エクスペリメントを作成¶
ワークベンチで実行可能なAIエクスペリメントの「タイプ」は2つあります。
-
このページで説明する_時間認識モデリング_は、 時間に関連するデータ を使用してモデルを作成し、行単位の予測、時系列予測、または現在値の予測である 「ナウキャスト」を行います。
備考
時間認識モデリングの基礎について、豊富な資料を用意しています。 手順はほとんどDataRobot Classicで適用されるワークフローを表していますが、 フレームワーク、 特徴量派生プロセスなどを説明するリファレンス資料も今までどおり適用できます。
エクスペリメントは、 ユースケース内の個々の"プロジェクト"です。 データ、ターゲット、モデリング設定を変更しながら、ビジネス問題を解決するための最適なモデルを見つけることができます。 各エクスペリメント内では、そのリーダーボードと モデルのインサイト、および エクスペリメントのサマリー情報にアクセスできます。
プレビュー
時系列モデリングはデフォルトでオンになっています。
機能フラグ:時系列プロジェクトでワークベンチを有効にする
基本を作成¶
ユースケース内から新しいエクスペリメントを作成するには、次の手順に従います。
備考
モデリングを開始ボタンをクリックして、データセットから直接モデリングを開始することもできます。 新しいエクスペリメントの設定ページが開きます。 ここから、以下の手順に従ってください。
特徴量セットを作成¶
モデリングの前に、データタブからカスタム特徴量セットを作成できます。 モデリングの設定中にそのセットを選択すると、DataRobotはそのセットの特徴量のみを使用して、モデリングデータを作成します。
新しいセットを作成するには:
- ユースケースから、モデリングするデータセットを選択し、データプレビューを開きます。
-
ページの上部にあるドロップダウンをクリックし、+ 新しい特徴量セットを選択して特徴量ビューを開きます。
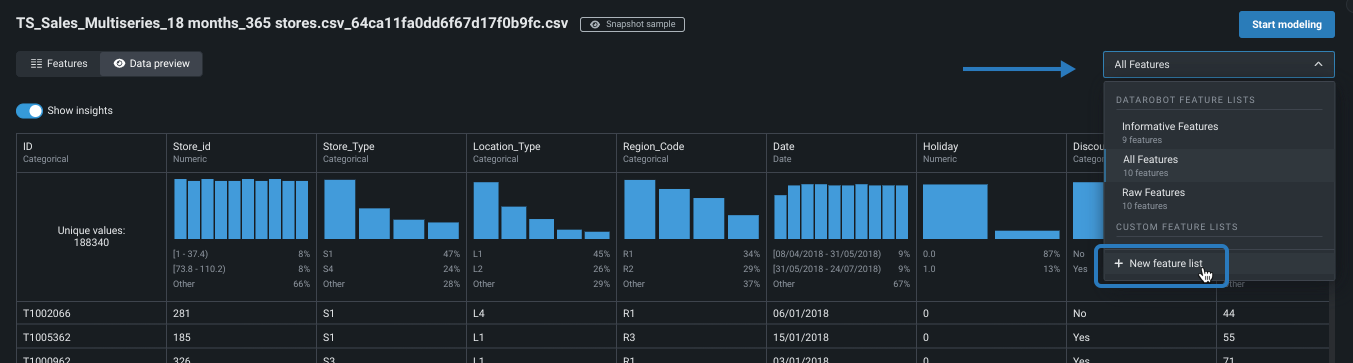
-
各特徴量の横にあるカスタムセットに含めたいチェックボックスを選択します。 次に、特徴量セットを作成をクリックし、名前と説明(オプション)を入力し、変更を保存をクリックします。
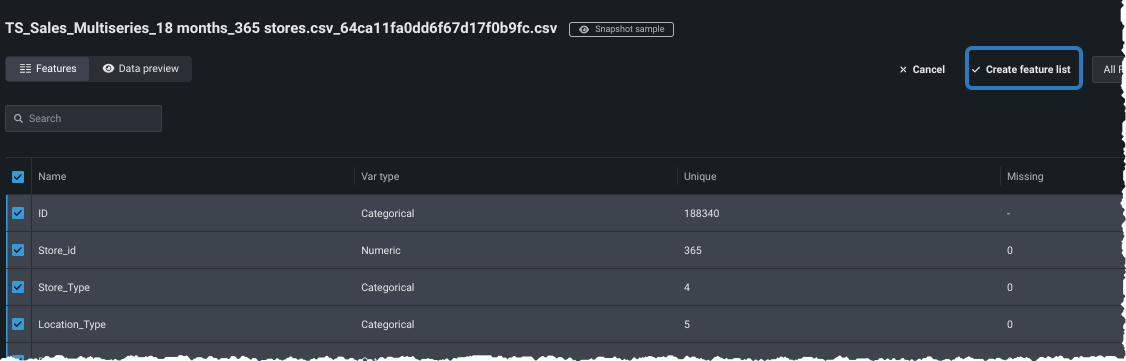
DataRobotは、特徴量派生処理の後に新しい特徴量セットを自動的に作成します。 モデリングが完了したら、時間認識セットを使用して 新しいモデルをトレーニングできます。 特徴量セットとデータタブの詳細については、 こちらを参照してください{ target=_blank }。
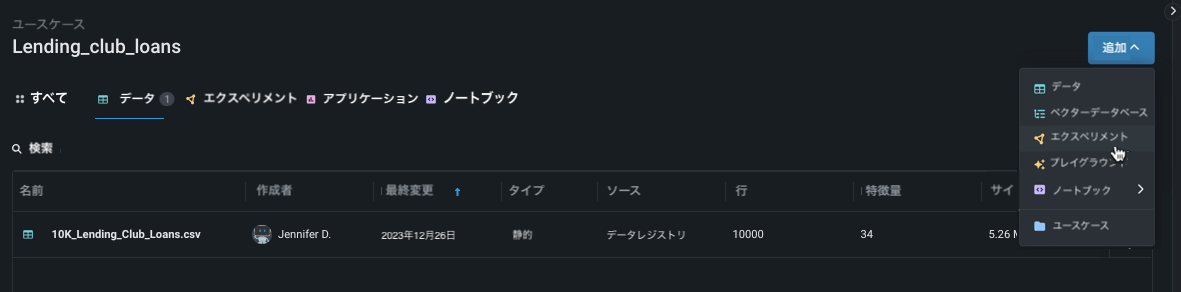
エクスペリメントを追加¶
ユースケース内から追加をクリックし、エクスペリメントを選択します。 新しいエクスペリメントの設定ページが開き、ユースケースにロード済みのすべてのデータが一覧表示されます。
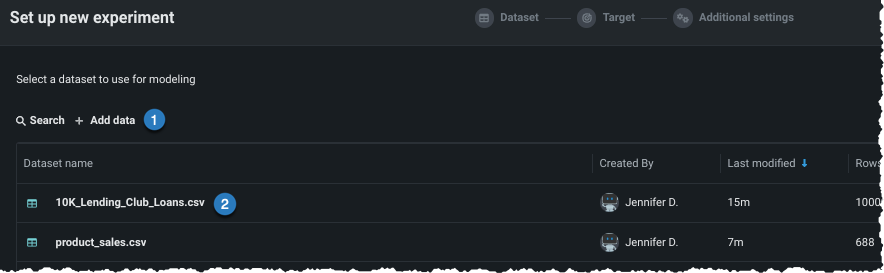
データを追加¶
新しいデータを追加 する(1)か、ユースケースに既にロードされているデータセットを選択する(2)ことにより、エクスペリメントにデータを追加します。
データがユースケースにロードされたら(上記のオプション2と同様)、エクスペリメントで使用するデータセットをクリックして選択します。 ワークベンチは、データのプレビューを開きます。
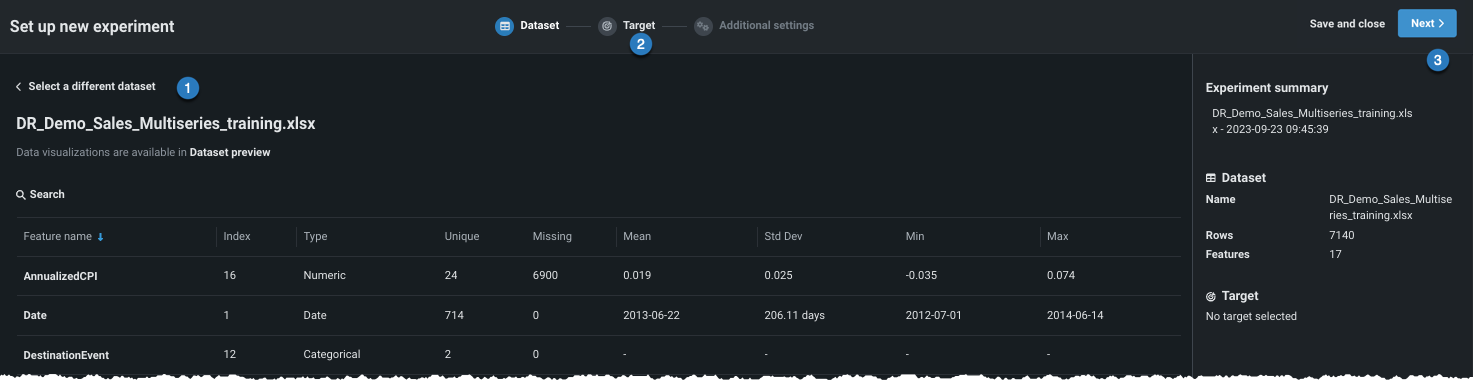
ここから、次のことができます。
| オプション | |
|---|---|
| 1 | クリックして、データリストに戻り、別のデータセットを選択します。 |
| 2 | アイコンをクリックして続行し、ターゲットを設定します。 |
| 3 | 次へをクリックして続行し、ターゲットを設定します。 |
ターゲットの設定¶
ターゲットの選択に進むと、ワークベンチでは、モデリング用のデータセットが準備されます(EDA 1)。
備考
これ以降のエクスペリメントの作成では、エクスペリメントの設定を続行しても(次へ)、終了してもかまいません。 終了を選択すると、変更を破棄するか、すべての進捗をドラフトとして保存するよう促されます。 どちらの場合でも、終了時にはエクスペリメントのセットアップを開始した時点に戻り、EDA1の処理は失われます。 終了してドラフトを保存を選択すると、ドラフトはユースケースディレクトリで利用できます。

ワークベンチで作成したドラフトをDataRobot Classicで開き、ワークベンチでサポートされていない機能を導入する変更を加えた場合、そのドラフトはユースケースにリストされますが、Classicインターフェイス以外からはアクセスできません。
EDA1が終了したとき、ターゲットを設定するには次のどちらかを実行します。
特徴量のリストをスクロールして、ターゲットを見つけます。 見つからない場合は、表示の下部からリストを展開します。
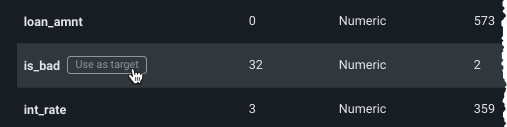
配置されたら、テーブル内のエントリーをクリックして、特徴量をターゲットとして使用します。
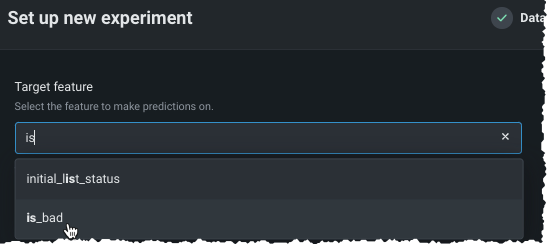
- 予測したいターゲット特徴量の名前を入力ボックスに入力します。 特徴量名の文字を入力するに従って、一致する特徴量がリスト表示されます。
DataRobotは、指定されたターゲット特徴量の値の数に応じて、自動的にエクスペリメントのタイプ(連続値または分類)を決定します。 分類エクスペリメントは、二値(二値分類)または3つ以上のクラス(多クラス)のいずれかになります。 次の表は、DataRobotが数値および非数値のターゲットデータ型にデフォルトの問題タイプを割り当てる方法を示しています。
| ターゲットデータ型 | 一意のターゲット値の数 | デフォルトの問題タイプ | 多クラス分類を使用 |
|---|---|---|---|
| 数値 | 2 | 分類 | いいえ |
| 数値 | 3+ | 連続値 | はい、オプション |
| 数値以外 | 2 | 二値分類 | いいえ |
| 数値以外 | 3-100 | 分類 | はい。自動 |
| 数値以外、数値 | 100+ | 集計された分類 | はい。自動 |
ターゲットを選択すると、ワークベンチには、ターゲット特徴量の分布に関する情報を提供するヒストグラムと、右ペインにエクスペリメント設定の概要が表示されます。
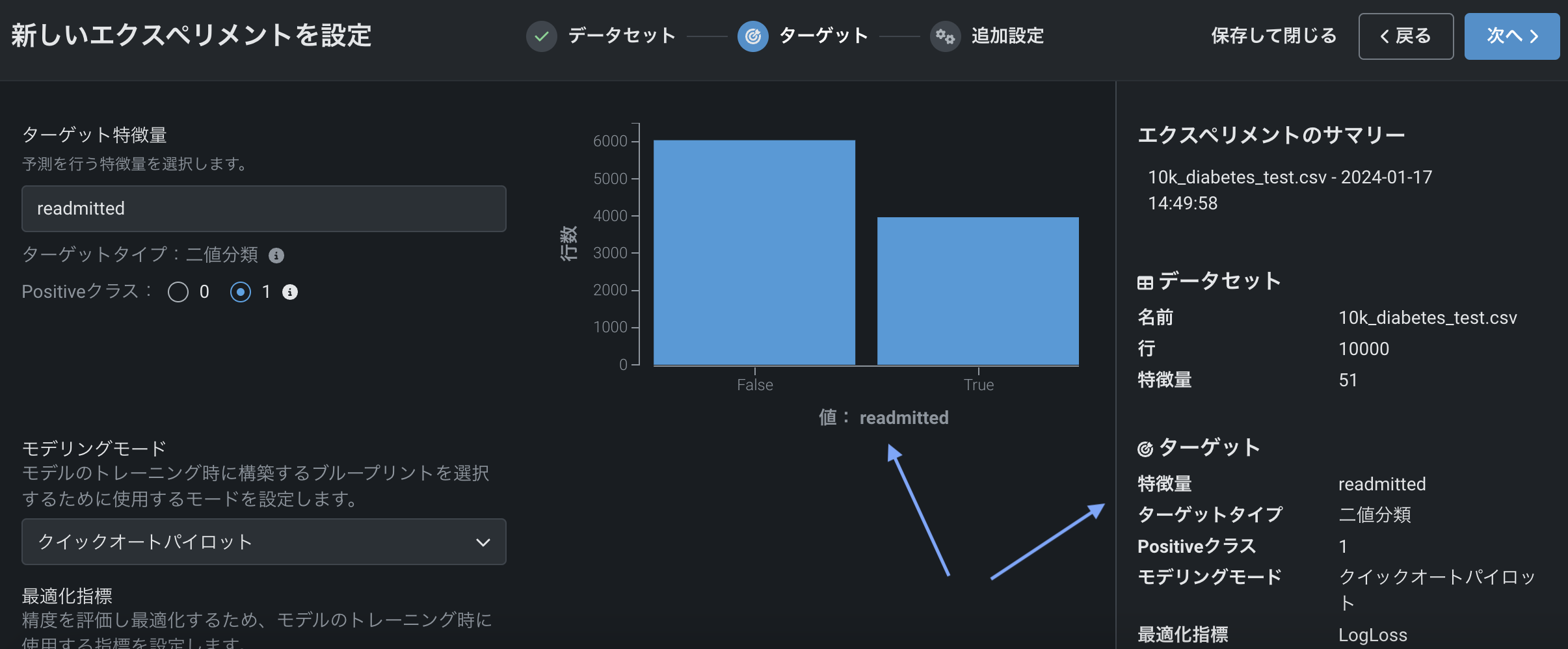
ここでは以下の操作を行うことができます。
-
連続値エクスペリメントを変更して多クラスエクスペリメントにします。
-
次へをクリックして、追加設定を表示します。そこでは、デフォルトの設定でモデルを作成したり、設定を変更したりすることができます。
-
多クラス分類エクスペリメントの場合、分類設定をさらに表示をクリックして、さらに集計設定を行います。
デフォルト設定を使用する場合は、モデリングを開始をクリックして、 クイックモードのオートパイロットモデリングプロセスを開始します。
ターゲットを入力すると、ターゲット特徴量の分布に関する情報を提供するヒストグラムがワークベンチに表示され、右側のペインにエクスペリメントのパラメーターのサマリーが表示されます。 ここから、 予測モデリングのデフォルト設定でモデルを構築できます。
エクスペリメントのサマリーで報告されたように、DataRobotがデータセットで時間特徴量(特徴量の型「日付」)を含む列を検出した場合、 時間認識モデルを構築できます。
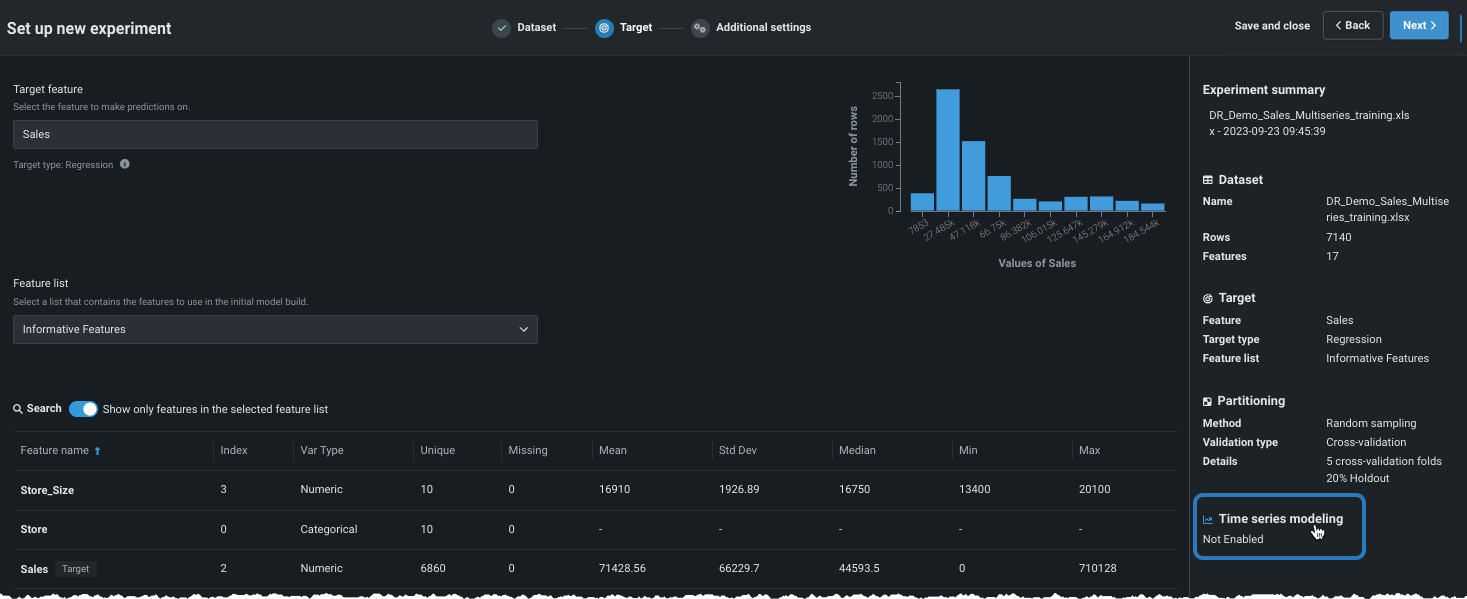
基本設定のカスタマイズ¶
時間認識モデリングを有効にする前に、いくつかの基本的なモデリング設定を変更できます。 これらのオプションは、予測モデリングと時間認識モデリングの両方に共通です。
エクスペリメントパラメーターを変更することは、ユースケースで同じ手順を繰り返すよい方法です。 モデリングを開始する前に、さまざまな設定を変更できます。
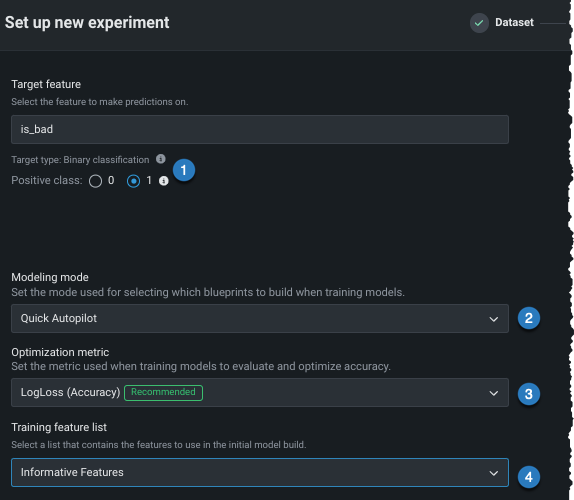
| 設定 | 変更対象 | |
|---|---|---|
| Positiveクラス | 二値分類プロジェクトの場合のみ。 予測スコアが分類しきい値よりも高い場合に使用するクラス。 | |
| モデリングモード | モデリングモード。DataRobotがトレーニングするブループリントに影響します。 | |
| 最適化指標 | DataRobotで推奨されているものとは異なる最適化指標に変更します。 | |
| トレーニング特徴量セット | DataRobotでモデルの構築に使用する特徴量のサブセット。 |
説明されている設定のいずれかまたはすべてを変更した後、次へをクリックして、より 高度な設定をカスタマイズし、 時間認識モデリングを有効にします。
モデリングモードの変更¶
デフォルトでは、DataRobotはクイックオートパイロットを使用してエクスペリメントを構築します。ただし、モデリングモードを変更することで、特定のブループリントまたは該当するすべてのリポジトリブループリントをトレーニングすることもできます。
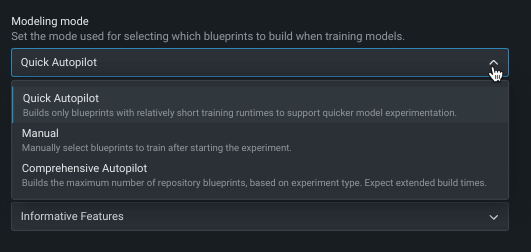
以下の表では、各モデリングモードについて説明しています。
| モデリングモード | 説明 |
|---|---|
| クイック(デフォルト) | クイックオートパイロットでは、最初に32%のサンプルサイズを使用し、その後に64%のサンプルサイズを使用して、指定されたターゲット特徴量とパフォーマンス指標に基づいてモデルのサブセットを実行し、モデルのベースセットとインサイトをすばやく提供します。 |
| 手動 | 手動モードでは、実行するブループリントを完全に管理できます。 EDA2が完了すると、DataRobotは ブループリントリポジトリにリダイレクトし、トレーニング用に1つまたは複数のブループリントを選択できます。 |
最適化指標の変更¶
最適化指標は、DataRobotによるモデルのスコアリング方法を定義します。 ターゲット特徴量を選択した後、モデリングタスクに基づいて最適化メトリックが選択されます。 通常、モデルのスコアリングのために DataRobotが選択する指標が、エクスペリメントに最適な選択です。 推奨された指標を上書きし、別の指標を使用してモデルを構築するには、最適化指標ドロップダウンを使用します。
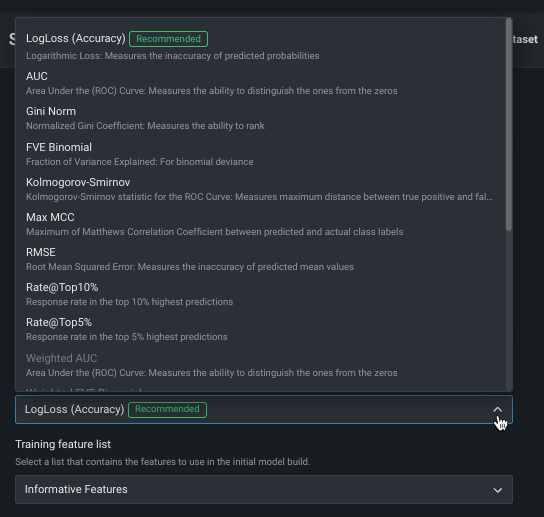
利用可能な指標の完全なリストと説明については、リファレンス資料を参照してください。
特徴量セットの変更(モデリング前)¶
特徴量セットは、DataRobotでモデルの構築に使用する特徴量のサブセットを制御します。 デフォルトでは 有用な特徴量セットですが、モデル構築の前に変更できます。 変更するには、特徴量セットドロップダウンをクリックし、別のセットを選択します。
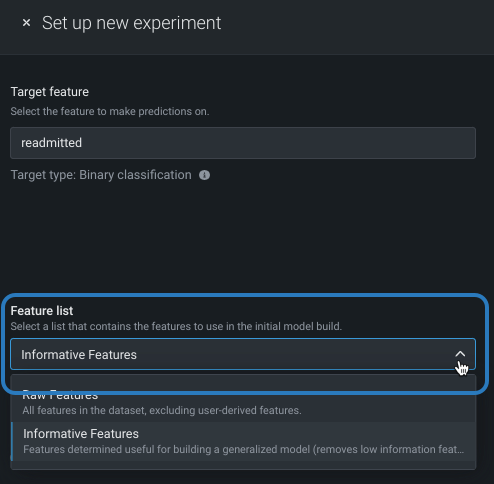
エクスペリメントの構築が終了したら、モデルごとに 選択済みリストを変更することもできます。
追加の自動化を設定¶
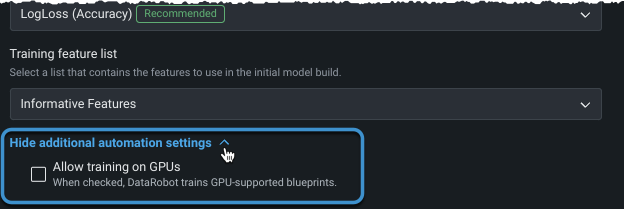
高度な設定に移動する前に、またはモデリングを開始する前に、他の自動化を設定できます。
ターゲットを設定し、基本設定を表示した後、追加の自動化設定を表示を展開して、追加のオプションを表示します。
GPUでのトレーニング¶
本機能の提供について
GPUワーカーはプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者にお問い合わせください。
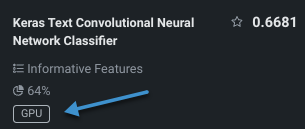
テキストや画像を含み、ディープラーニングモデルを必要とするデータセットの場合、 GPUでのトレーニングを選択すると、トレーニング時間を短縮できます。 一部のモデルはCPU上で実行できますが、他のモデルでは、適切なレスポンス時間を実現するためにGPUが必要です。 GPUでのトレーニングを許可するを選択すると、DataRobotは特定のタスクを含むブループリントを検出し、オートパイロットの実行にGPU対応のブループリントを含めます。 GPUバリアントとCPUバリアントの両方がリポジトリに用意されており、トレーニングに使用するワーカーのタイプを選択できます。GPUバリアントのブループリントは、GPUワーカーでより速くトレーニングできるように最適化されています。 GPUの使用については、以下の点を考慮してください。
- リーダーボードが生成されると、 フィルターを使用してGPUベースのモデルを簡単に識別できます。
- モデルを 再トレーニングすると、結果として得られるモデルもGPUを使用してトレーニングされます。
- 手動モードを使用すると、 ブループリントリポジトリでフィルターすることでGPU対応のブループリントを識別できます。
- 最初にGPUでトレーニングするように選択しなかった場合、リポジトリを介して、またはモデリングを再実行することで、GPU対応のブループリントを追加できます。
-
GPUでトレーニングされたモデルは、リーダーボードでバッジが付けられます。
エクスペリメントの構築が終了したら、モデルごとに 選択済みリストを変更することもできます。
追加設定を行う¶
より高度なモデリング機能を設定するには、追加設定タブを選択します。 時系列モデリングタブについては、データセットで日付/時刻特徴量が見つかったかどうかに応じて、使用可能になるかグレーアウトされます。
ビジネスユースケースに応じて、以下を設定します。
備考
時間認識設定と追加設定は、任意の順番で完了できます。
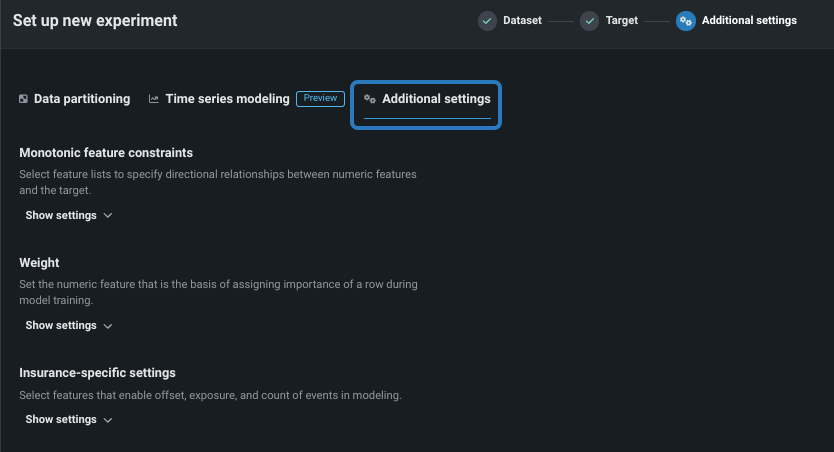
単調特徴量制約¶
単調制約は、特徴量とターゲットの間の上下方向の影響を制御します。 一部のプロジェクト(保険業や銀行業など)では、特徴量とターゲットの間の方向関係性を強制することが望ましい場合があります(評価価値の高い家屋の火災保険料が常に高くなるなど)。 単調制約でのトレーニングを行うことによって、特定のXGBoostモデルに特定の特徴量とターゲットの間の単調(常に増加または常に減少)関係性を学習させます。
単調制約特徴量を使用するには、 特殊な特徴量セットを作成する必要があります。この特徴量セットは、ここで選択されます。 また、手動モードを使用する場合、使用可能なブループリントにはMONOバッジが付けられ、サポートされるモデルを識別できます。
ウェイト¶
ウェイト違いを表す重みとして使用し、各行の相対的な有用性を示す単一の特徴量を設定します。 これは、モデルの構築やスコアリングの際に、リーダーボードで指標を計算する目的で使用されます。新しいデータで予測を行う目的では使用されません。 選択した特徴量のすべての値が0より大きい値である必要があります。DataRobotでは検定が行われ、選択した特徴量にはサポートされている値のみが含まれているかどうかが確認されます。
時間認識モデルの有効化¶
時間認識モデリングは、分割手法として日付/時刻に基づいています。 時間認識モデリングには2つのタイプがあります。
- シンプルな 日付/時刻パーティション。行を時系列でバックテストに割り当てます。
- 時系列モデリングは、ターゲットの複数の値を予測します。
両方のワークフローは分割から始まります。 単なる予測ではなく時系列予測が必要な場合、またはDataRobotの自動化された 時系列特徴量エンジニアリングを利用する場合は、時系列モデリングタブでセットアップを続行します。
graph TB
A(時間認識モデリングの開始)--> B[日付/時刻パーティションの有効化];
B --> C[順序付け特徴量の設定];
C --> D[バックテストパーティションの設定];
D --> E[サンプリングの設定];
E --> F{単なる予測か時系列予測か?} --> | 予測|G[モデリングの開始];
F --> |予測|H[時系列モデリングの有効化]
H --> I[エクスペリメントのセットアップを続行]
I --> J[モデリングの開始] 日付/日付範囲の表現
DataRobotでは、データ内の日付および日付範囲を表現するために日付ポイントが使用されます。以下の原則が適用されます。
- すべての日付ポイントはISO 8601、UTC(「2016-05-12T12:15:02+00:00」など)に準拠します。これは、日付と時刻を表現するために国際的に受け入れられている方法です。期間形式には若干のバリエーションがあります。 具体的には、ISO週間(P5Wなど)のサポートはありません。
- モデルは、2つのISO日付の間のデータでトレーニングされます。 これらの日付は、DataRobotで1つの日付範囲として表示されますが、含める日付の決定とすべての主要な境界は日付ポイントとして表現されます。 日付を指定すると、開始日が含まれ、終了日が除外されます。
- 日付パーティショニング列を使用する形式を変更すると、プロジェクトのすべてのチャートやセレクターなどが、その形式に変換されます。
- 分割の年/月/日の設定を変更すると、可能な場合は月と年の値は大きいクラスに合わせて調整される点に注意してください(たとえば、24か月は2年になります)。 しかし、DataRobotではデータに関連付けるときに閏年や月の閏日を考慮できないので、日を上位のコンテナに変換できません。
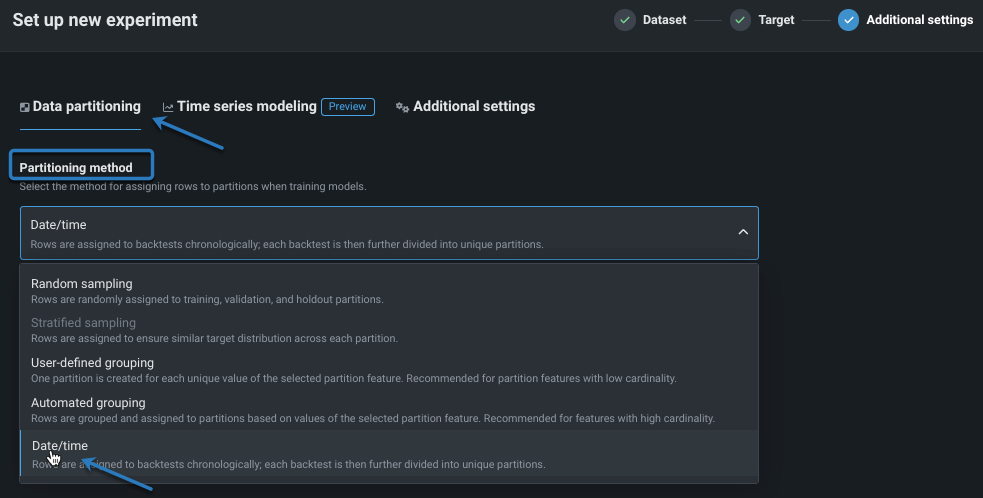
1. 日付/時刻パーティションの有効化¶
時間認識モデリングを有効にするには、最初に分割手法を日付/時刻に設定します。 これを行うには、次のいずれかを実行します。
- データパーティショニングタブを開きます。
- エクスペリメントサマリーパネルでパーティションをクリックすると、データパーティショニングタブが開きます。
データパーティショニングタブで、分割手法として日付/時刻を選択します。
2. 順序付け特徴量の設定¶
分割手法を日付/時刻に設定した後、 順序付け特徴量(DataRobotがモデリングに使用するプライマリー日付/時刻特徴量)を設定します。
備考
その他のすべての設定は、変更することも、デフォルトのままにすることもできます。 エクスペリメントのサマリーは、セットアップが進むにつれて更新されます。
順序付け特徴量を選択します。 対象となる特徴量が1つだけ検出された場合、フィールドに自動入力されます。 複数の特徴量が使用可能な場合は、ボックス内をクリックすると、該当するすべての特徴量のリストが表示されます。 特徴量がリストされていない場合、タイプdateとして検出されず、使用できません。
設定後、DataRobotは次の操作を行います。
-
DataRobotで、選択した特徴量の日付および時刻の形式(標準のGLIBC文字列)が検出されます。順序付けの特徴量が選択されると、DataRobotは、以下の選択した特徴量の日付および/または時刻の形式(標準GLIBC文字列)を検出して報告します。

-
順序付け特徴量の時間経過に伴う特徴量ヒストグラムを計算してロードします。 データセットが複数系列のモデリング条件を満たす場合、このヒストグラムは、ターゲット特徴量に対してプロットされたすべての系列にわたる時間特徴量値の平均を表します。

3. バックテストパーティションの設定¶
順序付け特徴量を設定すると、バックテスト設定が使用可能になります。 バックテストは交差検定の時系列版に相当しますが、ランダム行ではなく時間範囲または期間に基づきます。 DataRobotでは、データセットの特性に基づいてデフォルトが設定されており、通常はそのままで、堅牢なモデルを実現できます。
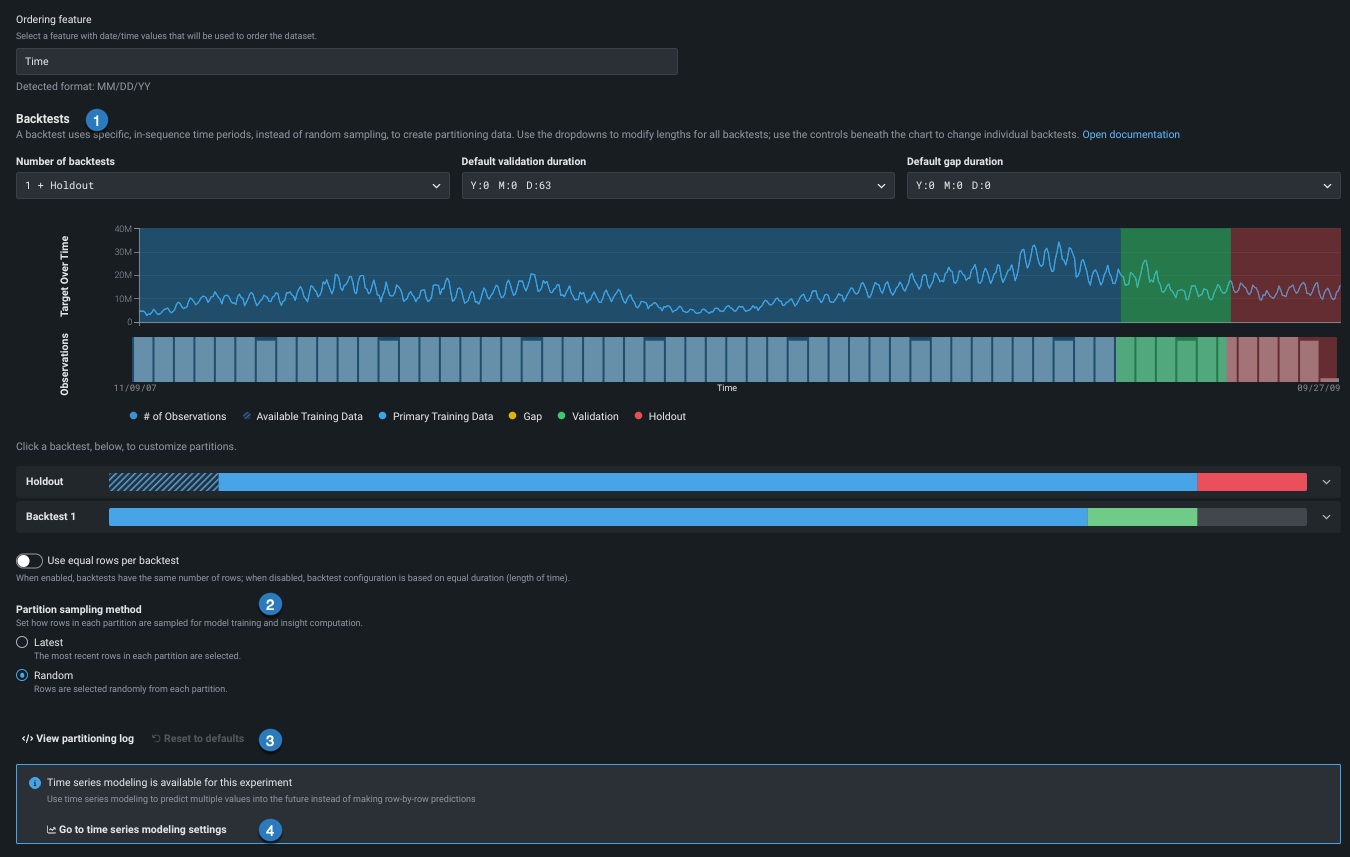
デフォルト設定を変更するには、以下の表のリンクを使用します。
| フィールド | 説明 | |
|---|---|---|
| 1 | バックテスト | バックテストパーティションの 数と 期間を設定します。 |
| 2 | 行の割り当て | バックテストへの行の割り当て方法とサンプリング方法を設定します。 |
| 3 | パーティションログ / リセット | パーティションの作成を報告するダウンロード可能なログと、リセットリンクを提供します。 |
| 4 | 時系列モデリング設定 | 予測を有効にして追加オプションを利用するには、時系列モデリングタブを開きます。 |
バックテストの数の変更¶
最初に、必要に応じてバックテストの数を変更します。
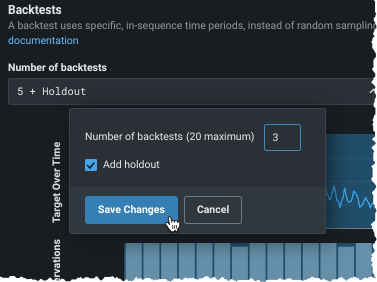
バックテストのデフォルトの数は、プロジェクトパラメーターに依存しますが、最大20まで設定できます。バックテストの数を設定する前に、ヒストグラムを使用して、各分割のトレーニングセットと検定セットにモデルのトレーニングに十分なデータがあることを確認します。
バックテストの要件
- OTVの場合、バックテストでは、各検定およびホールドアウト分割に少なくとも20行が必要で、各トレーニング分割に少なくとも100行が必要です。 その条件を満たさない結果が生じるバックテストを設定した場合、DataRobotでは、最小限の条件を満たすバックテストだけが実行されます(該当するバックテストにはアスタリスクが表示されます)。
- 時系列の場合、バックテストでは、検定およびホールドアウトに少なくとも4行が必要で、トレーニング分割に少なくとも20行が必要です。 多数のバックテストを設定しても、その条件を満たすパーティションがない場合、プロジェクトが失敗する可能性があります。 詳細については、 時系列パーティショニングのリファレンスを参照してください。
パーティションの期間を変更¶
次に、バックテストパーティションを設定。 設定を変更しない場合、DataRobotは行をバックテストに均等に分散します。 ただし、バックテストのギャップ、トレーニング、検定、ホールドアウトのデータは、次のいずれかの方法でカスタマイズできます。
- エクスペリメント内のすべてのバックテストにグローバルに適用するには、ドロップダウンを使用します。
- 個々のバックテストに変更を適用するには、表示されているバーをクリックします。 個々の設定はグローバル設定を上書きします。 個々のバックテストの設定を変更すると、編集したバックセットにはグローバル設定の変更は適用されません。
エクスペリメントの設定にバックテストを追加すると、使用されるトレーニングデータの期間が短縮されます。 検定とギャップは、ドロップダウンで設定された期間に維持されます(バックテストごとに個別に変更されていない場合)。
デフォルトのパーティション設定を確認し、必要に応じてクリックして変更を加えます。
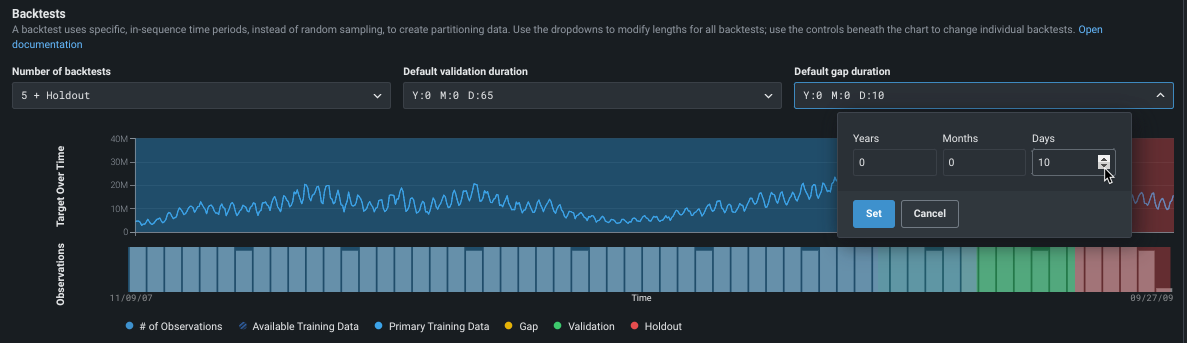
ここでは、各パーティションのアプリケーションの概要を示しますが、詳細についてはリンクされた資料を参照してください。
| パーティション | 説明 |
|---|---|
| デフォルトの検定期間 | モデルパフォーマンスの評価に使用されるトレーニングセットの一部ではないテスト—データに使用されるパーティションのサイズを設定します。 |
| デフォルトのギャップ期間 | モデルトレーニングとモデルデプロイの間のギャップを表す時間のスペースを設定します。 はじめはゼロに設定されており、テストでギャップは処理されません。 設定すると、モデルのトレーニングまたは評価に使用するギャップに相当するデータが拡張されます。 |
テストの表示で変更がどのように反映されるかに注意してください。
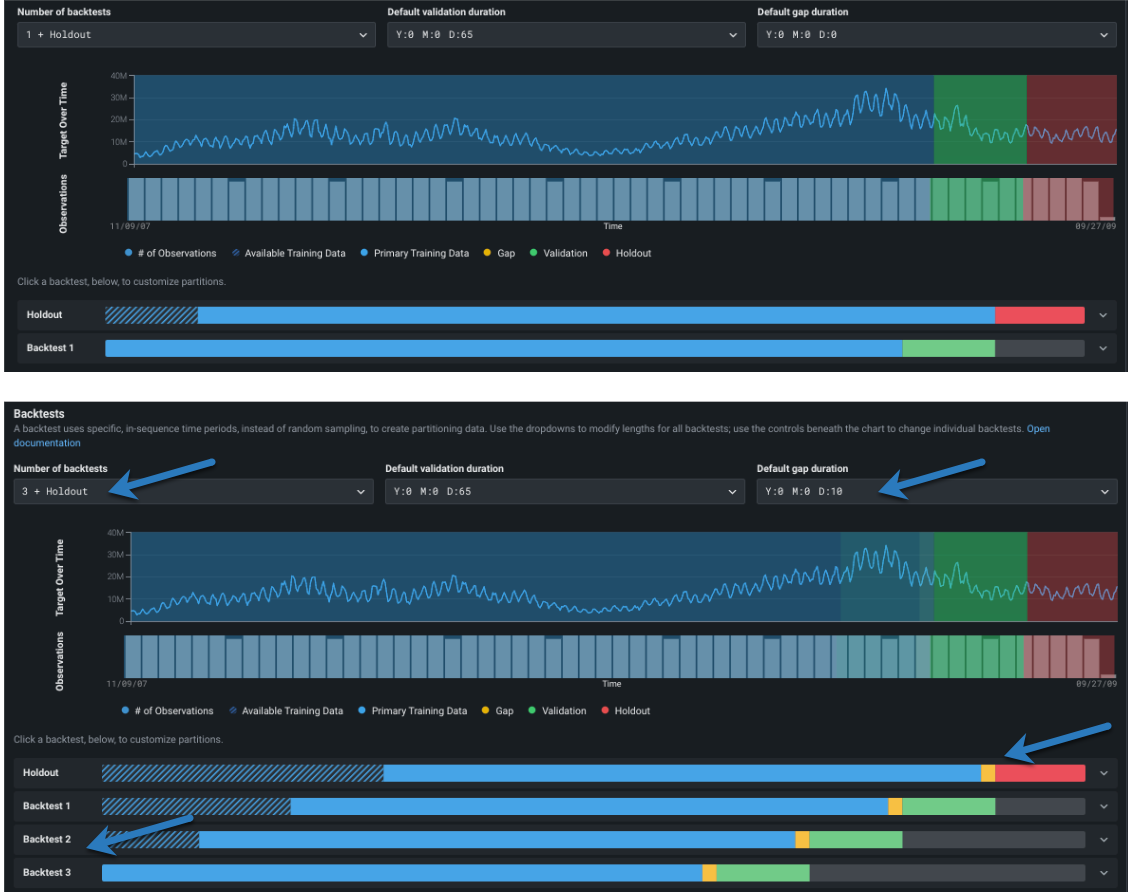
個々のバックテストパーティションの設定¶
どのパーティションに設定する(トレーニング、検定、ギャップ)かに関係なく、編集画面の要素の機能は同じです(ホールドアウトは多少違います)。 個々のバックテストの期間を変更するには、最初にカラーバンドにカーソルを合わせると、特定の期間設定の詳細が表示されます。

次に、個々のバックテストの期間を修正するには、バックテストをクリックして入力を開きます。

バックテストは、開始日と終了日、または開始日と期間のいずれかに基づいています。 ギャップトグル パーティション間のギャップを追加に設定して有効にすることは、日付または期間設定から派生します。 つまり、ギャップは、トレーニング終了と検定開始の間の時間ステップを残すことによって作成されます(ギャップがない場合は同じです)。
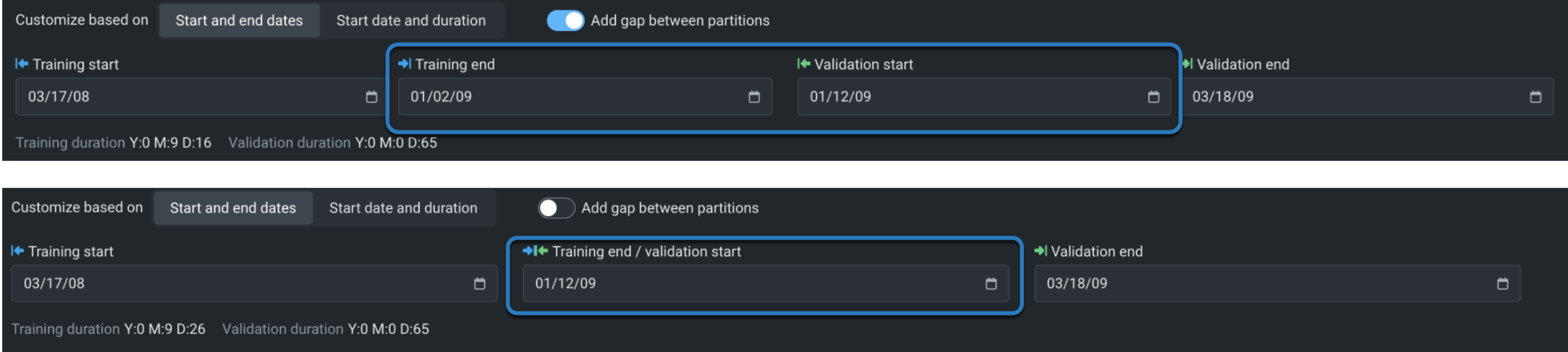
開始日と終了日に基づいてカスタマイズするには:
- ギャップありで、トレーニングと検定の両方の開始と期間を設定します。
- ギャップなしで、トレーニングの開始、トレーニング期間、検定期間を設定します。
開始日と期間に基づいてカスタマイズするには:
- ギャップありで、トレーニングと検定の開始と終了を設定します。
- ギャップなしで、トレーニングの開始、トレーニングの終了、検定の開始、検定の終了を設定します。
いずれの場合でも、DataRobotはエントリーを検証し、必要な変更があれば報告します。
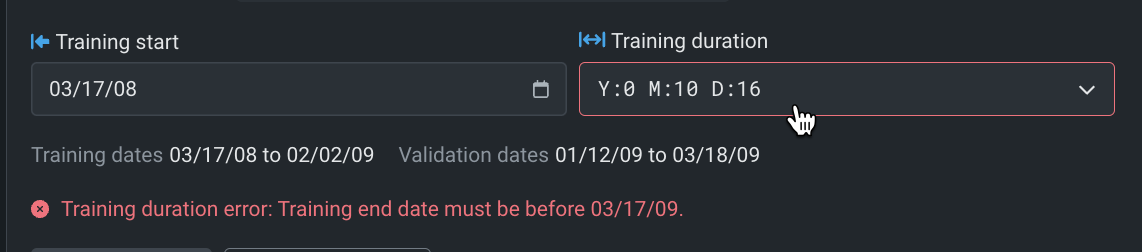
次に、有効なことを報告し、入力ボックスの下に時間ウィンドウを設定します。

設定が完了したら、変更を保存をクリックします。
データ要素を変更すると、バックテストに編集済みラベルが追加されます。 初期値に戻すリンクを使用して、バックテストの期間または数をデフォルト設定に手動でリセットできます。
ホールドアウトを変更¶
デフォルトでは、プロジェクト内のトレーニングモデルのホールドアウト分割が作成されます。
ホールドアウトを変更する際の注意事項
- 一般的に、ホールドアウトはエクスペリメントに大きく依存しますが、合計期間の約10%で、 n 週間、 n か月などの"自然"時間枠に丸めることができます。 (これは、単純な時間認識か時系列かによって異なります。) DataRobotの計算の説明については、パーティショニングログを参照してください。
- 設定できるのはホールドアウトバックテストのホールドアウトだけで、そのバックテストのトレーニングデータサイズを変更することはできません。 DataRobotは、ホールドアウトバックテストのトレーニングパーティションを自動的に設定します。
- 最初のパーティショニング検出中に、順序付け(日付/時刻)特徴量、系列ID、またはターゲットのバックテスト設定には、検定とホールドアウトの両方をカバーするのに十分な行がない場合、DataRobotは自動的にホールドアウトを無効化します。 他のパーティショニング設定(検定やギャップ期間、開始/終了日など)が変更された場合、手動で無効にしない限り、ホールドアウトは影響を受けません。
ホールドアウトの長さを変更するには、ホールドアウトバックテストをクリックして入力を開き、新しい値を入力します。
- 開始日と終了日に基づいてカスタマイズするには、ホールドアウトの開始日と終了日を入力します。
- 開始日と期間に基づいてカスタマイズするには、ホールドアウトの開始と期間を入力します。
トレーニングの時間範囲とギャップ設定は自動的に設定され、ホールドアウトバックテストでは変更できないことに注意してください。

備考
場合によっては、ホールドアウトセットなしでのプロジェクト作成が望ましいことがあります。 ホールドアウトを追加ボックスをオフにします。 検定とホールドアウトを切り替えるオプションのあるインサイトには、ホールドアウトオプションが表示されません。
4. サンプリングの設定¶
バックテストが完了したら、 行の割り当てとサンプリング方法を設定します。
行の割り当て¶
デフォルトでは、各バックテストの期間(デフォルト、またはドロップダウンか視覚化のバーで設定した値)は同じになります。 バックテストで同じ時間の長さではなく、同じ数の行を使用する場合は、1つのバックテストと等しい行数トグルを使用します。
備考
時系列プロジェクトには、特徴量エンジニアリングの期間中に使用されるトレーニングデータの行の割り当て(行数または期間)を設定するオプションもあります。 この設定は、 トレーニングウィンドウの形式セクションで設定します。
-
1つのバックテストと等しい行数を選択(パーティションが行ベースの割り当てに設定されます)した場合、適用できるのは「トレーニング終了日」だけです。
-
時系列のエクスペリメントでは、1つのバックテストと等しい行数をオンにすると、表示される日付は情報提供の目的のみ(近似)になり、特徴量の派生および予測ポイントウィンドウで設定されたパディングが含まれます。
サンプリング方法¶
バックテストにデータを割り当てるためのメカニズム/モードを選択したら、サンプリング方法(ランダムまたは最新)を選択して、データセットから行を割り当てる方法を選択します。
サンプリング方法の設定は、データセットが時間の経過とともに均等に分散されない場合に特に役立ちます。 たとえば、データが最新の日付に偏っている場合、ランダム行50%と最新の行50%の結果はまったく異なります。 データをより正確に選択することで、DataRobotがトレーニングするデータをより細かく制御できます。
初期値に戻す¶
バックテスト設定を変更して保存すると、バックテストにはバッジ(編集済み)が表示されます。 初期値に戻すリンクを使用して、バックテストの期間または数をデフォルト設定に手動でリセットできます。 時系列エクスペリメントの場合、このアクションではウィンドウ設定はリセットされません。
単なる予測か時系列予測か?¶
予測モデリングでは、モデリング設定を確認したら、モデリングを開始をクリックしてクイックモードのオートパイロットモデリング処理を開始します。
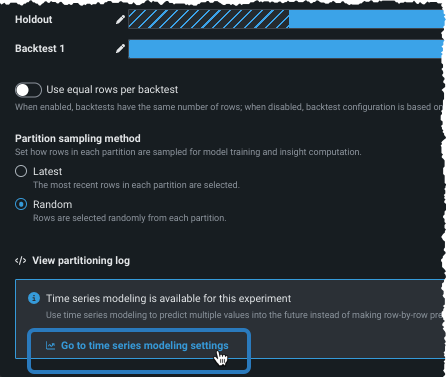
時系列予測では、エクスペリメントが適格である場合、時系列モデリング設定に移動をクリックして時系列モデリングタブを開き、設定を続行します。
5. 時系列設定を続行¶
時系列モデリングは、系列IDの識別(該当する場合)、モデリング用の派生した特徴量セットの作成の開始、予測のその他の詳細などのオプションのセットを追加します。
時間認識モデリングを開始するエクスペリメントを作成するには、以下を選択できます。
-
時間関連データの日付/時刻パーティション設定ページから時系列モデリング設定に移動します。
-
エクスペリメントのサマリーパネルの時系列モデリング。
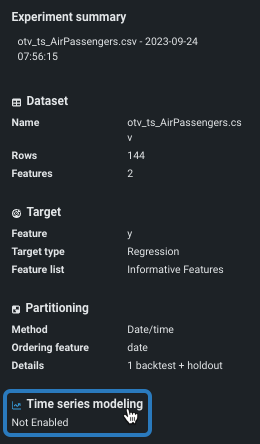
いずれかのオプションを選択すると、時系列モデリングタブの設定が開きます。 設定は、データパーティショニングタブ(順序付け特徴量とバックテスト)から継承されます。 必要に応じて、参照して完了します。
時系列エクスペリメントの設定には、以下の追加設定を使用できます。
- 順序付け特徴量の選択
- 系列IDの設定(複数系列プロジェクトの場合)
- ウィンドウ設定のカスタマイズ
- その他のオプション機能の設定
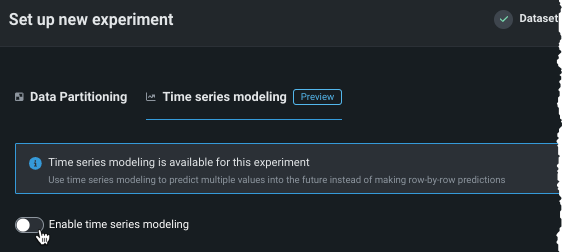
系列IDを設定¶
データで重複するタイムスタンプが検出された場合、DataRobotには 複数系列モデリングを設定するためのオプションがあります。 複数系列モデリングでは、重複するタイムスタンプを含むデータセットをモデル化できます。その場合、複数の個々の時系列データセットとして処理できます。 各行が属する系列を示す系列識別子を選択します。
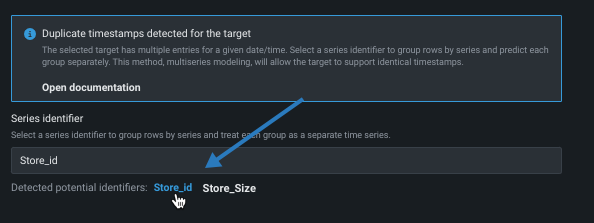
ウィンドウ設定のカスタマイズ¶
DataRobotには、データセットの特性に基づいて、デフォルトのウィンドウ設定である特徴量派生ウィンドウ(FDW)と予測ウィンドウ(FW)の機能があります。 これらの設定は、特徴量派生処理に使用される 基本的なフレームワークを定義することによって、DataRobotがモデリングデータセットの特徴量を派生する方法を決定します。 通常、そのままにしておくことができます。

次の表では、画面のウィンドウ設定セクションの要素を簡単に説明します。
重要
これらの値を変更する場合は、各ウィンドウの意味と意味合いについて、 詳細なガイダンスを参照してください。
| オプション | 説明 | |
|---|---|---|
| 1 | 特徴量の派生ウィンドウ (FDW) | DataRobotがモデリングデータセットの 特徴量派生に使用するデータ期間を設定します。 |
| 2 | リストされた特徴量を派生から除外する | 時間ベースの特徴量エンジニアリングの自動化から特定の特徴量を除外します(独自の時間指向の特徴量を抽出し、その特徴量で追加の派生処理を実行しない場合など)。 オプションをオンに切り替え、ドロップダウンから特徴量を選択します。 |
| 3 | 予測ウィンドウ | 予測ポイントの後にモデルが出力する予測の時間範囲を設定します。 |
| 4 | ウィンドウの概要 | ウィンドウ設定をグラフィカルに表示します。 ウィンドウの値を変更すると、すぐに表示に反映されます。 |
その他のオプション機能の設定¶
オプションで2つのエクスペリメント設定を追加できます。
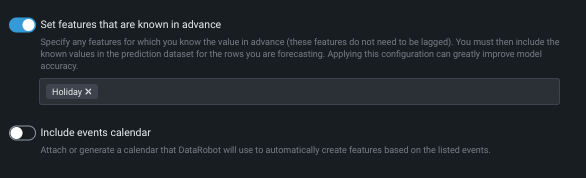
事前に既知の特徴量を設定を使用して、モデリング時に値が既知である特徴量を除外します。 このオプションで特徴量が識別された場合、モデリングデータを派生するときにラグは作成されません。 一部の変数が事前に既知であることを示し、予測時間を指定することにより、予測精度が大幅に向上します。 特徴量が既知としてフラグが付けられている場合、その将来の値は予測時に提供されなければなりません。 このオプションを使用するには、オンに切り替え、ドロップダウンから特徴量を選択します。
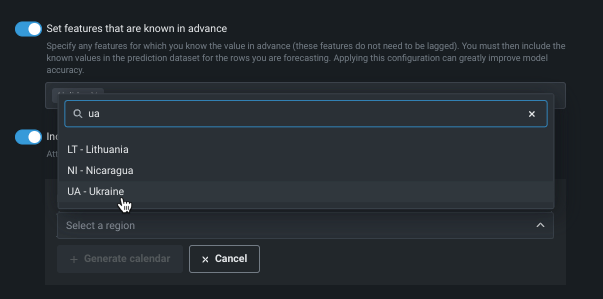
イベントカレンダーを含めるを使用し、さらなる注意が必要な日付やイベントを指定するイベントファイルのアップロードまたは生成を行います。 DataRobotはファイルを使用して、リストされたイベントに基づいて特徴量を自動的に作成します。 ローカルファイルまたはデータレジストリに保存されているファイルを選択できます。 または、カレンダーを生成をクリックして、選択した地域に基づいてイベントのファイルを生成します。
6. 予測モデリングを開始¶
モデリング設定(エクスペリメントのサマリーに要約されています)に問題がないことを確認したら、モデリングを開始をクリックします。 モデリングプロセスが開始されると、DataRobotはターゲットを分析し、モデリングに使用する時間ベースの特徴量を作成します。 You can control the number of workers applied to the experiment from the queue in the right panel. Increase or decrease workers for your experiment as needed.
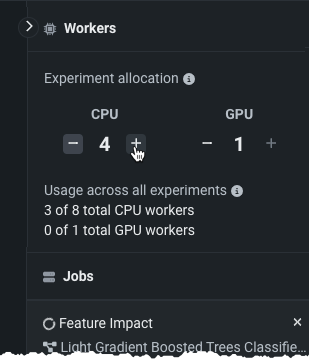
From there, you can also view the jobs that are running, queued, and failed. Expand the queue, if necessary, to see the running jobs and assigned workers.

次のアクション¶
モデリングを開始すると、DataRobotでリーダーボードにモデルが入力されます。 以下を実行することが可能です。
- 使用可能なモデルで モデル評価を開始します。
- エクスペリメント情報を表示オプションを使用すると、モデルに関するさまざまな情報を表示できます。
- モデルの構築に使用されたデータである派生モデリングデータを表示します。
派生したモデリングデータの詳細については、以下のセクションを参照してください。