データとモデリング(V10.2)¶
2024年11月21日
DataRobot v10.2.0リリースには、以下で説明するように、データ、モデリング、管理に関する多くの新機能と機能強化が含まれています。 リリース10.2のその他の詳細については、以下をご覧ください。
リリース10.2¶
リリースv10.2では、以下の言語のUI文字列の翻訳が更新されています。
- 日本語
- フランス語
- スペイン語
- 韓国語
- ブラジルポルトガル語
目的別にグループ化された機能
- プレミアム機能
データ¶
一般提供¶
DataRobotでADLS Gen2コネクターを一般提供¶
ネイティブADLS Gen2コネクターのサポートが、DataRobotで一般提供されました。 さらに、AzureサービスプリンシパルとAzure OAuthの資格情報は、セキュアな構成を使用して作成および共有できます。
ワークベンチでの特徴量探索の実行¶
ワークベンチで特徴量探索を実行し、複数のデータセットから新しい特徴量を発見および生成できます。 次の2つの場所で特徴量探索を開始できます。
- データタブで、プライマリーデータセットとなるデータセットの右側にあるアクションメニュー > 特徴量探索をクリックします。
- 特定のデータセットのデータ探索ページで、データのアクション > 特徴量探索を開始をクリックします。
このページでは、セカンダリーデータセットを追加して、データセット間の関係性を設定できます。
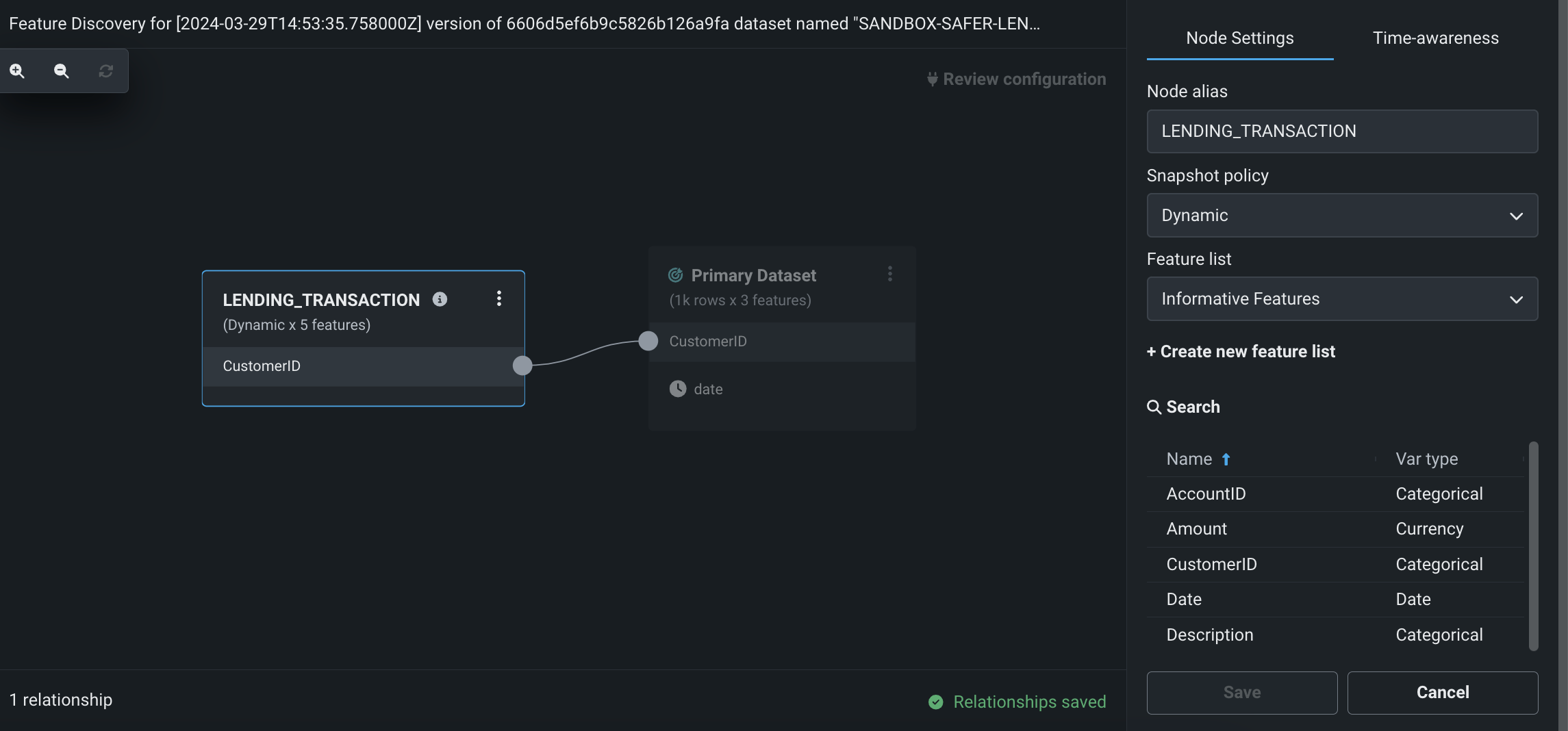
特徴量探索を設定し、自動化された関係性評価を完了したら、すぐにエクスペリメントのセットアップとモデリングに進むことができます。 モデル構築の一部として、DataRobotはこのレシピを使って結合と集計を実行し、新しい出力データセットを生成します。このデータセットはデータレジストリに登録され、現在のユースケースに追加されます。
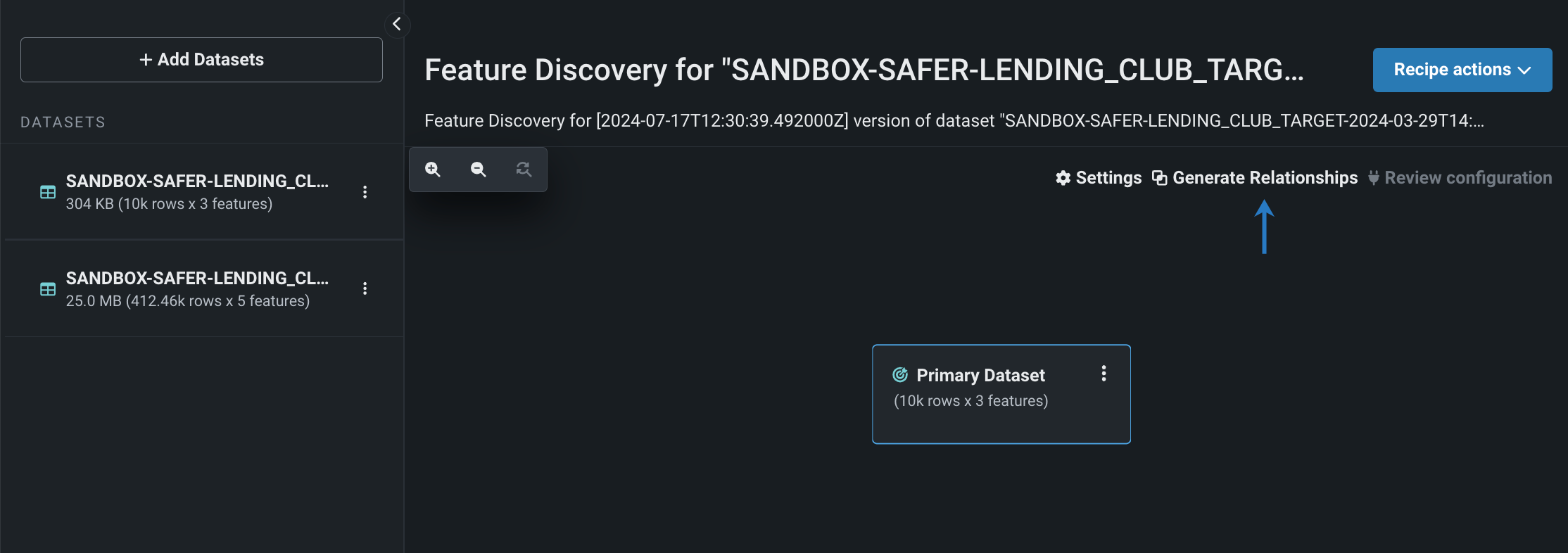
ワークベンチで特徴量探索での関係性を自動生成¶
ワークベンチで特徴量探索を行う場合、関係性の自動検出(ARD)を利用します。 ARDでは、レシピに追加されたプライマリーデータセットとすべてのセカンダリーデータセットを分析して、関係性を検出および生成します。 すべてのセカンダリーデータセットをレシピに追加した後、関係性の生成をクリックすると、セカンダリーデータセットがキャンバスに自動的に追加され、データセット間の関係性が設定されます。
個々のカタログアセットが他のDataRobotエンティティとどのように関連しているかを理解¶
AIカタログは、DataRobotのデータと関連アセットを操作するための集中型コラボレーションハブとして機能します。 個々のアセットの情報タブで、アプリケーション内の他のエンティティが現在のアセットにどのように関連しているか、つまり依存しているかを確認できるようになりました。 これは、アイテムが使用されているプロジェクトの数に基づいてアイテムの人気度を確認したり、変更や削除を行った場合に影響を受ける可能性のある他のエンティティを把握したり、エンティティがどのように使用されているかを理解したりできるなど、さまざまな理由で役立ちます。
ワークベンチでのラングリング機能を強化¶
このリリースでは、ワークベンチのデータラングリングに以下の改善を行いました。
- 特徴量の削除操作により、すべての特徴量を選択/選択解除することができます。
- ラングリングセッションの開始時や実行中に、既存のレシピから操作をインポートできます。
- ラングリングページのプレビュー設定ボタンから、ライブプレビューの設定にアクセスします。
- アクションメニューから、操作の上/下への追加、レシピの上/下へのインポート、複製、特定の操作までのプレビューなど、個々の操作に対して追加のアクションを実行できます。これにより、さまざまな操作の組み合わせがライブサンプルにどのように影響するかをすばやく確認できます。
ワークベンチにEDAのインサイトを追加¶
このリリースでは、ワークベンチのデータ探索ページの特徴量タブに、以下のEDAインサイトが導入されています。
-
データ探索ページの特徴量タブでは、個々の特徴量のインサイトに加えて、データ品質チェックが指標として表示されます。

-
ヒストグラムチャートには、外れ値に関するデータ品質の問題が表示されます。

-
頻出値チャートでは、インライア、偽装欠損値、過剰なゼロが報告されます。
- 特徴量探索での特徴量の系統インサイトでは、特徴量がどのように生成されたかが示されます。
DataRobotでSAP Datasphereコネクターをサポート¶
プレミアム機能です。NextGenとDataRobot Classicの両方で、SAP Datasphereコネクターをプレビュー機能としてサポートするようになりました。
デフォルトではオフの機能フラグ:SAP Datasphereコネクターを有効にする(プレミアム機能)
大規模な特徴量探索データセットを扱う際のスケーラビリティが向上¶
DataRobotでは、以下の改善により、特徴量探索で大規模なデータセットを扱う際のスケーラビリティが向上しています。
- 特徴量探索のジョブに対して柔軟なリソース割り当てを行います。 管理者は、ユーザー設定 > システム設定を開き、
XLARGE_MM_WORKER_SAFER_AIM_CONTAINER_MEM_MBを有効にして、該当フィールドでリソース数を指定することで、追加のコンピューティングリソースを割り当てることができます。 - 最大20GBのセカンダリーデータセットで特徴量探索を実行でき、出力データセットも20GBまで可能です。
- SQLレシピをダウンロードして、DataRobotが特徴量探索の一部として結合と集計を実行する方法を把握できます。
プレビュー¶
DataRobotデータセットのラングリングのサポートを拡大¶
ワークベンチのデータレジストリに保存されたデータセットをラングリングする機能は、10.1でプレビュー版として初めて導入されましたが、現在はすべての環境でサポートされています。
増分学習で動的データセットが利用可能に¶
Snowflake、BigQuery、またはDatabricksで用意したデータソースのデータなど、10GBを超える動的データセットでのモデリングが可能になりました。 エクスペリメントを設定するときは、順序付け特徴量を指定して、データセットから決定論的サンプルを作成し、その後は通常どおり増分モデリングを開始します。 モデルの構築が開始されると、選択した順序付け特徴量が「エクスペリメント情報を表示」で報告されます。
デフォルトではオンの機能フラグ:増分学習を有効にする、ワークベンチで動的データセットを有効にする、データのチャンキングサービスを有効にする
プレビュー機能のドキュメントをご覧ください。
新しい操作、派生プランの自動化を時系列のデータラングリングに導入¶
今回のリリースでは、時系列モデリングでの入力準備を支援するツールが既存のデータラングリングフレームワークに追加され、データ準備段階で時系列の特徴量エンジニアリングを実行できるようになりました。 この変更は、今月発表された基本的なラングリング機能の改善に合わせて行いました。 時系列特徴量の派生操作によって、入力データに対してラグやローリング統計を実行します。その際、提案された派生プランを使って特徴量を自動生成するか、特徴量の選択とタスクの適用を手動で行います。DataRobotでは新しい特徴量が構築され、ライブデータサンプルに適用されます。
これらの操作はどのレシピにも追加できますが、プレビューサンプルの方法を日付/時刻に設定すると、指定した設定に基づいて、DataRobotが特徴量変換を提案するオプションが有効になります。 自動化オプションを使用すると、予測距離に応じてデータが拡張されて、事前に既知の列(指定した場合)とナイーブベースライン特徴量が追加され、元のサンプルが置き換えられます。 完了後、必要に応じてプランを変更できます。
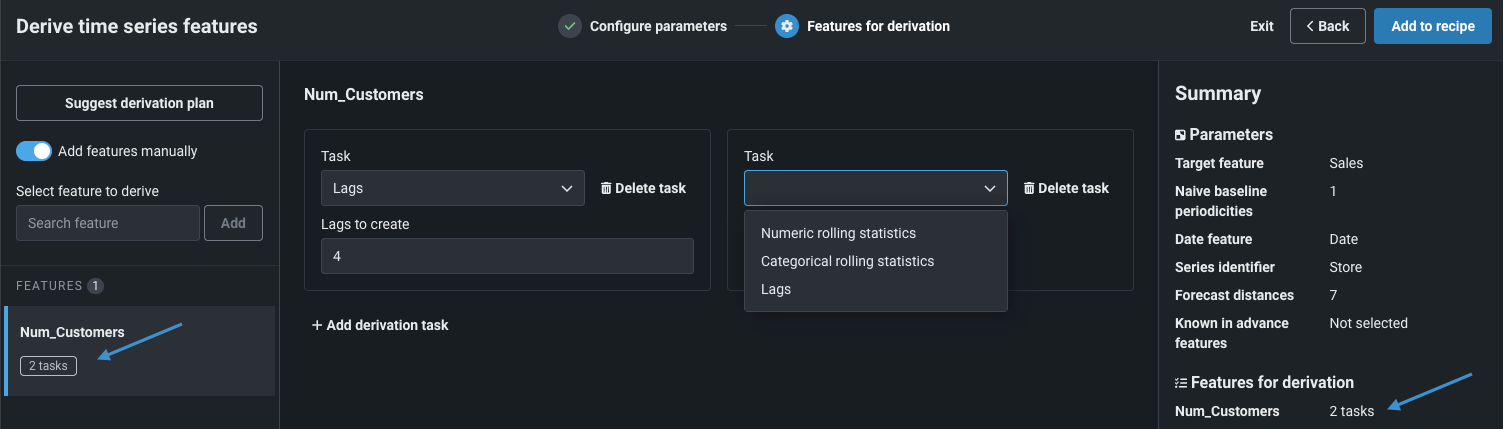
デフォルトではオンの機能フラグ:時系列データのラングリングを有効にする
プレビュー機能のドキュメントをご覧ください。
大規模なDataRobotデータセットのラングリングレシピをパブリッシュする際のスケーラビリティ¶
20GBを超える入力データセットのラングリングレシピをパブリッシュする際、データの変換と分析をDataRobotのコンピューティングエンジンにプッシュダウンできるようになりました。これにより、S3に保存されたCSVおよびParquetファイルに対してシームレスでスケーラブル、かつセキュアなデータ処理を行うことができます。この機能はAWS SaaSおよびVPC環境でのみ利用可能です。
デフォルトではオフの機能フラグ:データエンジンでSparkの分散処理を有効にする
モデリング¶
一般提供¶
オートパイロットを実行する前に日付特徴量を自動的に削除¶
DataRobot Classicで時間を認識しないプロジェクトを設定する場合、オートパイロットの実行に使用する特徴量セットから日付特徴量を自動的に削除できるようになりました。 これを行うには、プロジェクトの高度なオプションを開き、その他タブを選択して、選択したリストから日付特徴量を削除し、新しいモデリング特徴量セットを作成するを選択します。 このパラメーターを有効にすると、選択した特徴量セットが複製され、元の日付特徴量が削除されて、新しい特徴量セットがオートパイロットの実行に使用されます。 時間を認識しないプロジェクトから元の日付特徴量を除外することで、過剰適合のような問題を防ぐことができます。
OTVおよび時系列プロジェクトのデータで予測の説明を計算¶
一般提供機能になりました。時系列およびOTVプロジェクトで予測の説明を計算できます。 具体的には、トレーニングデータのホールドアウトパーティションおよびセクションでXEMPベースの予測の説明を取得できます。 DataRobotは、トレーニングデータのバックテスト1の検定パーティションに対してのみ予測の説明を計算します。
登録されたテキスト生成モデルでコンプライアンスドキュメントのサポートを開始¶
DataRobotは、予測モデルの法的検証に使用できるモデル開発ドキュメントを以前から提供しています。 今回、コンプライアンスドキュメントの機能が拡張され、レジストリのモデルディレクトリにあるテキスト生成モデルに対してドキュメントが自動生成されるようになりました。 DataRobotがネイティブにサポートするLLMの場合、このドキュメントは、モデルの概要、有用なリソース、そして特に注目すべきはモデルのパフォーマンスと安定性のテストなど、レポートの生成にかかる時間を短縮するのに役立ちます。 ネイティブにサポートしていないLLMの場合、生成されるドキュメントは、必要なセクションがすべて揃ったテンプレートとして使用できます。
個々の予測説明のためのバイオリン図の分布インサイト¶
SHAP分布:特徴量ごとは、バイオリン図とも呼ばれ、さまざまなカテゴリー間でデータセットの確率分布を比較するための統計図です。 この新しいSHAPインサイトでは、1,000行のサンプリングに基づいて、行のコホートが表示され、特徴量ごとに視覚化されるため、SHAP値と特徴量値の分布を調べることができます。

DataRobotには、特徴量が予測に与える影響を分析するのに役立つ2つのSHAPツールが用意されています。
- 「SHAP分布:特徴量ごと」では、視覚化にバイオリン図を使用して、特徴量ごとにスコアの分布と密度を示します。
- 個々の予測の説明では、各特徴量が予測に与える影響を行ごとに示します。
お客様からのご意見を反映してホームページを変更¶
2023年11月に導入されたDataRobotのホームページでは、DataRobotアプリで使用可能な豊富な情報にアクセスできます。 この新しいホームページは、お客様からのご要望にお応えして、新規のユーザーにはクイックヘルプを提供し、既存のユーザーには最近のアクティビティにアクセスできるように改良されました。 画面上部のタイルを使って、以下のものにすばやくアクセスできます。
-
アプリケーションテンプレートによるエンドツーエンドのソリューション。 これらのコードファーストで再利用可能なパイプラインは、すぐに使えますが、カスタマイズも簡単で、個々のニーズに合った成果をすばやく実現できます。
-
ユースケースディレクトリ。予測および生成AIモデルのためのエクスペリメントベースの反復ワークフローを作成または再利用できます。
-
レジストリのモデルディレクトリ。アセットの管理、ガバナンス、本番環境へのデプロイが可能です。

データタブとカスタム特徴量セットの機能を一般提供¶
UIを使用して既存の予測エクスペリメントに新しいカスタム特徴量セットを追加する機能が、プレビュー機能として4月に導入されましたが、 一般提供機能になりました。リーダーボードからアクセスできるエクスペリメント情報ウィンドウの特徴量セットまたはデータタブ(どちらも一般提供機能になりました)から、独自の特徴量セットを作成できます。 一括選択を利用すると、ワンクリックで複数の特徴量を選択できます。
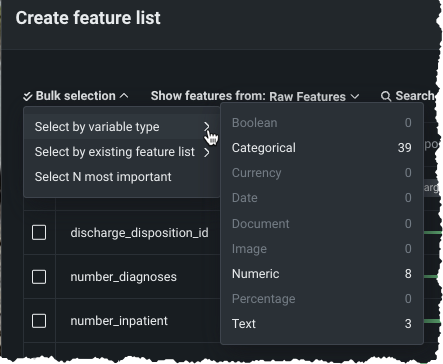
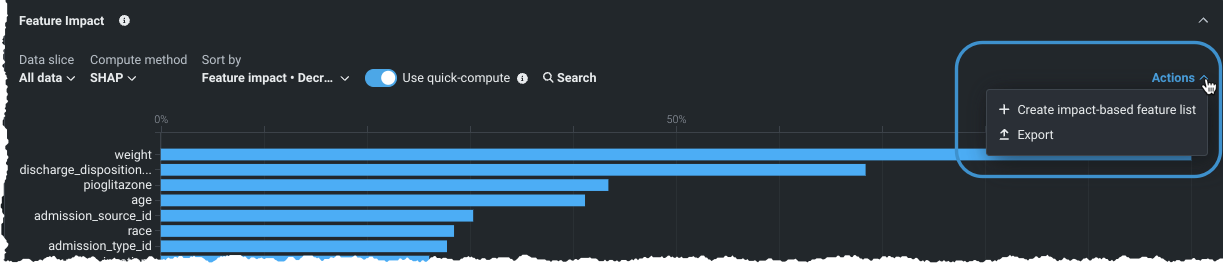
特徴量のインパクトからカスタム特徴量セットを作成¶
モデル概要からアクセスできる特徴量のインパクトのインサイトから、特徴量の相対的なインパクトに基づいて特徴量セットを作成できるようになりました。 NextGenの他の特徴量セット作成オプションと同じ使い慣れたインターフェイスを使用して、特徴量のインパクトで作成されたセットをエクスペリメント全体で利用できます。
時系列機能を一般提供。部分的な履歴しかない新しい系列のサポートを追加¶
このリリースでは、ワークベンチに時系列機能が一般提供されました。 アップデートの一環として、予測機能に新しい履歴と部分的な履歴データのサポートが追加されました。 一部のブループリントでは、部分的な履歴しかない新しい系列を参照すると、最適ではない予測を返すことがあります。 このオプションを選択すると、不完全な履歴データで予測を行うように設計されたモデルもトレーニングされます。 これは、トレーニングデータになかった系列(「コールドスタート」)や、系列の履歴が部分的にしかわからない予測データセット(過去の行は特徴量派生ウィンドウ内で部分的に利用可能)です。

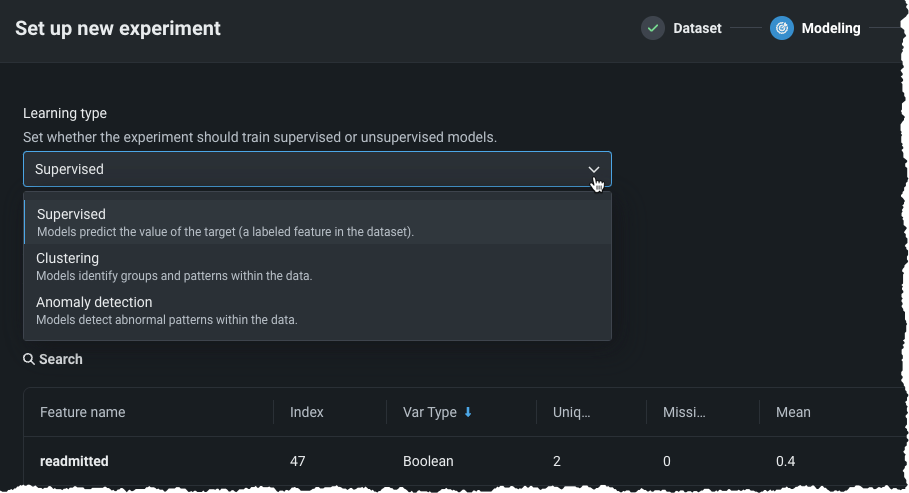
ワークベンチで教師なしモデリングのサポートを開始¶
ワークベンチで、ターゲットを指定せず、データにラベルを付けない教師なし学習が可能になりました。 教師なし学習は、予測を生成する代わりに、データのパターンに関するインサイトを明らかにします。 予測と時間認識の両方のエクスペリメントで利用できる教師なし学習では、クラスタリングと異常検知が可能で、「データに異常はあるか?」や 「自然なクラスターはあるか?」といった質問に答えます。教師なしエクスペリメントを作成するには、学習タイプを指定し、該当するフィールドに入力します。
モデルの構築が完了すると、教師なし固有のインサイトによって、特定されたパターンが明らかになります。
増分学習でのクラスタリング¶
今回のリリースでは、DataRobotの増分学習機能にK-Meansクラスタリングモデルのサポートが追加されました。 増分学習(IL)は大規模なデータセット(10GB〜100GB)に特化したモデルトレーニング方法であり、データをチャンク化してトレーニングのイテレーションを作成します。 これがサポートされていることで、より大きなデータセットで時系列以外のクラスタリングプロジェクトを構築でき、自然なセグメントのグループ化および識別によってデータの探索が可能です。
ワークベンチで地理空間モデリングのサポートを開始¶
データ内の地理空間パターンを把握しやすくするために、ワークベンチでのモデル構築時に、一般的な地理空間形式をネイティブに取り込み、空間的に明確なモデリングタスクで強化されたモデルブループリントを構築できるようになりました。 エクスペリメントの設定時に、追加設定から地理空間のインサイトセクションで位置特徴量を選択し、その特徴量がモデリングの特徴量セットに含まれていることを確認します。 それにより、地理空間のインサイトが作成されます。教師ありプロジェクトの場合は位置ごとの精度、教師なしプロジェクトの場合は位置ごとの異常です。

地理空間モデリングでトレーニングサイズを拡大¶
今回のリリースから、DataRobot Classicの地理空間モデリング(Location AI)でサポートする最大行数を10万行から1000万行に引き上げました。 Location AIでは、一般的な地理空間形式を取り込むことができ、地理空間座標を自動的に認識した地理空間分析モデリングが可能です。 トレーニングデータのサイズが引き上げられたことで、モデル内で地理空間パターンを見つける能力が向上しました。
ワークベンチで多クラス分類のサポートを一般提供¶
最初、2024年3月にワークベンチにリリースされた多クラスモデリングと関連する混同行列が、一般提供されました。 DataRobotでは、多クラスモデリングのさまざまなエクスペリメント(回答が3つ以上の分類問題)をサポートするために、集計機能を使用して無制限のクラス数に対応しています。

セルフマネージドAIプラットフォームでカスタムタスクのサポートを開始¶
カスタムタスクを使用すると、DataRobotのブループリントにカスタムステップを追加し、DataRobotが生成したブループリントと同様に、そのブループリントをトレーニング、評価、およびデプロイすることができます。 V10.2では、DataRobot Classicとセルフマネージド環境のAPIからもこの機能を利用できるようになりました。
XEMPベースの個々の予測説明をワークベンチに追加¶
ワークベンチでは、個々の予測の説明を2つの方法で計算できるようになりました。1つはSHAP(Shapley値に基づく)、もう1つはXEMP(eXemplarに基づくモデル予測の説明)です。 このインサイトは、方法に関係なく、予測の要因を説明するのに役立ちます。 XEMPベースの説明は、すべてのモデルをサポートする独自の方法であり、DataRobot Classicでは以前から利用できました。 ワークベンチでは、SHAPをサポートしていないエクスペリメントでのみ利用できます。

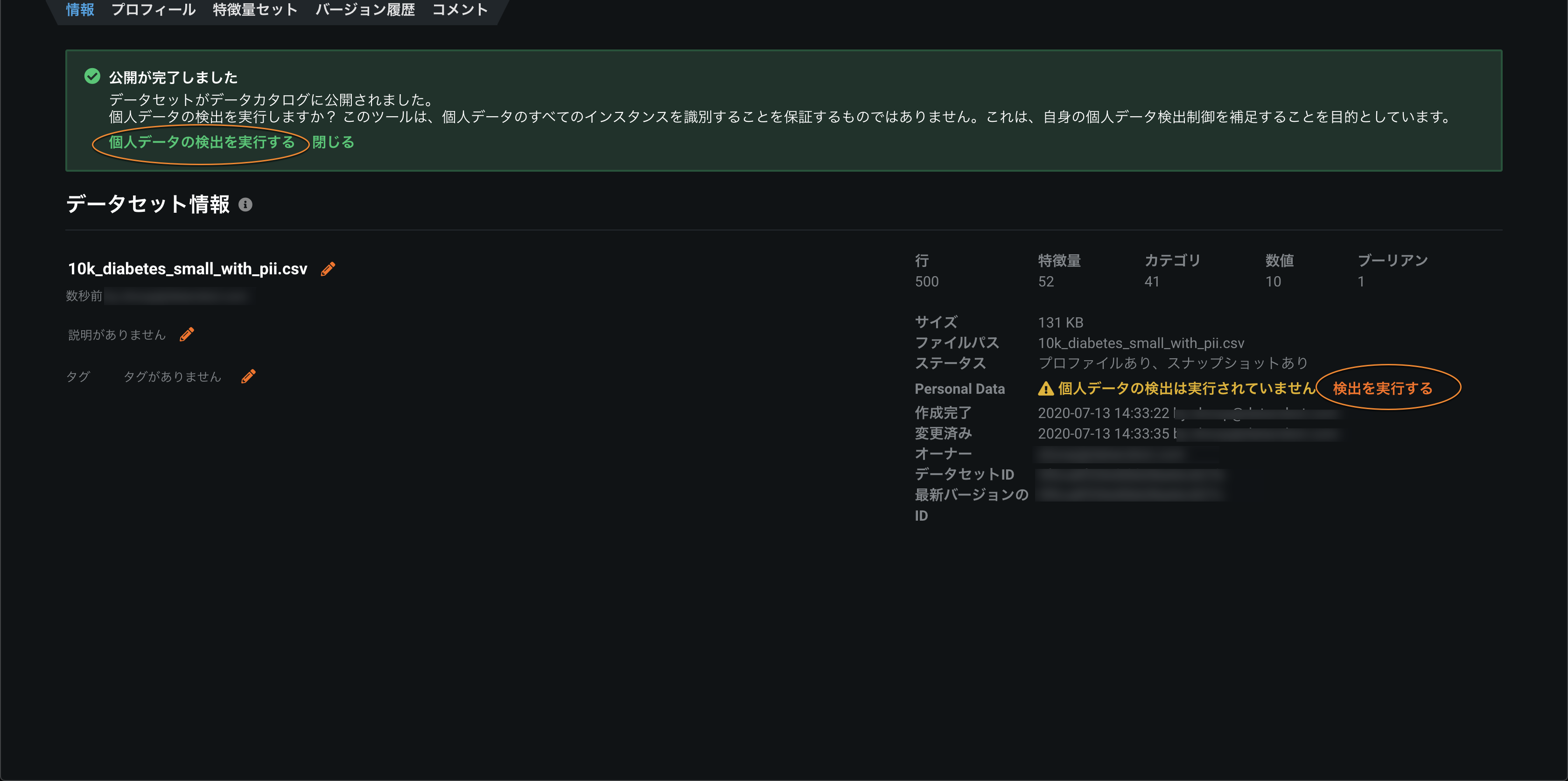
SaaSおよびセルフマネージド環境で個人情報の検出機能を一般提供¶
法規制の遵守が必要なユースケースには、個人情報をモデリングの特徴量として使用することが禁じられているものもあるため、DataRobot Classicでは個人情報の検出機能を提供しています。 この機能が、SaaSとセルフマネージドの両方の環境で一般提供されました。 AIカタログにデータをアップロードした後に、このチェックを利用できます。
プレビュー¶
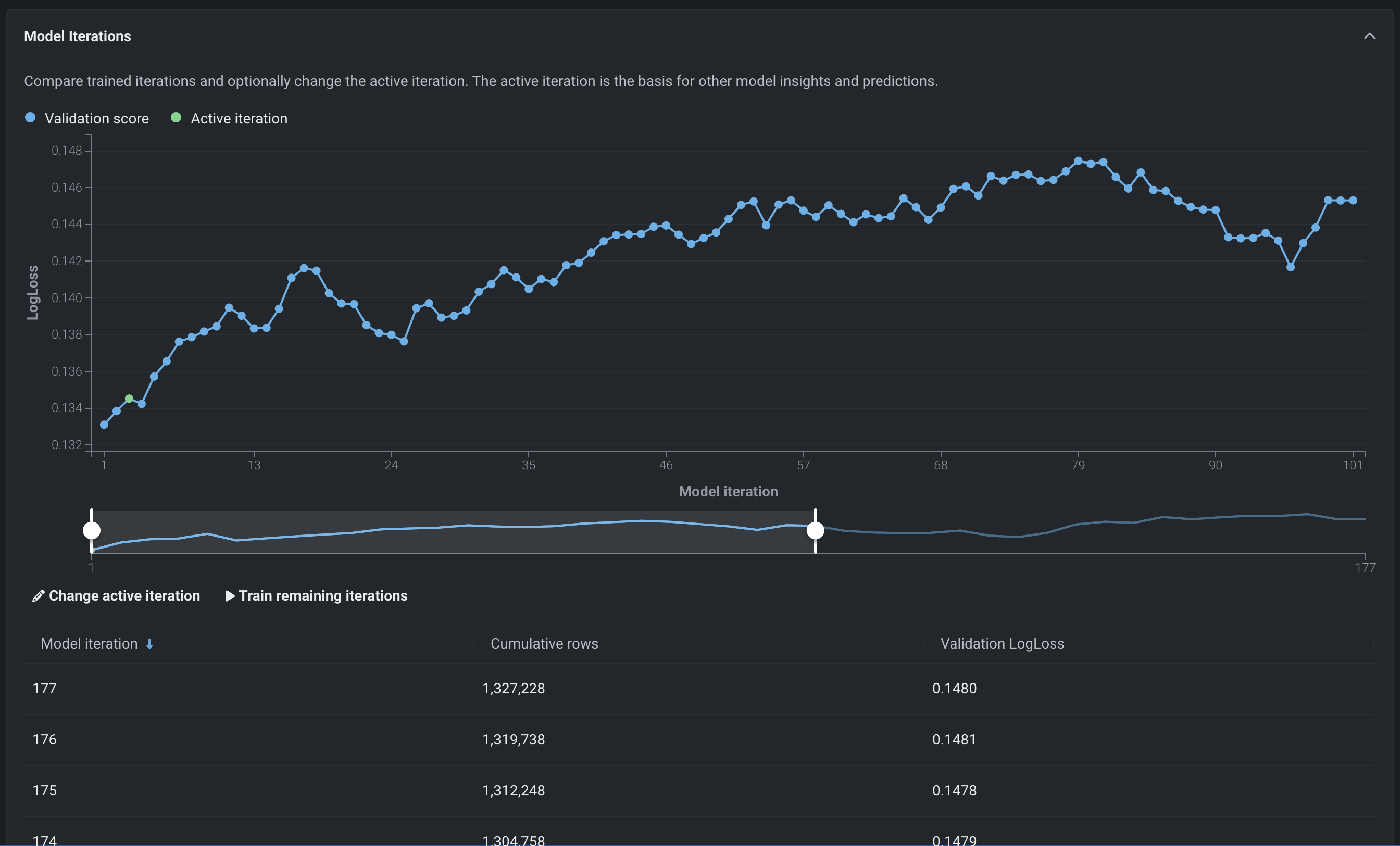
イテレーションの比較を目的とした、増分学習の新しいインサイト¶
増分学習でのモデルイテレーションのインサイトでは、トレーニングされたイテレーションを比較し、必要に応じて、別のアクティブなイテレーションを割り当てたり、トレーニングを継続したりすることができます。 今回、このインサイトに、データの視覚化を支援する学習曲線が追加されました。 チャートを見て得た情報で、たとえば、アクティブなイテレーションを変更したり、新しいイテレーションをトレーニングしたりして、エクスペリメントを続行することができます。
デフォルトではオンの機能フラグ:増分学習を有効にする
プレビュー機能のドキュメントをご覧ください。
管理¶
一般提供¶
サーバーレスプラットフォームに最大数のコンピューティングインスタンスを設定¶
管理者は、組織単位でデプロイの最大コンピューティングインスタンス数の上限を引き上げることが可能になりました。 指定しない場合、デフォルトは8です。コンピューティングリソースの使用を制限するには、最大値を最小値と同じに設定します。
組織全体でEDAリソースの使用状況を監視¶
一般提供機能になりました。管理者は、リソースモニターのEDAタブで、EDA1および関連タスクに使用されている設定済みのワーカーの数を監視することができます。 リソースモニターは、環境全体にわたってDataRobotのアクティブなモデリングおよびEDAワーカーを可視化し、アプリケーションの現在の状態に関する一般的な情報と、コンポーネントのステータスに関する特定の情報を提供します。
カスタム認証局とのバンドルを設定¶
セルフマネージドAIプラットフォームで一般提供されました。カスタム認証局(CA)と、プライベートおよびパブリックCA発行元からのルートTLS証明書とのバンドルを設定できます。 DataRobotでは、ALLOW_SELF_SIGNED_CERTS設定で自己署名証明書を使用している場合、移行することをお勧めします。 要件と設定手順の詳細については、DataRobotサポート(mailto:support@datarobot.com)にお問い合わせください。
ユーザーアクティビティモニターをデフォルトで有効化¶
ユーザーアクティビティモニターがすべての組織管理者に対して有効になり、機能フラグを手動で有効にすることなく、組織内のさまざまな使用状況データと予測統計にアクセスして分析できるようになりました。
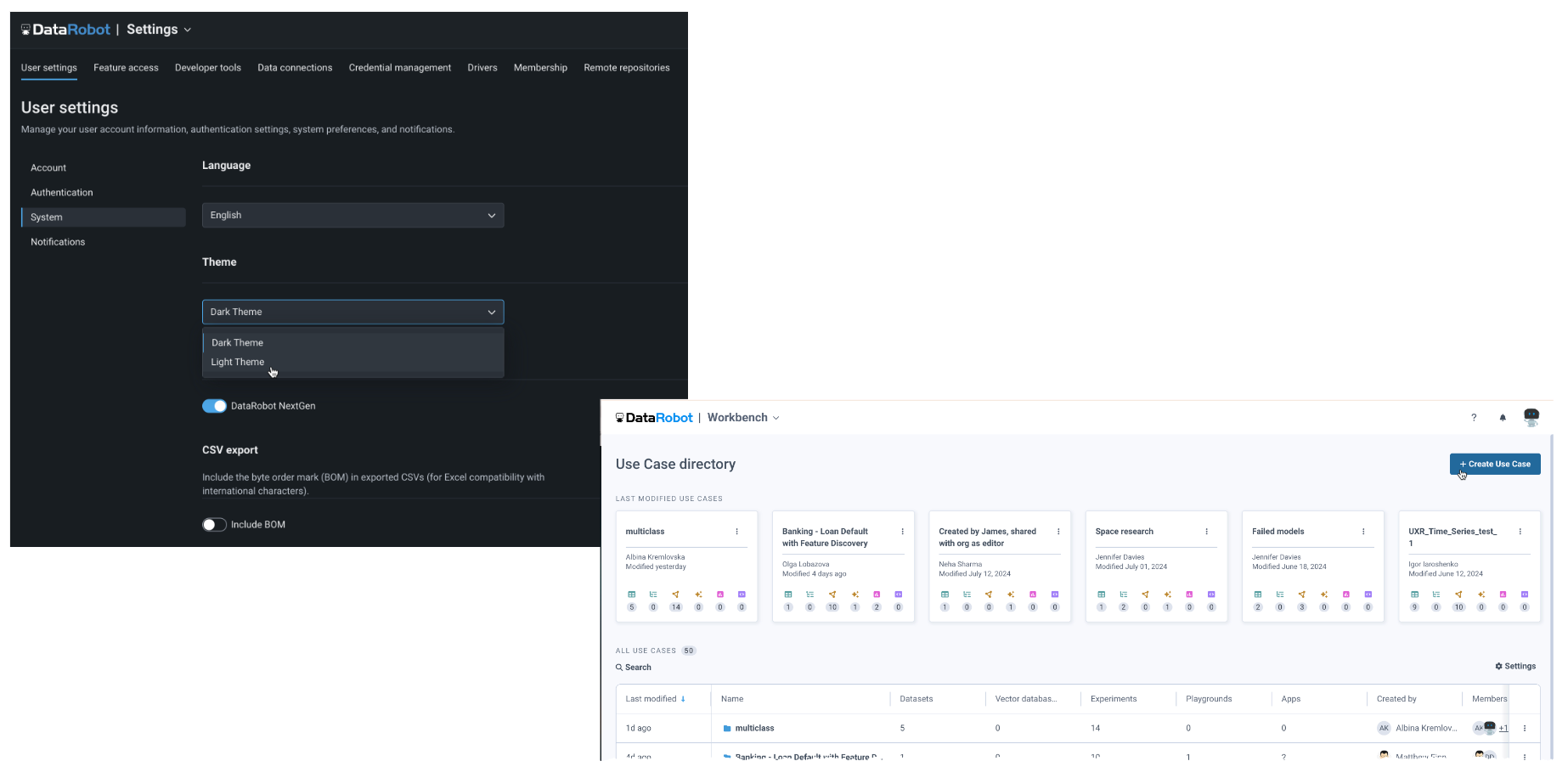
アプリケーションの表示にライトテーマを追加¶
デフォルトではダークテーマで表示されるDataRobotアプリケーションの表示テーマを変更できるようになりました。 表示色を変更するには、右上のプロフィールアバターから、ユーザー設定 > システムに進み、テーマドロップダウンを使用します。
サポート終了/移行ガイド¶
ADLS Gen2およびS3コネクターのバージョン¶
ADLS Gen 2(バージョン 2021.2.1634676262008および2020.3.1605726437949)とAmazon S3(バージョン2020.3.1603724051432)コネクターは使用非推奨になりました。 新しいバージョンのコネクターを使用して既存のデータ接続を再作成し、追加の認証メカニズム、バグ修正、およびNextGenでこれらの接続を使用する機能を活用できるようにすることをお勧めします。
以下のプレビュー機能フラグも無効になります。
- DataRobotコネクターを有効化する
- ADLS Gen2のOAuth 2.0を有効化
古いバージョンを使用して作成された既存の接続は、引き続き動作します。 ただし、DataRobotでは、これらの古いバージョンに対する機能強化やバグ修正は今後行いません。
自己署名証明書¶
自己署名証明書の設定(ALLOW_SELF_SIGNED_CERTS)は使用非推奨となりました。 11.1以降のリリースで削除される予定です。DataRobotでは、セキュリティ強化のため、自己署名証明書から、カスタム認証局(CA)とプライベートおよびパブリックCA発行元からのルートTLS証明書とのバンドルへの移行を推奨しています。 要件と設定手順の詳細については、DataRobotサポート(support@datarobot.com)にお問い合わせください。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。