ベクターデータベース¶
ベクターデータベース(VDB)は、チャンクごとに生成された埋め込みを使用してチャンクに分割された、非構造化テキストのコレクションです。 チャンクと埋め込みの両方がデータベースに保存され、取得できます。 VDBをオプションとして使用して、LLMレスポンスを特定の情報に基づかせ、 RAG操作中に活用のためにLLMブループリントに割り当てることができます。
VDBを操作するためのシンプルなワークフローは次のとおりです。
DataRobot GenAI機能を使用する際のガイダンスについては、 ベクターデータベースに関する注意事項を参照してください。
データを追加¶
GenAIは2つのタイプのVDBをサポートします。
- ローカル。「社内」構築されたVDB。
DataRobotとして識別され、データレジストリに保存されています。 - 外部。検定と登録のためにモデルワークショップでホストされ、ユースケースディレクトリリストでは
Externalとして識別されます。
データセットの要件¶
ベクターデータベースを作成するためにデータセットをアップロードする場合、サポートされている形式は.zipのみです。 DataRobotは.zipを処理して、リファレンスID(ファイルパス)列が関連付けられたテキスト列を含む.csvを作成します。 リファレンスID列は、.zipがアップロードされると自動的に作成されます。 すべてのファイルは、アーカイブのルート(root)、またはアーカイブ内の単一のフォルダーに配置する必要があります。 フォルダーツリー階層の使用はサポートされていません。
サポートされているファイルコンテンツの詳細については、 注意事項を参照してください。
内部VDB¶
DataRobotの内部VDBは、取得速度を維持しながら、許容可能な取得精度を確保するために最適化されています。 内部VDBにデータを追加するには:
-
ナレッジソースを構成するファイルを単一の
.zipファイルに圧縮して、データを準備します。 ファイルを選択して、すべてのファイルを保持するフォルダーをzipまたは圧縮できます。 -
.zipアーカイブをアップロードします。 アップロードは、次のいずれかの方法で行うことができます。-
ローカルファイルまたはデータ接続からの ワークベンチユースケース。
-
ローカルファイル、HDFS、URL、JDBCデータソースからの AIカタログ。 DataRobotはファイルを
.csv形式に変換します。 登録したら、プロフィールタブを使用してデータを確認できます。
-
DataRobotでデータが利用可能になったら、それをプレイグラウンドで使用する ベクターデータベースとして追加できます。
外部VDB¶
外部"bring-your-own"(BYO)VDBは、独自のモデルとデータソースを使用して、カスタムモデルデプロイをLLMブループリントのベクターデータベースとして活用する機能があります。 外部VDBの使用はUI経由で行うことはできません。DataRobotのPythonクライアントを使用して外部ベクターデータベースを作成する手順を説明した ノートブックを確認してください。
外部VDBの主な機能¶
-
カスタムモデルの統合:独自のカスタムモデルをベクターデータベースとして組み込み、高い柔軟性とカスタマイズを可能にします。
-
入力および出力形式の互換性:外部BYO VDBは、LLMブループリントとのシームレスな連携を確保するために、指定された入力および出力形式に準拠する必要があります。
-
検定と登録:カスタムモデルデプロイは、外部ベクターデータベースとして登録する前に、必要な要件を満たすように検定する必要があります。
-
LLMブループリントとのシームレスな統合:登録されると、外部VDBをローカルベクターデータベースと同様にLLMブループリントで使用できます。
-
エラー処理と更新:この機能では、エラー処理と更新機能を使用して、LLMブループリントを再検定または 複製を作成して、カスタムモデルデプロイの問題や変更に対処できます。
基本的な外部ワークフロー¶
このノートブックで詳しく説明されている基本的なワークフローは次のとおりです。
- APIを介してベクターデータベースを作成します。
- カスタムモデルデプロイを作成して、VDBをDataRobotに取り込みます。
- デプロイが登録されたら、ノートブックでのベクターデータベース作成の一部としてデプロイにリンクします。
VDBの追加¶
ユースケース内からVDBを追加する方法は4つあります。
備考
データセットはユースケースのリストでグレー表示される場合がありますが、ベクターデータベースの基準として引き続き使用できます。 ただし、プレビュー用にデータベースを選択することはできません。
-
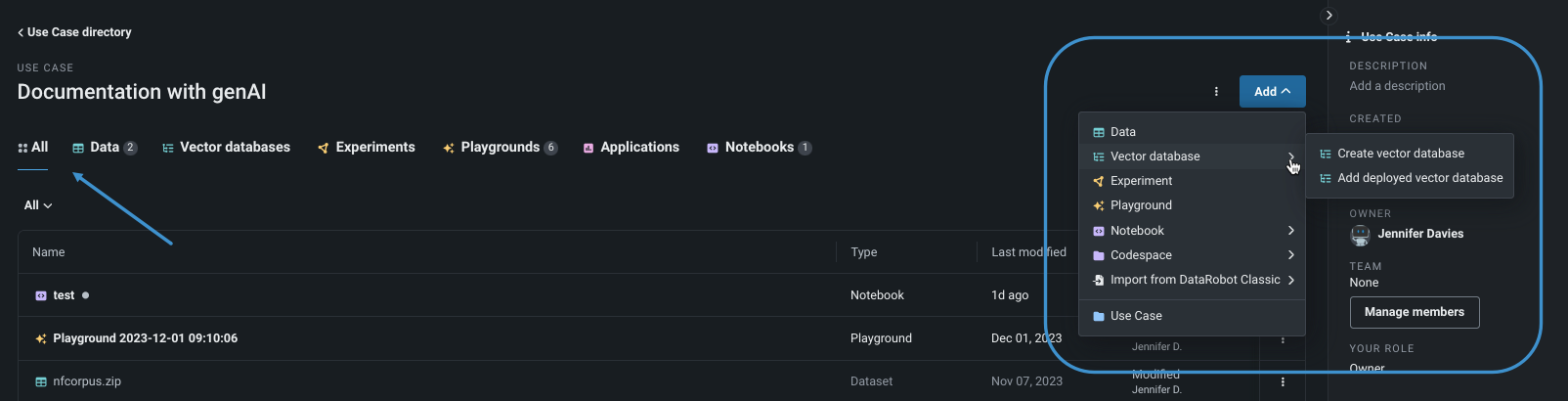
ユースケースのホームにあるすべてタブから、追加ドロップダウンをクリックします。
- AIカタログのデータからVDBを作成するには、ベクターデータベースを作成を選択します。
- LLMプロンプティング中に使用されるベクターデータベースを含むデプロイを追加するには、デプロイ済みベクターデータベースを追加を選択します。
-
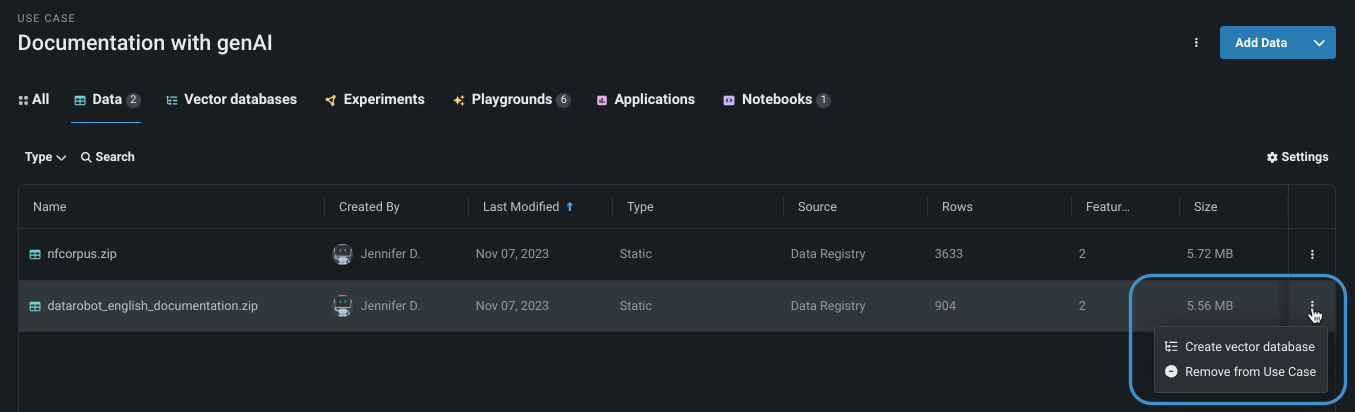
データタブから、追加ドロップダウンを使用するか、アクションメニュー をクリックして、ベクターデータベースを作成を選択します。 この方法は、設定 > データソースフィールドにデータベースをロードします。
-
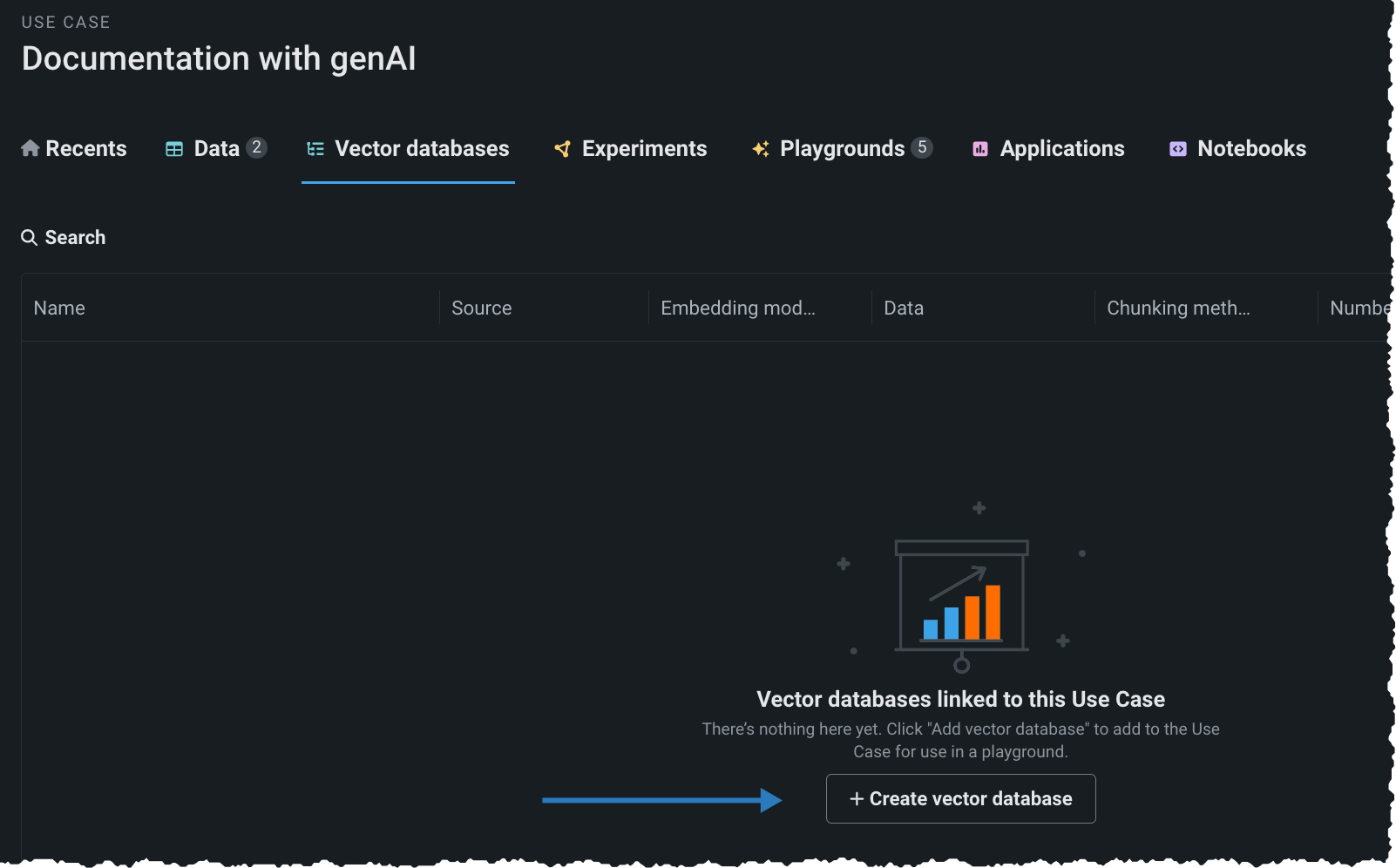
ベクターデータベースタブから、ベクターデータベースを作成をクリックします。
-
LLMブループリントの設定 > ベクターデータベースタブから、ドロップダウンを使用します。
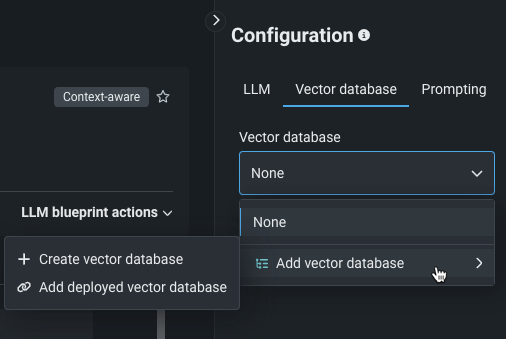
VDBの設定¶
VDBを作成するときは、 基本設定を行い テキストチャンキングを設定します。
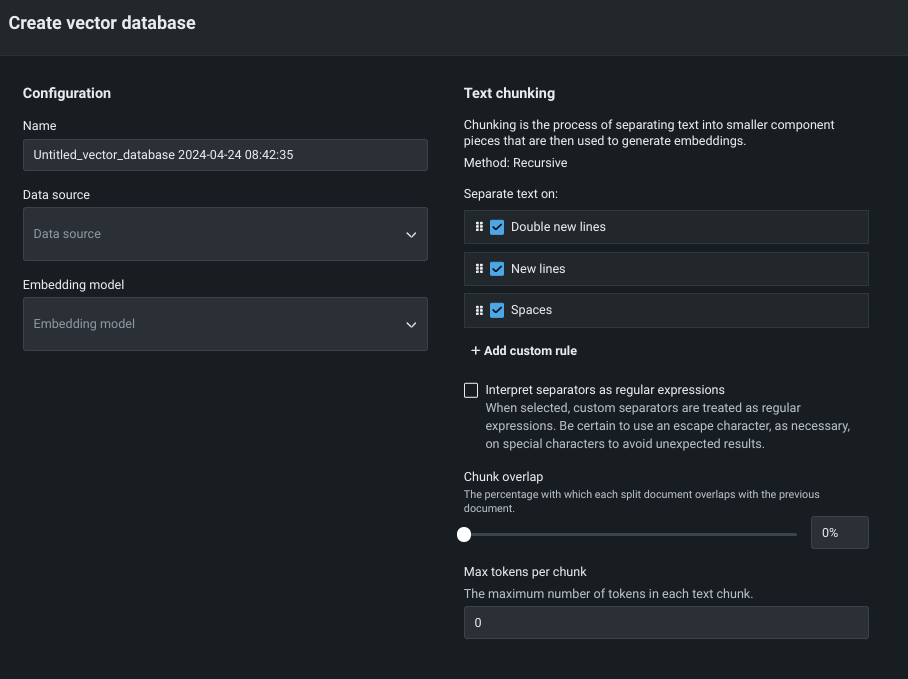
VDBの設定¶
次の表は、VDB作成の設定セクションの各設定を示します。
| フィールド | 説明 |
|---|---|
| 名前 | VDBが保存される名前。 この名前はユースケースベクターデータベースタブに表示され、プレイグラウンドを設定するときに選択できます。 |
| データソース | VDBのナレッジソースとして使用されるデータセット。 リストは、ユースケースベクターデータベースタブのエントリーに基づいて入力されます。 データタブのアクションメニューからVDBの作成を開始した場合、フィールドにはそのデータセットが自動入力されます。 |
| 埋め込みモデル | データのエンコーディングに使用される埋め込みのタイプを定義するモデル。 以下で説明されています。 |
埋め込み¶
GenAIの埋め込みは SentenceBERTフレームワークに基づいており、文章と段落の密ベクトル表現を簡単に計算できます。 モデルは、トランスフォーマーネットワーク(BERT、RoberTA、T5)に基づいており、さまざまなタスクで最先端のパフォーマンスを実現します。 テキストはベクトル空間に埋め込まれているため、類似したテキストがより近くなり、コサイン類似度を使用して効率的に見つけることができます。
GenAIは、データをエンコーディングするための5つのタイプの埋め込みをサポートしています。
-
_jinaai/jina-embedding-t-en-v1_:Jina AIのLinnaeus-Cleanデータセットを使用してトレーニングされた小さな言語モデル。 これは英語のコーパスで事前トレーニングされており、DataRobotのGenAIによって提供される最速の埋め込みモデルです。 データセットが英語で検出された場合に推奨されます。 -
_sentence-transformers/all-MiniLM-L6-v2_:10億個のセンテンスペアのデータセットでファインチューニングされた小さな言語モデル。 比較的高速で、英語のコーパスで事前トレーニングされています。 -
_intfloat/e5-base-v2_:Microsoft Researchの中規模の言語モデル(「大規模英語コーパスでの弱教師あり対照事前トレーニング」)。 -
_intfloat/e5-large-v2_:Microsoft Researchの大規模の言語モデル(「大規模英語コーパスでの弱教師あり対照事前トレーニング」)。 -
cl-nagoya/sup-simcse-ja-base::名古屋大学 大学院情報学研究科(「Japanese SimCSE Technical Report」)による中規模言語モデル。 データセット言語が日本語として検出される場合に推奨されます。 -
_huggingface.co/intfloat/multilingual-e5-base_:Microsoft Researchの中規模の言語モデル(「大規模複数言語コーパスでの弱教師あり対照事前トレーニング」)。 モデルは100の言語をサポートしています。 データセットが英語以外の言語として検出された場合に推奨されます。多言語サポート
対応言語:
"アフリカーンス語", "アムハラ語", "アラビア語", "アッサム語", "アゼルバイジャン語", "ベラルーシ語", "ブルガリア語", "ベンガル語", "ブルトン語", "ボスニア語", "カタルーニャ語", "チェコ語", "ウェールズ語", "デンマーク語", "ドイツ人語", "ギリシャ語", "英語", "エスペラント語", "スペイン語", "エストニア語", "バスク語", "ペルシャ語", "フィンランド語", "フランス語", "西フリジア語", "アイルランド語", "スコットランドのゲール語", "ガリシア語", "グジャラート語", "ハウサ語", "ヘブライ語", "ヒンディー語", "クロアチア語", "ハンガリー語", "アルメニア語", "インドネシア語", "アイスランド語", "イタリア語", "日本語", "ジャワ語", "ジョージア語", "カザフ語", "クメール語", "カンナダ語", "韓国語", "クルド語", "キルギス語", "ラテン語", "ラオス語", "リトアニア語", "ラトビア語", "マダガスカル語", "マケドニア語", "マラヤーラム語", "モンゴル語", "マラーティー語", "マレー語", "ビルマ語", "ネパール語", "オランダ語", "ノルウェー語", "オロモ語", "オリヤ語", "パンジャブ語", "ポーランド語", "パシュトゥー語", "ポルトガル語", "ルーマニア語", "ロシア語", "サンスクリット語", "シンド語", "シンハラ語", "スロバキア語", "スロベニア語", "ソマリ語", "アルバニア語", "セルビア語", "スンダ語", "スウェーデン語", "スワヒリ語", "タミル語", "テルグ語", "タイ語", "タガログ語", "トルコ語", "ウイグル語", "ウクライナ語", "ウルドゥー語", "ウズベク語", "ベトナム語", "コサ語", "イディッシュ語", "中国語",
チャンク設定¶
テキストチャンクは、テキストドキュメントを小さなテキストチャンクに分割するプロセスで、 埋め込みの生成に使用されます。 チャンク区切り文字とチャンク設定には、2つの要素があります。
区切り文字の操作¶
区切り文字は、テキストを分割するための「ルール」または検索パターン(サポート可能ですが正規表現ではありません)です。各区切り文字は、テキストをより小さなコンポーネントに分割するために、順番に適用されます。区切り文字は、ドキュメントをチャンクに分割するためのトークンを定義します。 チャンクはトピックごとにグループ化するのに十分な大きさで、サイズ制約はモデルの設定によって決定されます。 再帰的なテキストチャンクは、チャンクルールに適用される方法です。
再帰的チャンクとは?
再帰的テキストチャンクは、テキストチャンクの長さが指定された最大チャンクサイズ未満になるまで、テキスト区切り文字の順序付けられたリストに従ってテキストドキュメントを再帰的に分割することによって機能します。 生成されたチャンクの長さ/サイズが既に最大チャンクサイズよりも小さい場合、以降の区切り文字は無視されます。 それ以外の場合、DataRobotは、チャンクの長さ/サイズが最大チャンクサイズよりも小さくなるまで、区切り文字のリストを順番に適用します。 最終的に、生成されたチャンクが指定された長さよりも大きい場合、破棄されます。 その場合、DataRobotは「各文字を分離」戦略を使用して各文字で分割し、連続する分割文字のチャンクを最大チャンクサイズ制限のところに来るまでマージします。 「文字で分割」が区切り文字としてリストされていない場合、長いチャンクは切り取られます。 つまり、テキストの一部は埋め込みの生成で欠損しますが、チャンク全体は引き続きドキュメントの取得に使用できます。
各VDBは、テキストを分割する内容を定義する4つのデフォルトルールから始まります。
- 二重改行
- 改行
- スペース
これらのルールは、理解しやすいように単語で識別されますが、バックエンドでは個々の文字列として解釈されます(つまり、\n\n, \n, " ", "")。
ドキュメントに区切り文字が存在しない場合や、目的のチャンクサイズに分割するための十分なコンテンツがない場合があります。 その場合、DataRobotは「next-best character」(次にベストな文字)フォールバックルールを適用し、チャンクが定義されたチャンクサイズに適合するまで、次のチャンクに文字を移動します。 そうでない場合、埋め込みモデルは、継承されたコンテキストサイズを超えるチャンクを切り捨てます。
カスタムルールを追加¶
最大5つのカスタム区切り文字を追加して、チャンク戦略の一部として適用できます。 これにより、合計9つの区切り文字が使用できます(4つのデフォルトを一緒に考慮した場合)。 カスタム区切り文字には、以下が適用されます。
- 各区切り文字の最大文字数は20文字です。
-
区切り文字として単語を使用できる「変換ロジック」はありません。 たとえば、句読点を分割する場合は、各タイプに区切り文字を追加する必要があります。
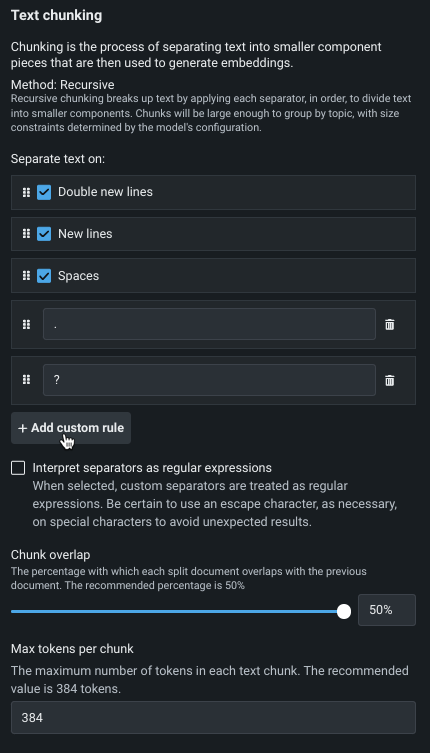
-
区切り文字の順序は重要です。 区切り文字を並べ替えるには、セルをクリックして目的の場所にドラッグします。
-
チャンク戦略のファインチューニングや区切り文字追加のための空き容量調整などで区切り文字を削除するには、ごみ箱アイコンをクリックします。 デフォルトの区切り文字は削除できません。
正規表現の使用¶
区切り文字に正規表現を使用できるようにするには、セパレーターを正規表現として解釈を選択します。 この機能をアクティブにすると、すべての区切り文字が正規表現として扱われることを理解するのが重要です。 例えば、「.」を追加すると、各文字に一致して分割されることを意味します。 リテラルの「dots」で分割する場合は、記号(「\.」など)を付けてエスケープする必要があります。 このルールは、カスタム区切り文字と(この方法で動作するよう設定されている)事前定義済みの両方の区切り文字に適用されます。
チャンクパラメーター¶
チャンクパラメーターは、VDBの出力をさらに定義します。 チャンクパラメーターのデフォルト値は、埋め込みモデルによって異なります。
チャンクのオーバーラップ¶
オーバーラップとは、隣接するチャンクがある程度のデータを共有できるようにする方法を指します。 チャンクオーバーラップパラメーターは、連続するチャンク間のトークンの重複割合(パーセント)を指定します。 重複は、言語モデルでテキストを処理するときにチャンク間のコンテキストの連続性を維持するのに役立ちますが、より多くのチャンクを生成しベクターデータベースのサイズを増やすという代償があります。
チャンクあたりの最大トークン数¶
チャンクあたりの最大トークン数(チャンクサイズ)は以下を指定します。
- ベクターデータベースを構築するときにデータセットから抽出された各テキストチャンクの最大サイズ(トークン単位)。
- 埋め込みの作成に使用されるテキストの長さ。
- RAG操作で使用される引用のサイズ。
VDBの保存¶
設定が完了したら、ベクターデータベースを作成をクリックして、データベースを プレイグラウンドで使用可能にします。
ユースケースに関連付けられたすべてのVDBは、ユースケース内のベクターデータベースタブから表示できます。 外部VDBの場合、ソースタイプのみを表示できます。DataRobotによって管理されていないため、他のデータはレポートに使用できません。