2024年10月
2024年10月¶
2023年10月30日
このページでは、新たにリリースされ、DataRobotのSaaS型マルチテナントAIプラットフォームで利用できる機能についてのお知らせと、追加情報へのリンクを掲載しています。 リリースセンターからは、次のものにもアクセスできます。
10月リリースの機能¶
次の表は、新機能の一覧です。
目的別にグループ化された機能
- プレミアム機能
一般提供¶
Anthropic社のClaude 3 Opus LLMのサポートを開始¶
一般提供機能になりました。Anthropic Claude 3 Opusのサポートを開始したことで、DataRobotのGenAI製品で利用可能なClaude 3モデルが増えました。 Claude 3ファミリーの各モデルは、特定のニーズに対応しています。Claude 3ファミリーの最大モデルであるClaude 3 Opusは、大規模な推論や複雑なタスクを得意としています。 DataRobotで利用可能なLLMの全リストをご覧ください。適切なモデルを選択するための開発者向けドキュメントへのリンクもあります。
ワークベンチで多クラス分類のサポートを一般提供¶
最初、2024年3月にワークベンチにリリースされた多クラスモデリングと関連する混同行列が、一般提供されました。 DataRobotでは、多クラスモデリングのさまざまなエクスペリメント(回答が3つ以上の分類問題)をサポートするために、集計機能を使用して無制限のクラス数に対応しています。

ワークベンチで地理空間モデリングのサポートを開始¶
データ内の地理空間パターンを把握しやすくするために、ワークベンチでのモデル構築時に、一般的な地理空間形式をネイティブに取り込み、空間的に明確なモデリングタスクで強化されたモデルブループリントを構築できるようになりました。 エクスペリメントの設定時に、追加設定から地理空間のインサイトセクションで位置特徴量を選択し、その特徴量がモデリングの特徴量セットに含まれていることを確認します それにより、地理空間のインサイトが作成されます。教師ありプロジェクトの場合は位置ごとの精度、教師なしプロジェクトの場合は位置ごとの異常です。

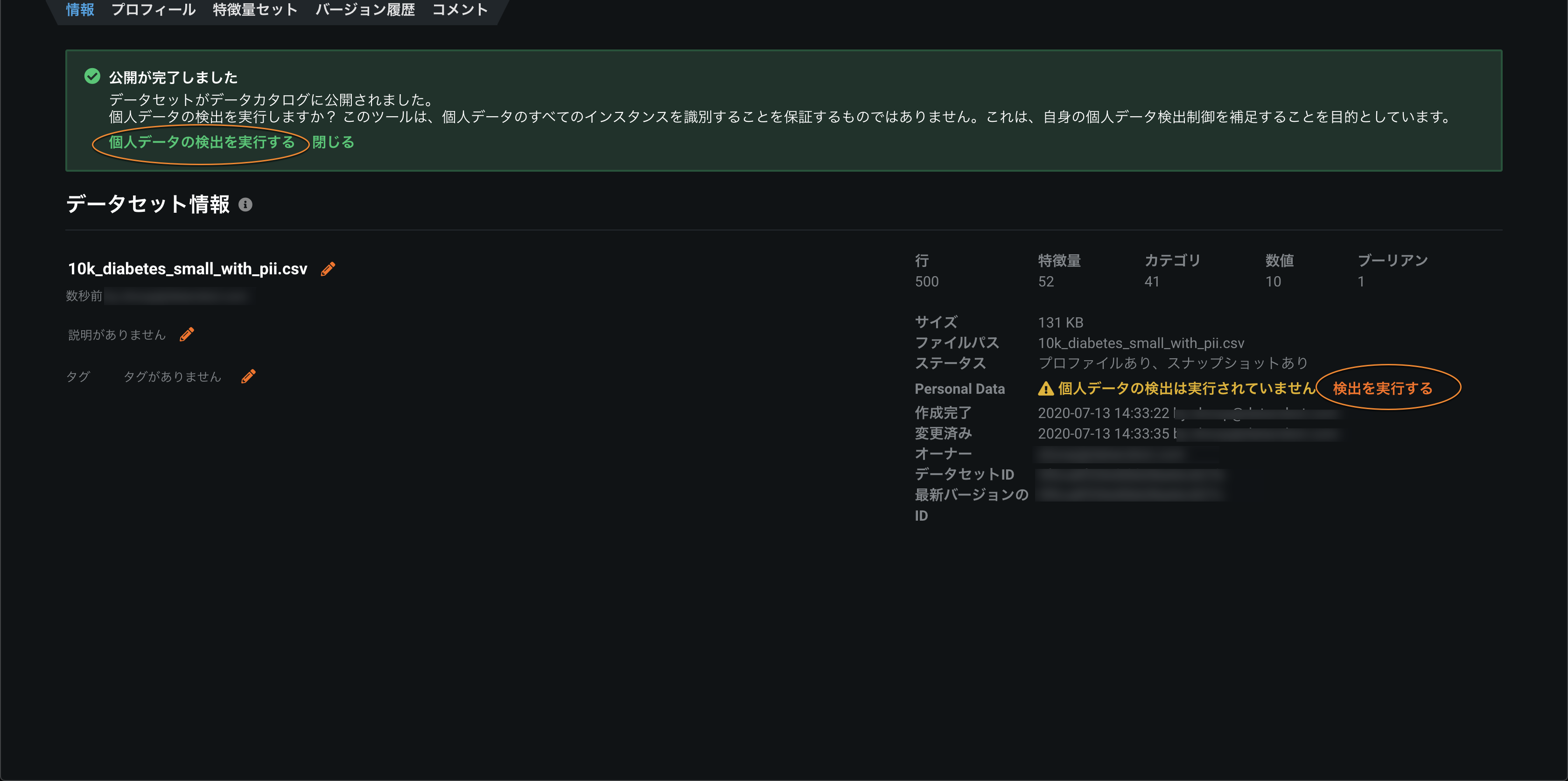
SaaSおよびセルフマネージド環境で個人情報の検出機能を一般提供¶
法規制の遵守が必要なユースケースには、個人情報をモデリングの特徴量として使用することが禁じられているものもあるため、DataRobot Classicでは個人情報の検出機能を提供しています。 この機能が、SaaSとセルフマネージドの両方の環境で一般提供されました。 AIカタログにデータをアップロードした後に、このチェックを利用できます。
XEMPベースの個々の予測説明をワークベンチに追加¶
ワークベンチでは、個々の予測の説明を2つの方法で計算できるようになりました。1つはSHAP(Shapley値に基づく)、もう1つはXEMP(eXemplarに基づくモデル予測の説明)です。 このインサイトは、方法に関係なく、予測の要因を説明するのに役立ちます。 XEMPベースの説明は、すべてのモデルをサポートする独自の方法であり、DataRobot Classicでは以前から利用できました。 ワークベンチでは、SHAPをサポートしていないエクスペリメントでのみ利用できます。

セルフマネージドAIプラットフォームでカスタムタスクのサポートを開始¶
カスタムタスクを使用すると、DataRobotのブループリントにカスタムステップを追加し、DataRobotが生成したブループリントと同様に、そのブループリントをトレーニング、評価、およびデプロイすることができます。 V10.2では、DataRobot Classicとセルフマネージド環境のAPIからもこの機能を利用できるようになりました。
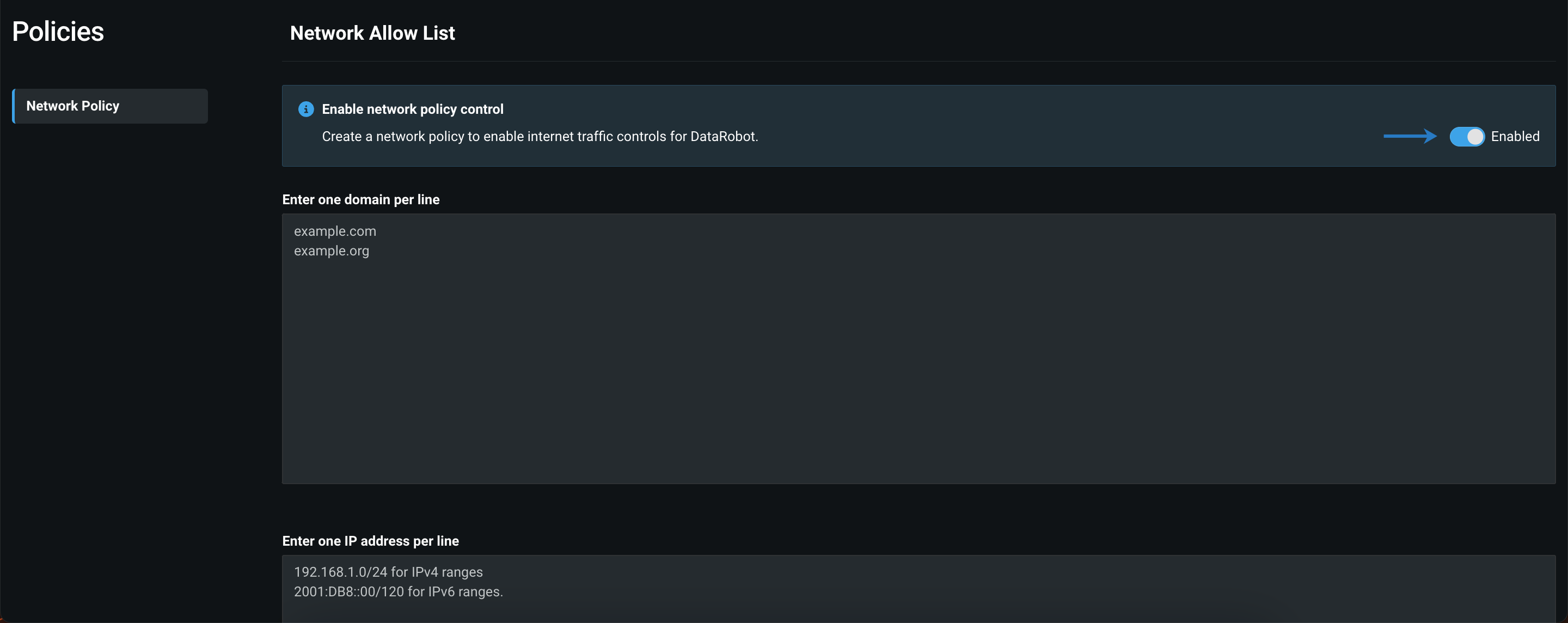
ネットワークポリシーを管理して、公開リソースへのアクセスを制限¶
デフォルトでは、ノートブックを含むDataRobotの一部の機能において、DataRobotがデプロイされているクラスター内から完全なパブリックインターネットアクセスが可能です。ただし、管理者は、ネットワークアクセス制御を設定することで、ユーザーがDataRobot内でアクセスできる公開リソースを制限できます。 これを行うには、ユーザー設定 > ポリシーを開き、ネットワークポリシー制御のトグルを有効にします。 このトグルが有効になっている場合、ユーザーはDataRobot内から公開リソースにアクセスできません。
組織全体でEDAリソースの使用状況を監視¶
一般提供機能になりました。管理者は、リソースモニターのEDAタブで、EDA1および関連タスクに使用されている設定済みのワーカーの数を監視することができます。 リソースモニターは、環境全体にわたってDataRobotのアクティブなモデリングおよびEDAワーカーを可視化し、アプリケーションの現在の状態に関する一般的な情報と、コンポーネントのステータスに関する特定の情報を提供します。
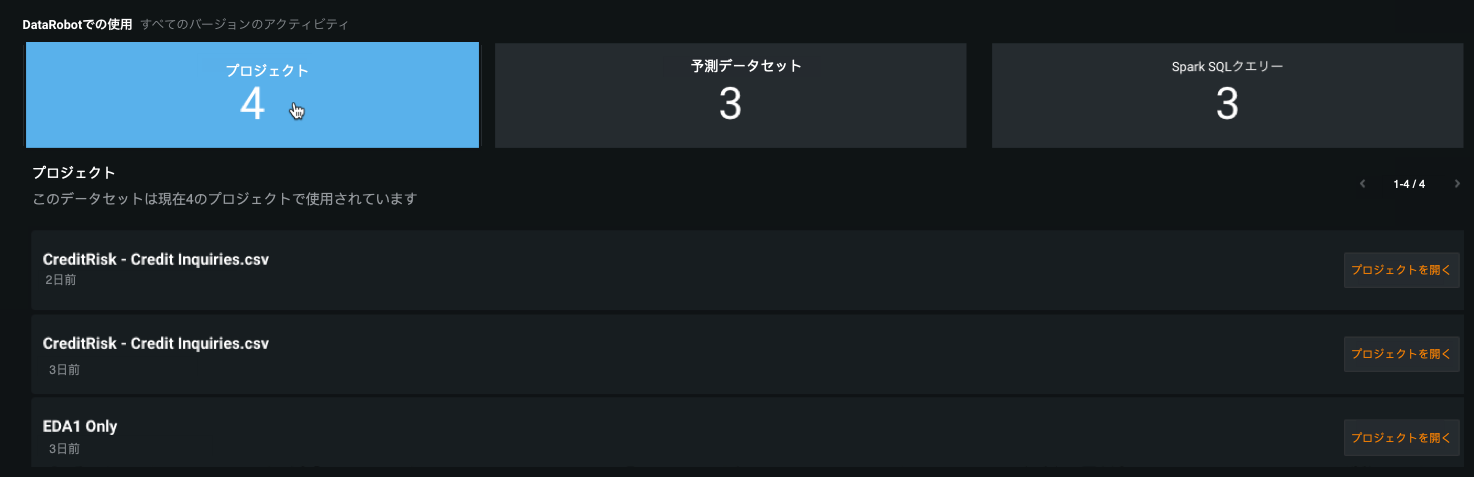
個々のカタログアセットが他のDataRobotエンティティとどのように関連しているかを理解¶
AIカタログは、DataRobotのデータと関連アセットを操作するための集中型コラボレーションハブとして機能します。 個々のアセットの情報タブで、アプリケーション内の他のエンティティが現在のアセットにどのように関連しているか、つまり依存しているかを確認できるようになりました。 これは、アイテムが使用されているプロジェクトの数に基づいてアイテムの人気度を確認したり、変更や削除を行った場合に影響を受ける可能性のある他のエンティティを把握したり、エンティティがどのように使用されているかを理解したりできるなど、さまざまな理由で役立ちます。
オートパイロットを実行する前に日付特徴量を自動的に削除¶
DataRobot Classicで時間を認識しないプロジェクトを設定する場合、オートパイロットの実行に使用する特徴量セットから日付特徴量を自動的に削除できるようになりました。 これを行うには、プロジェクトの高度なオプションを開き、その他タブを選択して、選択したリストから日付特徴量を削除し、新しいモデリング特徴量セットを作成するを選択します。 このパラメーターを有効にすると、選択した特徴量セットが複製され、元の日付特徴量が削除されて、新しい特徴量セットがオートパイロットの実行に使用されます。 時間を認識しないプロジェクトから元の日付特徴量を除外することで、過剰適合のような問題を防ぐことができます。
DataRobotでSAP Datasphereコネクターをサポート¶
プレミアム機能です。NextGenとDataRobot Classicの両方で、SAP Datasphereコネクターをプレビュー機能としてサポートするようになりました。
デフォルトではオフの機能フラグ:SAP Datasphereコネクターを有効にする(プレミアム機能)
バッチ予測でのSAP Datasphereの連携¶
プレミアム機能です。SAP Datasphereは、バッチ予測ジョブの取込み元および出力先としてサポートされています。
デフォルトではオフの機能フラグ:SAP Datasphereコネクターを有効にする(プレミアム機能)、SAP Datasphereとバッチ予測の連携を有効にする(プレミアム機能)
詳しくは、予測の入力および出力オプションに関するドキュメントをご覧ください。
ワークベンチにEDAのインサイトを追加¶
このリリースでは、ワークベンチのデータ探索ページの特徴量タブに、以下のEDAインサイトが導入されています。
-
データ探索ページの特徴量タブでは、個々の特徴量のインサイトに加えて、データ品質チェックが指標として表示されます。

-
ヒストグラムチャートには、外れ値に関するデータ品質の問題が表示されます。

-
頻出値チャートでは、インライア、偽装欠損値、過剰なゼロが報告されます。
- 特徴量探索での特徴量の系統インサイトでは、特徴量がどのように生成されたかが示されます。
登録されたテキスト生成モデルでコンプライアンスドキュメントのサポートを開始¶
DataRobotは、予測モデルの法的検証に使用できるモデル開発ドキュメントを以前から提供しています。 今回、コンプライアンスドキュメントの機能が拡張され、レジストリのモデルタブにあるテキスト生成モデルに対してドキュメントが自動生成されるようになりました。 DataRobotがネイティブにサポートするLLMの場合、このドキュメントは、モデルの概要、有用なリソース、そして特に注目すべきはモデルのパフォーマンスと安定性のテストなど、レポートの生成にかかる時間を短縮するのに役立ちます。 ネイティブにサポートしていないLLMの場合、生成されるドキュメントは、必要なセクションがすべて揃ったテンプレートとして使用できます。 テキスト生成モデルのコンプライアンスドキュメントを生成するには、機能フラグコンプライアンスドキュメントを有効化およびGenAIのエクスペリメントを有効にするが必要です。
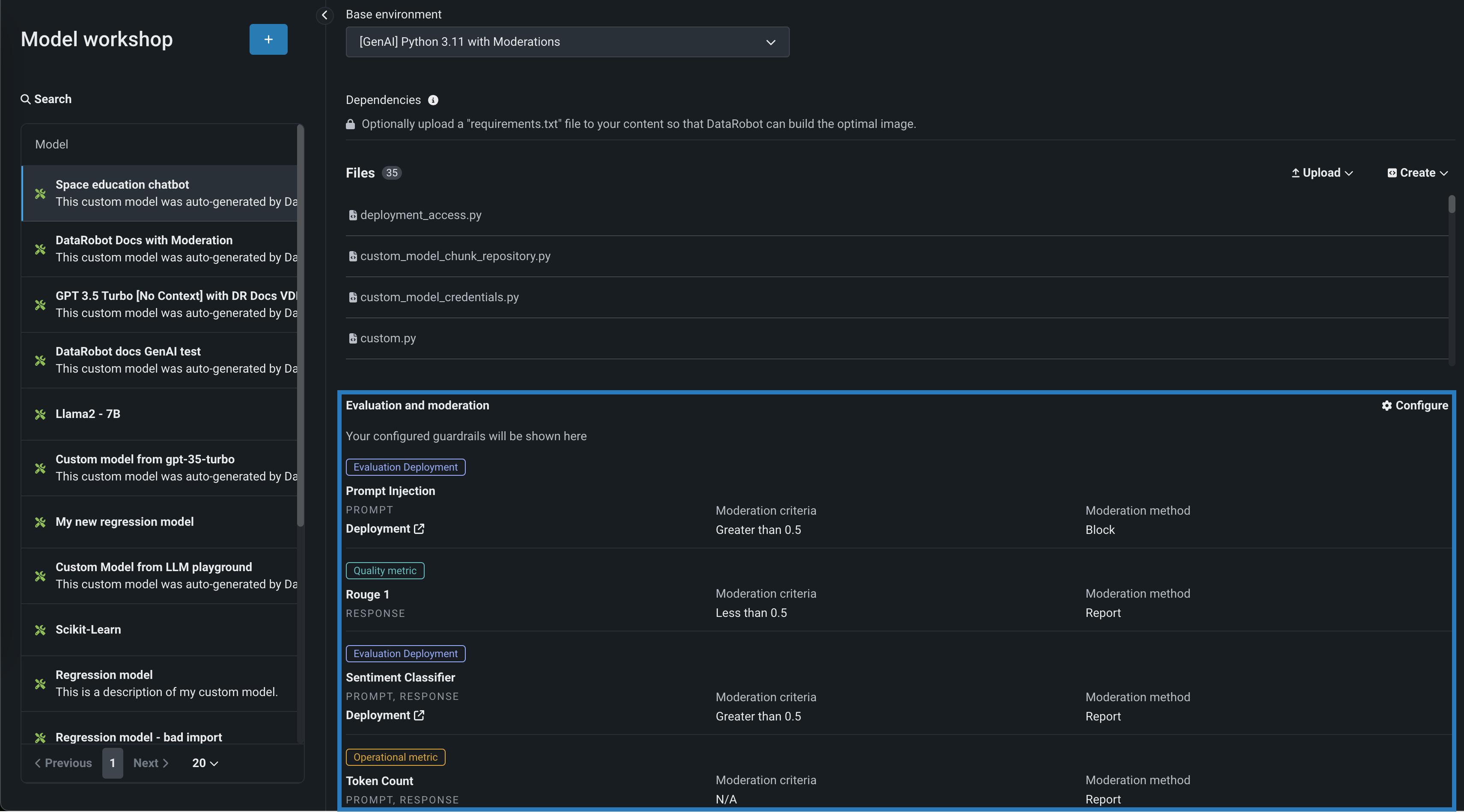
テキスト生成モデルの評価とモデレーション¶
評価とモデレーションのガードレールは、組織がプロンプトインジェクションや、悪意のある、有害な、または不適切なプロンプトや回答をブロックするのに役立ちます。 また、ハルシネーションや信頼性の低い回答を防ぎ、より一般的には、モデルをトピックに沿った状態に保つこともできます。 さらに、これらのガードレールは、個人を特定できる情報(PII)の共有を防ぐことができます。 多くの評価およびモデレーションガードレールは、デプロイされたテキスト生成モデル(LLM)をデプロイされたガードモデルに接続します。 これらのガードモデルはLLMのプロンプトと回答について予測し、これらの予測と統計を中心的なLLMデプロイに報告します。 評価とモデレーションのガードレールを使用するには、まず、LLMのプロンプトや回答について予測するガードモデルを作成してデプロイします。たとえば、ガードモデルは、プロンプトインジェクションや有害な回答を識別することができます。 次に、ターゲットタイプがテキスト生成のカスタムモデルを作成する場合、評価とモデレーションのガードレールを1つ以上定義します。 この機能は一般提供のプレミアム機能としてリリースされ、モデレーションのタイムアウトおよび評価とモデレーションのログに関する全般的な設定が導入されています。
デフォルトではオフの機能フラグ:モデレーションのガードレールを有効にする(プレミアム機能)、モデルレジストリでグローバルモデルを有効にする(プレミアム機能)、予測応答で追加のカスタムモデル出力を有効にする
詳しくはドキュメントをご覧ください。
NextGenコンソールでフィルターとモデル置換を改善¶
今回のNextGenコンソールのアップデートでは、デプロイのフィルターが改善され、モデル置換の操作性が一新されたことで、より直感的な置換ワークフローになりました。
コンソール > デプロイタブにおいて、自分が作成、タグ、およびモデルタイプ**でフィルターできるようになりました。
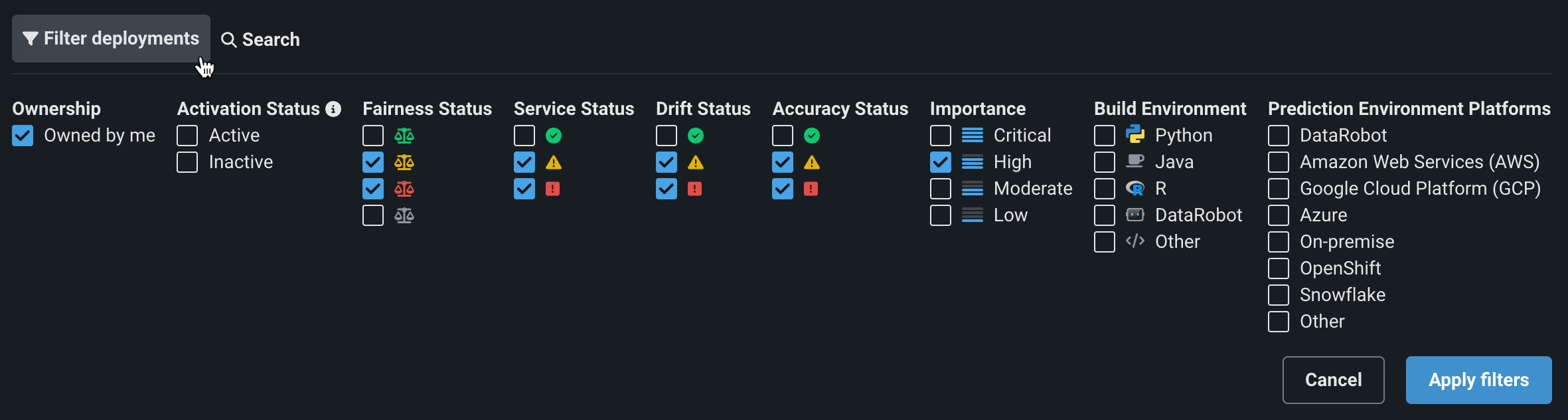
コンソール > デプロイタブ、またはデプロイの概要で、モデルのアクションメニューから、最新のモデル置換ワークフローにアクセスできます。

NextGenレジストリでカスタム実行環境を管理¶
NextGenレジストリに環境タブが提供されました。このタブでは、カスタムモデル、ジョブ、アプリケーション、ノートブックのカスタム実行環境を作成および管理できます。
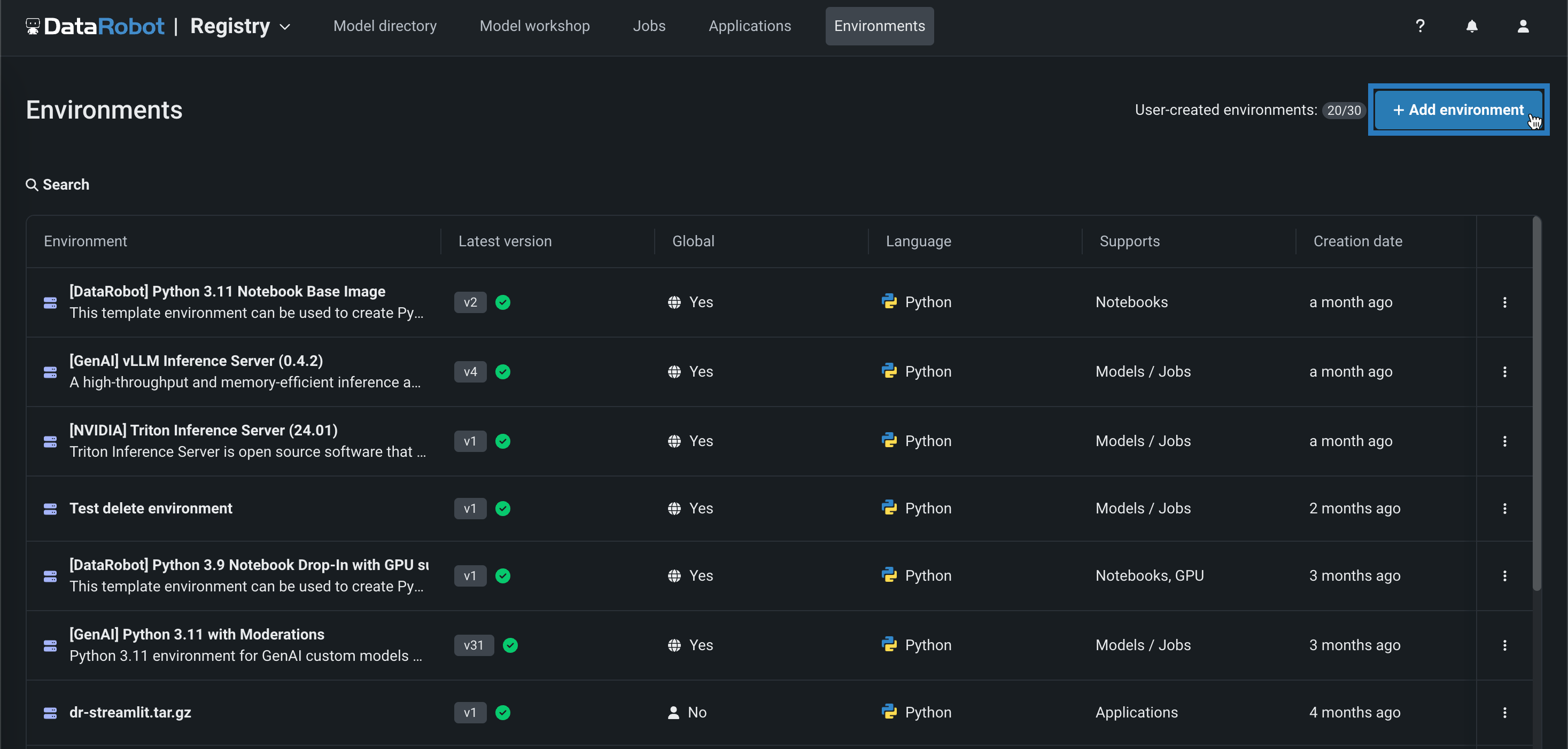
詳しくはドキュメントをご覧ください。
特徴量ドリフト追跡のカスタマイズ¶
デプロイの特徴量ドリフト追跡を有効にした場合、追跡対象として選択した特徴量をカスタマイズできるようになりました。 デプロイプロセス中またはその後に、デプロイ設定の特徴量ドリフトセクションで、特徴量の選択方法(自動的に25個の特徴量を選択する、または最大25個の特徴量を手動で選択する)を選択します。
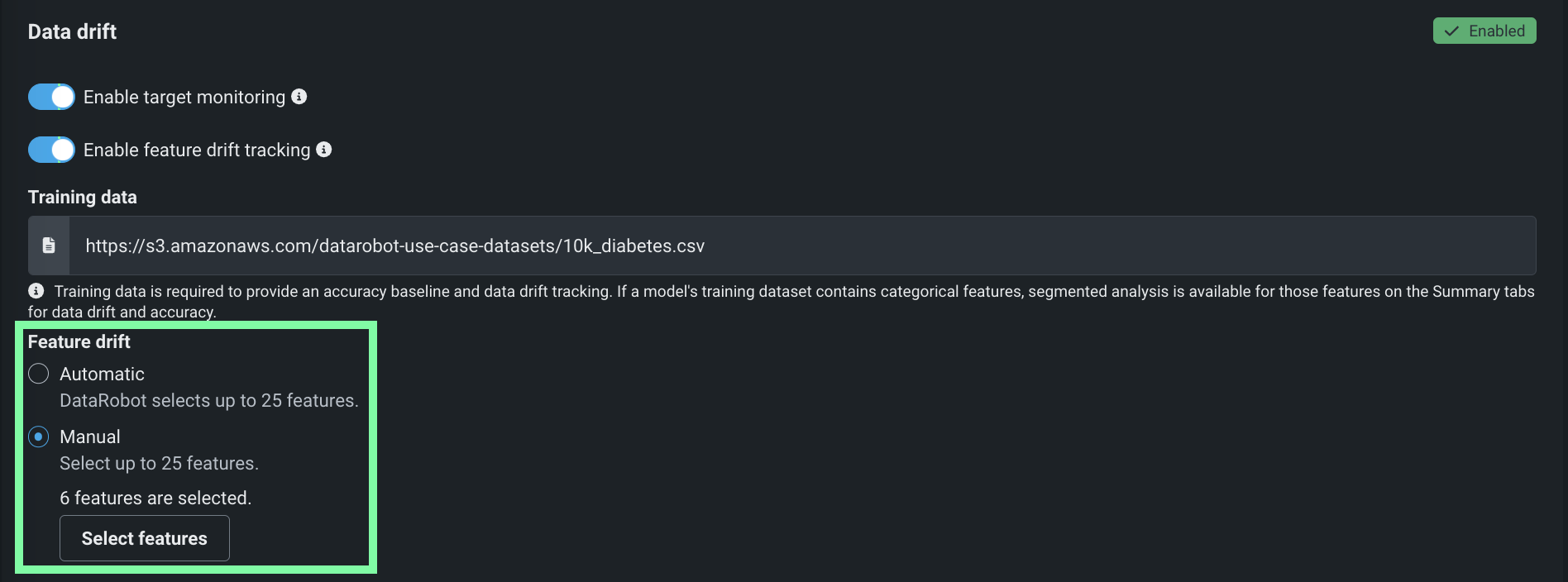

詳しくはドキュメントをご覧ください。
カスタムモデルの登録時にインサイトを計算¶
トレーニングデータが割り当てられたカスタムモデルでは、モデルのデプロイ時ではなく、モデルの登録時にモデルのインサイトと予測説明のプレビューが計算されるようになりました。 さらに、モデルワークショップからアクセスできる新しいモデルログは、インサイトの計算プロセス時のエラー診断に役立ちます。

詳しくはドキュメントをご覧ください。
レジストリとコンソールのアセットをユースケースにリンク¶
新しいユースケースリンク機能を使って、登録モデルのバージョン、モデルのデプロイ、カスタムアプリケーションをユースケースに関連付けます。 これらのアセットを既存のユースケースにリンクしたり、新しいユースケースを作成したり、リンクされたユースケースのリストを管理したりできます。



詳しくは、登録モデル、デプロイ、およびアプリケーションのリンクに関するドキュメントをご覧ください。
コードベースの再トレーニングジョブ¶
手動またはテンプレートから、コードベースの再トレーニングポリシーを実行するジョブを追加します。 再トレーニングジョブを表示および追加するには、ジョブ > 再トレーニングタブに移動し、以下の操作を行います。
-
新しい再トレーニングジョブを手動で追加するには、+ 新しい再トレーニングジョブを追加(またはジョブパネルが開いている場合は最小化された追加ボタン )をクリックします。
-
テンプレートから再トレーニングジョブを作成するには、追加ボタンの横にある をクリックし、再トレーニングの下にあるテンプレートから新規作成をクリックします。
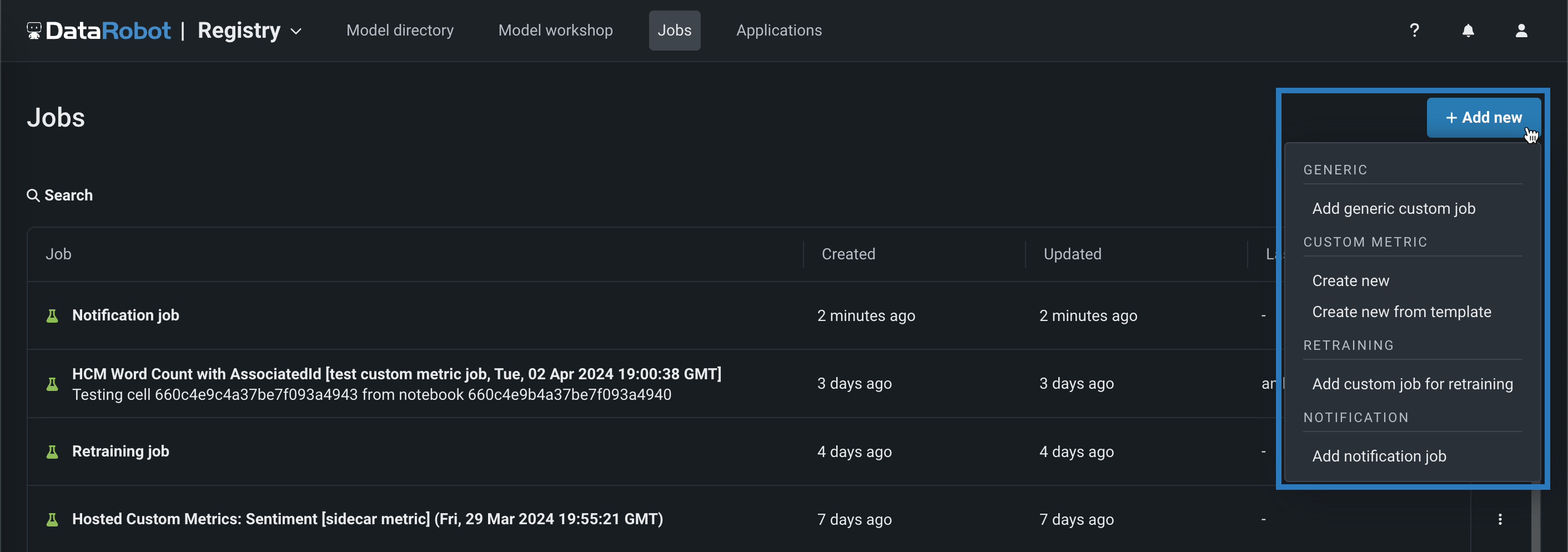
詳しくはドキュメントをご覧ください。
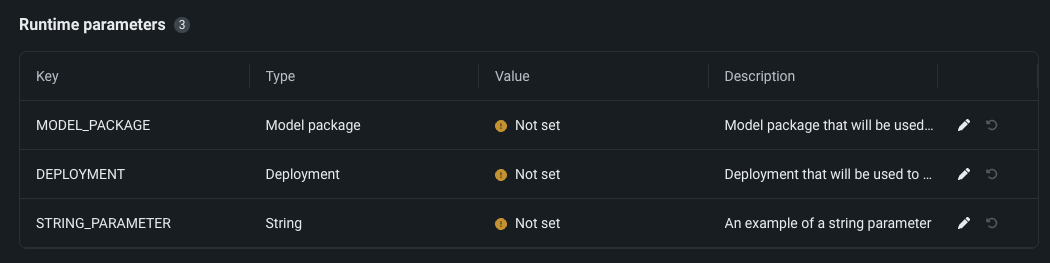
カスタムモデルのワーカーのランタイムパラメーター¶
カスタムモデルの設定に、DataRobotの新しい予約ランタイムパラメーターCUSTOM_MODEL_WORKERSを使用できます。 この数値ランタイムパラメーターにより、各レプリカは、設定された数の同時プロセスを処理できます。 このオプションは、主に生成AIのユースケースで、プロセスセーフなカスタムモデルを対象としています。
カスタムモデルプロセスの安全性
CUSTOM_MODEL_WORKERSを有効にして設定する場合、モデルがプロセスセーフであることを確認してください。 この設定オプションは、プロセスセーフなカスタムモデルのみを対象としています。リソース効率を向上させるためにカスタムモデルで一般的に使用するためのものではありません。 この方法でCPUリソースを利用するメリットがあるのは、I/Oバウンドタスクを持つプロセスセーフなカスタムモデル(プロキシモデルなど)だけです。
詳しくはドキュメントをご覧ください。
ノートブックとcodespaceでポート転送のサポートを一般提供¶
一般提供機能になりました。ノートブックとcodespaceでポート転送を有効にして、MLflowやStreamlitなどのツールやライブラリによって起動されるWebアプリケーションにアクセスできるようになりました。 ローカルで開発する場合、Webアプリケーションはhttp://localhost:PORTでアクセスできます。しかし、ホストされたDataRobot環境で開発する場合、Webアプリケーションにアクセスするには、そのアプリケーションが実行されている(セッションコンテナ内の)ポートを転送する必要があります。 1つのノートブックまたはcodespaceで、最大5つのポートを公開できます。

ノートブックでGPUのサポートを一般提供¶
マネージドAIプラットフォームにおいて、一般提供のプレミアム機能として、ノートブックおよびcodespaceセッションでのGPUのサポートを開始しました。 DataRobotでノートブックやcodespaceのセッションに環境を設定する際、リソースタイプのリストからGPUマシンを選択できます。 DataRobotには、セッションで使用するために選択でき、GPU向けに最適化された組み込み環境も用意されています。 これらの環境イメージには、必要なGPUドライバーに加え、TensorFlow、PyTorch、RAPIDSといった、GPUにより高速化されたパッケージが含まれています。
カスタムアプリケーションでランタイムパラメーターを一般提供¶
一般提供機能になりました。NextGenレジストリで、アプリケーションのソースにリソースとランタイムパラメーターを設定できます。 リソースバンドルは、本番環境での潜在的な環境エラーを最小限に抑えるために、アプリケーションが消費できるメモリーとCPUの最大量を決定します。 アプリケーションのソースから構築されたmetadata.yamlファイルに含めることで、カスタムアプリケーションで使用されるランタイムパラメーターを作成および定義できます。
テンプレートギャラリーからカスタムアプリケーションを構築¶
DataRobotには、カスタムアプリケーションの構築に使用できるテンプレートが用意されています。 これらのテンプレートにより、すぐに使える状態で構築済みのアプリケーションのフロントエンドを活用でき、豊富なカスタマイズオプションが提供されます すでにデプロイ済みのモデルを活用して、Streamlit、Flask、またはSlackアプリケーションをすばやく起動し、アクセスすることができます。 DataRobot内でカスタムコードを構築し実行するための簡単な方法として、カスタムアプリケーションテンプレートをご利用ください。

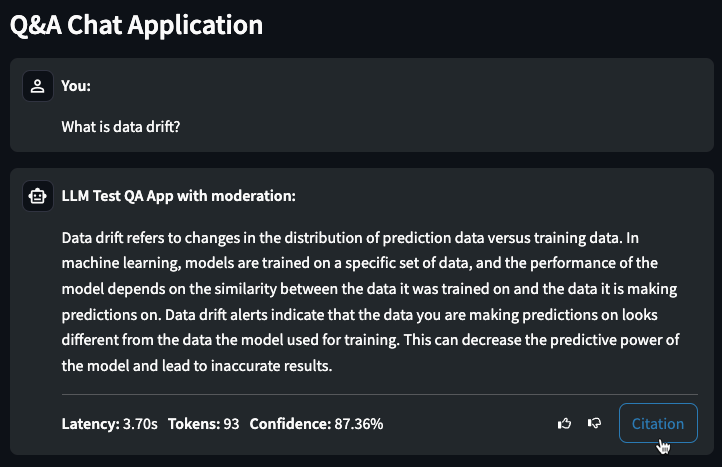
チャット生成Q&Aアプリケーションのサポートを一般提供¶
一般提供機能になりました。生成AIを活用してチャット生成Q&Aアプリケーションを作成できます。 Q&Aのユースケースを調べ、ビジネス上の意思決定を行い、ビジネス価値をアピールすることが可能です。 Q&Aアプリは、直感的かつ応答性に優れた方法で、構築したLLMモデルの結果をプロトタイプ化、調査、および共有できます。DataRobotのユーザー以外とも連携できるため、活用の場を広げることも可能です。
コードファーストのワークフローを使用して、チャット生成Q&Aアプリケーションを管理することもできます。 フローにアクセスするには、DataRobotのGitHubリポジトリに移動します。 このリポジトリには、アプリケーションコンポーネントのための変更可能なテンプレートが含まれています。
プレビュー¶
増分学習で動的データセットが利用可能に¶
Snowflake、BigQuery、またはDatabricksで用意したデータソースのデータなど、10GBを超える動的データセットでのモデリングが可能になりました。 エクスペリメントを設定するときは、順序付け特徴量を指定して、データセットから決定論的サンプルを作成し、その後は通常どおり増分モデリングを開始します。 モデルの構築が開始されると、選択した順序付け特徴量が「エクスペリメント情報を表示」で報告されます。
デフォルトではオンの機能フラグ:増分学習を有効にする、ワークベンチで動的データセットを有効にする、データのチャンキングサービスを有効にする
プレビュー機能のドキュメントをご覧ください。
カスタムジョブのテンプレートギャラリー¶
カスタムジョブテンプレートギャラリーは、カスタム指標ジョブに加えて、汎用、通知、再トレーニングのジョブタイプでも利用できるようになりました。 新しいテンプレートギャラリーにアクセスするには、レジストリ > ジョブタブで、任意のジョブタイプのテンプレートからジョブを作成します。
デフォルトではオンの機能フラグ:カスタムジョブのテンプレートギャラリーを有効にする
プレビュー機能のドキュメントをご覧ください。
ベクターデータベースの作成とデプロイ¶
モデルワークショップでベクターデータベースをターゲットタイプとすることで、他のカスタムモデルと同じように、ベクターデータベースを登録およびデプロイできます。

プレビュー機能のドキュメントをご覧ください。
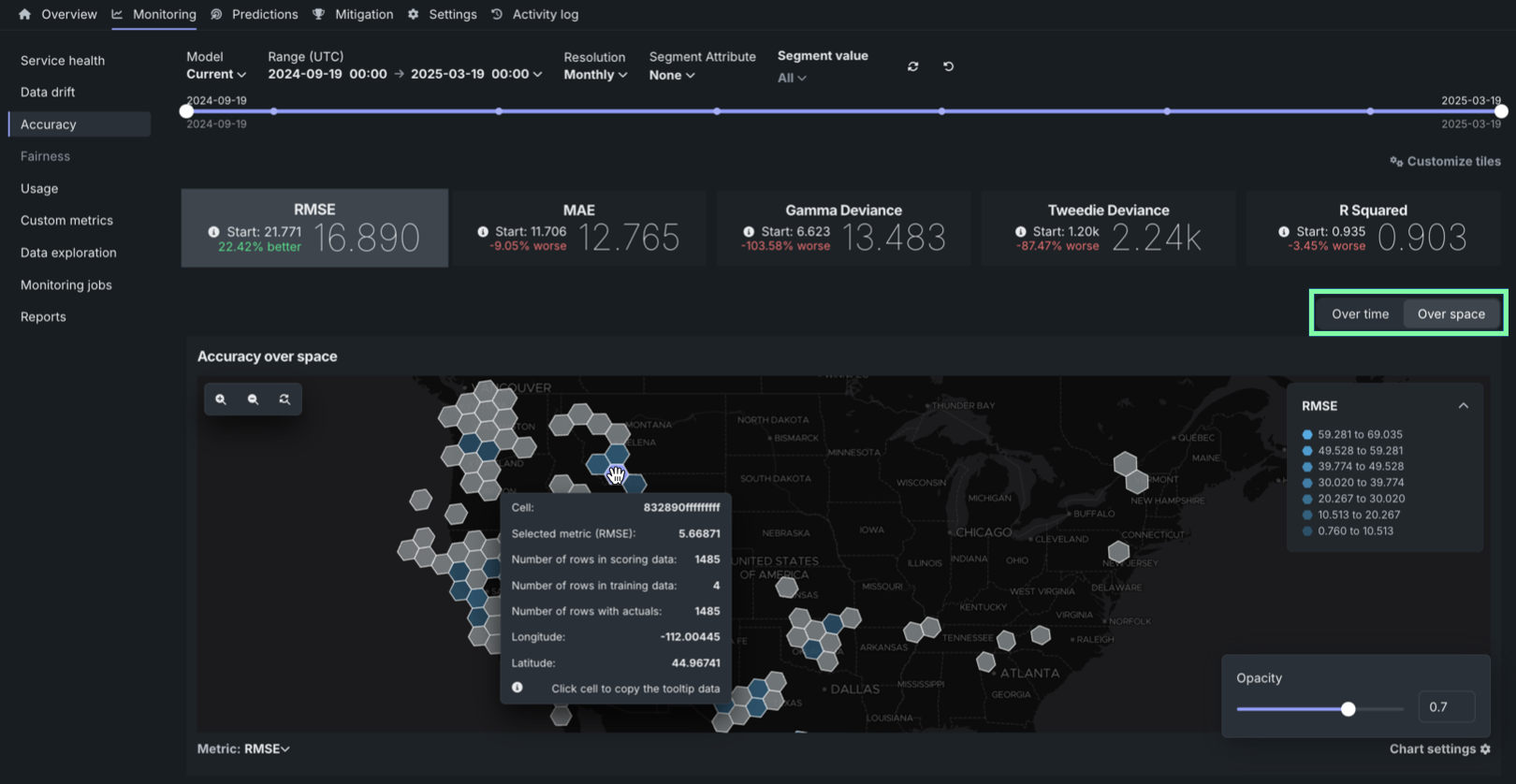
デプロイでの地理空間の監視¶
トレーニングデータセット内の位置データを使用して構築し、デプロイした二値分類、連続値、または多クラスモデルでは、DataRobotのLocation AIを活用して、デプロイのデータドリフトおよび精度タブで地理空間の監視ができるようになりました。 プロイで地理空間分析を有効にするには、セグメント化された分析を有効化し、位置データの取込み中に生成される位置特徴量geometryのセグメントを定義します。 geometryセグメントには、世界をH3セルのグリッドに分割する際に使われる識別子が含まれています。

デフォルトではオンの機能フラグ:地理空間特徴量の監視を有効にする、ワークベンチで特徴量探索を有効にする
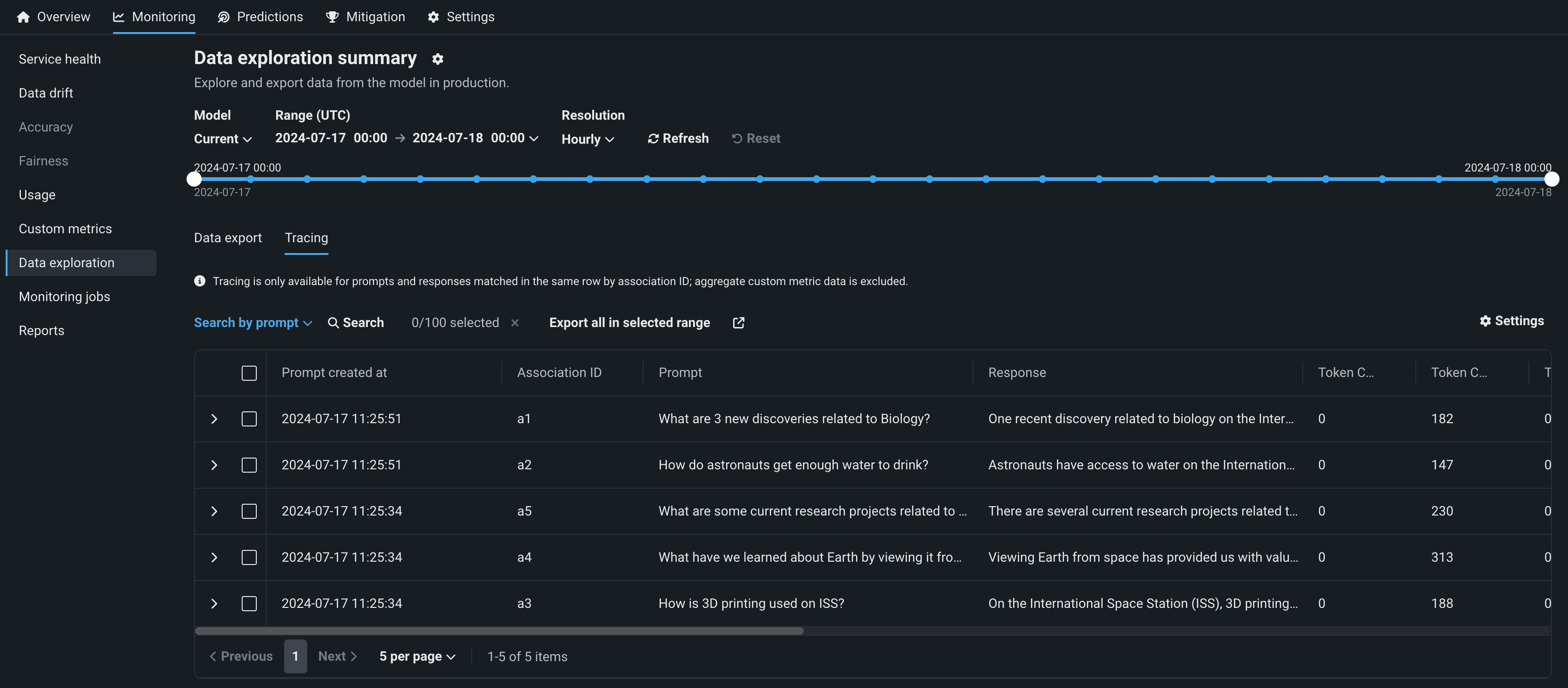
デプロイでのプロンプト監視の改善¶
デプロイされたテキスト生成モデルでは、モニタリング > データ探索タブのトレーステーブルに、追加のソートおよびフィルターオプションが含まれています。これにより、新たな方法で、生成AIデプロイの保存されたプロンプトおよび回答データを操作し、設定されたカスタム指標を通じてモデルのパフォーマンスに関するインサイトを得ることができます。 さらに、今回のリリースでは、コサイン類似度とユークリッド距離のカスタム指標テンプレートが導入されました。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:テキスト生成のターゲットタイプでデータ品質テーブルを有効にする(プレミアム機能)、生成モデルで実測値の保存を有効にする(プレミアム機能)
デフォルトではオンの機能フラグ:カスタムジョブのテンプレートギャラリーを有効にする
デプロイでの編集可能なリソース設定とランタイムパラメーター¶
デプロイされたカスタムモデルでは、カスタムモデルのCPU(またはGPU)リソースバンドルとカスタムモデルの構築時に定義されたランタイムパラメーターが、構築後に編集可能になりました。

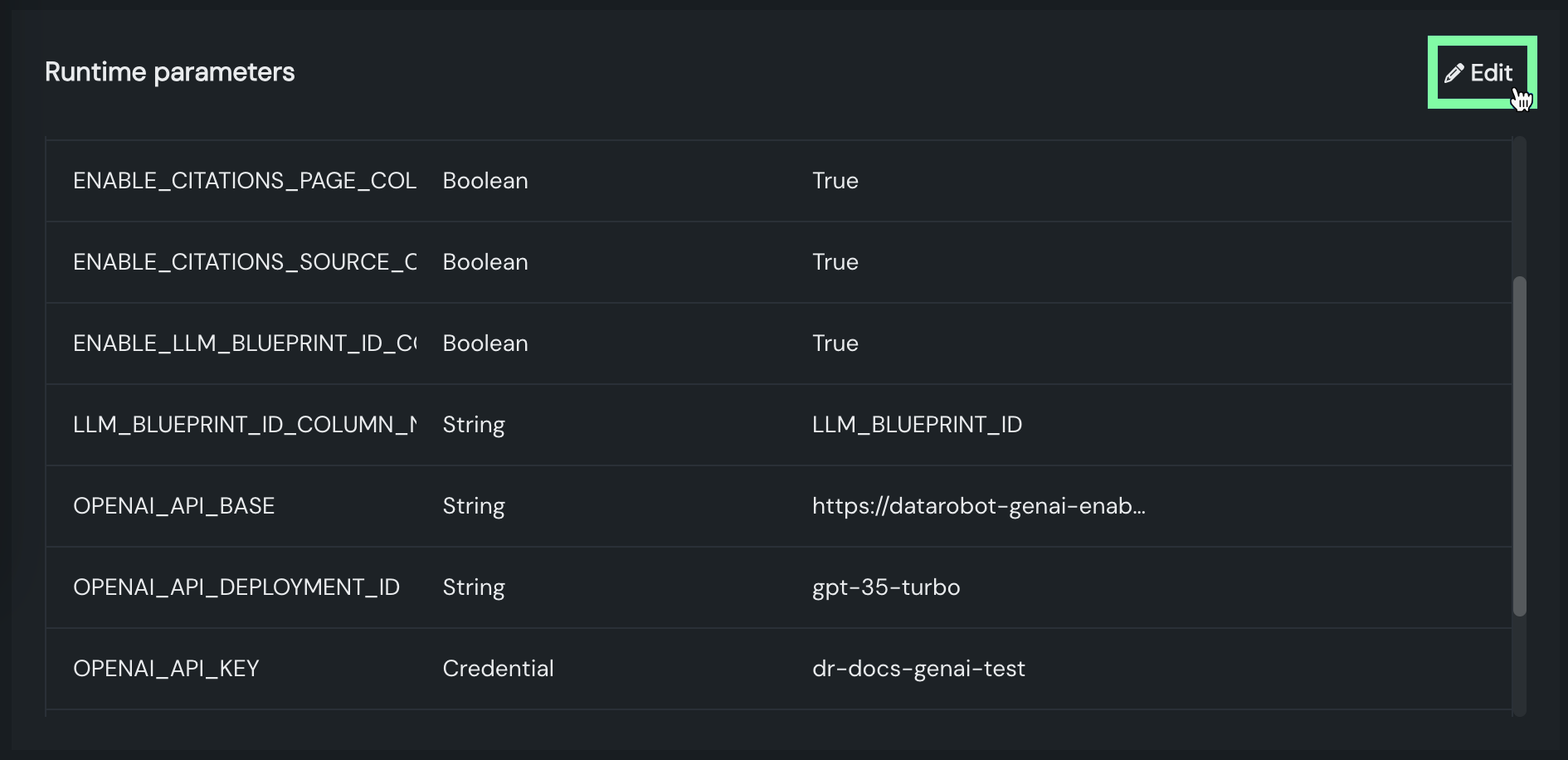
デフォルトではオンの機能フラグ:デプロイでカスタムモデルのランタイムパラメーターの編集を有効にする
デフォルトではオフの機能フラグ:リソースのバンドルを有効にする、カスタムモデルでGPUを使用した推論を有効にする(プレミアム機能)
データレジストリでのバッチ予測のためのラングリング¶
データレジストリからラングリングされたレシピでバッチ予測を行うには、デプロイの予測 > 予測を作成タブを使用します。 バッチ予測とは、大規模なデータセットで予測を行う方法で、入力データを渡すと各行の予測結果が得られます。 予測データセットボックスで、ファイルを選択 > ラングラーレシピをクリックし、データレジストリからレシピを選びます。
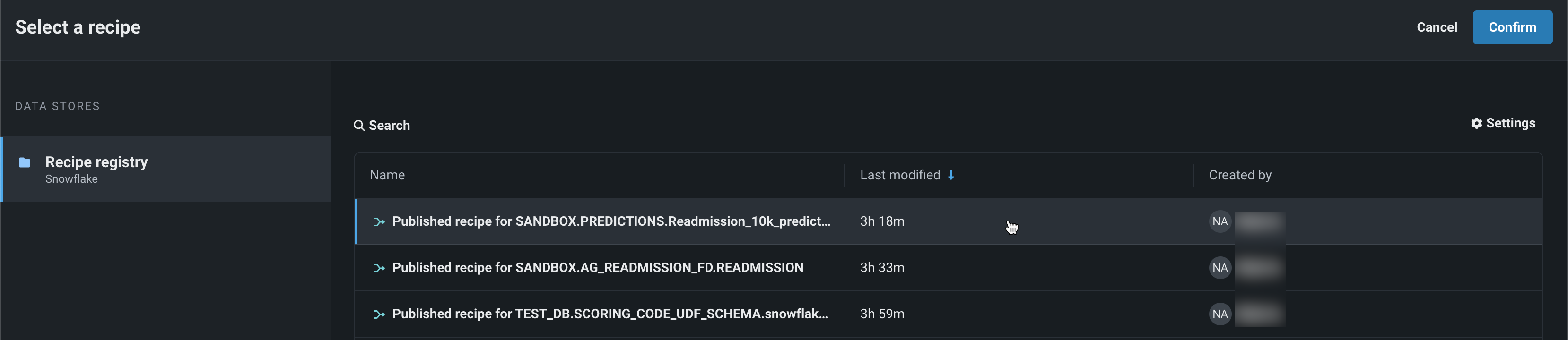
ワークベンチでの予測
データレジストリからラングリングされたレシピでのバッチ予測も、ワークベンチで利用できます。 デプロイ前のモデルで予測を行うには、エクスペリメントのモデルリストからモデルを選択し、モデルのアクション > 予測を作成をクリックします。
予測データの送信元と送信先を指定し、予測が実行されるタイミングを決定することで、バッチ予測ジョブをスケジュールすることもできます。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:データレジストリのデータセットでラングリングのプッシュダウンを有効にする
コードファースト¶
宣言型APIを使用してDataRobotのアセットをプロビジョニング¶
DataRobotの宣言型APIは、反復可能かつスケーラブルな方法でリソースをエンドツーエンドでプロビジョニングするためのコードファーストの方法として使用できます。 TerraformとPulumiの両方をサポートする宣言型APIを使って、モデル、デプロイ、アプリケーションなどのDataRobotエンティティをプログラムでプロビジョニングできます。 宣言型APIを使用すると、以下のことができます。
- インフラストラクチャの望ましい最終状態を指定することで、管理を簡単にし、クラウドプロバイダー間での適応性を高めることができます。
- DataRobotのアセットのプロビジョニングを自動化することで、環境間の整合性を確保し、実行順序に関する懸念を軽減できます。 TerraformとPulumiでは、プランと適用という2つの段階でプロビジョニングを行うことができます。 プロビジョニングアクションをコミットする前に、作成されるリソースの概要を示すプランを表示し、変更が行われたときに、お客様に代わってインフラストラクチャの依存関係を解決できます。 その後、プロビジョニングを個別に実行できます。 これにより、複雑なインフラストラクチャ内でのプロビジョニングの管理が容易になります。 変更がワークフローの下流にあるDataRobotアセットに与える影響をプレビューできます。
- バージョン管理を簡単にすることができます。
- アプリケーションテンプレートを使用することで、ワークフローの重複を減らし、一貫性を確保できます。
- DevOpsやCI/CDと連携することで、予測可能かつ一貫性のあるインフラストラクチャを確保し、デプロイのリスクを軽減できます。
宣言型APIを使用して、Pulumi CLIでDataRobotのリソースをプロビジョニングする方法の例を以下に示します。
import pulumi_datarobot as datarobot
import pulumi
import os
for var in [
"OPENAI_API_KEY",
"OPENAI_API_BASE",
"OPENAI_API_DEPLOYMENT_ID",
"OPENAI_API_VERSION",
]:
assert var in os.environ
pe = datarobot.PredictionEnvironment(
"pulumi_serverless_env", platform="datarobotServerless"
)
credential = datarobot.ApiTokenCredential(
"pulumi_credential", api_token=os.environ["OPENAI_API_KEY"]
)
cm = datarobot.CustomModel(
"pulumi_custom_model",
base_environment_id="65f9b27eab986d30d4c64268", # GenAI 3.11 w/ moderations
folder_path="model/",
runtime_parameter_values=[
{"key": "OPENAI_API_KEY", "type": "credential", "value": credential.id},
{
"key": "OPENAI_API_BASE",
"type": "string",
"value": os.environ["OPENAI_API_BASE"],
},
{
"key": "OPENAI_API_DEPLOYMENT_ID",
"type": "string",
"value": os.environ["OPENAI_API_DEPLOYMENT_ID"],
},
{
"key": "OPENAI_API_VERSION",
"type": "string",
"value": os.environ["OPENAI_API_VERSION"],
},
],
target_name="resultText",
target_type="TextGeneration",
)
rm = datarobot.RegisteredModel(
resource_name="pulumi_registered_model",
name=None,
custom_model_version_id=cm.version_id,
)
d = datarobot.Deployment(
"pulumi_deployment",
label="pulumi_deployment",
prediction_environment_id=pe.id,
registered_model_version_id=rm.version_id,
)
pulumi.export("deployment_id", d.id)