バージョン11.5.0¶
2026年2月8日
このページには、DataRobotのセルフマネージドAIプラットフォーム11.5.0リリースの新機能、機能強化、および修正された問題が記載されています。 これは長期サポート(LTS)リリースではありません。 リリース11.1が最新の長期サポートリリースです。
バージョン11.5.0には、以下の新機能と修正された問題が含まれています。
エージェント型AI¶
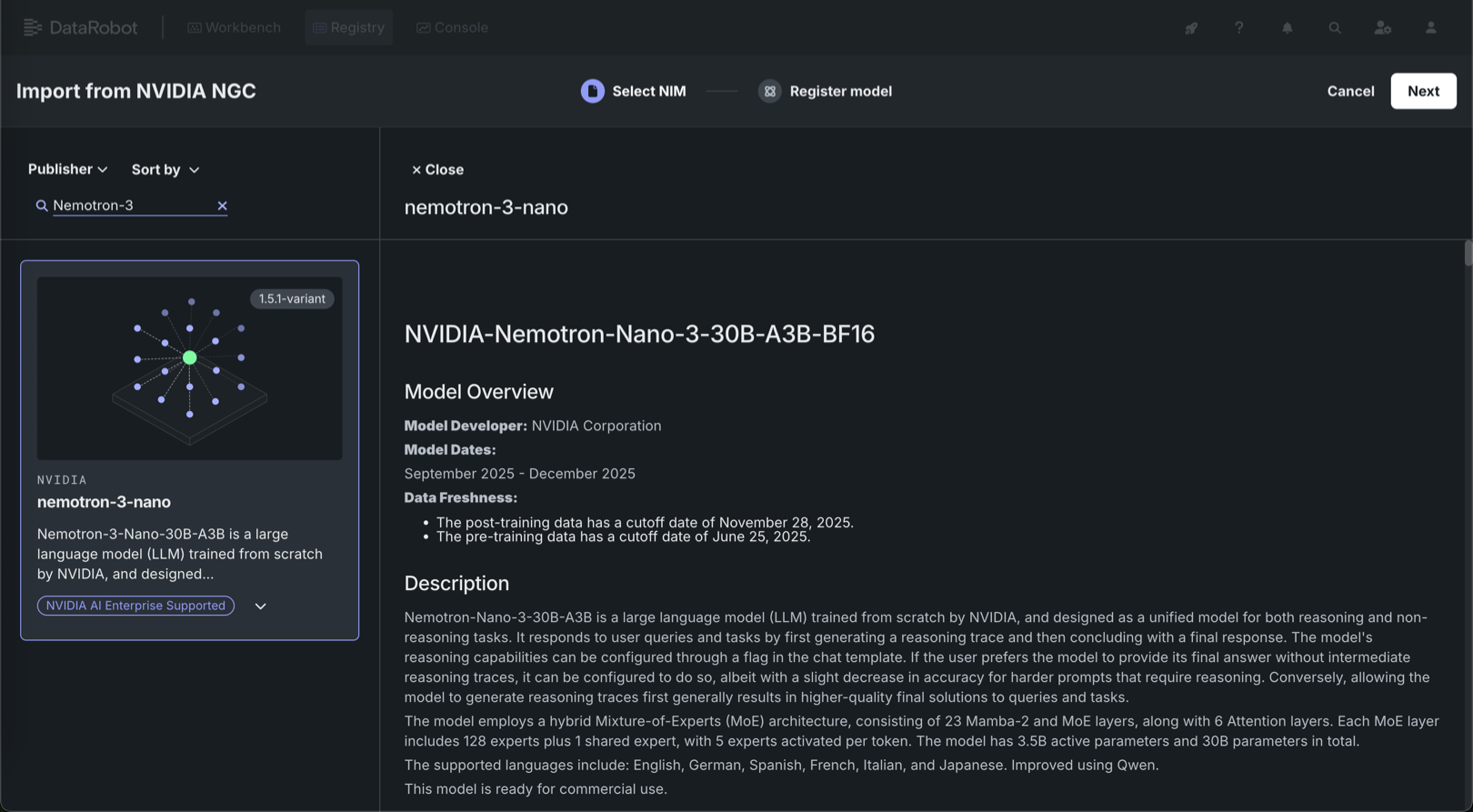
NIMギャラリーよりNemotron 3 Nanoを導入¶
NVIDIA AI EnterpriseとDataRobotは、お客様の組織の既存のDataRobotインフラストラクチャと連携するように設計された、構築済みのAIスタックソリューションを提供しています。これにより、堅牢な評価、ガバナンス、および監視の機能を利用できます。 この連携には、エンドツーエンドのAIオーケストレーションのための包括的なツール群が含まれており、組織のデータサイエンスパイプラインを高速化し、DataRobot Serverless ComputeのNVIDIA GPUで運用レベルのAIアプリケーションを迅速にデプロイすることができます。
DataRobotでは、AIアプリケーションとエージェントのギャラリーからNVIDIA Inference Microservices (NVIDIA NIM)を選択して、組織のニーズに合わせたカスタムAIアプリケーションを作成します。 NVIDIA NIMは、生成AIの導入を企業全体で加速させることを目的として、NVIDIA AI Enterprise内で構築済みおよび設定済みのマイクロサービスを提供します。
バージョン11.5のリリースより、最先端の精度と卓越した効率性を単一モデルに統合したNemotron 3 Nanoが、NIMギャラリーからワンクリックで導入できるようになりました。 Nemotron-Nano-3-30B-A3Bは、推論タスクと非推論タスクの両方に対応するNVIDIAの大規模言語モデルであり、300億のパラメーターを有します。設定可能な推論トレースとハイブリッドな混合エキスパートアーキテクチャを備えています。 Nemotron 3 Nanoは以下の特長を備えています。
- 実稼働エージェントにとって最も重要な機能であるコーディング、推論、数学、および長いコンテキストのタスクにおいて最先端の精度を実現。
- 高速スループットにより、トークンあたりのコストの経済性が向上。
- 対象となるタスクに対して高い精度と効率の両方を必要とするエージェントワークロードを最適化。
これらの機能により、高度な推論の実行に必要なパフォーマンスの余裕を確保しつつ、予測可能なGPUリソース消費を維持することが可能になります。 NIMギャラリーからNemotron 3 Nanoを今すぐ導入してください。
新しいLLMを導入¶
今回のリリースから、DataRobotではLLM Gatewayを通じて以下のLLMを利用できます。 従来通り、組織の特定のニーズに対応するために外部連携を追加できます。 サポートされているLLMの完全なリストについては、利用可能なLLMのページを参照してください。
| LLM | プロバイダー |
|---|---|
| Claude Opus 4.5 | AWS, Anthropic 1p |
| Nvidia Nemotron Nano 2 12B | AWS |
| Nvidia Nemotron Nano 2 9B | AWS |
| OpenAI GPT-5 Codex | Microsoft Foundry |
| Google Gemini 3 Pro Preview | GCP |
| OpenAI GPT-5.1 | Microsoft Foundry |
LLMの使用非推奨とサポート終了¶
Anthropic Claude Opus 3は2026年1月16日をもってサポートを終了しました。また、2026年2月16日をもって、Cerebras Qwen 3 32BとCerebras Llama 3.3 70Bもサポートを終了します。
予測AI¶
ワークベンチでハイパーパラメーターチューニングのサポートを開始¶
ハイパーパラメーターチューニングのインサイトを利用すると、モデルのハイパーパラメーターを手動で設定できます。これによりDataRobotでの選択内容がオーバーライドされ、モデルのパフォーマンス向上が期待できます。 When you provide new exploratory values, save, and build using new hyperparameter values, DataRobot creates a new child model using the best of each parameter value and adds it to the Leaderboard. さらに子モデルをチューニングして、変更の系統を作成できます。 ハイパーパラメーターは、テーブルまたはグリッドビューで表示および評価できます。
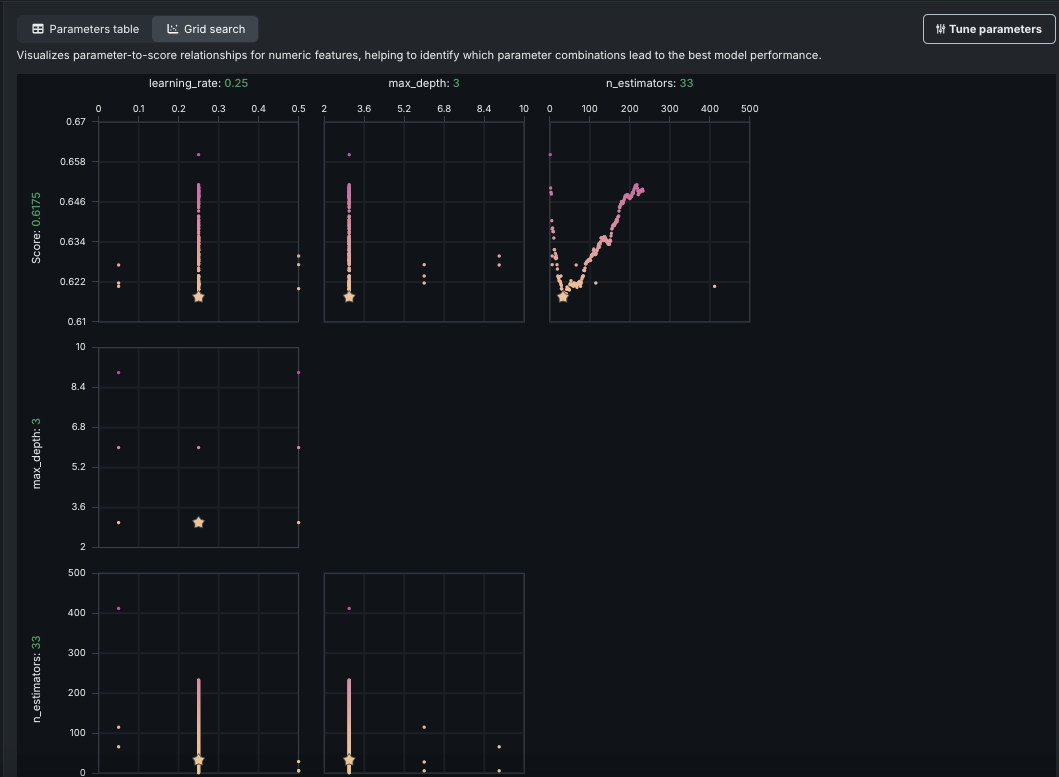
さらに、このリリースではベイズ探索のオプションが追加され、探索とチューニングにかかる時間のバランスをインテリジェントに調整できます。
増分学習の強化により、大規模データセットの処理を最適化¶
特にシングルテナントSaaS環境の場合に、大規模データセットの処理におけるメモリーの問題に対処するため、このリリースでは新しいアプローチが導入されています。 DataRobotでは、ストリーミングまたはバッチを使用して1つのパスでデータセットを読み取り(層化抽出分割を除く)、処理時にチャンクを作成するようになりました。 この変更によりメモリー要件が大幅に低減され、一般的なブロックサイズは16MBから128MBになります。 これにより、大きなデータセットを小さなインスタンスにチャンク化(たとえば、60GBのインスタンスで100GBをチャンク化)できます。 チャンクはParquetファイルとして保存されるため、サイズがさらに小さくなります(50GBのCSVファイルは3~6GBのParquetファイルになります)。 この変更はすべての環境で利用できます。
MLOps¶
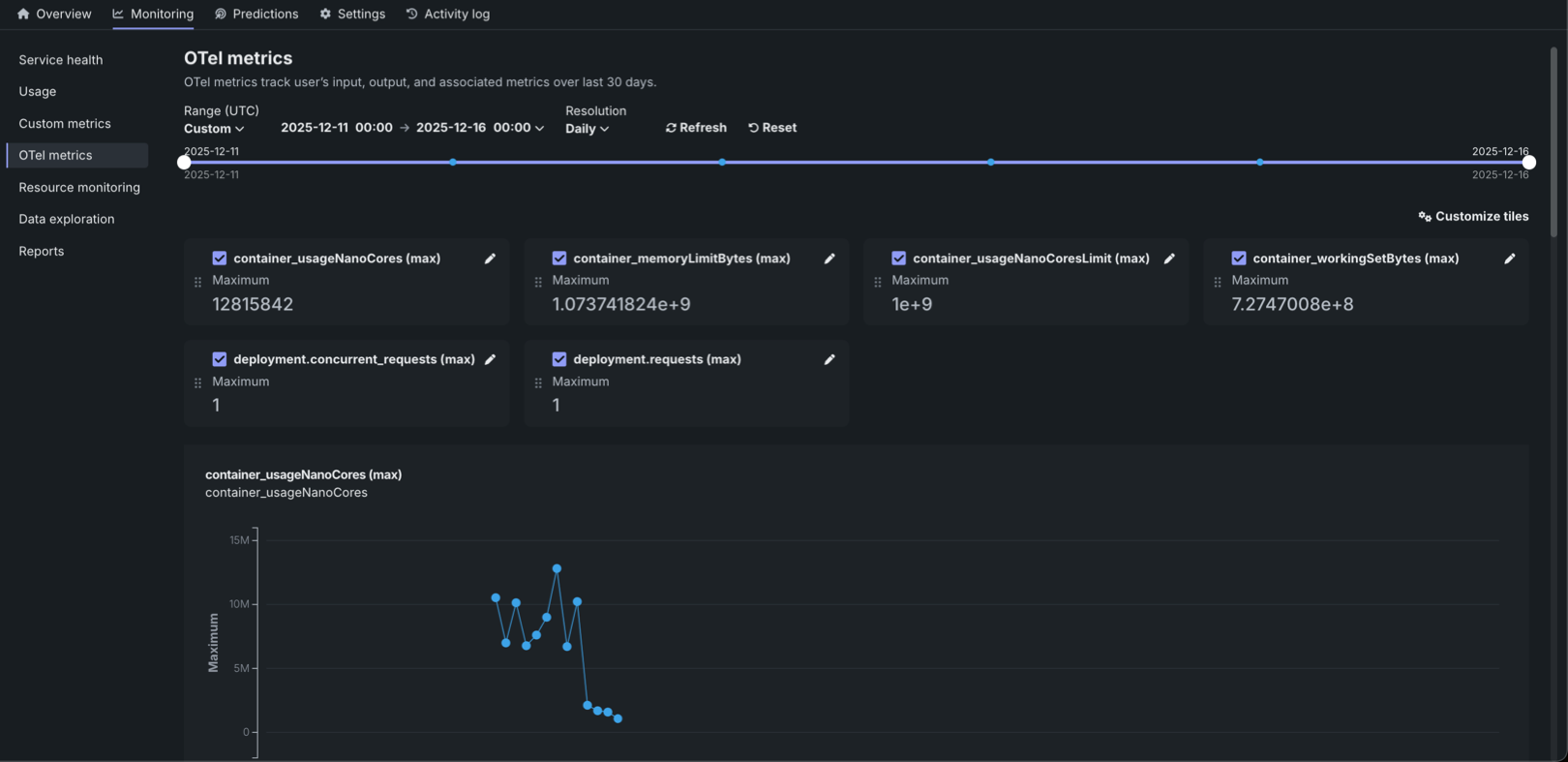
OpenTelemetryの指標とログ¶
OTel指標タブでは、デプロイのOpenTelemetry(OTel)指標を監視できます。これにより、アプリケーションやエージェントワークフローからの外部指標とDataRobotのネイティブ指標が可視化されます。 設定可能なダッシュボードには、最大50個の指標を表示できます。 指標は、自動削除されるまで30日間保持されます。 カスタマイズダイアログボックスで、指標名で検索してダッシュボードに指標を追加します。 監視する指標を選択したら、表示名の編集、集計方法の選択、トレンドチャートとサマリー値の切り替えを行って、表示を微調整します。 OTel指標はサードパーティのオブザーバビリティツールにエクスポートできます。
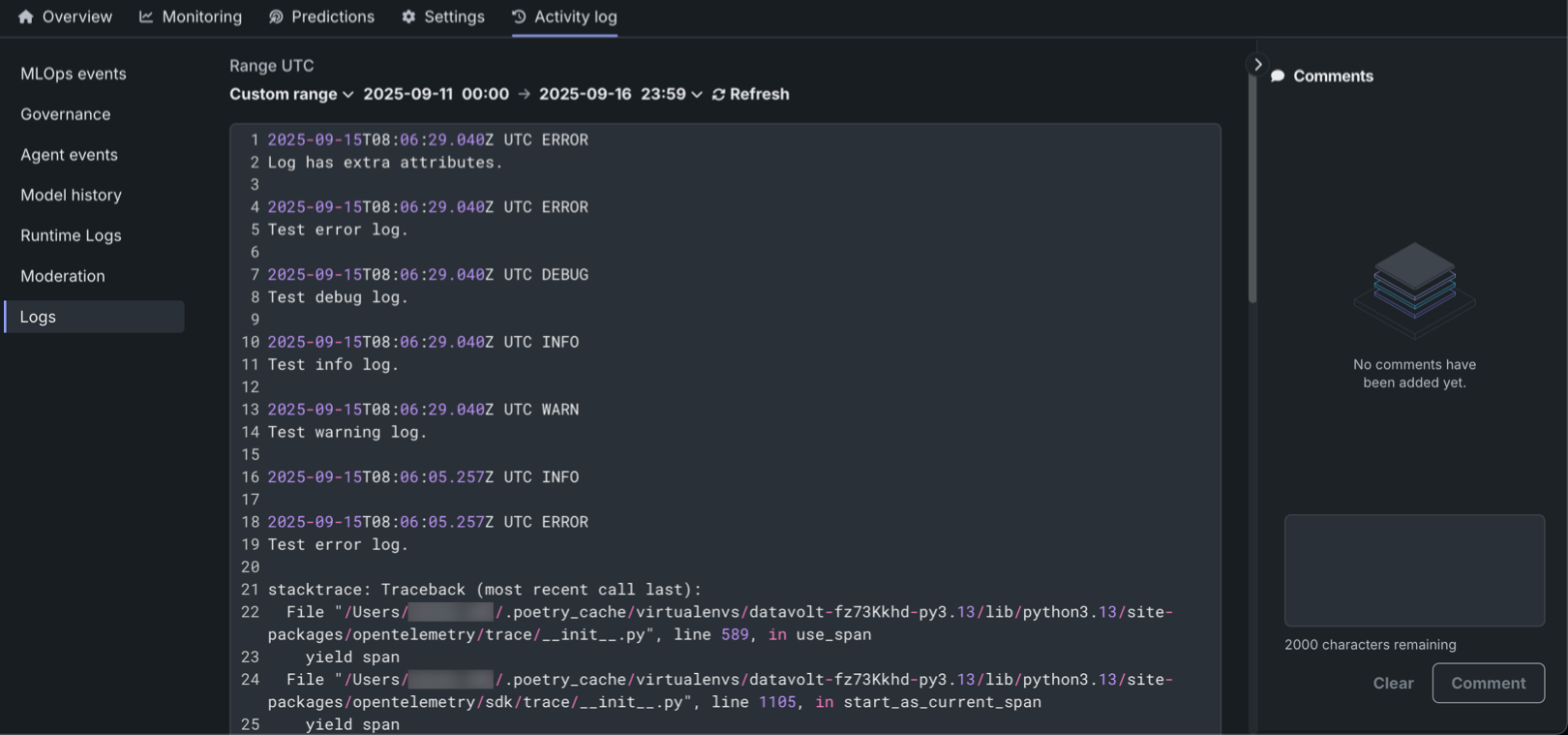
DataRobot OpenTelemetryサービスではOpenTelemetryのログが収集され、デプロイの詳細な分析とトラブルシューティングが可能です。 アクティビティログセクションのログタブでは、OpenTelemetry標準形式で報告されたデプロイのログを閲覧および分析できます。 ログはすべてのデプロイおよびターゲットタイプで入手可能であり、アクセスは「オーナー」および「ユーザー」ロールを持つユーザーに制限されています。 システムは4つのログレベル(INFO、DEBUG、WARN、ERROR)をサポートし、柔軟な時間フィルターオプションと検索機能が用意されています。 ログは自動削除されるまで30日間保持されます。 さらに、OTelログAPIを使用すると、プログラムによるログのエクスポートが可能になり、サードパーティ製のオブザーバビリティツールとの連携がサポートされます。 標準化されたOpenTelemetry形式により、各種監視プラットフォーム間での互換性が確保されます。
詳細については、OTel指標およびログのドキュメントを参照してください。
アプリケーション¶
アプリケーションのリソース使用状況を監視する¶
DataRobotの管理者とアプリケーションのオーナーは、個々のアプリケーションについて、使用状況、サービスの正常性、およびリソース消費量を監視できるようになりました。 これにより、問題を事前に検知し、パフォーマンスのボトルネックをトラブルシューティングし、サービスの中断に迅速に対応することが可能になり、ダウンタイムを最小限に抑え、ユーザーエクスペリエンス全体を向上させることができます。 リソース消費量の監視は、リソースが効率的に使用されていることを確認するためのコスト管理においても不可欠です。
アプリケーションの監視機能にアクセスするには、アプリケーションページで、確認したいアプリケーションの横にあるアクションメニュー を開き、サービスの正常性を選択します。
管理¶
非ビルダーユーザーを組織に追加する¶
管理者が、組織に非ビルダーユーザーを追加できるようになりました。 非ビルダーユーザーは、参加する組織に関連付けられたアプリケーションと、ユーザーの基本設定のみにアクセスできます。 アプリケーションを操作する際、予測の実行、プロンプトの追加、チャットの開始、表示/削除、およびデータのアップロードを行うことができます。
非ビルダーユーザーを追加するには、既存のユーザーアカウントに非ビルダーのシートライセンスを割り当てるか、新しいユーザーを招待する機能を使用して、一度に最大20名まで招待することができます。 なお、非ビルダーユーザーは、組織の最大アクティブユーザー割り当て数には含まれません。
コードファースト¶
Pythonクライアントv3.12¶
Pythonクライアントのv3.12が一般提供されました。 v3.12で導入された変更の完全なリストについては、Pythonクライアントの変更履歴を参照してください。
DataRobot REST API v2.41¶
DataRobotのREST API v2.41が一般提供されました。 v2.41で導入された変更の完全なリストについては、 REST APIの変更履歴を参照してください。
リリース11.5.0で修正された問題¶
アプリの修正¶
-
APP-5129:「データと会話する」アプリの安定性とユーザーエクスペリエンスが向上しました。
-
APP-5154:Q&Aチャットカスタムアプリケーションにおいてカスタム指標の関連付けIDの欠落を修正しました。
-
APP-5208:アプリ管理者がカスタム環境エンティティで読み取りおよび書き込みアクセス権限を持つようになりました。
-
APP-5239:すべてのカスタムアプリのリクエストタイムアウトを60秒から300秒に引き上げました。
エージェントの修正¶
-
BUZZOK-28718:LLMブループリントのカスタムモデルにおいて、未使用のランタイムパラメーターを削除しました。
-
BUZZOK-28953:データセットおよびメタデータデータセットの列名として、英語または日本語、あるいはその両方を組み合わせて、ベクターデータベースを作成できるようにサポートを追加しました。
データの修正¶
-
DM-19760:特徴量探索の実行時に「有用な特徴量」特徴量セットが作成されていない場合、詳細なエラーメッセージが表示されるようになりました。 通常、この特徴量セットが作成されないのは、データセットに含まれている特徴量では情報が少ない場合のみです。
-
DM-19771:カスタムドライバー接続の作成時に、ペイロード内で誤ったドライバーIDが送信される可能性のある問題を修正しました。
コアAIの修正¶
-
MODEL-21651:セグメント化された統合モデルのバッチ予測において、誤ったしきい値チェックによってブロックされる問題が修正されました。
-
MODEL-21916:バッチ予測APIまたは予測APIからのSHAP説明において、SHAP強度がゼロの特徴量が含まれる場合、その特徴量が特徴量セットにない列(同様にSHAP強度がゼロ)と混在する可能性があった問題を修正しました。 これにより、説明は適切にフィルターされ、モデル特徴量セットに実際に含まれる列、またはモデルで使用されている列のみが表示されるようになりました。
-
MMM-21322:データ品質タブにおけるプロンプトレポートに関する問題を修正しました。 これにより、デプロイで
association_idやPROMPT_COLUMN_NAMEが指定されていない特定のケースがないかチェックされ、ユーザーがトレースに移動して詳細情報を取得できるようになりました。 -
MMM-21436:Kedaの
modmonプロセス向けオートスケーラーは、Postgresホストにdr-commonを使用するようになりました。 -
MMM-21464:ユーザーアクティビティモニターにデプロイ共有アクションが記録されない問題を修正しました。
-
MMM-21749:特定の状況において、バッチ監視ジョブが失敗し、クラスターログにエラーメッセージのみが記録されることがありました。 今後は、ユーザーにもエラーが記録されます。
-
MMM-21556:DataRobotサーバーレス予測で、環境が実際にDataRobotサーバーレスである場合に「予測環境はDataRobotサーバーレスである必要があります...」というエラーが発生する問題を修正しました。 この修正により、プラットフォームタイプの不一致エラーが発生しなくなり、サーバーレス以外のエンタープライズ環境と同様の操作性になりました。
-
PRED-12214:カスタムモデル向けのJSONペイロード内の文字列値が、数値として扱われることがある問題を修正しました。
-
PRED-12117:AKS環境で実行されているサーバーレス予測において、予測データの監視が機能しない問題を修正しました。
-
RAPTOR-15740:組織内でのカスタムモデル予測レプリカの最大数の上限を16から25に引き上げました。
プラットフォームの修正¶
-
CMPT-4296:プライベートレジストリにおける認証用のv2エンドポイントのサポートを拡張しました。
-
CMPT-4324:イメージタグを公開するためにPulumiラッパーを拡張しました。
-
CMPT-4341:実行マネージャーがRabbitMQとの接続を失った場合(RabbitMQの再起動後など)の自動復旧機能を実装することで、システムの安定性が向上しました。 この措置により、アプリケーションのジョブ処理の継続が確保されます。
-
CMPT-4387:イメージスキャン機能を設定できるように、build-serviceの
values.yamlを更新しました。 -
CMPT-4599:
values.yamlのグローバルセクションにあるイメージビルダーのtolerationsおよびnodeSelector設定を修正しました。 -
FLEET-3153:
global.extraEnvVarsが指定されている場合、datarobot-primeHelmチャートのインストールまたはアップグレードが失敗する問題を修正しました。 -
PLT-19773:ユーザーに対して明示的な値が設定されていない場合でも、ユーザー権限タブに組織レベルまたはシステムレベルのデフォルト値が誤って入力される問題を修正しました。 現在では、値が明示的に設定されていない場合、システムは編集フィールドに値を正しく割り当てて表示します。
コードの修正¶
- CFX-4351:NBXカーネルにおいて、Jupyter Kernel-Gatewayの認証トークンメカニズムのオプトイン使用を追加しました。 また、明示的に許可リストに登録されていないサービスとエンドポイントからの通信を禁止するカーネルを除外するために、制限の緩いノートブックのサービス間ネットワークポリシーを制限します。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。