2022年5月¶
2022年5月24日
今回のデプロイにより、DataRobotのマネージドAIプラットフォームには、以下の一般提供およびプレビューの新機能が提供されました。 過去の新機能のお知らせについては、デプロイ履歴をご覧ください。
目的別にグループ化された機能
一般提供¶
これらの機能は、前回のリリースから一般提供されています。
AIカタログに一括操作機能を追加¶
このリリースから、複数のAIカタログアセットを一度に共有、タグ付け、ダウンロード、削除できるようになったため、より効率的に操作できます。 AIカタログで、管理したいアセットの左側にあるボックスを選択し、上部で適切なアクションを選択します。
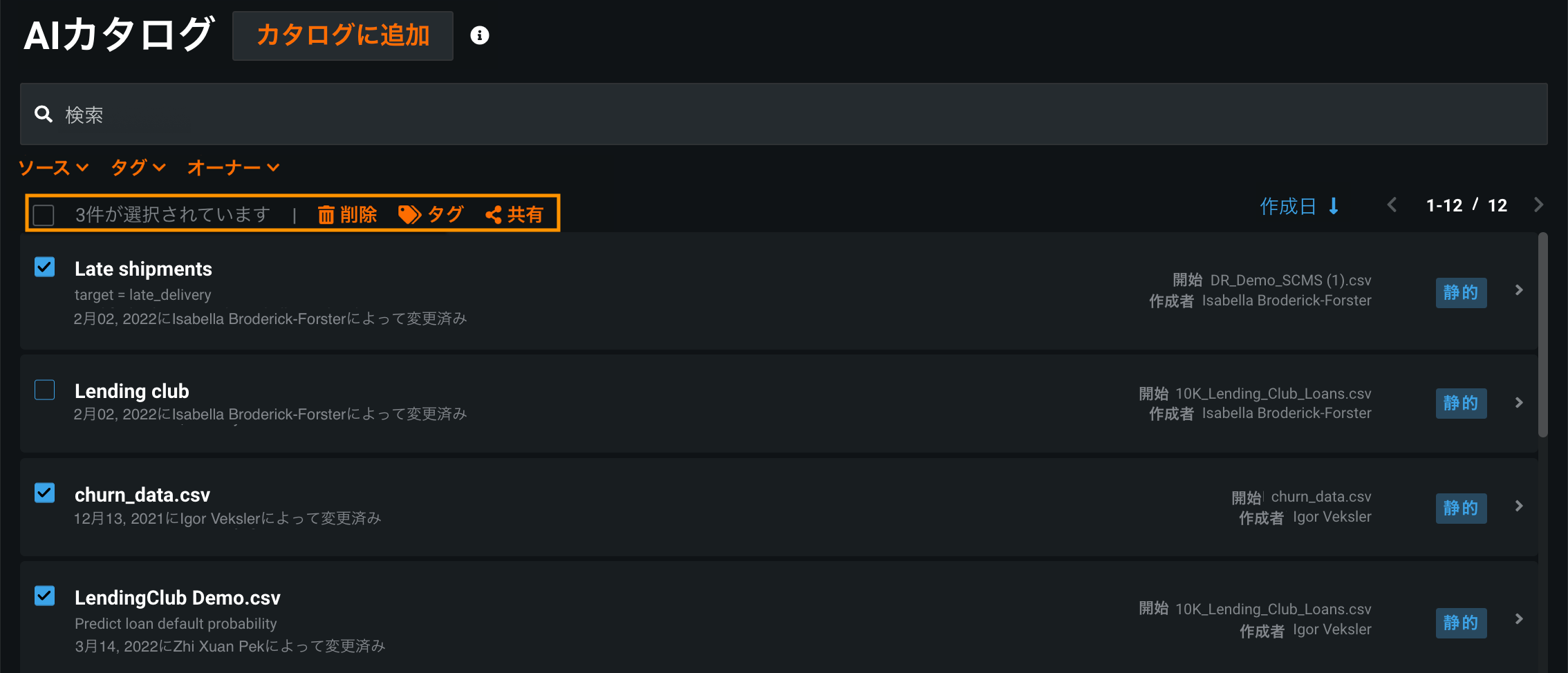
詳しくは、カタログアセットの管理に関するドキュメントをご覧ください。
Azure Event Hubsのスプーラー用のApache Kafka環境変数¶
MLOPS_KAFKA_CONFIG_LOCATION環境変数が削除され、Apache Kafkaスプーラー設定用の新しい環境変数に置き換えられました。 これらの新しい環境変数により、個別の設定ファイルが不要になり、スプーラータイプとしてのAzure Event Hubsのサポートが簡素化されます。
Apache Kafkaスプーラーの設定の詳細については、Apache Kafka環境変数のリファレンスを参照してください。
Apache Kafkaスプーラータイプを活用してMicrosoft Azure Event Hubsスプーラーを使用する方法については、Azure Event Hubsスプーラー設定リファレンスを参照してください。
バイアス軽減機能¶
バイアス軽減が、二値分類プロジェクトで一般提供機能として利用できるようになりました。 このリリースでは、親モデルとバイアス軽減策が適用された子モデルの関係性を明確にするため、リーダーボード上の親モデルからアクセスできる軽減策を適用したモデルテーブルが追加されました。
バイアス軽減は、ブループリントに対して前処理または後処理タスクでオーグメンテーションを行うことによって機能し、その後、ブループリントは保護された特徴量でクラス間のバイアスを減らすことを試みます。 バイアス軽減策は、自動(オートパイロットの一部として)または手動(オートパイロットの完了後)で適用できます。 自動的に実行する場合、高度なオプションでのバイアスと公平性の設定の一部として、バイアス軽減基準を設定します。 その後、オートパイロットはリーダーボードの上位3モデルにバイアス軽減策を適用します。 また、オートパイロットが完了したら、リーダーボードから入手できる、アンサンブル以外でバイアス未軽減のモデルに軽減策を適用できます。 最後に、バイアスと精度のインサイトから、バイアスを軽減したモデルと軽減していないモデルを比較します。
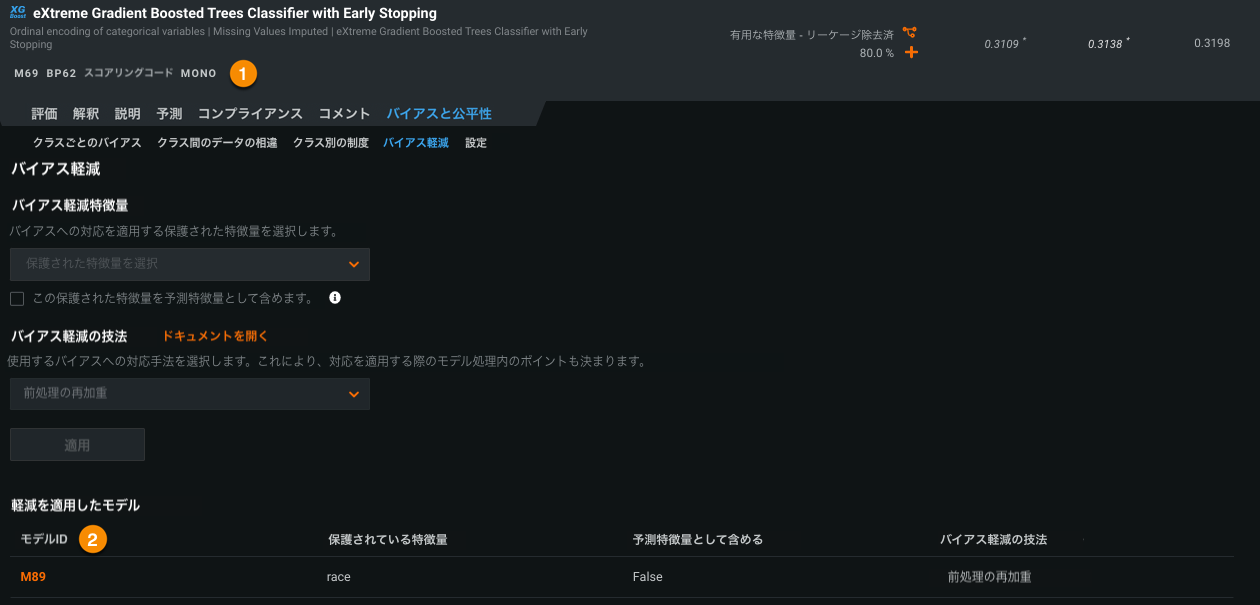
詳しくはバイアス軽減策をご覧ください。
Visual Artificial Intelligence (AI)での画像埋め込みによる視覚化で新しいフィルター機能を追加¶
解釈 > 画像埋め込みタブは、AIプロジェクトの予測結果を視覚化するのに役立ちます。 DataRobotは画像の予測値を計算し、その予測値でフィルターできるようになりました。 さらに、一部のプロジェクトタイプでは、予測しきい値を変更し(予測ラベルが変更される場合があります)、新しい結果に基づいてフィルターすることができます。 以下の図は、サポートされているすべてのプロジェクトタイプについて、新規と既存のすべてのフィルターオプションを示しています。
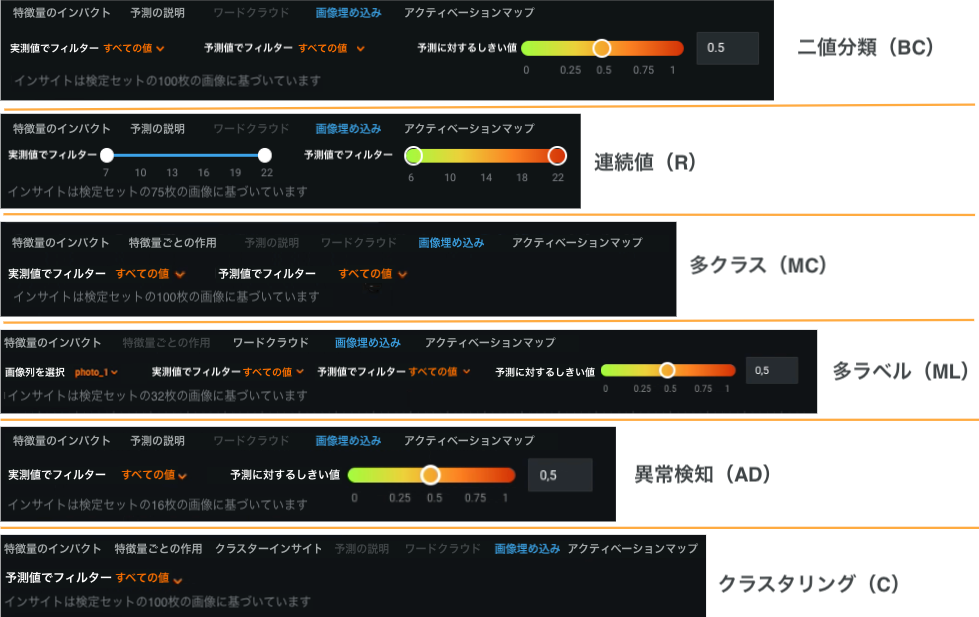
また、クラスターの操作性が向上し、Visual Artificial Intelligence (AI)の結果をより簡単に探索できるようになりました。 クラスタリングを使用すると、予測されるクラスターを示す色付きの境界線が画像に表示されます。
スケジュールされたモデリングジョブの並べ替え¶
プロジェクトのワーカーキューでスケジュールされたモデリングジョブと予測ジョブの順番を変更できるようになり、より重要なジョブをより早く実行できるようになりました。
詳しくはワーカーキューのドキュメントをご覧ください。
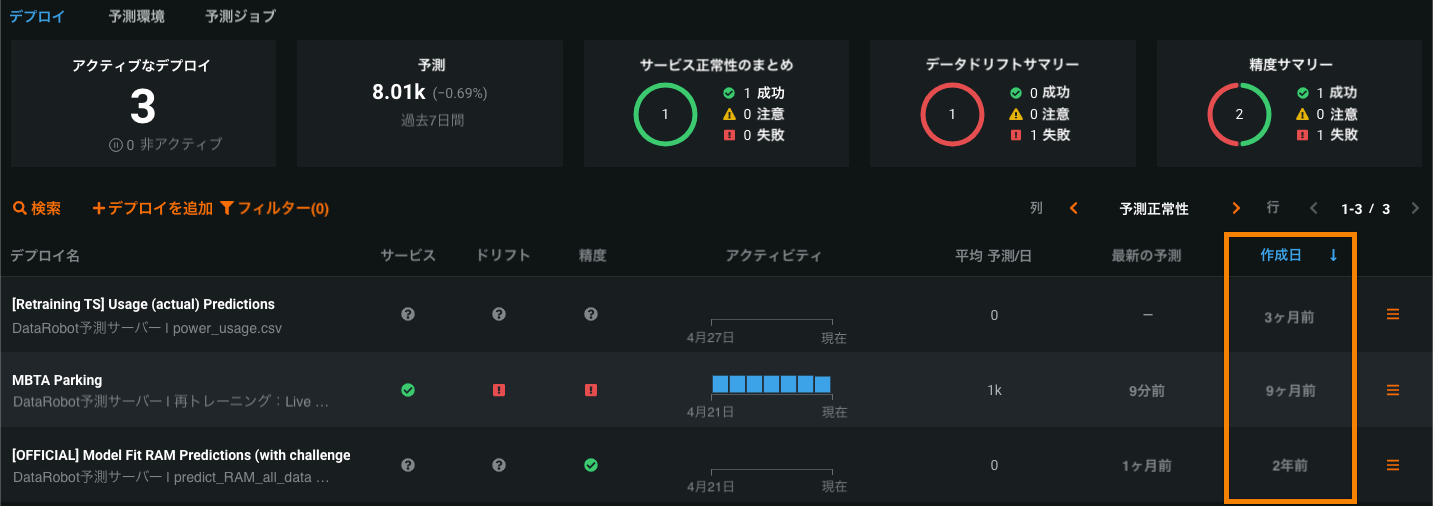
デプロイインベントリでの作成日による並べ替え¶
デプロイページのデプロイインベントリは、作成日順(新しい作成日列に従って、日付が新しい順)に並べ替えられるようになりました。 別の列のタイトルをクリックすると、代わりにその指標で並べ替えることができます。 ソート列のヘッダーの横に青い矢印が表示され、昇順か降順かが示されます。
備考
デプロイインベントリを並べ替えると、ブラウザーのローカルストレージデータをクリアするまで、最後に選択した並べ替えがローカル設定に保持されます。 そのため、通常、デプロイインベントリは最後に選択した列で並べ替えられます。
詳しくはデプロイインベントリのドキュメントをご覧ください。
「概要」タブにモデルIDとデプロイIDを追加¶
概要タブのコンテンツセクションには、デプロイのモデルおよび環境固有の情報が一覧表示され、次のIDが含まれるようになりました。
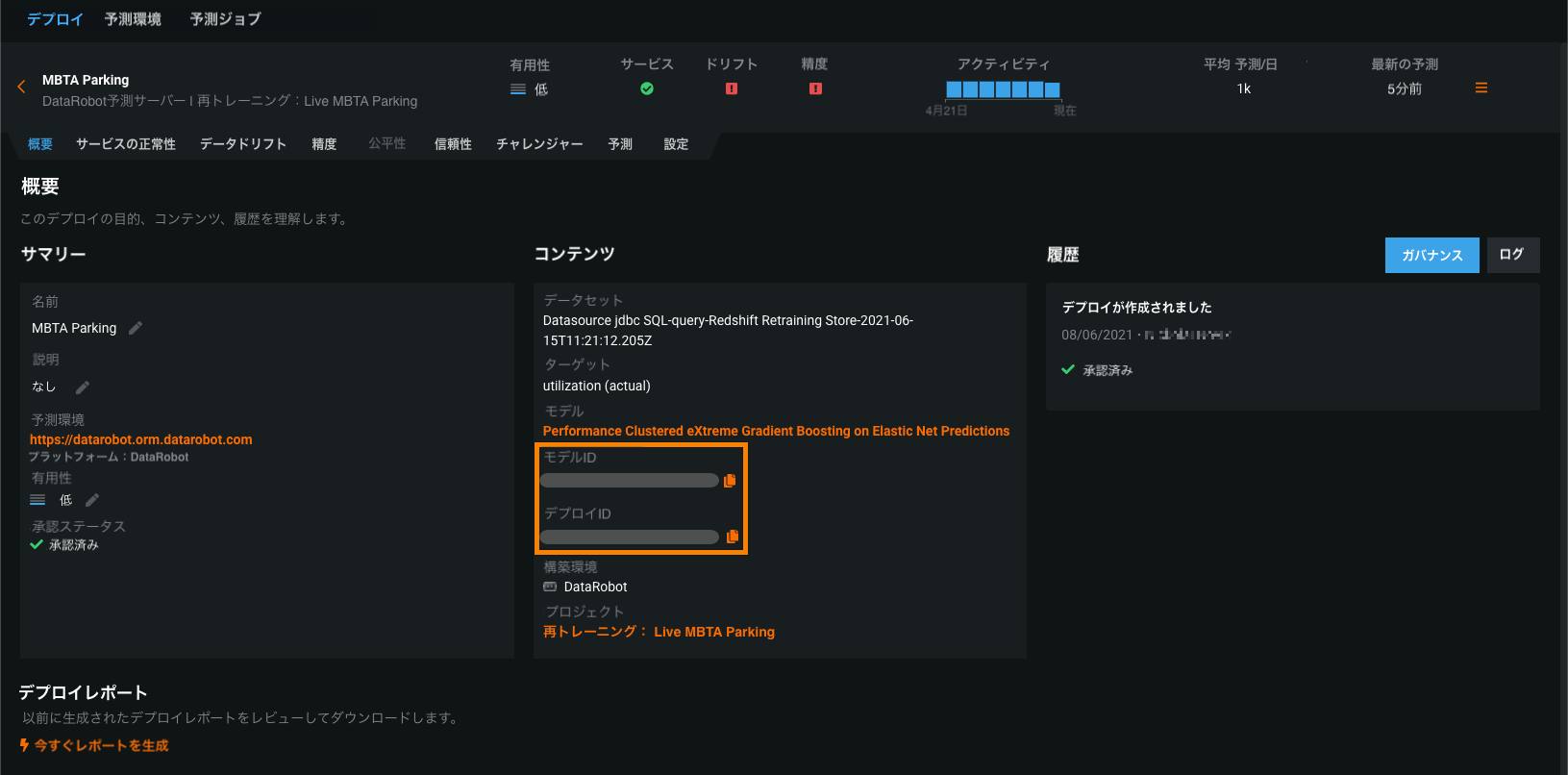
- モデルID:デプロイの現行モデルのID番号をコピーします。
- デプロイID:現在のデプロイのID番号をコピーします。
さらに、作成日とデプロイ日、モデル置換イベントなど、デプロイのモデル関連イベントを履歴 > ログで確認できます。 このログから、以前にデプロイされたモデルのモデルIDをコピーすることができます。
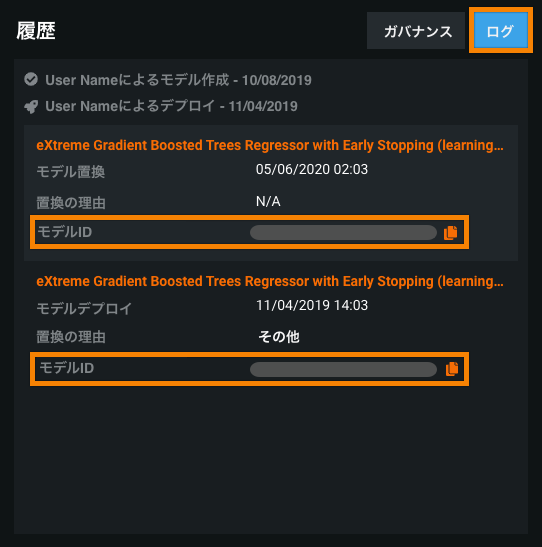
詳しくは「概要」タブのドキュメントをご覧ください。
プレビュー¶
これらの機能は、前回のリリースからプレビュープログラムに追加されています。 有効にするには、DataRobotの担当者または管理者にお問い合わせください。
AIカタログに大規模データセットをインポートする際のパフォーマンスを改善¶
REST API経由でAIカタログに大規模なデータセットをアップロードする場合、データステージ(大規模なデータセットのマルチパートアップロードをサポートする中間ストレージ)を使用して失敗の可能性を減らすことができます。 データステージでデータセット全体が確定されたら、AIカタログにプッシュすることができます。
Text AIのパラメーターをComposable MLで提供¶
特定のText AI前処理タスク(レンマ化、品詞タグ付け、ステミング)を変更する機能が、[高度なチューニング]タブからComposable MLでアクセス可能なブループリントタスクに移動しました。 Text AIの新しい前処理タスクは、独自のテキストブループリントを作成するための新たな経路を提供します。 たとえば、TF-IDFブループリントに限定されることなく、その前処理タスクをサポートするあらゆるテキストモデルで見出し語認定を使用できるようになりました。
必要な機能フラグ:Text AIで構成可能なステップを有効にする
多クラスプロジェクトでの予測の説明¶
DataRobotは、XEMPベースの多クラス分類プロジェクトにおいて、リーダーボードとデプロイの両方から各クラスの説明を計算するようになりました。 多クラスでは、計算するクラスの数を設定できます。また、予測結果や実際の結果からモードを選択したり(トレーニングデータを使用する場合)、特定のクラスのセットのみを表示するように指定したりすることもできます。
この機能は、複数の選択肢を検討する「ヒューマンインザループ」が必要なプロジェクトで特に役立ちます。 これまでの比較では、二値分類モデルを複数構築し、スクリプトで評価する必要がありました。 多クラスプロジェクトを構築する際、予測の説明は、モデルの精度が高すぎる場合(リーケージの可能性)、残差が大きすぎる場合(一部のデータが欠損している可能性)、モデルが2つのクラスを明確に区別できない場合(一部のデータが欠損している可能性)などを明らかにすることで、モデルの改善に役立てることができます。
言語サポートを強化してNLPオートパイロットをアップデート¶
このリリースでは、自然言語処理(NLP)が大幅に改善されましたが、その中で最も重要な改善点は、データ取込み時の言語検出にFastTextが適用されたことです。 そして、DataRobotは、その言語用に最適化されたパラメーターで、適切なブループリントを生成します。 検出された言語にトークン化を適応させることで、ワードクラウドと解釈性が向上します。 さらに、特定のブループリントトレーニングヒューリスティックがトリガーされるため、精度を最適化した高度なチューニング設定が適用されます。
この機能は、多言語のユースケースでも有効です。オートパイロットは複数の言語を検出し、ブループリントの各種設定を調整して、最高の精度を実現します。 さらに、このリリースでは、NLPの機能が次のように強化されています。
- 新しい事前学習済みBPEトークナイザー(任意の言語を処理できます)
- NLPのためのKerasブループリントを改良し、精度とトレーニング時間を改善しました。
- 他のNLPブループリントでもさまざまな改善を行いました。
- 新しいKerasブループリント(BPEトークナイザー付き)をリポジトリに追加しました。
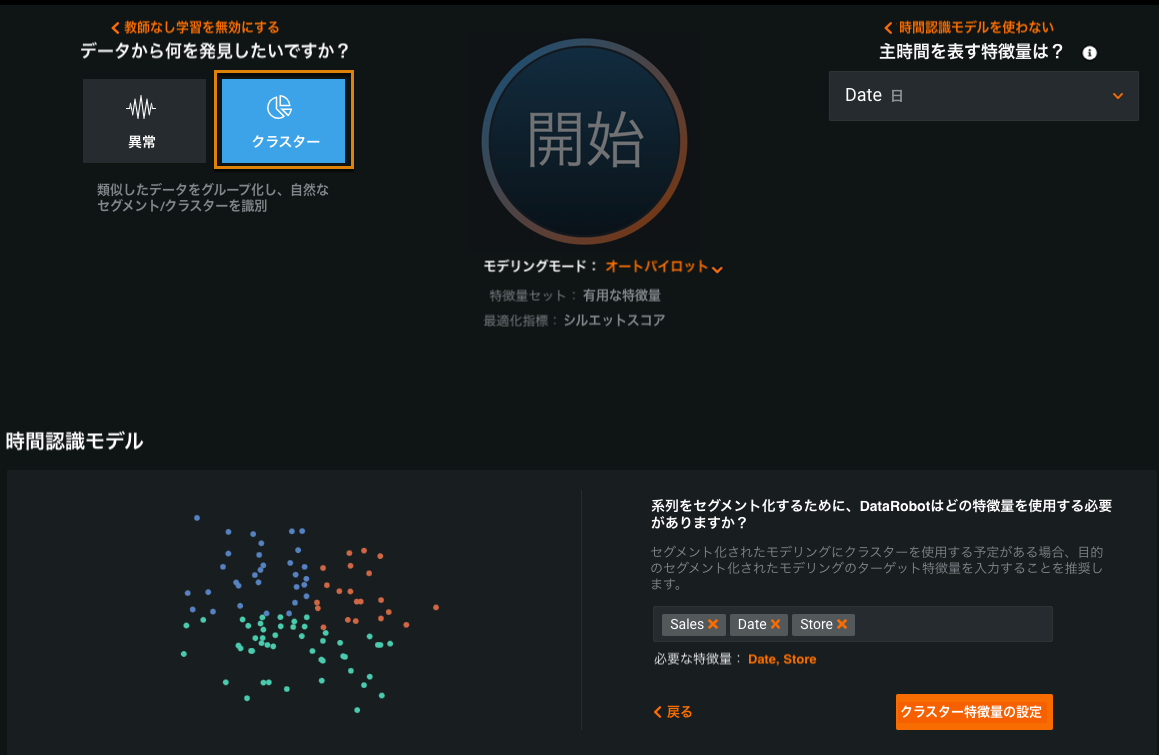
セグメントモデリングでのクラスタリング¶
クラスタリングは教師なし学習の手法の1つであり、データ内の自然なセグメントを識別するために使用できます。 DataRobotでは、クラスタリングによって、セグメントモデリングに使用するセグメントを検出できるようになりました。
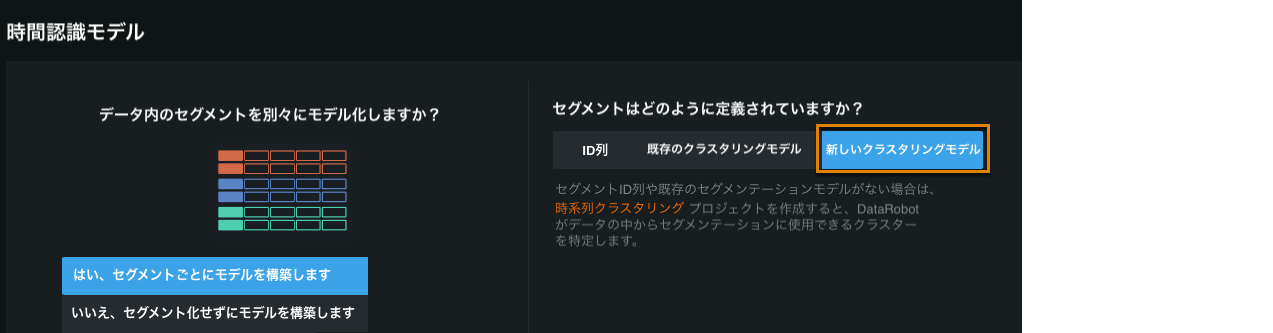
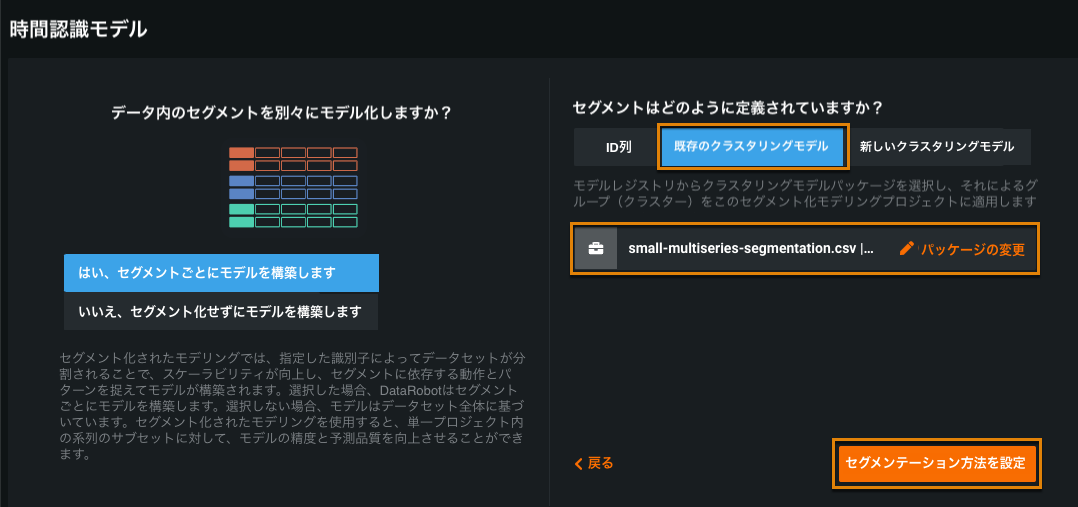
このワークフローは、クラスタリングモデルを構築し、そのモデルを使用して、セグメントモデリングプロジェクトのセグメントを定義します。
新しいセグメンテーションで使用タブでは、セグメントモデリングプロジェクトでクラスターを使用できるようにします。
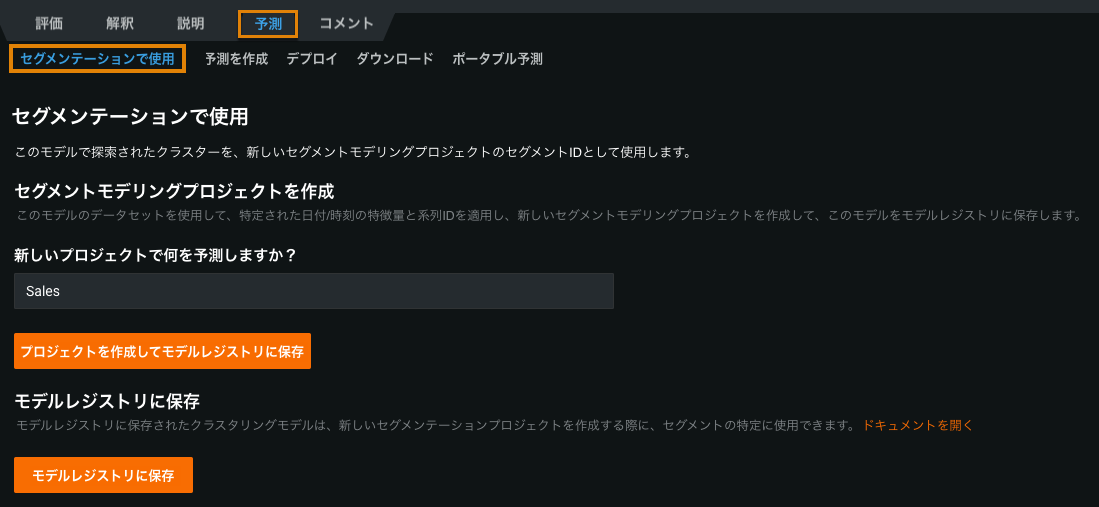
クラスタリングモデルはモデルレジストリにモデルパッケージとして保存されるので、以降のセグメントモデリングプロジェクトで使用することができます。
また、セグメントモデリングプロジェクトをすぐに作成せずに、明示的にクラスタリングモデルをモデルレジストリに保存することも可能です。 この場合、保存されたクラスタリングモデルパッケージを使用して、後でセグメントモデリングプロジェクトを作成できます。
必要な機能フラグ:時系列のクラスタリングからセグメンテーションのフローを有効にする
時系列プロジェクト向けに新しくブループリントを追加¶
DataRobotは、単一系列プロジェクトにおいて、ネイティブProphet、ETS、TBATSモデルをサポートするようになりました。 複数系列プロジェクトでは、これらのモデルを系列ごとに使用できます。 モデルの詳細な説明にアクセスするには、モデルブループリント(モデル > 説明 > ブループリント)にアクセスし、ブループリント内のモデルブロックをクリックして、[DataRobotモデルドキュメント]をクリックします。
必要な機能フラグ:
- 時系列プロジェクトでネイティブProphetブループリントを有効にする
- 時系列プロジェクトで系列パフォーマンスブループリントを有効にする
MLOpsエージェントイベントログのレート制限実施イベント¶
プレビュー版の機能です。デプロイのサービスの正常性タブのモニタリングイベントで、APIのレート制限が実施されたことを示すMLOpsエージェントイベントを表示できます。 MLOpsエージェントのインストールと設定がまだの場合は、インストールと設定のガイドを参照してください。
必要な機能フラグ:MLOpsの管理エージェントを有効化
ドキュメントを参照してください。
サポート終了のお知らせ¶
以下のサポート終了のお知らせは、DataRobotのマネージドAIプラットフォームで実施された変更の状況を把握するのに役立ちます。
[終了] H2OおよびSparkMLスケールアウトブループリント¶
2021年6月に、ブループリントの作成を不可とし、スケールアウト機能を非推奨としました。 現在、スケールアウトモデルは完全に無効になっています。 スケールアウトブループリントの実行やスケールアウトモデルからの予測値の取得など、すべてのアクションが製品から利用できなくなりました。
[終了] カスタムタスクでの未変更データの特徴量セット¶
この終了のお知らせは、現在カスタムタスクを用いる際に利用可能な、未変更データの特徴量セット(以前は"super raw"特徴量セットとも呼ばれていました)についてです。 これらの特徴量セットは、2022年10月25日以降使用できなくなります。
変更点
これまで、ブループリントにカスタムタスクのみが含まれている場合、DataRobotはプロジェクトに対して、変更前のデータの特徴量セット(つまり、データセットのすべての特徴量)を作成していました。 2022年10月25日以降、未変更データの特徴量セットは使用できなくなります。
影響
上記の日付以降、未変更データの特徴量セットは選択できなくなり、既存のものは削除されます。 既存のプロジェクトが影響を受ける可能性があるため、現在未変更データの特徴量セットを使用しているプロジェクトを慎重に調べ、必要に応じて移行してください。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。