2023年3月¶
2023年3月22日
このページでは、新たにリリースされ、DataRobotのSaaS型シングル/マルチテナントAIプラットフォームで利用できる機能についてのお知らせと、追加情報へのリンクを掲載しています。 3月のデプロイにより、DataRobotのAIプラットフォームには、以下の一般提供およびプレビューの新機能が提供されました。 リリースセンターからは、次のものにもアクセスできます。
3月リリース¶
次の表は、新機能の一覧です。 過去の新機能のお知らせについては、デプロイ履歴をご覧ください。
目的別にグループ化された機能
| 名前 | 一般提供 | プレビュー |
|---|---|---|
| データ | ||
| ドライバーのバージョンを更新 | ✔ | |
| モデリング | ||
| クイックオートパイロットモードで特徴量セットの縮小が復活 | ✔ | |
| 時系列アプリケーションに詳細ページを追加 | ✔ | |
| AIアプリで予測件数の上限を引き上げ | ✔ | |
| 予測とMLOps | ||
| カスタムモデルのバージョンにトレーニングデータを割り当てる | ✔ | |
| APIの機能強化 | ||
| Pythonクライアントv3.1 | ✔ | |
一般提供¶
クイックオートパイロットモードで特徴量セットの縮小が復活¶
このリリースでは、クイックモードでのデプロイ用モデルの作成時に、縮小された特徴量セットが再び作成されるようになりました。 1月に、DataRobotは、 AutoMLのクイックモードの機能強化を行いました。2月に、 時系列プロジェクトで、改善が利用可能となりました。 当時、フィッティングにはモデルの再トレーニングが必要であったため、DataRobotによって数が削減された特徴量セットの生成とフィッティングが自動で行われなくなりました。 現在、ユーザーリクエストに基づいて、デプロイ用のモデルを推奨および準備するとき、DataRobotは、削減済み特徴量セットを再度作成します。 ただし、このプロセスにはモデルフィッティングは含まれません。 推奨モデルまたはリーダーボードモデルにリストを適用するには、手動で再トレーニング可能です。
時系列アプリケーションに詳細ページを追加¶
時系列予測ウィジェットで、特定の予測や日付に絞って予測情報を表示できるようになり、予測値を見るだけでなく、同じ日付に行われた他の予測との比較も可能になりました。
予測の詳細を見るには、予測値対実測値または予測の説明チャートで予測をクリックします。 これにより、予測の詳細ページが開き、以下の情報が表示されます。
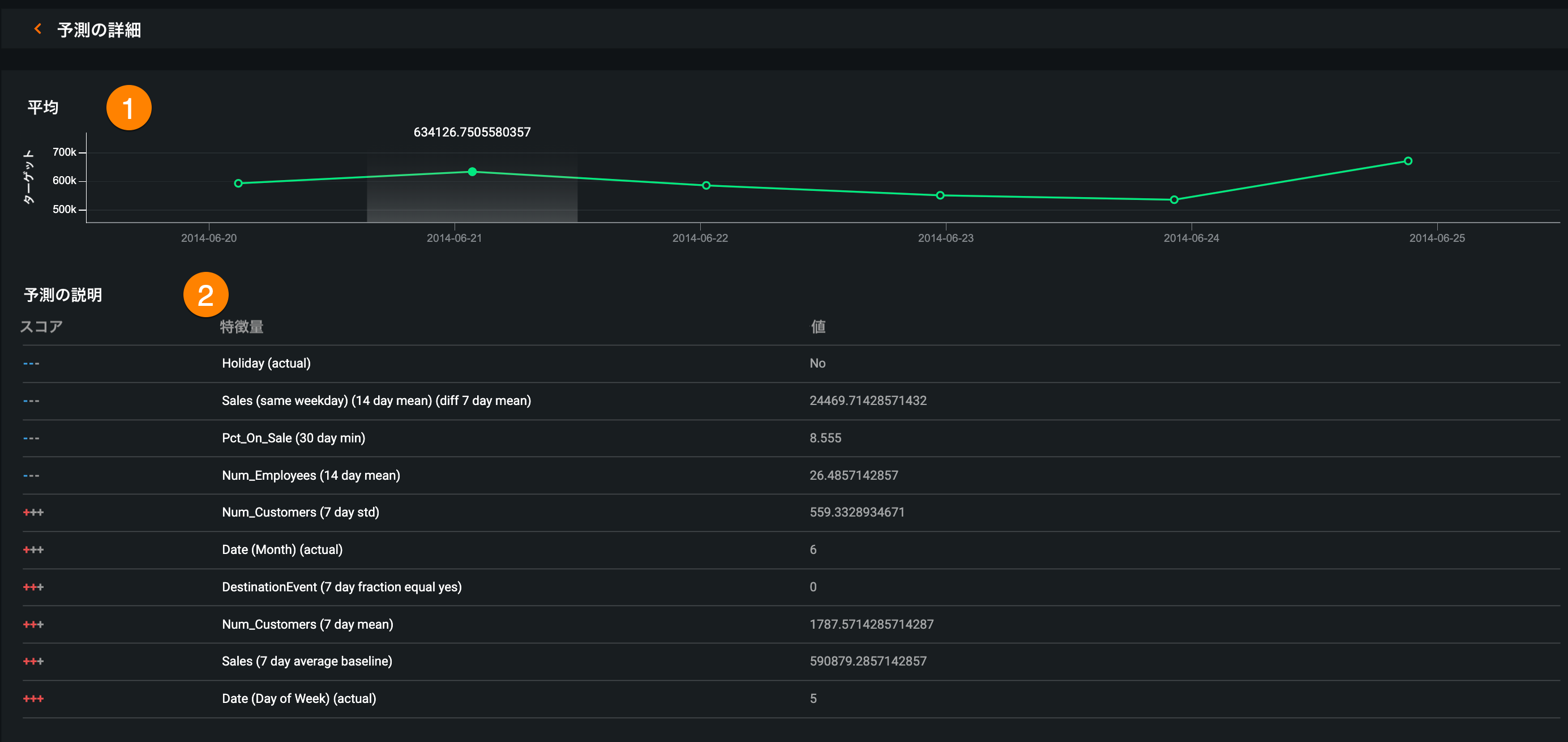
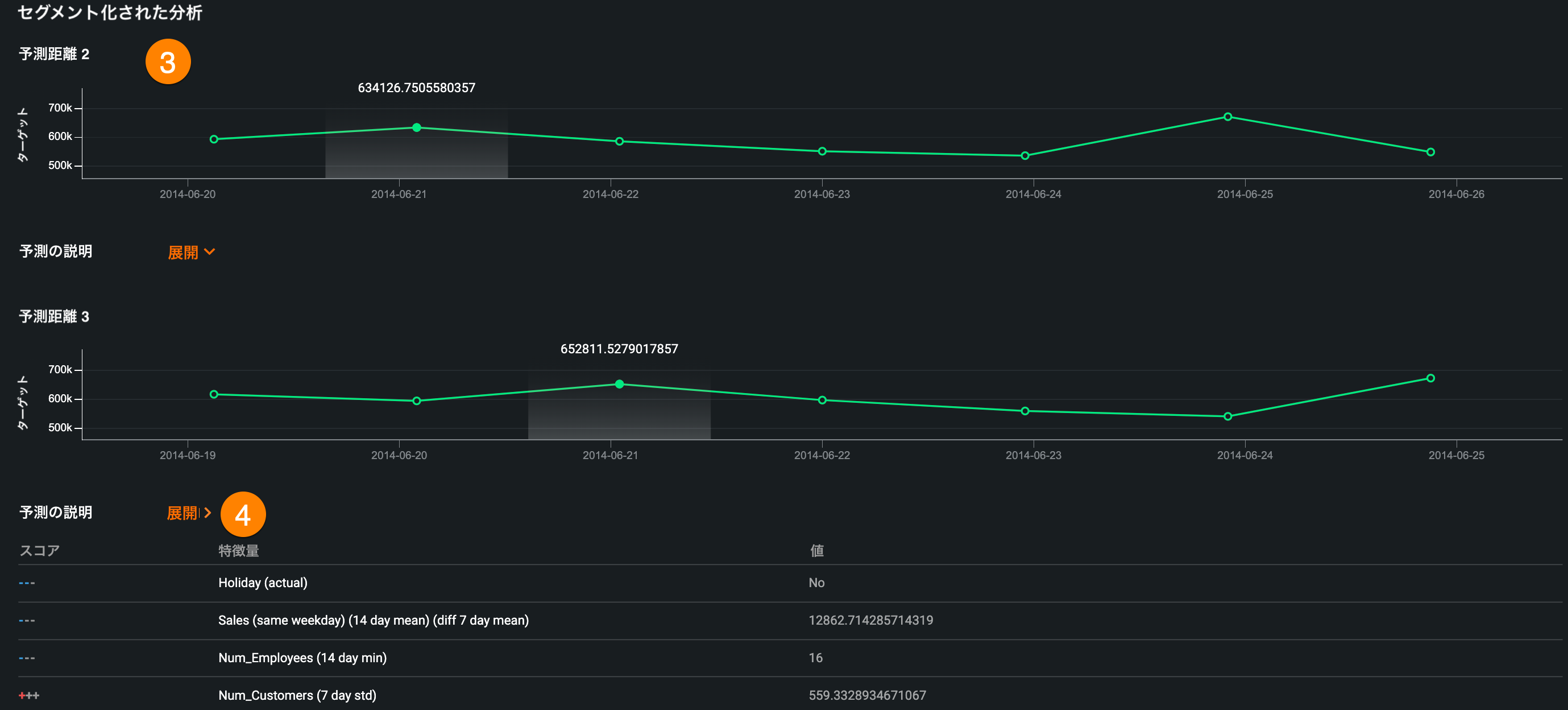
| 説明 | |
|---|---|
| 1 | 予測ウィンドウ内の平均予測値 |
| 2 | 各予測に対して最大10個の予測説明 |
| 3 | 予測ウィンドウ内の予測距離ごとのセグメント分析 |
| 4 | セグメント分析に含まれる、予測距離ごとの予測の説明 |
ドライバーのバージョンを更新¶
このリリースでは、以下のドライバーのバージョンが更新されました。
- AWS Athena==2.0.35
- SAP Hana==2.15.10
DataRobotで サポート済みドライバーバージョンの完全なリストを参照してください。
カスタムモデルのバージョンにトレーニングデータを割り当てる¶
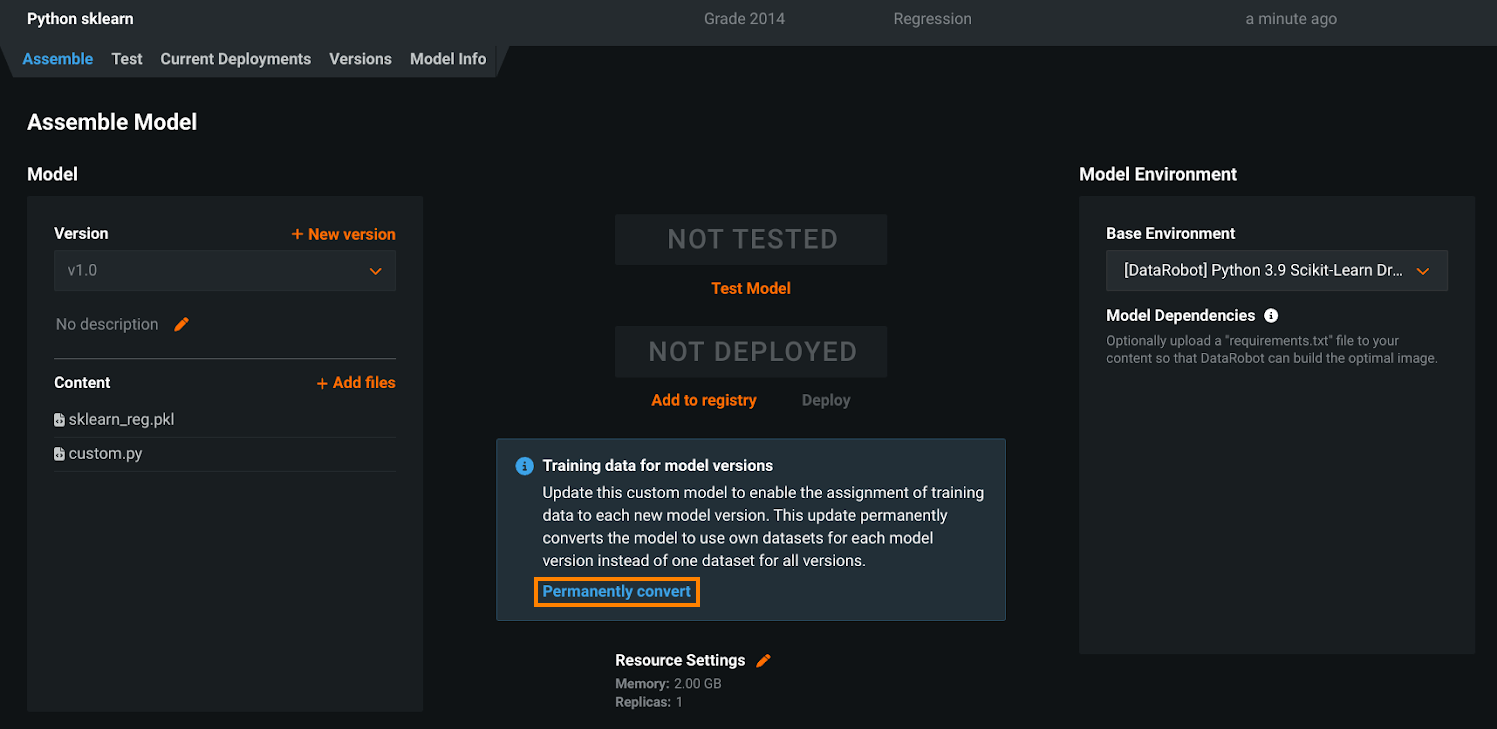
カスタムモデルのデプロイで特徴量ドリフトの追跡を有効にするには、トレーニングデータを追加する必要があります。 現在、トレーニングデータを追加すると、そのデータはカスタムモデルに直接割り当てられます。 その結果、そのモデルのすべてのバージョンで同じデータが使用されます。 このリリースでは、カスタムモデルへの直接のトレーニングデータ割り当ては、使用非推奨となり、削除が予定され、各カスタムモデルバージョンへのトレーニングデータ割り当てに置き換えられます。 下位互換性をサポートするために、使用非推奨トレーニングデータの割り当て方法は、新規作成されたモデルであっても、使用非推奨期間中のデフォルトのままとなります。
カスタムモデルのバージョンにトレーニングデータを割り当てるには、モデルを変換する必要があります。 アセンブルタブで、モデルバージョン用のトレーニングデータのアラートを見つけて、恒久的に変換をクリックします。
注意
モデルのトレーニングデータの割り当て方法を変更することは、一方向の操作です。 元に戻すことはできません。 変換後は、モデルレベルでトレーニングデータを割り当てることはできません。 この変更はUIおよびAPIに適用されます。 「モデルごと」 のトレーニングデータの割り当てに基づく自動化を組織内で行っている場合は、モデルを変換する前に、関連する自動化を更新して新しいワークフローをサポートする必要があります。 別の方法として、新しいカスタムモデルを作成して 「バージョンごと」 のトレーニングデータの割り当て方法に変更し、自動化に必要なモデルで使用非推奨の 「モデルごと」 の方法を維持することもできます。ただし、機能のギャップを避けるために、使用非推奨のプロセスが終了する前に自動化を更新する必要があります。
モデルを変換したら、カスタムモデルのバージョンにトレーニングデータを割り当てることができます。
-
モデルにトレーニングデータがすでに割り当てられている場合、データセットセクションには、既存のトレーニングデータセットに関する情報が含まれます。 既存のトレーニングデータを置き換えるには、編集アイコン(
 )をクリックします。 トレーニングデータを変更ダイアログボックスで、削除アイコン(
)をクリックします。 トレーニングデータを変更ダイアログボックスで、削除アイコン( )をクリックして既存のトレーニングデータを削除し、新しいトレーニングデータをアップロードします。
)をクリックして既存のトレーニングデータを削除し、新しいトレーニングデータをアップロードします。 -
モデルバージョンにトレーニングデータが割り当てられていない場合、割り当てをクリックし、トレーニングデータを追加ダイアログボックスで、トレーニングデータをアップロードします。
新しいカスタムモデルのバージョンを作成するときに、前のバージョンのトレーニングデータを保持することができます。 この設定は、デフォルトで有効化しており、トレーニングデータを、現在のバージョンから新規カスタムモデルバージョン移動します。
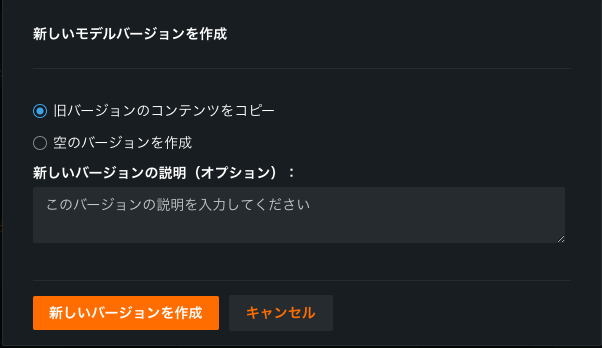
詳細については、カスタムモデルにトレーニングデータを追加するとカスタムモデルのバージョンを追加するを参照してください。
プレビュー¶
AIアプリで予測件数の上限を引き上げ¶
プレビュー版の機能です。1つのアプリケーションで最大5万件の予測が可能です。 以前は、フラグを有効化せずに、アプリケーションは5K予測のみをサポートしていました。 フラグの有無にかかわらず、残りの予測数を示すメッセージが表示されます。 制限は、個々のユーザーではなく、個々のアプリに適用されることに注意してください。 つまり、アプリを共有した場合、ユーザーが作成する予測は、残りの予測から差し引かれます。
必要な機能フラグ:予測行数の上限引き上げを有効にする
APIの機能強化¶
Pythonクライアントv3.1¶
DataRobotのPythonクライアントのバージョン3.1では、以下のAPIの機能が強化されました。
-
ファイルやデータセットに時系列データ準備を適用し、デプロイでバッチ予測を行う新しいメソッド
BatchPredictionJob.apply_time_series_data_prep_and_scoreとBatchPredictionJob.apply_time_series_data_prep_and_score_to_fileを追加しました。 -
ファイルまたはカタログデータセットに時系列データ準備を適用し、予測データセットをプロジェクトにアップロードする新しいメソッド
DataEngineQueryGenerator.prepare_prediction_datasetとDataEngineQueryGenerator.prepare_prediction_dataset_from_catalogを追加しました。 -
メソッド
Project.create_from_datasetに新しくmax_waitパラメーターを追加しました。 データセットからプロジェクトを作成する際、タイムアウトを避けるために、デフォルトより大きな値を指定することができます。 -
既存のクラスタリングプロジェクトとモデルからセグメントモデリングプロジェクトを作成するためのメソッド
Project.create_segmented_project_from_clustering_modelを追加しました。 これまでセグメントモデリングを目的としてModelPackageを使用していた場合は、この関数に切り替えてください。 -
クラスタリングまたは多クラスのパラメーターが使用されているかどうかをチェックするメソッド
is_unsupervised_clustering_or_multiclassを追加しました。 API呼び出しを追加することなく、すばやく効率的に実行できます。 -
RECOMMENDED_MODEL_TYPE列挙型にPREPARED_FOR_DEPLOYMENTを追加しました。 -
ImageAugmentationListクラスに2つの新しいメソッドImageAugmentationList.listとImageAugmentationList.updateを追加しました。 -
S3、GCP、Azureでのバッチ予測の入出力設定に
formatキーを追加しました。 -
メソッド
PredictionExplanations.is_multiclassに、多クラスターゲットの有効性をチェックするためのAPIコールを追加しました。それにより、処理時間がわずかに長くなります。 -
AdvancedOptionsのパラメーターblend_best_modelsのデフォルトはFalseになりました。 -
AdvancedOptions <datarobot.helpers.AdvancedOptions>のパラメーターconsider_blenders_in_recommendationのデフォルトはFalseになりました。 -
DatetimePartitioningにパラメーターunsupervised_modeを追加しました。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。