2023年6月¶
2023年6月28日
今回のデプロイにより、DataRobotのAIプラットフォームには、以下の一般提供およびプレビューの新機能が提供されました。 リリースセンターからは、次のものにもアクセスできます。
注目の新機能¶
Text AIの基本モデル¶
このデプロイでは、Text AIの基本モデルが一般提供されました。 基本モデル(膨大な量のラベルなしデータで大規模にトレーニングされた大きなAIモデル)は、高い精度と多様性を提供し、事前にトレーニングされた大規模なディープラーニング手法をText AIに活用することができます。
DataRobotはすでにTinyBERTのようないくつかの基本モデルを実装していますが、これらのモデルは単語レベルで動作するため、追加の計算が発生します(テキスト行の変換には、各トークンの埋め込みを計算し、そのベクトルを平均化する必要があります)。 これらの新しいモデル(英語用のSentence Robertaと多言語ユースケース用のMiniLM)は、幅広い下流タスクに適応させることができます。 これら2つの基本モデルは、リポジトリ内の構築済みブループリントで利用可能です。または、これらの基本モデルを活用して精度を向上させることを目的として、カスタマイズされた(埋め込まれた)任意のブループリントに追加することもできます。
新しいブループリントは、リポジトリで入手できます。
ワークベンチの一般提供を開始¶
今月のデプロイでは、DataRobotのエクスペリメントプラットフォームであるワークベンチが、プレビューから一般提供に移行しました。 ワークベンチは、直感的に操作できる、ガイド付きの機械学習ワークフローを提供して、エクスペリメントと反復作業を支援し、スムーズなコラボレーション環境を実現します。 今月は、ワークベンチが一般提供されただけでなく、新たなプレビュー機能が導入されました。
ワークベンチとDataRobot Classicで使用可能な機能の比較については、機能マトリックス(2025年1月をもって更新終了)を参照してください。
6月リリース¶
次の表は、新機能の一覧です。
目的別にグループ化された機能
| 名前 | 一般提供 | プレビュー |
|---|---|---|
| 管理 | ||
| カスタムロールベースのアクセス制御(RBAC) | ✔ | |
| アプリケーション | ||
| ワークベンチでの新しいアプリ体験 | ✔ | |
| 事前入力済みのアプリケーションテンプレート | ✔ | |
| DataRobotモデルでのStreamlitアプリケーションの構築 | ✔ | |
| データ | ||
| セキュアな構成の共有 | ✔ | |
| ドライバーのバージョンを更新 | ✔ | |
| モデリング | ||
| Text AI Sentence Featurizerの基本モデル | ✔ | |
| カスタムタスクでのハイパーパラメーターのチューニング | ✔ | |
| 一般提供(GA)リリースでのデータスライスのサポート拡大と新機能 | ✔ | |
| XEMPベースの予測の説明での計算を改善 | ✔ | |
| Document AIがPDFドキュメントに対応 | ✔ | |
| GPUがディープラーニングに対応 | ✔ | |
| ブループリントリポジトリとブループリントの視覚化 | ✔ | |
| ワークベンチのスライス | ✔ | |
| 時間認識プロジェクトのスライス(Classic) | ✔ | |
| Notebooks | ||
| DataRobot Notebooks | ✔ | |
| 予測とMLOps | ||
| カスタムモデルのためのGitHub Actions | ✔ | |
| 予測の監視ジョブ | ✔ | |
| スコアリングコード用のSpark API | ✔ | |
| キー値でコンプライアンスドキュメントを拡張する | ✔ | |
| API | ||
| DataRobotX | ✔ | |
一般提供¶
セキュアな構成の共有¶
IT管理者は、データ接続にOAuthベースの認証パラメーターを設定し、機微情報に関するフィールドを公開することなく、他のユーザーと安全に共有できるようになりました。 これにより、ユーザーは、データ接続パラメーターについてIT部門に連絡することなく、データウェアハウスに簡単に接続できます。
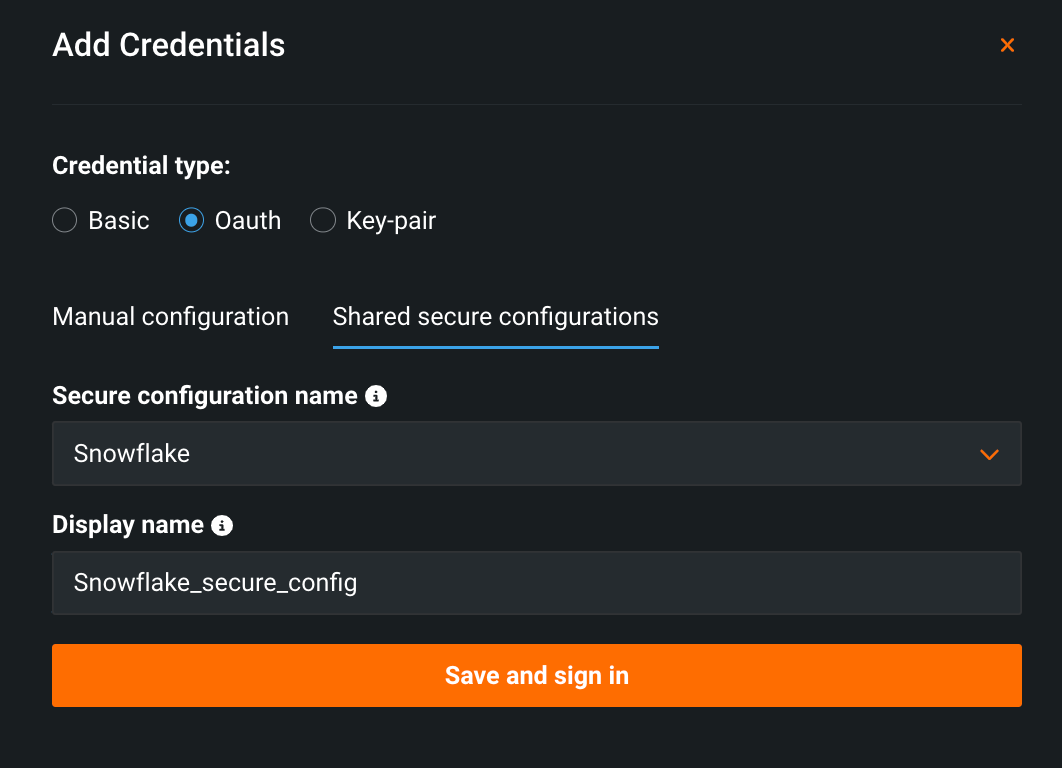
詳しくは、完全なドキュメントをご覧ください。
カスタムロールベースのアクセス制御(RBAC)¶
一般提供機能になりました。カスタムRBACは、DataRobotのデフォルトのロールでは対応できないユースケースを持つ組織向けのソリューションです。 管理者は、より詳細なレベルでロールを作成してアクセス権を定義し、ユーザーやグループに割り当てることができます。
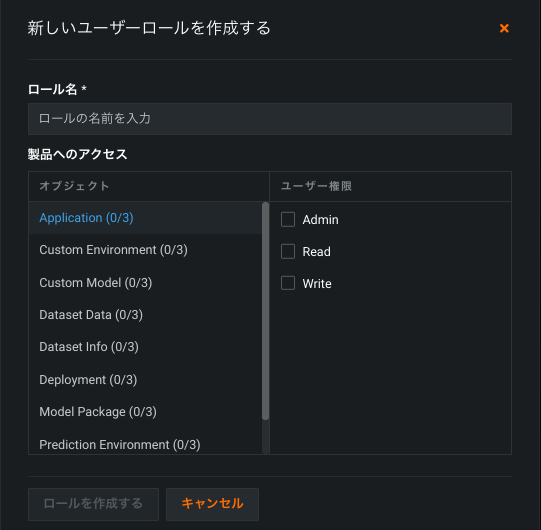
ユーザー設定 > ユーザーロールからカスタムRBACにアクセスできます。ここには、DataRobotのデフォルトのロールなど、管理者が組織内のユーザーに割り当てることができる利用可能な各ロールが一覧表示されます。
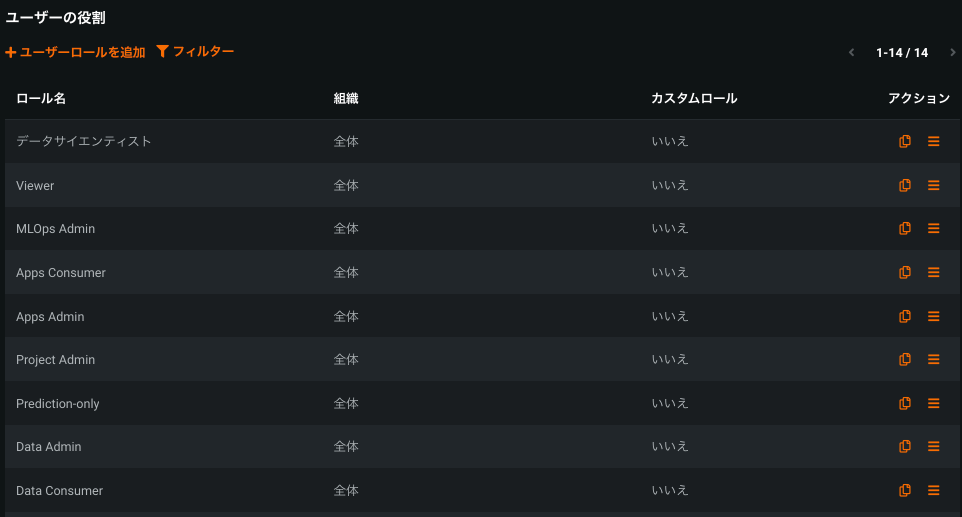
詳しくは、完全なドキュメントをご覧ください。
ドライバーのバージョンを更新¶
このリリースでは、以下のドライバーのバージョンが更新されました。
- MySQL==8.0.32
- Microsoft SQL Server==12.2.0
- Snowflake==3.13.29
DataRobotで サポート済みドライバーバージョンの完全なリストを参照してください。
カスタムモデルのためのGitHub Actions¶
一般提供機能になりました。カスタムモデルアクションは、GitHubのCI/CDワークフローを通じて、DataRobotのカスタム推論モデルとそれに関連するデプロイを管理します。 これらのワークフローでは、モデルやデプロイを作成または削除したり、設定を変更したりできます。 YAMLファイルで定義されたメタデータにより、カスタムモデルのアクションによるモデルとデプロイの制御が可能になります。 このアクションのほとんどのYAMLファイルは、カスタムモデルのリポジトリ内の任意のフォルダーに配置できます。 YAMLは、これらのワークフローで使用されるエンティティが含まれているかどうかを判断するために、検索、収集、スキーマに対するテストが行われます。 詳細については、 custom-models-actionリポジトリを参照してください。
クイックスタートの例では、 datarobot-user-modelリポジトリからの Python Scikit-Learnモデルテンプレートを使用します。 ワークフローを設定し、DataRobotでモデルとデプロイを作成した後、モデルのバージョン情報とパッケージ情報、およびデプロイの概要からコミット情報にアクセスできます。
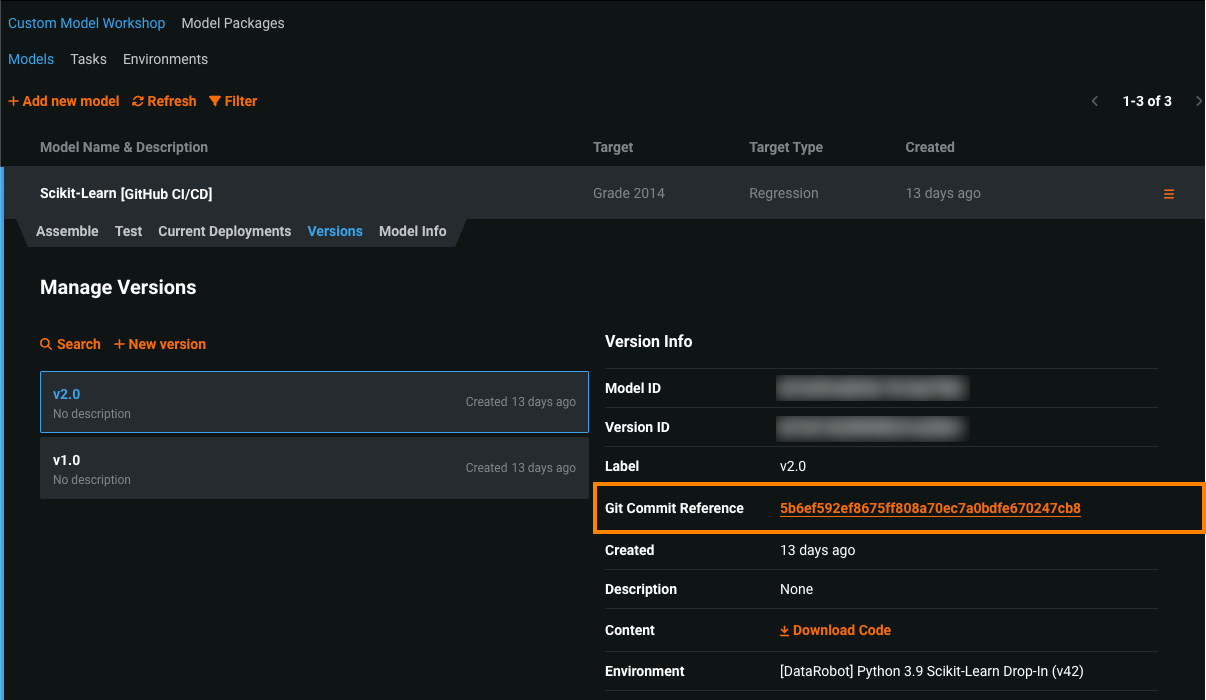
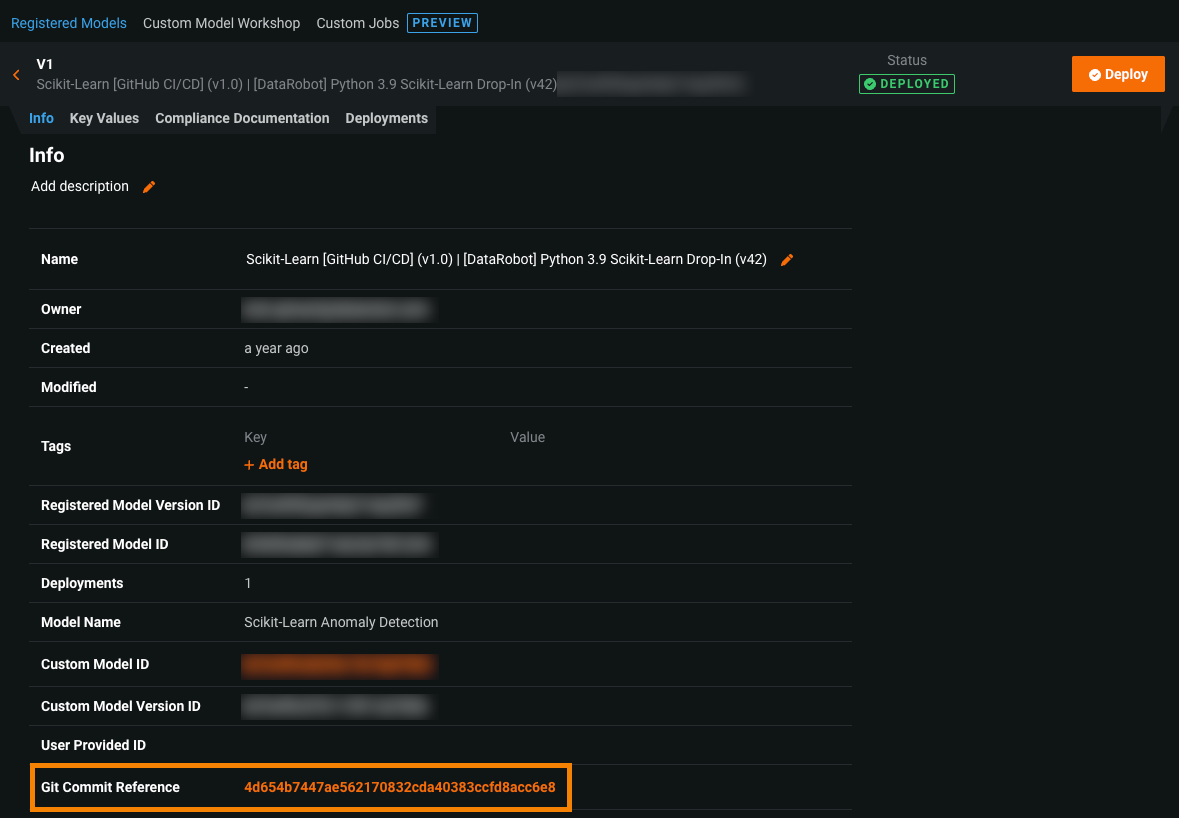
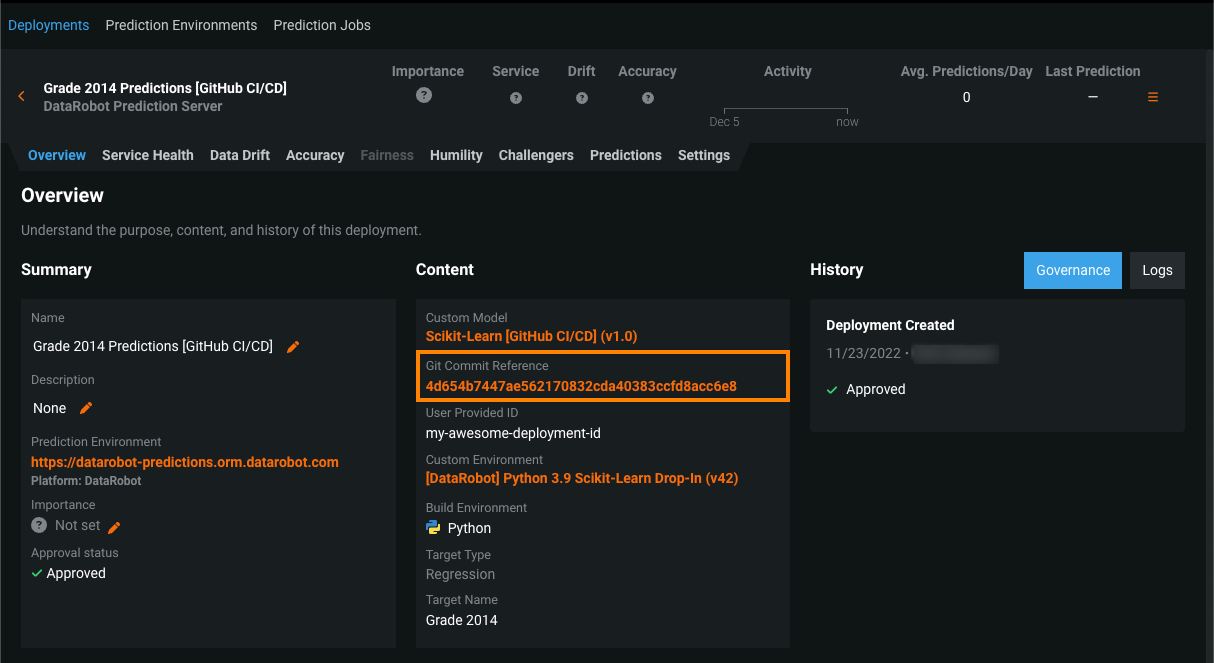
詳細については、カスタムモデルのためのGitHub Actionsを参照してください。
予測の監視ジョブ¶
一般提供機能になりました。監視ジョブの定義により、DataRobotの外部で実行されているデプロイを監視し、特徴量データ、予測値、実測値を保存することができます。 たとえば、Snowflakeに接続して、関連するSnowflakeテーブルから元データを取得し、監視目的でDataRobotにデータを送信する監視ジョブを作成することができます。 この機能の一般提供版では、大規模監視が有効な外部モデルに対して、予測監視ジョブ専用のAPIと集計使用機能を提供します。
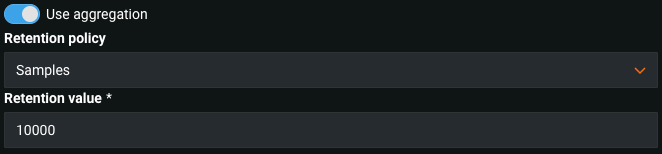
詳しくは、予測の監視ジョブをご覧ください。
スコアリングコード用のSpark API¶
スコアリングコード用のSpark APIライブラリは、DataRobotのスコアリングコードJARをSparkクラスターに統合します。 これにより、定型コードを記述したり、クラスパスに追加の依存関係を含めたりすることなく、PySparkとSpark Scalaでスコアリングコードを簡単に使用できるようになり、同時にAPIを介したスコアリングとデータ転送のパフォーマンスも向上しました。
このライブラリはPySpark APIおよびSpark Scala APIとして提供されています。 以前のバージョンでは、スコアリングコード用のSpark APIは、複数のライブラリで構成され、それぞれが特異なSparkバージョンをサポートしていました。 これからは、サポートされているすべてのSparkバージョンが1つのライブラリに含まれます。
-
スコアリングコード用のPySpark APIは、PyPIでリリースされた
datarobot-predictPythonパッケージに含まれています。 PyPIプロジェクトの説明には、ドキュメントと使用例が含まれています。 -
スコアリングコード用のSpark Scala APIはMavenで
scoring-code-spark-apiとして公開されており、APIリファレンスに説明があります。
詳しくは、スコアリングコード用のApache Spark APIをご覧ください。
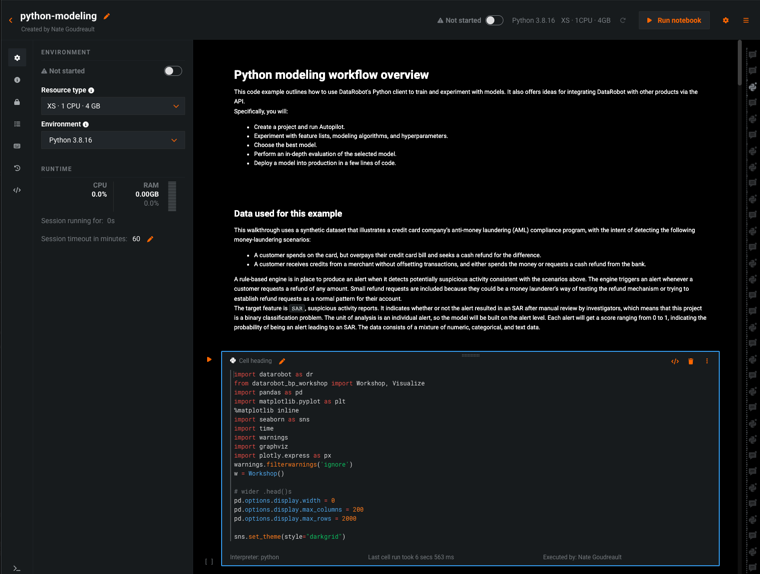
DataRobot Notebooks¶
一般提供機能になりました。DataRobotには、データサイエンス分析やモデリング用のノートブックを作成・実行するためのブラウザー内エディターが含まれています。 Notebooksでは、計算結果をテキスト、画像、グラフ、プロット、表など、さまざまな形式で表示することができます。 オープンソースのプラグインを使用することで、出力表示をカスタマイズできます。 セルには、コーディングワークフローの注釈や説明のためのマークダウンリッチテキストを含めることもできます。 DataRobotでは、ノートブックを作成・編集すると、変更履歴が保存されるため、いつでも戻ることができます。
DataRobot Notebooksには、ノートブックの作成、アップロード、管理をホストするダッシュボードが用意されています。 個々のノートブックには、よく使われる機械学習ライブラリを備えた、コンテナ化された環境が組み込まれているため、数回のクリックで簡単に設定できます。 ノートブック環境はDataRobotのAPIとシームレスに統合され、セル関数のキーボードショートカット、インラインドキュメント、シークレット管理と自動認証のために保存された環境変数を利用できる、堅牢なコーディングエクスペリエンスを提供します。
一般提供(GA)リリースでのデータスライスのサポート拡大と新機能¶
データスライスを使用すると、カテゴリー、数値、またはその両方の型の特徴量に対してフィルターを定義できます。 プロジェクトのデータセグメントに基づいてインサイトを表示および比較すると、さまざまな部分母集団に対してモデルがどのように機能するかを理解できます。これを行うには、特徴量を選択し、演算子と値を設定して返されるデータを絞り込むフィルターを設定します。 一般提供リリースの一環として、改善をいくつか加えました。
- 特徴量ごとの作用がスライスに対応しました。
- クイックコンピューティングオプションは、特徴量のインパクトでサンプルサイズを設定するためのサンプルサイズモーダルに代わるものです。
- 手動によるスライス計算を開始すると、まずスライスの検証が行われるため、演算処理が誤って開始されることはありません。
XEMPベースの予測の説明での計算を改善¶
5月にバージョン0.23.4から1.3.5にPandasライブラリがアップグレードされたことで、DataRobotでのXEMP予測の説明の計算方法が改善されました。 新しいライブラリでは、新しいバージョンのPandasでの精度向上による計算の違いが、インサイトの精度向上につながっています。
プレビュー¶
Document AIがPDFドキュメントをデータソースとしてサポート¶
Document AIは、手作業が多いデータ準備手順を増やさずに、未処理のPDFドキュメントでモデルを構築する方法を提供します。 Document AIが登場するまでは、データ準備の要件が、ドキュメントをデータソースとして効率的に利用する上で困難な障壁となっていました。膨大なコーパスに分散している情報や、一貫性のない多様なフォーマットが原因で、ドキュメントを利用できないことさえありました。 Document AIによって、データを準備する際のドキュメントの処理が楽になるだけではありません。DataRobotは、リーダーボード上のモデルの比較、モデルの説明可能性、ブループリントのフルリポジトリへのアクセスなど、データソースとしてドキュメントに依存するプロジェクトに自動化をもたらします。
ユーザーが選択できる2つの新しいタスクがモデルブループリントに追加されたことで、DataRobotは(Document Text Extractorタスクで)埋め込みテキストを抽出するか、(Tesseract OCRタスクで)スキャンテキストを抽出して、モデル構築にPDFテキストを使用できるようになりました。 DataRobotはプロジェクトに基づいて自動的にタスクのタイプを選択しますが、必要に応じてそのタスクを柔軟に変更することができます。 Document AIは、連続値、二値および多クラス分類、多ラベル、クラスタリング、異常検知など、多くのプロジェクトタイプで使用できますが、単一のブループリント内でテキスト、画像、数値、カテゴリーなどのマルチモーダルサポートも提供します。
ドキュメントのテキスト要素の独自の性質を確認および理解できるように、DataRobotではドキュメントインサイトの視覚化が導入されています。 DataRobotがドキュメントから抽出した情報と、正しいタスクを選択したかどうかをダブルチェックするのに便利です。
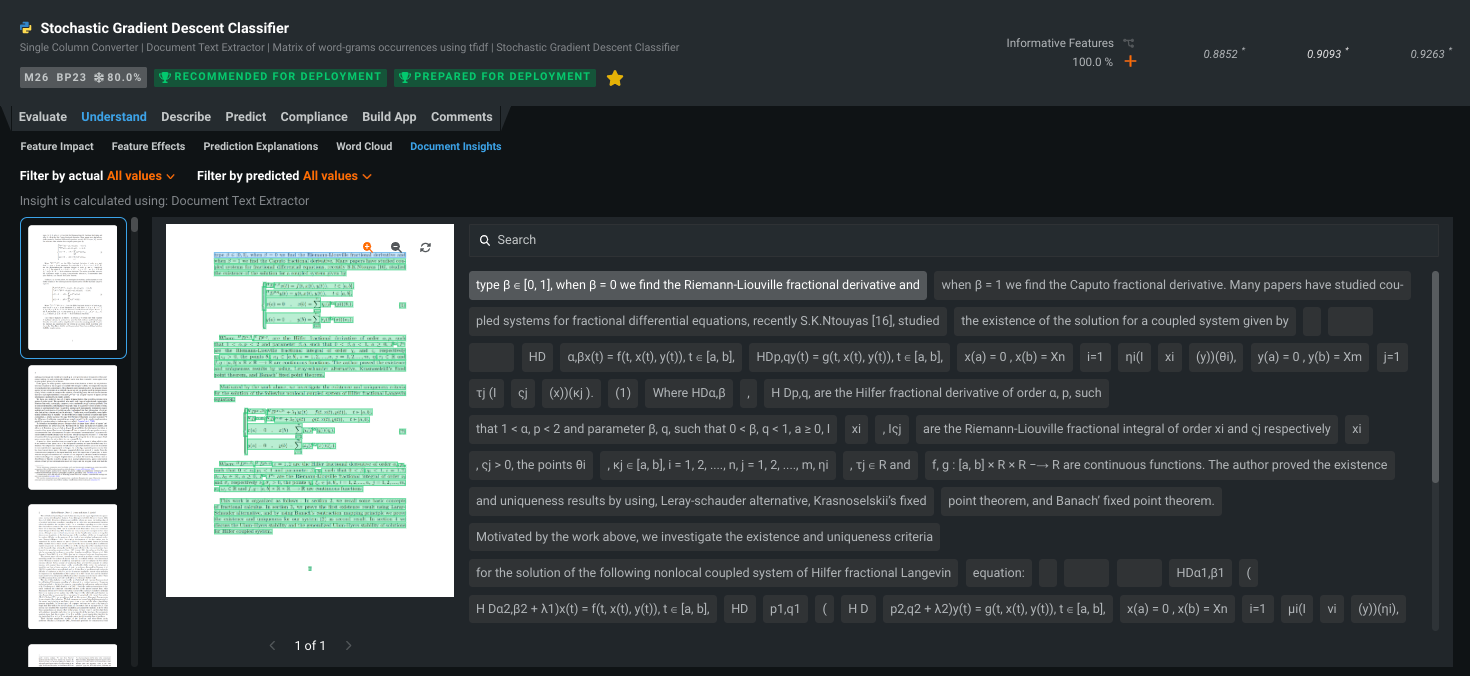
document型のサポートは、他のいくつかのデータおよびモデルの視覚化にも追加されています。
必要な機能フラグ: ドキュメントの取込みを有効にする、ドキュメントの取込みでOCRを有効にする
GPUがディープラーニングに対応¶
たとえば、ディープラーニングモデル、Large Language Modelsのサポートは、ビジネスユースケースの拡大において、ますます重要になっています。 CPUで実行できるモデルもありますが、適切なトレーニング時間を実現するためにGPUを必要とするモデルもあります。 これらの「重要な」ディープラーニングモデルを使用して効率的にトレーニング、ホスト、および予測を行うために、DataRobotは、アプリケーション内でNvidia GPUを活用します。 GPUのサポートが有効な場合、DataRobotは特定のタスクを含むブループリントを検出し、GPUワーカーを使用してそれらをトレーニングする可能性があります。 つまり、最小サンプルサイズが満たされていない場合、ブループリントは、CPUキューにルーティングされます。 さらに、ヒューリスティックによって、CPUワーカーのランタイムを抑えてトレーニングするブループリントが決定されます。
必要な機能フラグ: GPUワーカーを有効にする
プレビュー機能のドキュメントをご覧ください。
ブループリントリポジトリとブループリントの視覚化¶
このデプロイでは、モデリングブループリントのライブラリであるブループリントリポジトリがワークベンチに導入されました。 クイックオートパイロットを実行した後、リポジトリにアクセスして、DataRobotがデフォルトで実行しなかったブループリントを選択することができます。 特徴量セットとサンプルサイズ(または時間認識の場合はトレーニング期間)を選択すると、DataRobotはブループリントを構築し、生成されたモデルをリーダーボードとエクスペリメントに追加します。
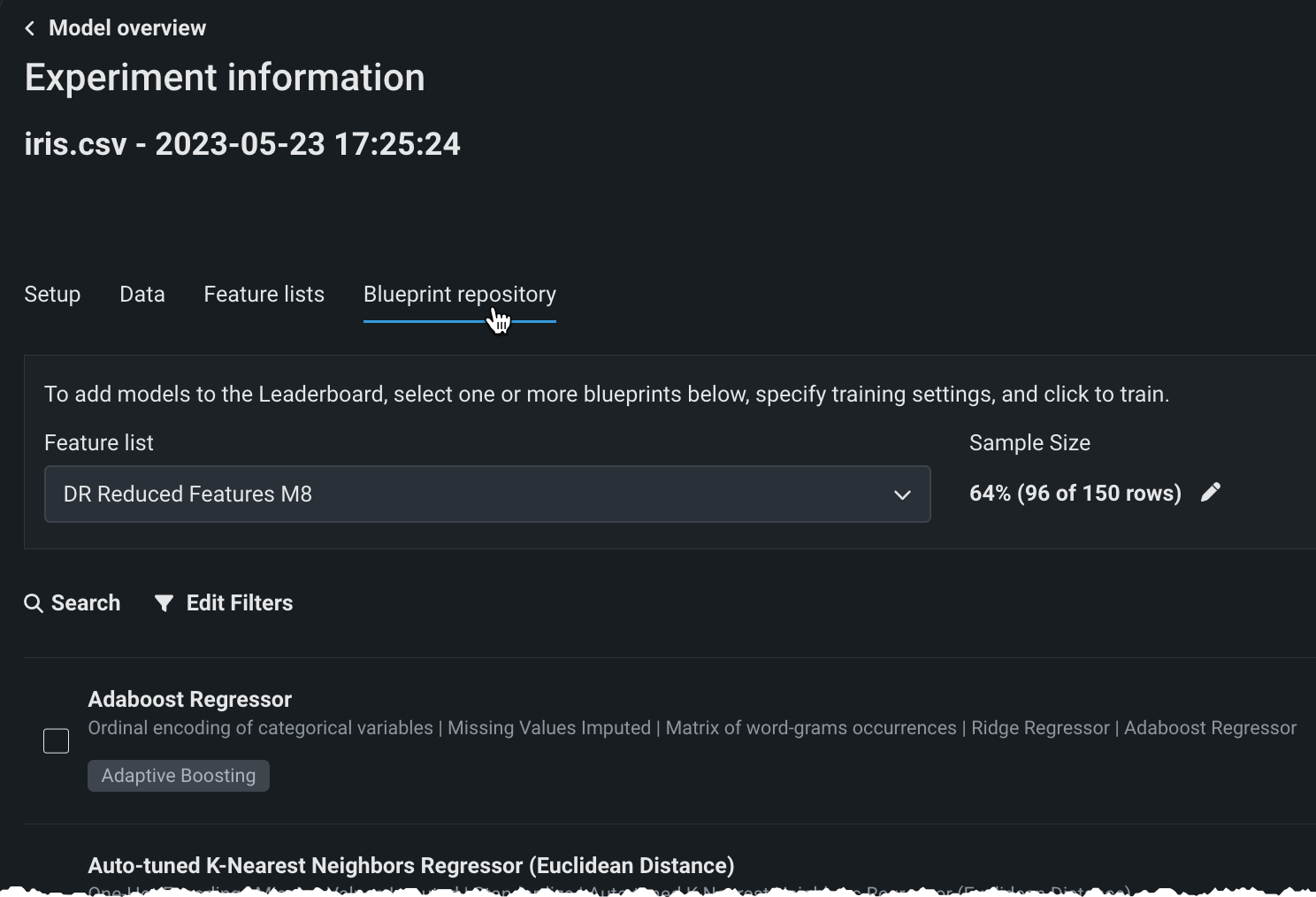
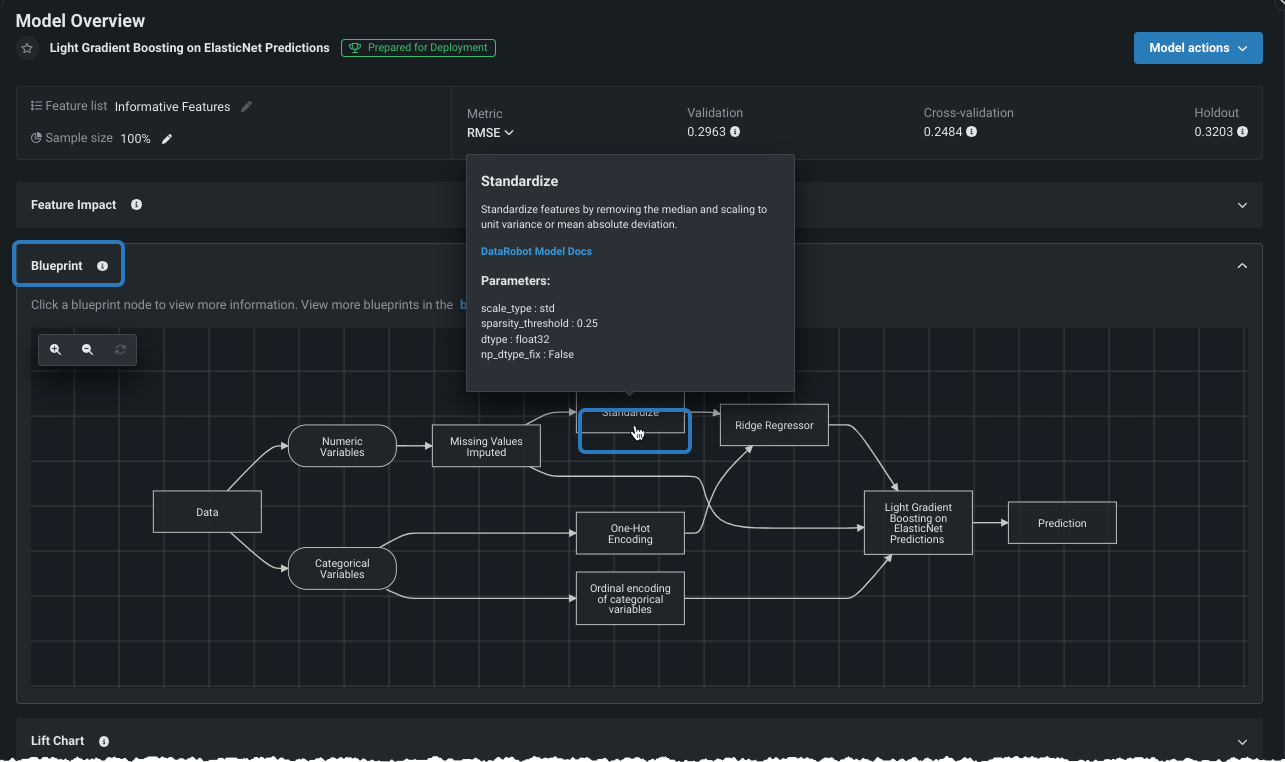
さらに、ブループリントの視覚化が可能になりました。 [ブループリント]タブには、モデルの構築に必要な前処理ステップ(タスク)、モデリングアルゴリズム、後処理ステップがグラフィカルに表示されます。
ワークベンチのスライス¶
データスライスは、プロジェクトデータの部分母集団を作成するフィルターを設定できる機能で、 一部のワークベンチインサイトで使用できるようになりました。 データスライスドロップダウンからスライスを選択したり、新しいフィルターを作成するためのモーダルにアクセスしたりすることができます。
必要な機能フラグ:ワークベンチのスライス
事前入力済みのアプリケーションテンプレート¶
以前は、新しいアプリケーションを作成すると、空白のテンプレートが開かれ、予測の生成を開始する方法についての説明が不十分でした。 現在では、アプリケーションを作成すると、トレーニングデータを使って設定されるため、モデルの出力をただちに明らかにし、紹介して、共同作業を行うことができます。
必要な機能フラグ: トレーニングデータでNCAテンプレートの事前入力を有効にする
プレビュー機能のドキュメントをご覧ください。
ワークベンチでの新しいアプリ体験¶
プレビュー版の機能です。DataRobotは新たにワークベンチに効率的なアプリケーションエクスペリエンスを導入しました。リーダーシップチーム、COEチーム、ビジネスユーザー、データサイエンティストなどが、貴重な情報のスナップショットを簡単に表示、探索、作成できるユニークな機能を利用できます。 このリリースには、以下の改善が実施されています。
- アプリケーションには、より直感的に操作できる新しいシンプルなインターフェイスがあります。
- すべての新たなワークベンチアプリから、特徴量のインパクトおよび特徴量ごとの作用を含むモデルインサイトにアクセスできます。
- ワークベンチのエクスペリメントから作成されたアプリケーションは、ワークベンチのアプリケーションビルダー以外では開かれなくなりました。
必要な機能フラグ: 新しいAIアプリの編集モードを有効にする
推奨機能フラグ: トレーニングデータでNCAテンプレートの事前入力を有効にする
プレビュー機能のドキュメントをご覧ください。
時間認識プロジェクトのスライス(Classic)¶
プレビュー版の機能です。DataRobot Classicの時間認識(OTVおよび時系列)プロジェクトで、データスライスの作成と適用ができるようになりました。 スライスされたインサイトは、特徴量値に基づいて、モデルの派生データの部分母集団を表示するオプションを提供します。 プロジェクトのデータのセグメントに基づいてインサイトを表示および比較すると、モデルがさまざまな部分母集団でどのように動作するかを理解することができます。 スライスされたインサイトから取得したセグメントベースの精度情報を使用するか、セグメントを「グローバル」スライス(すべてのデータ)と比較して、トレーニングデータを改善、セグメントごとに個別モデルを作成、またはデプロイ後の予測を補強します。
必要な機能フラグ: 時間認識プロジェクトのスライスされたインサイト
キー値でコンプライアンスドキュメントを拡張する¶
プレビュー版の機能です。コンプライアンスドキュメントのテンプレートで参照するキー値を作成できます。 キー値の参照を追加すると、生成されたテンプレートに関連データが含まれるため、コンプライアンスドキュメントを完成させるために必要な手動編集が最小限に抑えられます。 モデルレジストリのモデルに関連付けられたキー値は、登録されたモデルパッケージに関する情報を含むキーと値のペアです。
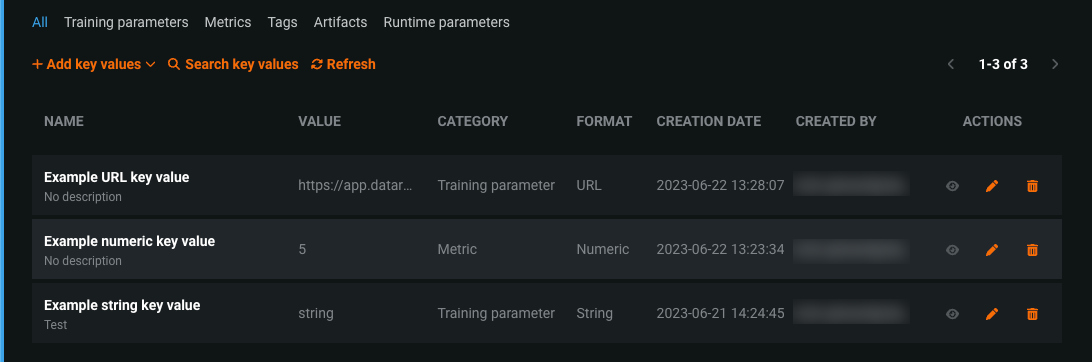
カスタムコンプライアンスドキュメントのテンプレートを作成する際に、文字列、数値、ブール値、画像、データセットのキー値を含めることができます。
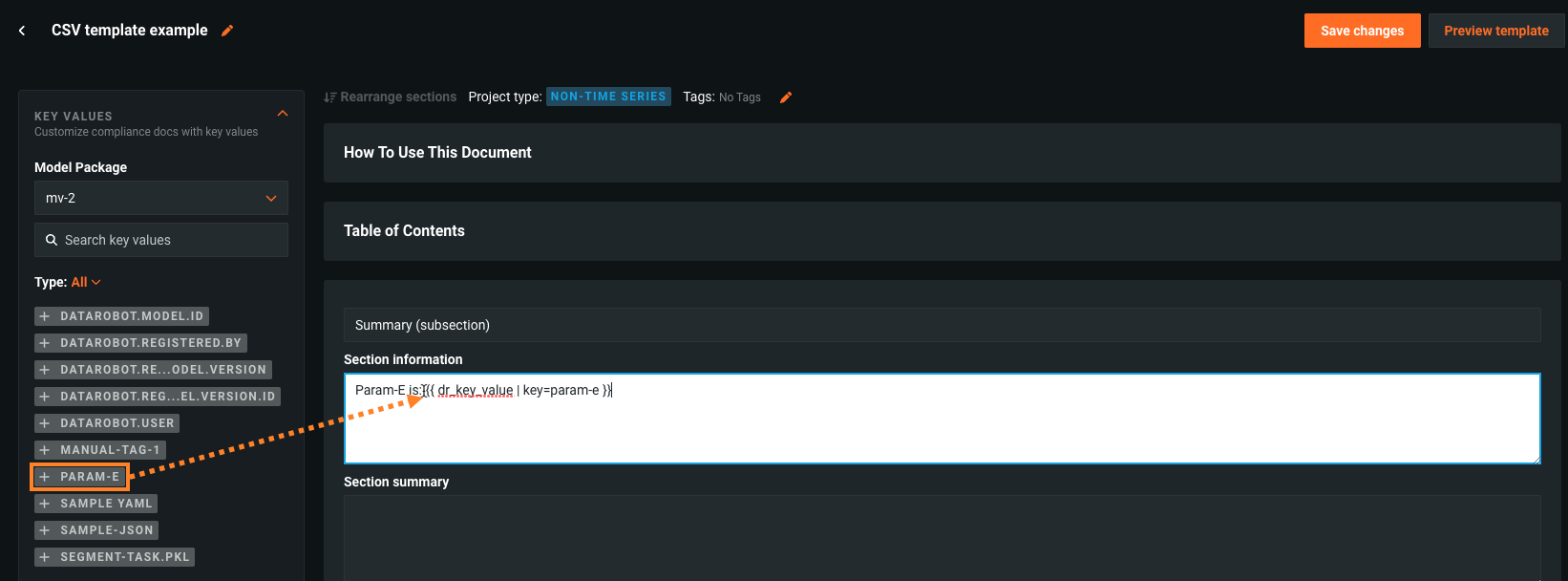
そして、サポートされているキー値を参照するカスタムテンプレートを使用してモデルパッケージのコンプライアンスドキュメントを生成すると、DataRobotは関連するモデルパッケージから一致する値を挿入します。たとえば、キー値に画像が添付されている場合、その画像が挿入されます。
必要な機能フラグ:拡張コンプライアンスドキュメントを生成する
詳しくは、完全なドキュメントをご覧ください。
カスタムタスクでのハイパーパラメーターのチューニング¶
カスタムタスクでハイパーパラメーターをチューニングできるようになりました。 各ハイパーパラメーターには、nameとtypeの2つの値を指定できます。 typeはint、float、string、select、multi のいずれかで、すべてのtypeがdefault値をサポートします。 ハイパーパラメーターの詳細と設定例については、 モデルのメタデータと検証スキーマを参照してください。
プレビュー機能のドキュメントをご覧ください。
DataRobotモデルでのStreamlitアプリケーションの構築¶
DataRobotモデルを使用してStreamlitアプリケーションを構築できるようになりました。StreamlitダッシュボードにDataRobotのインサイトを簡単に組み込むことができます。
含まれる内容と設定の詳細については、 dr-streamlit Githubリポジトリを参照してください。
API¶
DataRobotX¶
プレビュー版の機能です。DataRobotX (DRX)は、データサイエンス体験を強化するために設計されたDataRobot拡張機能のコレクションです。 DRXは通常のワークフローに効率的なエクスペリエンスを提供するだけでなく、新しく実験的な高レベルの抽象化も提供します。
DRXは、以下を含むユニークなエクスペリメントワークフローを提供します。
- Pysparkによるスマートダウンサンプリング
- LLMを使用したデータセットの強化
- 特徴量有用性ランクアンサンブル(FIRE)
- カスタムモデルのデプロイ
- MLFlowでのエクスペリメント追跡
プレビュー機能のドキュメントをご覧ください。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。