リアルタイム予測¶
データが取り込まれると、DataRobotはモデルデータのスコアリングのためにいくつかのオプションを提供します。 最も緊密に連携され、機能豊富なスコアリング方法は、予測APIを使用することです。 APIを活用して水平方向にスケーリングすることで、リアルタイムのスコアリングリクエストとバッチスコアリングの両方をサポートできます。 1つ以上のレコードのデータペイロードで1つのAPIリクエストを送信できます。また、多数のリクエストを同時に送信することもできます。 DataRobotは、スコアリングリクエストのために入ってくるデータを追跡し、モデルの構築にも使用するトレーニングデータと比較します。 モデル管理を使用すると、APIエンドポイントに関する技術的なパフォーマンス統計が、データドリフトおよびモデルドリフト(モデル自体の状態に関連)とともに提供されます。 詳細については、DataRobot予測APIドキュメントを参照してください。
成功するAPIリクエストを構築するために必要な情報は、DataRobot内のいくつかの場所から収集できますが、必要なすべての値を取得する最も簡単な方法は、予測 > 予測APIタブから行います。 このタブでは関連するフィールドが完成したサンプルのPythonスクリプトを利用できます。
APIエンドポイントは、CSVおよびJSONデータを受け入れます。 コンテンツタイプのヘッダー値は、送信されるデータのタイプ(text/csvまたはapplication/json)に合わせて適切に設定する必要があります。元のAPIリクエストは常にJSONで応答します。 リアルタイム予測でJSONの代わりにCSVを返すには、-H "Accept: text/csv"を使用します。
以下では、ローカルまたはスタンディングサーバー環境の両方からのクライアントリクエストを介して、Snowflakeからデータをスコアリングする例をいくつか紹介します。
予測APIの使用¶
次の連携スクリプトの値をメモしてください。
API_KEY = 'YOUR API KEY'
DEPLOYMENT_ID = 'YOUR DEPLOYMENT ID'
DATAROBOT_KEY = 'YOUR DR KEY'
連携スクリプトのフィールドは次のとおりです。
| フィールド | 説明 |
|---|---|
USERNAME |
指定ユーザーに関連付けられた特権を適用します。 |
API_KEY |
DataRobot APIおよび予測APIへのウェブリクエストを認証します。 |
DEPLOYMENT_ID |
DataRobotデプロイの一意のIDを指定します。この値はモデルの前にあります。 |
DATAROBOT_KEY |
(マネージドAIプラットフォームのユーザーのみ) 追加のエンジンアクセスキーを指定します。 セルフマネージドAIプラットフォームでは、このオプションを削除できます。 |
DR_PREDICTION_HOST |
(セルフマネージドAIプラットフォームのユーザーのみ) ローカルにインストールされたクラスターにアプリケーションホストを提供します。 (マネージドAIプラットフォームのユーザーの場合、ホストのデフォルトはapp.datarobot.comまたはapp.eu.datarobot.comです。) |
Content-Type |
headersで、送信される入力データのタイプ(CSVまたはJSON)を特定します。 |
URL |
スコアリングデータのホスト名を特定します。 通常、これは1つ以上の予測エンジンの前にあるロードバランサーです。 |
次のスクリプトスニペットは、SnowflakeからPythonコネクター経由でデータを抽出し、DataRobotに送信してスコアリングを行う方法を示しています。 1つのリクエストで単一のスレッドを作成します。 速度を最大化するには、適切なサイズのデータペイロードで並列リクエストスレッドを作成し、あらゆるサイズの入力を処理する必要があります。
スコアリングリクエストを作成し、結果を操作する基本的な例を考えてみましょう。
import snowflake.connector
import datetime
import sys
import pandas as pd
import requests
from pandas.io.json import json_normalize
# snowflake parameters
SNOW_ACCOUNT = 'dp12345.us-east-1'
SNOW_USER = 'your user'
SNOW_PASS = 'your pass'
SNOW_DB = 'TITANIC'
SNOW_SCHEMA = 'PUBLIC'
# create a connection
ctx = snowflake.connector.connect(
user=SNOW_USER,
password=SNOW_PASS,
account=SNOW_ACCOUNT,
database=SNOW_DB,
schema=SNOW_SCHEMA,
protocol='https',
application='DATAROBOT',
)
# create a cursor
cur = ctx.cursor()
# execute sql
sql = "select passengerid, pclass, name, sex, age, sibsp, parch, fare, cabin, embarked " \
+ " from titanic.public.passengers"
cur.execute(sql)
# fetch results into dataframe
df = cur.fetch_pandas_all()
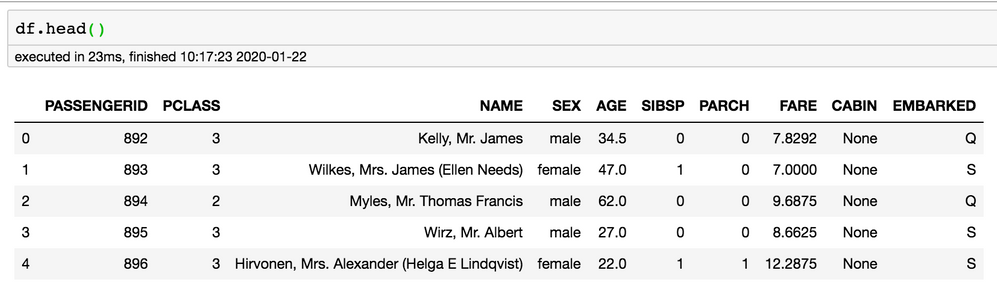
フィールドは、ANSI標準SQLに従ってすべて大文字になります。 DataRobotでは特徴量名の大文字と小文字が区別されるため、DataRobotのフィールドが指定されたデータと一致していることを確認してください。 使用するモデル構築ワークフローによっては、SQLを介したデータベース抽出では、モデル特徴量の大文字と小文字を一致させるために列のエイリアスが必要になる場合があります。 この時点で、データはPythonスクリプトになっています。 モデル構築前にDataRobotの外部で行われた前処理をスコアリングに適用できるようになりました。 データの準備ができたら、モデルのスコアリングを開始できます。
# datarobot parameters
API_KEY = 'YOUR API KEY'
USERNAME = 'mike.t@datarobot.com'
DEPLOYMENT_ID = 'YOUR DEPLOYMENT ID'
DATAROBOT_KEY = 'YOUR DR KEY'
# replace with the load balancer for your prediction instance(s)
DR_PREDICTION_HOST = 'https://app.datarobot.com'
# replace app.datarobot.com with application host of your cluster if installed locally
headers = {
'Content-Type': 'text/csv; charset=UTF-8',
'Datarobot-Key': DATAROBOT_KEY,
'Authorization': 'Bearer {}'.format(API_KEY)
}
predictions_response = requests.post(
url,
data=df.to_csv(index=False).encode("utf-8"),
headers=headers,
params={'passthroughColumns' : 'PASSENGERID'}
)
if predictions_response.status_code != 200:
print("error {status_code}: {content}".format(status_code=predictions_response.status_code, content=predictions_response.content))
sys.exit(-1)
# first 3 records json structure
predictions_response.json()['data'][0:3]

上記は基本的で単純な呼び出しで、エラー処理はほとんどありません(あくまでも一例です)。 リクエストには、返されるデータの論理キーまたはビジネスキーを要求するパラメーター値と、ラベルおよびスコアが含まれます。 出力からインデックス列を削除するためにdf.to_csv(index=False)が必要であり、Unicode文字列をUTF-8バイト(Content-Typeで指定された文字セット)に変換するには.encode("utf-8")が必要であることに注意してください。
APIは常にレコードをJSON形式で返します。 SnowflakeはJSONを柔軟に処理できるため、応答をデータベースにロードするだけで済みます。
df_response = pd.DataFrame.from_dict(predictions_response.json())
df_response.head()
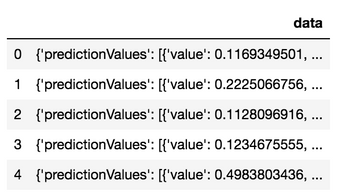
次のコードは、テーブルを作成し、元のJSONを挿入します。 これは、短縮された5つのレコードのセットでのみ行われます。 このデモンストレーション用に、Python Snowflakeコネクターからレコードが一度に1つずつ挿入されています。 これはベストプラクティスではなく、デモ用にのみ提供されています。これを自分で行う場合は、代わりにSnowflakeを使用して、フラットファイルとステージオブジェクトからデータを取り込むようにしてください。
ctx.cursor().execute('create or replace table passenger_scored_json(json_rec variant)')
df_head = df_response.head()
# this is not the proper way to insert data into snowflake, but is used for quick demo convenience.
# snowflake ingest should be done via snowflake stage objects.
for _ind_, row in df5.iterrows():
escaped = str(row['data']).replace("'", "''")
ctx.cursor().execute("insert into passenger_scored_json select parse_json('{rec}')".format(rec=escaped))
print(row['data'])
SnowflakeのネイティブJSON関数を使用して、データを解析およびフラット化します。 以下のコードは、二値分類モデルから生存に対する、正のクラスラベル1向けにすべてのスコアを取得します。
select json_rec:passthroughValues.PASSENGERID::int as passengerid
, json_rec:prediction::int as prediction
, json_rec:predictionThreshold::numeric(10,9) as prediction_threshold
, f.value:label as prediction_label
, f.value:value as prediction_score
from titanic.public.passenger_scored_json
, table(flatten(json_rec:predictionValues)) f
where f.value:label = 1;
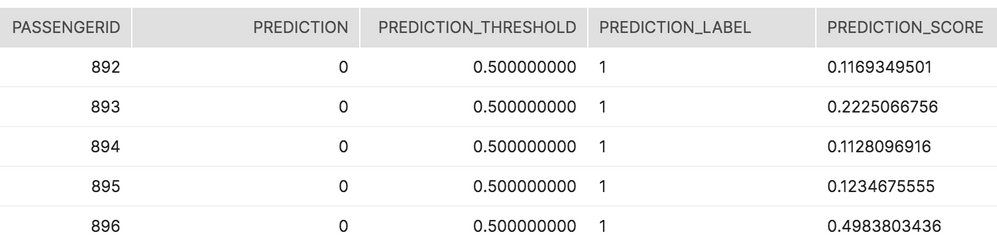
元のスコアとそれが提供する出力をしきい値に照らして使用できます。 この例では、乗客892人の生存率(11.69%)は50%のしきい値よりも低くなりました。 その結果、正のクラスの生存ラベル1に対する予測は0(つまり、生存していない)でした。
Pythonの元の応答は、Python内でもフラット化できます。
df_results = json_normalize(data=predictions_response.json()['data'], record_path='predictionValues',
meta = [['passthroughValues', 'PASSENGERID'], 'prediction', 'predictionThreshold'])
df_results = df_results[df_results['label'] == 1]
df_results.rename(columns={"passthroughValues.PASSENGERID": "PASSENGERID"}, inplace=True)
df_results.head()
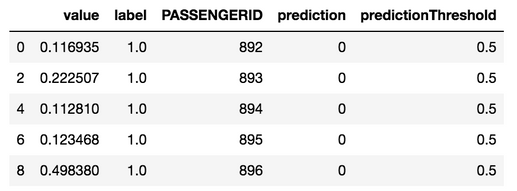
上記のデータフレームは、1つ以上のCSVに書き込むか、データベースに取り込むためにSnowflakeステージ環境で圧縮ファイルとして提供できます。