レシピの構築¶
レシピの構築は、データの準備の第一歩です。 ラングリングセッションを開始すると、DataRobotはデータソースに接続し、ライブのランダムサンプルを取得し、そのサンプルで探索的データ解析を実行します。 レシピに操作を追加すると、変換がサンプルに適用され、探索的データインサイトが再計算されるため、パブリッシュ前にデータをすばやく反復処理してプロファイルを作成できます。
ラングリング要件
データをラングリングするには、 設定済みのデータ接続を使用してデータセットを追加する必要があります。
本機能の提供について
The ability to perform wrangling and pushdown on datasets stored in the Data Registry is off by default. この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
To wrangle Data Registry datasets, you must first add the dataset to your Use Case. Then, you can begin wrangling from the Actions menu next to the dataset. Note that this feature is only available for multi-tenant SaaS users and installations with AWS VPC or Google VPC environments.
機能フラグ:データレジストリのデータセットでラングリングのプッシュダウンを有効にする
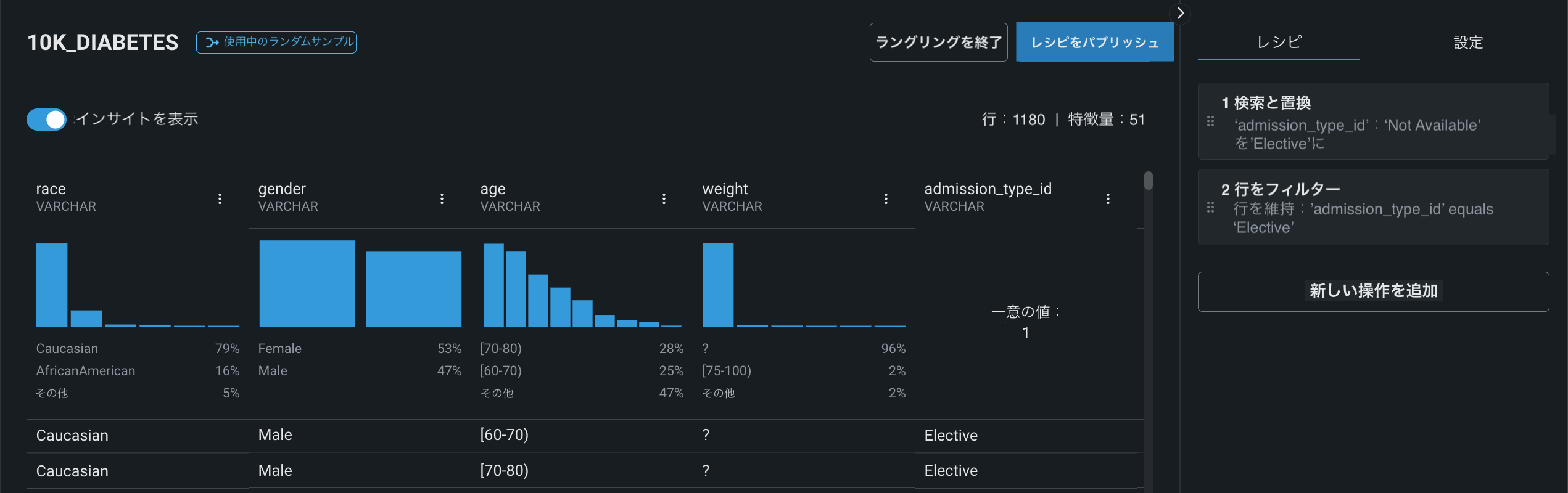
ユースケースでデータセットをラングリングする際(同じデータセットを再度ラングリングする場合も含む)、操作を追加したかどうかに関係なく、データタブにレシピのコピーが作成されて保存されます。 その後、レシピを変更するたびに、変更内容が自動的に保存されます。 さらに、保存されたレシピを開いて変更を続けることができます。
こちらもご覧ください。
- その他の重要情報については、関連する 注意事項を参照してください。
- ワークベンチで利用可能な接続と、それらの接続がサポートする機能の完全なリスト。
- 大規模なSnowflakeデータセットのラングリングでパフォーマンスを向上させるためのヒント。
ラングリング設定の変更¶
レシピでは、設定を変更して、後で使用できるようにサマリー情報をよりわかりやすくしたり、ライブプレビューに含まれる行数を変更したりできます。
レシピメタデータの編集¶
デフォルトでは、DataRobotはソースデータに基づいて各ラングリングレシピに名前と説明を割り当てますが、この情報を変更して、特定のユースケースに適用しやすくすることができます。
レシピメタデータを編集するには:
-
タイトルまたは説明のいずれかを編集するフィールドにカーソルを合わせます。 次に、フィールドまたは右側の鉛筆アイコンをクリックします。

-
名前または説明を変更します。完了したら、フィールド外または右側のチェックマークをクリックして変更を保存します。

ライブサンプルの設定¶
デフォルトでは、DataRobotはライブサンプルで10000行をランダムに取得しますが、この数とサンプリング方法は、ラングリング設定で変更できます。 取得する行が多いほど、ライブサンプルのレンダリングに時間がかかることに注意してください。
ライブサンプルを設定するには:
-
右側のパネルで設定をクリックし、プレビューサンプルを開きます。
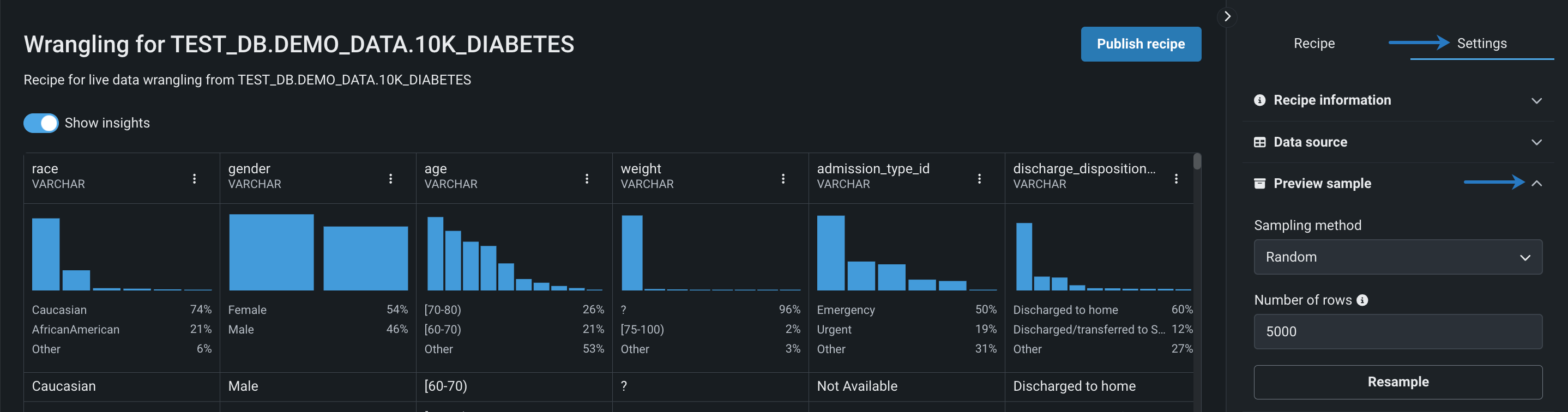
-
サンプリング方法を選択します。 ドロップダウンを使用して、サンプリング方法(ランダムまたは先頭のN行)を選択します。
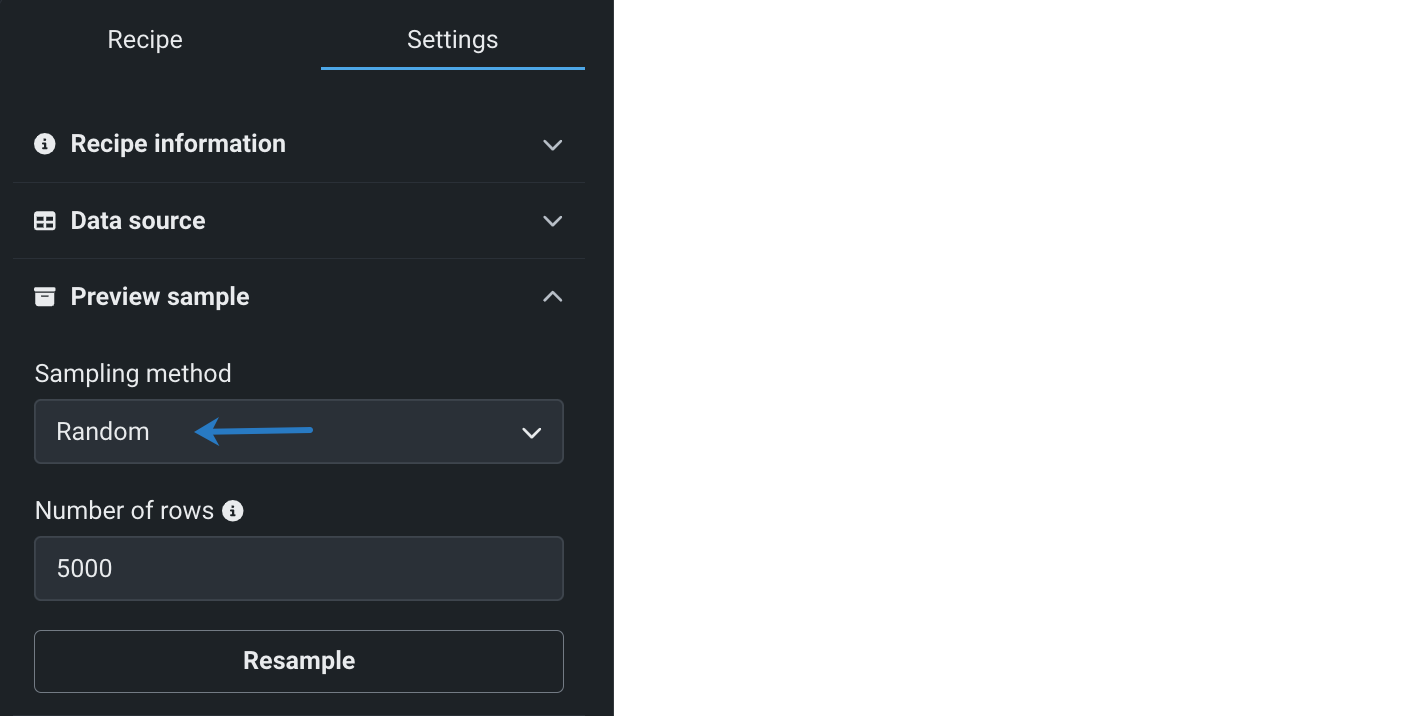
-
ソースデータから取得する行数を指定します。 ライブサンプルに含める行数(10000未満)を入力して、再サンプリングをクリックします。 ライブサンプルが更新され、指定された行数が表示されます。
ライブサンプルを分析¶
データのラングリング中、DataRobotはライブサンプルに対して探索的データ解析を実行して、表レベルおよび列レベルの サマリー統計と 視覚化を生成します。これは、データセットのプロファイリングや、操作を適用する際のデータ品質の問題の認識に役立ちます。 ライブサンプルの操作の詳細は、 探索的データインサイトのセクションを参照してください。
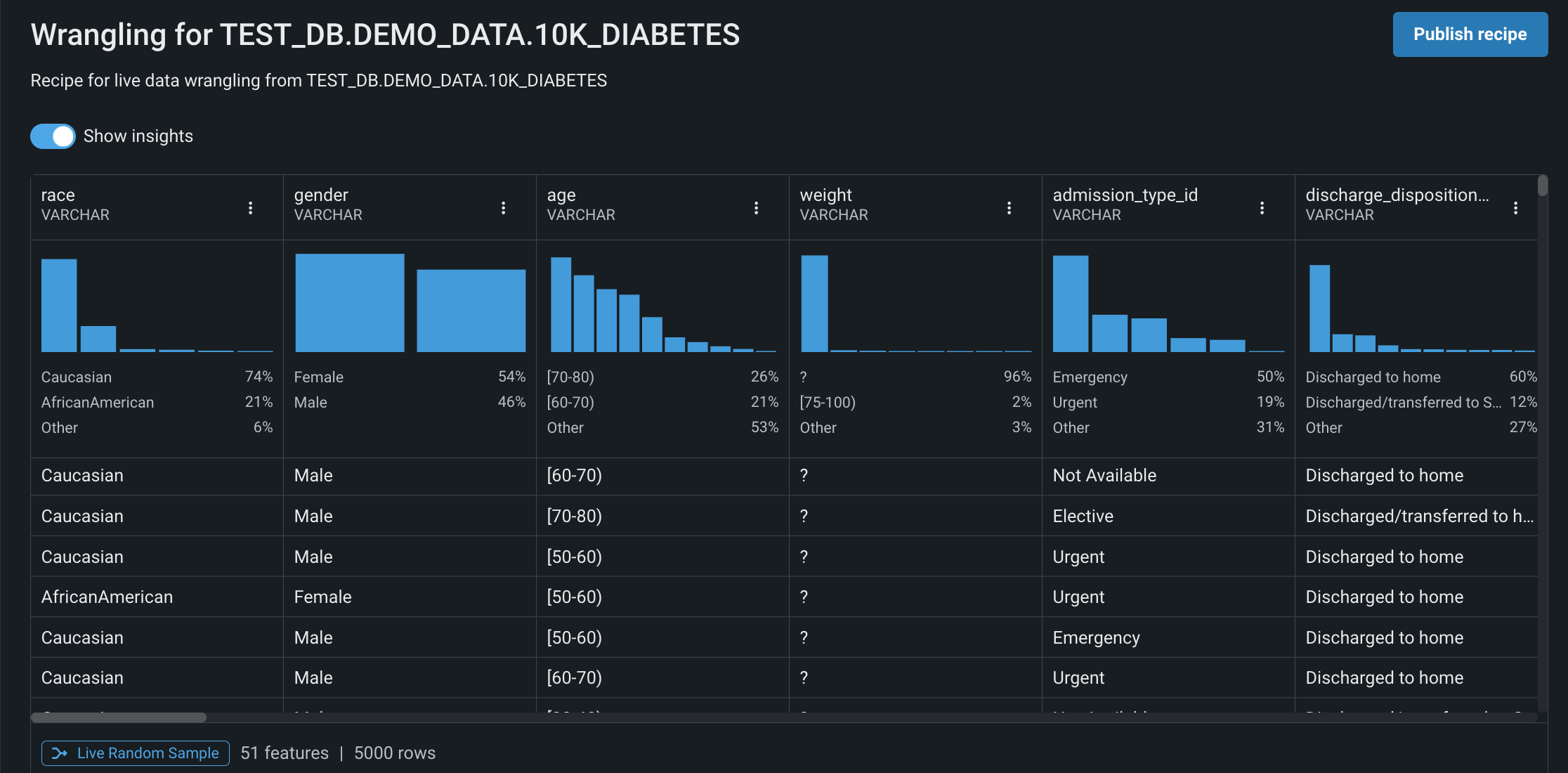
ライブサンプルの高速処理
ライブサンプルの取得とレンダリングにかかる時間を短縮するには、インサイトを表示の横にあるトグルを使用して、特徴量分布チャートを非表示にします。
データタブでのライブサンプルと探索的データインサイトの比較
両方のページには同様のインサイトがありますが、ライブサンプルに表示される行数を指定でき、これはレシピに変換を追加するたびに更新されます。
操作の追加¶
レシピは、モデリングの準備を行うためにソースデータに適用される変換である操作で構成されています。 操作は連続して適用されるので、望ましい結果を得るには、レシピで 操作を並べ替える必要となる場合があることに注意してください。
操作の挙動
ラングリングレシピが接続先のクラウドデータプラットフォームにプッシュダウンされると、その環境で操作が実行されます。 操作がどのように動作するかを理解するには、お使いのデータプラットフォームのドキュメントを参照してください。
データセットがDataRobotでマテリアライズされ、ユースケースに追加されると、データタブに移動し、プッシュダウン中にクラウドデータプラットフォームによって どのクエリーが実行されたかを表示できます。
以下の表は、ワークベンチで現在利用できるラングリング操作について説明したものです。
| 操作 | 説明 |
|---|---|
| 結合 | 同じ接続インスタンスからアクセスできるデータセットを結合します。 |
| 集計 | データセット内の特徴量に数学的集計を適用します。 |
| 新しい特徴量を計算 | スカラーサブクエリ、スカラー関数、またはウィンドウ関数を使用して、新しい特徴量を作成します。 |
| 行をフィルター | 指定した値と条件に従って、データセットの行をフィルターします。 |
| 重複行の排除 | データセットから重複する行をすべて自動的に削除します。 |
| 検索と置換 | データセットに含まれる特定の特徴量の値を置き換えます。 |
| 特徴量名を変更する | データセットに含まれる1つまたは複数の特徴量の名前を変更します。 |
| 特徴量の削除 | データセットから1つまたは複数の特徴量を削除します。 |
アンバランスなデータセットに対してマジョリティークラスのダウンサンプリングを実行できますか?
はい、ラングリングの パブリッシュ段階でマジョリティークラスのダウンサンプリングを有効にすることができます。 ワークベンチでは、ダウンサンプリングがソース内で行われ、サンプリングの加重が生成されます。 次に、ターゲットと加重がエクスペリメントに渡されます。
レシピに操作を追加するには:
-
レシピが選択された状態で、右側のパネルで操作を追加をクリックします。
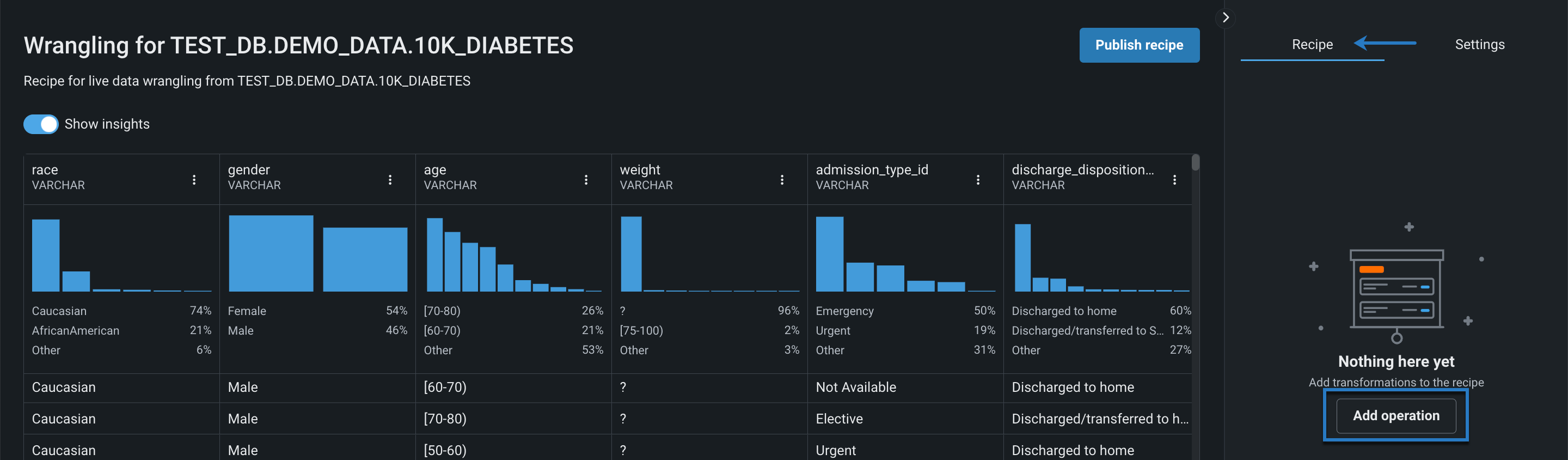
-
操作を選択し、設定します。 続いて、レシピに追加をクリックします。
ライブサンプルは、DataRobotがデータソースから新しいサンプルを取得し、操作を適用すると更新され、変換をリアルタイムで確認できます。
-
ライブサンプルへの影響を分析しながら、操作を追加し続けます。完了したら、レシピをパブリッシュする準備が整います。
結合¶
結合操作を使用して、同じ接続インスタンスからアクセスできるデータセットを結合します。
テーブルまたはデータセットを結合するには:
-
右側のパネルで結合をクリックします。
-
+ データセットを選択をクリックして、接続インスタンスからデータセットを参照して選択します。
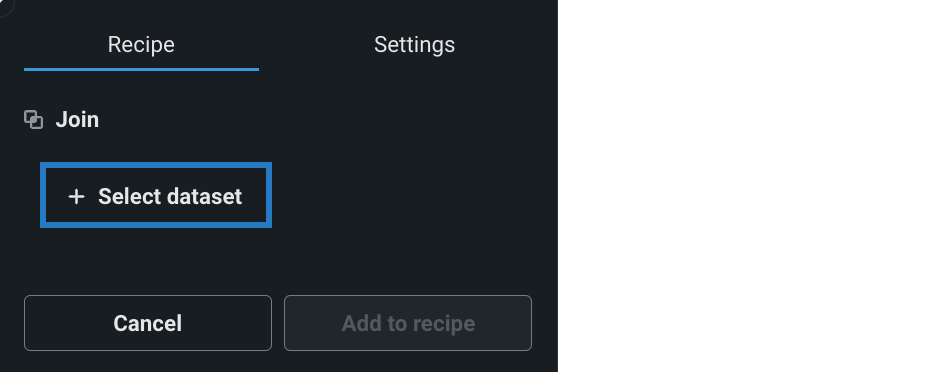
-
追加するデータセットを開いてプロファイリングしたら、選択をクリックします。
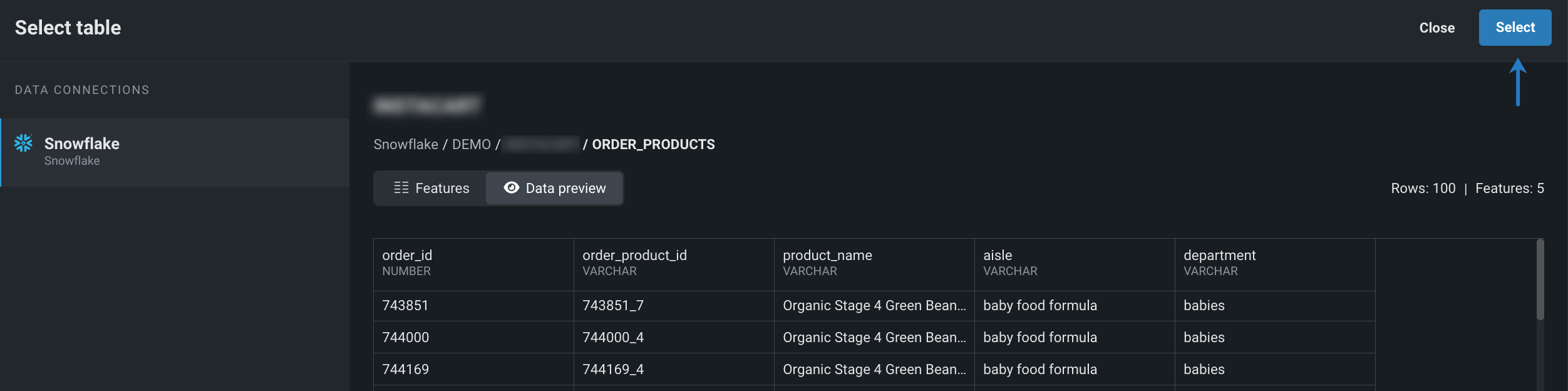
-
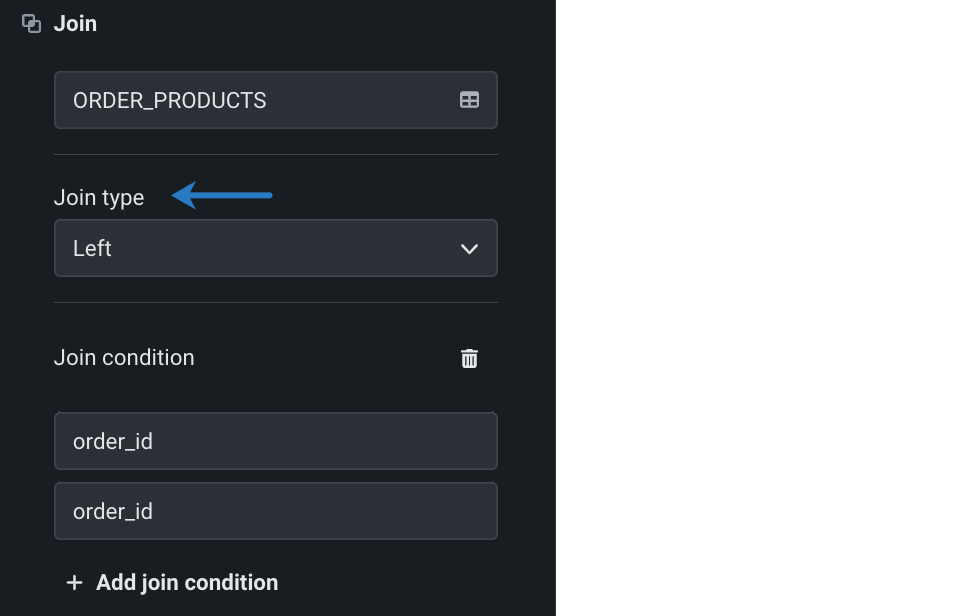
ドロップダウンから適切な結合タイプを選択します。
- 内部は、両方のデータセットで一致する値を持つ行(
order_id列で一致する値を持つ行など)のみを返します。 - 左は、左側のデータセット(元のデータセット)からすべての行を返し、右側のデータセット(結合済み)で一致する値を持つ行のみを返します。
- 内部は、両方のデータセットで一致する値を持つ行(
-
2つのデータセットの関係性を定義する結合条件を選択します。 この例では、両方のデータセットは
order_idによって関連付けられています。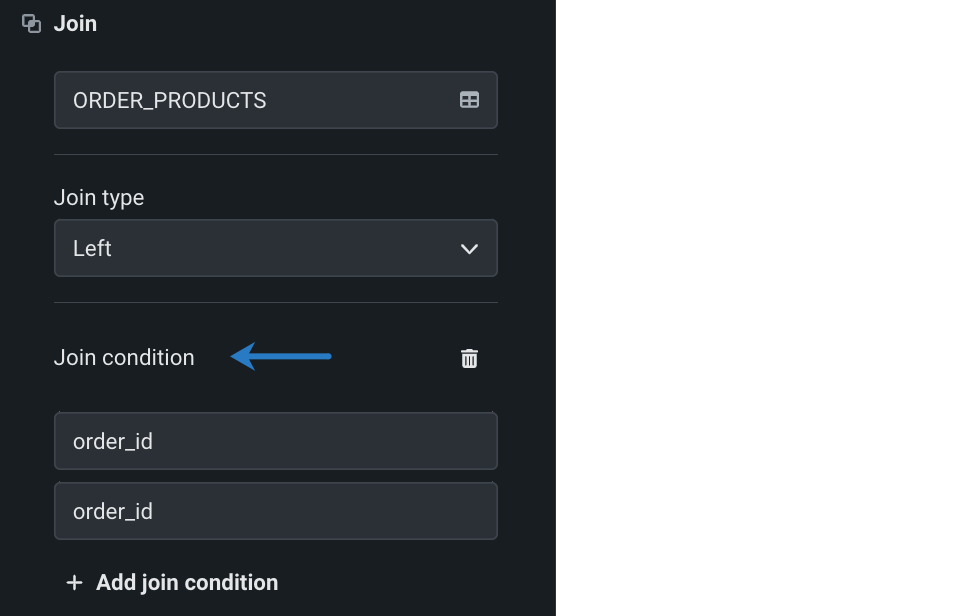
-
レシピに追加をクリックします。
集計¶
集計操作を使用して、次の数学的集計をデータセットに適用します(使用可能な集計は、特徴量タイプによって異なります)。
- 合計
- 最小
- 最大
- 平均
- 標準偏差
- 件数
- 一意の値の数
- 最も高い頻度(Snowflakeのみ)
集計を追加するには:
-
右側のパネルで集計をクリックします。
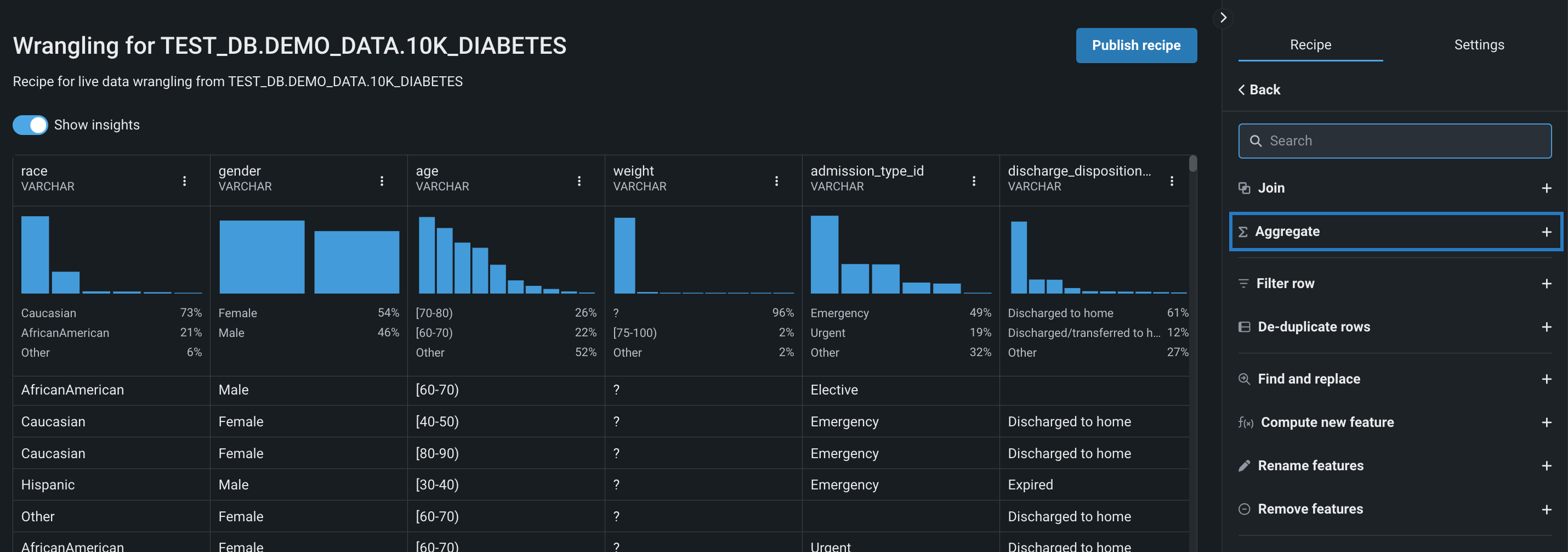
-
キーによるグループ化で、集計のグループ化に使用する特徴量を選択します。
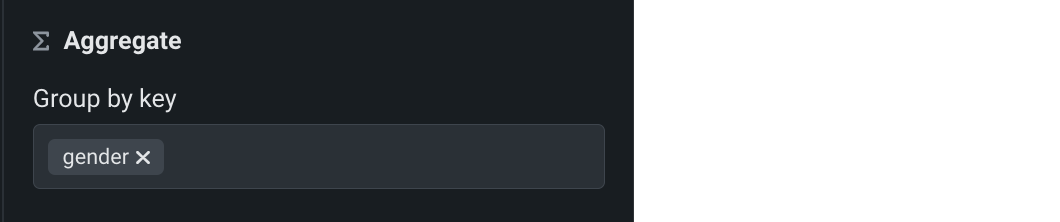
-
集計する特徴量の下のフィールドをクリックし、ドロップダウンから特徴量を選択します。 次に、集計関数の下のフィールドをクリックし、特徴量に適用する1つ以上の集計を選択します。
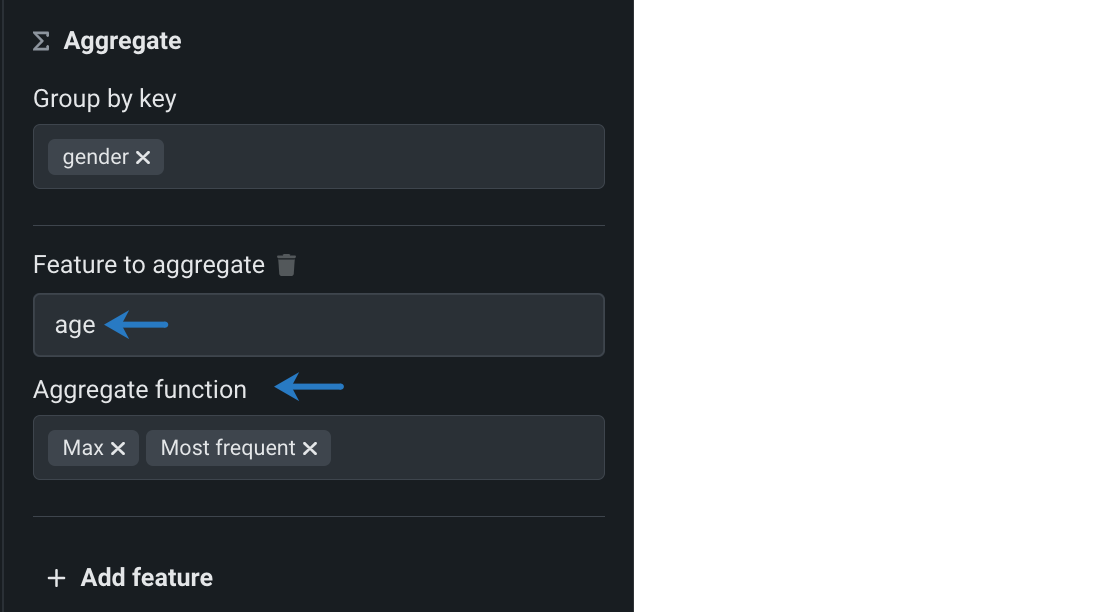
-
(オプション)+ 特徴量を追加をクリックして、このグループ内の追加特徴量に集計を適用します。
-
レシピに追加をクリックします。
レシピに操作を追加すると、DataRobotは
_AggregationFunctionサフィックスが付加された元の名前を使用して、集計済み特徴量の名前を変更します。 この例では、新しい列はage_maxとage_most_frequentです。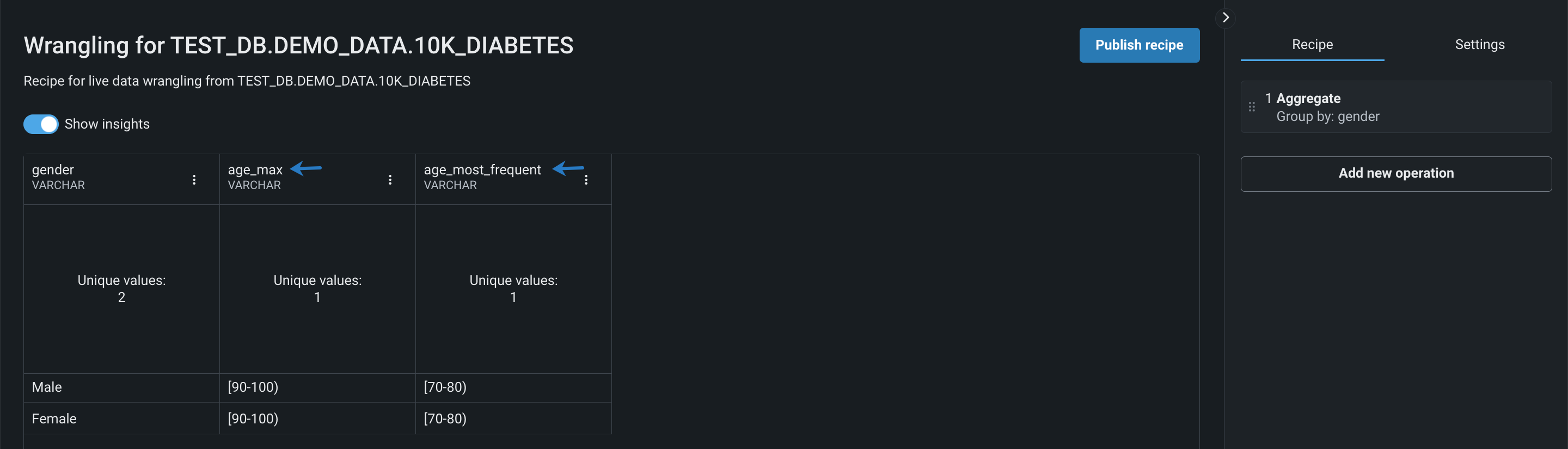
新しい特徴量を計算¶
新しい特徴量を計算操作を使用して、データセット内の既存の特徴量から新しい出力特徴量を作成します。 ドメイン知識を適用することで、元のデータセットよりもビジネス問題をモデルに表現する機能を向上させる特徴量を作成できます。
新しい特徴量を計算するには:
-
右側のパネルで新しい特徴量を計算をクリックします。
-
新しい特徴量の名前を入力し、式で、選択したクラウドデータプラットフォームのスカラーサブクエリー、スカラー関数、またはウィンドウ関数を使用して特徴量を定義します。
以下については、Snowflakeのドキュメントを参照してください。
以下については、BigQueryのドキュメントを参照してください。
以下については、Databricksのドキュメントを参照してください。
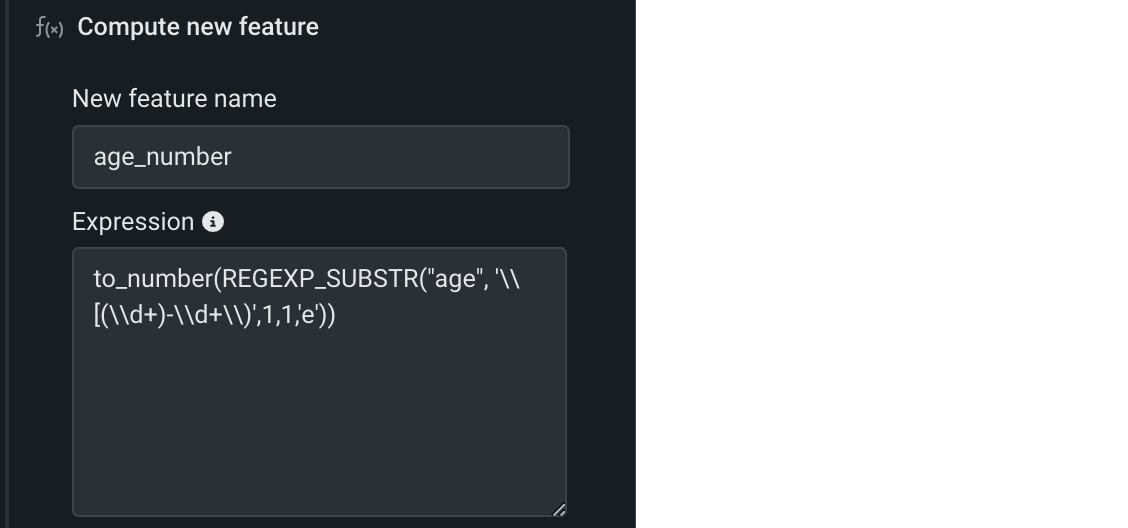
この例では
REGEXP_SUBSTRを使用して、age列の[<age_range_start> - <age_range_end>)から最初の数値を抽出し、またto_numberを使用して、文字列からの出力を数値に変換します。式の形式
新しい特徴量式を計算する形式については、データ接続に基づく例を提供する式フィールドを参照してください。このフィールドは、データ接続に基づく例を提供します。
-
レシピに追加をクリックします。
行をフィルター¶
行をフィルター操作を使用して、指定した値と条件に従ってデータセットの行をフィルターします。
行をフィルターするには:
-
右側のパネルで行をフィルターをクリックします。
-
定義された条件に一致する行を保持するか、除外するかを決定します。
-
フィルターする特徴量、条件タイプ、およびフィルターする値を選択して、フィルター条件を定義します。 選択した列がハイライトされます。
-
(オプション)条件を追加をクリックして、追加のフィルター条件を定義します。
-
レシピに追加をクリックします。
重複行の排除¶
重複除去操作を使用すると、重複する情報を含むすべての行が、データセットから自動的に削除されます。
行の重複除去を行うには、右側のパネルで行の重複除去をクリックします。 この操作は、直ちにレシピに追加され、ライブサンプルに適用されます。
検索と置換¶
検索して置換操作を使用すると、データセット内の特定の特徴量値をすばやく置換できます。 これは、たとえば、データセットのタイプミスを修正する場合に役立ちます。
特徴量値を検索して置換するには:
-
右側のパネルで検索して置換をクリックします。
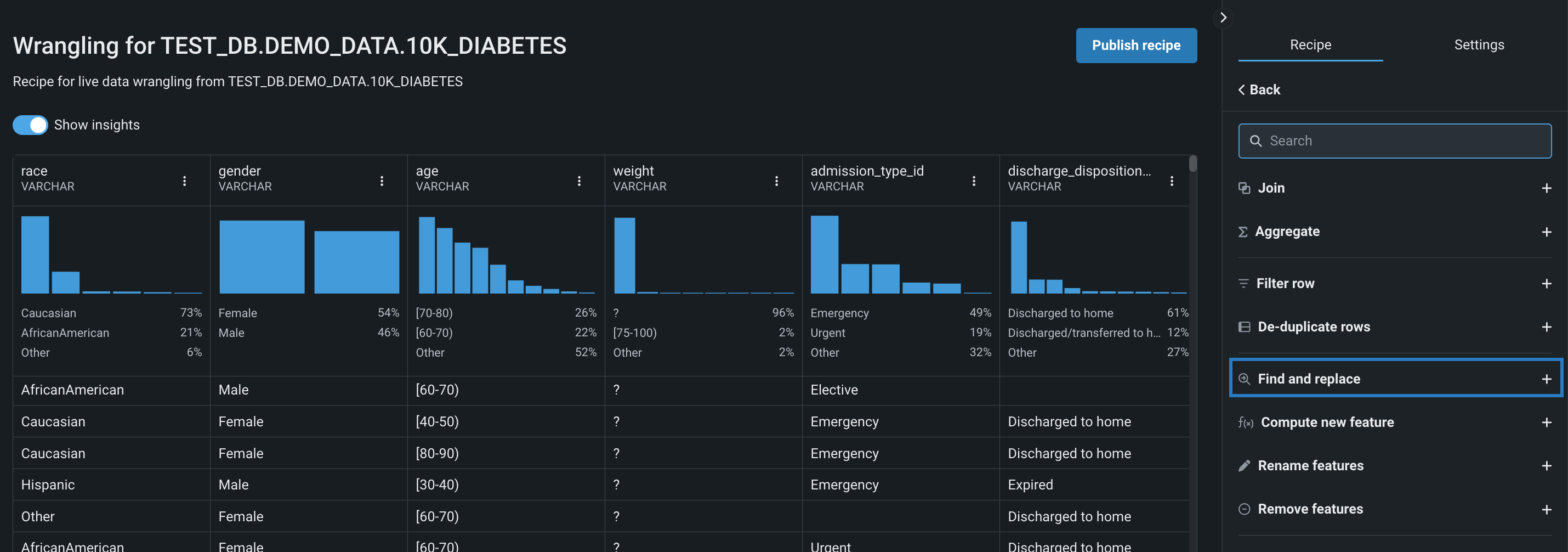
-
特徴量を選択で、ドロップダウンをクリックし、置換する値を含む特徴量を選択します。 選択した列がハイライトされます。
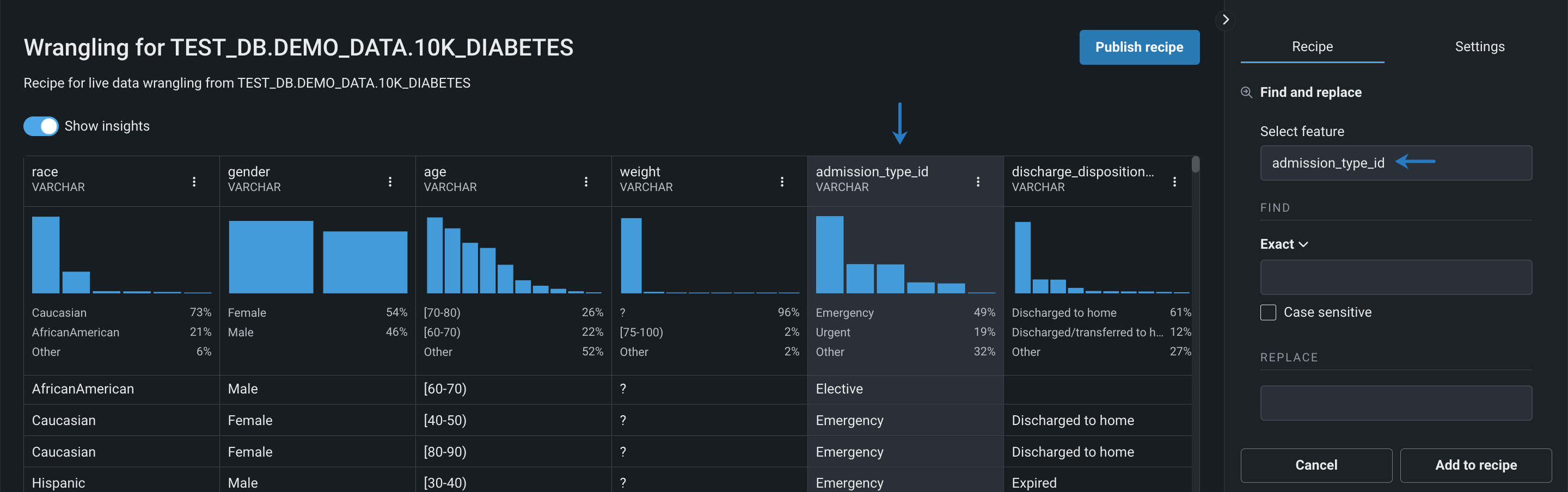
-
検索で、一致条件(完全、部分、または正規表現)を選択し、置換する特徴量値を入力します。 次に、置換で、新しい値を入力します。
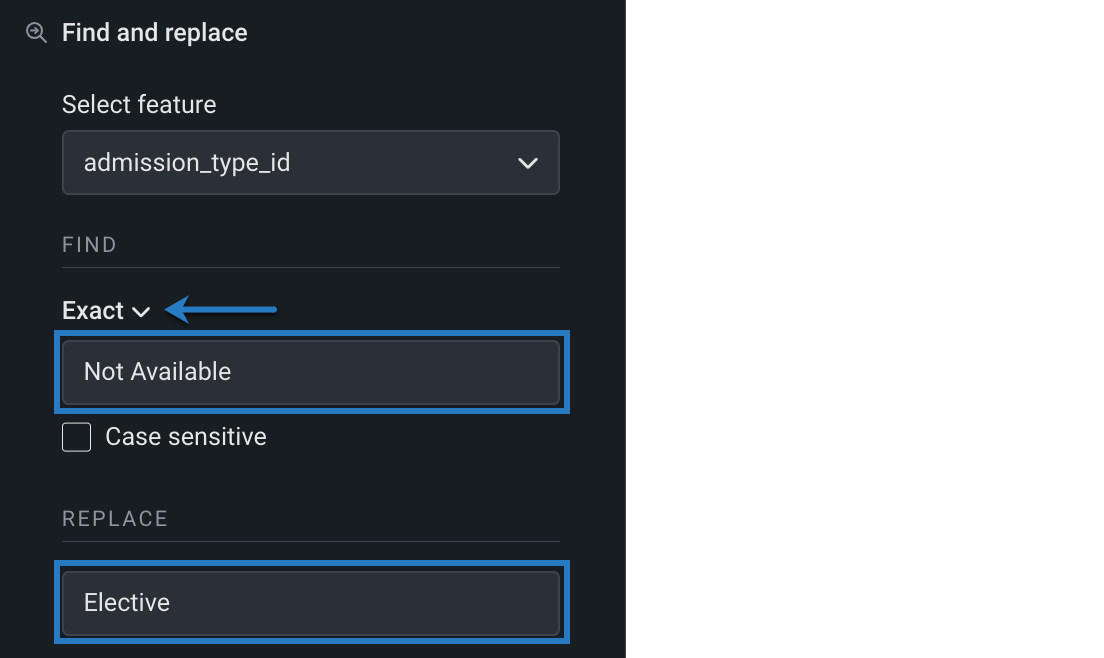
-
レシピに追加をクリックします。
特徴量名を変更する¶
データセットに含まれる1つまたは複数の特徴量の名前を変更するには、特徴量名の変更操作を使用します。
特徴量の名前を変更するには:
-
右パネルの特徴量名の変更をクリックします。
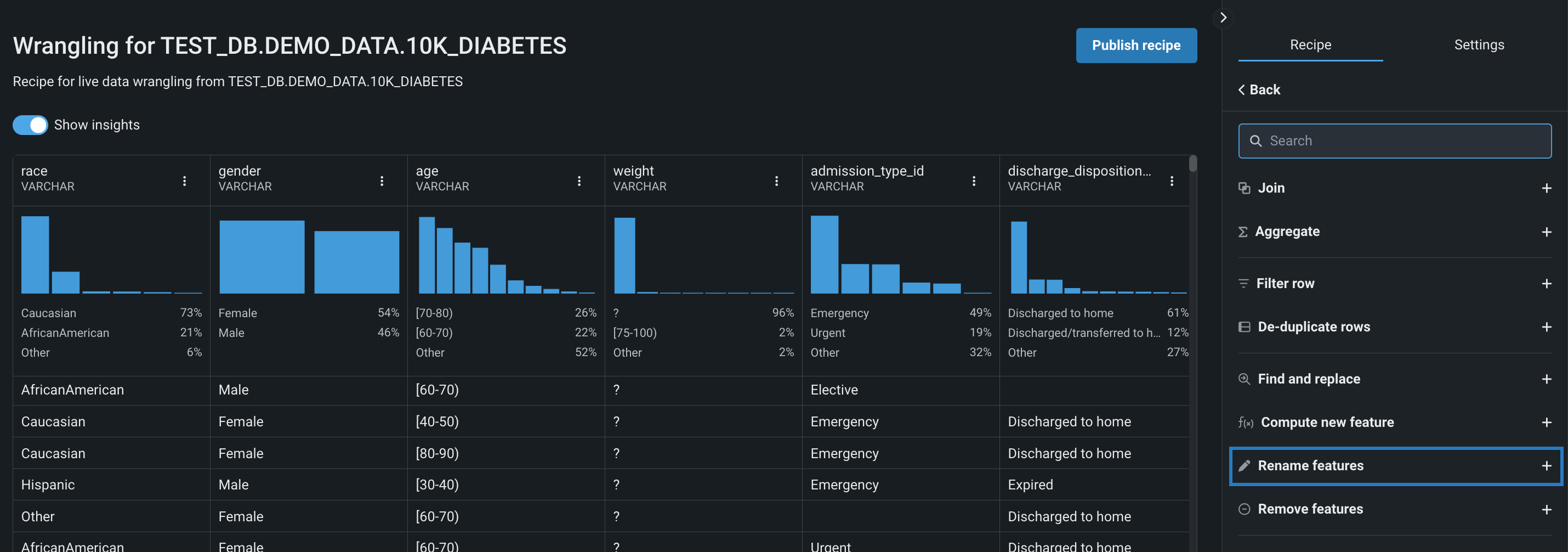
ライブサンプルから特定の特徴量名を変更する
名前を変更する特徴量の横にあるアクションメニュー をクリックすることもできます。 これにより、特徴量フィールドが既に入力されている状態で、操作パラメーターを、右側パネルで開きます。
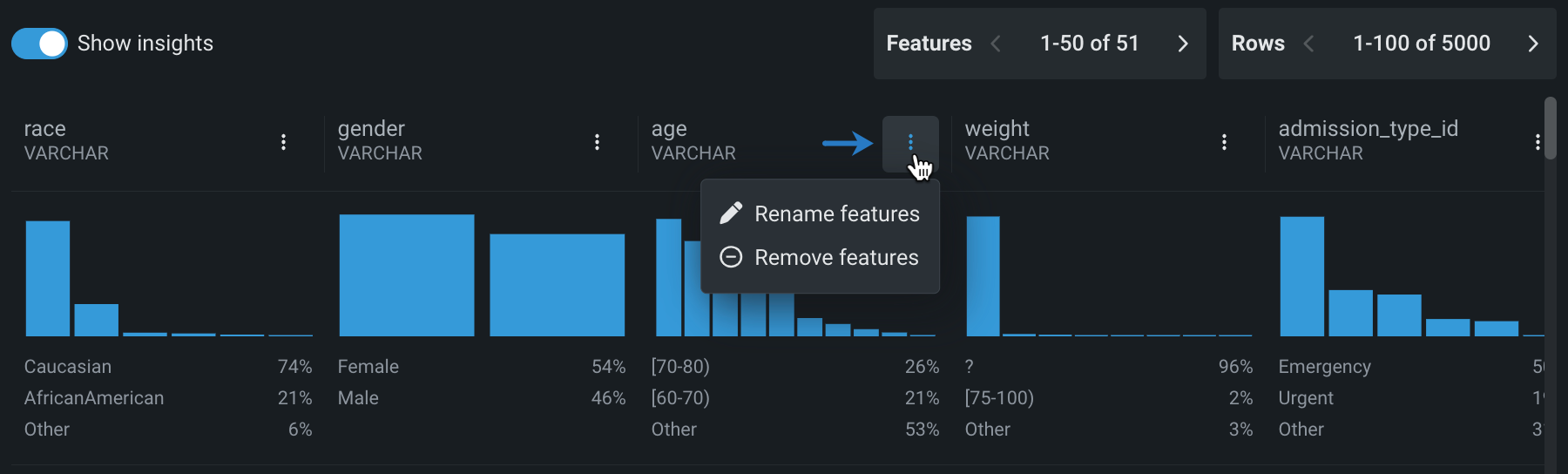
-
特徴量名でドロップダウンをクリックし、名前を変更したい特徴量を選択します。 続いて、2番目のフィールドに新しい特徴量名を入力します。
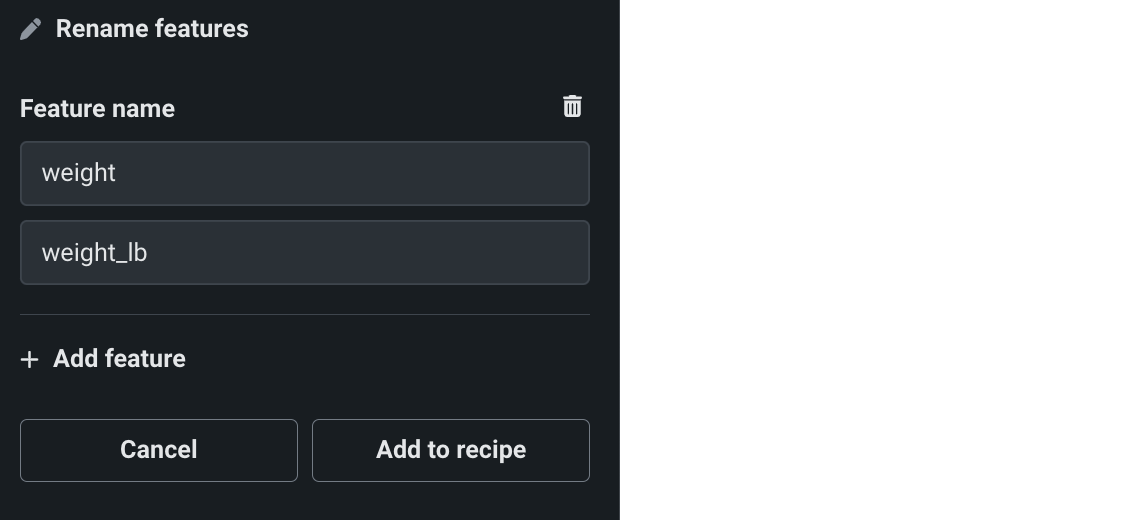
-
(オプション)追加特徴量の名前を変更するには、特徴量を追加をクリックします
-
レシピに追加をクリックします。
特徴量の削除¶
データセットから特徴量を削除するには、特徴量の削除操作を使用します。
特徴量を削除するには:
-
右パネルの特徴量の削除をクリックします。
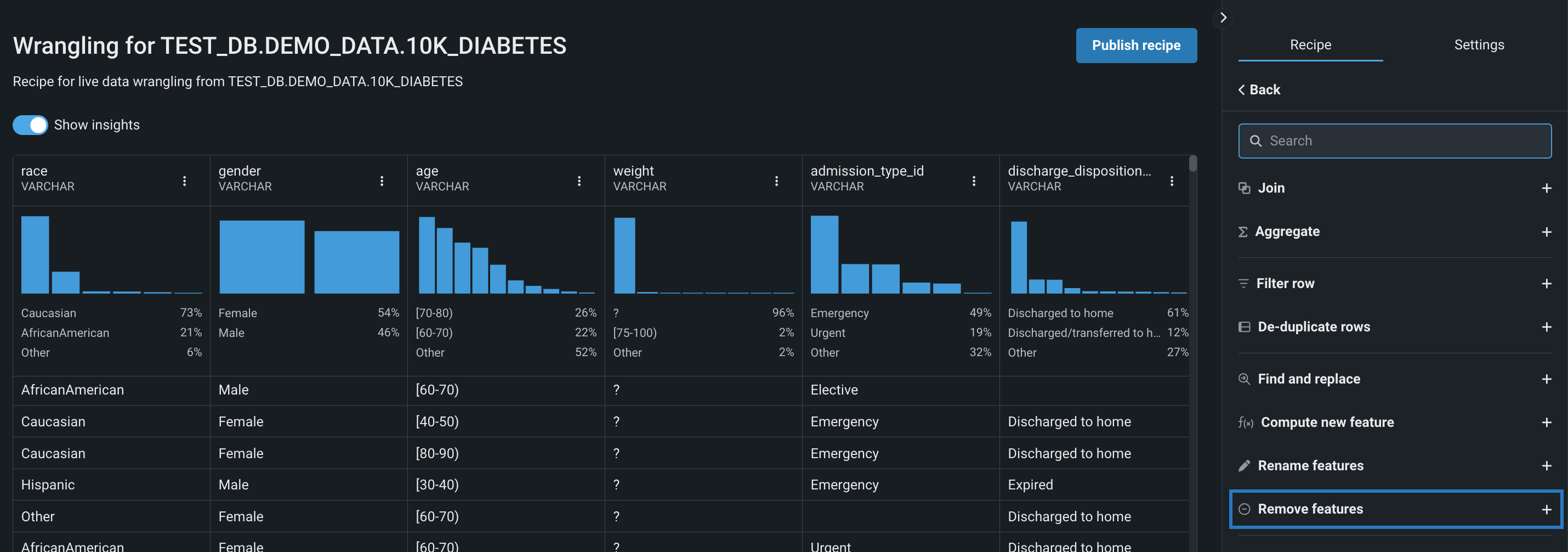
ライブサンプルから特定の特徴量を削除する
削除する特徴量の横にあるアクションメニュー をクリックすることもできます。 これにより、特徴量フィールドが既に入力されている状態で、操作パラメーターを、右側パネルで開きます。
-
特徴量名でドロップダウンをクリックし、名前を変更したい特徴量を選択します。 特徴量の選択が終わったら、ドロップダウンの外をクリックします。
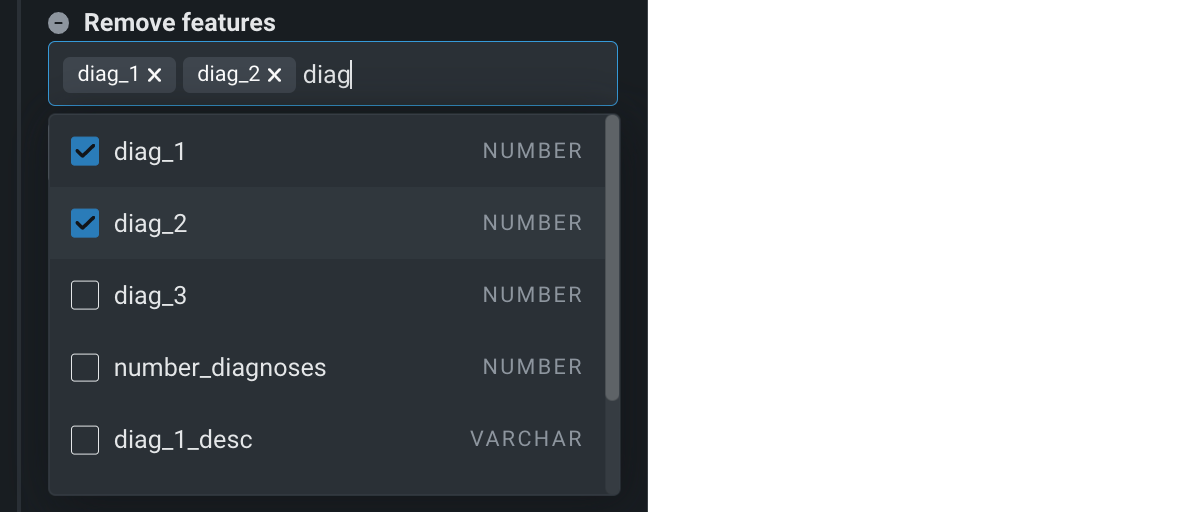
-
レシピに追加をクリックします。
操作の並べ替え¶
ラングリングレシピのすべての操作は、順番に適用されるため、表示される順序は、出力データセットの結果に影響します。
操作を新たな場所に移動するには、移動する操作をクリックしてホールドし、新たな位置にドラッグします。
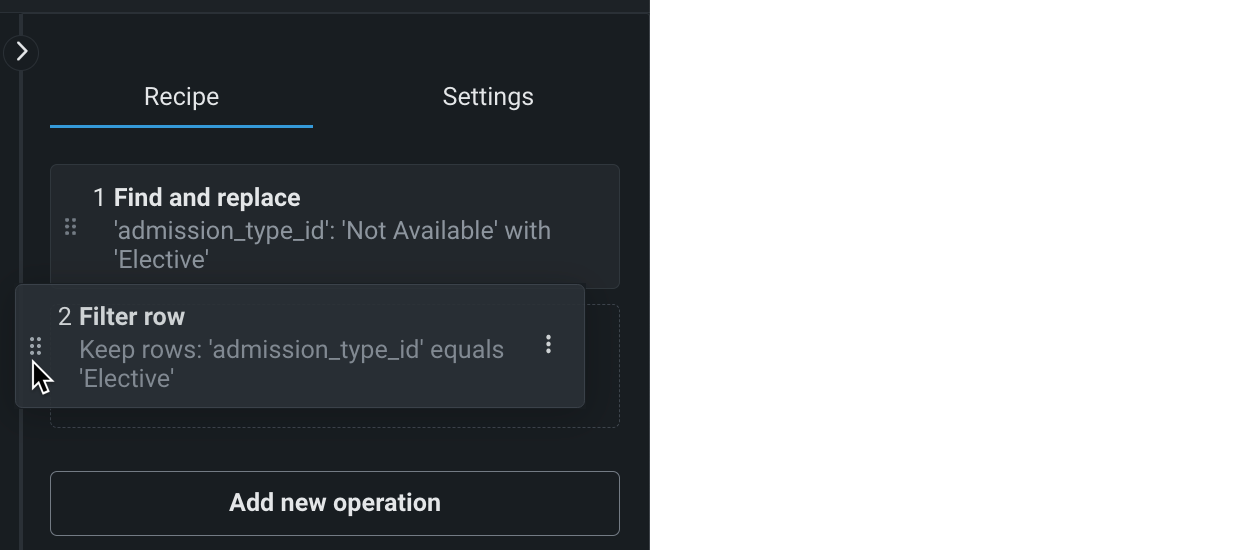
ライブサンプルが更新され、新たな順序が反映されます。
次のステップ¶
ここから、次のことができます。
続けて読む¶
このページで説明されているトピックの詳細については、以下を参照してください。