MLOps(V7.1)¶
2021年6月14日
DataRobot MLOps v7.1リリースには、以下に示す多くの新機能が含まれています。
リリースv7.1では、以下の言語のUI文字列の翻訳が更新されています。
- 日本語
- フランス語
- スペイン語
Introducing Pricing 5.0¶
Pricing 5.0 introduces a number of capabilities supporting DataRobot MLOps:
-
各ユーザーまたは組織には、一度に実行できるアクティブなデプロイの数が設定されています。 The limit is displayed in the Deployment Inventory status tiles. Pricing 5.0のユーザーは、アクティブまたは非アクティブなデプロイでリーダーボードをフィルターできます。
-
Users who built models in AutoML can download model packages (.mlpkgs) to use the Portable Prediction Server directly from the model Leaderboard without engaging in the deployment workflow.
-
Users who built models in AutoML can download Scoring Code for the model via the model Leaderboard without engaging in the deployment workflow. 以前は、スコアリングコードをダウンロードすると、関連するデプロイが永続的に使用されていました。 現在、これらのデプロイは非アクティブにすることや削除することができるようになりました。 さらに、ユーザーはスコアリングコードのダウンロードに予測の説明を含めることができます。
新機能と機能強化¶
See details of new deployment features below:
- Now GA: Improved monitoring support for multiclass deployments
- Automatic actuals feedback for time series deployments
- Now GA: Use challenger models with external deployments
The following new deployment features are currently in public beta. この機能を有効にする方法については、DataRobotの担当者にお問い合わせください:
- デプロイレポート
- Reset deployment statistics
- The management agent
- Baseline revisions for external models
新しい予測機能¶
See details of new prediction features below:
- Batch prediction cloud connectors
The following new prediction features are currently in public beta. この機能を有効にする方法については、DataRobotの担当者にお問い合わせください:
- Snowflakeのスコアリングコード
- Include prediction explanations in Scoring Code
- Batch prediction job definitions and scheduling
- MLOps agent: Kafka
- ポータブルバッチ予測
- Batch prediction Parquet support
- Improved batch predictions for custom models
新しいモデル登録機能¶
See details of new model registry features below:
- Upload environments as prebuilt images
- Now GA: Integrate a Bitbucket Server or GitHub enterprise repository with custom inference models
- Now GA: Custom Inference Anomaly Detection
新しいガバナンス機能¶
See details of new governance features below:
- Feature lists added to governance metadata
新しいデプロイ機能¶
Release v7.1 introduces the following generally available deployment features.
デプロイのセグメント化された分析を改善¶
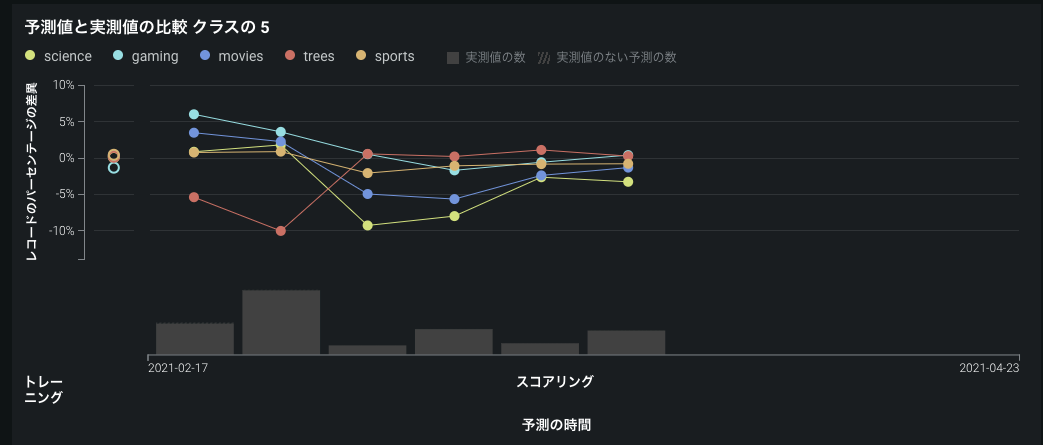
Now generally available, multiclass deployments have additional monitoring support. Multiclass deployments offer class-based configuration to modify the data displayed on the Accuracy and Data Drift graphs. Use the class selector to display the desired classes for a deployment. DataRobotには、クラスのクイック選択ショートカット(トレーニングデータで最も一般的な5つのクラス、精度スコアが最も低い5つのクラス、データドリフトが最も多い5つのクラス)が用意されています。 Once specified, the charts on the tab (Accuracy or Data Drift) update to display the selected classes.
Automatic actuals feedback for time series deployments¶
Time series deployments that have indicated an association id can enable the automatic submission of actuals, so that you do not need to submit them manually via the UI or API. 有効にした場合、予測の生成に使用されるデータから実測値を抽出できます。 各予測リクエストが送信されると、DataRobotは特定の日付の実測値を抽出できます。 これは、予測行を予測に送信すると、履歴データが含まれるためです。 This historical data serves as the actual values for the previous prediction request.
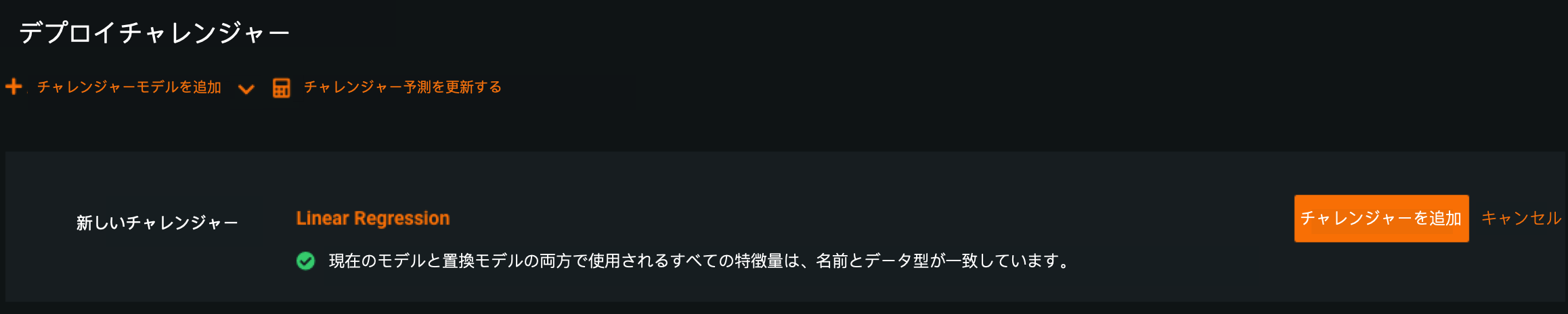
チャレンジャーモデルが外部デプロイで利用可能になりました¶
Deployments in remote prediction environments can use the Challengers tab. Remote models can serve as the champion model, and you can compare them to DataRobot and custom models challengers. If you want to replace the champion model with a challenger, you can also replace the model with a custom or DataRobot challenger model and deploy the new champion to your remote prediction environment.
New public beta deployment features¶
Release v7.1 introduces the following public beta deployment features.
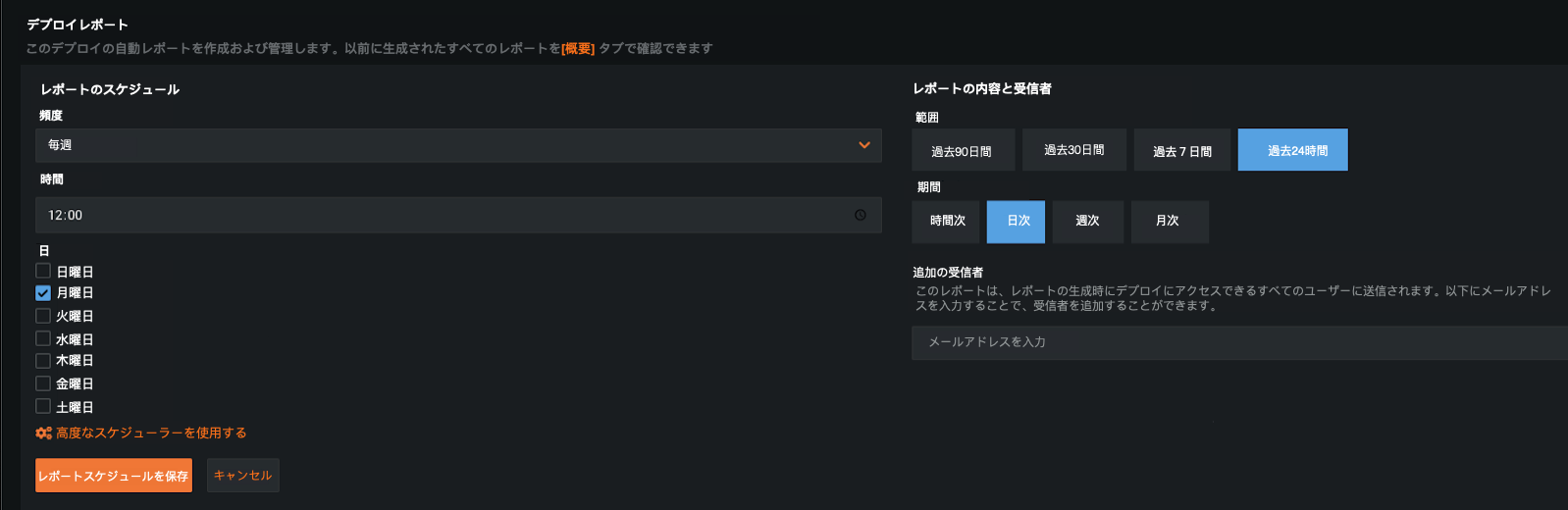
デプロイレポート¶
You can now generate a deployment report on-demand, detailing essential information about a deployment's status such as insights about service health, data drift, and accuracy statistic (among many other details). Additionally, you can create a report schedule that acts as a policy to automatically generate deployment reports based on the defined conditions (frequency, time, and day). When the policy is triggered, then a new report is generated and DataRobot sends an email notification to those who have access to the deployment.
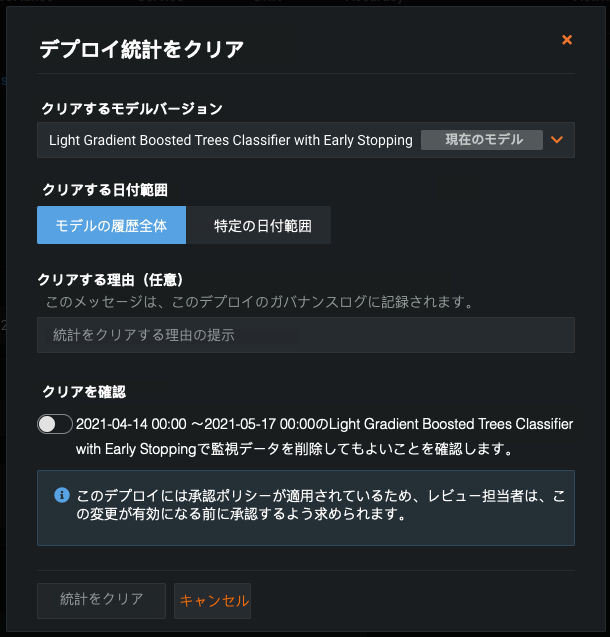
デプロイ分析をリセットする¶
Deployments now support the deletion of monitoring data by model or time range. This action is governed by the approval workflow to safeguard against accidental deletion. この機能により、誤って送信された監視データや、モデルをデプロイする際の結合テストの段階で送信された監視データをデプロイから削除することができます。
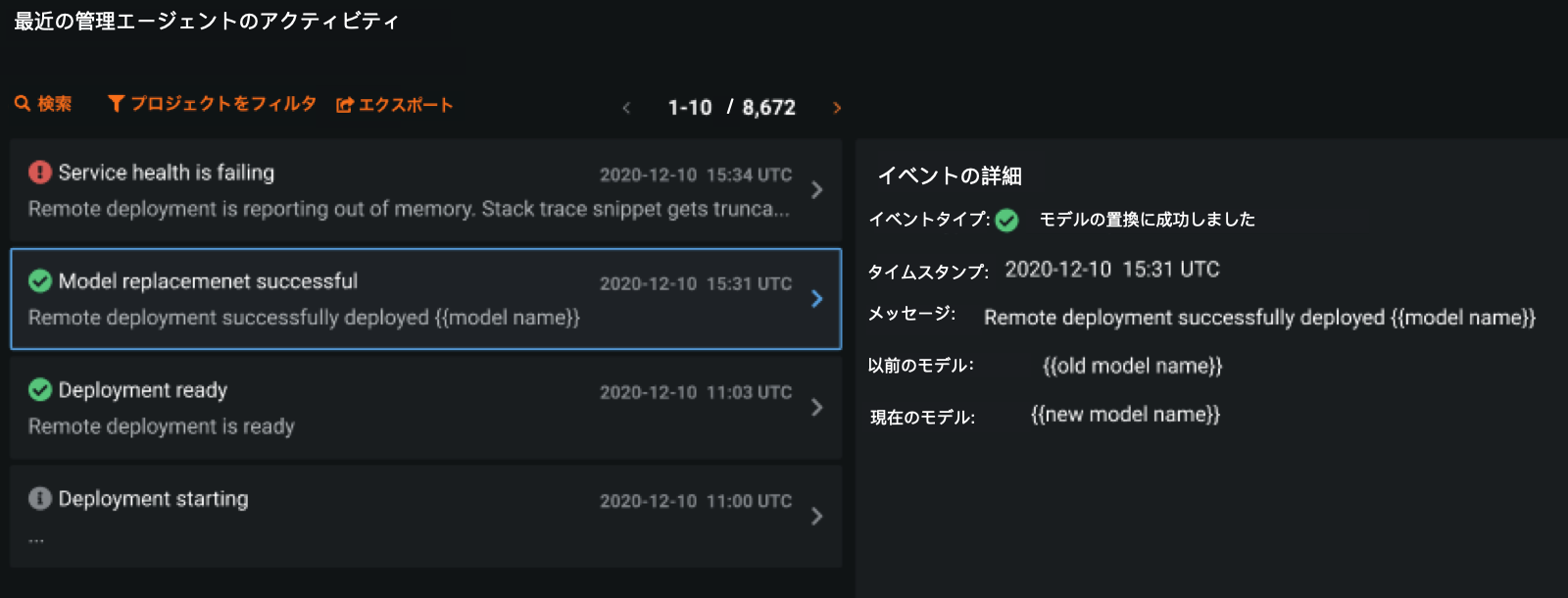
The management agent¶
DataRobot is introducing the management agent, which understands the state of a deployment and can automate the task of retrieving artifacts, deploying models, and replacing them externally. The agent is extensible to support a variety of use cases in various model formats and prediction environments. Administrators can configure the management agent in their prediction environments to automate the deployment and replacement of models based on user actions within MLOps. It pairs easily with the MLOps Agent to automatically monitor models and integrate them with additional MLOps functionality such as challenger models. The management agent is a tool for standardizing and automating model deployment.
Baseline revisions for external models¶
Binary classification models deployed to remote environments can now be registered with Holdout data, allowing external deployments to calculate additional drift and accuracy baselines previously only available to models built with DataRobot AutoML. When monitoring accuracy, you can now compare the current accuracy calculation to the baseline at the time of training the model. Additionally, target drift now supports more detailed drift analysis using prediction values prior to the application of the prediction threshold.
新しい予測機能¶
Release v7.1 introduces the following generally available prediction features.
Batch prediction cloud connectors¶
The batch prediction API now supports connectors specific to Snowflake and Azure Synapse for the ingest and export of data while scoring. The use of JDBC to transfer data can be costly in terms of input/output operations per second (IOPS) and expenses for data warehouses. このアダプターは、クラウドストレージと一括挿入を使用してハイブリッドJDBCクラウドストレージソリューションを作成することで、予測スコアリング時のデータベースエンジンの負荷を軽減させます。
New public beta prediction features¶
Release v7.1 introduces the following public beta prediction features.
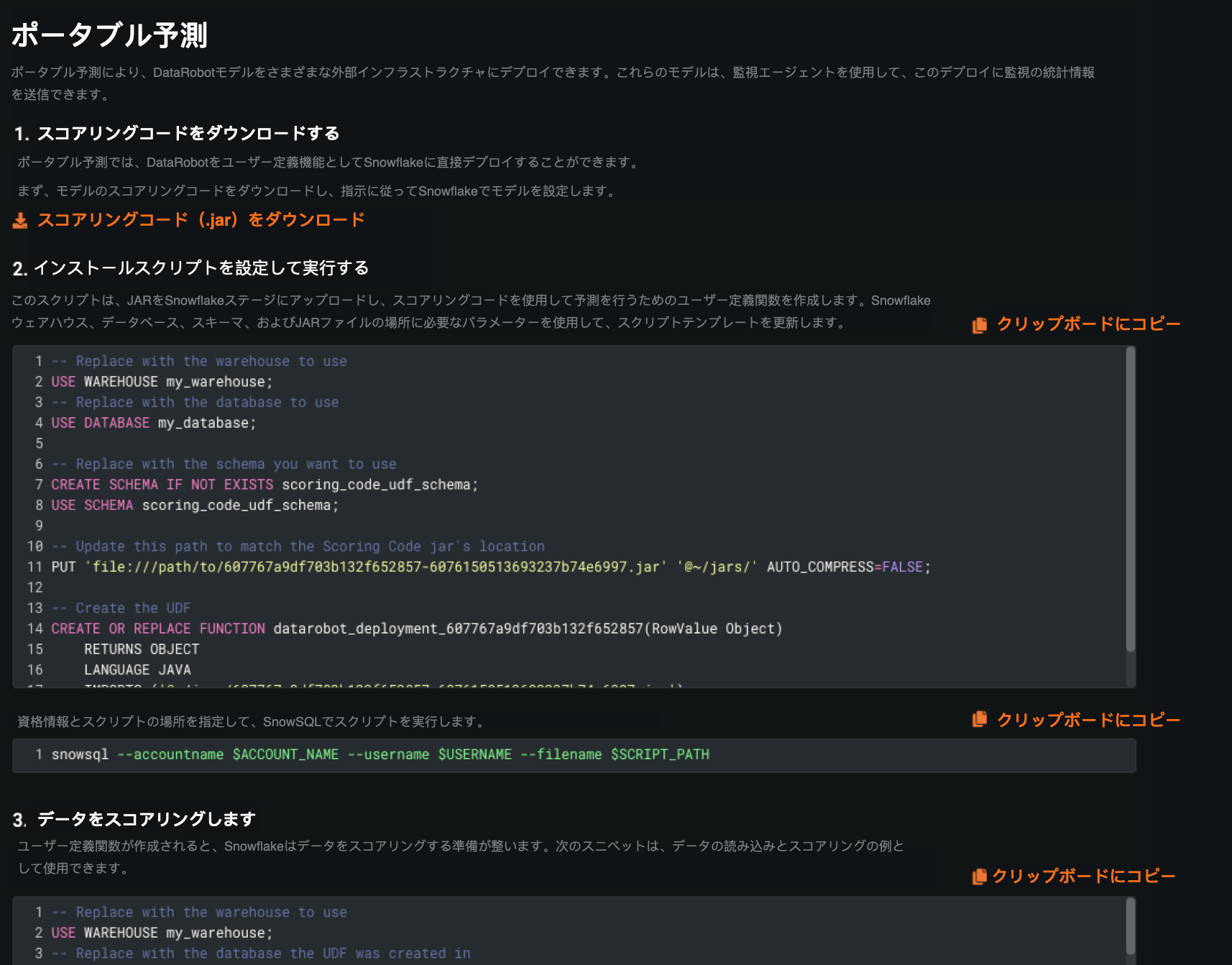
Snowflakeのスコアリングコード¶
DataRobot Scoring Code now supports execution directly inside of Snowflake using Snowflake’s new Java UDF functionality. This capability removes the need to extract and load data from Snowflake, resulting in a much faster route to scoring large datasets. The Portable Predictions tab for deployments has been tailored to enable this functionality when the deployment is created in a Snowflake prediction environment.
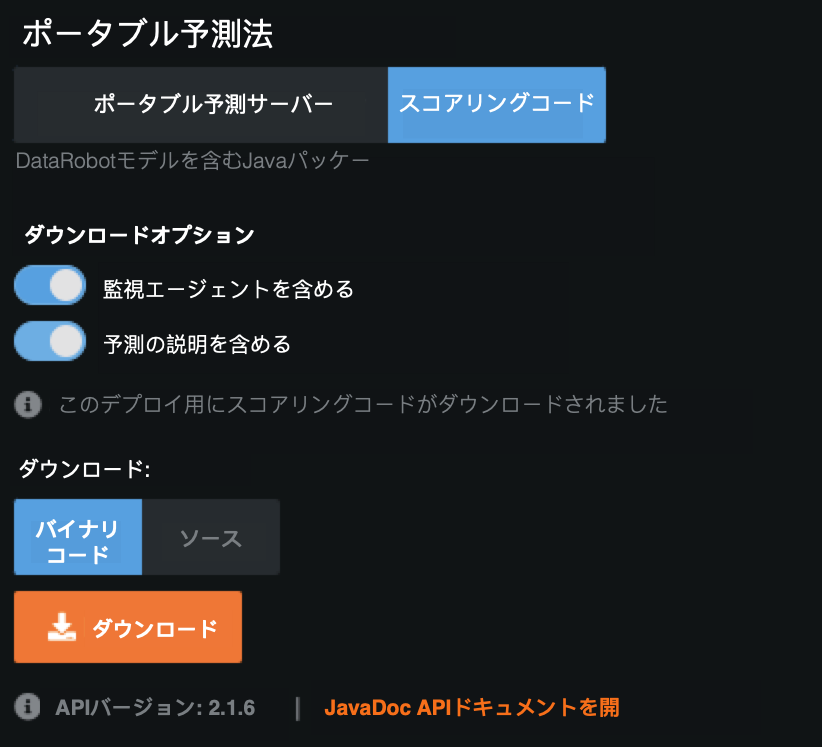
Include prediction explanations in Scoring Code¶
You can now receive prediction explanations anywhere you deploy a model: in DataRobot, with the Portable Prediction Server, and now in Java Scoring Code. Prediction explanations provide a quantitative indicator of the effect variables have on the predictions, answering why a given model made a certain prediction. You can enable prediction explanations on the Portable Predictions tab when downloading a model via Scoring Code.
Batch prediction job definitions and scheduling¶
When making batch predictions for deployments via the Make Predictions tab, you can now create and schedule JDBC and cloud storage prediction jobs directly from the deployment without utilizing the API. Additionally, you can view a history of the prediction jobs that ran. Define the name of the job, the prediction source, configurations, and the prediction destination. All specifications are saved for later use.
New MLOps agent channel: Kafka¶
The MLOps agent now supports Kafka as a channel, in addition to previously supported channels: File, AWS SQS, Google Pub, Google Sub, and RabbitMQ. The agent can now be easily deployed to many prediction environments and Kafka support, eliminates the need for additional queuing services.
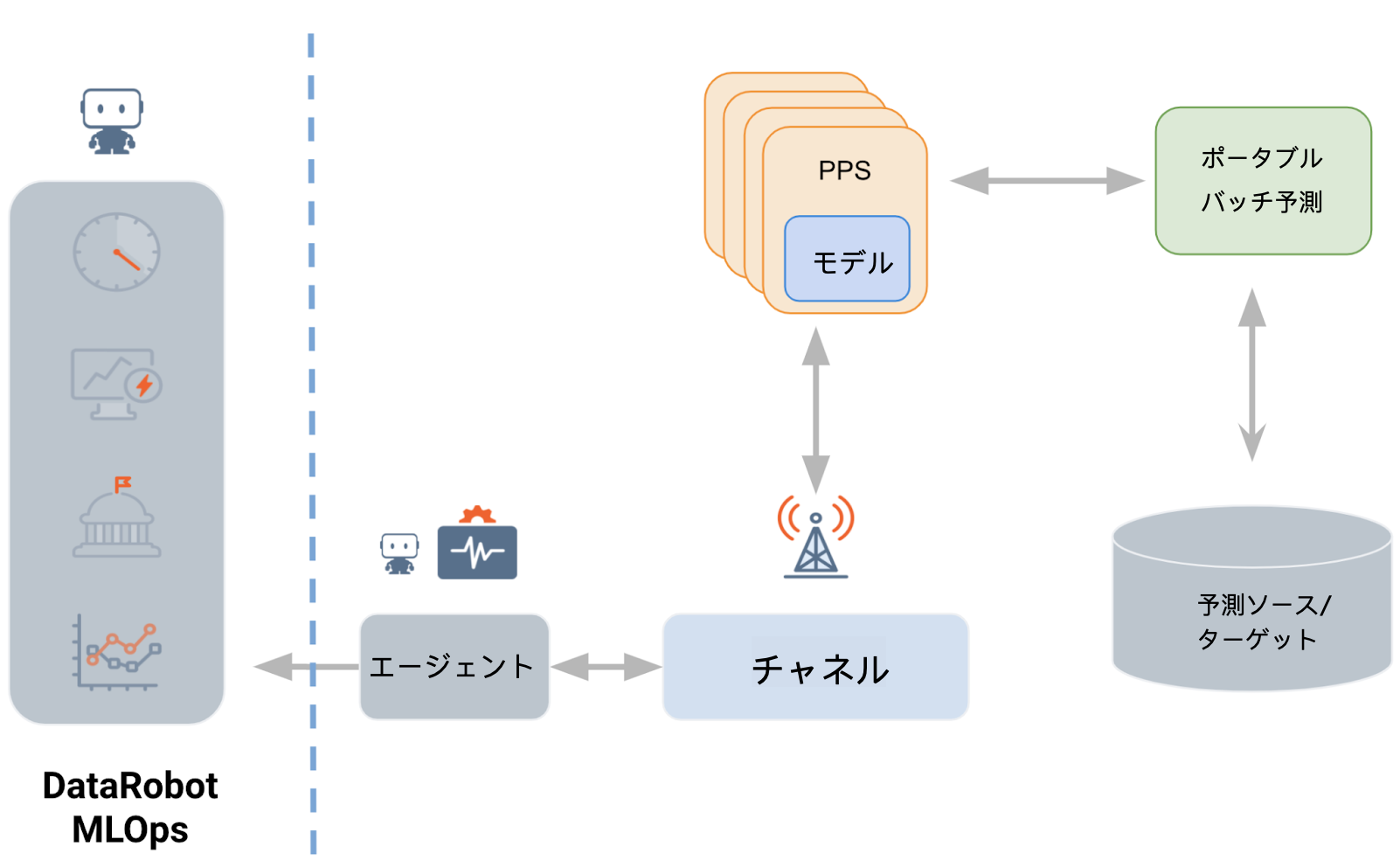
ポータブルバッチ予測¶
The Portable Prediction Server can now be paired with an additional container to orchestrate batch predictions jobs using file storage, JDBC, and cloud storage. You no longer need to manually manage the large scale batching of predictions while utilizing the Portable Prediction Server. Additionally, large batch predictions jobs can be collocated at or near the data, or in environments behind firewalls without access to the public Internet
Batch prediction Parquet support¶
The batch prediction API has been enhanced to support Parquet-formatted files for both ingest and output with cloud storage connections (Azure Blob Storage, Google Cloud Storage, and Amazon S3). Parquet file format support removes the need to implement an additional conversion step in prediction pipelines.
Improved batch predictions for custom models¶
For custom model deployments, batch prediction replica configuration enhances performance and stabilizes large prediction jobs.
新しいモデル登録機能¶
Release v7.1 introduces the following generally available model registry features.
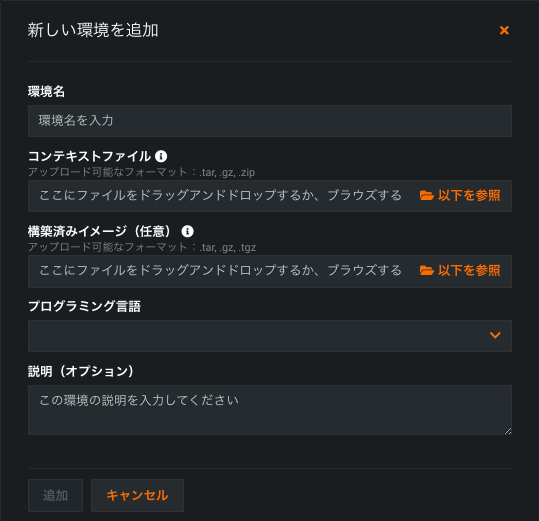
Upload environments as prebuilt images¶
You can now upload environments for custom models as prebuilt images. This image is a Docker image saved as a tarball in .tar, .gz, or .tgz format. If you provide a prebuilt image, you do not need to provide a context file for the environment (the tarball archive containing the Dockerfile and any other relevant files). If you supply a prebuilt image or build an environment with a context file, you can then download the built environment image as a .tar file.
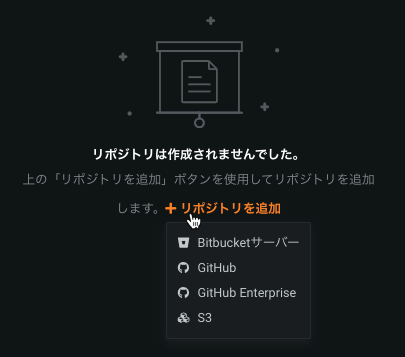
GitHub Enterprise and Bitbucket Server integration for custom models¶
Users can now register GitHub Enterprise and Bitbucket Server repositories in the Model Registry to pull artifacts into DataRobot and build custom inference models. Integrating either of these repositories allows you to directly transfer between a governed, code-centric machine learning development environment and a governed MLOps environment.
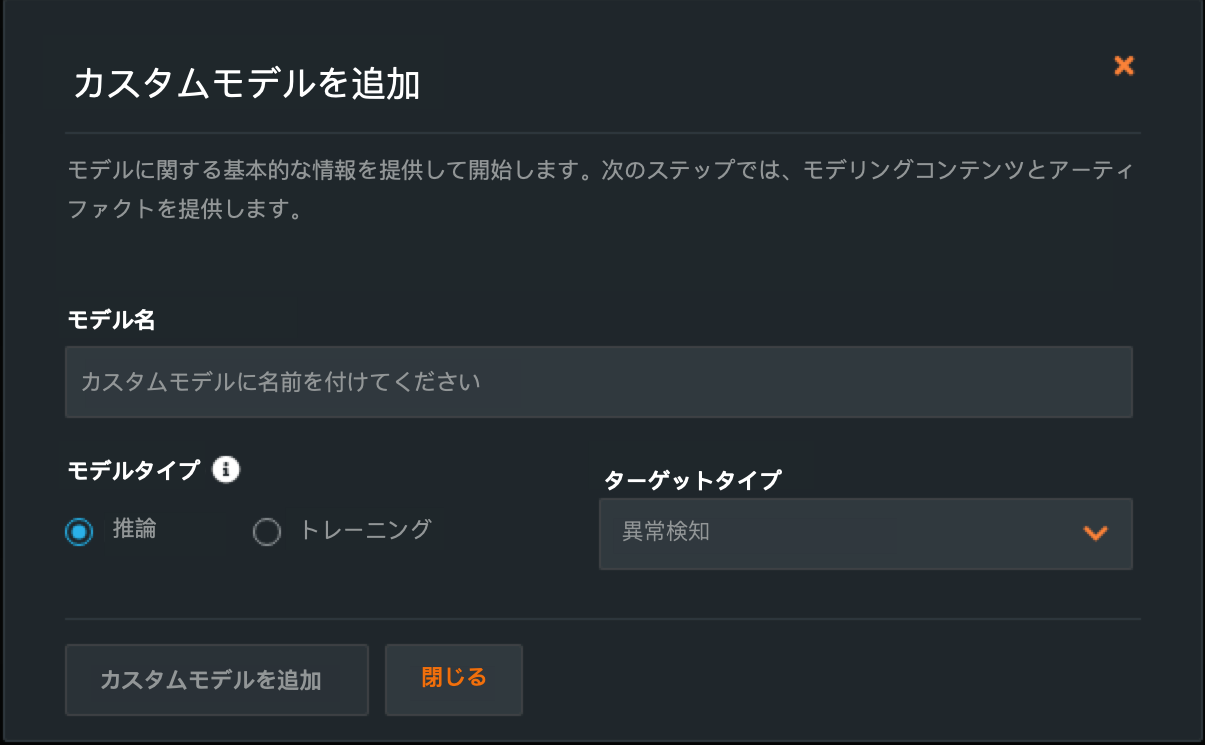
Custom inference anomaly detection models¶
Now available generally available, you can create a custom inference model for anomaly detection problems. When creating a custom model, you can indicate "Anomaly Detection" as a target type. Additionally, access the DRUM template for anomaly detection models. For deployed custom inference anomaly detection models, note that the following functionality is not supported:
- データドリフト
- 精度と関連付けID
- チャレンジャーモデル
- 信頼性ルール
- 予測の説明
New public beta governance features¶
Release v7.1 introduces the following public beta features.
Feature lists added to governance metadata¶
The Model Registry and deployments have been enhanced to allow you to view a model's feature list and feature importance. You can now access this metadata without navigating back into the original modeling project to understand the full list of features for their model.
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。