2023年7月¶
2023年7月26日
今回のデプロイにより、DataRobotのAIプラットフォームには、以下の一般提供およびプレビューの新機能が提供されました。 リリースセンターからは、次のものにもアクセスできます。
7月リリース¶
次の表は、新機能の一覧です。
目的別にグループ化された機能
| 名前 | 一般提供 | プレビュー |
|---|---|---|
| アプリケーション | ||
| ワークベンチでの新しいアプリエクスペリエンスを改善 | ✔ | |
| データ | ||
| ワークベンチにBigQueryのサポートを追加 | ✔ | |
| ラングリングされたデータセットをSnowflakeでマテリアライズ | ✔ | |
| ワークベンチでデータの結合と集計を実行 | ✔ | |
| スマートダウンサンプリングを使用したレシピのパブリッシュ | ✔ | |
| ワークベンチでのデータ準備の改善 | ✔ | |
| BigQueryとの接続の強化 | ✔ | |
| モデリング | ||
| カスタムタスクでのハイパーパラメーターのチューニング | ✔ | |
| Sklearnライブラリのアップグレード | ✔ | |
| 予測とMLOps | ||
| Apache Airflow用のDataRobotプロバイダー | ✔ | |
| モデルレジストリのMLflow連携 | ✔ | |
| カスタム指標の監視ジョブ | ✔ | |
| 予測値と実測値の適時性インジケーター | ✔ | |
| モデルレジストリでのバージョン管理のサポート | ✔ | |
| カスタムモデルのパブリックネットワークへのアクセス | ✔ | |
| 生成モデルの監視サポート | ✔ | |
| APIの機能強化 | ||
| DataRobot REST API v2.31 | ✔ | |
| Rクライアント v2.31 | ✔ | |
| Rクライアント v2.18.3 | ✔ | |
データの強化¶
プレビュー¶
ワークベンチにBigQueryのサポートを追加¶
Google BigQueryのサポートがワークベンチに追加され、以下のことが可能になります。
- データ接続を作成して設定する。
- BigQueryデータセットをユースケースに追加。
- BigQueryのデータセットをラングリングし、BigQueryにレシピをパブリッシュして、データレジストリで出力をマテリアライズ。
機能フラグ: ネイティブBigQueryドライバーを有効にする
ラングリングされたデータセットをSnowflakeでマテリアライズ¶
ラングリングレシピをパブリッシュして、DataRobotのデータレジストリまたはSnowflakeでデータをマテリアライズできるようになりました。 ラングリングレシピをパブリッシュすると、操作がSnowflakeの仮想ウェアハウスにプッシュダウンされ、Snowflakeのセキュリティ、コンプライアンス、財務管理を活用できるようになります。 デフォルトでは、出力データセットはDataRobotのデータレジストリでマテリアライズされます。 書き込みアクセス権があるSnowflakeデータベースとスキーマで、ラングリングされたデータセットをマテリアライズできるようになりました。
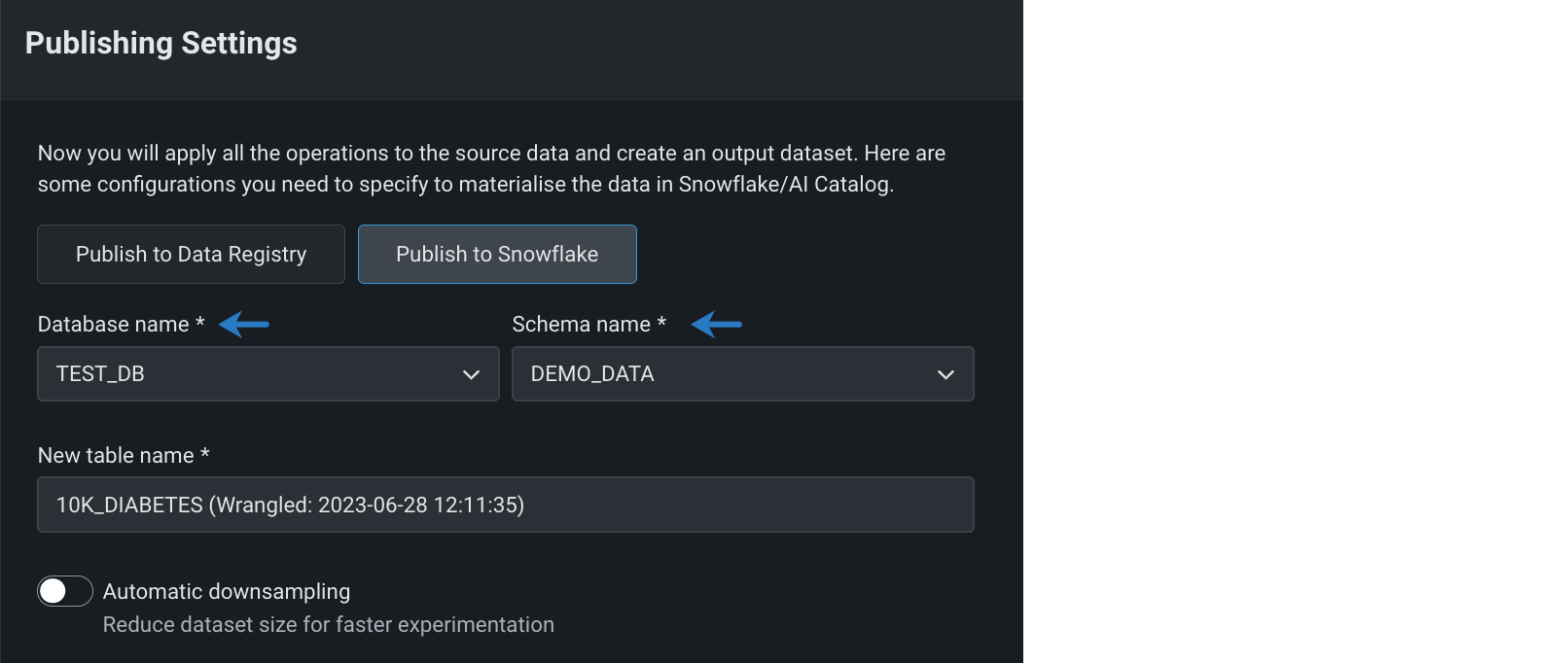
プレビュー機能のドキュメントをご覧ください。
機能フラグ: ワークベンチでSnowflakeのソース内マテリアライズを有効にする、ワークベンチで動的データセットを有効にする
ワークベンチでデータの結合と集計を実行¶
結合および集計操作をワークベンチのラングリングレシピに追加できるようになりました。 結合操作を使用すると、同じ接続インスタンスからアクセスできるデータセットを組み合わせることができます。集計操作を使用すると、合計、平均、カウント、最小値/最大値、標準偏差、推定などの集計関数に加えて、いくつかの非数学的操作をデータセット内の特徴量に適用できます。
プレビュー機能のドキュメントをご覧ください。
機能フラグ: 追加のラングラー操作を有効にする
スマートダウンサンプリングを使用したレシピのパブリッシュ¶
ワークベンチでラングリングレシピをパブリッシュする際には、スマートダウンサンプリングを使用して、出力データセットのサイズを縮小し、モデルのトレーニングを最適化します。 スマートダウンサンプリングは、精度を犠牲にすることなく、モデルの適合にかかる時間を短縮するデータサイエンス技術です。 このダウンサンプリング手法は、クラスごとにサンプルを階層化することにより、クラスの不均衡を考慮します。 たいていの場合、マイノリティークラス全体が保持され、サンプリングはマジョリティークラスにのみ適用されます。これは不均衡なデータに特に役立ちます。 一般的に、マイノリティークラスでは精度が重視されるので、この手法ではモデルの精度を維持しながら、トレーニングデータセットのサイズを大幅に削減(モデリング時間とコストを削減)します。
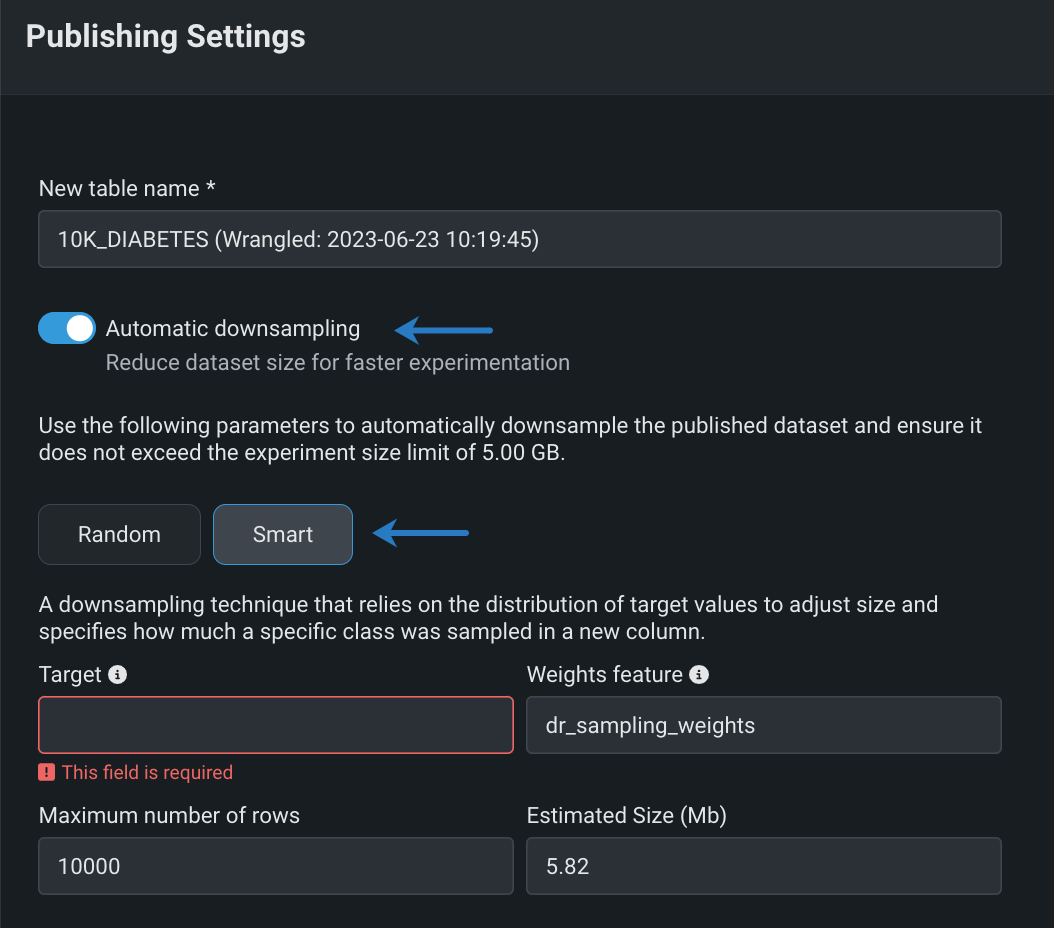
機能フラグ:ラングリングのパブリッシュ設定でスマートダウンサンプリングを有効にする
ワークベンチでのデータ準備の改善¶
このリリースでは、ワークベンチでのデータ準備にいくつかの改善が加えられています。
ワークベンチで _動的データセット_がサポートされるようになりました。
- データ接続を介して追加されたデータセットは、データレジストリとユースケースに動的データセットとして登録されます。
- 接続を介して追加された動的データセットは、データレジストリで選択できます。
- DataRobotは、動的データセットの探索的データインサイトを表示するときに、新しいライブサンプルを取得します。
機能フラグ: ワークベンチで動的データセットを有効にする
ワークベンチのユースケースに登録されたデータセットを探索しながら、 カスタム特徴量セットを表示および作成 できるようになりました。
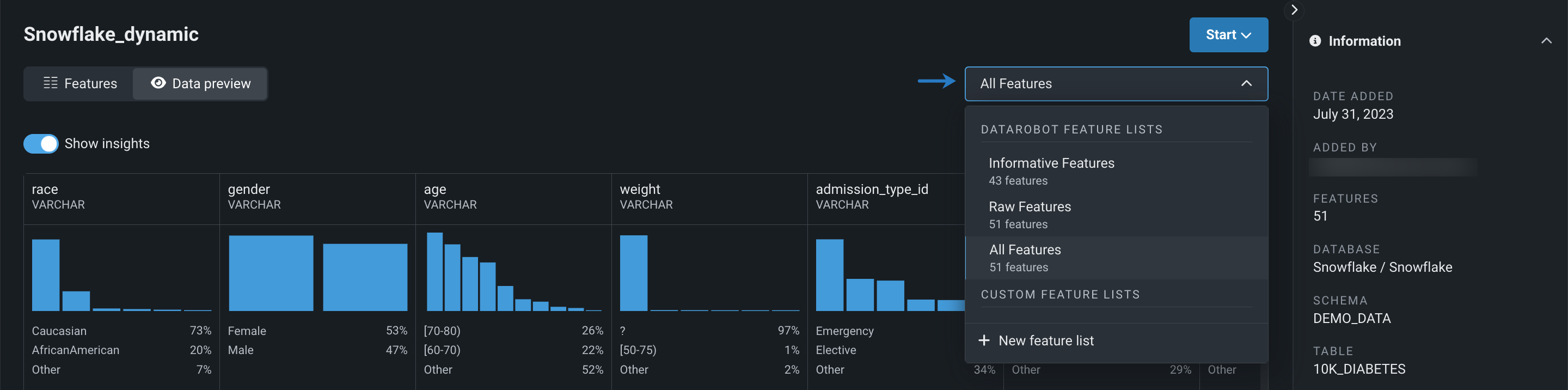
プレビュー機能のドキュメントをご覧ください。
機能フラグ: ワークベンチのプレビューで特徴量セットを有効にする
さらに、ユースケースに追加されたラングリングデータセットの場合、出力の生成に使用される SQLレシピを表示 できるようになりました。
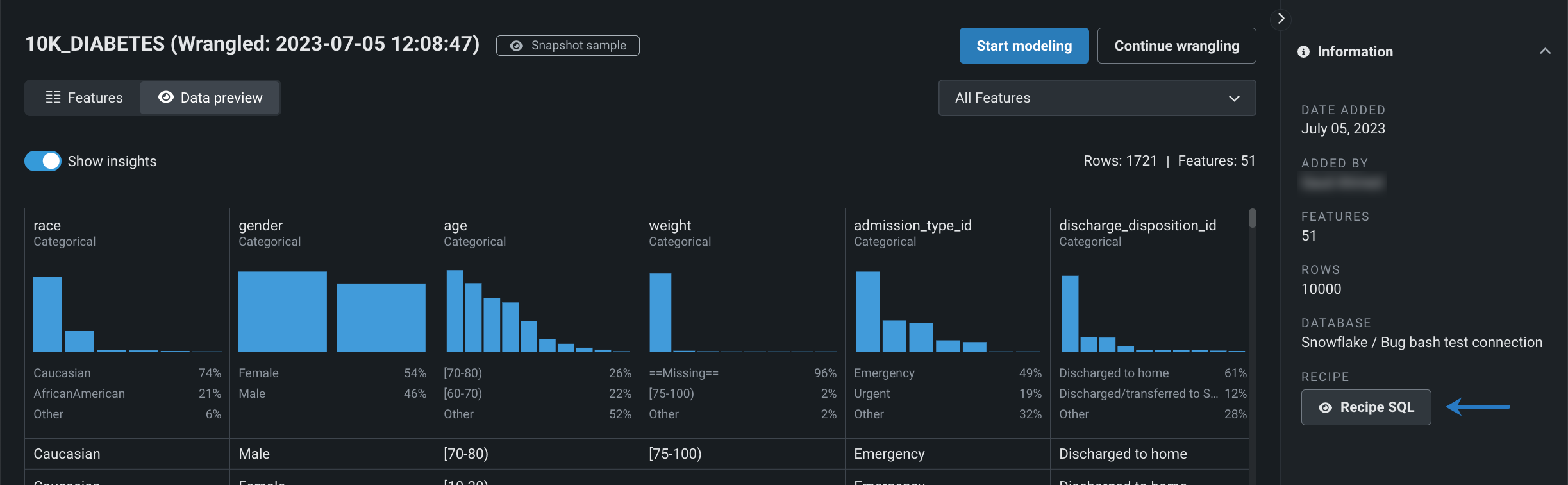
BigQueryとの接続の強化¶
新しいBigQueryコネクターがプレビューで利用可能になりました。パフォーマンスと互換性が強化され、サービスアカウントの資格情報を使用した認証にも対応しています。
プレビュー機能のドキュメントをご覧ください。
機能フラグ: ネイティブBigQueryドライバーを有効にする
モデリングの機能強化¶
一般提供¶
Sklearnライブラリのアップグレード¶
このリリースでは、sklearnライブラリが0.15.1から0.24.2にアップグレードされました。その影響は以下のとおりです。
-
特徴量の関連性のインサイト:スペクトルクラスタリングロジックが更新されました。 これは、クラスターID(各クラスターの数値識別子、たとえば0、1、2、3)にのみ影響します。 特徴量の関連性のインサイトの値は影響を受けません。
-
AUC/ROCインサイト:sklearn ROC曲線の計算が改善されたため、AUC/ROC値のプレシジョンに若干の影響があります。
プレビュー¶
カスタムタスクでのハイパーパラメーターのチューニング¶
カスタムタスクでハイパーパラメーターをチューニングできるようになりました。 各ハイパーパラメーターには、nameとtypeの2つの値を指定できます。 typeはint、float、string、select、multi のいずれかで、すべてのtypeがdefault値をサポートします。 ハイパーパラメーターの詳細と設定例については、 モデルのメタデータと検証スキーマを参照してください。
プレビュー機能のドキュメントをご覧ください。
AIアプリの機能強化¶
プレビュー¶
ワークベンチでの新しいアプリエクスペリエンスを改善¶
このリリースでは、ワークベンチでの新しいアプリケーションエクスペリエンス(プレビュー版)に以下の改善が加えられています。
- 概要フォルダーでアプリケーションの作成に使用したモデルのブループリントを表示するようになりました。
- 利用可能なアプリテーマにAlpine Lightが追加されました。
プレビュー機能のドキュメントをご覧ください。
機能フラグ: 新しいAIアプリの編集モードを有効にする
MLOpsの機能強化¶
一般提供¶
Apache Airflow用のDataRobotプロバイダー¶
一般提供機能になりました。DataRobot MLOpsとApache Airflowの機能を組み合わせることで、モデルの再トレーニングと再デプロイのための信頼性の高いソリューションを実装できます。たとえば、モデルの再トレーニングと再デプロイは、スケジュールに従って、モデルのパフォーマンスが低下したときに、または新しいデータが存在するときにパイプラインをトリガーするセンサーを使用して行うことができます。 Apache Airflow用のDataRobotプロバイダーは、 GitHubのパブリックリポジトリで利用可能なソースコードから構築されたPythonパッケージであり、 PyPI(Pythonパッケージインデックス)で公開されています。 これは、 Astronomerレジストリにも一覧表示されています。 この連携では、REST APIを介してDataRobotインスタンスと通信する DataRobot Python APIクライアントが使用されます。
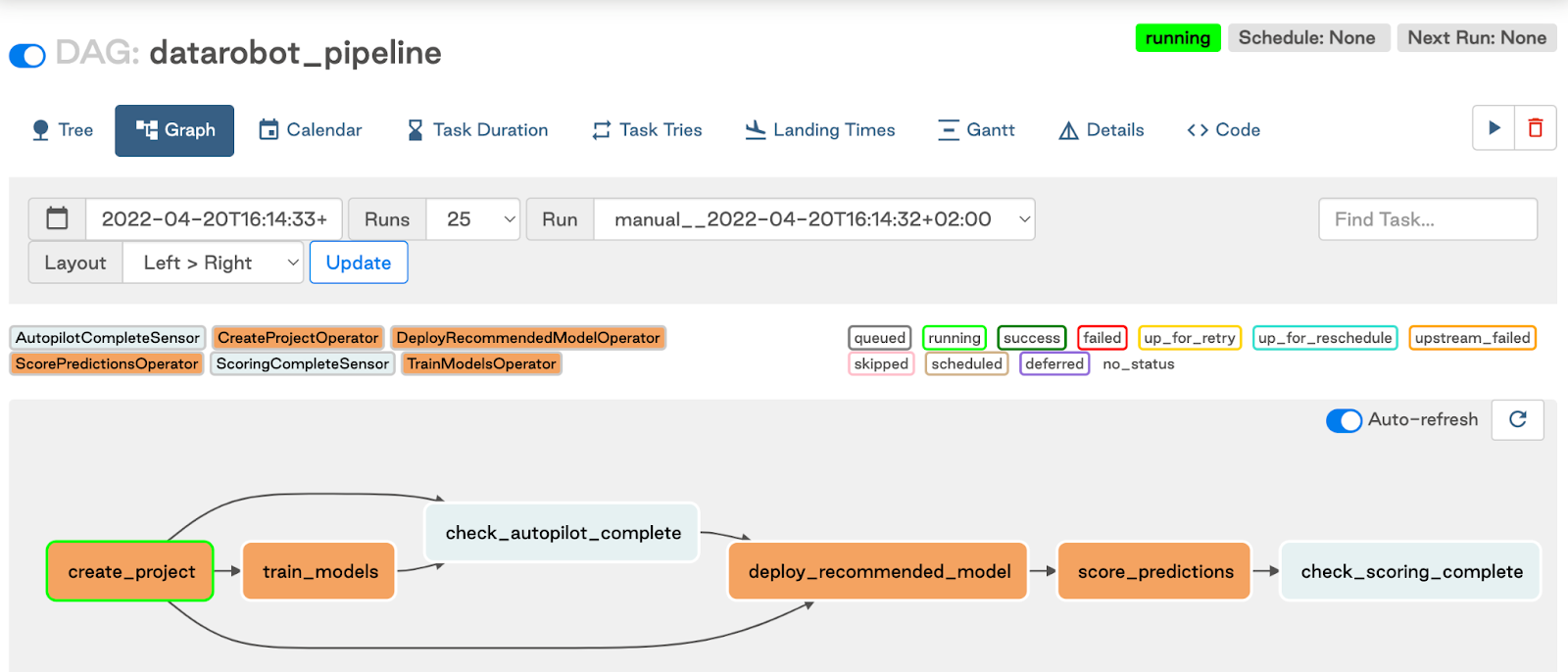
詳細は、 Apache AirflowのDataRobotプロバイダークイックスタートガイドを参照してください。
プレビュー¶
DataRobotモデルレジストリのMLflowインテグレーション¶
DataRobotのMLflow連携のプレビューリリースにより、MLflowからモデルをエクスポートしてDataRobot モデルレジストリにインポートし、MLflowモデルのトレーニングパラメーター、指標、タグ、アーティファクトから キー値を作成します。 インテグレーションのコマンドラインインターフェイスを使用して、エクスポートおよびインポート処理を実行できます。
DR_MODEL_ID="<MODEL_PACKAGE_ID>"
env PYTHONPATH=./ \
python datarobot_mlflow/drflow_cli.py \
--mlflow-url http://localhost:8080 \
--mlflow-model cost-model \
--mlflow-model-version 2 \
--dr-model $DR_MODEL_ID \
--dr-url https://app.datarobot.com \
--with-artifacts \
--verbose \
--action sync
プレビュー機能のドキュメントをご覧ください。
機能フラグ:拡張コンプライアンスドキュメントを生成する
カスタム指標の監視ジョブ¶
プレビュー版の機能です。監視ジョブの定義により、DataRobotの外部から計算済みのカスタム指標値を、 カスタム指標タブで定義された指標に取り込むことができ、外部データソースを使用したカスタム指標をサポートします。 たとえば、Snowflakeに接続する監視ジョブを作成し、関連するSnowflakeテーブルからカスタム指標データを取得し、DataRobotにデータを送信できます。
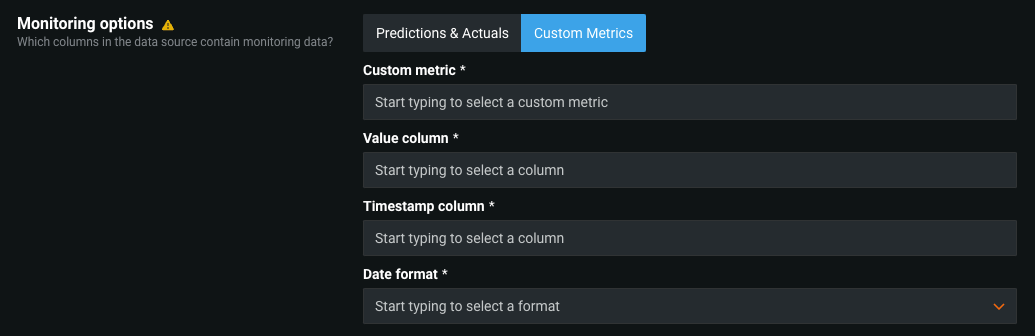
詳しくはドキュメントをご覧ください。
予測値と実測値の適時性インジケーター¶
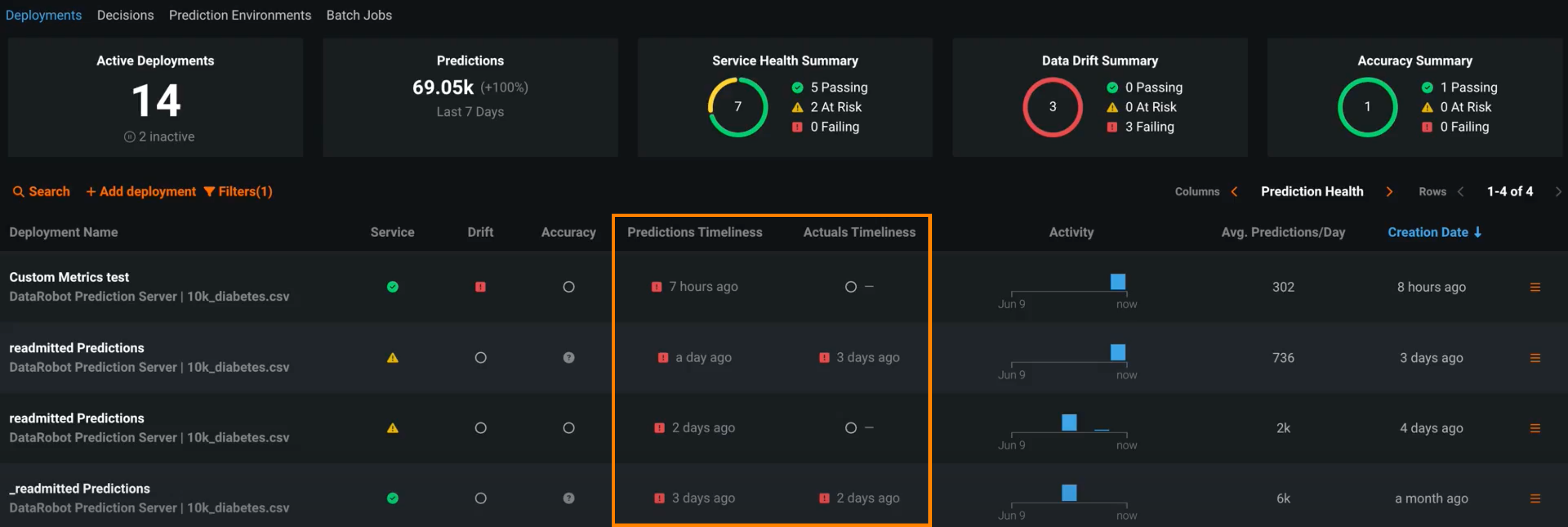
デプロイには、 サービスの正常性、 データドリフト、 精度など、デプロイの全般的な正常性を定義するいくつかのステータスがあります。 これらのステータスは、最新の使用可能なデータに基づいて計算されます。 24時間以上の間隔で行われたバッチ予測に依存するデプロイの場合、この方法では、 デプロイインベントリの予測正常性インジケーターのステータスがグレー/不明になることがあります。 プレビュー版の機能です。これらのデプロイの正常性インジケーターは、最後に計算された正常性の状態を保持し、古いデータに基づいているときはそれを明示する適時性ステータスインジケーターとともに表示されます。 状況に応じて、デプロイに適した適時性の間隔を決定できます。 デプロイの使用状況 > 設定タブで適時性の追跡を有効にすると、 使用状況タブと デプロイインベントリで適時性インジケーターを表示できます。
予測値の適時性と実測値の適時性の列を表示します。
予測値の適時性と実測値の適時性のタイルを表示します。
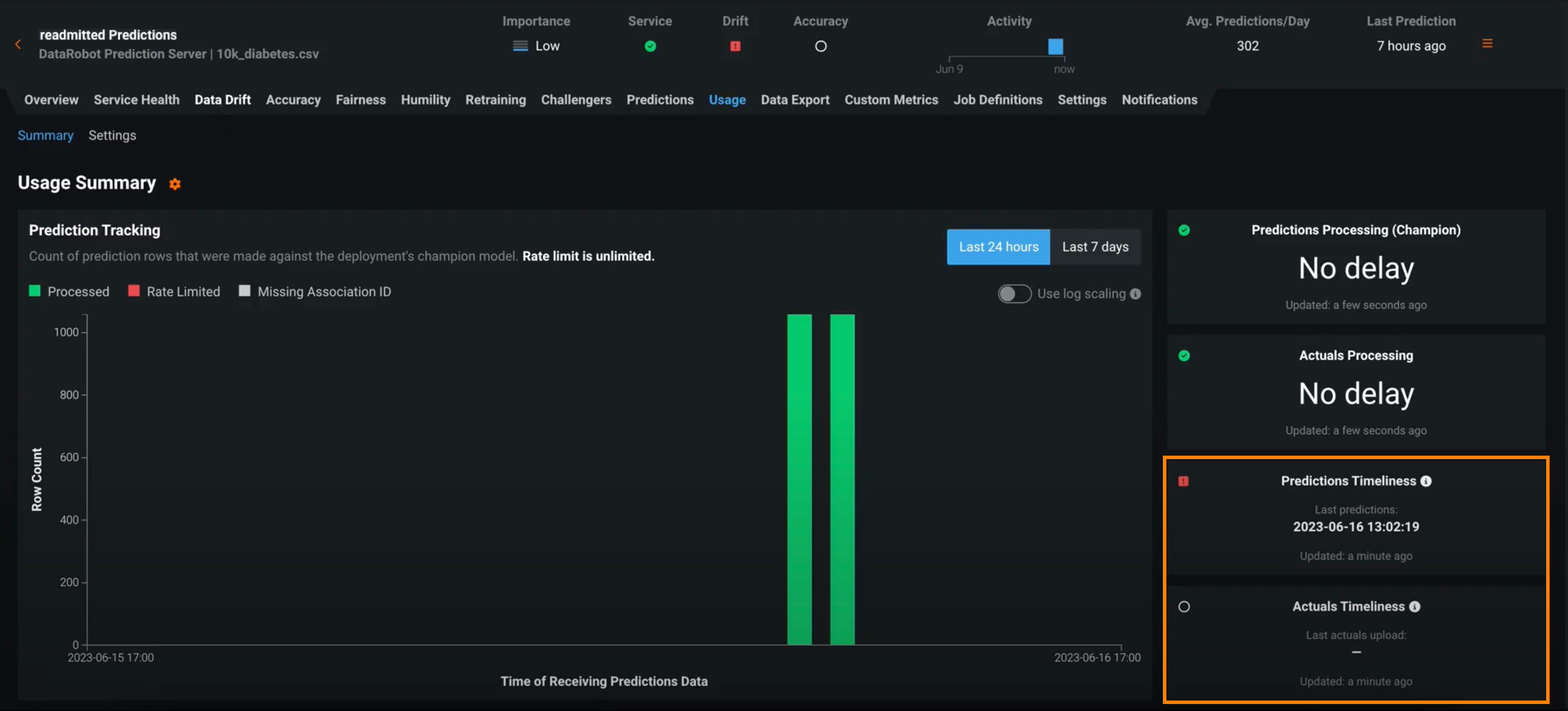
ステータスに加えて、適時性タイルの更新時間を確認できます。
備考
使用状況タブとデプロイインベントリのインジケーターに加えて、適時性のステータスが赤/失敗に変わると、メールまたは 通知ポリシーで設定されたチャネルを通じて通知が送信されます。
詳しくはドキュメントをご覧ください。
機能フラグ: デプロイの適時性統計インジケーターを有効にします
モデルレジストリでのバージョン管理のサポート¶
モデルレジストリは、DataRobotで使用されるさまざまなモデルの組織的なハブです。ここでは、デプロイ可能なモデルパッケージとしてモデルにアクセスできます。 プレビュー版の機能です。モデルレジストリ > 登録済みのモデルページでは、モデルをさらに整理することができます。
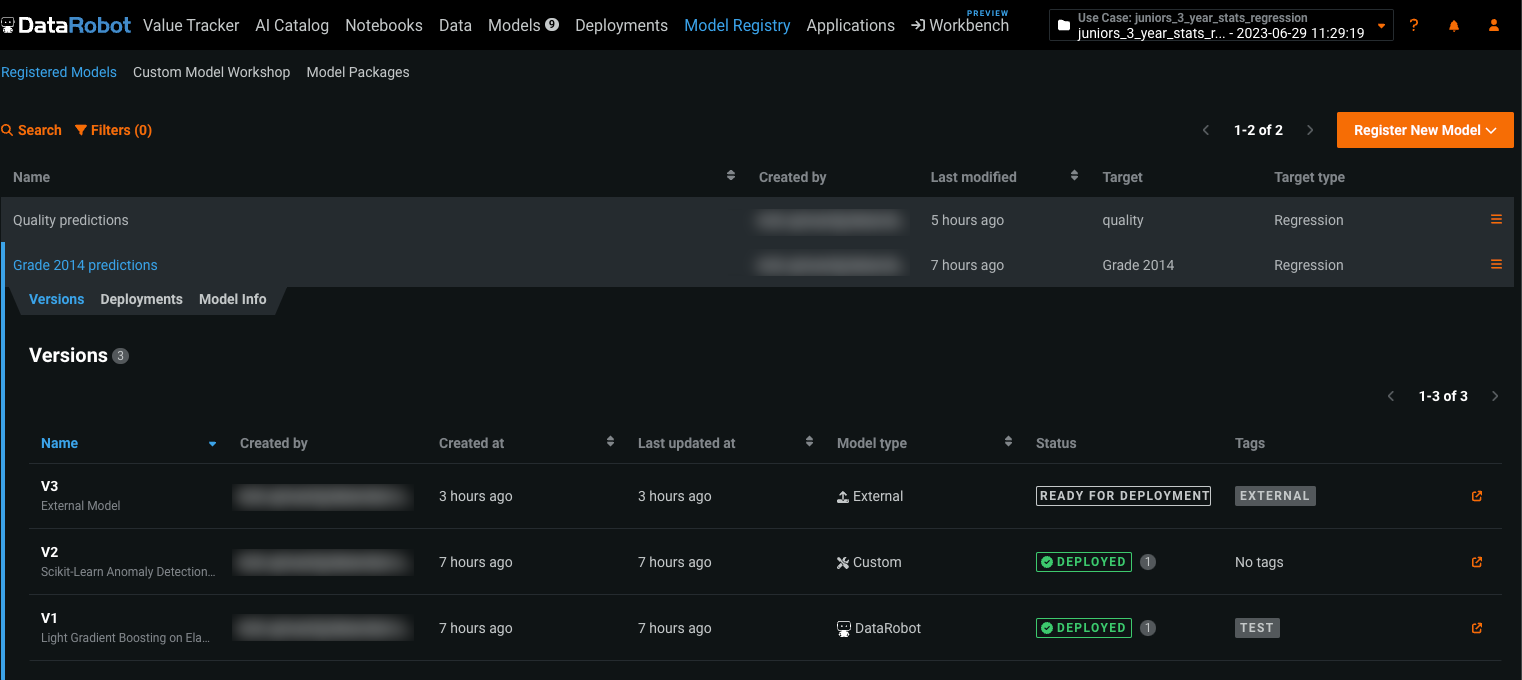
このページでは、モデルパッケージを登録済みモデルにグループ化して、解決するビジネス上の問題に基づいて分類できます。 登録済みモデルには、以下を含めることができます。
-
DataRobotモデル、カスタムモデル、および外部モデル
-
チャレンジャーモデル(チャンピオンと共に)
-
自動的に再トレーニングされたモデル。
登録済みモデルを追加した後には、検索、フィルター、並び替えを行うことができます。 登録済みモデル(およびそのモデルに含まれるバージョン)を他のユーザーと共有することもできます。
詳細については、モデルレジストリのドキュメントを参照してください。
機能フラグ: モデルレジストリでのバージョン管理サポートを有効にする
カスタムモデルのパブリックネットワークへのアクセス¶
プレビュー版の機能です。どのカスタムモデルにも完全なネットワークアクセスを有効にすることができます。 カスタムモデルを作成すると、パブリックネットワーク内の任意の完全修飾ドメイン名(FQDN)にアクセスできるため、サードパーティのサービスをモデルで利用できます。 または、モデルをネットワークから分離し、発信トラフィックをブロックしたい場合は、パブリックネットワークへのアクセスを無効にすると、モデルのセキュリティを強化できます。 カスタムモデルでこのアクセス設定をレビューするには、リソース設定の下のアセンブルタブで、ネットワークアクセスを確認します。
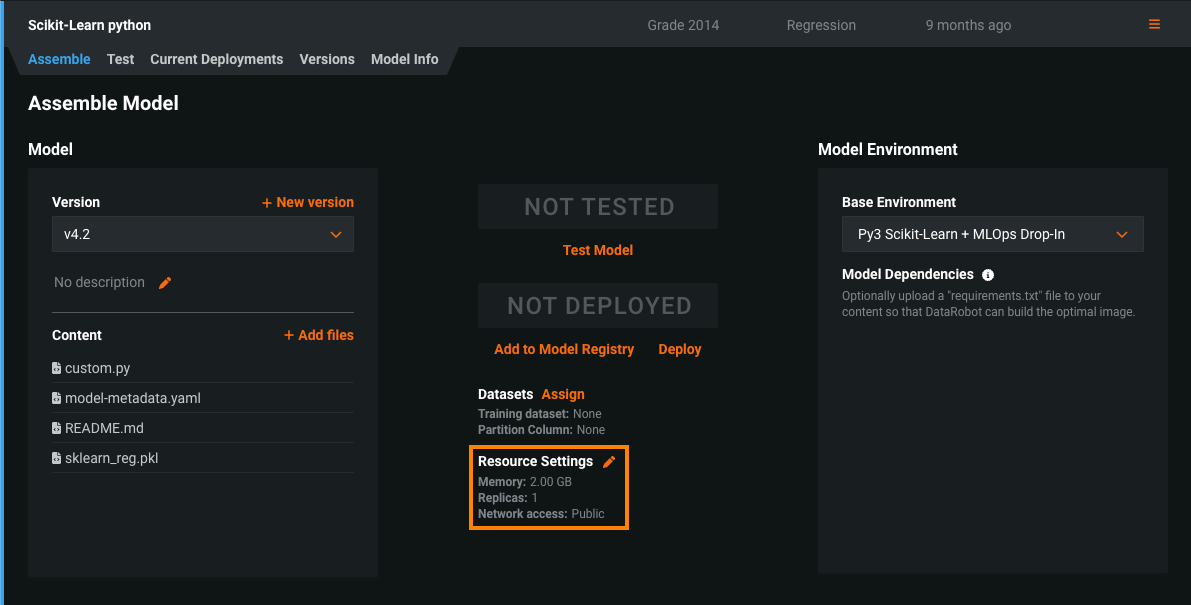
詳しくはドキュメントをご覧ください。
機能フラグ: すべてのカスタムモデルでパブリックネットワークへのアクセスを有効にする
生成モデルの監視サポート¶
プレビュー版の機能です。DataRobotのカスタムモデルと外部モデルのテキスト生成ターゲットタイプは、生成LLM(大規模言語モデル)と互換性があり、生成モデルのデプロイ、予測の実行、サービス、使用状況、データドリフト統計の監視、カスタム指標の作成が可能です。 DataRobotは、次の2つのデプロイ方法でLLMに対応しています。
-
DataRobotでカスタム推論モデルとしてテキスト生成モデルを作成:DataRobotのカスタムモデルワークショップを使用してテキスト生成モデルを作成してデプロイし、LLMのAPIを呼び出して、直接推論を実行する代わりにテキストを生成し、DataRobot MLOpsが監視のためにLLMの入力と出力にアクセスできるようにします。 LLMのAPIを呼び出すには、 カスタムモデルのパブリックネットワークアクセスを有効にする必要があります。
-
外部で実行されているテキスト生成モデルを監視:インフラストラクチャ(ローカルまたはクラウド)にテキスト生成モデルを作成してデプロイし、監視エージェントを使用して、LLMの入出力を監視のためにDataRobotに通信します。
生成モデルをデプロイした後、 サービスの正常性と 使用状況の統計の表示、 デプロイデータのエクスポート、 カスタム指標の作成、 データドリフトの識別を行うことができます。 生成モデルのデータドリフトタブでは、 特徴量ドリフト対特徴量の有用性、 特徴量の詳細、 時間経過に伴うドリフトチャートを表示できます。
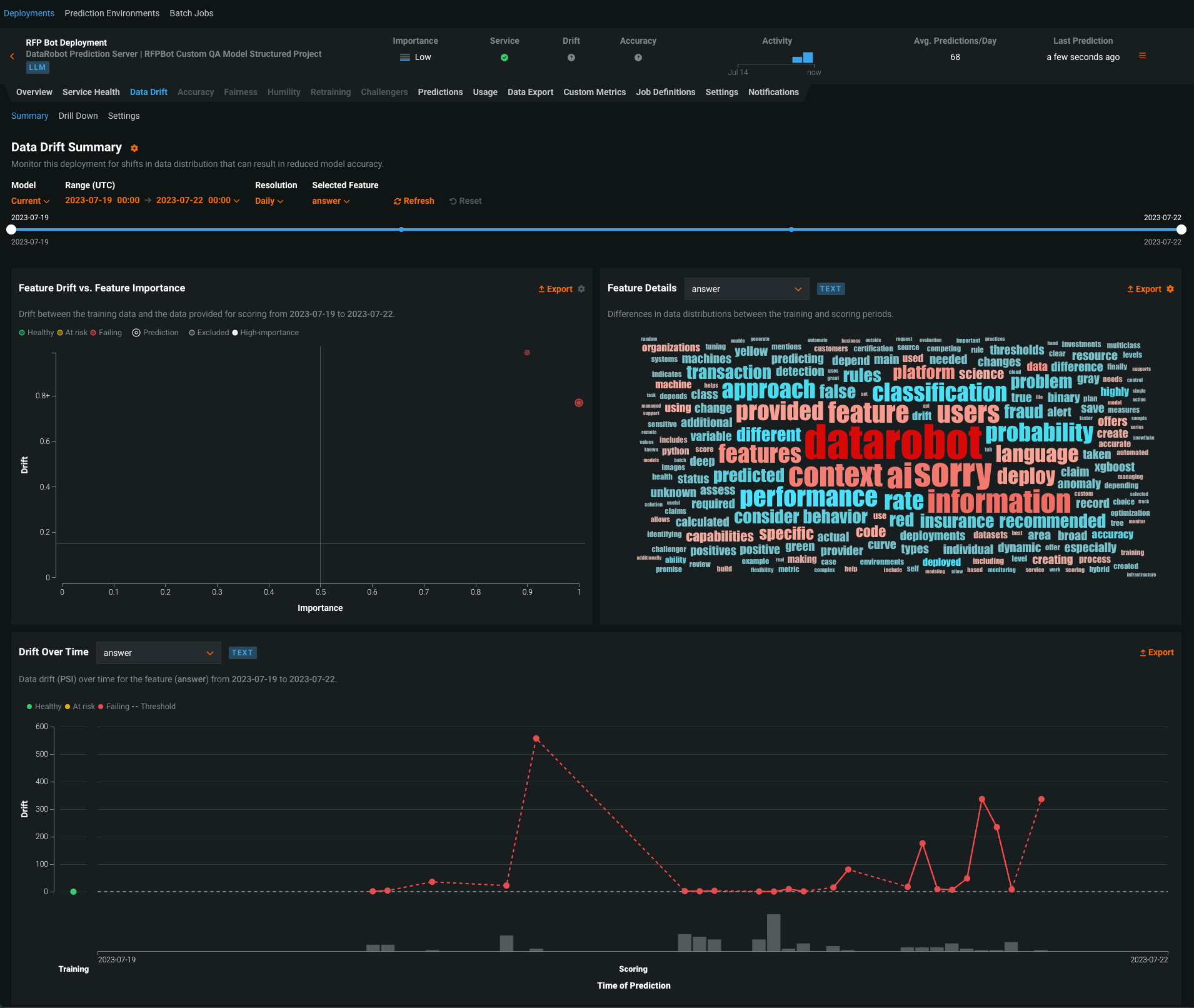
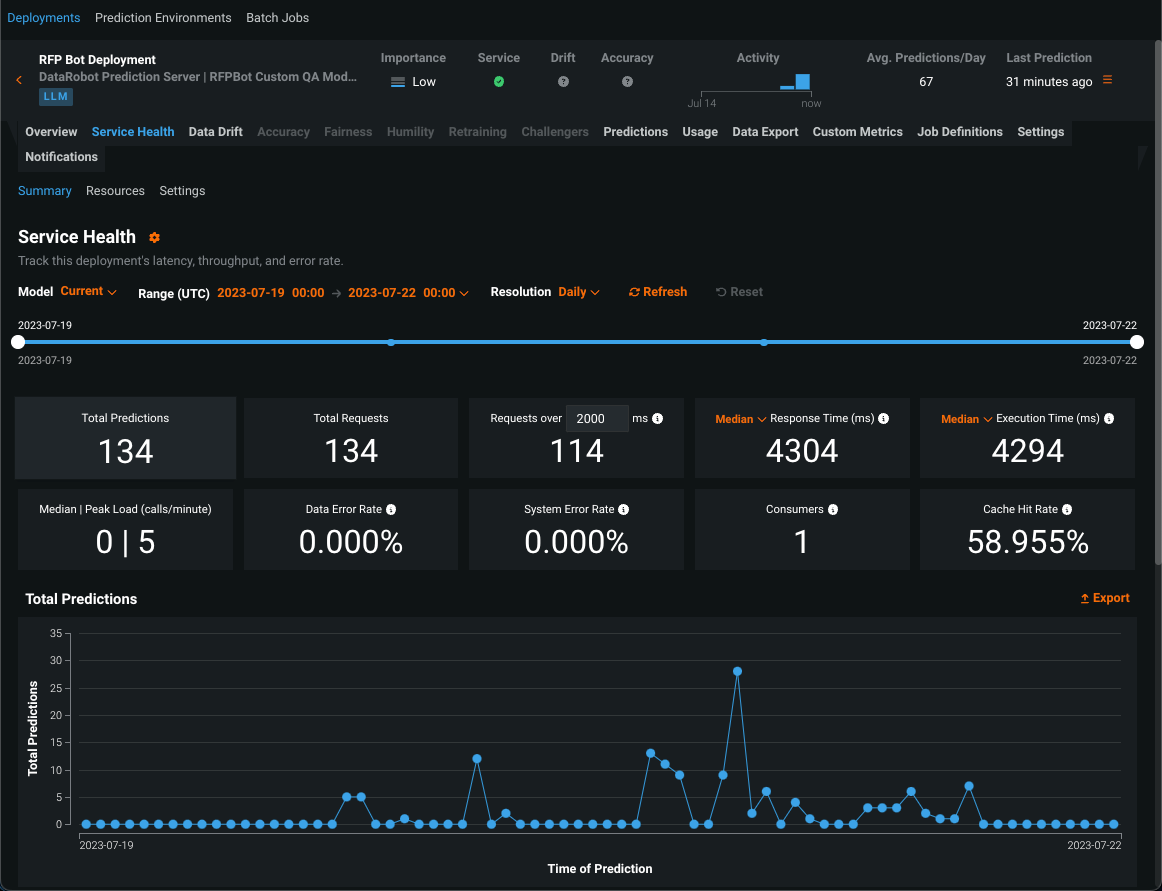
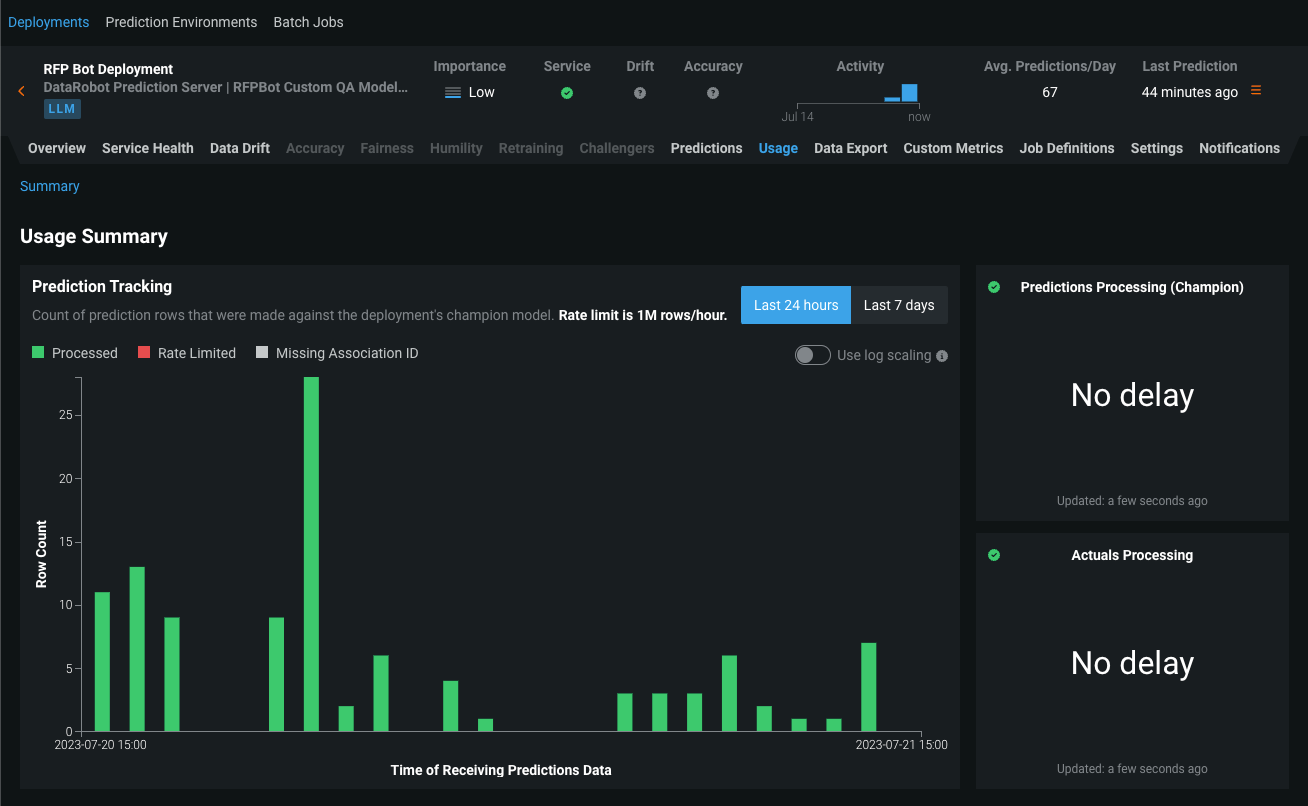
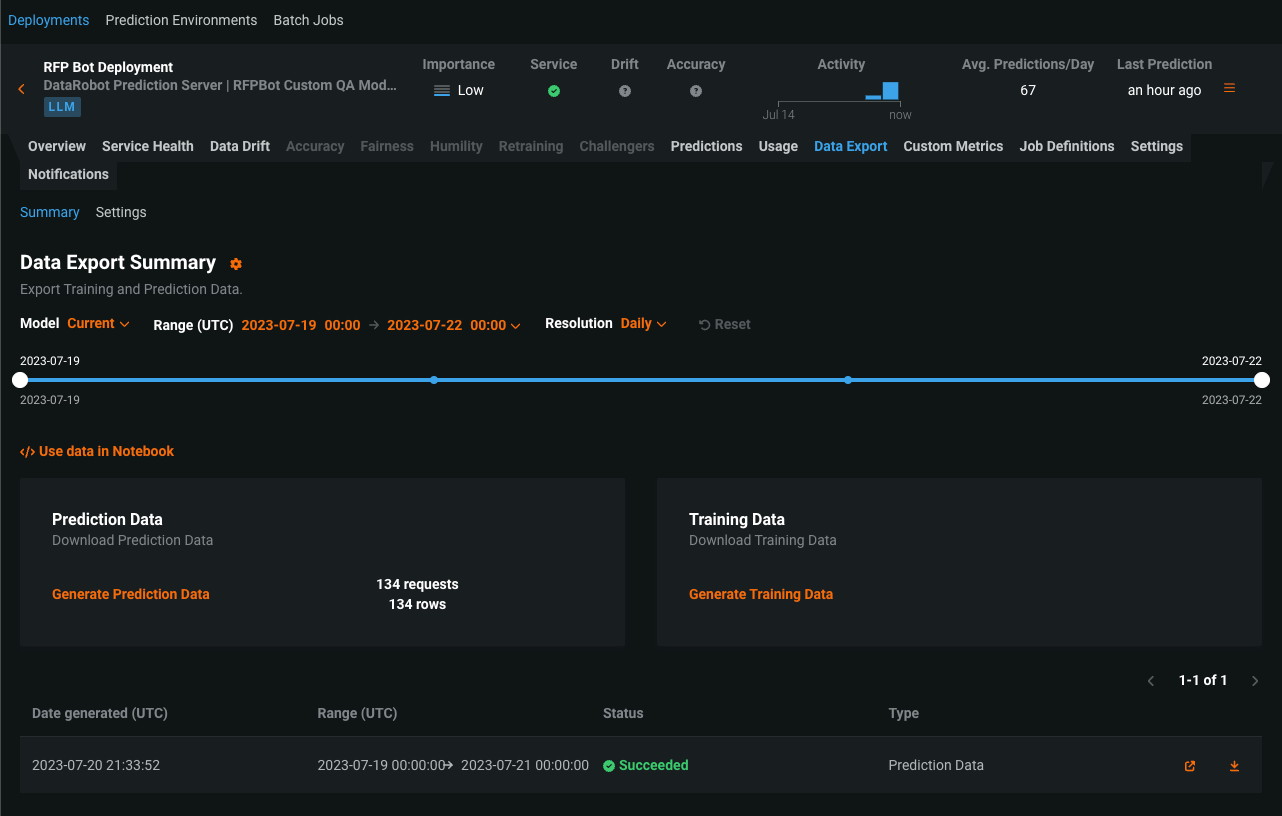
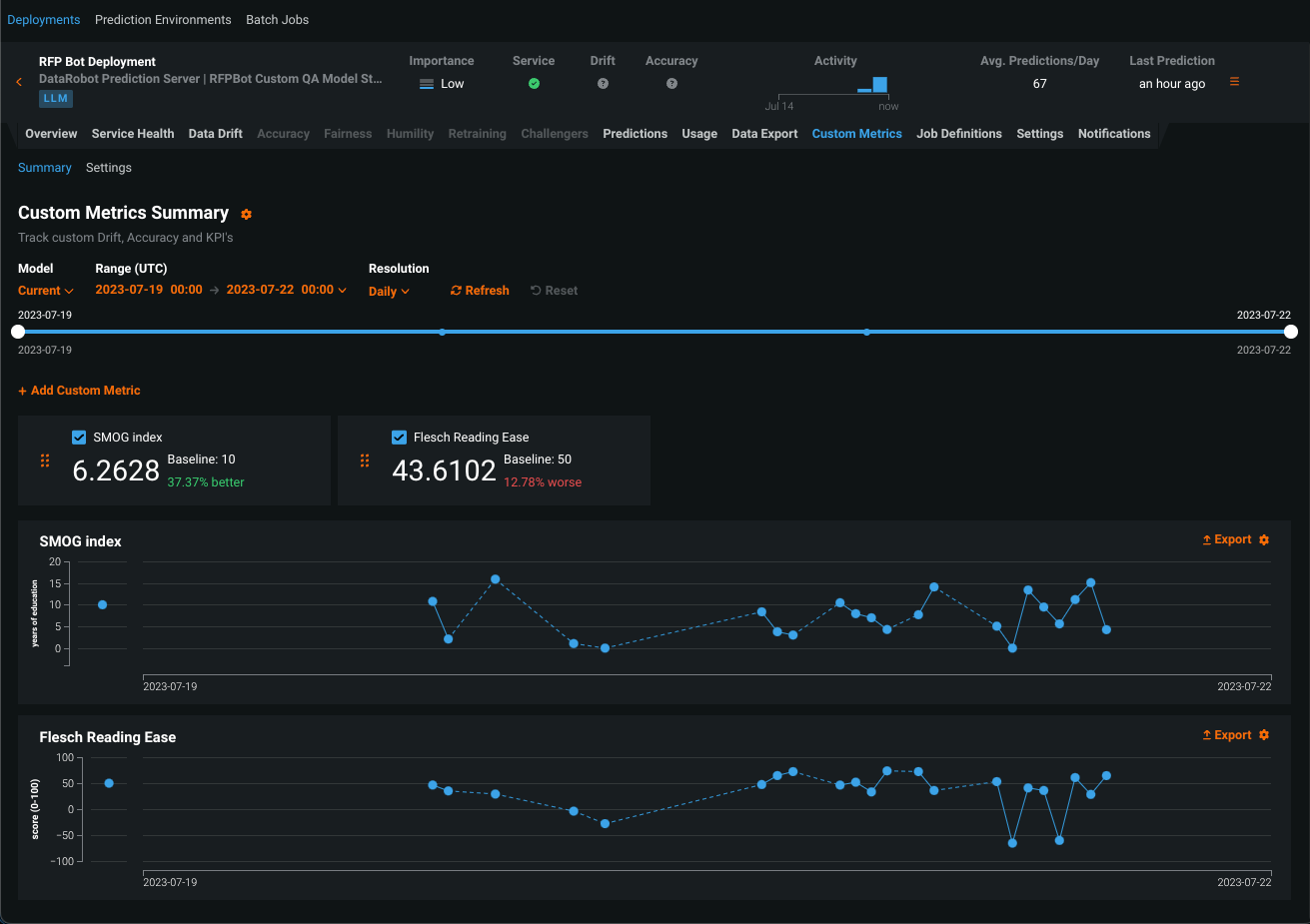
プレビュー機能のドキュメントをご覧ください。
機能フラグ: 生成モデルの監視サポートを有効にする
APIの機能強化¶
DataRobot REST API v2.31¶
新機能¶
- 時間経過に伴うデプロイの公平性スコアを取得する新しいルート:
GET /api/v2/deployments/(deploymentId)/fairnessScoresOverTime/- 時間経過に伴うデプロイ予測統計を取得する新しいルート:
GET /api/v2/deployments/(deploymentId)/predictionsOverTime/- スライスされたインサイトを計算および取得するための新しいルート:
POST /api/v2/insights/featureEffects/GET /api/v2/insights/featureEffects/models/(entityId)/POST /api/v2/insights/featureImpact/GET /api/v2/insights/featureImpact/models/(entityId)/POST /api/v2/insights/liftChart/GET /api/v2/insights/liftChart/models/(entityId)/POST /api/v2/insights/residuals/GET /api/v2/insights/residuals/models/(entityId)/POST/api/v2/insights/rocCurve/GET GET /api/v2/insights/rocCurve/models/(entityId)/- スライスされたインサイトで使用するデータスライスを作成および管理するための新しいルート:
POST /api/v2/dataSlices/- :http:delete:
/api/v2/dataSlices/ DELETE /api/v2/dataSlices/(dataSliceId)/GET /api/v2/dataSlices/(dataSliceId)/GET /api/v2/projects/(projectId)/dataSlices/POST /api/v2/dataSlices/(dataSliceId)/sliceSizes/GET /api/v2/dataSlices/(dataSliceId)/sliceSizes/- リーダーボードモデルを登録する新しいルート:
POST /api/v2/modelPackages/fromLeaderboard/- バリュートラッカー(以前のユースケース)を作成および管理するための新しいルート:
POST /api/v2/valueTrackers/GET /api/v2/valueTrackers/GET /api/v2/valueTrackers/(valueTrackerId)/PATCH /api/v2/valueTrackers/(valueTrackerId)/DELETE /api/v2/valueTrackers/(valueTrackerId)/GET /api/v2/valueTrackers/(valueTrackerId)/activities/GET /api/v2/valueTrackers/(valueTrackerId)/attachments/POST /api/v2/valueTrackers/(valueTrackerId)/attachments/DELETE /api/v2/valueTrackers/(valueTrackerId)/attachments/(attachmentId)/GET /api/v2/valueTrackers/(valueTrackerId)/attachments/(attachmentId)/GET /api/v2/valueTrackers/(valueTrackerId)/realizedValueOverTime/GET /api/v2/valueTrackers/(valueTrackerId)/sharedRoles/PATCH /api/v2/valueTrackers/(valueTrackerId)/sharedRoles/
APIの変更¶
- カスタムモデルバージョン作成エンドポイントにトレーニングおよびホールドアウトデータの割り当てが追加されました。
POST /api/v2/customModels/(customModelId)/versions/-
PATCH /api/v2/customModels/(customModelId)/versions/ -
組織からユーザーを削除するための組織管理者ルート
DELETE /api/v2/organizations/(organizationId)/users/(userId)/が削除されました。 代わりにユーザーを無効にしてください。また、システム管理者がユーザーを別の組織に移動することもできます。 -
useGpuオプション/パラメーターを追加します。 GPUワーカーが有効な場合、このオプションはプロジェクトでGPUワーカーを使用するかどうかを制御します。 パラメーターは次のルートに追加されます。PATCH /api/v2/projects/(projectId)/aim/
-
ルートを使用してプロジェクトデータを取得すると、
useGpuオプション/パラメーターも新しいフィールドとして返されます。 -
GET /api/v2/projects/(projectId)/ -
FEARなしのOTV時系列プロジェクトの新しいオプションパラメーター
modelBaselines、modelRegimeId、modelGroupIdがPATCH /api/v2/projects/(projectId)/aim/に追加されます。 これらのフィールドを使用するには、機能フラグForecasting Without Automated Feature Derivationを有効にします。
使用非推奨¶
- 以下のカスタム推論モデルのトレーニングデータ割り当てエンドポイントは使用非推奨であり、バージョン2.33で削除される予定です。
PATCH /api/v2/customModels/(customModelId)/trainingData/-
PATCH /api/v2/customModels/(customModelId)/versions/withTrainingData/ -
リーダーボードモデルを登録する次のルートは、
POST /api/v2/modelPackages/fromLeaderboard/が優先されて使用非推奨となり、v2.33で削除される予定です。 -
POST /api/v2/modelPackages/fromLearningModel/ -
次のユースケース管理エンドポイントは、新しい
GET /api/v2/valueTrackers/ベースのエンドポイントが優先されて使用非推奨となり、v2.33で削除される予定です。POST /api/v2/useCases/GET /api/v2/useCases/GET /api/v2/useCases/(useCaseId)/PATCH /api/v2/useCases/(useCaseId)/DELETE /api/v2/useCases/(useCaseId)/GET /api/v2/useCases/(useCaseId)/activities/GET /api/v2/useCases/(useCaseId)/attachments/POST /api/v2/useCases/(useCaseId)/attachments/DELETE /api/v2/useCases/(useCaseId)/attachments/(attachmentId)/GET /api/v2/useCases/(useCaseId)/attachments/(attachmentId)/GET /api/v2/useCases/(useCaseId)/realizedValueOverTime/GET /api/v2/useCases/(useCaseId)/sharedRoles/PATCH /api/v2/useCases/(useCaseId)/sharedRoles/
-
現在の
useCases/エンドポイントはvalueTracker/エンドポイントに名前が変更されています。 現在のuseCases/エンドポイントは、2回のリリース後(API 2.33)に廃止される予定です。現在のuseCases/エンドポイントの代わりに、valueTrackers/エンドポイントの使用を開始してください。
Rクライアント v2.31¶
Rクライアントのバージョンv2.31のプレビューを開始しました。 GitHub経由でインストールできます。
このバージョンのRクライアントは、curl==5.0.1パッケージ内の新しい機能により、datarobot:::UploadDataの呼び出し(つまり、SetupProject)がエラーNo method asJSON S3 class: form_fileで失敗する問題に対処します。
機能強化¶
エクスポートされない関数datarobot:::UploadDataは、オプションの引数fileNameを取るようになりました。
バグ修正¶
suppressPackageStartupMessages()でdatarobotパッケージをロードすると、すべてのメッセージが抑制されるようになりました。
使用非推奨¶
CreateProjectsDatetimeModelsFeatureFitは削除されました。 代わりにCreateProjectsDatetimeModelsFeatureEffectsを使用してください。ListProjectsDatetimeModelsFeatureFitは削除されました。 代わりにListProjectsDatetimeModelsFeatureEffectsを使用してください。ListProjectsDatetimeModelsFeatureFitMetadataは削除されました。 代わりにListProjectsDatetimeModelsFeatureEffectsMetadataを使用してください。CreateProjectsModelsFeatureFitは削除されました。 代わりにCreateProjectsModelsFeatureEffectsを使用してください。ListProjectsModelsFeatureFitは削除されました。 代わりにListProjectsModelsFeatureEffectsを使用してください。ListProjectsModelsFeatureFitMetadataは削除されました。 代わりにListProjectsModelsFeatureEffectsMetadataを使用してください。
依存関係の変更¶
クライアントドキュメントがRoxygen2 v7.2.3で明示的に生成できるようになりました。 ユニットテストの開発体験を向上させるために、Suggests: mockeryが追加されました。
Rクライアント v2.18.3¶
Rクライアントのバージョンv2.31の一般提供を開始しました。 CRANからアクセスできます。
datarobotパッケージはR >= 3.5に依存するようになりました。
新機能¶
-
Rクライアントは、DataRobotプラットフォームのPython 3への移行によって使用非推奨または無効になった特定のリソース(プロジェクト、モデル、デプロイなど)にアクセスしようとすると、警告を出力するようになりました。
-
包括的なオートパイロットのサポートが追加されました。
mode = AutopilotMode.Comprehensiveを使用してください。
機能強化¶
-
RequestFeatureImpact関数でrowCount引数を指定できるようになりました。これにより、特徴量のインパクトの計算に使用されるサンプルサイズが変更されます。 -
エクスポートされない関数
datarobot:::UploadDataは、オプションの引数fileNameを取るようになりました。
バグ修正¶
-
curl==5.0.1のドキュメント化されていない機能がインストールされ、datarobot:::UploadDataの呼び出し(つまり、SetupProject)がエラーNo method asJSON S3 class: form_fileで失敗する問題が修正されました。 -
suppressPackageStartupMessages()でdatarobotパッケージをロードすると、すべてのメッセージが抑制されるようになりました。
APIの変更¶
-
関数
ListProjectsとas.data.frame.projectSummaryListは、v2.5.0で削除されたレコメンダーモデルに関連するフィールドを返さなくなりました。 -
関数
SetTargetでは、オートパイロットモードがデフォルトでクイックに設定されるようになりました。 また、クイックが渡されると、基盤となる/aimエンドポイントはオートで呼び出されなくなります。
使用非推奨¶
-
関数
SetTargetからquickrun引数が削除されました。 ユーザーは代わりにmode = AutopilotMode.Quickを設定する必要があります。 -
コンプライアンスドキュメントは使用非推奨となり、Automated Documentation APIに引き継がれました。
依存関係の変更¶
-
更新された「DataRobot入門」ビネットの変更により、
datarobotパッケージはR >= 3.5に依存するようになりました。 -
更新された「DataRobot入門」ビネットで
AmesHousingパッケージへの依存関係が追加されました。 -
MASSパッケージへの依存を削除しました。 -
クライアントドキュメントがRoxygen2 v7.2.3で明示的に生成できるようになりました。
ドキュメントの変更¶
- ボストンの住宅データセットではなく、アイオワ州エイムズの住宅データを使用するように「DataRobot入門」ビネットが更新されました。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。