MLOpsと予測(V10.0)¶
2024年4月29日
DataRobot MLOps v10.0リリースには、以下に示す多くの新機能が含まれています。 リリース10.0のその他の詳細については、データとモデリングおよびコードファーストのリリースノートをご覧ください。
新機能と機能強化¶
目的別にグループ化された機能
| 名前 | 一般提供 | プレビュー |
|---|---|---|
| 予測とMLOps | ||
| AzureMLでのスコアリングコードの自動デプロイと置換 | ✔* | |
| 予測値と実測値の適時性インジケーター | ✔ | |
| バッチ予測での列名の再マッピング | ✔ | |
| 日本語テキストの特徴量ドリフトでのトークン化を改善 | ✔ | |
| デプロイ予測のバッチ監視 | ✔ | |
| カスタムモデルのランタイムパラメーター | ✔ | |
| カスタムモデル用の新しいランタイムパラメーター定義オプション | ✔ | |
| カスタムモデル用の新しい環境変数 | ✔* | |
| モデルレジストリのカスタムジョブ | ✔ | |
| カスタムモデル出力で列を追加 | ✔ | |
| NextGenの予測とMLOps | ||
| NextGenコンソールのレイアウトを一新 | ✔ | |
| NextGenのレジストリを一般提供 | ✔ | |
| レジストリのグローバルモデル | ✔* | |
| デプロイの通知ポリシー | ✔ | |
| 予測リクエストでの列フィルターの無効化 | ✔ | |
| 実測値と予測値のアップロード制限を設定 | ✔ | |
| カスタムモデルのリソースバンドル | ✔ | |
| テキスト生成モデルの評価とモデレーション | ✔* | |
| NVIDIA GPUでNeMo Guardrailsを使用した生成AI | ✔* | |
| 時系列カスタムモデル | ✔ | |
| デプロイのデータ品質分析 | ✔* | |
| バッチ予測のラングラーレシピ | ✔ | |
| カスタム指標および再トレーニングジョブ | ✔ | |
| カスタムアプリケーション | ||
| カスタムアプリの一般提供を開始 | ✔ | |
| チャット生成Q&Aアプリケーションの構築と使用 | ✔* | |
| DRApps CLIでのカスタムアプリのホスティング | ✔ | |
| カスタムアプリケーションのランタイムパラメーターとリソースバンドルを設定 | ✔ | |
| カスタムアプリケーションの共有 | ✔ | |
| レジストリでのカスタムアプリケーションの管理 | ✔ | |
| サポート終了/移行ガイド | ||
| カスタムモデルのトレーニングデータ割り当てを変更 | ||
| Tableau拡張機能の削除 | ||
* プレミアム機能
注目の新機能¶
NextGenコンソールのレイアウトを一新¶
今回リニューアルされたNextGenコンソールでは、重要な監視、予測、バイアス軽減の各機能を、新しく直感的なレイアウトのモダンなユーザーインターフェイスで提供します。
動画:NextGenコンソール
この新しくなったレイアウトにより、ワークベンチでのモデルエクスペリメントやレジストリでのモデル登録から、コンソールでのモデルの監視と管理へシームレスに移行できます。また、DataRobot Classicの機能も引き続き利用できます。
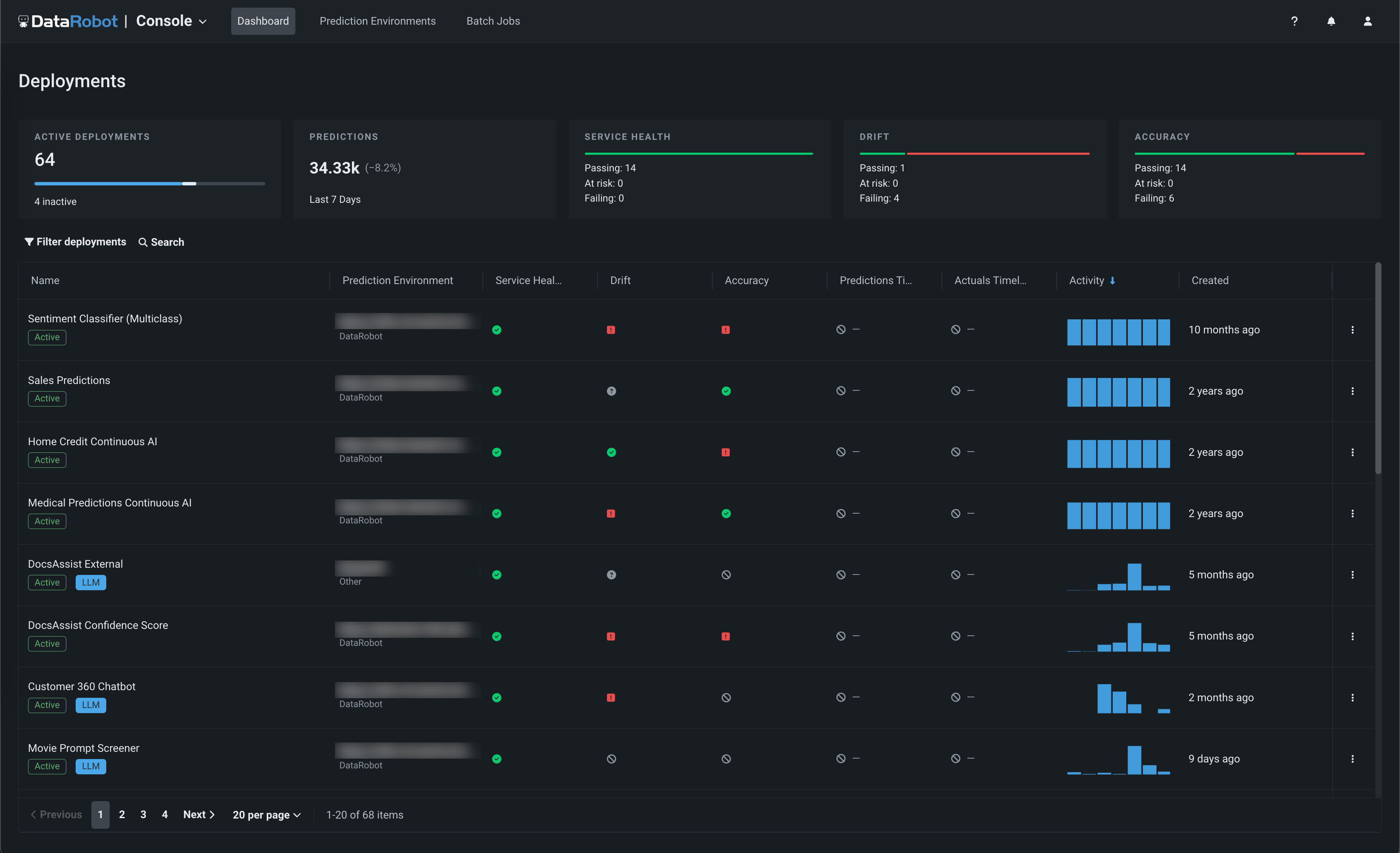
詳しくはドキュメントをご覧ください。
NextGenのレジストリを一般提供¶
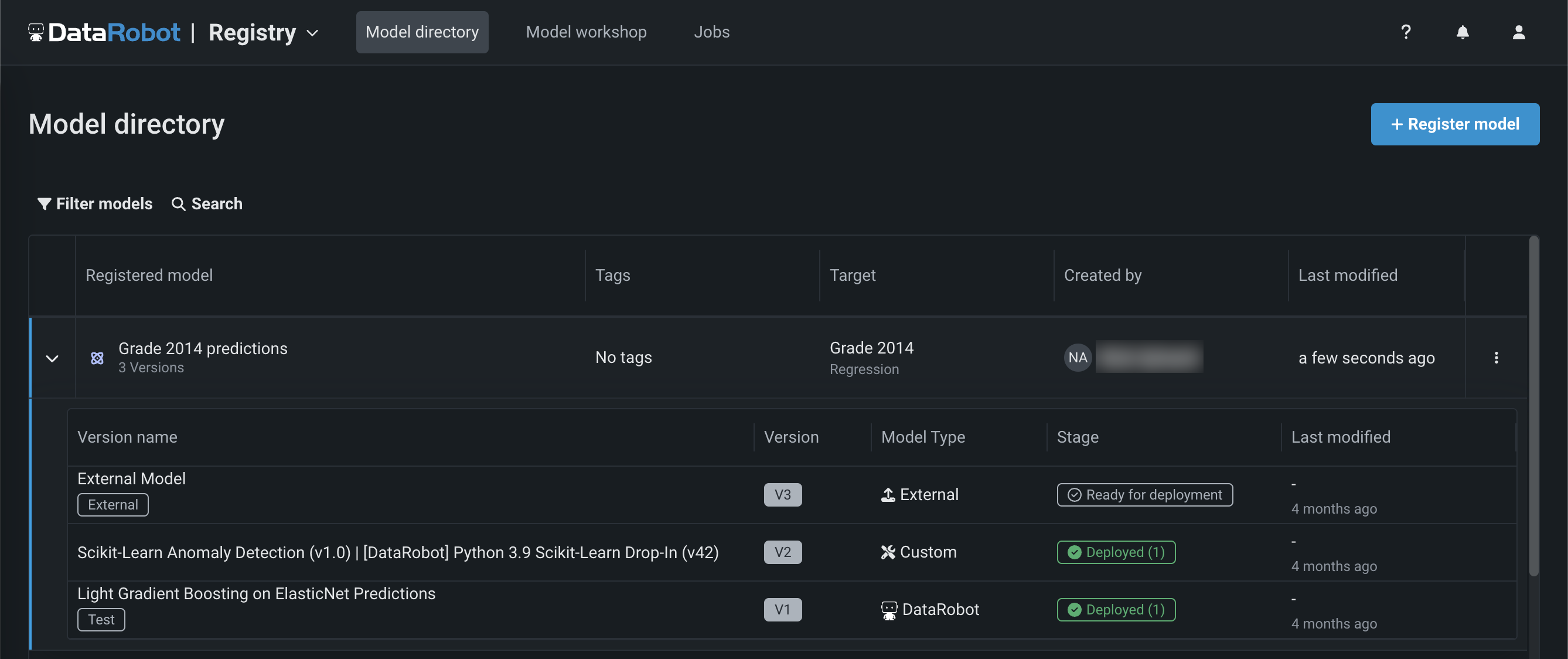
NextGenで一般提供を開始しました。レジストリは、DataRobotで使用されるさまざまなモデルのための組織的ハブです。 レジストリ > モデルディレクトリページには、_登録されたモデル_が一覧表示され、それぞれにデプロイ可能なモデルパッケージが_バージョン_として含まれています。 これらの登録モデルには、DataRobotのモデル、カスタムモデル、外部モデルをバージョンとして含めることが可能で、予測モデルや生成モデルの進化を追跡し、一元管理することができます。
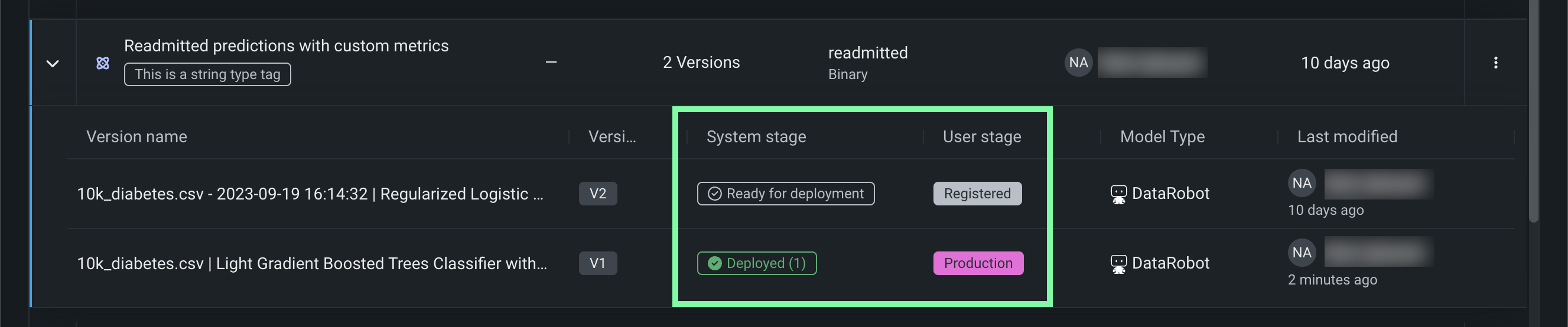
このリリースから、レジストリは登録されているモデルバージョンのシステムステージと変更可能なユーザーステージを追跡します。 登録モデルのバージョンのステージ に変更を加えると、システムイベントが生成されます。 これらのイベントは通知ポリシーで追跡できます。
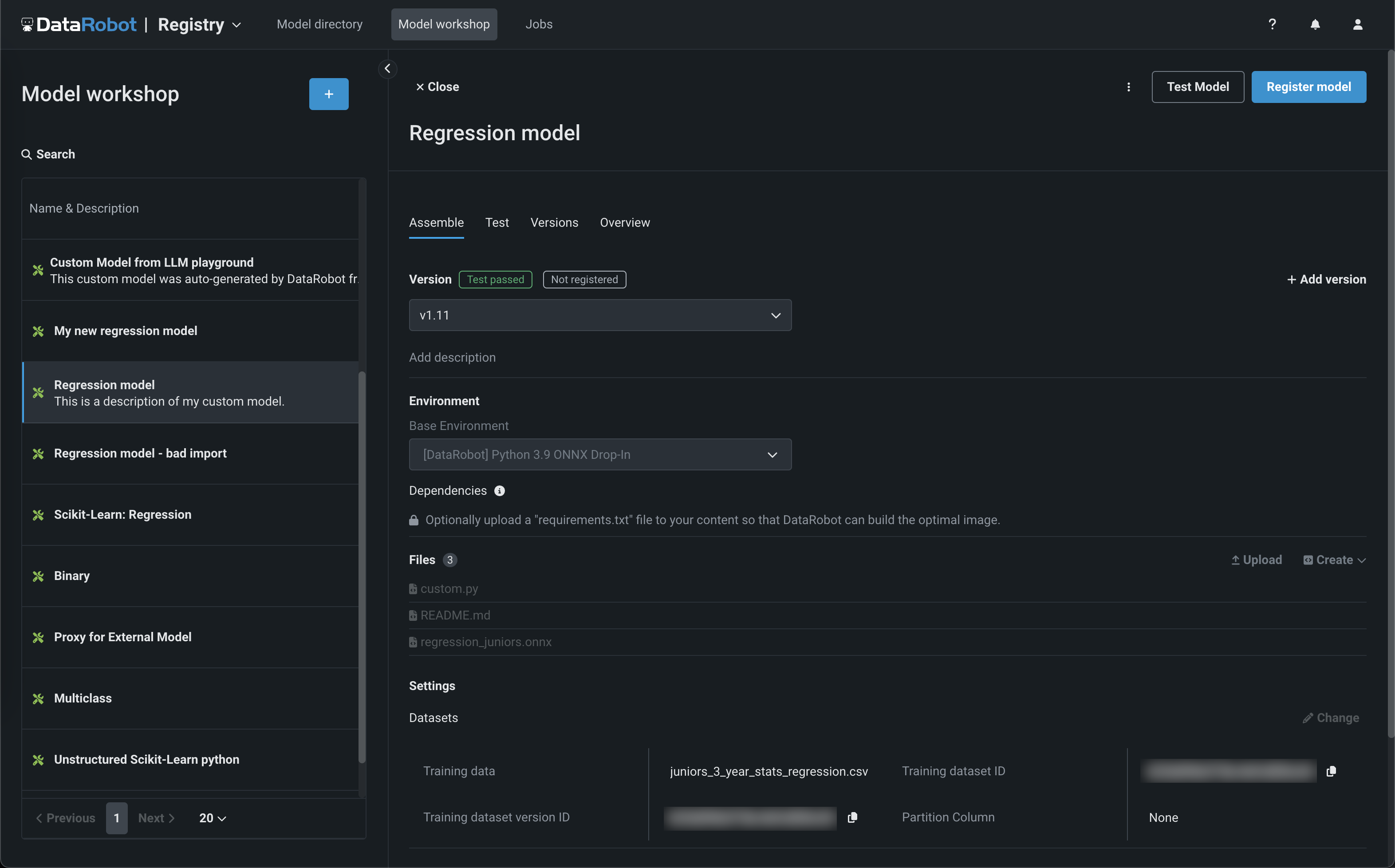
レジストリ > モデルワークショップのページでは、カスタムモデルを作成、テスト、登録、デプロイするためのモデルアーティファクトを、一元化されたモデル管理・デプロイハブにアップロードすることができます。 カスタムモデルは、DataRobotのMLOps機能のほとんどをサポートする事前トレーニング済みのユーザー定義モデルです。 DataRobotは、Python、R、Javaを始めとするさまざまなコーディング言語で構築されたカスタムモデルをサポートします。 DataRobot以外でモデルを作成し、DataRobotにアップロードする場合は、モデルワークショップでモデルの内容とモデル環境を定義します。
レジストリ > ジョブページでは、ジョブを使用して、モデルとデプロイのために自動化(カスタムテスト、指標、通知など)を実装します。 各ジョブは自動化されたワークロードとして機能し、終了コードによって正常終了か失敗かが判定されます。 作成したカスタムジョブは、1つ以上のモデルまたはデプロイで実行できます。 カスタムジョブによって定義された自動ワークロードは、DataRobotのパブリックAPIを使用して、予測リクエスト、入力の取得、出力の保存を行うことができます。
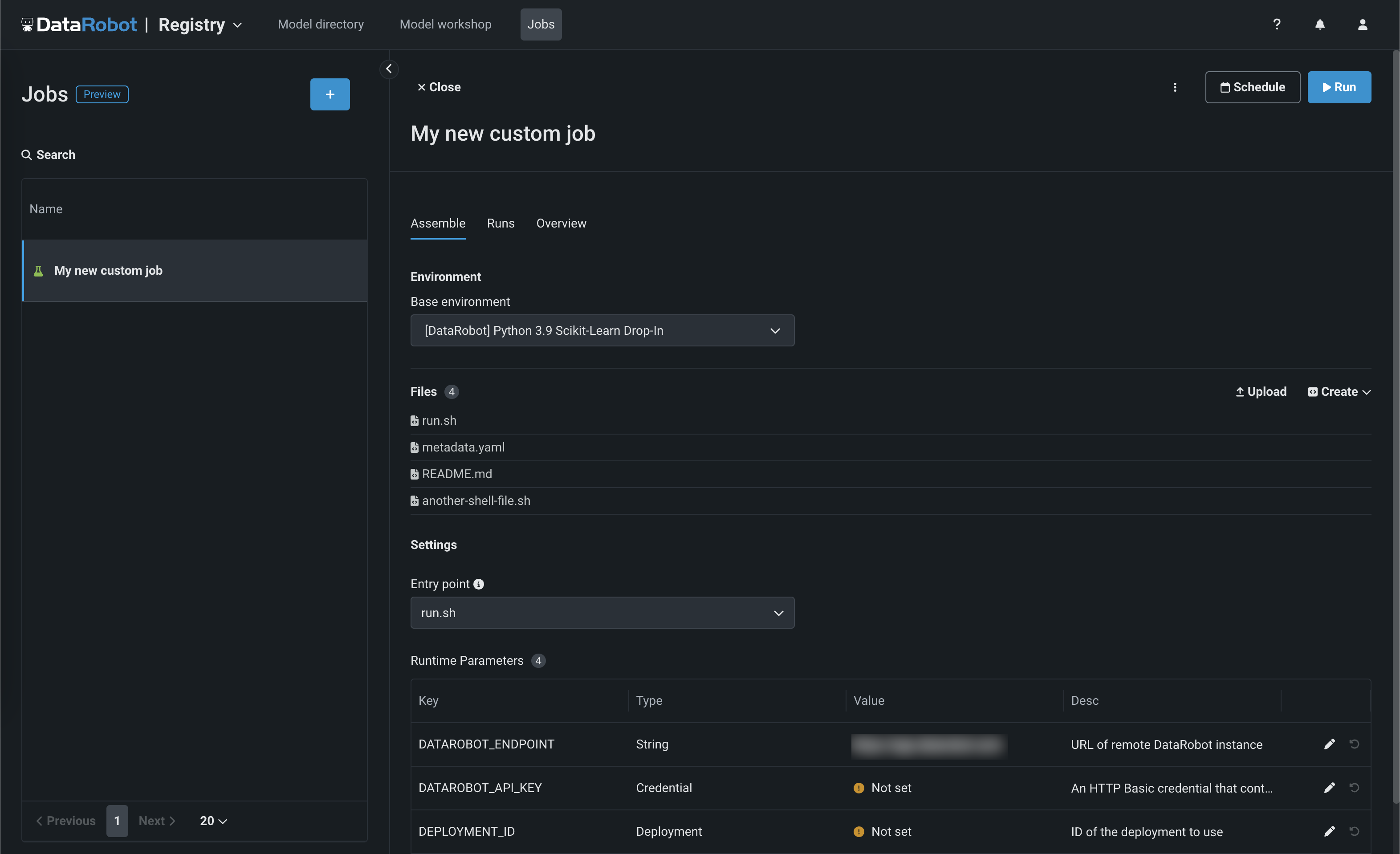
このリリースから、カスタムジョブにリソース設定セクションが含まれています。このセクションでは、カスタムジョブの実行に使用するリソースと、カスタムジョブのエグレストラフィックを設定できます。
詳しくはドキュメントをご覧ください。
プレミアム機能¶
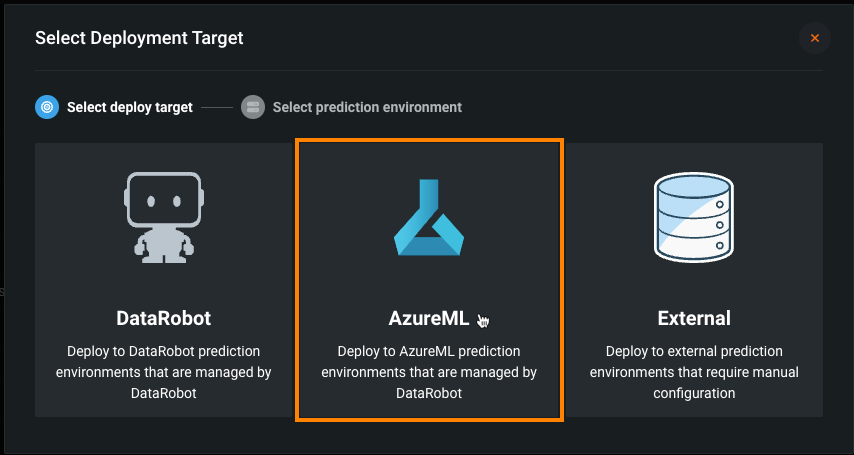
AzureMLでのスコアリングコードの自動デプロイと置換¶
DataRobotのスコアリングコードをAzureMLにデプロイするには、DataRobotが管理するAzureMLの予測環境を作成します。 DataRobotによる管理オプションを有効にすると、AzureMLに外部デプロイされたモデルは、スコアリングコードの自動置換を含むMLOps管理機能を利用できます。 AzureMLの予測環境を作成したら、モデルレジストリからその環境にスコアリングコード対応モデルをデプロイできます。
詳しくはドキュメントをご覧ください。
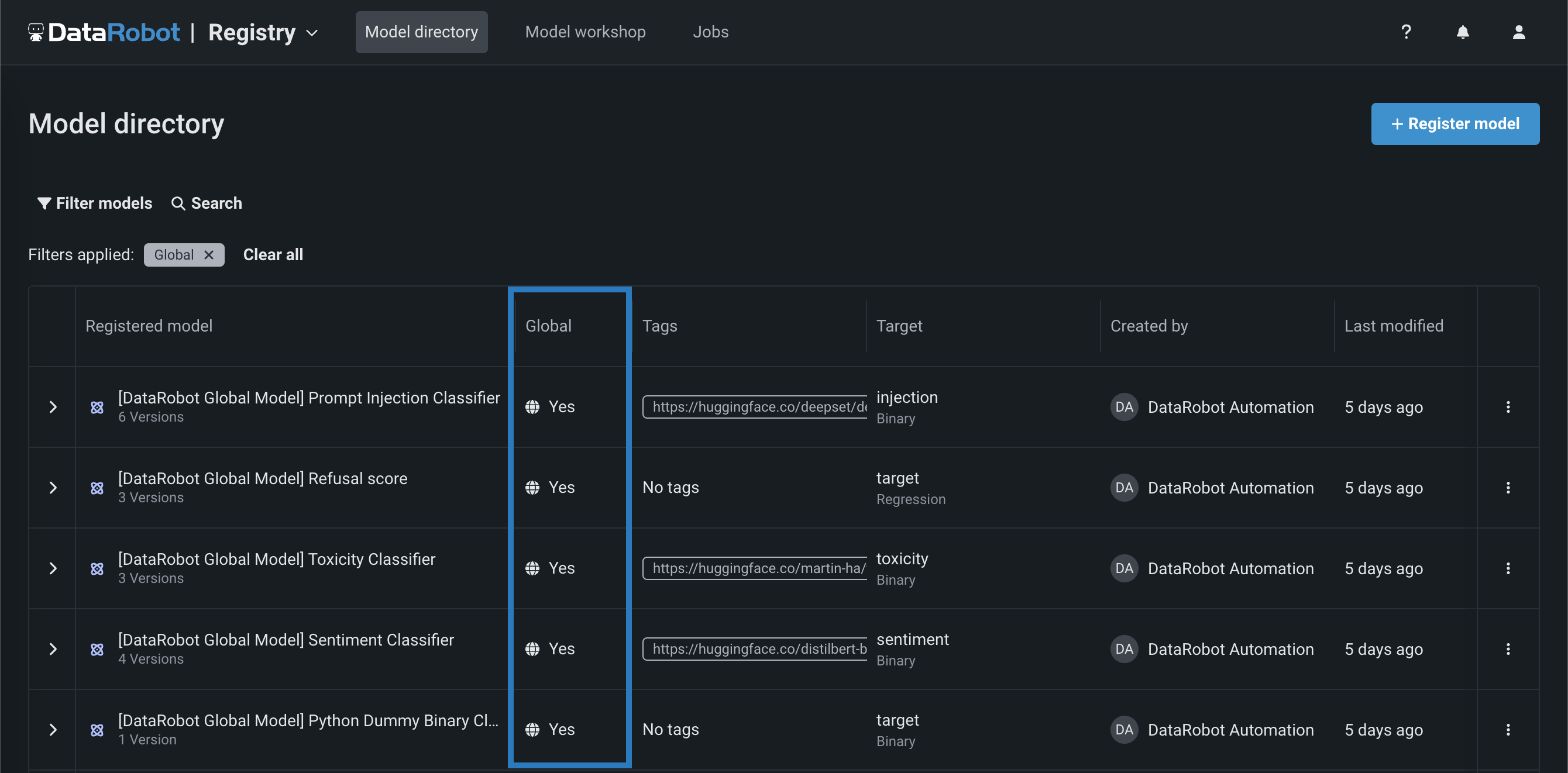
レジストリのグローバルモデル¶
レジストリ(NextGen)とモデルレジストリ(Classic)から、予測ユースケースや生成ユースケースのために事前にトレーニングされたグローバルモデルをデプロイすることができます。 これらの高品質でオープンソースのモデルは、トレーニング済みですぐにデプロイできるため、DataRobotのインストール後すぐに予測を行うことができます。 GenAIのユースケースには、プロンプトインジェクション、毒性、センチメントを識別する分類器や、拒否スコアを出力するリグレッサーが用意されています。 グローバルモデルはすべてのユーザーが使用できますが、編集権限を持つのは管理者のみです。 レジストリ > モデルディレクトリページでグローバルモデルを識別するには、グローバル列を見つけて、 はいが付いているモデルを探します。
チャット生成Q&Aアプリケーションの構築と使用¶
プレミアム機能です。DataRobotでチャット生成のQ&Aアプリケーションを作成し、ナレッジベースのQ&Aユースケースを探索しながら、生成AIを活用してビジネス上の意思決定を繰り返し行い、ビジネス価値を示すことができます。 Q&Aアプリは、構築したLLMモデルの結果をプロトタイプ化、調査、および共有するための直感的で応答性に優れた方法を提供します。 Q&Aアプリにより、引用に裏打ちされた生成AIの会話が可能になります。 さらに、DataRobot以外のユーザーとアプリを共有して、使いやすさを広めることもできます。
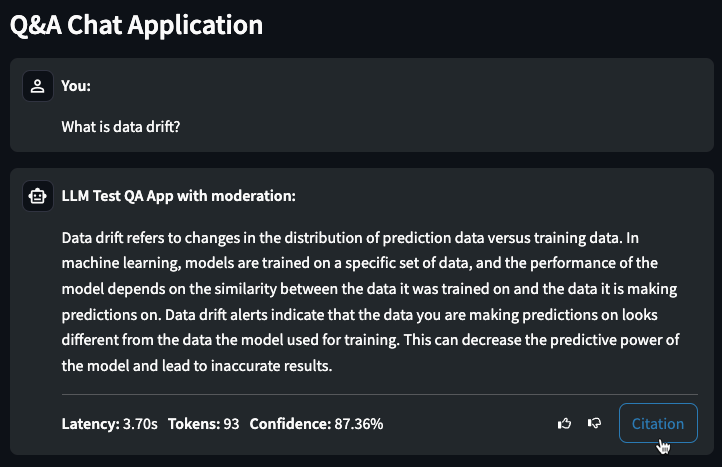
プレミアム機能のドキュメントをご覧ください。
一般提供機能¶
デプロイの通知ポリシー¶
通知ポリシーの作成を通じてデプロイ通知を設定すると、通知チャネルやテンプレートを設定したり組み合わせたりできます。 通知テンプレートは通知をトリガーするイベントを決定し、チャネルは通知されるユーザーを決定します。 使用可能な通知チャネルのタイプは、Webhook、メール、Slack、Microsoft Teams、ユーザー、グループ、カスタムジョブです。 デプロイに通知ポリシーを作成する場合、ポリシーテンプレートを変更せずに使用することも、新しいポリシーのベースとして変更を加えることもできます。 また、完全に新規の通知ポリシーを作成することもできます。
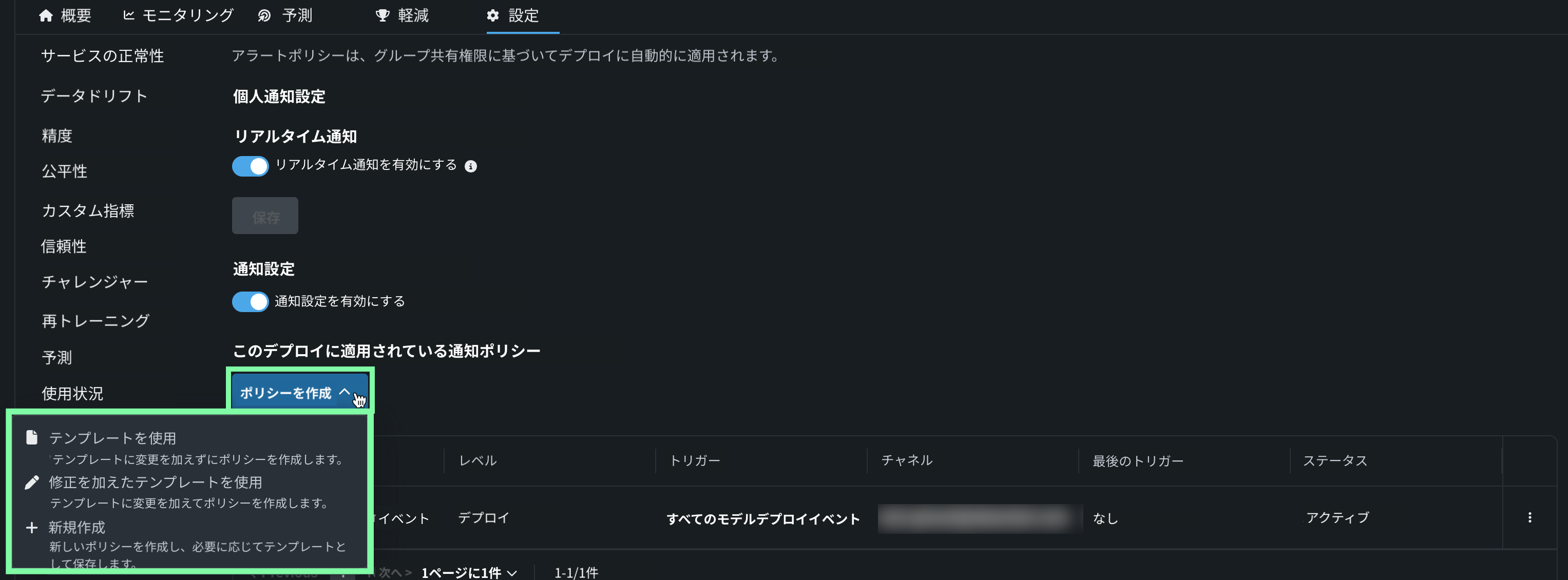
詳しくはドキュメントをご覧ください。
予測値と実測値の適時性インジケーター¶
デプロイには、サービスの正常性、データドリフト、精度など、デプロイの全般的な正常性を定義するいくつかのステータスがあります。 これらのステータスは、最新の使用可能なデータに基づいて計算されます。 24時間以上の間隔で行われたバッチ予測に依存するデプロイの場合、この方法では、 デプロイインベントリの予測正常性インジケーターのステータスがグレー/不明になることがあります。 一般提供機能になりました。これらのデプロイの正常性インジケーターは、最後に計算された正常性の状態を保持し、古いデータに基づいているときはそれを明示する適時性ステータスインジケーターとともに表示されます。 状況に応じて、デプロイに適した適時性の間隔を決定できます。 デプロイの使用状況 > 設定タブで適時性の追跡を有効にすると、 使用状況タブと デプロイインベントリで適時性インジケーターを表示できます。
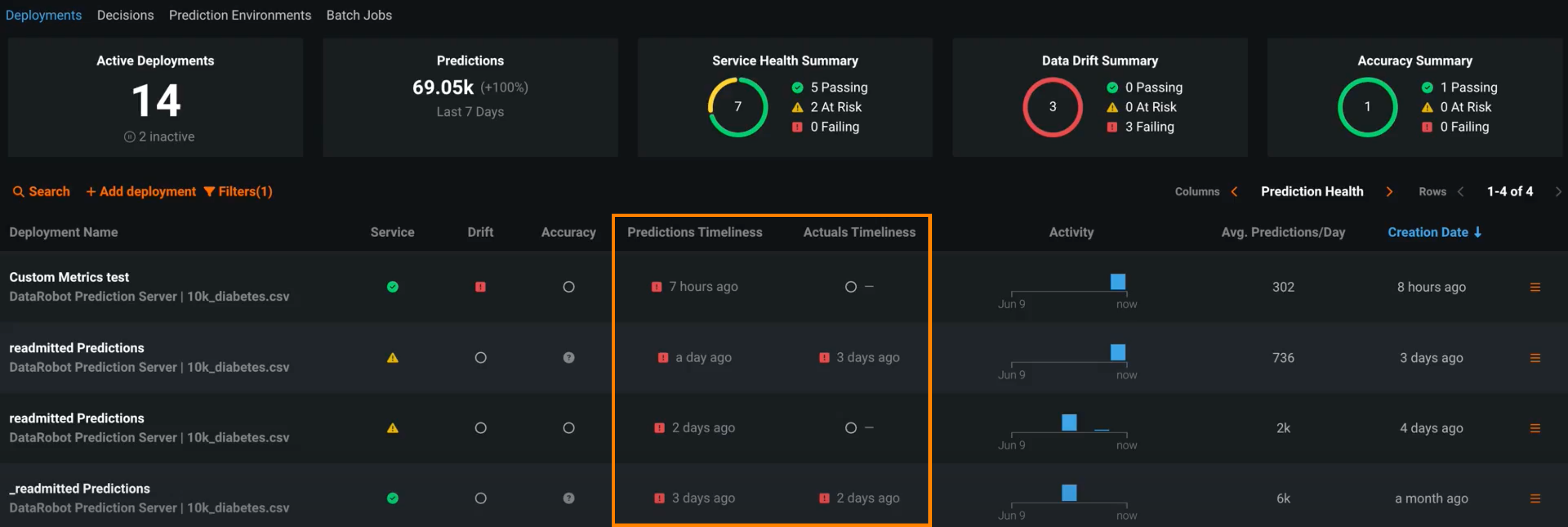
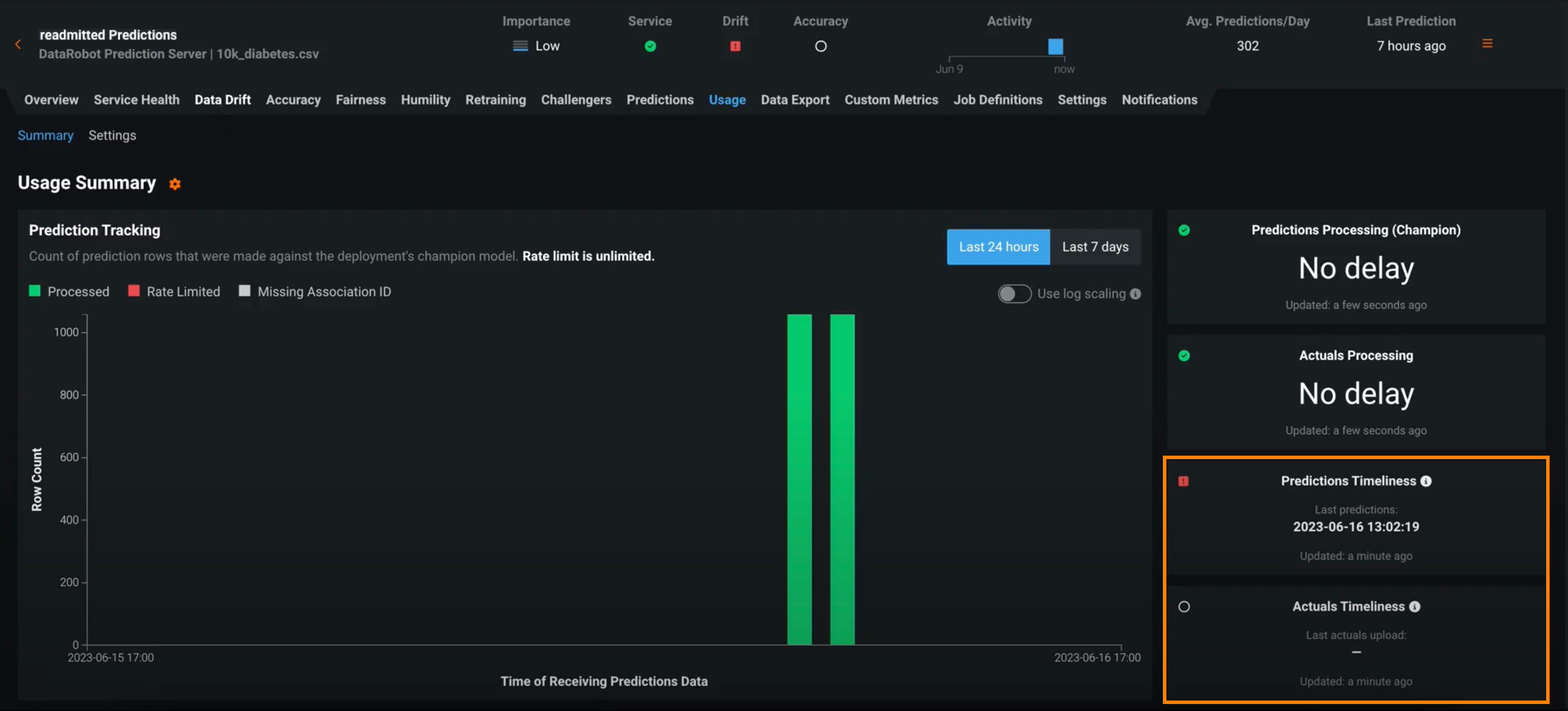
DRApps CLIでのカスタムアプリのホスティング¶
DRAppsはシンプルなコマンドラインインターフェイス(CLI)です。DataRobotでDataRobotの実行環境を使用するStreamlitアプリなどのカスタムアプリケーションをホストするのに必要なツールを提供します。 これにより、独自のDockerイメージを構築せずにアプリを実行できます。 カスタムアプリケーションはストレージを提供しません。ただし、DataRobotの全APIやその他のサービスにアクセスできます。 また、DockerコンテナにAIアプリ(Classic)またはカスタムアプリケーション(NextGen)をアップロードすることもできます。
休止状態のアプリケーション
アプリケーションは、一定期間操作がないと休止状態になります。 休止状態のアプリケーションに初めてアクセスすると、再起動中にロード画面が表示されます。
詳細については、ドキュメントとdr-appsリポジトリを参照してください。
バッチ予測での列名の再マッピング¶
1回限りまたは定期的なバッチ予測を設定する際に、予測ジョブの出力で列名を変更できます。これを行うには、予測オプションの列名の再マッピングセクションで、追加されたエントリーに列名をマッピングします。 + 列名の再マッピングを追加をクリックし、入力列名を予測出力で指定された出力列名に置き換えるように定義します。

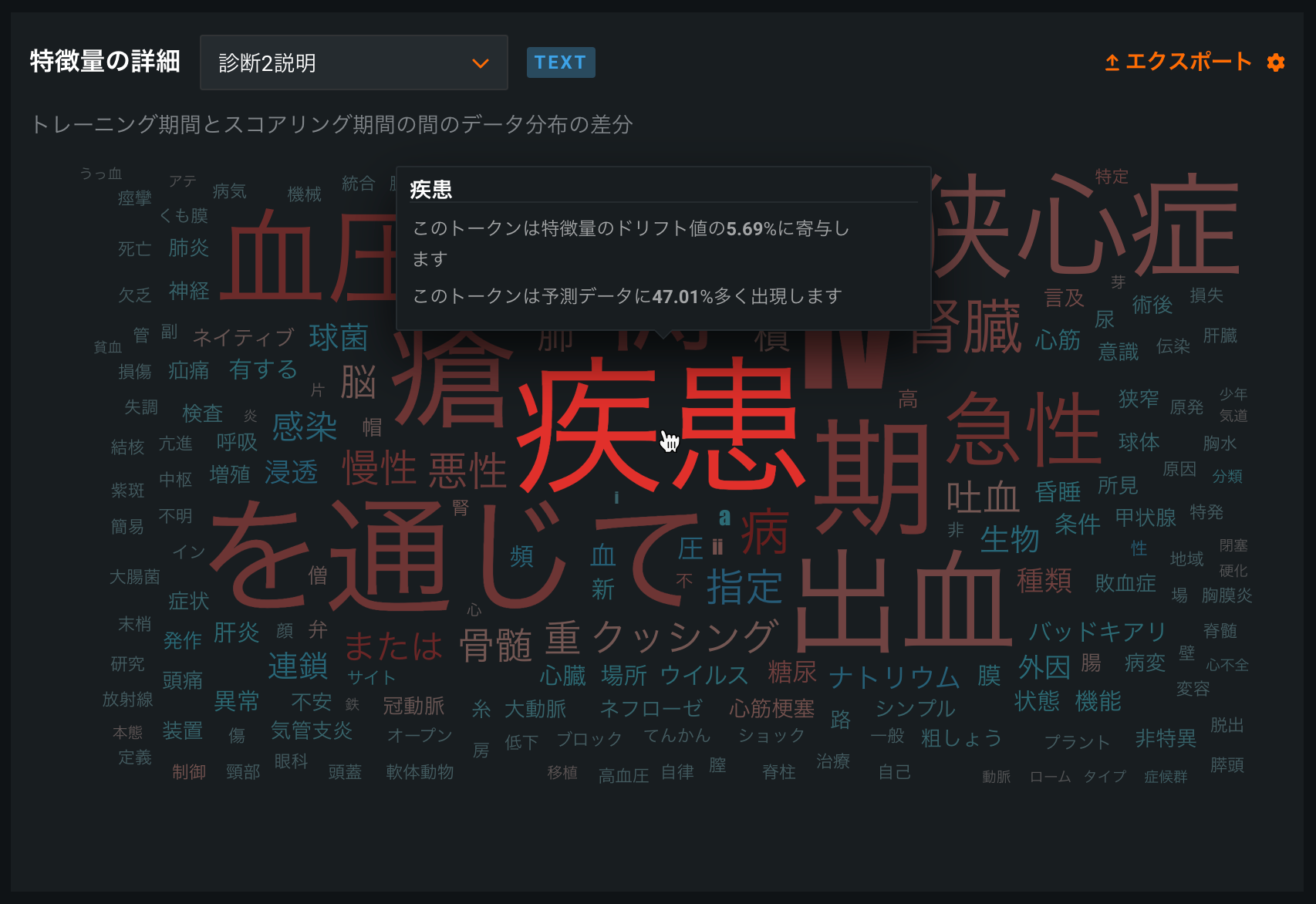
日本語テキストの特徴量ドリフトでのトークン化を改善¶
データドリフトタブの特徴量の詳細チャートのテキストトークン化が日本語のテキスト特徴量向けに改善され、MeCabでのトークン化による単語グラムベースのデータドリフト分析が実装されました。 さらに、日本語のテキスト特徴量で、デフォルトのストップワードフィルターが改善されました。
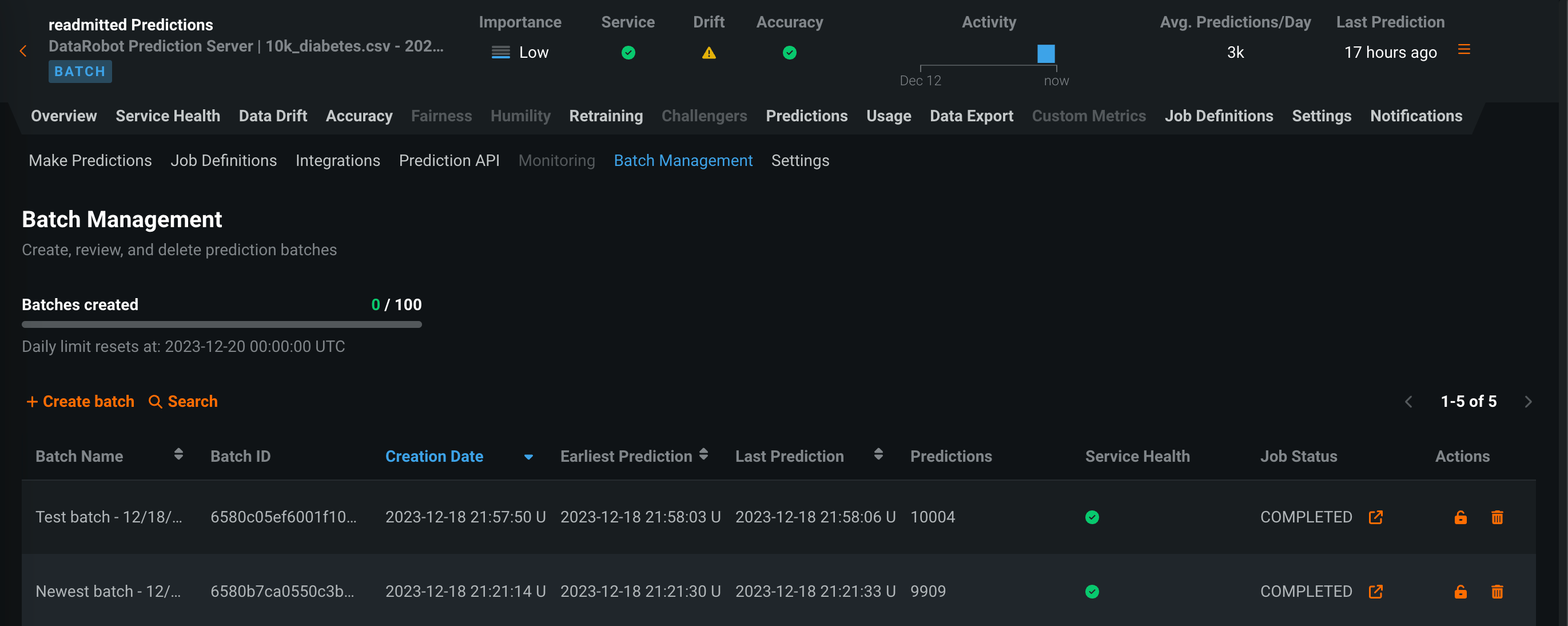
デプロイ予測のバッチ監視¶
バッチ対応のデプロイで、時間ではなくバッチごとに整理された監視統計を表示します。 予測 > バッチ管理タブでは、バッチの作成と管理ができます。 その後、これらのバッチに予測を追加し、デプロイ内のバッチごとにサービスの正常性、データドリフト、精度、カスタム指標の統計情報を表示できます。 バッチを作成して、バッチに予測を割り当てるには、UIまたはAPIを使用します。 さらに、バッチ予測またはスケジュールされたバッチ予測ジョブが実行されるたびに、バッチが自動的に作成され、バッチ予測ジョブからのすべての予測がそのバッチに追加されます。
詳しくはドキュメントをご覧ください。
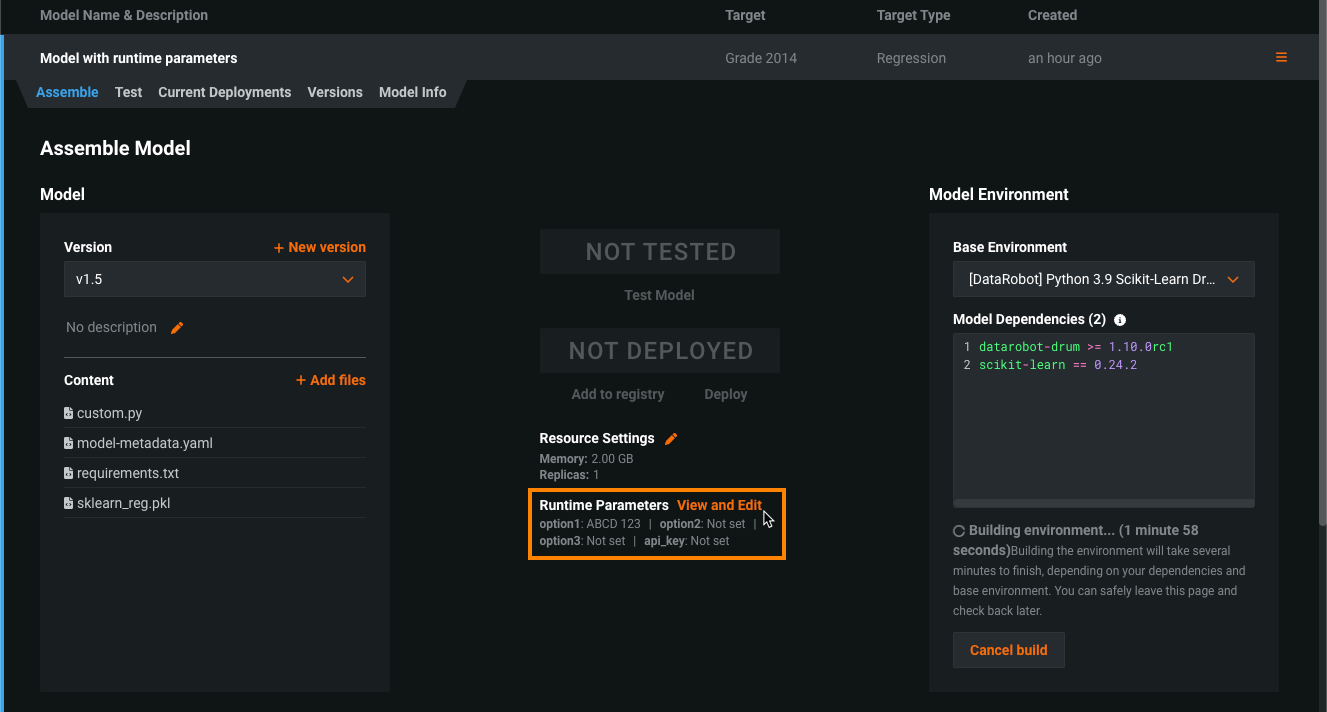
カスタムモデルのランタイムパラメーター¶
model-metadata.yamlファイル内のruntimeParameterDefinitionsでランタイムパラメーターを定義し、カスタムモデルのアセンブル タブ内のランタイムパラメーターセクションで管理します。
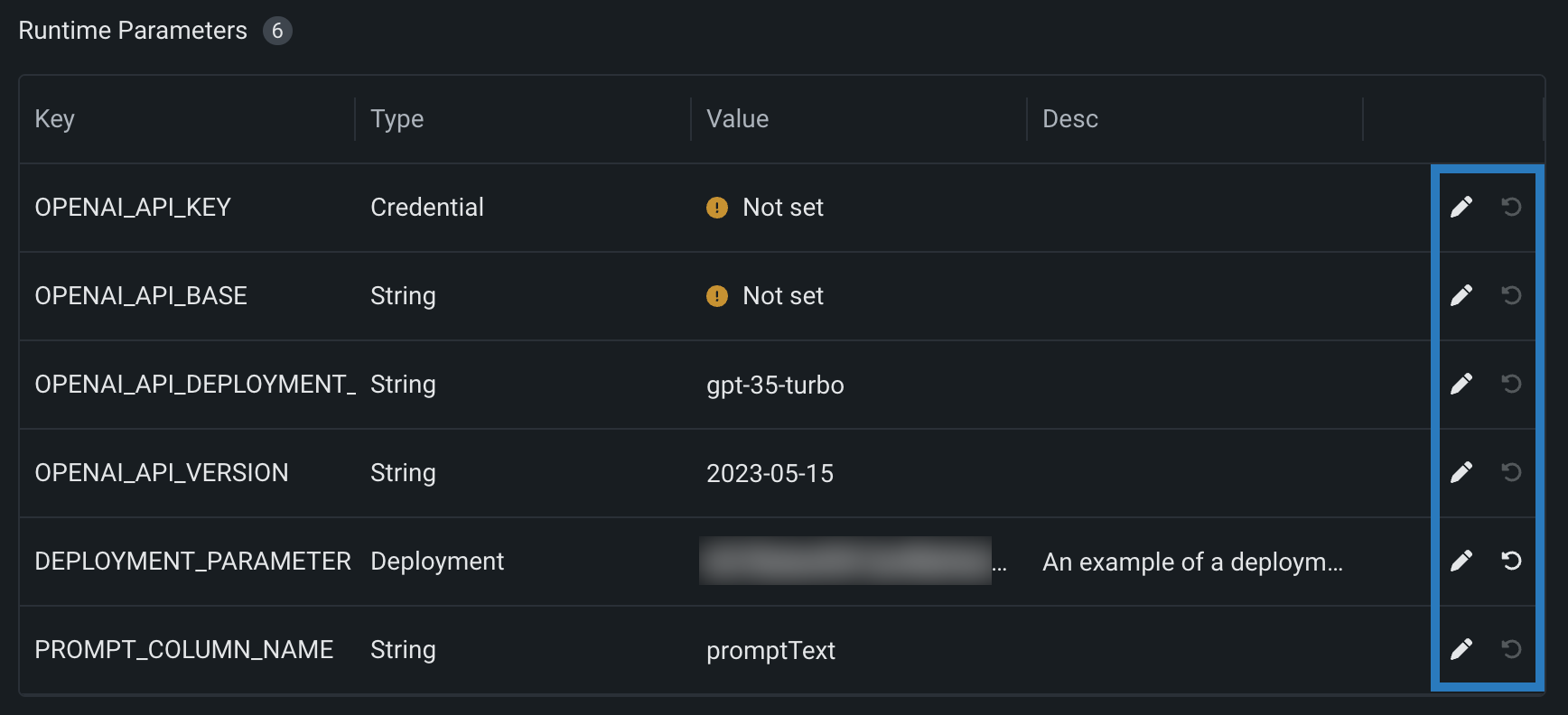
defaultValueのない定義で、ランタイムパラメーターにallowEmpty: falseがある場合は、カスタムモデルを登録する前に値を設定する必要があります。
詳細については、ClassicのドキュメントまたはNextGenのドキュメントをご覧ください。
カスタムモデル用の新しいランタイムパラメーター定義オプション¶
モデルメタデータを使用してカスタムモデルのランタイムパラメーターを作成する際に、typeキーをstringやcredentialに加えてbooleanまたはnumericに設定できるようになりました。 model-metadata.yamlに、以下の新しい_オプション_のruntimeParameterDefinitionsを追加することもできます。
| キー | 説明 |
|---|---|
defaultValue |
ランタイムパラメーターのデフォルト文字列値(credentialタイプはデフォルト値をサポートしません) |
minValue |
numericランタイムパラメーターの場合、そのランタイムパラメーターで入力可能な最小数値を設定します。 |
maxValue |
numericランタイムパラメーターの場合、そのランタイムパラメーターで入力可能な最大数値を設定します。 |
credentialType |
credentialランタイムパラメーターの場合、パラメーターに含める資格情報のタイプを設定します。 |
allowEmpty |
ランタイムパラメーターの空のフィールドに関するポリシーを設定します。
|
詳しくはドキュメントをご覧ください。
カスタムモデル用の新しい環境変数¶
ドロップイン環境またはDRUM上に構築されたカスタム環境を使用する場合、カスタムモデルのコードは、DataRobotクライアントおよびMLOps接続クライアントへのアクセスを容易にするために挿入された複数の環境変数を参照できます。 環境変数DATAROBOT_ENDPOINTとDATAROBOT_API_TOKENには、NextGenおよびDataRobot Classicのプレミアム機能であるパブリックネットワークアクセスが必要です。
| 環境変数 | 説明 |
|---|---|
MLOPS_DEPLOYMENT_ID |
カスタムモデルがデプロイモードで実行されている場合(カスタムモデルがデプロイされている場合)、デプロイIDを使用できます。 |
DATAROBOT_ENDPOINT |
カスタムモデルに パブリックネットワークアクセスがある場合、DataRobotエンドポイントURLを使用できます。 |
DATAROBOT_API_TOKEN |
カスタムモデルに パブリックネットワークアクセスがある場合、DataRobot APIトークンを使用できます。 |
モデルレジストリのカスタムジョブ¶
モデルレジストリでカスタムジョブを作成して、モデルとデプロイの自動化(たとえば、カスタムテスト)を実装します。 各ジョブは自動化されたワークロードとして機能し、終了コードによって正常終了か失敗かが判定されます。 作成したカスタムジョブは、1つ以上のモデルまたはデプロイで実行できます。 カスタムジョブを構築するときに定義する自動ワークロードは、DataRobotのパブリックAPIを使用して予測リクエストの作成、入力の取得、出力の保存を行うことができます。
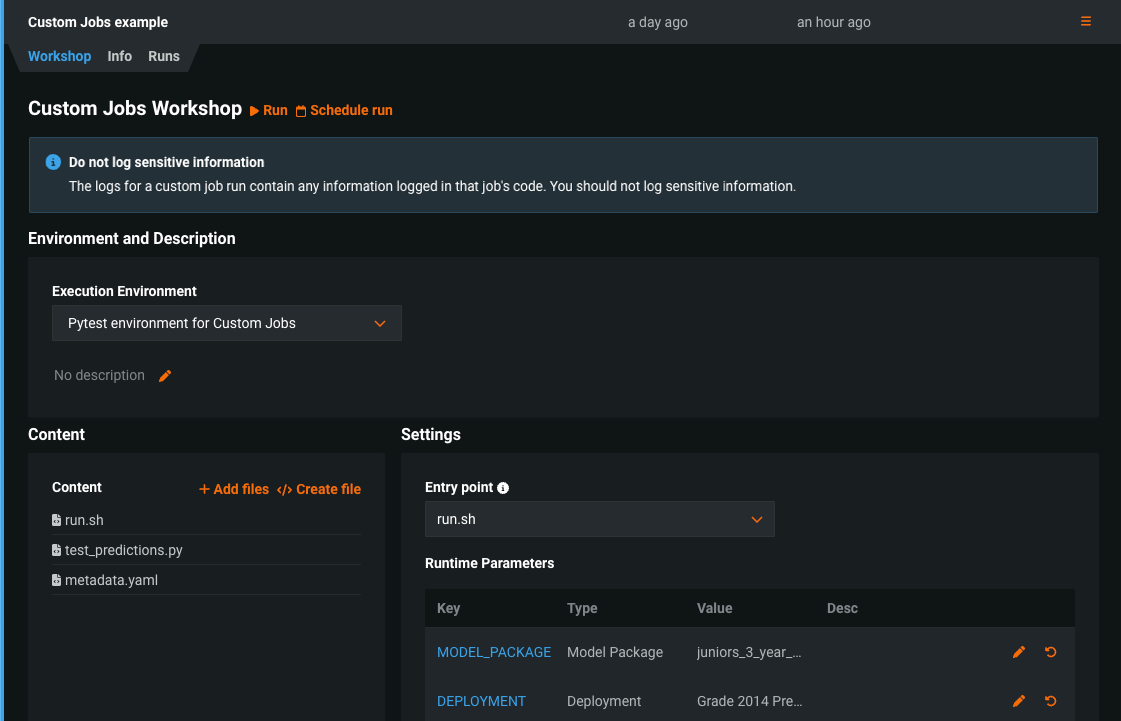
詳しくはドキュメントをご覧ください。
カスタムアプリの一般提供を開始¶
一般提供機能になりました。Dockerで作成したイメージから、DataRobotでカスタムアプリケーションを作成し、Streamlit、Dash、R Shinyなどのウェブアプリケーションを使って機械学習プロジェクトを共有できます。 DRApps(シンプルなコマンドラインインターフェイス)により、DataRobotの実行環境を使用して、DataRobotでカスタムアプリケーションをホストすることもできます。 これにより、独自のDockerイメージを構築せずにアプリを実行できます。 カスタムアプリケーションはストレージを提供しません。ただし、DataRobotの全APIやその他のサービスにアクセスできます。 このリリースから、カスタムアプリケーションは、一定期間使用されないと休止状態になります。休止状態のカスタムアプリケーションに初めてアクセスすると、再起動中にロード画面が表示されます。
カスタムアプリケーションの共有¶
カスタムアプリケーションをDataRobotユーザーだけでなくDataRobot以外のユーザーとも共有できるため、作成したカスタムアプリケーションの利用範囲が広がります。 共有機能には、アプリケーションページのアクションメニューからアクセスします。 カスタムアプリをDataRobot以外のユーザーと共有するには、外部共有を有効にするをオンに切り替えて、アプリへのアクセスを許可するメールドメインとアドレスを指定する必要があります。 共有設定を行うと、これらのユーザーと共有するためのリンクが提供されます。
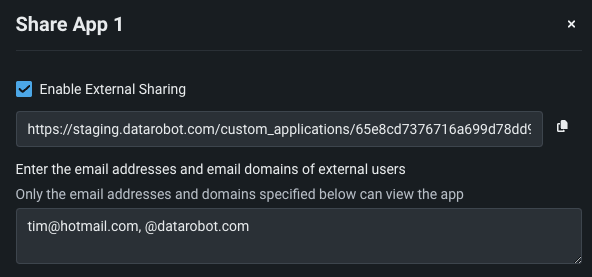
プレビュー機能¶
カスタムモデル出力で列を追加¶
score()フックは、string、int、float、bool、またはdatetime型のデータを含む追加の列を数に制限なく返すことができます。 追加の列がscore()メソッドによって返される場合、予測応答は次のようになります。
- 表形式の応答(CSV)の場合、追加の列は応答テーブルまたはデータフレームの一部として返されます。
- JSON応答の場合、
extraModelOutputキーが各行と一緒に返されます。 このキーは、行内の各追加列の値を含むディクショナリです。
デフォルトではオフの機能フラグ:予測応答で追加のカスタムモデル出力を有効にする
プレビュー機能のドキュメントをご覧ください。
予測リクエストでの列フィルターの無効化¶
カスタムモデルを構築する際、カスタムモデルによる予測での列フィルターを有効および無効にすることができます。 選択したフィルター設定は、カスタムモデルの テストやデプロイの際に同様に適用されます。 デフォルトでは、ターゲット列は予測リクエストから除外されます。また、トレーニングデータが割り当てられている場合、トレーニングデータセットに存在しない追加の列は、モデルに送信されるスコアリングリクエストから除外されます。 あるいは、予測データセットに欠損列がある場合、欠損している特徴量を通知するエラーメッセージが表示されます。
カスタムモデルを構築する場合、この列フィルターを無効にすることができます。 モデルワークショップでカスタムモデルを開いて、アセンブルタブをクリックし、設定セクションの列フィルターで、リクエストからターゲット列を除外をオフにします(または、トレーニングデータが割り当てられている場合は、ターゲット列とトレーニングデータにない余分な列を除外をオフにします)。
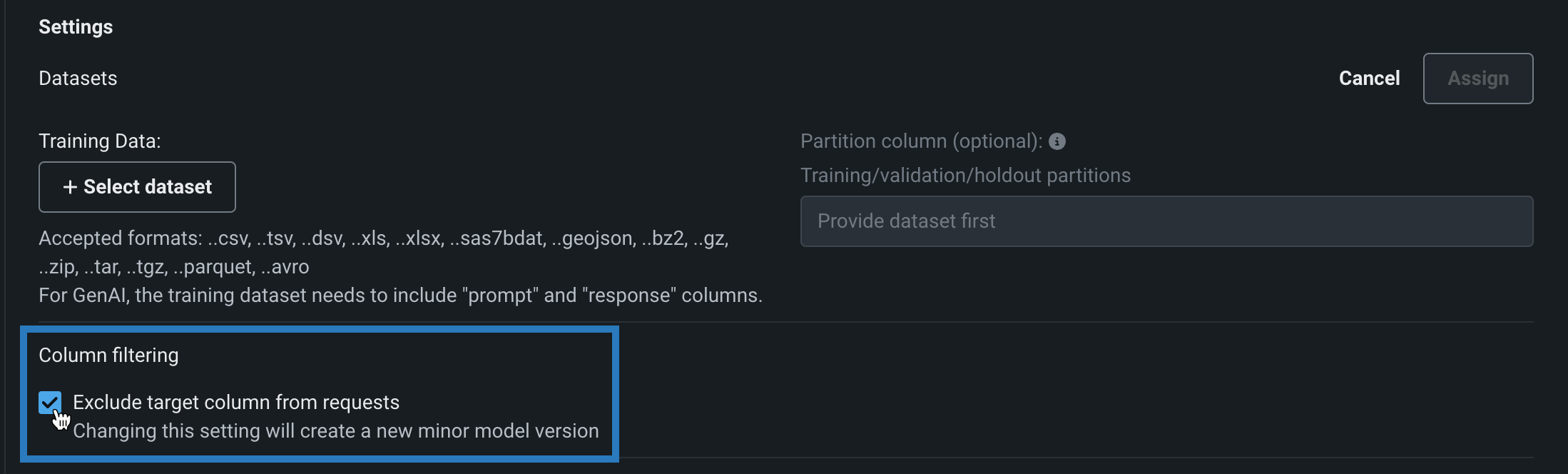
デフォルトではオフの機能フラグ:カスタムモデルの予測で特徴量のフィルターを有効にする
プレビュー機能のドキュメントをご覧ください。
DataRobotの監視エージェント¶
通常、監視エージェントはDataRobotの外部で実行され、外部モデルのコードでDataRobot MLOpsライブラリの呼び出しによって設定されたスプーラーから指標を報告します。 外部スプーラーの資格情報と設定の詳細を使用して外部予測環境を作成し、DataRobot_内_で監視エージェントを実行できるようになりました(プレビュー版の機能です)。
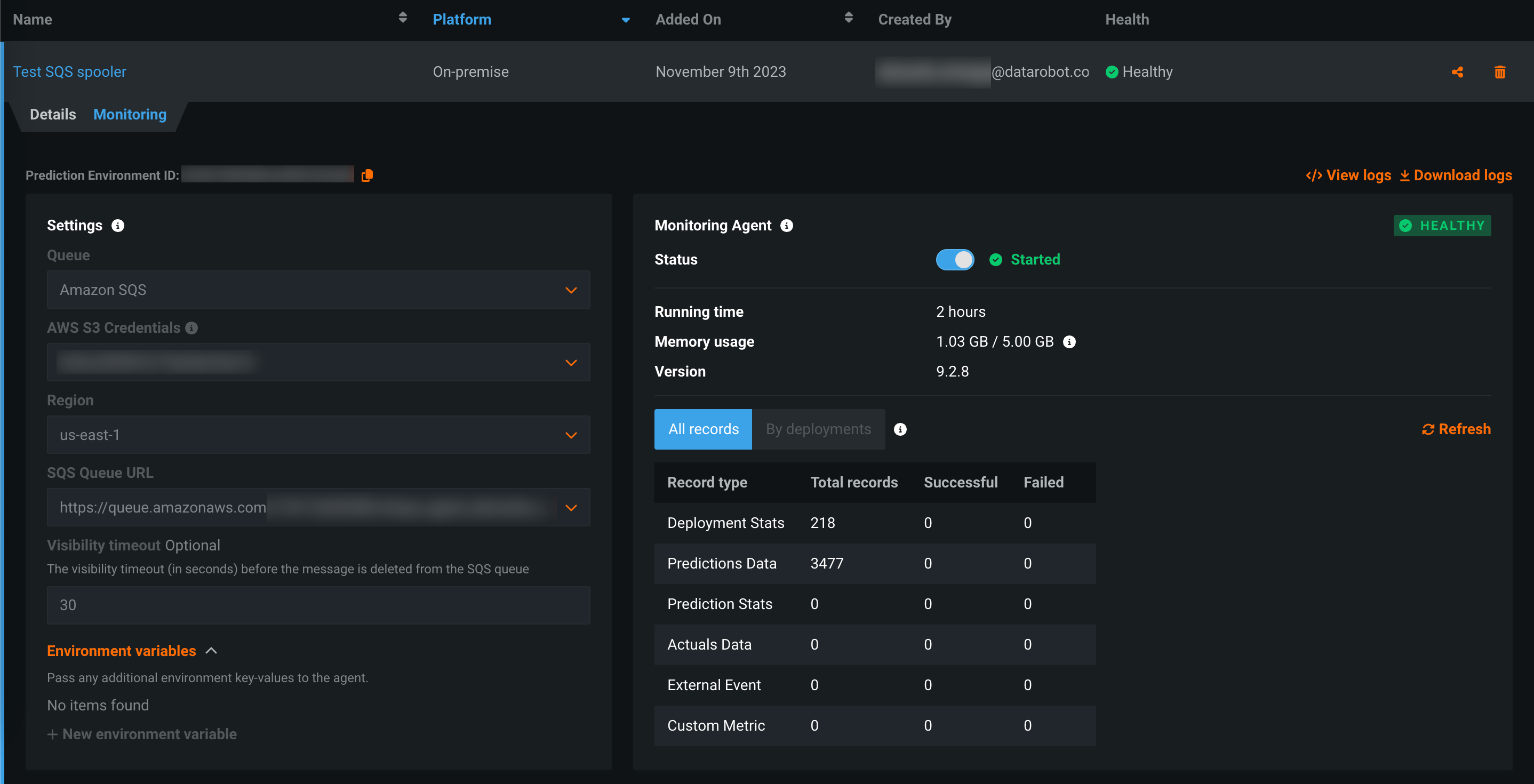
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ:DataRobotの監視エージェント
実測値と予測値のアップロード制限を設定¶
プレビュー版の機能です。使用状況タブから、組織のデプロイに設定されている時間単位、日単位、週単位のアップロード上限値を監視できます。 処理された予測値と実測値の数を視覚化するチャートと、返された予測結果のテーブルサイズの上限値を示すタイルが表示されます。
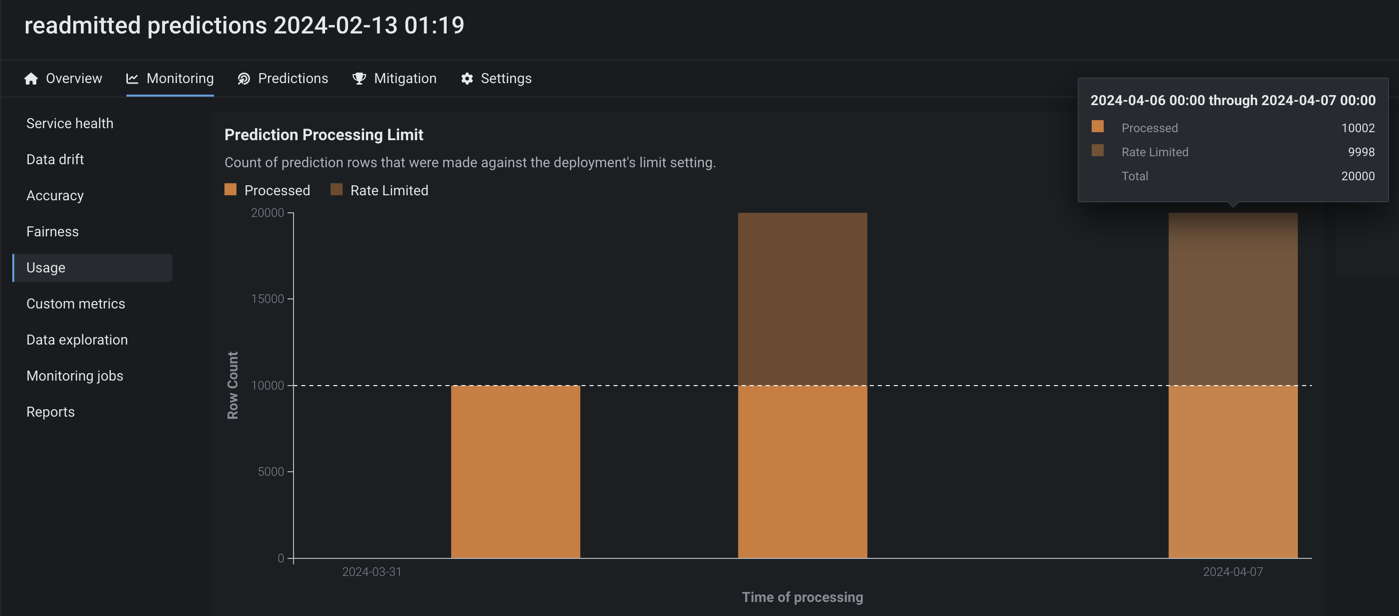
デフォルトではオフの機能フラグ:設定可能な予測値と実測値の制限を有効にする
プレビュー機能のドキュメントをご覧ください。
カスタムアプリケーションのランタイムパラメーターとリソースバンドルを設定¶
プレビュー版の機能です。NextGenのレジストリで、アプリケーションのソースにリソースとランタイムパラメーターを設定できます。 リソースバンドルは、本番環境での潜在的な環境エラーを最小限に抑えるために、アプリケーションが消費できるメモリーとCPUの最大量を決定します。 アプリケーションのソースから構築されたmetadata.yamlファイルに含めることで、カスタムアプリケーションで使用されるランタイムパラメーターを作成および定義できます。
デフォルトではオフの機能フラグ: ランタイムパラメーターとリソースの上限を有効にする、リソースのバンドルを有効にする
プレビュー機能のドキュメントをご覧ください。
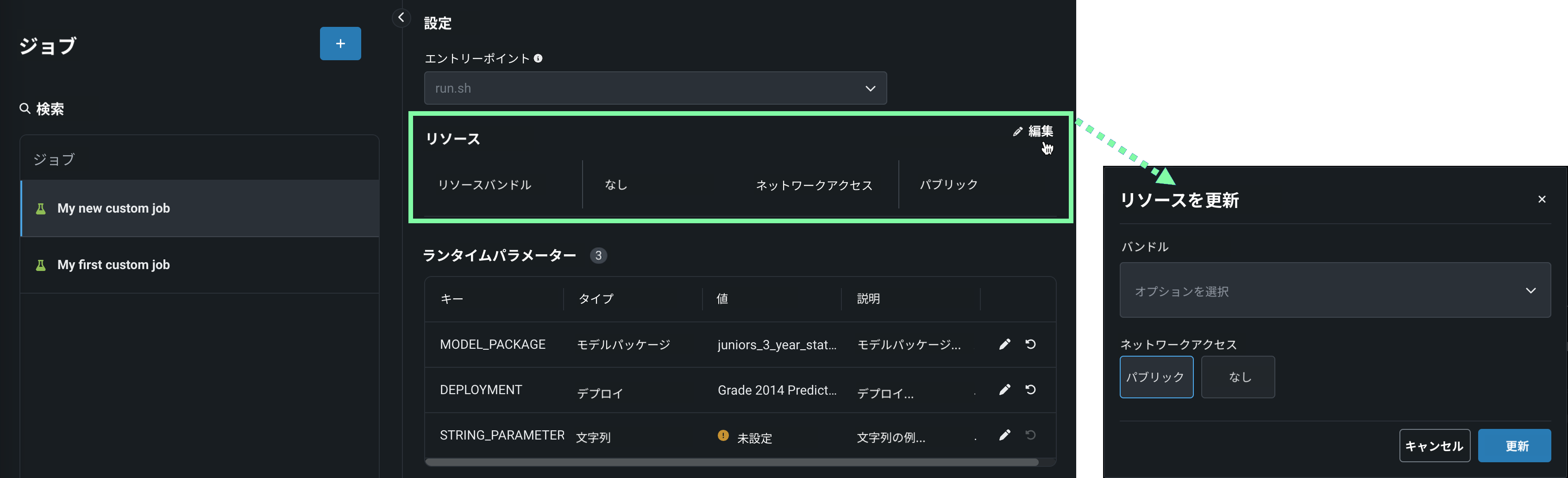
カスタムモデルのリソースバンドル¶
モデルを構築してリソース設定を行う際、メモリーではなくリソースバンドルを選択します。 リソースバンドルを使用すると、さまざまなCPUおよびGPUハードウェアプラットフォームから選択して、カスタムモデルを構築およびテストできます。 カスタムモデルの設定セクションで、リソース設定を開き、リソースバンドルを選択します。 この例では、モデルはNVIDIA A10デバイスでテストおよびデプロイされるように構築されています。
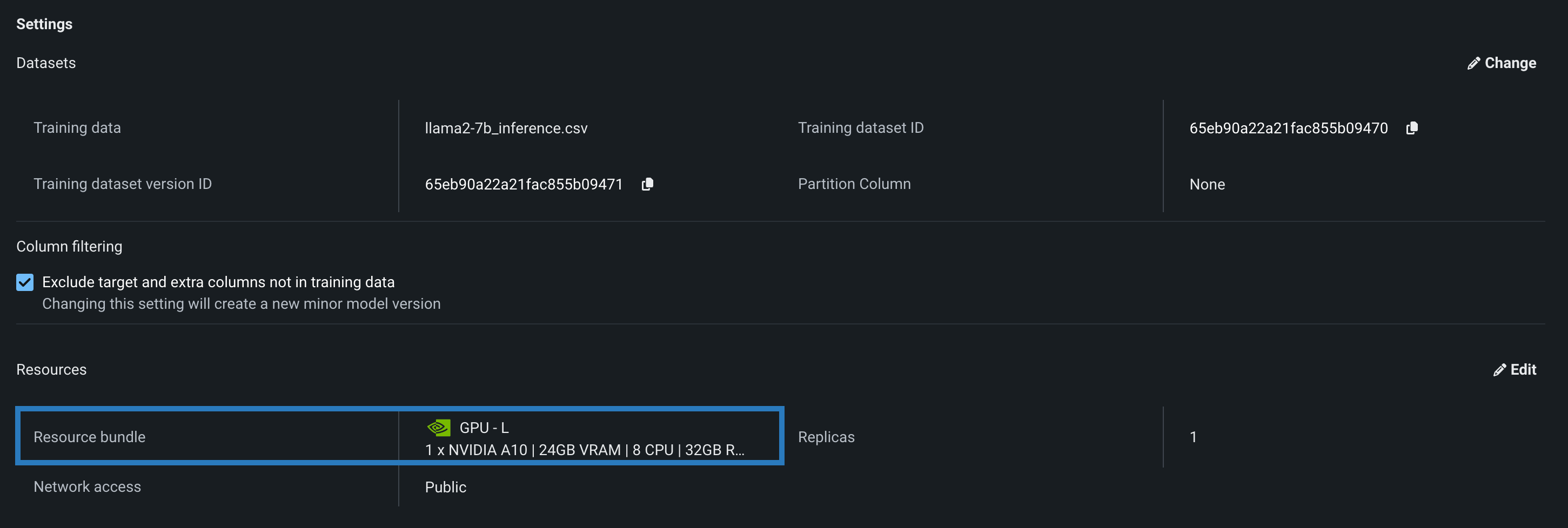
編集をクリックしてリソース設定の更新ダイアログボックスを開き、リソースのバンドルフィールドで、構築環境として使用可能な CPUおよび NVIDIA GPUデバイスを確認します。
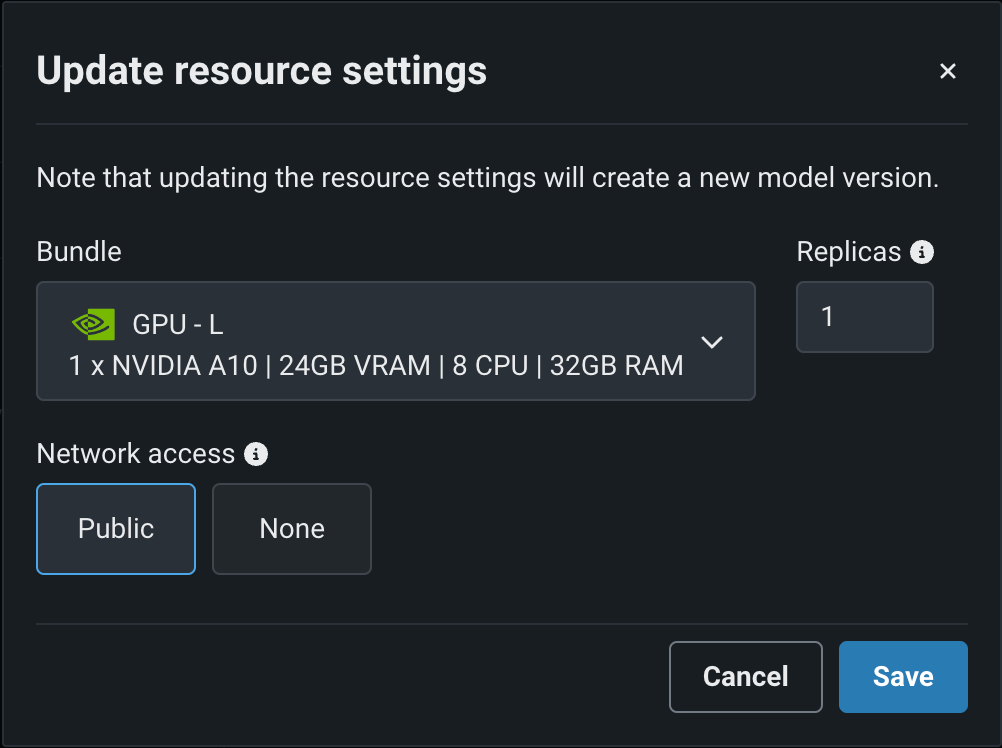
デフォルトではオフの機能フラグ: リソースのバンドルを有効にする、カスタムモデルでGPUを使用した推論を有効にする
プレビュー機能のドキュメントをご覧ください。
テキスト生成モデルの評価とモデレーション¶
評価とモデレーションのガードレールは、組織がプロンプトインジェクションや、悪意のある、有害な、または不適切なプロンプトや回答をブロックするのに役立ちます。 また、ハルシネーションや信頼性の低い回答を防ぎ、より一般的には、モデルをトピックに沿った状態に保つこともできます。 さらに、これらのガードレールは、個人を特定できる情報(PII)の共有を防ぐことができます。 多くの評価およびモデレーションガードレールは、デプロイされたテキスト生成モデル(LLM)をデプロイされたガードモデルに接続します。 これらのガードモデルはLLMのプロンプトと回答について予測し、これらの予測と統計を中心的なLLMデプロイに報告します。 評価とモデレーションのガードレールを使用するには、まず、LLMのプロンプトや回答について予測するガードモデルを作成してデプロイします。たとえば、ガードモデルは、プロンプトインジェクションや有害な回答を識別することができます。 次に、ターゲットタイプがテキスト生成のカスタムモデルを作成する場合、評価とモデレーションのガードレールを1つ以上定義します。
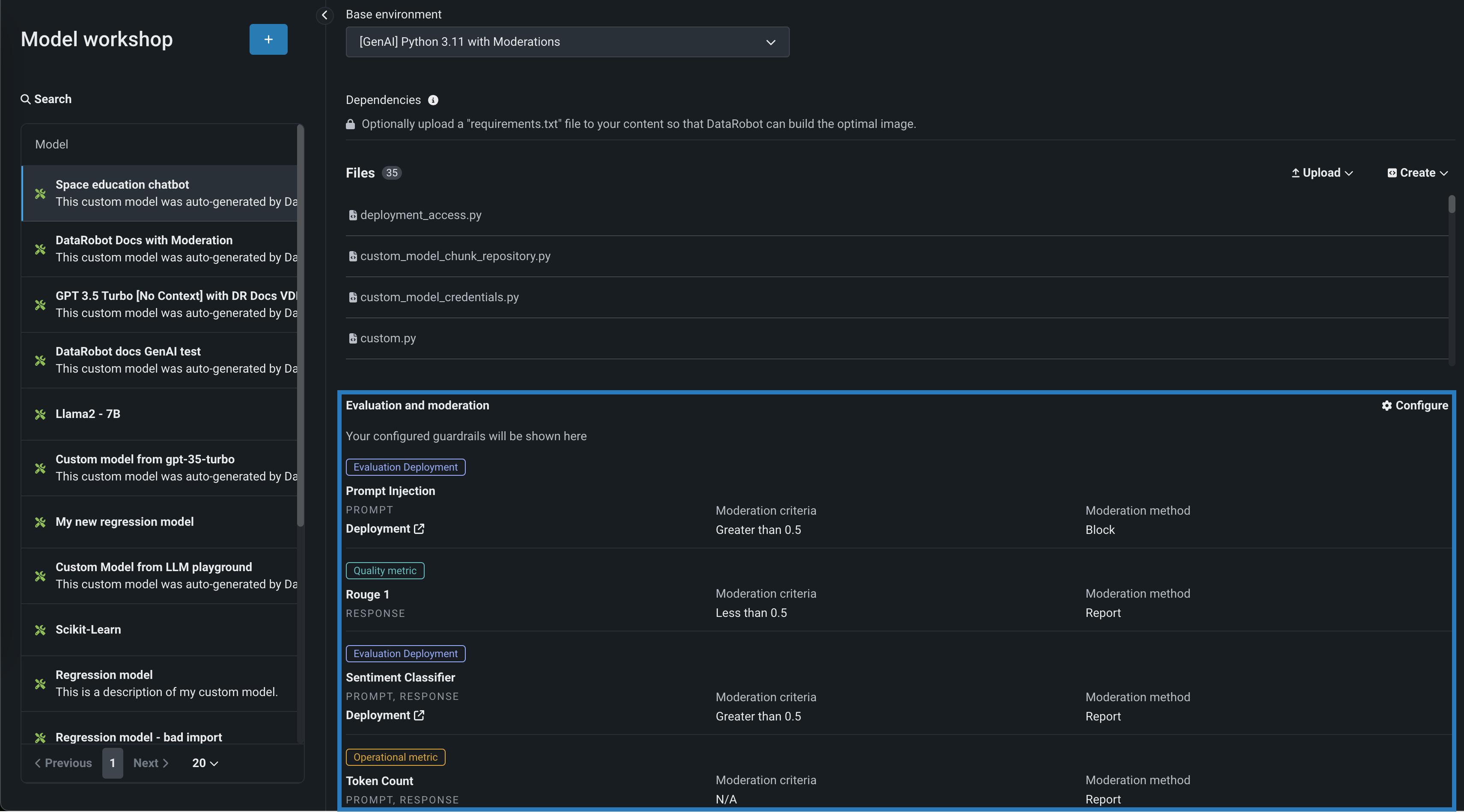
デフォルトではオフの機能フラグ:モデレーションのガードレールを有効にする、モデルレジストリでグローバルモデルを有効にする(プレミアム)、予測応答で追加のカスタムモデル出力を有効にする
プレビュー機能のドキュメントをご覧ください。
NVIDIA GPUでNeMo Guardrailsを使用した生成AI¶
DataRobotでNVIDIAを使用して、パフォーマンスの高速化を実現し、最高のオープンソースモデルとガードレールを活用することで、エンドツーエンドの生成AI (GenAI) 機能をすばやく構築できます。 DataRobotとNVIDIAの連携により、完全なエンドツーエンドの生成AI機能を提供する推論ソフトウェアスタックが構築されます。重要な機能がすぐに使えることで、パフォーマンス、ガバナンス、安全性が確保されます。
NextGen DataRobotのモデルワークショップでカスタム生成AIモデルを作成する際、基本環境として[NVIDIA] Triton Inference Server(vLLMバックエンド)を選択できます。 DataRobotにはNVIDIA Triton Inference Serverがネイティブに組み込まれており、GPUベースのモデルをNVIDIAデバイスに構築・デプロイする際に、特別なアクセラレーションを提供します。
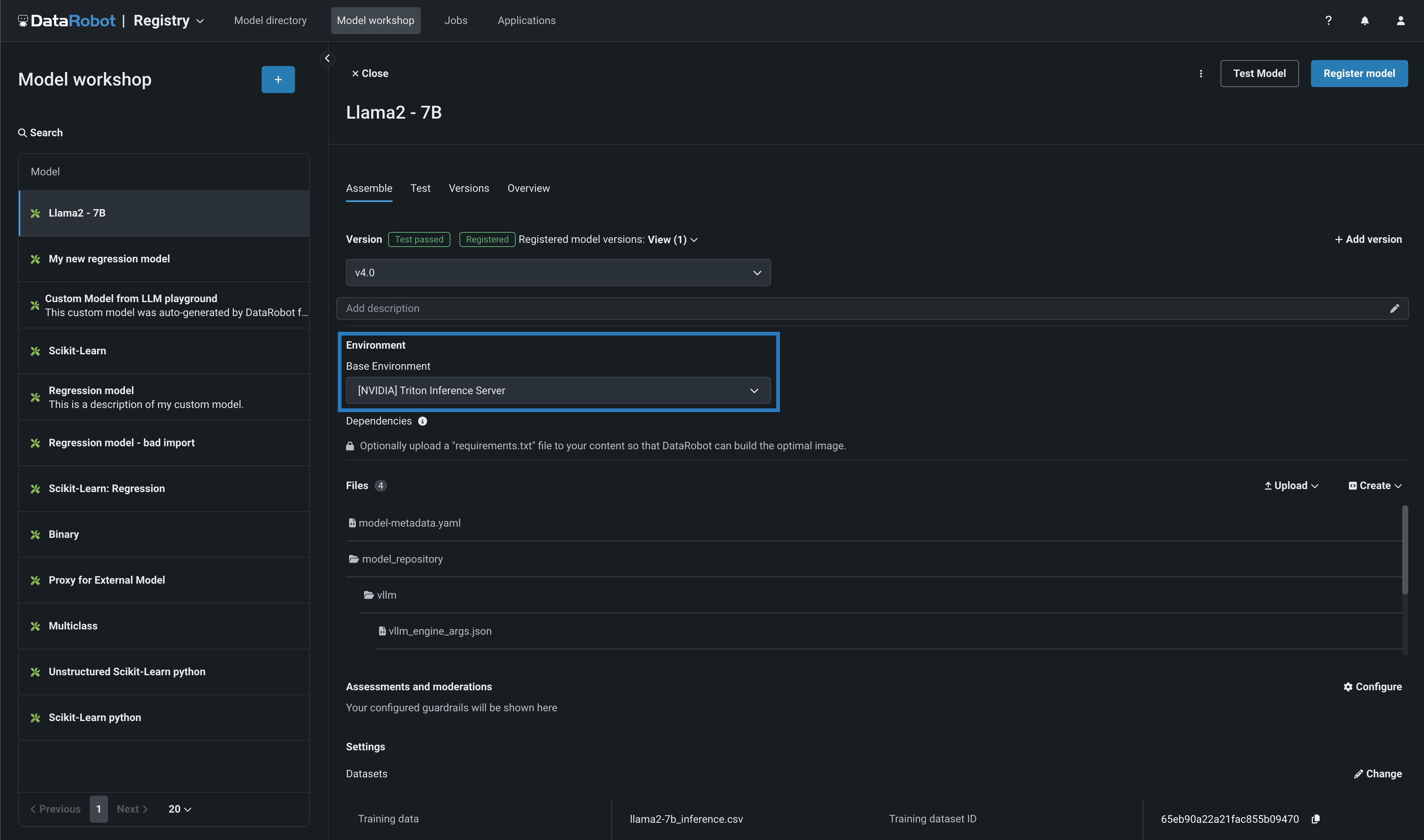
次に、カスタムモデルのリソース設定に移動して、DataRobotでの構築環境として利用可能なNVIDIAデバイスの範囲からリソースバンドルを選択できます。
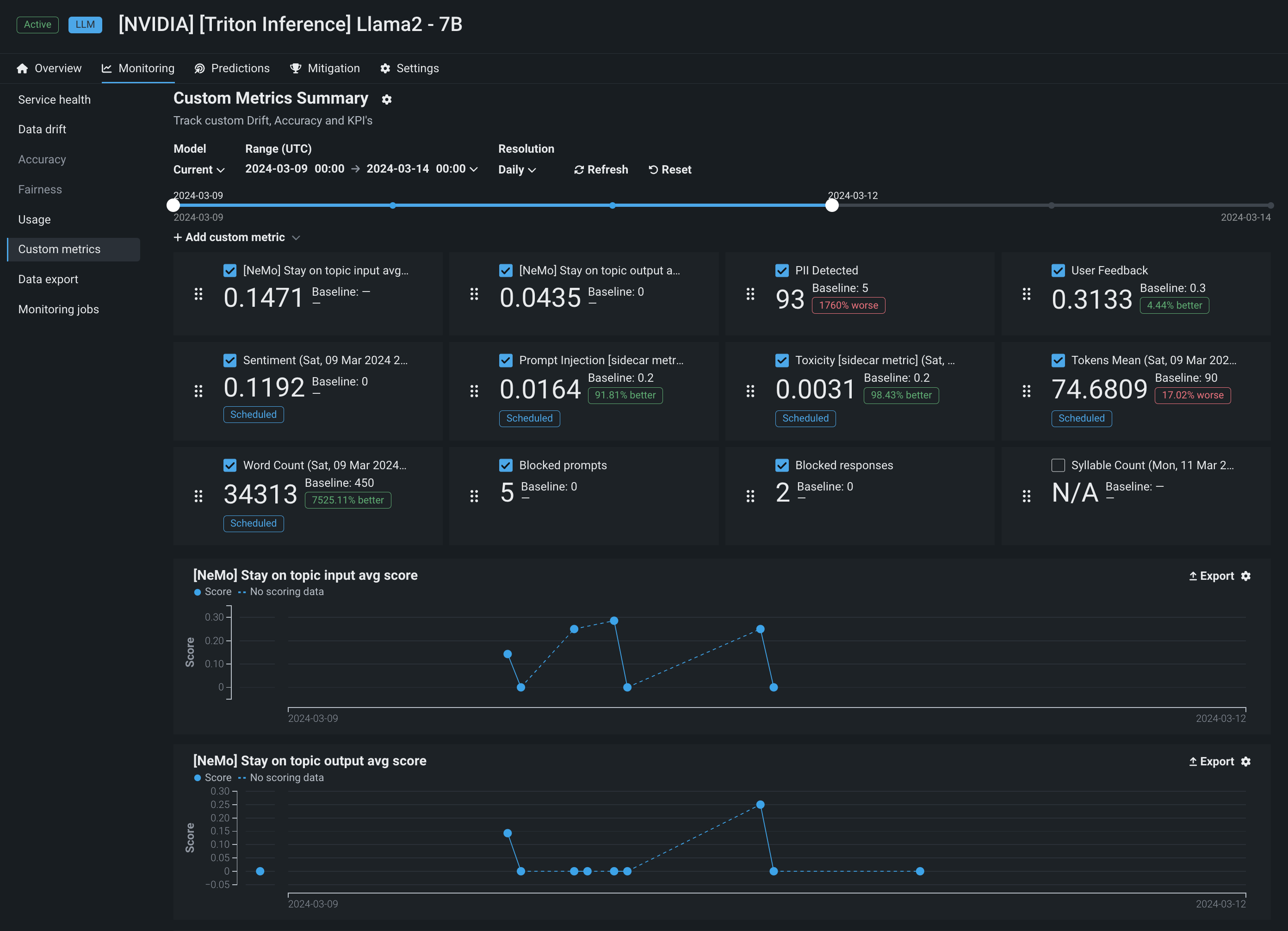
さらに、DataRobotには、NeMo Guardrailsとの連携により、カスタム指標を作成するための強力なインターフェイスも用意されています。 NeMoとの連携により、NeMoが提供する 「トピックに沿った」原則に違反した場合、プロンプトや補完をブロックする介入を用いて、モデルがトピックに沿った状態を維持できるようにする強力なレールが提供されます。
時系列カスタムモデル¶
時系列(二値)または時系列(連続値)をターゲットタイプとして選択し、二値分類および連続値モデルに必要なフィールドに加えて、時系列固有のフィールドを設定することによって、時系列カスタムモデルを作成します。
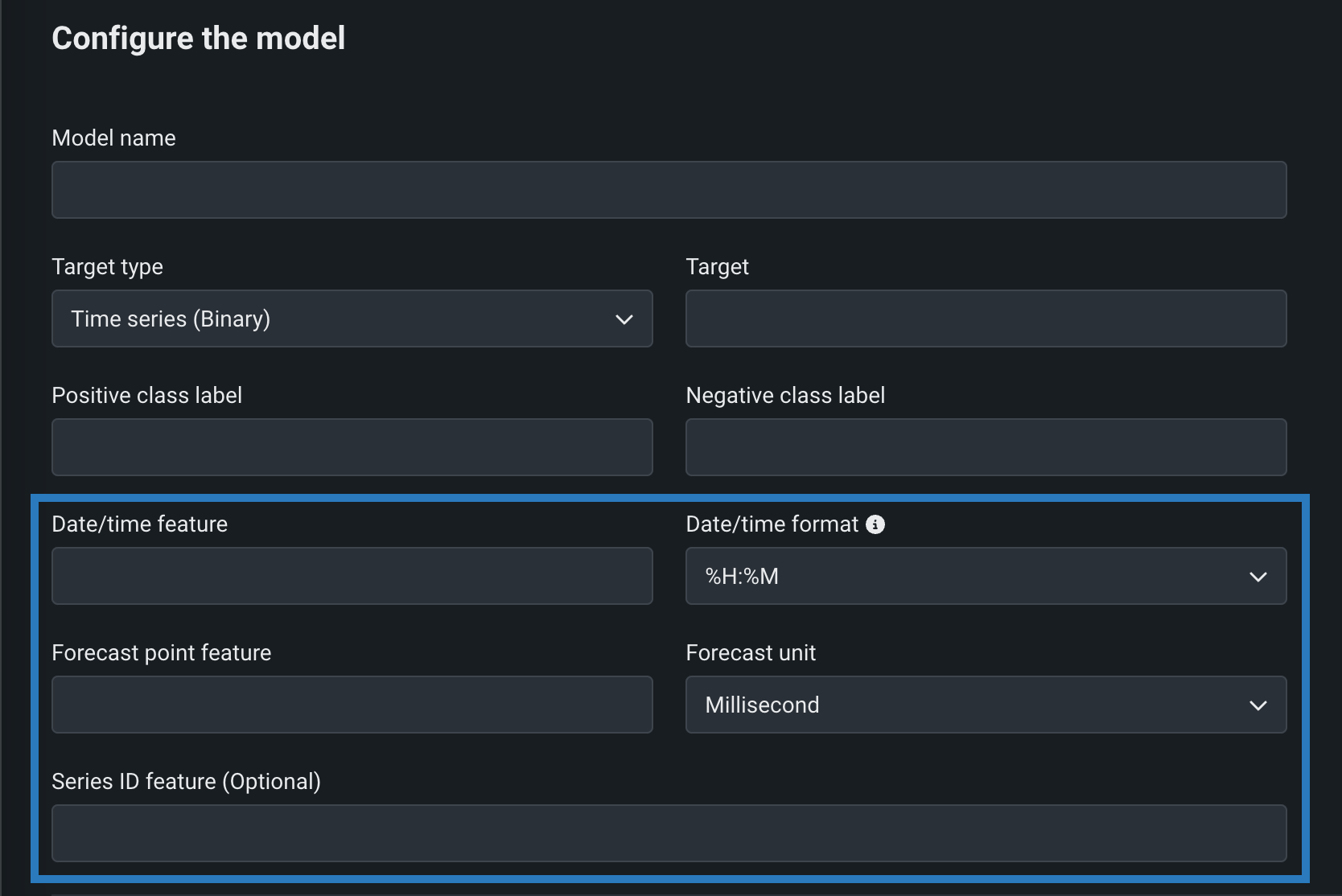
デフォルトではオフの機能フラグ: 時系列のカスタムモデルを有効にする、カスタムモデルの予測で特徴量のフィルターを有効にする
プレビュー機能のドキュメントをご覧ください。
デプロイのデータ品質分析¶
生成AIデプロイのデータ探索タブで、データ品質をクリックすると、関連付けIDが一致するプロンプト、回答、ユーザー評価、カスタム指標を調べることができます。 このビューでは、生成AIモデルの回答の品質に関するインサイトが、ユーザーによる評価と、実装した生成AIのカスタム指標に基づいて提供されます。
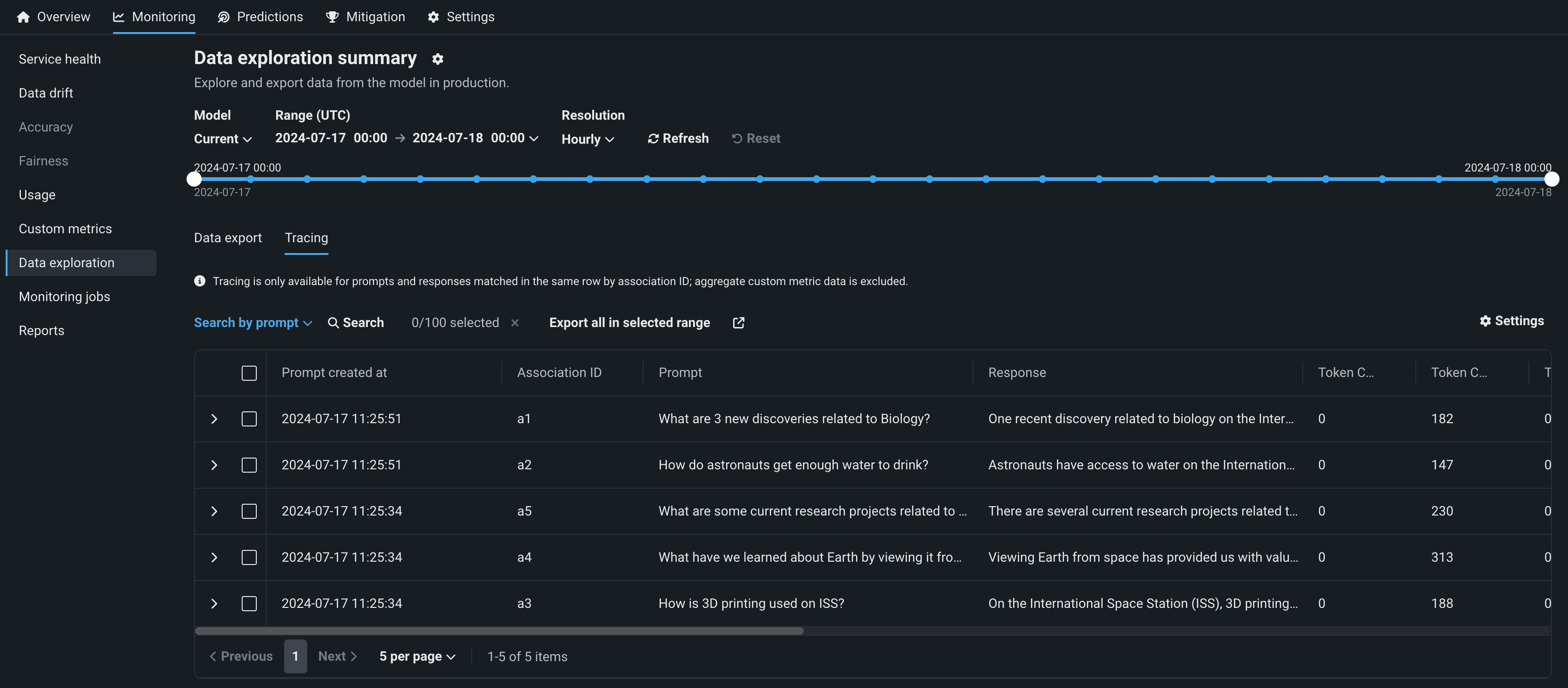

デフォルトではオフの機能フラグ:テキスト生成のターゲットタイプでデータ品質テーブルを有効にする(プレミアム機能)、生成モデルで実測値の保存を有効にする(プレミアム機能)
プレビュー機能のドキュメントをご覧ください。
カスタム指標および再トレーニングジョブ¶
NextGenのレジストリ > ジョブ ページでカスタムジョブを作成する場合、カスタム指標および再トレーニングジョブを作成できるようになりました。 + 新規追加(またはカスタムジョブパネルが開いている場合は ボタン)をクリックします。
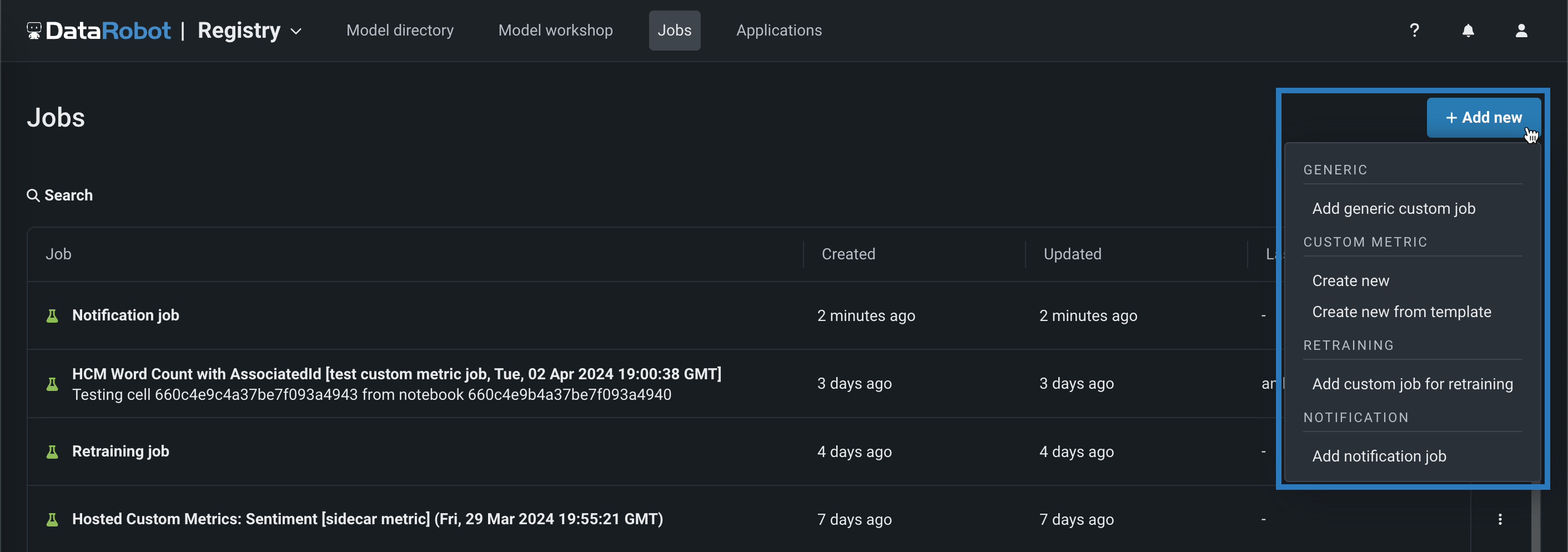
| カスタムジョブタイプ | 説明 |
|---|---|
| カスタム指標 | |
| 新しく作成 | 新しいホストされたカスタム指標のカスタムジョブを追加します。カスタム指標設定を定義し、指標をデプロイに関連付けます。 |
| テンプレートから新規作成 | DataRobotによって提供されるテンプレートからカスタム指標のカスタムジョブを追加して、指標をデプロイに関連付け、ベースラインを設定します。 |
| 再トレーニング | |
| 再トレーニングのためにカスタムジョブを追加 | コードベースの再トレーニングポリシーを実装するカスタムジョブを追加します。 再トレーニング用のカスタムジョブを作成したら、それを再トレーニングポリシーとしてデプロイに追加できます。 |
カスタム指標ジョブを作成する場合、アセンブルタブからジョブをデプロイに接続できます。 接続されたデプロイパネルで、+ デプロイに接続をクリックします。 次に、カスタム指標の名前を編集し、デプロイIDを選択して、ベースラインを設定し、接続をクリックします。
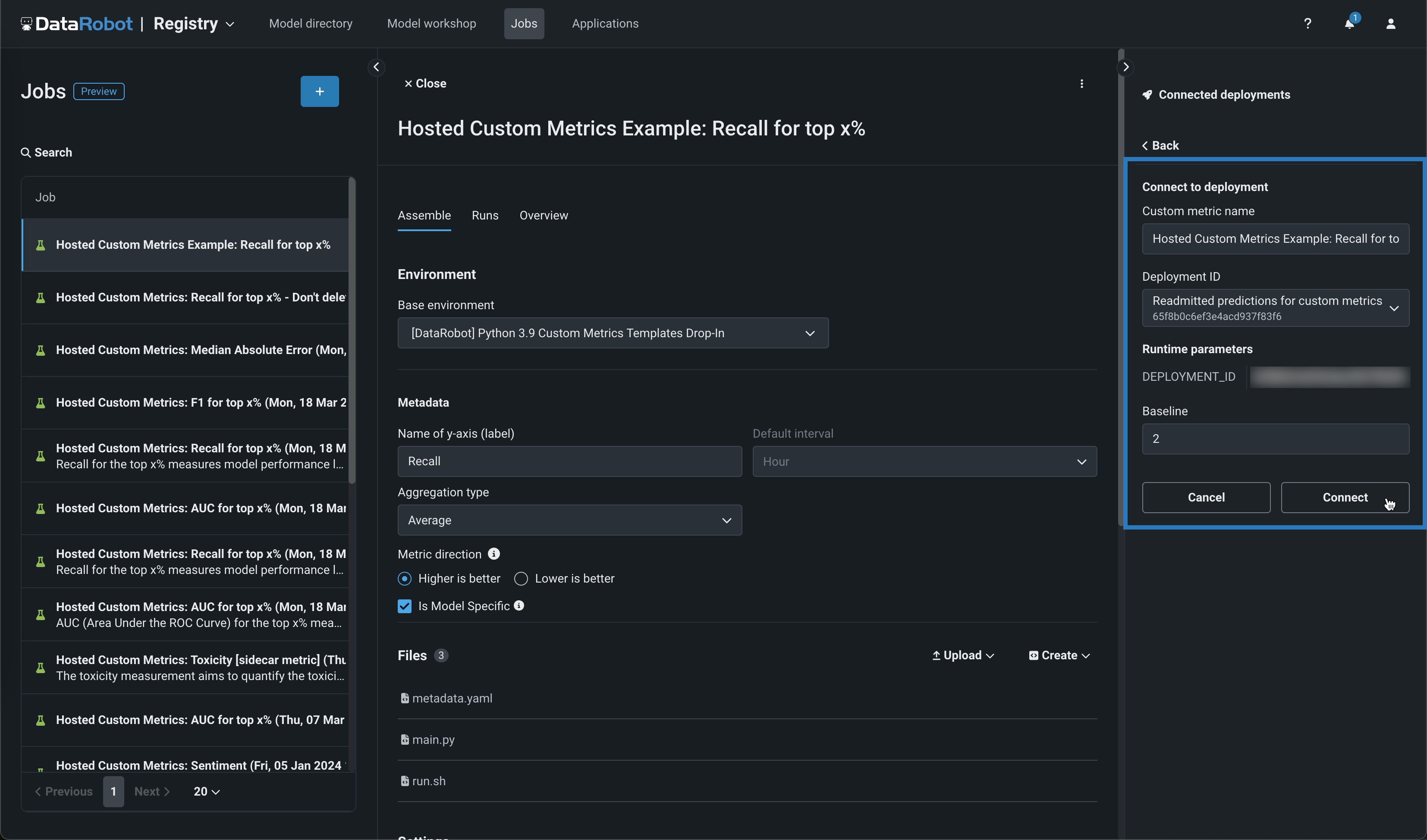
デフォルトではオフの機能フラグ: ホストされたカスタム指標を有効にする、カスタムジョブを有効にする、Notebooksでカスタム環境を有効にする
再トレーニングジョブを対象とした、デフォルトではオフの機能フラグ:カスタムジョブベースの再トレーニングポリシーを有効にする、カスタムジョブを有効にする、Notebooksでカスタム環境を有効にする
プレビュー機能のドキュメントをご覧ください。
バッチ予測のラングラーレシピ¶
デプロイの予測 > 予測を作成タブを使用して、バッチ予測を行うことで、デプロイされたモデルでラングラーデータセットを効率的にスコアリングできます。 バッチ予測とは、大規模なデータセットで予測を行う方法で、入力データを渡すと各行の予測結果が得られます。 予測データセットボックスで、ファイルを選択 > ラングラーをクリックし、ラングラーデータセットで予測を行います。
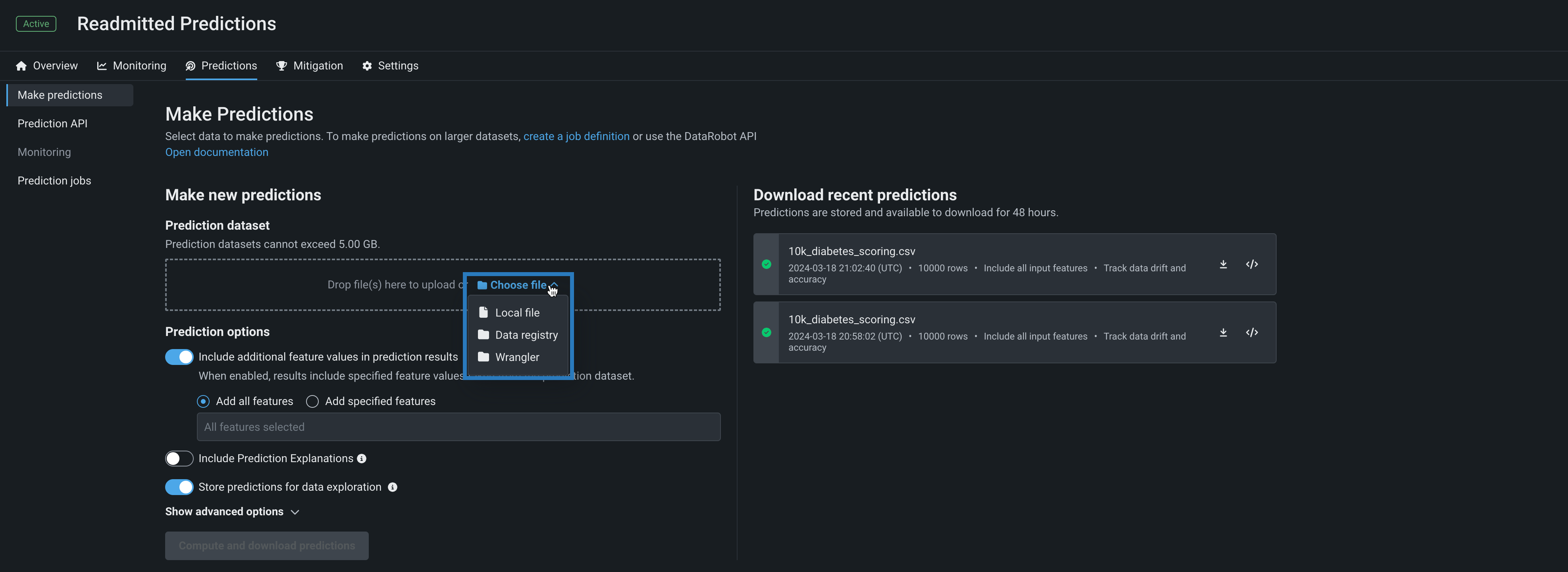
ワークベンチでの予測
ラングラーは、ワークベンチでは予測データセットソースとしても使用できます。 デプロイ前のモデルで予測を行うには、エクスペリメントのモデルリストからモデルを選択し、モデルのアクション > 予測を作成をクリックします。
予測データの送信元と送信先を指定し、予測が実行されるタイミングを決定することで、バッチ予測ジョブをスケジュールすることもできます。
デフォルトではオフの機能フラグ: バッチ予測ジョブでラングラーレシピを有効にする、ワークベンチでのレシピ管理を有効にする
プレビュー機能のドキュメントをご覧ください。
レジストリでのカスタムアプリケーションの管理¶
プレビュー機能です。NextGenレジストリの「アプリケーション」ページには、ユーザーが利用できる構築済みのカスタムアプリケーションとアプリケーションソースがすべて表示されます。 アプリケーションのソースを作成できるようになりました。これには、構築したいカスタムアプリケーションのファイル、環境、ランタイムパラメーターが含まれます。 これらのソースから直接カスタムアプリケーションを構築できます。 アプリケーションページを使って、共有や削除を行うことで、アプリケーションを管理することもできます。
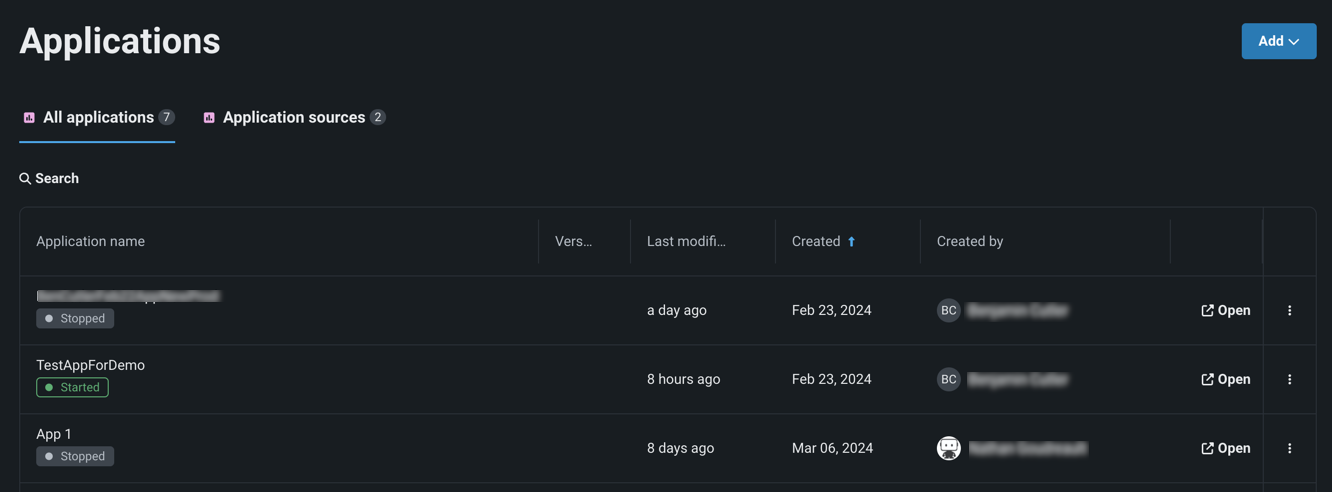
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:カスタムアプリケーションワークショップを有効にする
サポート終了/移行ガイド¶
カスタムモデルのトレーニングデータ割り当てを変更¶
DataRobotバージョン10.1では、カスタムモデルレベルでトレーニングデータを割り当てる使用非推奨の方法に代わって、(DataRobotバージョン9.1リリースで発表されたとおり)カスタムモデルのバージョンにトレーニングデータが割り当てられるようになりました。 つまり、「カスタムモデルバージョンごと」の方法がデフォルトになり、「カスタムモデルごと」の方法は削除されました。 準備として、カスタムモデルのトレーニングデータ割り当てを変更のドキュメントで、手動変換の手順を確認できます。
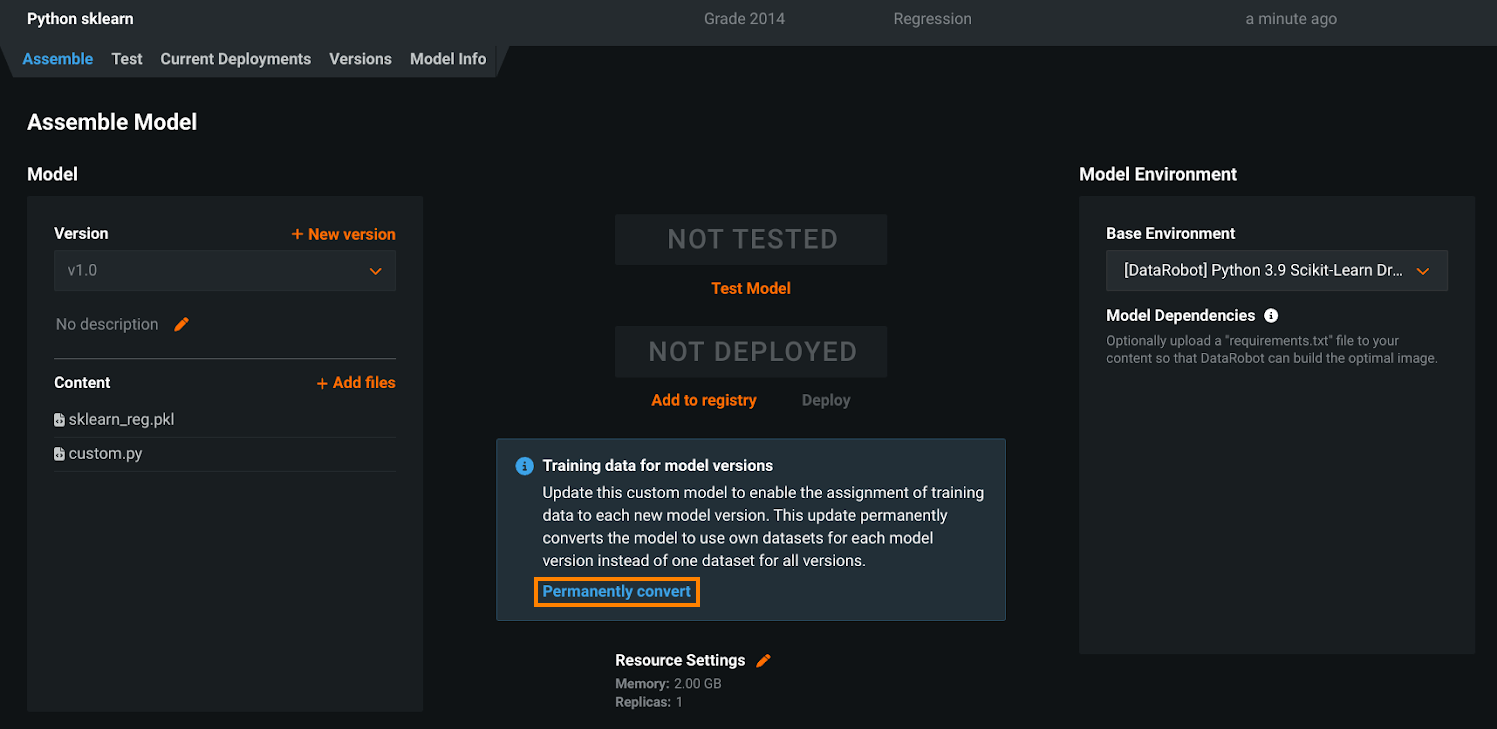
「カスタムモデルごと」の方法を使用した残りのカスタムモデルの自動変換は、使用非推奨期間が終了すると自動的に行われ、カスタムモデルのバージョンレベルでトレーニングデータが割り当てられます。 ほとんどの場合、何もする必要はありません。ただし、「カスタムモデルごと」の割り当て方法を使用していても変換されていないカスタムモデルに依存する自動化が残っている場合は、機能のギャップを避けるために、「カスタムモデルバージョンごと」の割り当て方法をサポートするように更新する必要があります。
割り当て方法の変更の概要については、カスタムモデルのトレーニングデータ割り当てを変更のドキュメントを参照してください。
Tableau拡張機能の削除¶
DataRobotは以前、2つのTableau拡張機能、InsightsとWhat-Ifを提供していましたが、現在は使用非推奨となり、アプリケーションから削除されました。 これらの拡張機能は、Tableauストアからも削除されました。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。