プラットフォーム¶
エンドツーエンドの機械学習プラットフォームとは?¶
パンを焼くようなものだと思ってください。 市販のパンミックスを使ってレシピ通りに作ったとしても、他の人がそれを食べてしまったら、エンドツーエンドにはなりません。 自分で小麦を収穫し、製粉して、小麦粉、イースト、水などを入れて一からパンを作り、いくつかのレシピを試して、一番おいしいパンを選び、自分で食べ、カビが生えないかどうか見る、これがエンドツーエンドです。
シングルテナントとマルチテナントのSaaS?¶
DataRobotは、シングルテナントとマルチテナントの両方のSaaSをサポートしています。こちらがその意味です。
シングルテナント:賃貸物件に住むのと似ています。 自分が使っていないときは、他の誰も使っていません。 他人に荒らされる心配もなく、安心して荷物を置いておけます。
マルチテナント:ホテルに泊まるのと似ています。
マルチテナント:鍵付きの個室がたくさんある図書館を想像してみてください。すべての利用者が個人蔵書のために専用の部屋を持っていますが、スペースの中央に収納された主要な蔵書は共有されており、誰でもそれらの資料を利用できます。 ほとんどの場合、プライバシーが十分に確保された中で個人蔵書を管理できます。しかし、建物の中心部に収納された各蔵書は1冊ずつしかないため、誰かが特定のトピックに関する蔵書全部を借りてしまうと、他の人は順番待ちということもあり得ます。
シングルテナント:多数の分館で構成される図書館ネットワークを想像してみてください。どの分館も所蔵する蔵書は申し分なく、かつ個室も提供しています。 利用者は自分が利用する分館にある個人蔵書を他の利用者と共有する必要はありませんが、各分館は中央図書館委員会によって管理され、すべての利用者のためにそれぞれの蔵書内容が定期的に更新されるようになっています。
セルフマネージド:一部の利用者は、図書館のスペースを使わずに、コピーを取って自宅で使用したいと考えています。 このような人たちは、蔵書と資料のコピーを取って家に持ち帰り、自分のスケジュールで、個人所有の資料とともにそれらをメンテナンスしています。 これにより、コンテンツのプライバシーとコントロールがさらに強化されますが、自動更新、新刊、および図書館管理の利便性は失われます。
Robot 1
シングルテナントSaaSおよびマルチテナントSaaSとはどういう意味ですか? 特にDataRobot Cloudに関しては?
Robot 2
シングルテナントとマルチテナントは一般的に、サービスとしてのソフトウェア(SaaS)アプリケーションのアーキテクチャを指します。 シングルテナントのアーキテクチャでは、各顧客はDataRobotアプリケーションの自分の専用インスタンスを持っています。 これは、DataRobotは他の顧客から完全に分離され、顧客はソフトウェアの独自のインスタンスを完全に制御できることを意味します(自己管理)。 この場合、これらのデプロイオプションはこのカテゴリーに分類されます。
- 仮想プライベートクラウド(VPC)、顧客が管理
- AIプラットフォーム、DataRobotが管理
マルチテナントSaaSアーキテクチャでは、複数の顧客がDataRobotアプリケーションの単一のインスタンスを共有し、共有インフラストラクチャ上で実行します。 これは、顧客はソフトウェアの専用インスタンスを所有しておらず、そのデータや操作が他の顧客と共に保存および実行される可能性はありますが、さまざまなセキュリティ管理によって分離されることを意味します。 これは、DataRobotマネージドクラウドが提供するものです。
DataRobotのコンテキストでは、マルチテナントSaaSは、インスタンス / ノードのコアセットである単一のコアDataRobotアプリ(app.datarobot.com)です。 すべての顧客が、同じジョブキューとリソースプールを使用しています。
シングルテナントでは、代わりに各ユーザーに対してカスタム環境を実行し、プライベート接続で接続します。 したがって、リソースは単一顧客専用であり、アクセスの制限とカスタマイズ性が向上します。
Robot 3
- シングルテナント = 顧客1社のために1つのクラウドインストールを管理します。
- マルチテナント = 1つのインスタンスで複数の顧客を管理します。これはhttps://app.datarobot.com/です。
Robot 2
シングルテナント環境では、ある顧客のリソース負荷が他の顧客から分離され、誰かの非常に大規模でリソース集約的なジョブが他の顧客に影響を与えることを回避できます。 とは言え、ワーカーを分離しているため、大きな作業ジョブが1人のユーザーで実行されている場合でも、他のユーザーには影響しません。 また、1人のユーザーがすべてのワーカーを独占できないようにするためのワーカー制限もあります。
Robot 1
わかりました...
Robot 2
シングルテナントのより厳格な分離は、セルフマネージドのメリット(プライバシー、専用リソースなど)と、クラウドのメリット(独自のサーバー / ハードウェアを維持する必要がなく、ソフトウェアの更新と一般的なメンテナンスはDRによって処理されるなど)とのバランスを取る方法です。
Robot 1
ありがとう、Robot 2(および3)... この概念がずっとよく理解できるようになりました!
Robot 2
少し理解してもらえてしてうれしいです!シングルテナントの開発に直接関与していないため、実装方法の詳細はありませんが、これは、マルチテナント環境と並行してシングルテナントSaaSオプションをホストする一般的な動機については正確な説明です。
Kubernetesとは何ですか?さらに、Kubernetesをネイティブで実行することが重要な理由は何ですか?¶
Kubernetesは、アプリケーションをホストし、動的なアプリケーションワークロードをスケジュールするためのオープンソースプラットフォームです。
Kubernetes以前は、ほとんどのアプリケーションは個々のサーバーを起動し、データベースノードやWebサーバーノードなどにソフトウェアをデプロイすることでホストされていました。
Kubernetesはコンテナ技術とコントロールプレーンを使用して個々のサーバーを抽出し、負荷に応じてアプリケーションのデプロイサイズを簡単に変更し、ローリングアップデートやノード障害からの自動リカバリーなどの一般的なニーズに対応できるようにします。
Kubernetesは世界で最も人気のあるアプリケーションホスティングプラットフォームとなっているため、DataRobotがKubernetes上でネイティブで動作することは重要です。 ユーザーのインフラストラクチャチームにはKubernetesクラスターがあり、あらゆるアプリケーションに特注の仮想マシンを維持するのではなく、サードパーティーベンダーのソフトウェアをクラスタにデプロイしたいと考えています。 これは、多くのインフラストラクチャチームがKubernetesクラスターのセットアップ方法または提供方法をすでに知っているため、インストールがより簡単であることを意味します。
注目すべきリンク:
CPUとGPUの比較¶
以下のNVIDIAの図は、CPUとGPUの比較に役立ちます。
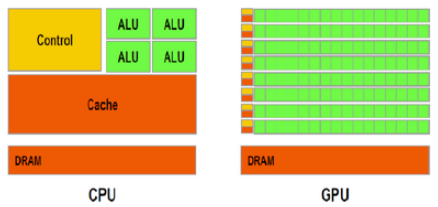
CPUは、たくさんの数学の調整と計算の両方をするように設計されています。これらには、多数のルーティング設定があり、ドライバー [またはオペレーティングシステム] に、そのパス設定や整理をシンプルな計算と同じ様に簡単にするために構築させます。 これらはコンピューターの「脳」として設計されているため、すべてを実行するよう構築されています。
GPUは、名前のとおり、グラフィックに特化して設計されています。 動画と3Dグラフィックをすばやくレンダリングするには、非常に単純な計算を一度にたくさん実行する必要があります。たとえば、1920×1080のディスプレイ [合計2073600ピクセル]の色を計算する「もの」 [CPUコア] を1個用意するのではなく、それぞれ1行分のピクセルを計算する専用の 「もの」 [GPUコア] を1920個用意し、すべてを並行して実行します。
「このピクセルの16進数コードを別のR、G、およびB値に分割して、画面のピクセルマトリックスに送信する」タスクは、たとえば、「この動画ファイルを一連のフレームに変換し、それらをこの他のアプリケーションの現在の表示フレームと組み合わせ、このタスクを中断してキーボード / マウス入力を検出して応答する準備をして、このバックグラウンドプロセスを常に実行し続ける...」タスクよりもはるかにシンプルです。 このため、GPUはCPUよりも低速かつ制限的でありながら、なおも有用です。また、その計算を完了するユニークな方法を持つ可能性があるため、X目的 [3Dレンダリングを「画面への表示」よりも柔軟性を高くする]ために特殊化することができます。 非常に単純な変換しかわからないか、以前に実行していたことを追跡できないのかもしれません。特にCPUとバッファ [RAM] が履歴を追跡している場合、「履歴」がグラフィックの表示に常に役立つとは限りません。
CPUはさまざまな用途で使用されるようにしたいので、私が記述する可能性のある高水準コードと、マシン固有のレジスターやルーティングの間で翻訳するオペレーティングシステム / ドライバーが多数ある傾向があります。 しかし、GPUはデフォルトの前提「これは基本的なグラフィックデータをよりスケーラブルにする」をもとに作成されるため、より特殊なマシンの機能が使用されることがよくあり、また多くの場合に、要因ははるかに制限されることがあります。 特定のユースケースで役立つ非常に具体的な操作をGPUに指示できる翻訳者を見つけることは、必要な操作をCPUに説明できる複数の有用な翻訳者に比べて難しいかもしれません。
ELI5の例
CPU(中央処理装置)はトラックが計算を行う4車線の高速道路、GPU(グラフィックスプロセッシングユニット)は小さなショッピングカートが計算を行う100車線の高速道路と考えてください。 GPUは並列処理に優れていますが、それほど複雑でないタスクに限られます。 ディープラーニングは主に行列乗算のバッチであり、これらは非常に簡単に並列処理できるため、特にGPUのメリットを受けています。 したがって、GPUでのニューラルネットワークのトレーニングは、CPUでのトレーニングよりも10倍速くなる可能性があります。 ただし、すべてのモデルタイプでその利点が得られるわけではありません。
別の例をご紹介します。
非常に大規模な図書館があり、所蔵するすべての本を数える必要があるとします。 図書館員は、本がどこにあるか、どのように整理されているか、図書館がどのように機能しているかなどについて精通しています。図書館員は自分で本の数を完璧に数えることができ、おそらく整理も非常に上手でしょう。
しかし、図書館員と一緒に本を数えることができる大きなチームがあればどうでしょうか。図書館の専門家ではなく、正確に数えることができる人たちです。
- 本を数える人が3人いる場合、数える速度が速くなります。
- 本を数える人が10人いる場合、数える速度がさらに速くなります。
- 本を数える人が100人いる場合...最高です。
CPUは図書館員のようなものです。図書館を運営する図書館員が必要なように、CPUが必要です。 CPUは基本的に、実行を要するすべてのジョブを実行できます。 図書館員が1人ですべての本を数えることができるように、CPUは機械学習モデルの構築といった数学的処理を行うことができます。
GPUは、本を数える作業を行うチームのようなものです。本を数える作業は、図書館についての特別な専門知識がなくても多くの人ができます。それと同じように、GPUを使えば、ジョブを受け取ってさまざまなユニットに分割し、機械学習モデルを構築するような数学的処理を行うことがはるかに簡単になります。
GPUは通常、特定のタスクをCPUよりもはるかに高速に実行できます。
- 本を数える人のチームの一員である場合、たぶん図書館員が各人に棚1つを割り当てます。 自分の棚の本をカウントします。 同じ時間に、全員が自分の棚の本をカウントします。 次に、全員が集まって、本の数を足し合わせて、図書館内の本の総数を求めます。
このプロセスは並列化と呼ばれ、「大きなジョブを小さなチャンクに分割し、これらの小さなチャンクを同時に実行できること」のしゃれた言い方にすぎません。これらのジョブを「並列で」実行しているため、並列化と言います。隣りの人が本をカウントするのと同時に、自分の本をカウントします。 (並列で実行できないジョブは、通常、順次に実行されます。)
図書館に100の本棚があって、1つの本棚のすべての本をカウントするのに1分かかるとします。
- 図書館員がカウントする唯一の人物である場合、一度に1つの本の山をカウントできるのは1人だけなので、仕事を並行させることができません。 したがって、図書館員がすべての書籍をカウントするには100分かかります。
- 100人のチームでそれぞれが自分の棚をカウントする場合、すべての本が1分でカウントされます。 (ここで、図書館員は、誰がどの棚を担当するかを割り当てるのに少し時間がかかります。 また、100人からのすべての数字を合計するのに少し時間がかかります。 しかし、これらの部分は比較的速いので、図書館全体は、おそらく2〜3分でカウントされます。)
100分ではなく3分です。はるかに優れています!繰り返しになります。GPUは通常、CPUよりもはるかに高速に特定のタスクを実行できます。
GPUが必要ないケースがある
-
本棚が1つしかないとします。 図書館員が100人をシェルフの別々の部分に割り当て、数えて、それらを合計することには、おそらくその価値がありません。 図書館員がすべての書籍を数えればもっと早いかもしれません。
-
データサイエンスジョブを並列化(同時に実行できるような小さなチャンクに分割すること)できない場合には、通常は、GPUは役に立ちません。 幸いなことに、データサイエンスタスクの大部分を並列化できる非常にスマートな人材が何人かいます。
シンプルな数学の例を見てみましょう。数値の集合の平均を計算することです。
CPUで平均を計算した場合、図書館員を使用するようなものです。 CPUはすべての数値を合計してから、サンプルサイズで除算する必要があります。
GPUを活用して平均を計算する場合、チーム全体を使用するのと同じようなものです。 CPUは数値を小さなチャンクに分割してから、各GPUワーカー(コア)はそれらのチャンクの数値を合計します。 次に、CPU(図書館員)は、これらの数値の組み合わせを調整して平均に戻します。
たとえば、10億個の数値の集合の平均を計算する場合、CPUが単独ですべてを実行するよりも、CPUがその10億個をまとまった断片に分割し、個別のGPUワーカーに加算をしてもらうほうが、はるかに高速です。
より複雑な機械学習の例を見てみましょう。ランダムフォレストは、基本的に多数の意思決定木です。 100のディシジョンツリーでランダムフォレストを構築する場合を考えてみます。
-
CPU上にRandom Forestを構築する場合、それは図書館員に自分でカウントをしてもらうようなものです。 CPUは基本的に、最初のツリーを構築してから、2番目のツリー、3番目のツリー、といった順に構築する必要があります。
-
GPUを活用してRandom Forestを構築する場合、それはチーム全体が本をカウントし、図書館員に全員を調整してもらうようなものです。 GPUの一部(コア)が最初のツリーを構築します。 同時に、別のGPUコアが2番目のツリーを構築します。 これはすべて同時に行われます!
図書館員がライブラリ内のあらゆる種類の作業(カウント、整理、フロントの人員配置、書籍の置換)を管理するのと同様に、CPUにはたくさんのさまざまなジョブがあります。 CPU図の緑色のALUボックスは「算術演算装置」を表します。これらのALUは、数学的計算を行うために使用されます。 図書館員が本を数えるのと同じように、CPUは独自にいくつかの数学的計算を行うことができます。ただし、CPUの多くの部屋は、これらの他のボックスによって占められています。CPUでは他の多くの作業も担当しているためです。 単なる数学的計算の問題ではありません。
数える人のチームが1つのジョブ(本をカウントする)を実行するのと同様に、GPUは基本的に数学的計算だけを行うように最適化されます。 数学的な作業になれば、それはずっと強力です。
したがって、要するに、
-
CPUは多くのジョブを実行します。 CPUは独自に数学的計算を行うことができます。
-
GPUは、数学的計算を行うために高度に最適化されています。
-
数学に依存するジョブ(カウント、平均化、機械学習モデルの構築など)がある場合、GPUは一部の数学をCPUよりもはるかに高速に実行できます。 これは、非常にスマートな人たちの発見を利用して並列化できるからです(大きなジョブを小さなチャンクに分割する)。
-
数学に依存しない、または依存度が非常に小さいジョブがある場合、GPUにはおそらくその価値はありません。
もっと例えてみましょう
ここに文字通り、類推に関する動画があります。 具体的には、アナログCPU(デジタルではなく)です。 この動画は非常に興味深く、非常にうまく紹介されており、AI関連のCPUとGPUの使用についての完全な歴史と、次の展開がアナログコンピュータになる理由を説明しています。 視聴する価値が十分にあります!!
CPUが教師で、GPUは小学生でいっぱいのクラスルームとすればどうでしょうか。
場合によっては、教師にグループプロジェクトを支援する方法をクラスに説明してもらうことに価値があります。ただしこれは、学生に理解し聞いてもらえるように各学生と話す方法を、教師に理解してもらうコストに加えて、今や、学生がすべきことをしていることや、その途上で必要な材料を入手していることを確認するために、教師が費やすことになったエネルギーに依存します。 一方、教師は事前にトレーニングを受けており、より複雑なタスクと組織をこなす方法をすでに理解しています。
スキルがなくても熱心な大勢の人の助けで作業を速く進めることができるプロジェクトであれば、GPUを使用する価値があるかもしれません。 しかし、メリットが得られるようになるには、クラスルームの子供たちそれぞれが話す言語と、行う方法について既に何を知っているかを確認する必要があります。 時には、子どもを募集する前に、教師が自分でタスクを行えるようにすることに焦点を合わせる方が、より簡単でより役立ちます。