2022年8月¶
2022年8月24日
今回のデプロイにより、DataRobotのマネージドAIプラットフォームには、以下の一般提供およびプレビューの新機能が提供されました。 過去の新機能のお知らせについては、デプロイ履歴をご覧ください。 こちらもご覧ください。
目的別にグループ化された機能
| 名前 | 一般提供 | プレビュー |
|---|---|---|
| データとインテグレーション | ||
| AIアプリケーションのUI/UXを改善 | ✔ | |
| 新しいデータ接続UI | ✔ | |
| 予測とMLOps | ||
| デプロイ統計のクリア | ✔ | |
| 多クラスモデルや外部モデルに対するチャレンジャーモデルのインサイト | ✔ | |
| カスタムモデルやタスクのためのリモートリポジトリファイルブラウザー | ✔ | |
| カスタム指標のためのデプロイ予測データとトレーニングデータのエクスポート | ✔ | |
一般提供¶
AIアプリケーションのUI/UXを改善¶
このリリースでは、AIアプリケーションに以下の改善を行いました。
-
最適化アプリケーションの設定に役立つアプリ内ツアーが追加されました。 右上の「?」をクリックし、最適化ガイドを表示を選択します。
-
アプリケーションを開く際、構築モードではなく、利用モードで開くようになりました。
-
利用 > 最適化の詳細において、「What-Ifと最適化」ウィジェットがページ上部に移動しました。
-
これまで、最適化アプリケーションで最適化の計算を行うには、予測行を選択する必要がありました。 [すべての行]ウィジェットの行の最適化ボタンをクリックすれば、ページを離れることなく、最適化された予測値を計算して表示できるようになりました。
-
構築モードでは、ウィジェットに例を表示しないようにしました。
デプロイ統計のクリア¶
一般提供機能になりました。モデルバージョンや日付範囲ごとに監視データをクリアすることができます。 組織内でデプロイ承認ワークフローを有効にしている場合、デプロイから監視データを消去するには、事前に承認が必要です。 この機能により、誤って送信された監視データや、モデルをデプロイする際の結合テストの段階で送信された監視データをデプロイから削除することができます。
インベントリから、統計情報をリセットするデプロイを選択します。 アクションメニューをクリックし、統計をクリアを選択します。
リセットの条件を設定して、デプロイ統計をクリアウィンドウでの設定を完了します。
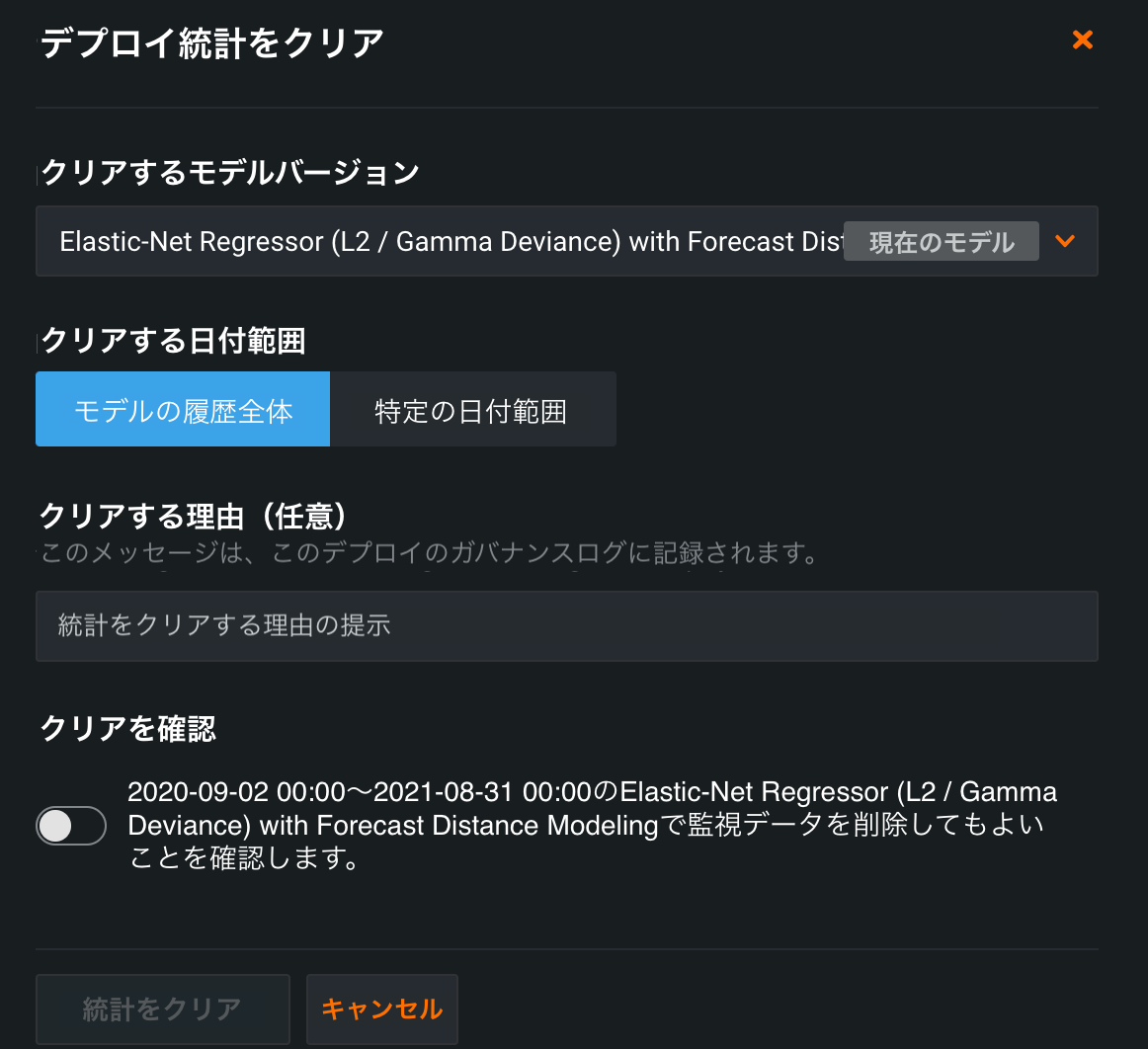
設定が完了したら、統計をクリアをクリックします。 DataRobotは、指定された日付範囲の監視データをデプロイからクリアします。
詳細については、デプロイ統計のクリアに関するドキュメントを参照してください。
多クラスモデルや外部モデルに対するチャレンジャーモデルのインサイト¶
一般提供機能になりました。多クラスモデルと外部モデルで、チャレンジャーモデルのインサイトを計算することができます。
-
多クラス分類プロジェクトは、精度比較のみをサポートします。
-
外部モデル(プロジェクトの種類を問わず)には、チャレンジャーモデルとの比較にデータセットが必要です。
外部モデルとチャレンジャーを比較するには、実測値と予測結果の両方を含むデータセットを提供する必要があります。 比較用のデータセットをアップロードする際に、予測結果を含む列を指定することができます。
外部モデルチャレンジャー用に比較データセットを追加するには、モデル比較の生成プロセスに従い、モデル比較タブで、予測列識別子を持つ比較データセットをアップロードします。 指定する予測データセットに、予測列で識別された場所にある外部モデルによって生成された予測結果が含まれていることを確認します。
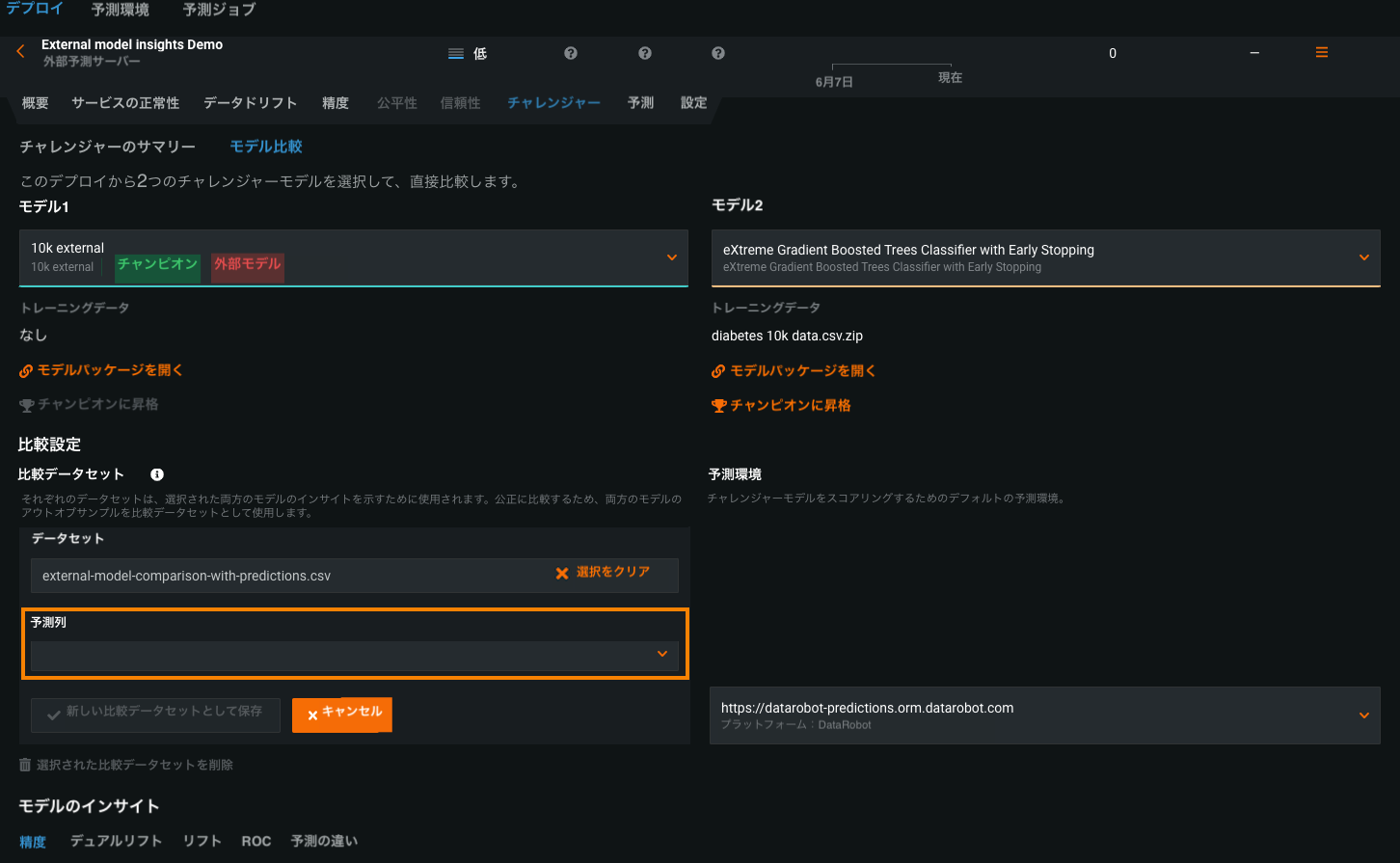
モデルのインサイトを計算すると、モデルのインサイトページには、プロジェクトタイプに応じた比較タブが表示されます。
| 精度 | デュアルリフト | リフト | ROC | 予測の違い | |
|---|---|---|---|---|---|
| 連続値 | ✔ | ✔ | ✔ | ✔ | |
| 二値 | ✔ | ✔ | ✔ | ✔ | ✔ |
| 多クラス | ✔ | ||||
| 時系列 | ✔ | ✔ | ✔ | ✔ |
詳細については、モデル比較の表示に関するドキュメントを参照してください。
プレビュー¶
新しいデータ接続UI¶
プレビュー版の機能です。DataRobotではデータ接続のユーザーインターフェイスが改善され、AIカタログ > データ接続ページからのデータ接続の追加と設定のプロセスが簡素化されました。 複数のウィンドウを開いてデータ接続を設定するのではなく、データストアを選択した後、同じウィンドウでパラメーターを設定し、資格情報を認証することができます。 各データ接続では、必須フィールドのみが表示されますが、ページ下部の高度なオプションで追加のパラメーターを定義できます。
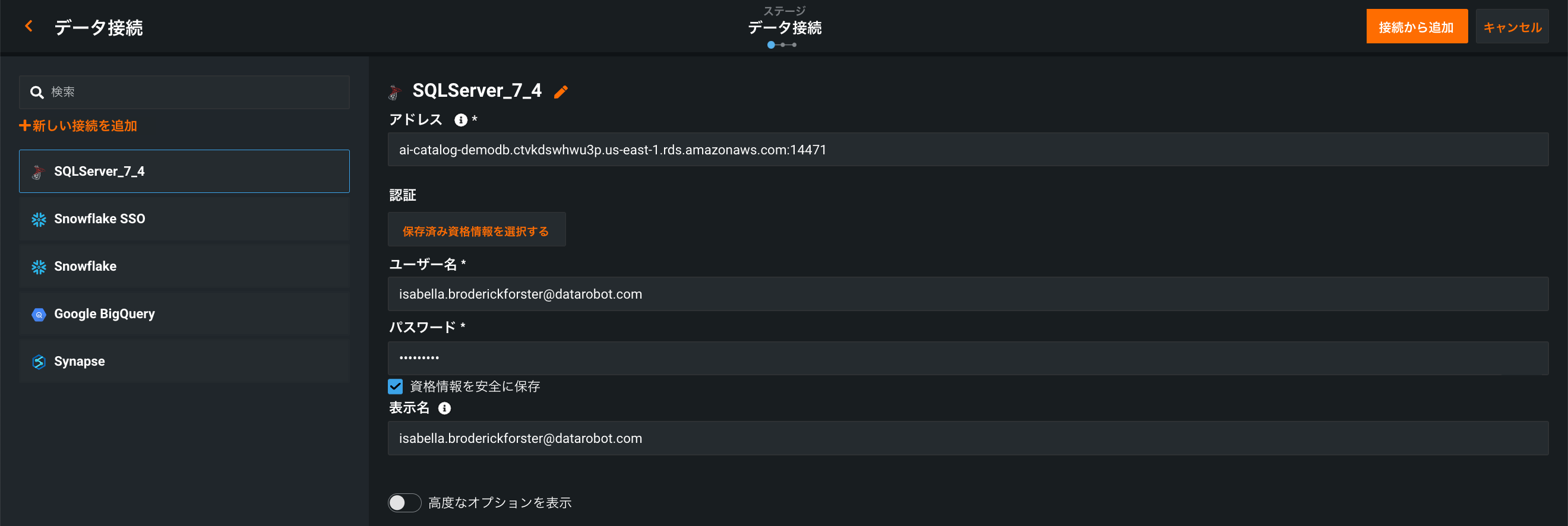
さらに、資格情報を使用したデータソースへの接続も簡素化されました。 データ接続の設定時に資格情報を入力すると、接続から新しいAIカタログデータセットを作成する際に、これらの資格情報が自動的に適用されます。
必要な機能フラグ:新しいデータ接続UIを有効にする
カスタムモデルやタスクのためのリモートリポジトリファイルブラウザー¶
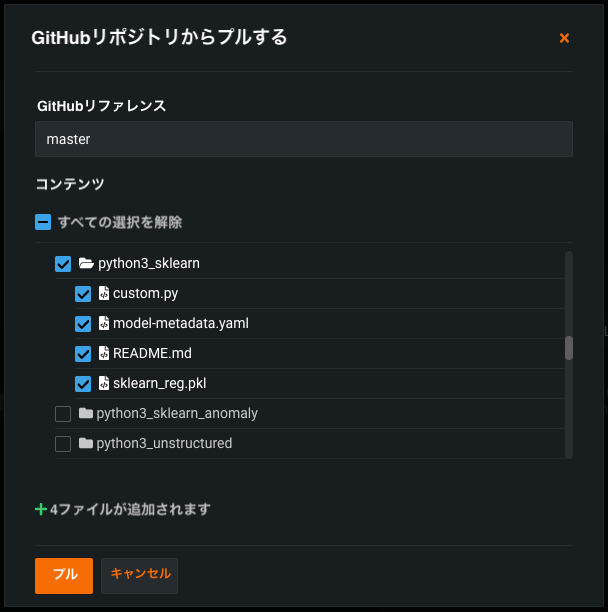
プレビュー版の機能です。リモートリポジトリ内のフォルダーやファイルを参照して、カスタムモデルまたはタスクに追加するファイルを選択できます。 カスタムモデルワークショップにモデルを追加したり、タスクを追加したりすると、Bitbucket、GitHub、GitHub Enterprise、S3、GitLab、GitLab Enterpriseなどのさまざまなリポジトリから、そのモデルやタスクにファイルを追加できます。 DataRobotにリポジトリを追加した後、リポジトリからファイルをプルして、カスタムモデルやモデルに含めることができます。
リモートリポジトリからプルする場合、GitHubリポジトリからプルするダイアログボックスで、カスタムモデルにプルしたいファイルやフォルダーのチェックボックスを選択することができます。
また、すべて選択をクリックすると、リポジトリ内のすべてのファイルを選択できます。1つまたは複数のファイルを選択した後、すべての選択を解除をクリックすると、選択したファイルがクリアされます。
備考
この例ではGitHubを使用していますが、各リポジトリタイプで手順は同じです。
詳しくはドキュメントをご覧ください。
カスタム指標のためのデプロイ予測データとトレーニングデータのエクスポート¶
プレビュー版の機能です。デプロイの保存済みトレーニングデータと予測データ(スコアリングデータと予測結果の両方)をエクスポートして、DataRobotの外でカスタムビジネスまたはパフォーマンス指標を計算および監視することができます。
デプロイに保存されている予測データとトレーニングデータをエクスポートするには、次の手順を実行します。
-
上部のナビゲーションバーで、デプロイをクリックします。
-
デプロイタブで、保存されている予測またはトレーニングデータを開いてエクスポートしたいデプロイをクリックします。
備考
[データのエクスポート]タブにアクセスするには、デプロイに予測データを保存する必要があります。 デプロイの設定で、チャレンジャーモデルの分析で予測行ごとの履歴保存を有効化していることを確認します。
-
デプロイで、データエクスポートタブをクリックします。
トレーニングデータを開く、またはダウンロードするには、次の操作を実行します。
-
トレーニングデータの下にあるオープンアイコン
 をクリックすると、AIカタログにトレーニングデータが開かれます。
をクリックすると、AIカタログにトレーニングデータが開かれます。 -
ダウンロードアイコン
 をクリックすると、トレーニングデータがダウンロードされます。
をクリックすると、トレーニングデータがダウンロードされます。
予測データを開く、またはダウンロードするには、次の手順を実行します。
-
以下の設定を行い、エクスポートする保存済み予測データを指定します。
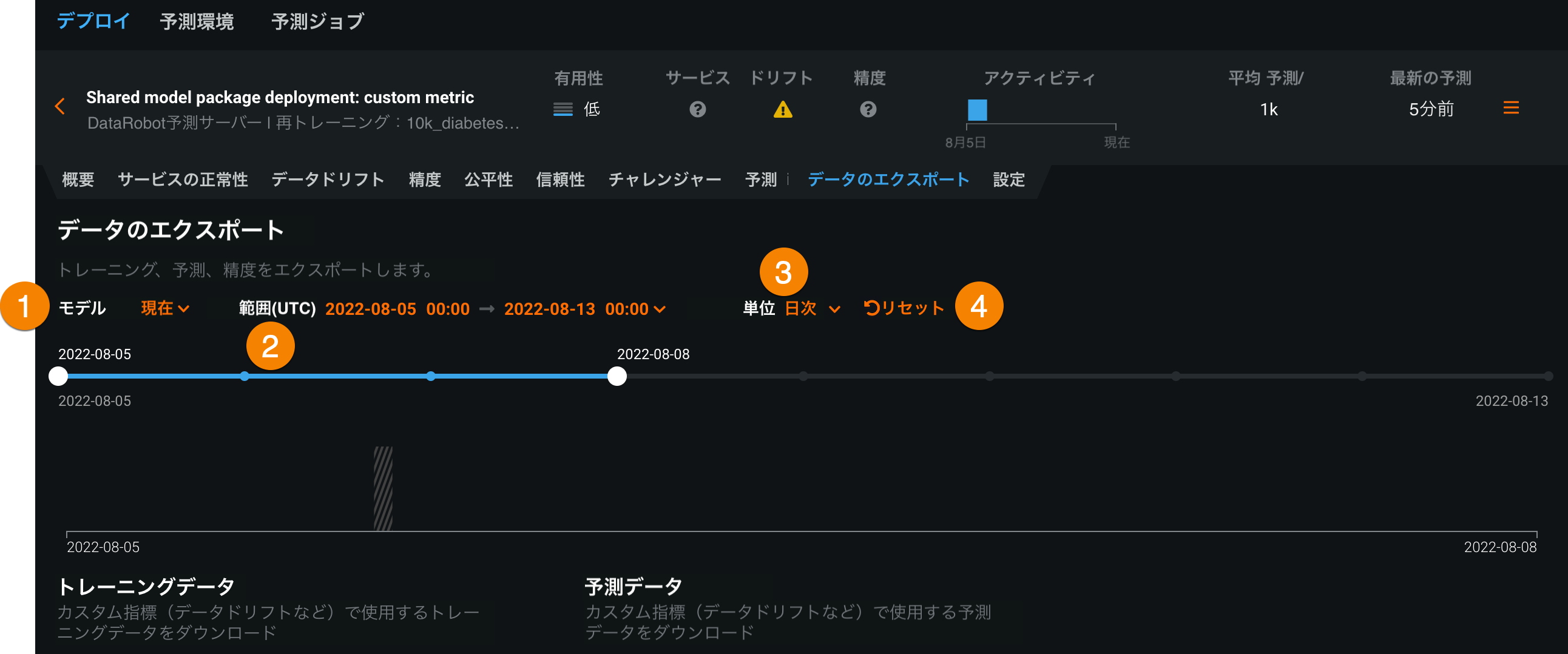
設定 説明 1 モデル 予測データをエクスポートするデプロイのモデル(現在または以前)を選択します。 2 範囲 (UTC) 予測データをエクスポートする期間の開始日と終了日を選択します。 3 単位 日付スライダーの時間単位を選択します。 選択した時間範囲に基づき、単位を毎時、毎日、毎週、毎月から選択します。 時間範囲が7日を超える場合、単位を毎時にすることはできません。 4 リセット データのエクスポート設定をデフォルトに戻します。 -
予測データの下にある予測データを生成をクリックします。
予測データ生成に関する注意事項
予測データを作成する際には、以下の点に注意してください。
-
予測データの生成時にエクスポート可能な行数は、最大で20万行までです。 設定した時間範囲で予測データが20万行を超える場合は、範囲を縮小してください。
-
AIカタログで持つことができる予測エクスポート項目は、最大で100個までです。 エクスポート用の予測データを生成すると、AIカタログの予測エクスポート項目の数がその制限を超える場合は、AIカタログで古い予測エクスポート項目を削除してください。
-
時系列デプロイで予測データを生成する場合、2つの予測エクスポート項目がAIカタログに追加されます。 1つは予測データ用、もう1つは予測結果用です。 [データのエクスポート]タブは予測結果にリンクしています。
予測データのエクスポートは、下図のように表示されます。
-
-
予測データの生成後:
-
オープンアイコン
をクリックすると、AIカタログに予測データが開かれます。 -
ダウンロードアイコン
をクリックすると、予測データがダウンロードされます。
-
エクスポートされたデプロイデータを使用して独自のカスタム指標を作成するには、エクスポートされたデータを含むCSVファイルから読み取り、エクスポートプロセスで自動的に生成された列を含む結果の値を使用して指標を計算するスクリプトを実行します。
この例では、エクスポートされた予測データを使い、DataRobotの予測タイムスタンプ(DR_RESERVED_PREDICTION_TIMESTAMP)をDateFrameインデックス(または行ラベル)として、30日間のtime_in_hospital特徴量の変化を計算およびプロットしています。 また、エクスポートされたトレーニングデータをプロットのベースラインとして使用します。
import pandas as pd
feature_name = "<numeric_feature_name>"
training_df = pd.read_csv("<path_to_training_data_csv>")
baseline = training_df[feature_name].mean()
prediction_df = pd.read_csv("<path_to_prediction_data_csv>")
prediction_df["DR_RESERVED_PREDICTION_TIMESTAMP"] = pd.to_datetime(
prediction_df["DR_RESERVED_PREDICTION_TIMESTAMP"]
)
predictions = prediction_df.set_index("DR_RESERVED_PREDICTION_TIMESTAMP")["time_in_hospital"]
ax = predictions.rolling('30D').mean().plot()
ax.axhline(y=baseline - 2, color="C1", label="training data baseline")
ax.legend()
ax.figure.savefig("feature_over_time.png")
DataRobot は、エクスポート用に生成された予測データに、以下の列を自動的に追加します。
| 列 | 説明 |
|---|---|
| DR_RESERVED_PREDICTION_TIMESTAMP | 予測のタイムスタンプが格納されます。 |
| DR_RESERVED_PREDICTION | 連続値の予測値を示します。 |
| DR_RESERVED_PREDICTION_{Label} | 分類の予測値を示します。 |
必要な機能フラグ:デプロイのトレーニングおよび予測データのエクスポートを有効にする
プレビュー機能のドキュメントをご覧ください。
サポート終了のお知らせ¶
USER/オープンソースモデルが使用非推奨になり、その後無効化¶
このリリースでは、USER/オープンソース(「ユーザー」)タスクを含むすべてのモデルが使用非推奨です。 既存モデルの非推奨の正確なプロセスは、今後数か月の間に展開され、その影響は後続のリリースでお知らせする予定です。 6月のクラウドリリースで詳細をご確認ください。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。