モデルのインサイトを表示¶
プレビュー
Support for Feature Impact on a registered model's Insights tab is a preview feature, on by default. 特徴量のインパクトの計算は、ターゲットタイプが二値分類か連続値のDataRobotモデルとカスタムモデルで可能です。
機能フラグ:NextGenでカスタムモデルに対してSHAPを有効にする
DataRobotモデルとカスタムモデル(エージェントで監視される外部モデルではありません)で利用できる特徴量のインパクトでは、モデルの決定を最も強力に推進している特徴量を識別する概要レベルの視覚化が提供されます。 以下の情報が表示されます。
-
最も有用性の高い特徴量(人口統計データ、取引データ、またはモデルの結果を左右する他のデータ)。業界の専門家のナレッジとのすり合わせ。結果をモデル化するために重要な機能を理解することで、モデルがビジネスルールに準拠しているかどうかをより簡単に検証できます。
-
モデルを改善する機会の有無。たとえば、負の精度を持つ特徴量がある場合があります。 新しい特徴量セットを作成することで、そのような特徴量を削除すると、モデルの精度と速度が向上することがあります。 一部の特徴量は、有用性が予想外に低い可能性があるので調査する価値があります。データに問題があるかどうか。 データ型が正しく定義されているかどうか。
特徴量のインパクトのインサイトにアクセスするには、レジストリ > モデルディレクトリで登録モデルのバージョンを開き、インサイトタブをクリックします。 次に、特徴量のインパクトパネルを開き、 計算するをクリックします。
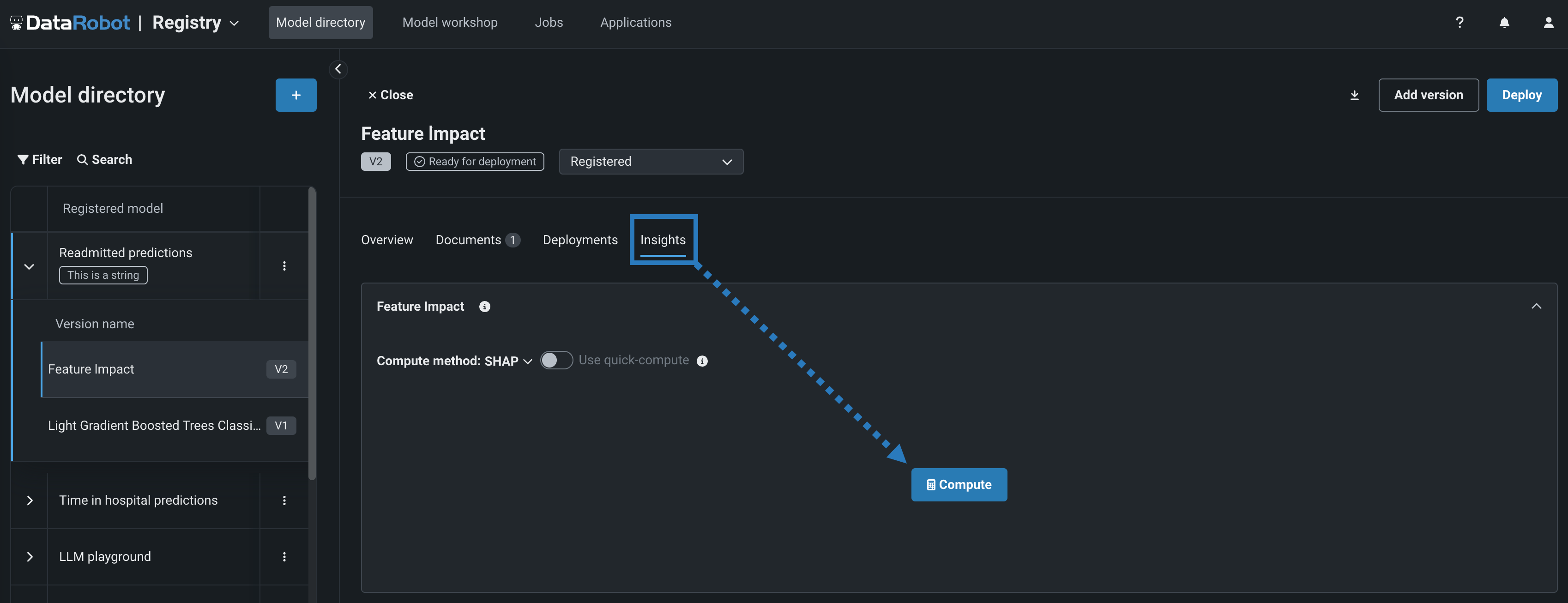
カスタムモデルの場合、登録モデルのバージョンは、モデルの構築時に割り当てられたトレーニングデータが含まれている必要があります。 トレーニングデータがカスタムモデルの登録モデルバージョンに割り当てられていない場合は、通知が表示され、モデルワークショップに移動して新しいカスタムモデルバージョンを作成し、トレーニングデータセットを割り当てて、新しい登録モデルバージョンを作成するように指示されます。
特徴量のインパクトのチャートをコントロール¶
登録モデルのバージョンについて特徴量のインパクトを計算した後、提供されているコントロールを使って表示を変更できます。
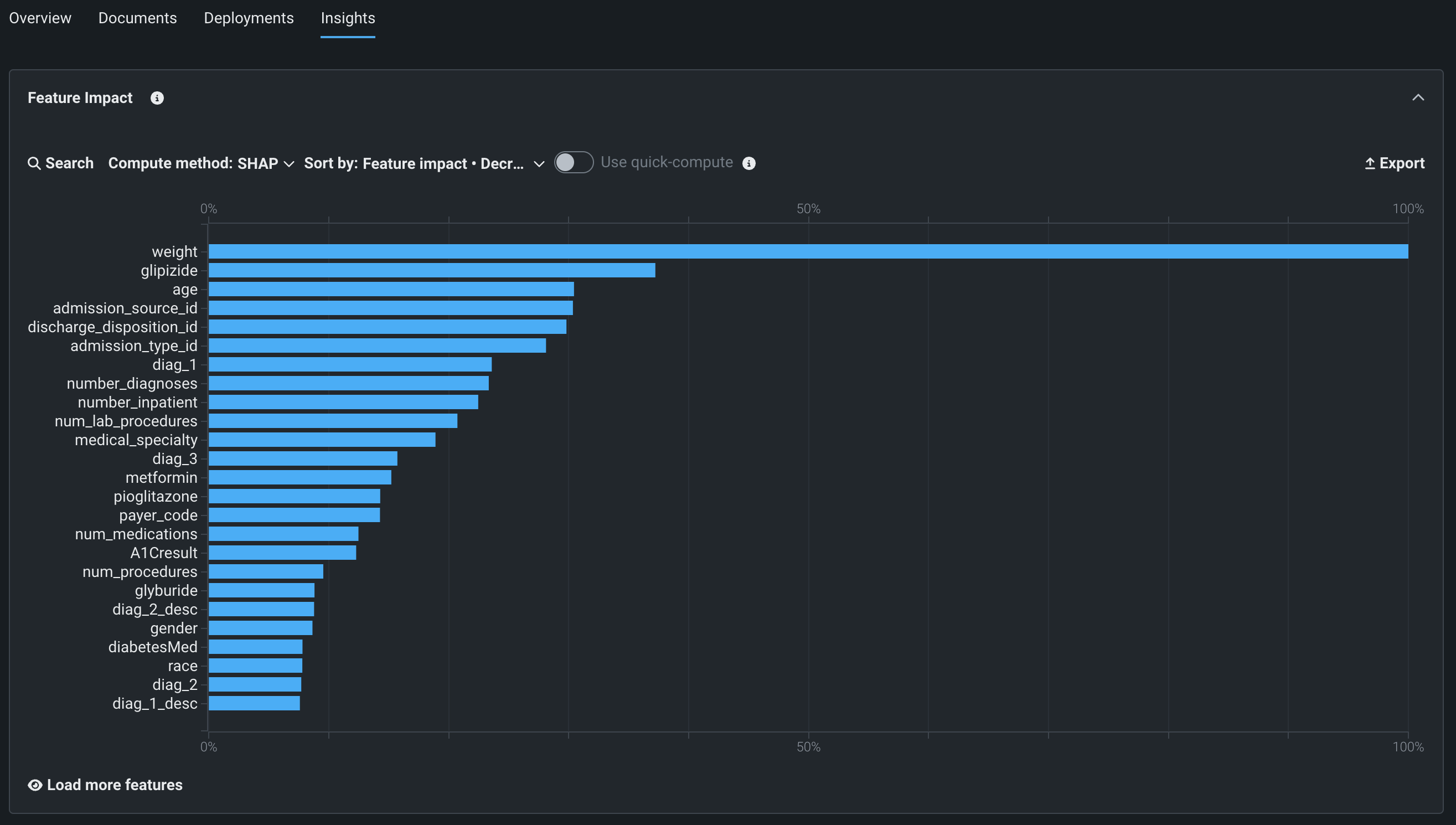
| オプション | 説明 |
|---|---|
| 検索 | チャートを更新して、検索文字列に一致する特徴量のみを含めます。 |
| 計算方法 | インサイトの基盤となる計算方法(SHAPまたはPermutation)を選択します。 これはオンデマンド機能です。つまり、結果を表示するには、モデルごとに計算を開始する必要があります。 |
| ソート条件 | ソート方法(インパクト(有用性)または名前のアルファベット順)とソート順を設定します。 デフォルトは、インパクトの降順なので、最もインパクトの大きい特徴量が最初に表示されます。 |
| クイックコンピューティングを使用する | チャートで使用するサンプルサイズを制御します。 |
| エクスポート | 各特徴量とその相対的な有用性を含むCSV、チャートのPNG、またはその両方を含むZIPファイルをエクスポートします。 |
| さらに特徴量をロード | チャートを展開してエクスペリメントで使用されたすべての特徴量を表示し、クリックするたびに25の特徴量がロードされます。 デフォルトでは、最もインパクトの高い上位25個の特徴量がチャートに表示されます。 インサイトを閉じると、上位25位までの表示がリセットされます。 |
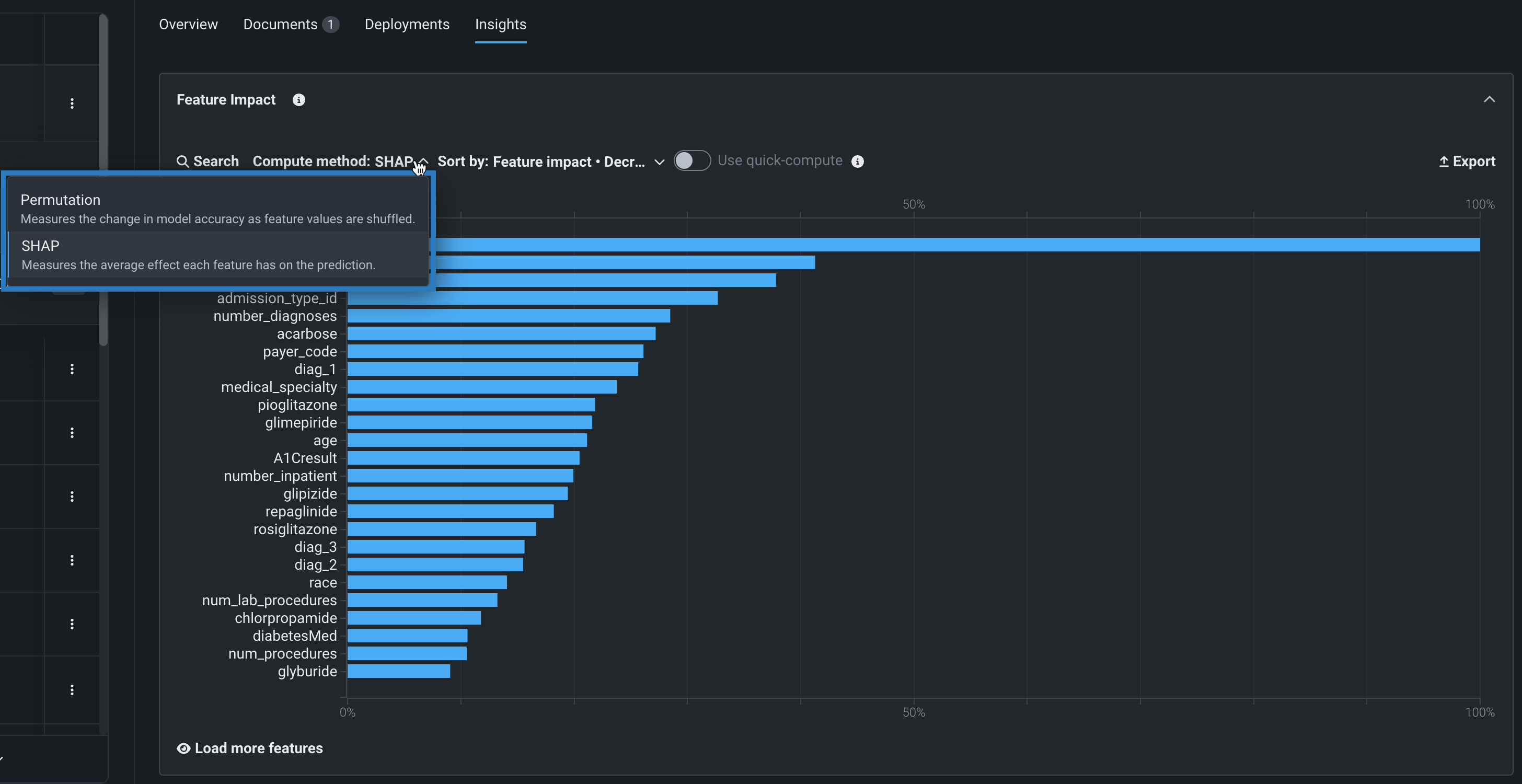
計算方法の選択¶
計算方法として、SHAPまたはPermutationのインパクトを選択できます。 どのモデルについても、SHAPまたはPermutationベースの特徴量のインパクトを確認するには、それぞれについて再計算する必要があります。
-
SHAPベースでは、平均で各機能がトレーニングデータの予測値にどの程度影響するかを示します。 教師ありプロジェクトの場合、SHAPはAutoMLプロジェクトのみに使用できます。 SHAPリファレンスおよびSHAPに関する注意事項も参照してください。
-
Permutationベースでは、列の値がシャッフルされた場合に、トレーニングデータのサンプルに基づいて、モデルの誤差がどの程度増加するかが示されます。
方法論のいくつかの顕著な特性:
-
SHAPベースおよびPermutationペースのインパクトは、すべてのモデリング手法で機能する、モデルにとらわれないアプローチを提供します。
-
SHAPベースの特徴量のインパクトは、サンプルサイズが小さい場合、Permutationベースの特徴量のインパクトよりも高速かつ堅牢です。
クイックコンピューティングを使用する¶
特徴量のインパクトを操作する場合、クイック計算を使用オプションは、視覚化で使用するサンプルサイズを制御します。 視覚化の作成に使用される行数は、トグル設定に基づきます。
-
オンの場合、DataRobotは、2500行またはモデルトレーニングサンプルサイズの行数のいずれか小さい方を使用します。
-
オフの場合、DataRobotは、100,000行またはモデルトレーニングサンプルサイズの行数のいずれか小さい方を使用します。
このオプションは、精度と安定性が高い結果を取得するために、例えば、デフォルトの2500行よりも大きいサンプルサイズ(またはダウンサンプリングした場合はより小さいサンプルサイズ)で、特徴量のインパクトをトレーニングする際に使用します。
備考
特徴量のインパクトの前に特徴量ごとの作用を実行すると、DataRobotは最初に特徴量のインパクトの計算を開始します。 その場合、クイックコンピューティングオプションが特徴量ごとの作用画面で使用できるようになり、特徴量のインパクトの計算基準が設定されます。
一歩進んだ操作¶
特徴量のインパクトはオンデマンド特徴量なので、結果を使用するには各モデルに対して計算を行う必要があります。 これはトレーニングデータを使用して計算され、デフォルトでは有用性の最も高いモデルから低いモデルにソートされ、有用性の最も高いモデルの精度が常に 1 に正規化されます。
方法の計算¶
このセクションには、2つの利用可能な方法のそれぞれの計算に関する技術的な詳細が含まれています。
Permutationベースの特徴量のインパクト¶
Permutationベースの特徴量のインパクトは、特徴量値がシャッフルされたときのモデル精度の低下を測定します。 値を計算するために、DataRobotでは次の処理が行われます。
- トレーニングレコードのサンプルで予測を作成します。デフォルトでは2500行、最大100,000行です。
- トレーニングデータを変更します(列の値をシャッフルします)。
- 新しい(シャッフルされた)トレーニングデータの予測を作成し、シャッフルによる精度の低下を計算する。
- 平均低下を計算する。
- 特徴量ごとに手順2~4を繰り返します。
- 結果を正規化します(一番上の特徴量のインパクトは100%)。
サンプリングプロセスは、以下の条件のいずれかに対応します。
- 均衡したデータの場合、ランダムサンプリングが使用されます。
- 不均衡な二値データの場合、スマートダウンサンプリングが使用されます。DataRobotは、50/50により近い不均衡な二値ターゲットの分布を作成し、スコアリングに使用するサンプルの加重を調整します。
- ゼロ過剰連続値データの場合、スマートダウンサンプリングが使用されます。DataRobotは、非ゼロ要素をマイノリティークラスにグループ化します。
- 不均衡の多クラスデータの場合、ランダムサンプリングが使用されます。
SHAPベースの特徴量のインパクト¶
SHAPベースの特徴量のインパクトは、平均で各特徴量がトレーニングデータの予測値にどの程度影響するかを測定します。 値を計算するために、DataRobotでは次の処理が行われます。
- トレーニングデータからレコードのサンプルを取得します(デフォルトで5000行、最大100,000行)。
- サンプルの各レコードのSHAP値を計算し、各レコードの各特徴量の局所的な有用性を生成します。
- サンプル内の各特徴量の
abs(SHAP values)の平均を取ることにより、グローバルな有用性を計算します。 - 結果を正規化します(一番上の特徴量のインパクトは100%)。
機能に関する注意事項¶
特徴量のインパクトを評価する際は、以下の点に注意してください。
-
特徴量のインパクトは、モデルのトレーニングデータのサンプルを使用して計算されます。 サンプルサイズが結果に影響する場合があるため、より大きいサンプルサイズで数値を再計算する必要があります。
-
時折、データに含まれるランダムノイズが原因で、負の特徴量のインパクトスコアを含む特徴量がある場合があります。 極度にアンバランスなデータでは、大部分が負の値となる場合があります。 これらの特徴量を削除することを検討してください。
-
いくつかの条件の下では、モデリングに使用するアルゴリズムの関数が原因で特徴量のインパクトの結果が変わることがあります。 これは、多重共線性の場合などに発生する可能性があります。 そのような場合、L1ペナルティを使用するアルゴリズム(いくつかの線形モデルなど)の場合、インパクトは1つの信号に集中しますし、ツリーの場合は相関する複数の信号にわたって均一に分散されます。