AWS Athenaを使用したデータの取込み¶
複数のビッグデータ形式により、ストレージと分析用に大量のデータを圧縮するためのさまざまなアプローチが提供されています。これらの形式には、Orc、Parquet、Avroなどがあります。 これらのデータセットを使用してクエリーを実行すると、いくつかの課題を提示できます。 このセクションでは、DataRobotがAWS S3に保存されているApache Parquet形式のデータを取り込む1つの方法を示します。同様の手法が他のクラウド環境にも適用できます。
Parquetの概要¶
Parquetは、オープンソースの列指向データストレージ形式です。 主に圧縮に使用されると誤解されることがよくあります。 さらに、圧縮データを使用すると、圧縮と解凍の両方にCPUコストがかかります。すべてのデータを使用する場合でも、速度の利点はありません。 Snowflakeは10TBのベンチマークデータをロードするためのいくつかのアプローチを紹介する記事でこれに対処しています。
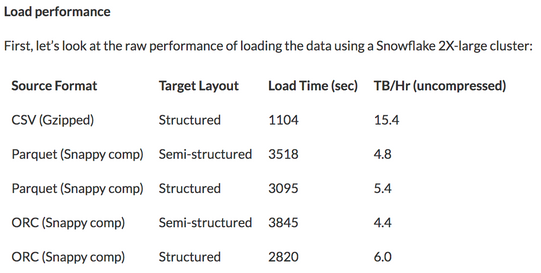
Snowflakeは、単純なCSV形式の場合、完全なデータレコードの負荷がはるかに高くなることを示しています。 Parquetの利点とは
完全なレコードが対象の場合、Columarデータストレージにはほとんどまたはまったく利点がありません。 要求される列が多いほど、それらを読み取って解凍するには、より多くの作業を行う必要があります。 上に表示されている完全なデータの演習は、基本的なCSVファイルのパフォーマンスが非常に高いことを示している理由です。 ただし、データのサブセットの選択には、列指向が実に有益です。 ローンデータセット内の50列のデータのうち、対象データがloan_idである場合、CSVファイルを読み取るにはデータファイルの100%を読み取る必要があります。 ただし、parquetファイルを読み取るには、50列のうち1列だけを読み取ります。 簡単にするために、すべての列がまったく同じスペースを占めると仮定しましょう。つまり、データの2%のみを読み取る必要があるということです。
データを分割することで、読み取りをさらに削減できます。 これを行うには、フィールドのデータ値に基づいてパス構造を作成します。 SQLエンジンのWHERE句がフォルダーパス構造に適用され、その中のParquetファイルを読み取る必要があるかどうかが決定されます。 たとえば、日次ファイルを分割して、ローンデータソースのYYYY/MM/DD構造に格納できます。
loans/2020/1/1/jan1file.parquet
loans/2020/1/2/jan2file.parquet
loans/2020/1/3/jan3file.parquet
この「ハイブスタイル」には、ディレクトリ(パーティション)内のフィールド名が含まれます:
loans/year=2020/month=1/day=1/jan1file.parquet
loans/year=2020/month=1/day=2/jan2file.parquet
loans/year=2020/month=1/day=3/jan3file.parquet
元のプログラムがloan_id、特に2020年1月2日のloan_id値のみが対象の場合、2%の読み取り値はさらに減少します。 均等に分散すると、読み取りおよび解凍操作がデータのわずか0.67%に削減され、その結果、読み取りとデータの戻りが高速になり、データの取得に必要なリソースの請求額が削減されます。
プロジェクト作成用データ¶
このページの例で使用されているデータをGitHubで見つけてください。 このデータセットは、LendingClubからの20,000レコードのローンデータを使用し、AWSコマンドラインインターフェイスを使用してS3にアップロードされました。
aws --profile support s3 ls s3://engineering/athena --recursive | awk '{print $4}'
athena/
athena/ loan_credit /20k_loans_credit_data.csv
athena/ loan_history /year=2015/1/1020de8e664e4584836c3ec603c06786.parquet
athena/loan_history/year=2015/1/448262ad616e4c28b2fbd376284ae203.parquet
athena/loan_history/year=2015/2/5e956232d0d241558028fc893a90627b.parquet
athena/loan_history/year=2015/2/bd7153e175d7432eb5521608aca4fbbc.parquet
athena/loan_history/year=2016/1/d0220d318f8d4cfd9333526a8a1b6054.parquet
athena/loan_history/year=2016/1/de8da11ba02a4092a556ad93938c579b.parquet
athena/loan_history/year=2016/2/b961272f61544701b9780b2da84015d9.parquet
athena/loan_history/year=2016/2/ef93ffa9790c42978fa016ace8e4084d.parquet
20k_loans_credit_data.csvにはすべてのローンのクレジットスコアと履歴が含まれています。 AWS Athena内でいずれかの形式を使用する手順を示すために、ローンは公平なハイブ形式で年月ごとに分割されます。 複数のparquetファイルがYYYY/MM構造内で表され、ローンが作成された異なる日を表す可能性があります。 すべての.parquetファイルは、ローンの申し込みと返済を表します。 このデータはAWS Region US-East-1。 (バージニア北部)のバケットにあります。
AWS Athena¶
AWS AthenaはAWS上のマネージドサービスであり、S3オブジェクトに対してANSI SQLを使用するためのサーバーレスアクセスを提供します。 Apache Prestoを使用し、次のファイル形式を読み取ることができます。
- CSV
- TSV
- JSON
- ORC
- Apache Parquet
- Avro
Athenaは、Snappy、Zlib、LZO、およびGZIP形式の圧縮データもサポートしています。 読み取られたデータ量に基づいて、クエリーごとの支払いモデルで課金されます。 AWSは、通常のテキストファイルとparquetの両方に対してAthenaを使用することに関する記事も提供しており、読み取られたデータの量、クエリーにかかった時間、費やされたコストについて説明します。

AWS Glue¶
AWS Glueは、この例でキャプチャされたワークフローをサポートするExtract Transform Load(ETL)ツールです。 ETLジョブは構築およびスケジュールされません。 Glueを使用して、ホストされたS3バケット上のファイルと構造を検出し、コンテンツに対して高レベルのスキーマを適用して、Athenaがコンテンツの読み取り方法とクエリー方法を理解できるようにします。 Glueはハイブのようなメタストアにコンテンツを格納します。 Hive DDLは明示的に記述できますが、この例では潜在的に異なる多数のファイルを想定し、Glueのクローラーを利用してスキーマを検出し、テーブルを定義します。
AWS Glueはクローラーを作成し、S3バケットをポイントします。 クローラーは、そのデータをAWS Glueデータカタログに出力するように設定され、その後Athenaによって活用されます。 Glueジョブは、AWS S3バケットと同じリージョン(このページの例ではUS-East-1)に作成する必要があります。 以下にこのプロセスの概要を示します。
-
AWSコンソールのAWS Glueサービスでクローラーを追加をクリックし、クローラージョブを追加します。
-
クローラーに名前を付けます。
-
データストアタイプを選択し、対象のバケットを指定します。
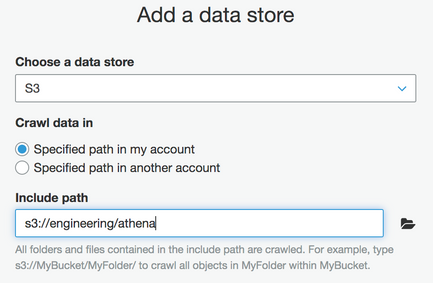
-
クローラーのIdentity and Access Management(IAM)ロールを選択または作成します。 IAMの管理はこの例では対象外ですが、IAM権限の詳細についてはAWSドキュメントを参照してください。

-
オンデマンドで実行する頻度を設定するか、要件を満たすように必要に応じて更新します。
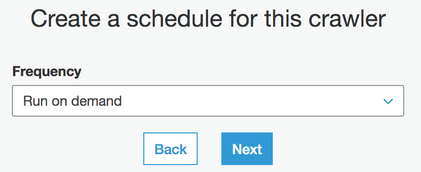
-
クローラーが検出したメタデータを、宛先に書き込む必要があります。 カタログとして機能する新規または既存のデータベースを選択します。
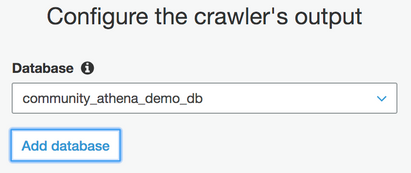
クローラーの作成が完了しました。 デマンドクローラーを今すぐ実行するかどうかを尋ねるプロンプトが表示されます。はいを選択します。 この例では、クローラーがパスの2つのテーブル(
loan_creditとloan_history)を検出して作成したことがわかります。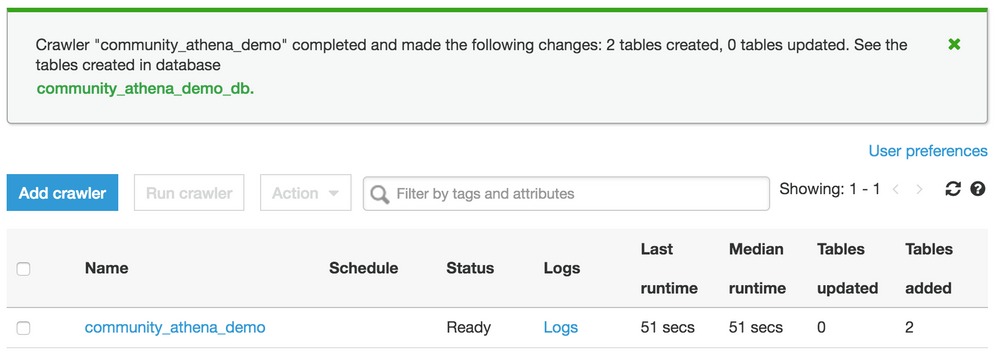
ログには、
loan_historyのテーブルとパーティションの作成が表示されます。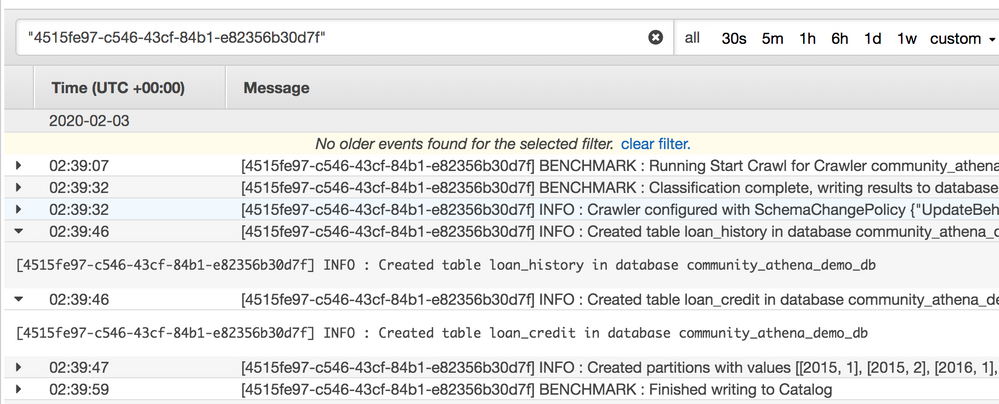
この方法論が適用されない場合に何が起こるかを示すために、年パーティションはHive形式のままにしましたが、月はそうではありません。 Glueはそれに一般的な名前を割り当てます。
-
テーブルに移動して
loan_historyを開きます。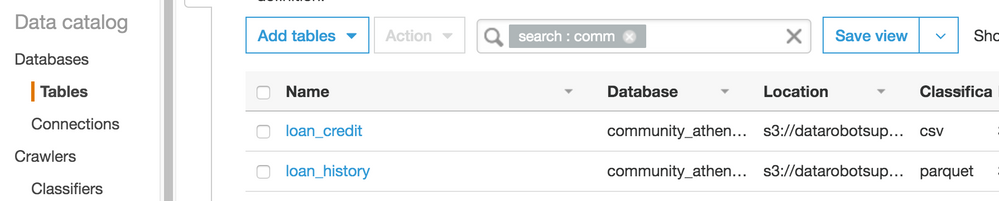
-
スキーマの編集を選択し、列名をクリックしてセカンダリーパーティションの名前を月に変更し、保存します。
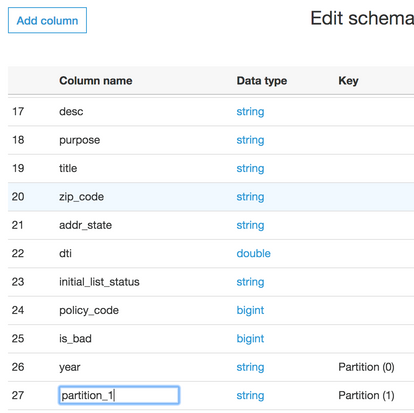
Athenaでのクエリーにこのテーブルを使用できるようになりました。
DataRobotでのプロジェクトの作成¶
このセクションでは、Athenaでクエリーされたデータを使用してプロジェクトを開始するための4つの方法について概説します。 すべてのプログラムメソッドは、これらのDataRobotコミュニティGitHubの例で定義されているように、Python SDKといくつかのヘルパー関数を使用します。
データを指定する方法は次の4つです。
JDBCドライバー¶
JDBCドライバーをインストールし、DataRobotで使用してデータを取り込むことができます(ドライバーのインストールに関するサポートについては、サポートにお問い合わせください。このワークフローでは扱っていません)。 マネージドAIプラットフォームのDataRobot 6.0では、バージョン2.0のJDBCドライバーが利用可能です。 具体的には2.0.5がインストールされ、クラウドで利用できます。 カタログアイテムデータセットは、AIカタログ > 新しいデータを追加に移動し、データ接続 > 新しいデータ接続を追加を選択して構築できます。
この例では、Athena JDBCドライバーの接続を設定し、明示的にアドレスを指定しました。 AwsregionとS3OutputLocation(必須)も指定しました。 設定が完了すると、クエリー結果がCSVファイルとしてこの場所に書き込まれます。
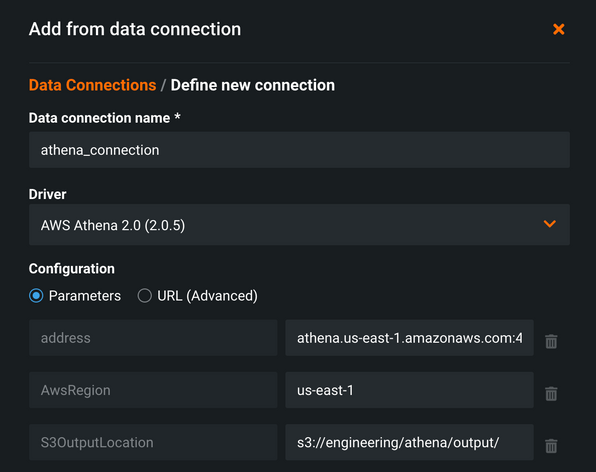
認証は、最後の手順でユーザーとパスワードにAWSAccessKeyとAWSSecretAccessKeyを使用して行われます。 多くの場合、AWSユーザーは、多くのリソースをスピンアップする機能など、多数のサービスにアクセスできるため、ベストプラクティスは、AWS内にクエリー用の特定の権限を持つIAMアカウントを作成してから、AthenaとS3だけを操作します。
データ接続を作成したら、データ接続から新しいデータを追加ウィンドウで選択し、アイテムとプロジェクトの作成に使用します。
SQL結果をローカルで取得する¶
以下のスニペットは、クエリーを送信して、サンプルデータセットからローン履歴の最初の100レコードを取得します。 結果は、Athenaからの結果セットをページ分割してローカルメモリーにロードした後、ディクショナリに返されます。 次に、新規プロジェクトを作成するために、結果をデータフレームにロードし、それを操作して新しい機能を設計し、DataRobotにプッシュします。 s3_out変数は、Athenaの必須パラメーターであり、AthenaがCSVクエリー結果を書き込む場所です。 このファイルは以降の例で使用されます。
athena_client = session.client('athena')
database = 'community_athena_demo_db'
s3_out = 's3://engineering/athena/output/'
query = "select * from loan_history limit 100"
query_results = fetchall_athena_sql(query, athena_client, database, s3_out)
# Convert to dataframe to view and manipulate
df = pd.DataFrame(query_results)
df.head(2)
proj = dr.Project.create(sourcedata=df,
project_name='athena load query')
# Continue work with this project via the DataRobot python package, or work in GUI using the link to the project printed below
print(DR_APP_ENDPOINT[:-7] + 'projects/{}'.format(proj.id))
DataRobotは、小さなデータセットに対してのみこの方法を推奨しています。ページ分割されたクエリー結果にデータをスプールするよりも、単にファイルとしてデータをダウンロードする方が簡単で高速な場合があります。 この方法では、pandasデータフレームを使用して、潜在的なデータ操作と機能エンジニアリングを便利かつ容易にします。データの操作やDataRobotプロジェクトの作成には必要ありません。 さらに、このコードが実行されるマシンには、この例で使用されているデータセットサイズのpandasデータフレームを操作するのに十分なメモリーが必要です。
S3 CSV結果をローカルで取得する¶
以下のスニペットは、上記の方法よりも複雑なクエリーを示しています。 ここでは、すべてのローンをプルし、CSVのクレジット履歴データをParquetのローン履歴データと結合します。 完了すると、S3結果ファイル自体がローカルのPython環境にダウンロードされます。 ここから追加の処理を行うか、またはスニペットで示されているように、新しいプロジェクト用にファイルを直接DataRobotにプッシュできます。
athena_client = session.client('athena')
s3_client = session.client('s3')
database = 'community_athena_demo_db'
s3_out_bucket = 'engineering'
s3_out_path = 'athena/output/'
s3_out = 's3://' + s3_out_bucket + '/' + s3_out_path
local_path = '/Users/mike/Documents/community/'
local_path = !pwd
local_path = local_path[0]
query = "select lh.loan_id, " \
"lh.loan_amnt, lh.term, lh.int_rate, lh.installment, lh.grade, lh.sub_grade, " \
"lh.emp_title, lh.emp_length, lh.home_ownership, lh.annual_inc, lh.verification_status, " \
"lh.pymnt_plan, lh.purpose, lh.title, lh.zip_code, lh.addr_state, lh.dti, " \
"lh.installment / (lh.annual_inc / 12) as mnthly_paymt_to_income_ratio, " \
"lh.is_bad, " \
"lc.delinq_2yrs, lc.earliest_cr_line, lc.inq_last_6mths, lc.mths_since_last_delinq, lc.mths_since_last_record, " \
"lc.open_acc, lc.pub_rec, lc.revol_bal, lc.revol_util, lc.total_acc, lc.mths_since_last_major_derog " \
"from community_athena_demo_db.loan_credit lc " \
"join community_athena_demo_db.loan_history lh on lc.loan_id = lh.loan_id"
s3_file = fetch_athena_file(query, athena_client, database, s3_out, s3_client, local_path)
# get results file from S3
s3_client.download_file(s3_out_bucket, s3_out_path + s3_file, local_path + '/' + s3_file)
proj = dr.Project.create(local_path + '/' + s3_file,
project_name='athena load file')
# further work with project via the python API, or work in GUI (link to project printed below)
print(DR_APP_ENDPOINT[:-7] + 'projects/{}'.format(proj.id))
署名付きURLを持つAWS S3バケット¶
DataRobotでプロジェクトを作成するもう1つの方法は、URL取込みを使用してS3からデータを取り込むことです。 これを行うには、使用するデータ、環境、および設定に基づいていくつかの方法があります。 この例では、クラウド上のプライベートデータセットを活用し、DataRobotで使用する署名付きURLを作成します。
| データセット | DataRobot環境 | アプローチ | 説明 |
|---|---|---|---|
| パブリック | ローカルインストール、クラウド | パブリック | データセットがパブリックバケットにある場合、ファイルオブジェクトへの直接のHTTPリンクを取り込むことができます。 |
| プライベート | ローカルインストール | グローバルIAMロール | DataRobotは、S3への独自のアクセス権限を持つDataRobotサービスアカウントに付与されたIAMロールでインストールできます。渡されたURLは、DataRobotサービスアカウントが参照できるものであれば、データの取込みに使用できます。 |
| プライベート | ローカルインストール | IAMインパーソネーション | DataRobotにユーザーのロールとS3権限を引き継がせることで、よりきめ細かいセキュリティ制御を実装できます。 これにはLDAP認証が必要であり、S3情報を含むLDAPフィールドを利用可能にする必要があります。 |
| プライベート | ローカルインストール、クラウド | 署名付きS3 URL | AWSユーザーは、S3オブジェクトへの署名付きURLを作成して、指定された時間が経過すると期限切れになる一時的なリンクを提供できます。 |
以下のスニペットは、S3 CSVの結果をローカルで取得する方法で示された作業に基づいています。 ファイルをローカル環境にダウンロードするのではなく、AWS認証情報を使用してURLに署名し、一時的に使用できます。 応答変数には、結果ファイルへのリンクが含まれており、認証文字列は3600秒間有効です。 URL文字列全体を持つユーザーは誰でも、要求された期間中ファイルにアクセスできます。 このように、結果をローカルにダウンロードするのではなく、URL値を参照してDataRobotプロジェクトを開始できます。
response = s3_client.generate_presigned_url('get_object',
Params={'Bucket': s3_out_bucket,
'Key': s3_out_path + s3_file},
ExpiresIn=3600)
proj = dr.Project.create(response,
project_name='athena signed url')
# further work with project via the python API, or work in GUI (link to project printed below)
print(DR_APP_ENDPOINT[:-7] + 'projects/{}'.format(proj.id))
ヘルパー関数と完全なコードは、DataRobotコミュニティGitHubリポジトリで入手できます。
まとめ¶
上記の方法のいずれかを使用した後、データをDataRobotに取り込む必要があります。 AWS AthenaとApache Prestoは、さまざまなデータソースに対してSQLを有効にして、データの取込みに使用できる結果を生成します。 同様のアプローチを使用して、AzureおよびGoogle Cloudサービスでもこのタイプの入力データを処理できます。