マネージドSaaS版リリースノート¶
6月にリリースされたSaaS機能のお知らせ¶
2026年6月
このページでは、新たにリリースされ、DataRobotのSaaS型マルチテナントAIプラットフォームで利用できる機能についてのお知らせと、追加情報へのリンクを掲載しています。 リリースセンターからは、過去にリリースされた機能のお知らせや、セルフマネージドAIプラットフォームのリリースノートにもアクセスできます。
エージェント型AI¶
管理者はLLMに対して体系化されたポリシーベースのアクセス制御が可能¶
組織の管理者は、LLMモデルへのアクセスを設定するための専用ページLLM Gatewayの管理を利用できるようになりました。 GenAIは、LLMブループリントの作成時に使用できるいくつかの異なるLLMをサポートしています。以前は、これらのLLMへのアクセスは機能フラグによって制御されていました。つまり、各LLMタイプには個別の機能フラグが割り当てられていました。 管理者設定にあるLLM Gatewayの管理では、管理者が、組織、グループ、または個々のユーザーレベルで、特定のプロバイダー、作成者、およびモデルへのアクセスを許可または拒否することができます。
Agent Assistのスキル¶
Agent Assistのスキル (datarobot-agent-assist)は、dr assistと同じ設計、コード、デプロイワークフローをパッケージ化し、Claude Code、Cursor、OpenCode、VS Code Copilot、およびその他のサポートされているコーディングエージェントで使用できるようにしています。 DataRobot Agentic Skillsリポジトリ (npx ai-agent-skills install datarobot-oss/datarobot-agent-skills)またはエージェントマーケットプレースからインストールします。ワークスペースごとに1回datarobot-setupを実行してから、Run datarobot-agent-assistで開始します。 詳細な手順については、Agent Assistのスキルに関するドキュメントを参照してください。
エージェントフレームワークの再構築¶
Agentic Starterテンプレートの最新版および将来のバージョンでは、DataRobot内のGenAIエージェント向けの、統一された非同期インターフェイスへ移行できるよう再設計されました。 新しいエージェントでは、エージェントワークフロー向けに設計されていない予測用カスタムモデルフロントサーバーであるDataRobot User Models (DRUM)の使用を廃止し、オープンソースのNeMo Agentic Toolkit (NAT)と、DRAgentと呼ばれるカスタムフロントエンドサーバーを統合したハイブリッドモデルへと移行しています。 この新しい非同期機能により、DRAgentを使用するエージェントワークフローでは、エージェント全体の効率が劇的に向上し、応答時間も短縮されました。
すべての新しいAgentic Starterテンプレートのインスタンスは、デフォルトでDRAgentを使用します。既存のエージェントは引き続きDRUMを使用して従来通り実行されますが、エージェントの.envファイルに新しい環境変数を追加することで、新しいエクスペリエンスに切り替えることができます。
ENABLE_DRAGENT_SERVER=true
新しいLLMとサポートが終了したLLM¶
以下に、利用可能なLLMについて先月のリリースノート以降に行われた変更の一覧を示します。 サポートされているLLMの完全なリストについては、利用可能なLLMのページを参照してください。 従来通り、組織の特定のニーズに対応するために外部連携を追加できます。
次のモデルが新たに利用可能になりました。
- Claude Opus 4.8:Amazon Bedrock、Anthropic、Google Gemini Enterprise Agent Platform(以前のVertex AI)。
- Google Gemini 3.5 Flash:Google Gemini Enterprise Agent Platform(以前のVertex AI)。
これらの新しいモデルへのアクセスを有効にするには、組織管理者は新しいLLM Gatewayの管理ページを使用して、アクセス制御ポリシーを設定できます。
使用非推奨とサポート終了の日程の詳細については、利用可能なLLMに関する情報を参照してください。
データ¶
ファイルレジストリでファイルを保存、共有、検索する¶
レジストリ内のファイルタイルは、構造化データや非構造化データ、ドキュメント、バイナリなど、あらゆるタイプのファイルを保存、共有、検索するための一元的な場所です。 通常、非構造化ナレッジワークフローの基盤となるデータを保管するために使用されますが、管理や再利用が必要なあらゆるファイルに活用することができます。 DataRobot内のワークフローの一部として非構造化データが追加された場合、登録が完了すると、(関連するユースケースが削除された場合でも)レジストリ > ファイルからそのファイルに再度アクセスすることができます。
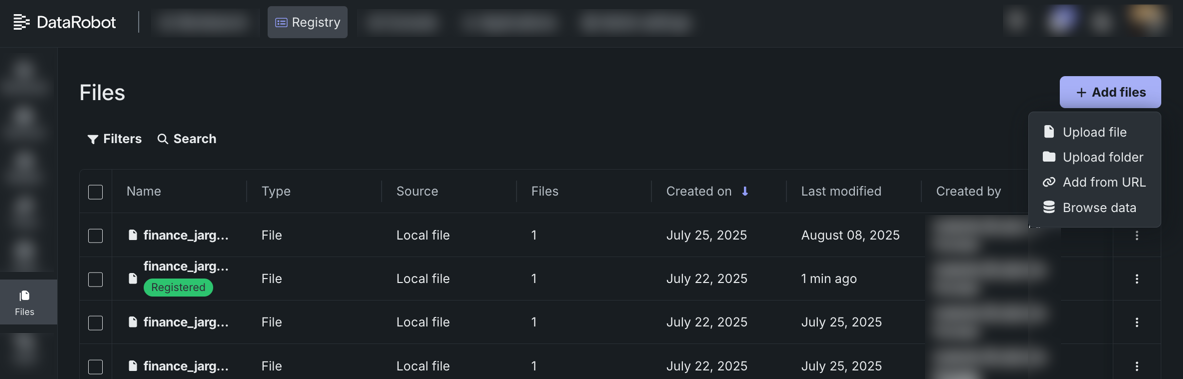
詳細については、ファイルレジストリのドキュメントを参照してください。
接続文字列またはSASを使用してADLS Gen2に接続する¶
DataRobotでADLS Gen2に接続する際、サポートされる認証方法として、Azureの接続文字列および共有アクセス署名(SAS)が追加されました。 これらの接続の設定に関する詳細については、ADLS Gen2のページを参照してください。
データコネクターのプレビュー速度が向上¶
DataRobotは、データ接続のプレビュー機能を統合コネクターフレームワーク(UCF)へ移行しています。 この変更により、テーブルおよびクエリーにおけるプレビューのパフォーマンスが大幅に向上しました。 この移行により、プレビューリクエストのレイテンシーが約5~8秒から1~1.5秒に短縮され、接続されたデータを探索する際のユーザーエクスペリエンスがより高速で応答性の高いものになります。
予測AI¶
外部データを用いてモデルのパフォーマンスを評価する¶
外部テストデータセットを使用すると、トレーニング中に使用されなかったデータセット(すなわち、外部ホールドアウト)に対してトレーニング済みのモデルを評価できます。 エクスペリメントにデータセットをアタッチし、必要に応じて個々のモデルをスコアリングします。 結果は、完全なリーダーボードに表示されるほか、UI全体でトレーニングから得られたスコアの横にも表示されます。 さまざまなモデルインサイトから利用可能で、データ選択ドロップダウンを使用して、比較対象となる外部データセットを選択することができます。
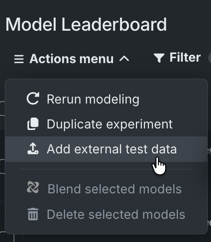
MLOpsと予測¶
カスタムモデルでの多ラベルのサポート¶
構造化カスタム推論モデルで多ラベル分類がサポートされるようになりました。 ワークショップで、ターゲットタイプとして多ラベルを選択し、モデルが予測したラベルの確率と同じ順序でターゲットラベルを指定します。 コードファーストのワークフローでは、model-metadata.yaml内のtargetType: multilabel、またはPythonクライアント内のdr.TARGET_TYPE.MULTILABELを使用して、多ラベルモデルを定義できます。
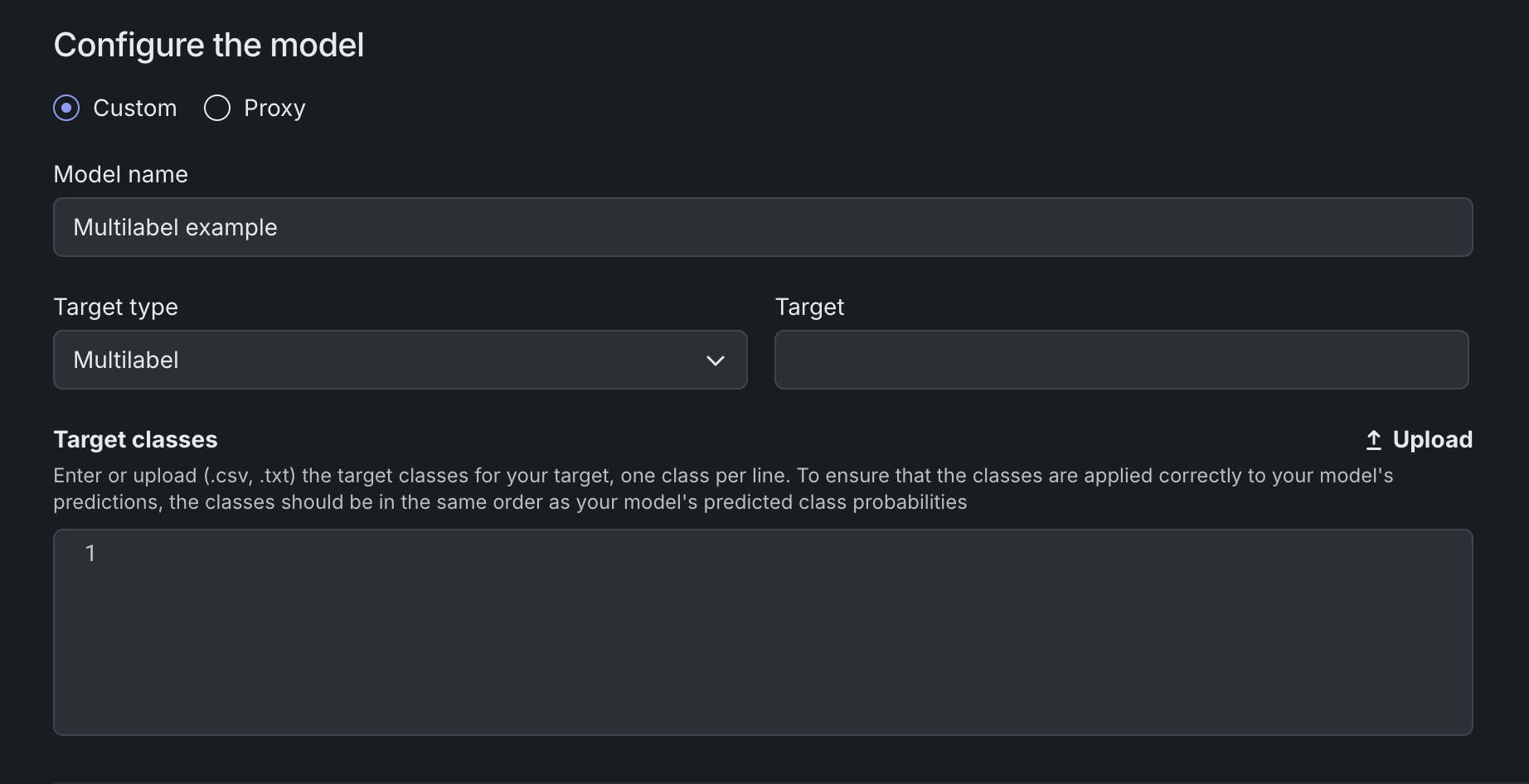
多ラベルカスタムモデルでは、サービス正常性と特徴量ドリフトの監視を備えた推論のみがサポートされます。 詳細については、カスタムモデルの作成、カスタムモデルのメタデータを定義する、および構造化カスタムモデルを参照してください。
ランタイムパラメーター使用時のセキュアな構成における資格情報フィールド名を修正¶
資格情報は、手動で作成することも、共有のセキュアな構成から作成することもできます。 Azureサービスプリンシパル、Snowflakeのキーペア、およびAzure OAuth / ADLS OAuthの各タイプにおいて、secure-configベースの資格情報は、これまで手動で作成された資格情報とは異なるフィールド名を使用していました。 これらのタイプのいずれかのsecure-configベースの資格情報を使用してカスタムモデル、アプリケーション、またはエージェントをデプロイすると、エラーメッセージが表示されないまま失敗する可能性がありました。つまり、ワークロードは非アクティブのままとなり、ユーザーにエラーが表示されることなくタイムアウトしていました。 手動で設定された資格情報には影響はありませんでした。
今回のリリースでは、すべての資格情報作成パスに単一の標準的なフィールド名マッピングが適用されたため、secure-configベースの資格情報は、ランタイムパラメーターとしてマウントされた場合、カスタムモデル、アプリケーション、およびエージェントに対して正しく解決およびデプロイされるようになりました。
互換性を損なう変更 — カスタムジョブのみ
カスタムジョブは、資格情報を展開済みの環境変数として受け取り、他のワークロードとは異なる挿入パスを使用します。 カスタムモデル、アプリケーション、エージェントとは異なり、secure-configのフィールド名が正規のスキーマと一致しない場合でも、カスタムジョブはブロックされませんでした。 一部のカスタムジョブでは、共有セキュア構成から作成された資格情報タイプのランタイムパラメーターを読み込む際に、すでに以下のレガシーフィールド名に依存している可能性があります。
以下のいずれかのフィールドを読み取るカスタムジョブのコードを更新してください。
| 資格情報のタイプ | 以前のフィールド(変更前) | 新しいフィールド(変更後) |
|---|---|---|
| Azureサービスプリンシパル | tenant_id |
azure_tenant_id |
| Snowflakeのキーペア | user_name |
username |
| Azure OAuth / ADLS OAuth | scopes(スペース区切りの文字列) |
oauth_scopes(JSONリストの文字列表現) |
client_idやclient_secretなどのフィールドは変更されません。 手動で設定された資格情報を使用するカスタムジョブも変更されません。
資格情報タイプのランタイムパラメーターは、大文字のスネークケースで{PARAMETER_NAME}_{FIELD_NAME}という名前の個別の環境変数に展開されます。 ランタイムパラメーターの名前がMY_AZURE_CREDであるAzureサービスプリンシパルについては、この例を参照してください。
ランタイムパラメーターの名前がMY_AZURE_CREDであるAzureサービスプリンシパルの例:
import os
import json
# simulate injection of credential to custom job
# before upgrade
os.environ["AZURE_SP_CRED"] = '{"credential_type": "azure_service_principal", "client_id": "C123", "client_secret": "S456", "tenant_id": "T789"}'
tenant_id = json.loads(os.environ["AZURE_SP_CRED"]).get("tenant_id")
print(tenant_id) # 'T789'
# after upgrade
os.environ["AZURE_SP_CRED"] = '{"credential_type": "azure_service_principal", "client_id": "C123", "client_secret": "S456", "azure_tenant_id": "T789"}'
tenant_id = json.loads(os.environ["AZURE_SP_CRED"]).get("tenant_id") # KeyError if not using get()
print(tenant_id) # None
tenant_id = json.loads(os.environ["AZURE_SP_CRED"]).get("azure_tenant_id"). # using corrected field name
print(tenant_id) # 'T789'
資格情報タイプのランタイムパラメーターの挿入方法については、カスタムジョブのランタイムパラメーターを参照してください。
アプリケーション¶
UIコンポーネントレジストリをアプリケーションに追加してパフォーマンスを向上¶
アプリケーションは、shadcn上に構築されたAIネイティブなUIコンポーネントレジストリを利用するようになり、コンポーネントの再利用と配布が効率化されました。 コンポーネントが構築されると、一元化されたレジストリに保存され、複数のアプリケーションで再利用できるようになります。 このコンポーネントレジストリにより、より一貫性のあるユーザーインターフェイスが実現され、提供までの時間が短縮されるほか、採用と透明性を高めるために、一般に公開されたオープンソースライブラリも提供されています。
さらに、Talk to My Docs(ドキュメントと会話する)アプリケーションテンプレートやAgentic Starterアプリケーションテンプレートにおいて、設定ページで表示テーマと言語を選択できるようになりました。
アプリケーションのOTel準拠トレースを表示する¶
アプリケーションには、OTel準拠のトレースを表示するトレースタブが追加されました。 トレースは、モデルまたはエージェントのワークフローに対するリクエストがたどった経路を表します。 各トレースは、リクエストのオリジンから解決までのエンドツーエンドのパス全体を追跡し、ルートスパンを起点として1つ以上のスパンで構成されています。 ルートスパンはリクエストのパス全体を表し、プロセスの個々のステップの子スパンを含みます。
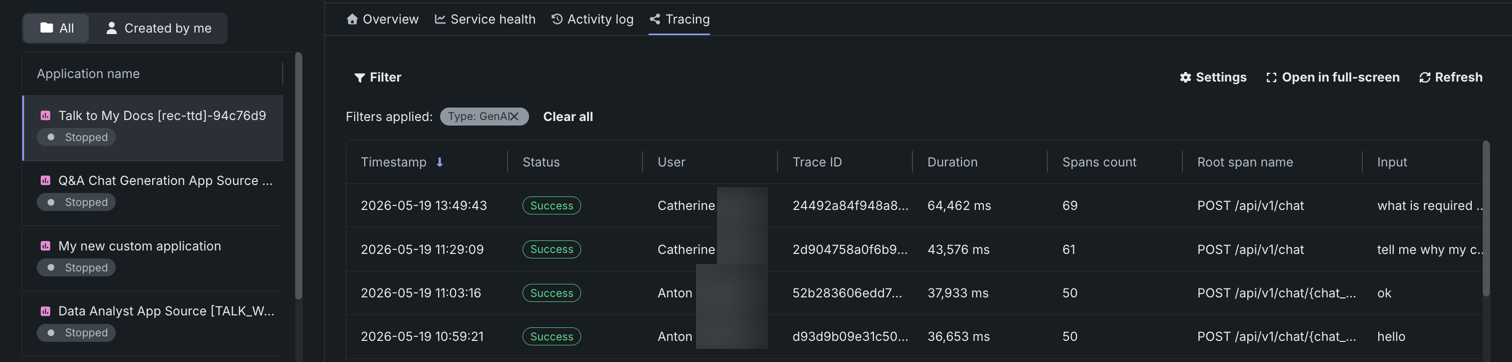
プラットフォーム¶
ユーザーグループとのユースケースの共有¶
ワークベンチでは、個々のユーザーや組織に加え、ユーザーグループと直接ユースケースを共有できるようになりました。 グループに直接ロールを割り当てることができます。 そのロールはグループの全メンバーに適用され、メンバーはデータセットを含むユースケース内のすべてのアセットにアクセスできるようになります。
管理者設定を上部のナビゲーションに移動¶
プラットフォーム管理者は、NextGen UI上部のナビゲーションバーから管理者設定を開けるようになりました。これは、以前プロフィールアイコンの下にあったアプリ管理者メニューに代わるものです。 最新の操作手順については、管理者向け概要を参照してください。
コードファースト¶
Pythonクライアントv3.17¶
Pythonクライアントのv3.17が一般提供されました。 v3.17で導入された変更の完全なリストについては、Pythonクライアントの変更履歴を参照してください。
DataRobot REST API v2.46¶
DataRobotのREST API v2.46が一般提供されました。 v2.46で導入された変更の完全なリストについては、REST APIの変更履歴を参照してください。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。