カスタムジョブの作成¶
カスタムジョブを作成する場合は、必要となる実行環境とファイルをジョブを実行する前に構築する必要があります。 実行環境とエントリーポイントファイル(通常はrun.sh)のみが必要ですが、エントリーポイントとして追加するファイルを指定できます。 ジョブを作成するために他のファイルを追加する場合、エントリーポイントファイルはそれらのファイルを参照するようにしてください。 さらに、ランタイムパラメーターを設定するには、ジョブのランタイムパラメーター設定を含むmetadata.yamlファイルを作成またはアップロードしてください。
カスタムジョブの追加¶
レジストリに新しいカスタムジョブを登録して構築するには、レジストリ > ジョブをクリックし、+ 新規追加(またはカスタムジョブパネルが開いている場合は ボタン)をクリックして、次のカスタムジョブタイプのいずれかを選択し、テーブルでリンクされている設定ステップに進みます。
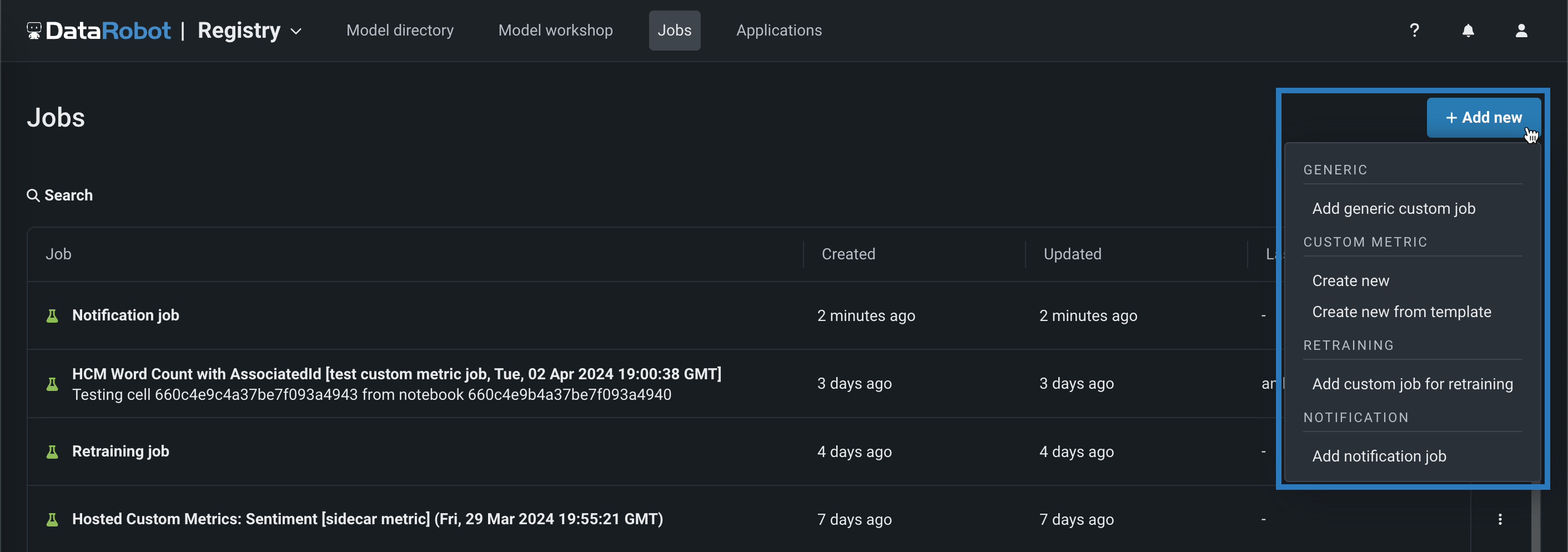
| カスタムジョブタイプ | 説明 |
|---|---|
| 汎用カスタムジョブを追加 | カスタムジョブを追加して、モデルとデプロイの自動化(たとえば、カスタムテスト)を実装します。 |
| 新しく作成 | 新しいホストされたカスタム指標のカスタムジョブを追加します。カスタム指標設定を定義し、指標をデプロイに関連付けます。 |
| テンプレートから新規作成 | DataRobotによって提供されるテンプレートからカスタム指標のカスタムジョブを追加して、指標をデプロイに関連付け、ベースラインを設定します。 |
| 再トレーニングのためにカスタムジョブを追加 | コードベースの再トレーニングポリシーを実装するカスタムジョブを追加します。 |
| 通知ジョブを追加 | コードベースの通知ポリシーを実装するカスタムジョブを追加します。 |
汎用カスタムジョブの作成¶
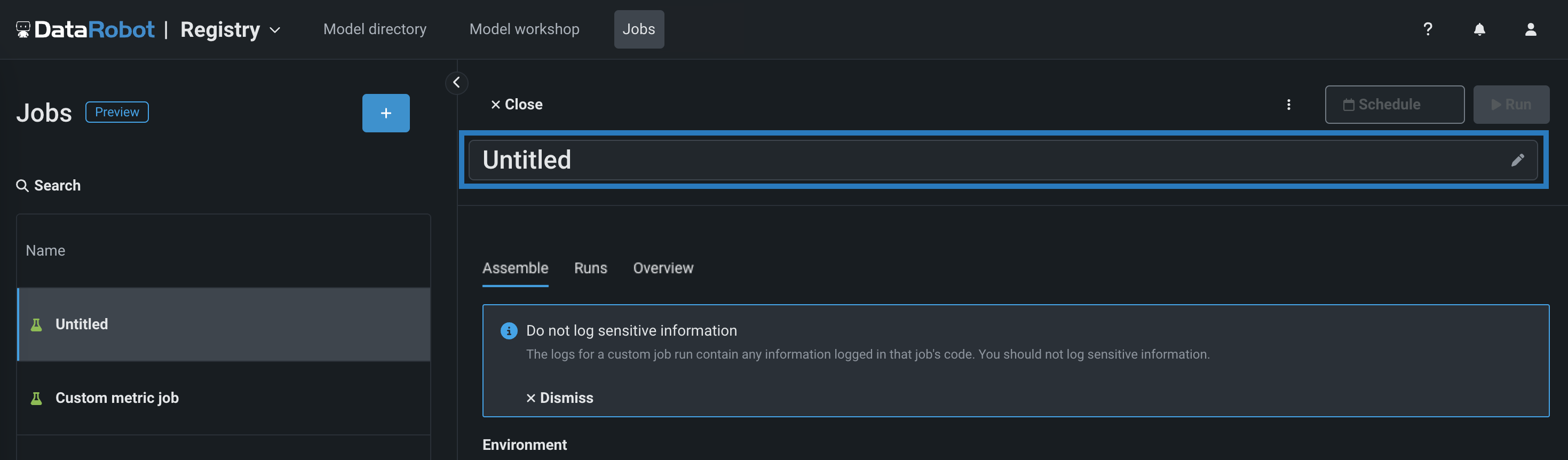
汎用ジョブを作成するには:
-
新しいジョブのアセンブルタブで、編集アイコン()をクリックしてジョブ名を更新します。
-
環境セクションで、ジョブの基本環境を選択します。
-
ファイルセクションで、カスタムジョブを構築します。 ボックスにファイルをドラッグするか、このセクションのオプションを使用して、カスタムジョブの構築に必要なファイルを作成またはアップロードします。
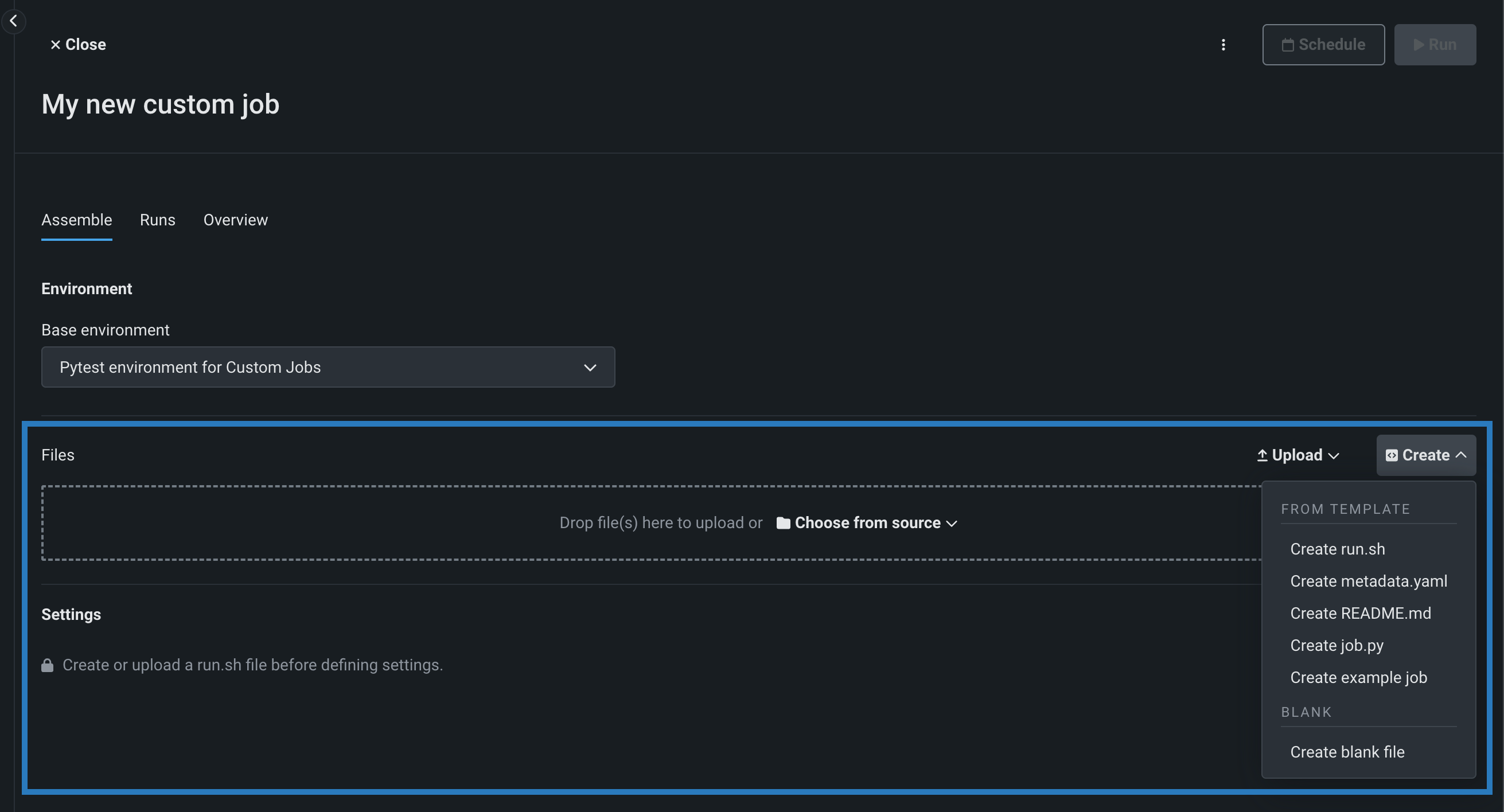
オプション 説明 ソース/アップロードから選択 既存のカスタムジョブファイル( run.sh、metadata.yaml、など)をローカルファイルまたはローカルフォルダーとしてアップロードします。作成 空のファイルまたはテンプレートを含んだファイルとして新しいファイルを作成し、カスタムジョブに保存します。 - run.shを作成:エントリーポイントファイルの基本的で編集可能な例を作成します。
- metadata.yamlを作成:ランタイムパラメーターファイルの基本的で編集可能な例を作成します。
- README.mdを作成:基本的で編集可能なREADMEファイルを作成します。
- job.pyを作成:実行時のパラメーターとデプロイをプリントするための基本的で編集可能なPythonジョブファイルを作成します。
- サンプルジョブを作成:すべてのテンプレートファイルを結合して、基本的で編集可能なカスタムジョブを作成します。 簡単にランタイムパラメーターを設定し、このサンプルジョブを実行できます。
- 空白ファイルを作成:空のファイルを作成します。 名称未設定の横にある編集アイコン()をクリックしてファイル名と拡張子を入力し、カスタムコンテンツを追加します。 次のステップでは、カスタム名とコンテンツを使用して、このように作成されたファイルをエントリーポイントとして識別できます。 新しいファイルを設定したら、保存をクリックします。
ファイルの置き換え
既存のファイルと同じ名前の新しいファイルを追加する場合、保存をクリックすると、ファイルセクションで古いファイルが置き換えられます。
-
設定セクションで、ジョブのエントリーポイントシェル(
.sh)ファイルを設定します。run.shファイルを追加した場合、そのファイルがエントリーポイントです。それ以外の場合は、ドロップダウンリストからエントリーポイントシェルファイルを選択する必要があります。 エントリーポイントファイルでは、複数のジョブファイルを調整できます。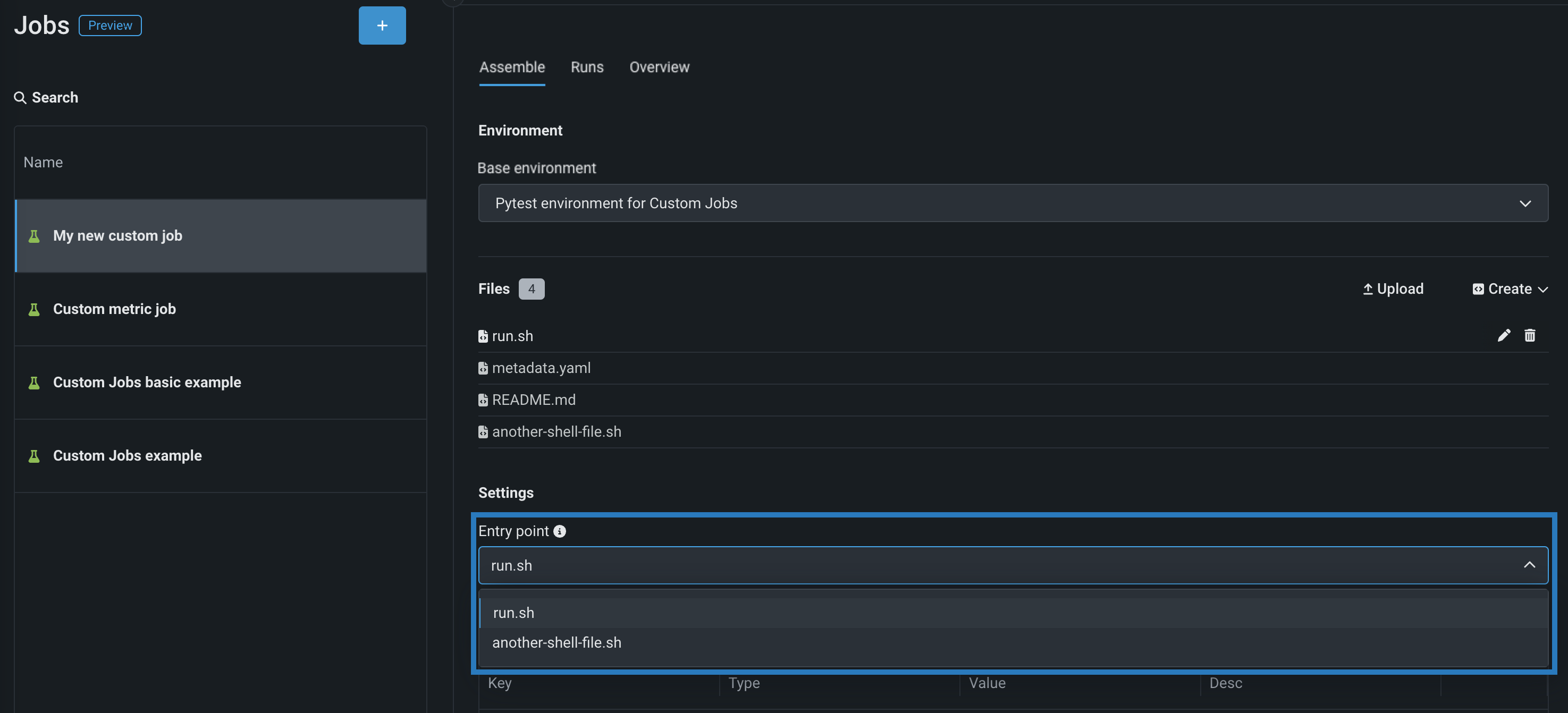
-
リソースセクションのセクションヘッダーの横にある 編集をクリックして、以下を設定します。
本機能の提供について
カスタムジョブのリソースバンドルは、プレビュー機能として提供され、デフォルトではオフになっています。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:リソースのバンドルを有効にする
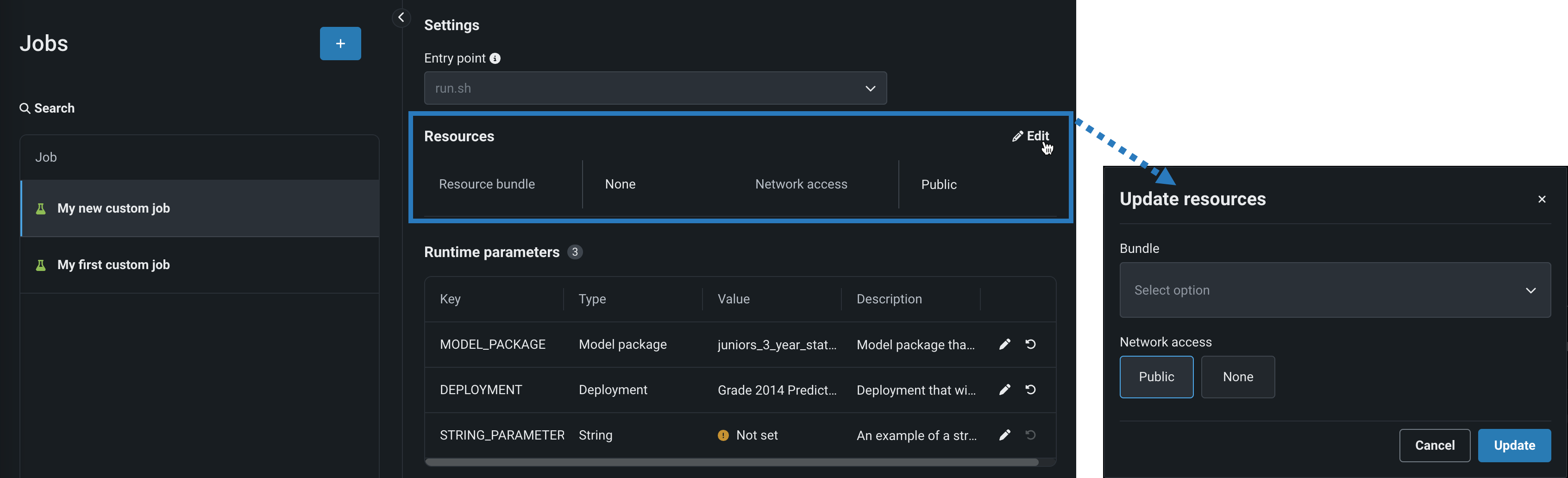
設定 説明 リソースバンドル プレビュー機能 カスタムジョブが実行に使用するリソースを設定します。 ネットワークアクセス カスタムジョブのエグレストラフィックを設定します。 ネットワークアクセスで、以下のいずれかを選択します。 - パブリック:デフォルト設定。 カスタムジョブは、パブリックネットワーク内の任意の完全修飾ドメイン名(FQDN)にアクセスして、サードパーティのサービスを利用できます。
- なし:カスタムジョブはパブリックネットワークから隔離され、サードパーティのサービスにアクセスできません。
デフォルトのネットワークアクセス
_マネージドAIプラットフォーム_では、ネットワークアクセスはデフォルトでパブリックに設定されていますが、変更可能です。 _セルフマネージドAIプラットフォーム_では、ネットワークアクセスはデフォルトでなしに設定されており、制限があります。ただし、管理者は、DataRobotプラットフォームの設定時にこれを変更できます。 詳細については、DataRobotの担当者または管理者にお問い合わせください。
-
(オプション)
metadata.yamlファイルをアップロードした場合は、設定したい各キー値の行の編集アイコン()をクリックして、ランタイムパラメーターを定義します。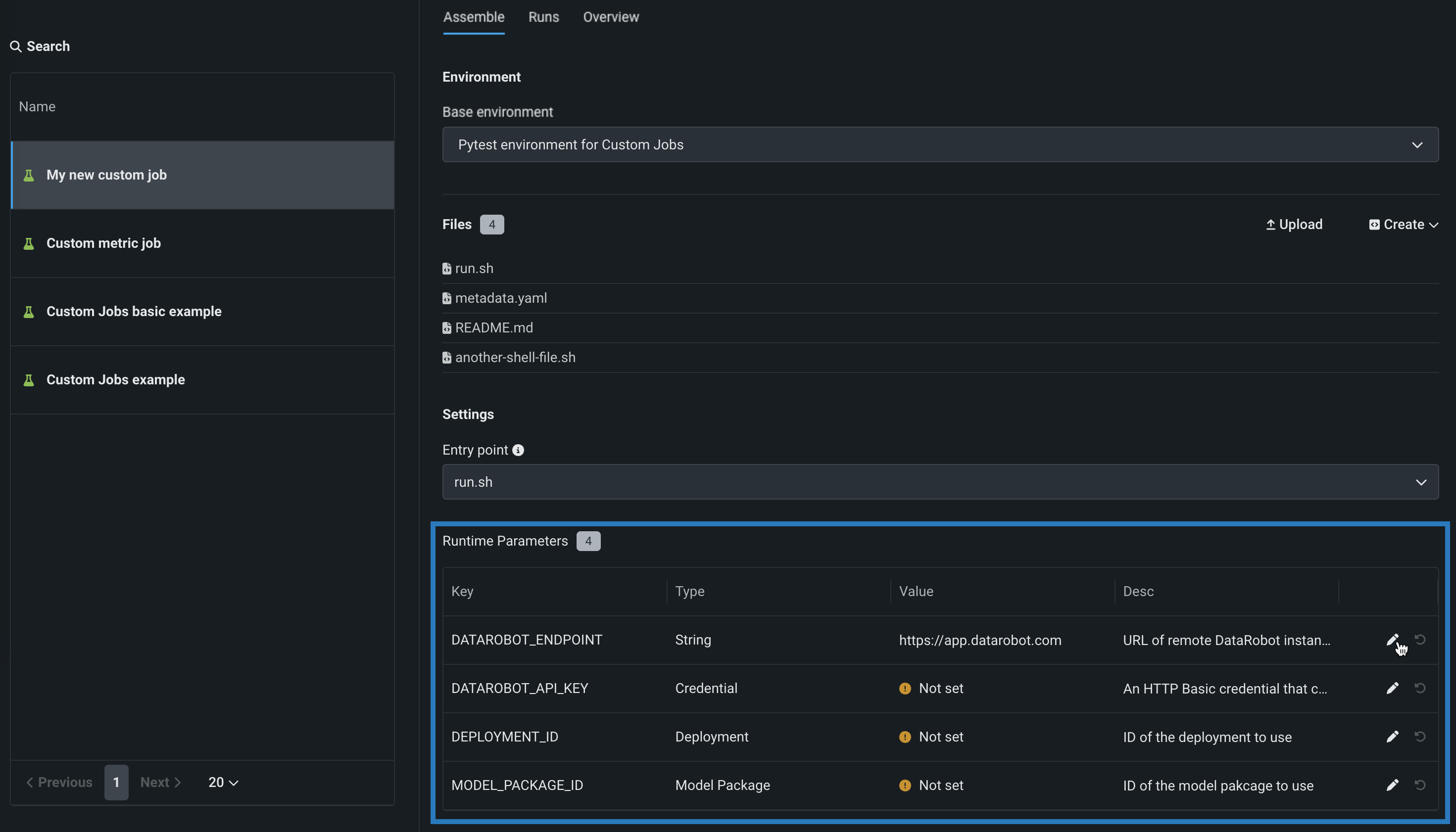
-
(オプション)タグ、指標、トレーニングパラメーター、アーティファクトに、追加の キー値を設定します。
ホストされたカスタム指標ジョブの作成¶
ホストされたカスタム指標ジョブを作成するには:
-
新しいカスタム指標ジョブのアセンブルタブで、編集アイコン()をクリックしてジョブ名を更新します。
-
環境セクションで、ジョブの基本環境を選択します。
-
メタデータセクションで、次のカスタム指標ジョブフィールドを設定します。
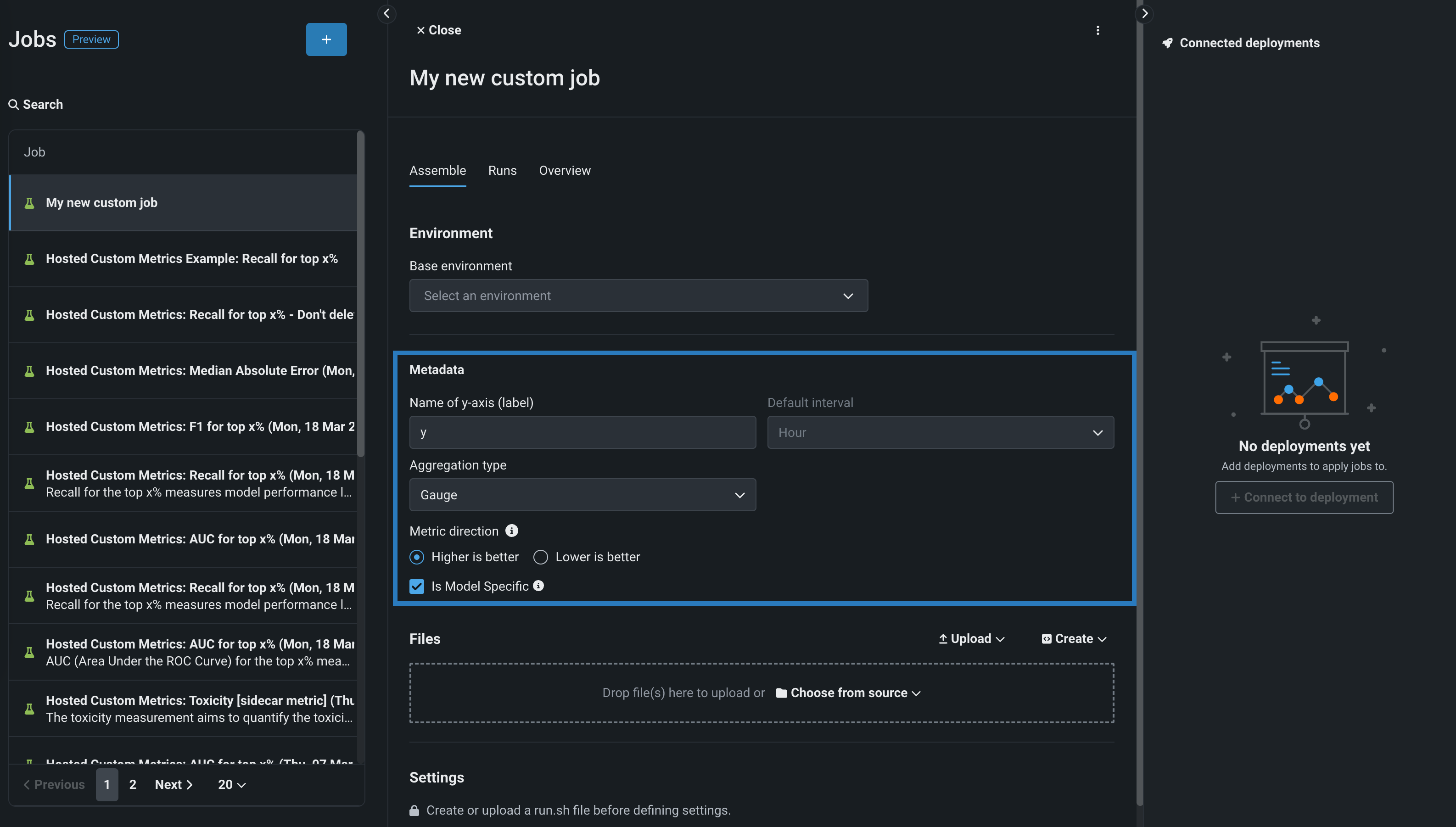
フィールド 説明 Y軸の名前(ラベル) 従属変数の説明的な名前。 この名前は、カスタム指標サマリーダッシュボードのカスタム指標のチャートに表示されます。 デフォルトの間隔 選択した集計タイプで使用されるデフォルトの間隔を決定します。 HOURのみサポートされています。 集計タイプ 指標を合計、平均、またはゲージ(単一時点で測定された明確な値を持つ指標)として計算するかどうかを決定します。 指標の方向 指標の方向性を決定し、指標の変更を視覚化する方法を変更します。 大きいほど良いまたは低いほど良いを選択できます。 たとえば、低いほど良いを選択すると、カスタム指標の計算値が10%減少することが、10%改善とみなされ、緑色で表示されます。 モデル固有 この設定を有効にすると、データセットで提供されたモデルパッケージID(登録されているモデルバージョンID)を使用して、指標をモデルにリンクします。 この設定は、値が集計(またはアップロード)される場合に影響します。 例: - モデル固有(有効):モデルの精度指標はモデル固有であるため、値は完全に個別に集計されます。 モデルを置換すると、カスタム精度指標のチャートには、置換後の日についてのデータだけが表示されます。
- モデル固有ではありません(無効):収益指標はモデル固有ではないため、値は一緒に集計されます。 モデルを置換しても、カスタム収益指標のチャートは変更されません。
-
ファイルセクションで、カスタムジョブを構築します。 ボックスにファイルをドラッグするか、このセクションのオプションを使用して、カスタムジョブの構築に必要なファイルを作成またはアップロードします。
オプション 説明 ソース/アップロードから選択 既存のカスタムジョブファイル( run.sh、metadata.yaml、など)をローカルファイルまたはローカルフォルダーとしてアップロードします。作成 空のファイルまたはテンプレートを含んだファイルとして新しいファイルを作成し、カスタムジョブに保存します。 - run.shを作成:エントリーポイントファイルの基本的で編集可能な例を作成します。
- metadata.yamlを作成:ランタイムパラメーターファイルの基本的で編集可能な例を作成します。
- README.mdを作成:基本的で編集可能なREADMEファイルを作成します。
- job.pyを作成:実行時のパラメーターとデプロイをプリントするための基本的で編集可能なPythonジョブファイルを作成します。
- サンプルジョブを作成:すべてのテンプレートファイルを結合して、基本的で編集可能なカスタムジョブを作成します。 簡単にランタイムパラメーターを設定し、このサンプルジョブを実行できます。
- 空白ファイルを作成:空のファイルを作成します。 名称未設定の横にある編集アイコン()をクリックしてファイル名と拡張子を入力し、カスタムコンテンツを追加します。 次のステップでは、カスタム名とコンテンツを使用して、このように作成されたファイルをエントリーポイントとして識別できます。 新しいファイルを設定したら、保存をクリックします。
ファイルの置き換え
既存のファイルと同じ名前の新しいファイルを追加する場合、保存をクリックすると、ファイルセクションで古いファイルが置き換えられます。
-
設定セクションで、ジョブのエントリーポイントシェル(
.sh)ファイルを設定します。run.shファイルを追加した場合、そのファイルがエントリーポイントです。それ以外の場合は、ドロップダウンリストからエントリーポイントシェルファイルを選択する必要があります。 エントリーポイントファイルでは、複数のジョブファイルを調整できます。 -
リソースセクションのセクションヘッダーの横にある 編集をクリックして、以下を設定します。
本機能の提供について
カスタムジョブのリソースバンドルは、プレビュー機能として提供され、デフォルトではオフになっています。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:リソースのバンドルを有効にする
設定 説明 リソースバンドル(プレビュー) カスタムジョブが実行に使用するリソースを設定します。 ネットワークアクセス カスタムジョブのエグレストラフィックを設定します。 ネットワークアクセスで、以下のいずれかを選択します。 - パブリック:デフォルト設定。 カスタムジョブは、パブリックネットワーク内の任意の完全修飾ドメイン名(FQDN)にアクセスして、サードパーティのサービスを利用できます。
- なし:カスタムジョブはパブリックネットワークから隔離され、サードパーティのサービスにアクセスできません。
デフォルトのネットワークアクセス
_マネージドAIプラットフォーム_では、ネットワークアクセスはデフォルトでパブリックに設定されていますが、変更可能です。 _セルフマネージドAIプラットフォーム_では、ネットワークアクセスはデフォルトでなしに設定されており、制限があります。ただし、管理者は、DataRobotプラットフォームの設定時にこれを変更できます。 詳細については、DataRobotの担当者または管理者にお問い合わせください。
-
(オプション)
metadata.yamlファイルをアップロードした場合、ランタイムパラメーターを定義します。 設定したい各キー値の行の編集アイコン()をクリックします。 -
(オプション)タグ、指標、トレーニングパラメーター、アーティファクトに、追加の キー値を設定します。
-
接続されたデプロイパネルで、+ デプロイに接続をクリックして、カスタム指標名を定義し、デプロイIDを選択して、そのデプロイに接続します。
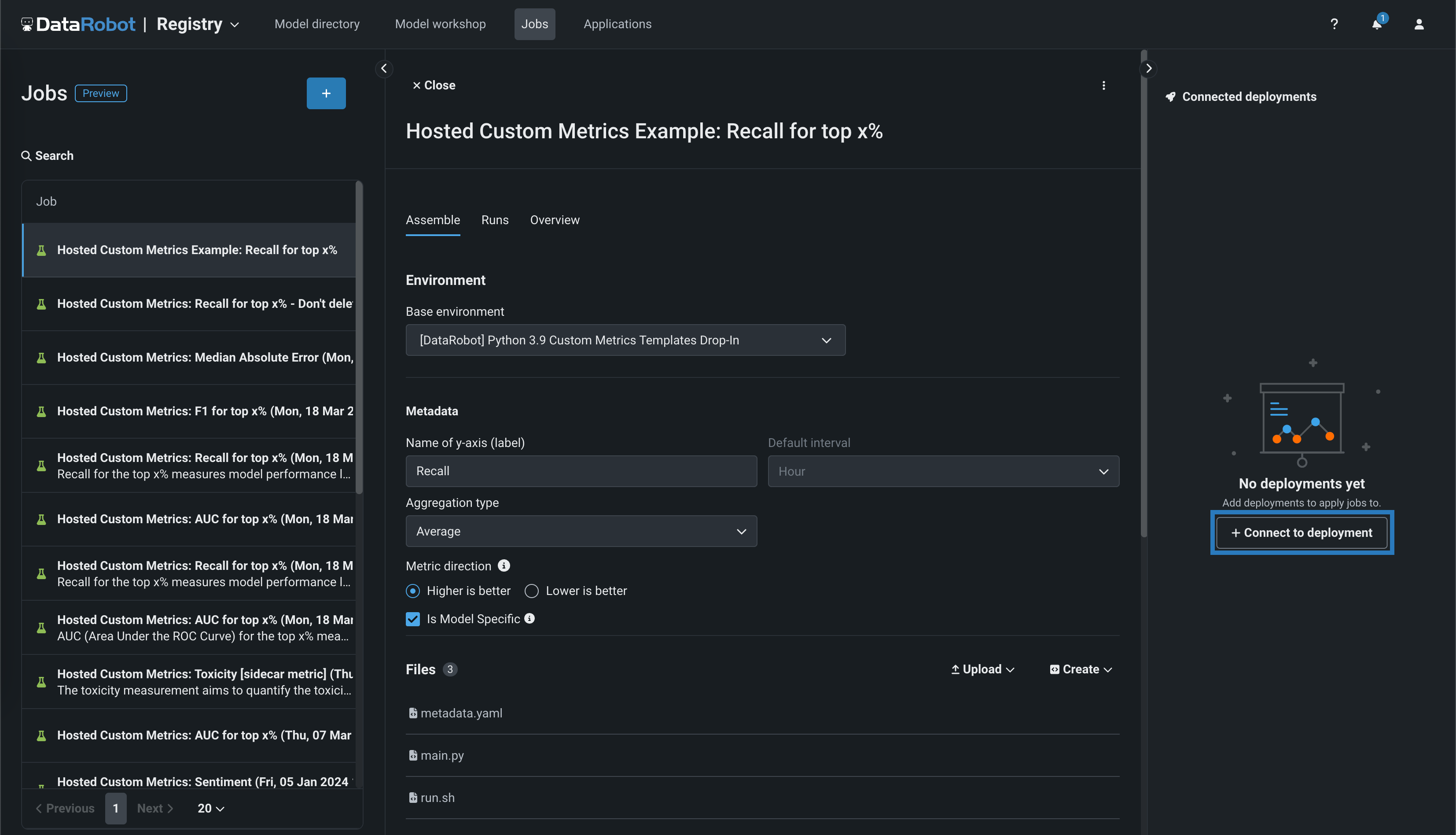
-
カスタム指標名を編集してデプロイIDを選択し、ベースラインでx%改善またはx%悪いを計算する場合に比較の基準として使用する値を設定し、接続をクリックします。
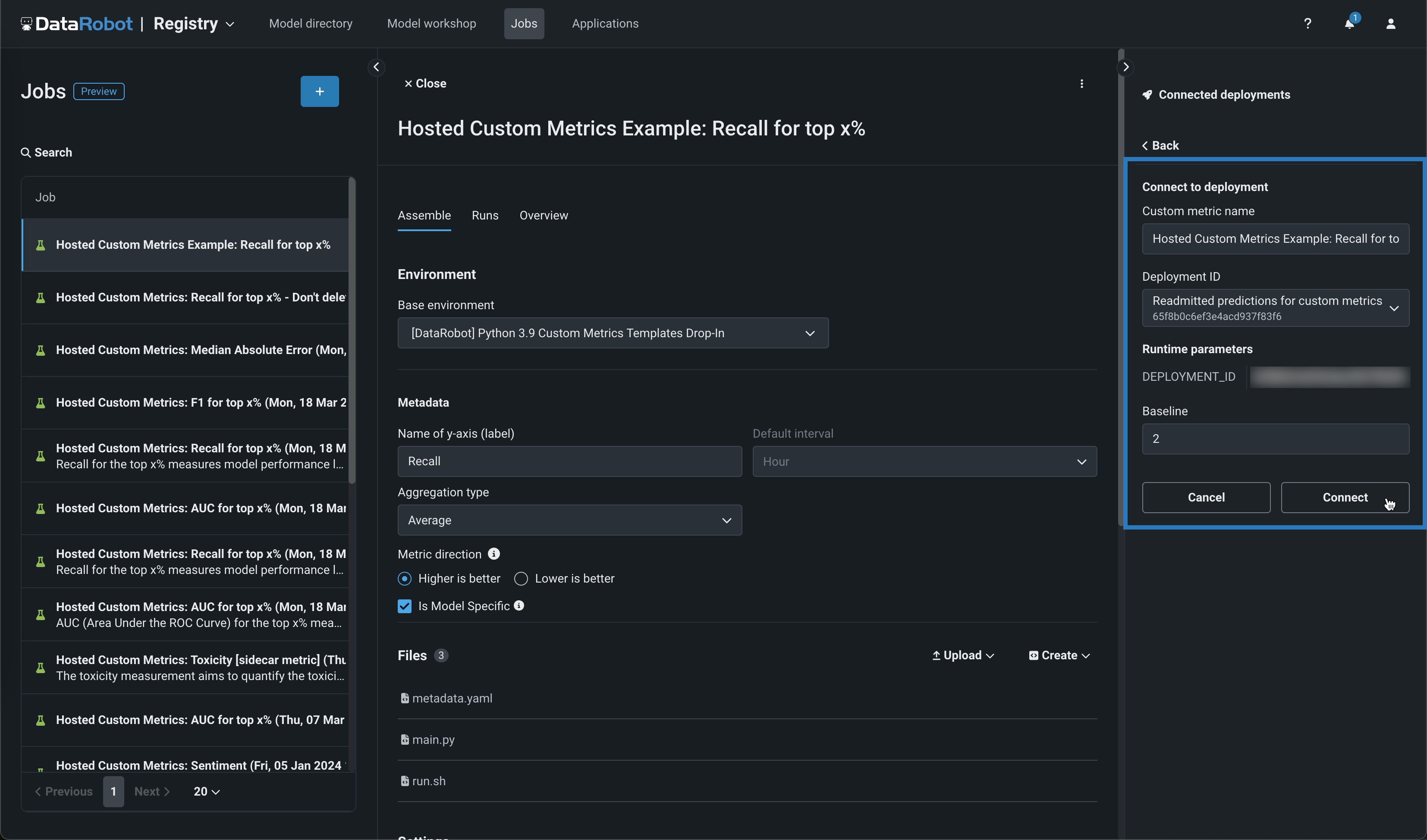
How many Deployments can I connect to a hosted custom metric job?
ホストされたカスタム指標ジョブに、最大10のデプロイを接続できます。
接続されたデプロイとランタイムパラメーター
ホストされているカスタム指標ジョブにデプロイを接続し、実行をスケジュールした後は、
metadata.yamlファイルのランタイムパラメーターを変更できません。metadata.yamlファイルに変更を加えるには、接続されているすべてのデプロイを切断する必要があります。
ホストされたカスタム指標ジョブをテンプレートから作成¶
テンプレートから事前に作成されたカスタム指標を追加するには:
-
カスタム指標を追加パネルで、ユースケースに適したカスタム指標テンプレートを選択し、指標を作成をクリックします。
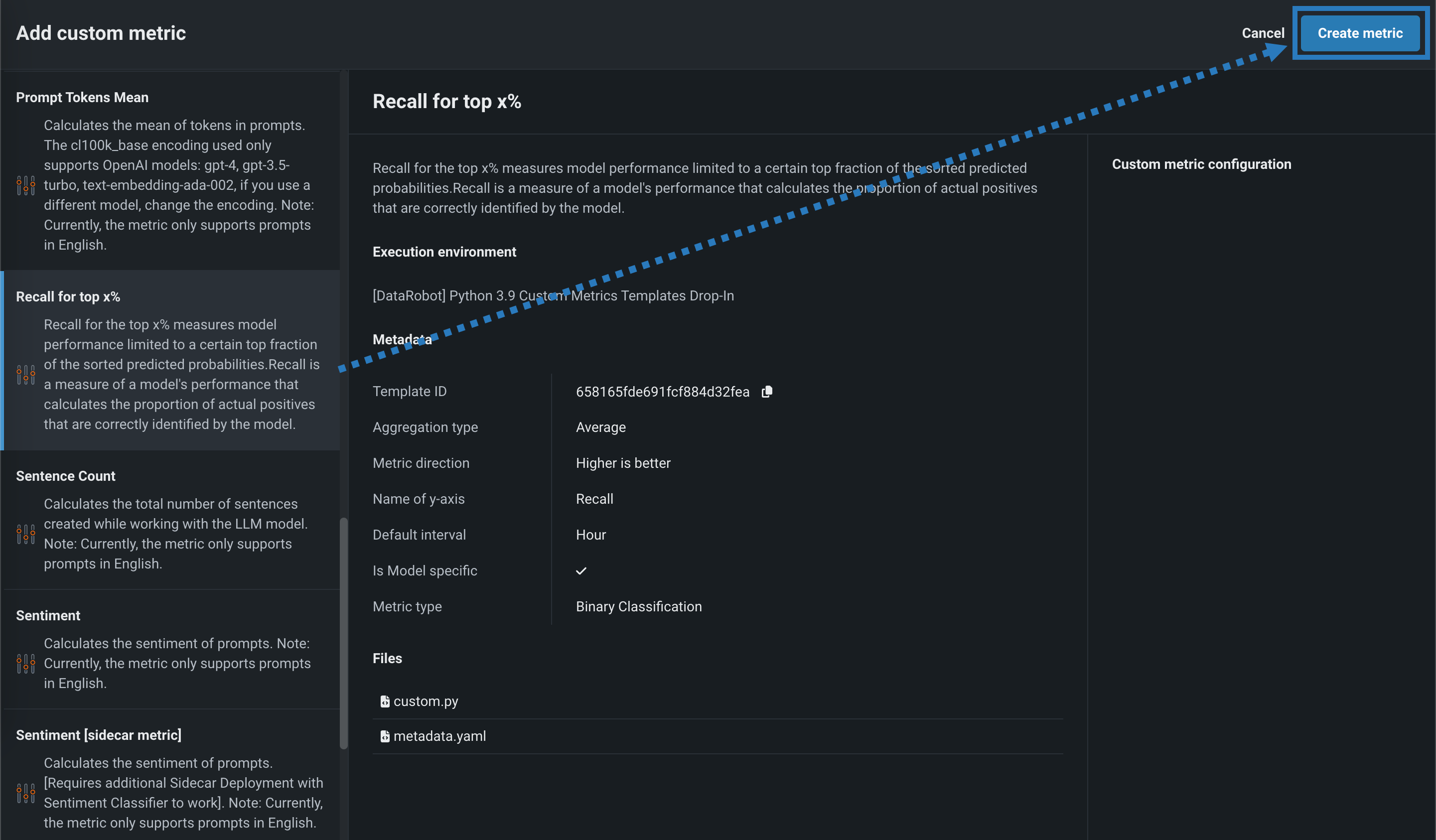
ホストされた新しいカスタム指標が、レジストリ > ジョブタブで開きます。
-
アセンブルタブでは、 標準のカスタム指標ジョブと同様に、テンプレートのデフォルト名、環境、ファイル、設定、リソース、ランタイムパラメーター、またはキー値を必要に応じて変更できます。
-
接続されたデプロイパネルで、+ デプロイに接続をクリックします。
接続されたデプロイとランタイムパラメーター
ホストされているカスタム指標ジョブにデプロイを接続し、実行をスケジュールした後は、
metadata.yamlファイルのランタイムパラメーターを変更できません。metadata.yamlファイルに変更を加えるには、接続されているすべてのデプロイを切断する必要があります。 -
カスタム指標名を編集してデプロイIDを選択し、ベースラインでx%改善またはx%悪いを計算する場合に比較の基準として使用する値を設定し、接続をクリックします。
How many Deployments can I connect to a hosted custom metric job?
ホストされたカスタム指標ジョブに、最大10のデプロイを接続できます。
サイドカー指標
[sidecar metric]を選択した場合は、アセンブルタブを開いたときに、ランタイムパラメーターセクションに移動してSIDECAR_DEPLOYMENT_IDを設定します。サイドカー指標を、その指標の計算に必要な接続されたデプロイに関連付けます。 指標を計算するモデルをデプロイしていない場合、これらの指標には、 グローバルモデルとして事前に定義されたモデルがあります。
再トレーニング用のカスタムジョブの作成¶
本機能の提供について
Code-based retraining custom jobs are off by default and require custom notebook environments. この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
Feature flags: Enable Custom Job Based Retraining Polices, Enable Notebooks Custom Environments
コードベースの再トレーニング用カスタムジョブを作成するには:
-
新しいジョブのアセンブルタブで、編集アイコン()をクリックしてジョブ名を更新します。
-
環境セクションで、ジョブの基本環境を選択します。
-
ファイルセクションで、カスタムジョブを構築します。 ボックスにファイルをドラッグするか、このセクションのオプションを使用して、カスタムジョブの構築に必要なファイルを作成またはアップロードします。
オプション 説明 ソース/アップロードから選択 既存のカスタムジョブファイル( run.sh、metadata.yaml、など)をローカルファイルまたはローカルフォルダーとしてアップロードします。作成 空のファイルまたはテンプレートを含んだファイルとして新しいファイルを作成し、カスタムジョブに保存します。 - run.shを作成:エントリーポイントファイルの基本的で編集可能な例を作成します。
- metadata.yamlを作成:ランタイムパラメーターファイルの基本的で編集可能な例を作成します。
- README.mdを作成:基本的で編集可能なREADMEファイルを作成します。
- job.pyを作成:実行時のパラメーターとデプロイをプリントするための基本的で編集可能なPythonジョブファイルを作成します。
- サンプルジョブを作成:すべてのテンプレートファイルを結合して、基本的で編集可能なカスタムジョブを作成します。 簡単にランタイムパラメーターを設定し、このサンプルジョブを実行できます。
- 空白ファイルを作成:空のファイルを作成します。 名称未設定の横にある編集アイコン()をクリックしてファイル名と拡張子を入力し、カスタムコンテンツを追加します。 次のステップでは、カスタム名とコンテンツを使用して、このように作成されたファイルをエントリーポイントとして識別できます。 新しいファイルを設定したら、保存をクリックします。
ファイルの置き換え
既存のファイルと同じ名前の新しいファイルを追加する場合、保存をクリックすると、ファイルセクションで古いファイルが置き換えられます。
-
設定セクションで、ジョブのエントリーポイントシェル(
.sh)ファイルを設定します。run.shファイルを追加した場合、そのファイルがエントリーポイントです。それ以外の場合は、ドロップダウンリストからエントリーポイントシェルファイルを選択する必要があります。 エントリーポイントファイルでは、複数のジョブファイルを調整できます。 -
リソースセクションのセクションヘッダーの横にある 編集をクリックして、以下を設定します。
本機能の提供について
カスタムジョブのリソースバンドルは、プレビュー機能として提供され、デフォルトではオフになっています。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:リソースのバンドルを有効にする
設定 説明 リソースバンドル プレビュー機能 カスタムジョブが実行に使用するリソースを設定します。 ネットワークアクセス カスタムジョブのエグレストラフィックを設定します。 ネットワークアクセスで、以下のいずれかを選択します。 - パブリック:デフォルト設定。 カスタムジョブは、パブリックネットワーク内の任意の完全修飾ドメイン名(FQDN)にアクセスして、サードパーティのサービスを利用できます。
- なし:カスタムジョブはパブリックネットワークから隔離され、サードパーティのサービスにアクセスできません。
デフォルトのネットワークアクセス
_マネージドAIプラットフォーム_では、ネットワークアクセスはデフォルトでパブリックに設定されていますが、変更可能です。 _セルフマネージドAIプラットフォーム_では、ネットワークアクセスはデフォルトでなしに設定されており、制限があります。ただし、管理者は、DataRobotプラットフォームの設定時にこれを変更できます。 詳細については、DataRobotの担当者または管理者にお問い合わせください。
-
(オプション)
metadata.yamlファイルをアップロードした場合は、設定したい各キー値の行の編集アイコン()をクリックして、ランタイムパラメーターを定義します。 -
(オプション)タグ、指標、トレーニングパラメーター、アーティファクトに、追加の キー値を設定します。
再トレーニング用のカスタムジョブを作成したら、それを再トレーニングポリシーとしてデプロイに追加できます。
通知用のカスタムジョブを作成¶
通知用のカスタムジョブを作成するには:
-
新しいジョブのアセンブルタブで、編集アイコン()をクリックしてジョブ名を更新します。
-
環境セクションで、ジョブの基本環境を選択します。
-
ファイルセクションで、カスタムジョブを構築します。 ボックスにファイルをドラッグするか、このセクションのオプションを使用して、カスタムジョブの構築に必要なファイルを作成またはアップロードします。
オプション 説明 ソース/アップロードから選択 既存のカスタムジョブファイル( run.sh、metadata.yaml、など)をローカルファイルまたはローカルフォルダーとしてアップロードします。作成 空のファイルまたはテンプレートを含んだファイルとして新しいファイルを作成し、カスタムジョブに保存します。 - run.shを作成:エントリーポイントファイルの基本的で編集可能な例を作成します。
- metadata.yamlを作成:ランタイムパラメーターファイルの基本的で編集可能な例を作成します。
- README.mdを作成:基本的で編集可能なREADMEファイルを作成します。
- job.pyを作成:実行時のパラメーターとデプロイをプリントするための基本的で編集可能なPythonジョブファイルを作成します。
- サンプルジョブを作成:すべてのテンプレートファイルを結合して、基本的で編集可能なカスタムジョブを作成します。 簡単にランタイムパラメーターを設定し、このサンプルジョブを実行できます。
- 空白ファイルを作成:空のファイルを作成します。 名称未設定の横にある編集アイコン()をクリックしてファイル名と拡張子を入力し、カスタムコンテンツを追加します。 次のステップでは、カスタム名とコンテンツを使用して、このように作成されたファイルをエントリーポイントとして識別できます。 新しいファイルを設定したら、保存をクリックします。
ファイルの置き換え
既存のファイルと同じ名前の新しいファイルを追加する場合、保存をクリックすると、ファイルセクションで古いファイルが置き換えられます。
-
設定セクションで、ジョブのエントリーポイントシェル(
.sh)ファイルを設定します。run.shファイルを追加した場合、そのファイルがエントリーポイントです。それ以外の場合は、ドロップダウンリストからエントリーポイントシェルファイルを選択する必要があります。 エントリーポイントファイルでは、複数のジョブファイルを調整できます。 -
リソースセクションのセクションヘッダーの横にある 編集をクリックして、以下を設定します。
本機能の提供について
カスタムジョブのリソースバンドルは、プレビュー機能として提供され、デフォルトではオフになっています。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:リソースのバンドルを有効にする
設定 説明 リソースバンドル プレビュー機能 カスタムジョブが実行に使用するリソースを設定します。 ネットワークアクセス カスタムジョブのエグレストラフィックを設定します。 ネットワークアクセスで、以下のいずれかを選択します。 - パブリック:デフォルト設定。 カスタムジョブは、パブリックネットワーク内の任意の完全修飾ドメイン名(FQDN)にアクセスして、サードパーティのサービスを利用できます。
- なし:カスタムジョブはパブリックネットワークから隔離され、サードパーティのサービスにアクセスできません。
デフォルトのネットワークアクセス
_マネージドAIプラットフォーム_では、ネットワークアクセスはデフォルトでパブリックに設定されていますが、変更可能です。 _セルフマネージドAIプラットフォーム_では、ネットワークアクセスはデフォルトでなしに設定されており、制限があります。ただし、管理者は、DataRobotプラットフォームの設定時にこれを変更できます。 詳細については、DataRobotの担当者または管理者にお問い合わせください。
-
(オプション)
metadata.yamlファイルをアップロードした場合は、設定したい各キー値の行の編集アイコン()をクリックして、ランタイムパラメーターを定義します。 -
(オプション)タグ、指標、トレーニングパラメーター、アーティファクトに、追加の キー値を設定します。
通知用のカスタムジョブを作成したら、それを 通知チャネルとして通知テンプレートに追加できます。