
-
False Positive(コスト):これは、キャンセルされなかった注文をキャンセル済みとして分類することに関連するコストです。 発生するコスト。注文が満たされていないか遅延しているための機会の損失またはビジネスの損失(-200)
-
False Negative(コスト):これは、キャンセルされていないものとして分類された注文が、実際にはキャンセルされることに関連するコストです。 ここでインベントリ管理のコスト(-$100)が発生する必要があります
共有しようと思っていたところです!
Robot 2
素晴らしい!
小規模データに関する予測の説明¶
注意
説明されている回避策は、DataRobotモデリングで使用される 分割手法に精通しているユーザーを対象としています。 変更による影響、および結果として得られるモデルへの影響を必ず理解してください。
Robot 1
小規模データセットの 予測の説明を取得できますか?
小規模データセット、特に検定サブセットが100行未満のデータセットの場合、XEMP予測の説明は実行できません。 (これはSHAPにも当てはまることが想定されますが、まだ確認していません)。 これに対して共通の回避策はありますか? 重複を作成してデータセットを2倍や3倍にすることを検討していましたが、他のユーザーがより巧妙なアプローチを使用したかどうかはわかりません。
Robot 2
これは実際には、SHAPには当てはまりません。 最少行数はありません。 🤠
#cfdsまたは#data-science、またはどこかで回避策が説明されているような気がします... 一つだけできることは、100行が検定に表示されるようにパーティショニング比率を調整することです。 他にもトリックがあるかもしれません。
Robot 1
そのとおりです。2番目のアイデアは理にかなっていますが、おそらく200を超える行が必要です。 ユーザーは86行のデータセットを有しています。
86個のユースケースを必要としたくないだけです。 🥁
Robot 2
OK、ダメでした。 🎲
重複には十分注意していますが、これによって問題が解決される可能性があります。
-
実際のデータセットでトレーニングし、「トレーニング予測」を実行し、すべての行のパーティションを注意深くメモします。
-
データセットをコピーした行で補完し、元のすべての行が以前と同じパーティションになり、コピーしたすべての行が検定分割になるように、パーティション列を追加します。 おそらく、ホールドアウトはそのままにしておきたいものと推定します。
-
新しいプロジェクトを開始し、ユーザーCVを選択してモデルをトレーニングします。 おそらくトレーニング予測をし直し、元の行が同じ予測値を保持していることを確認します。
-
今すぐXEMPを実行できる状態であるべきです。
Robot 2
私は(願わくは)、結果的に同じトレーニング済みモデルになると思いますが、あなたが手にするのは偽装されたXEMPです。 しかし、変更したモデルの検定スコアは非常に疑わしいものとなります。 XEMPの説明は、コピーしたデータが検定セット内の特徴量の分布を著しく変更しない限り、おそらく問題ありません。
ホールドアウト行を慎重に同じにし、かつホールドアウトスコアが2つのモデルで一致すれば、それは成功の兆しであると思います。
Robot 1
そのとおりです。オートパイロットを再実行すれば、その検定セットでは途方もなくうまく機能します。ところが、元のオートパイロットから同じブループリントをトレーニングするだけで、問題はなくなるでしょう。
Robot 2
はい。 リーダーボードの順序がおかしく、うまくいくブループリントはかなり異なったものである可能性があるため、オートパイロットはおそらく異なるシーケンスのブループリントを実行します。
言うまでもなく、モデル選択プロセスの早い段階で行うほど、より疑わしくなります。 ほぼ固定されたモデルについてディープダイブをしているのであれば、それはそれでよいとして、まだ多くのオプションから選択している段階であれば、それは別の状況です。
Robot 1
素晴らしい、ありがとう!