データ、モデリング、アプリ(V10.1)¶
2024年7月15日
DataRobot v10.1.0リリースには、以下で説明するように、データ、モデリング、アプリ、管理に関する多くの新機能と機能強化が含まれています。 リリース10.1のその他の詳細については、MLOpsおよびコードファーストのリリースノートをご覧ください。
リリース10.1¶
リリースv10.1では、以下の言語のUI文字列の翻訳が更新されています。
- 日本語
- フランス語
- スペイン語
- 韓国語
- ブラジルポルトガル語
目的別にグループ化された機能
| 名前 | 一般提供 | プレビュー |
|---|---|---|
| エクスペリエンス | ||
| ワークベンチでのユーザーエクスペリエンスの変更 | ✔ | |
| データ | ||
| データレジストリのデータセットに対してラングリングを実行する。 | ✔ | |
| モデリング | ||
| ワークベンチでのユーザーエクスペリエンスの変更 | ✔ | |
| ワードクラウドをワークベンチで一般提供 | ✔ | |
| ワークベンチでコンポーザブルブループリントのサポートを開始 | ✔ | |
| DataRobot ClassicのデータセットをNextGenに移行 | ||
| インクリメンタルモデリングで最大インクリメントサイズを引き上げ | ✔ | |
| 管理 | ||
| Kerberos認証によるHive JDBCのサポート | ✔ | |
| サポート終了/移行ガイド | ||
| ADLS Gen2およびS3コネクターのバージョン | ||
このドキュメントでは、DataRobotの修正された問題についても説明します。
エクスペリエンスの強化¶
ワークベンチでのユーザーエクスペリエンスの変更¶
リリースのたびに、DataRobot ClassicからNextGenへの新機能の移行が行われ、2つのエクスペリエンスが同等になりつつあります。 さらに、特にワークベンチでは、常に改善が行われています。
データ¶
今回のリリースでは、ワークベンチにさまざまな機能改善と新機能が導入されています。
- データ探索ページでは、データセットのバージョン管理、およびデータセットの名前変更とダウンロードができるようになりました。 さらに、特徴量セットのドロップダウンは、データ探索ページで独立したタブになりました。
- データを追加モーダルに検索機能が追加されました。
- 新しい特徴量の計算で、オートコンプリート機能が改善されました。
- 動的データセットを使ってエクスペリメントを設定できるようになりました。
モデリング¶
今回のリリースでは、モデリングに対して以下を含むさまざまな改善が加えられています。
-
リーダーボードでのソート動作が変更されました。 少なくとも1つのモデルですべてのバックテストまたは交差検定パーティションが計算されると、モデルはこのパーティションを使用して自動的に並べ替えられるようになりました。
-
右パネルのワーカーキューからモデリングに利用できるワーカー数をコントロールできるようになりました。
-
EDA2の計算時に、DataRobotがターゲットリーケージを持つ特徴量を特定すると、特徴量の有用性が表示されている各特徴量の横にバッジが追加されます。
-
時系列モデルの新しい特徴量セットを作成する際に、順序付け特徴量を含めることも除外することもできるようになりました。
データの強化¶
プレビュー¶
データレジストリのデータセットに対してラングリングを実行する。¶
データレジストリに保存されたデータセットに対して、ラングリングレシピを構築し、プッシュダウンを実行できるようになりました。 データレジストリのデータセットに対してラングリングを実行するには、まずユースケースにデータセットを追加する必要があります。 次に、データセットの横にあるアクションメニューからラングリングを開始します。
この機能は、マルチテナントSaaSをご利用の場合と、AWS VPCまたはGoogle VPC環境のプラットフォームでのみ利用可能です。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:データレジストリのデータセットでラングリングのプッシュダウンを有効にする
モデリングの機能強化¶
一般提供¶
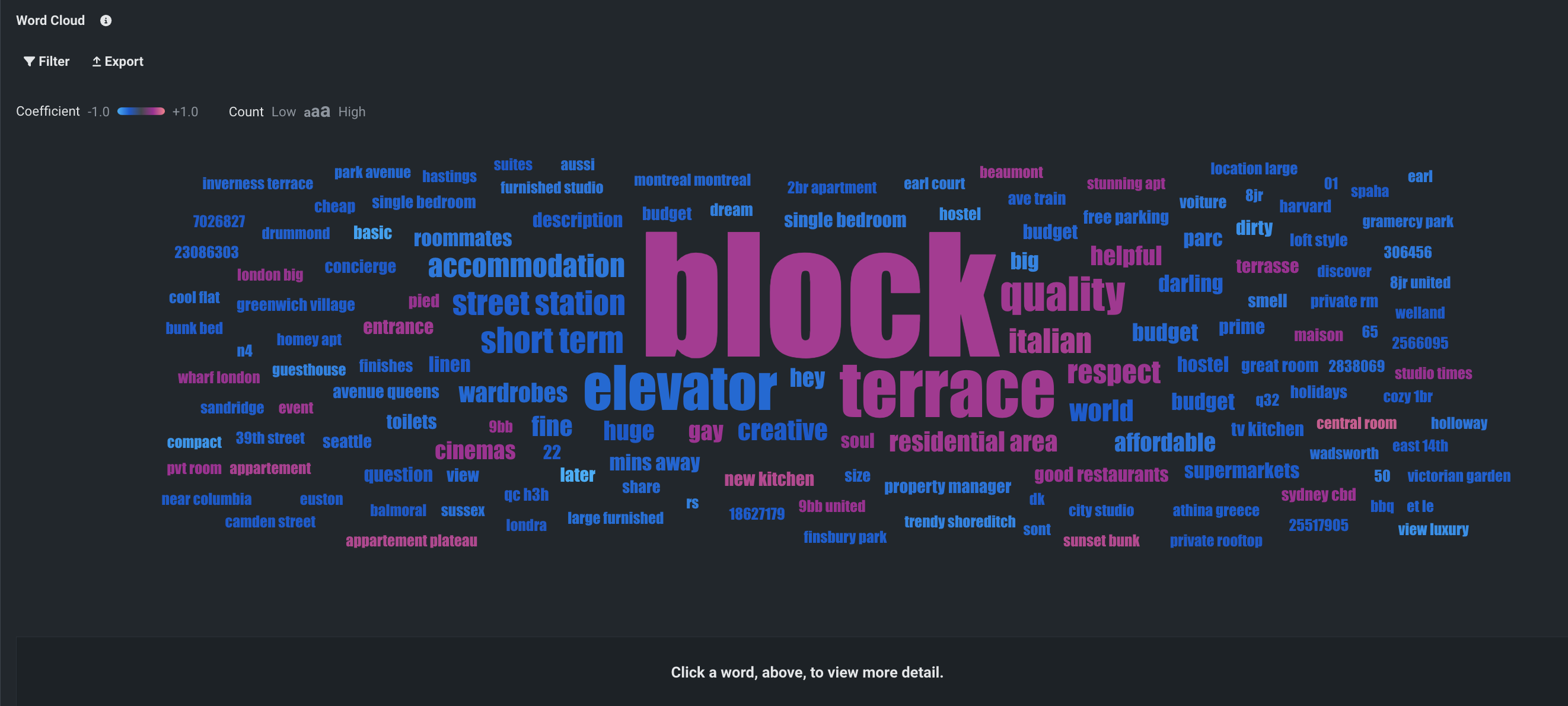
ワードクラウドをワークベンチで一般提供¶
分類と連続値のプロジェクトのためのテキストベースのインサイトであるワードクラウドが、ワークベンチで一般提供されました。 最も影響力のある単語や短いフレーズが最大200個表示され、ターゲットと単語の相関関係を理解するのに役立ちます。 ワードクラウドでは、個々の単語の詳細を表示したり、表示をフィルター処理したり、インサイトをエクスポートしたりできます。
プレビュー¶
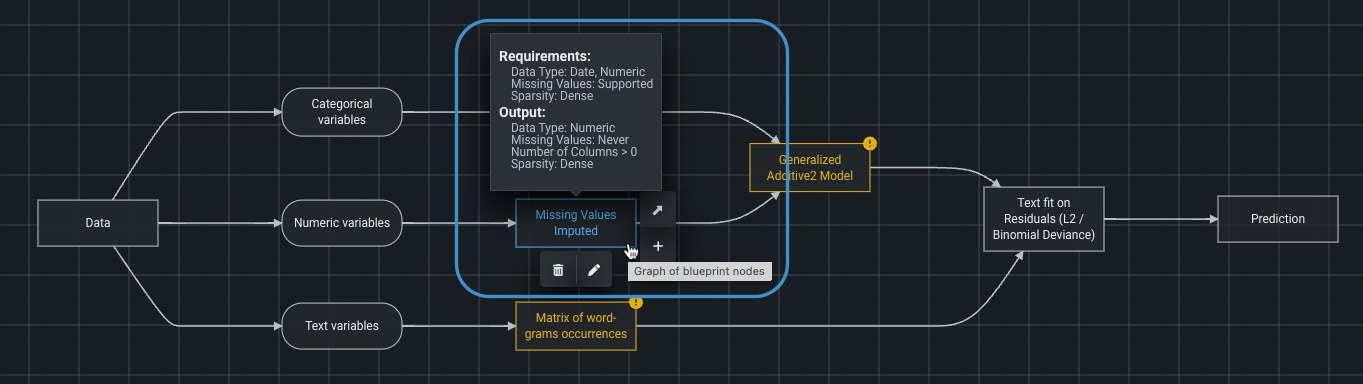
ワークベンチでコンポーザブルブループリントのサポートを開始¶
リーダーボードから、モデルのブループリントにアクセスして、前処理ステップ、モデリング、後処理ステップを含めた、モデルフィッティングのためのエンドツーエンドの手順の概要を確認できます。 組み込みタスクとカスタムPython/Rコードを使ってブループリントを編集できるようになりました。 新しいブループリントをDataRobotの他の機能(MLOpsなど)と一緒に使って、生産性を向上させることができます。 ブループリントの編集では、ブループリントのノードとコネクターを変更、追加、または削除します。 検証メッセージにより、新しいパイプラインに関する潜在的な問題が報告されます。 構築した新しいブループリントは、編集ウィンドウからトレーニングできます。 または、後でトレーニングするためにリポジトリに保存することもできます。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ::ワークベンチのブループリントでComposable MLを有効にする
DataRobot ClassicのデータセットをNextGenに移行¶
以前追加されたアセット移行機能を拡張しました。(AIカタログ内でオーナーアクセス権を持ち、)DataRobot Classicプロジェクトに関連付けられたデータセットもすべてNextGenに移行されるようになったため、ユースケースの機能をフル活用できます。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ:アセットの移行を有効にする
インクリメンタルモデリングで最大インクリメントサイズを引き上げ¶
インクリメンタルモデリングの_デフォルト_のインクリメントサイズは4GBですが、インクリメント(「チャンク」)を10GBまで増やすことができるようになりました。 組織の管理者は、機能フラグ「20GBのスケールアップモデリングの最適化を有効にする」を有効にすると、ユーザーの最大インクリメントサイズを20GBに増やすことができます。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ:増分学習を有効にする、データのチャンキングサービスを有効にする(10GB) デフォルトではオフの機能フラグ:20GBのスケールアップモデリングの最適化を有効にする
管理機能の強化¶
プレビュー¶
Kerberos認証によるHive JDBCのサポート¶
Kerberos認証によるHive JDBCのサポートが、DataRobotのバージョン9.2、10.0、10.1に追加されました。
サポート終了/移行ガイド¶
ADLS Gen2およびS3コネクターのバージョン¶
今後リリースされるDataRobot 10.2では、ADLS Gen 2(バージョン2021.2.1634676262008と2020.3.1605726437949)とAmazon S3(バージョン2020.3.1603724051432)は使用非推奨となります。 新しいバージョンのコネクターを使用して既存のデータ接続を再作成し、追加の認証メカニズム、バグ修正、およびNextGenでこれらの接続を使用する機能を活用できるようにすることをお勧めします。
10.2の時点で、以下のプレビュー機能フラグも無効になります。
- DataRobotコネクターを有効化する
- ADLS Gen2のOAuth 2.0を有効化
古いバージョンを使用して作成された既存の接続は、引き続き動作します。 ただし、DataRobotでは、これらの古いバージョンに対する機能強化やバグ修正は今後行いません。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。