生成AI(V11.1)¶
2025年7月17日
スケーラブルでガバナンスの効いたAIアプリケーション開発のためのエージェント型AIプラットフォームを発表¶
プレミアム機能
DataRobotの生成AI機能はプレミアム機能です。詳細については、DataRobotの担当者にお問い合わせください。 DataRobotの試用版では、この機能を制限付きでお試しいただけます。
バージョン11.1.0のリリースでは、新しいエージェント型AIプラットフォームをローンチしました。このプラットフォームでは、スケーラブルなエージェント型AIアプリケーションの構築、運用、ガバナンスが可能です。 ほとんどのアプリ開発者はローカルのIDEでエージェントの構築を始めるため、DataRobotではテンプレートとCLIを提供して、シームレスなローカル開発、DataRobotへのコードの移行、プラットフォーム機能へのフックを促進します。 これにより、本番環境向けのエージェントプロトタイプを準備できます。これには、高度なエージェントデバッグおよびエクスペリメントツール(トラブルシューティング、評価、DataRobot Codespaceによる個々のコンピューティングインスタンスでのエージェントフローのガードモデルのテスト)の適用も含まれます。 エージェントフローを使用すると、フローを並べて比較し、詳細なエラーレポートを作成してトラブルシューティングを容易にしたり、OTEL準拠のトレースを使用してエージェントの各コンポーネントを監視できるようにしたりできます。
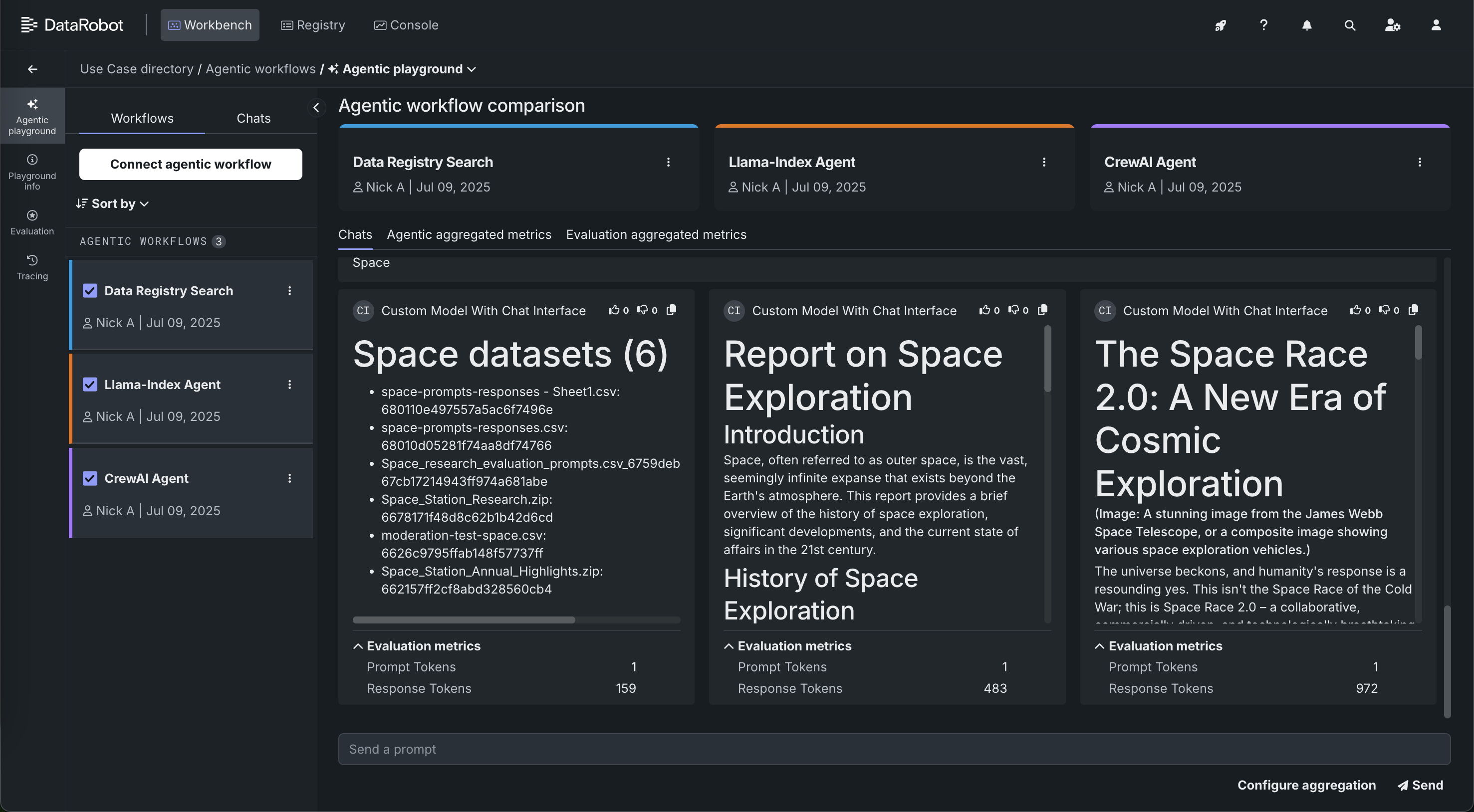
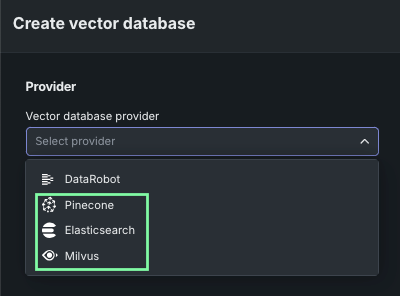
グローバルツールは、ツールレベルの認証とともに一般的なユースケースで利用できるため、エージェントを安全に本番環境に導入できます。 DataRobotでは、Azure OpenAI、Bedrock、GCPなどの主要プロバイダーのサーバーレスLLMとの"Batteries Included"の連携も提供しており、LLM gatewayを介して、シームレスなエクスペリメント、ガバナンス、オブザーバビリティを実現します。 最終的に、開発中および本番環境で使用するために、独自のPineconeまたはElasticsearchベクターデータベースに接続できるようになりました。これにより、LLMに適切なコンテキストを提供するスケーラブルなベクターデータベースを利用できます。
これらはすべて、他のいくつかの新機能と一緒に使用できます。 DataRobotでは、エアギャップ環境やソブリンクラウドでNVIDIA推論マイクロサービス(NIM)をワンクリックでデプロイできます。 エージェントのワークフローで使用されるすべてのツールとモデルのための一元化されたAIレジストリでは、堅牢な承認ワークフロー、RBAC、およびカスタムアラートが用意されています。 リアルタイムでのLLMへの介入とモデレーションが、すぐに使えるガードとカスタムガードでサポートされています。これには、コンテンツの安全性とトピックレールのためのNVIDIA NeMoとの連携も含まれます。 GenAIのコンプライアンステストおよびドキュメントは、規制要件を満たすために、PII、プロンプトインジェクション、毒性、バイアス、および公平性に関するレポートを生成します。
11.1エージェントリリースの主な機能¶
エンドツーエンドのエージェントワークフローの主な機能の一部を以下に示します。その他のGenAI機能については、以降のセクションで説明します。
-
LangGraph、LlamaIndex、CrewAIなどのフレームワークで構築された独自の(BYO)エージェントワークフローをレジストリワークショップから新しいエージェントプレイグラウンドに持ち込み、テストとファインチューニングを行います。
-
マルチエージェントフレームワークを活用したテンプレートからエージェントを構築およびデプロイします。 LangGraph、CrewAI、またはLlamaIndexを使用して、DataRobotまたは任意のローカル開発環境でエージェントを開発します。 デコレーターを使用すると、DataRobotはツール間、モデル間などの相互関係を自動認識します。
-
エージェントレベルとプレイグラウンドレベルの指標を活用します。
-
シングルエージェントとマルチエージェントのチャット比較機能。
-
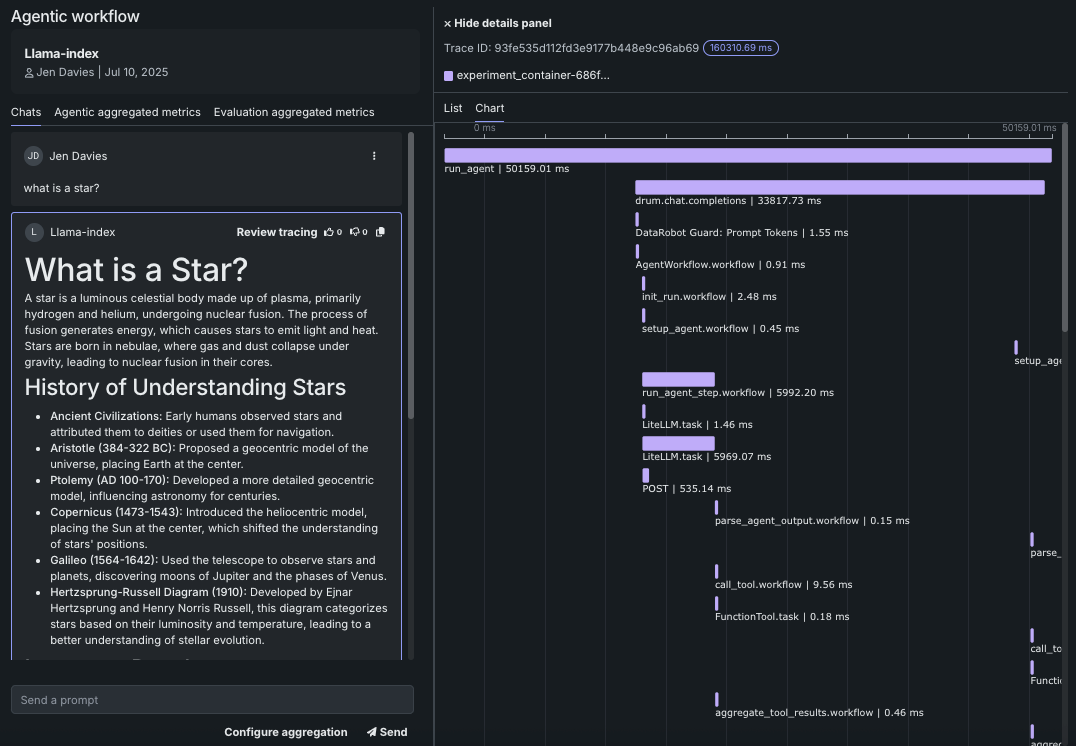
エージェントレベルとツールレベルの両方の指標を使用した根本原因分析のための詳細なトレース。
-
DataRobot Codespacesを使用した反復的なエクスペリメントにより、エージェントプレイグラウンドでのテストと並行して、エージェントワークフローを開発します。
-
RAGルックアップ、LLMの回答品質、ユーザー定義のガードレールの有効性を評価するためのテストスイート。 評価データを合成的に生成または定義し、LLMと組み込みのNLP指標を使って回答の品質(正確性、忠実度、ハルシネーションなど)を判定します。 設定可能な「ジャッジとしてのLLM」が、プロンプトとコンテキストに基づいて回答を評価します。 合成例は、グラウンディングデータ内の内容に基づいて自動的に生成されます。
-
レジストリとコンソールで、以下のような監視とガバナンスを行います。
-
エンドツーエンドの監視。ツールとエージェントの両レベルで、機能指標と運用指標を用いて、実行フローを視覚的にトレースします。 各実行フローの詳細なトレースには、ツールの使用状況やLLMの入出力が含まれます。
-
レジストリおよびコンソールにエージェントとツールを登録およびデプロイして、本番環境で利用可能なガバナンス、監視、軽減、およびモデレーションの機能を有効にします。
-
エージェントのフロー(PII、関連性、ジェイルブレイク、ヘイトスピーチなど)に、OSSと独自の評価およびモデレーションガードをデプロイします。
-
コンソールで、デプロイ済みのエージェントワークフローに、エージェントのコスト、プロンプトトークン、および出力トークンのカスタム指標を接続します。
-
GenAI全般の機能強化¶
GenAIのその他の新機能を以下に示します。 V11.1のその他の新機能もご参照ください。
NIMギャラリーでGPU向けに最適化された60以上のコンテナを探索¶
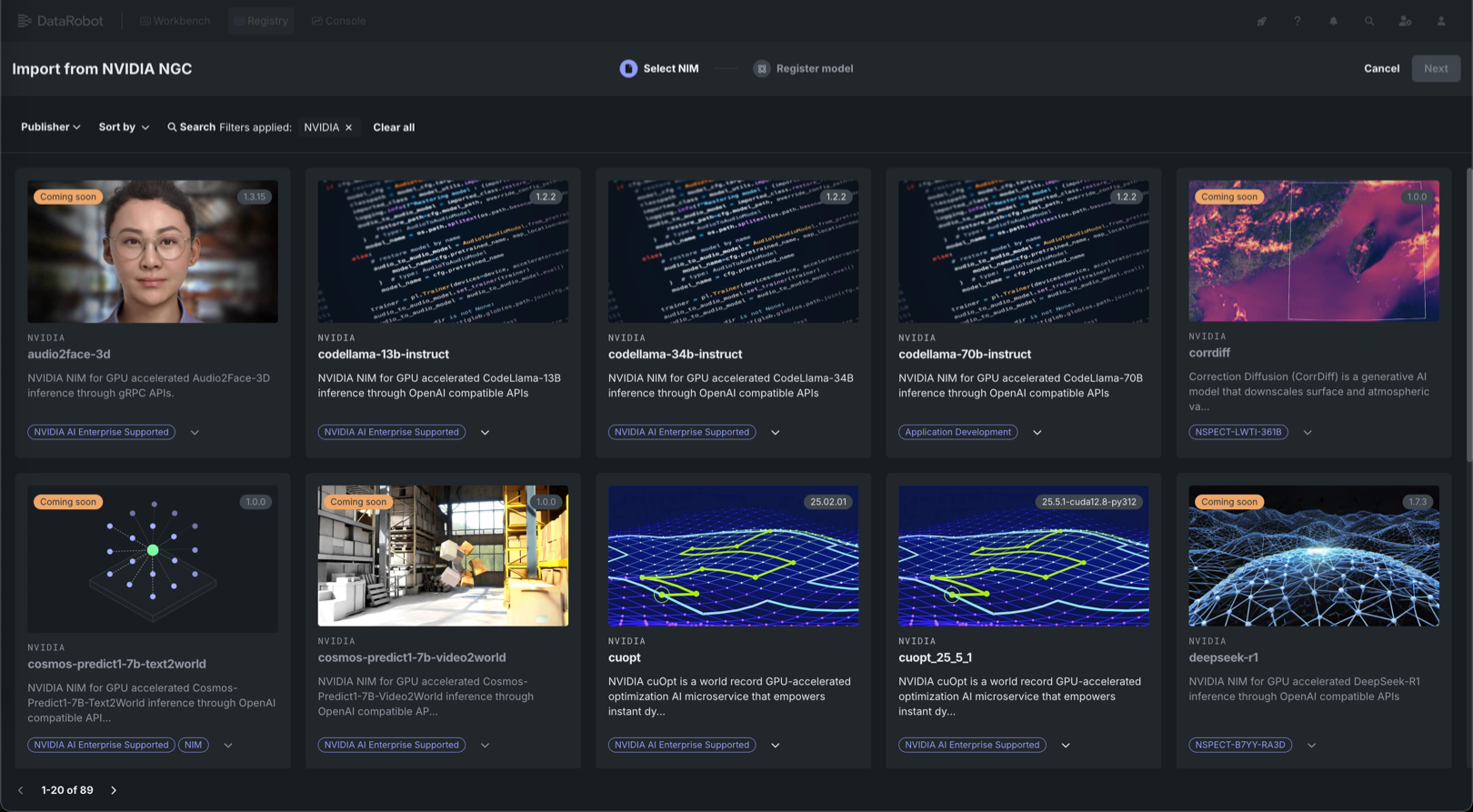
NVIDIA AI EnterpriseとDataRobotは、お客様の組織の既存のDataRobotインフラストラクチャと連携するように設計された、構築済みのAIスタックソリューションを提供しています。これにより、堅牢な評価、ガバナンス、および監視の機能を利用できます。 この連携には、エンドツーエンドのAIオーケストレーションのための包括的なツール群が含まれており、組織のデータサイエンスパイプラインを高速化し、DataRobot Serverless ComputeのNVIDIA GPUで運用レベルのAIアプリケーションを迅速にデプロイすることができます。
DataRobotでは、AIアプリケーションとエージェントのギャラリーからNVIDIA Inference Microservices (NVIDIA NIM)を選択して、組織のニーズに合わせたカスタムAIアプリケーションを作成します。 NVIDIA NIMは、生成AIの導入を企業全体で加速させることを目的として、NVIDIA AI Enterprise内で構築済みおよび設定済みのマイクロサービスを提供します。
バージョン11.1のリリースでは、GPU向けに最適化された以下のようなコンテナが、NIMギャラリーに新たに追加されました。
-
ドキュメント処理:OCR、ドキュメント解析、PDFやフォームからのインテリジェントなデータ抽出のためのPaddleOCRとNemoRetrieverスイート。
-
言語モデル:推論、コンテンツ生成、対話型AIのためのDeepSeek R1 Distill (14B/32B)とNemotron (Nano-8B/Super-49B)。
-
専門ツール:CuOptによる意思決定の最適化、StarCoder2-7Bによるコード生成、OpenFold2によるタンパク質フォールディング。
DataRobot LLM Gatewayの使用¶
プレミアム機能です。DataRobotのLLM Gatewayサービスは、外部LLMプロバイダーによってホストされているLLMと連携するためのDataRobot APIエンドポイントを提供します。 LLMの回答をDataRobotのLLM Gatewayに要求するには、OpenAI互換のチャット補完APIをサポートするAPIクライアント、たとえばOpenAI Python APIライブラリを使用します。
このサービスを使用するには、コードでDataRobot LLM Gatewayにリクエストを行う方法を確認してください。 または、プレイグラウンドからのテキスト生成カスタムモデルで、ENABLE_LLM_GATEWAY_INFERENCEランタイムパラメーターをTrueに設定して、そのモデルのゲートウェイを使用します。
サービスとしてのベクターデータベース¶
ユースケースでベクターデータベースを作成する際に、DataRobotか、PineconeまたはElasticsearchへの直接接続(外部データソース)を選択できるようになりました。 これらの接続では、最大100GBのファイルサイズをサポートします。 接続すると、データソースがデータレジストリにローカルに保存されて、構成設定が適用され、作成されたベクターデータベースがプロバイダーに書き戻されます。 PineconeまたはElasticsearchを選択する場合、資格情報と接続情報を提供します。 その他の点では、これらの注意事項を除き、DataRobotに常駐するFacebook AI Similarity Search (FAISS)ベクターデータベースと同じフローになります。
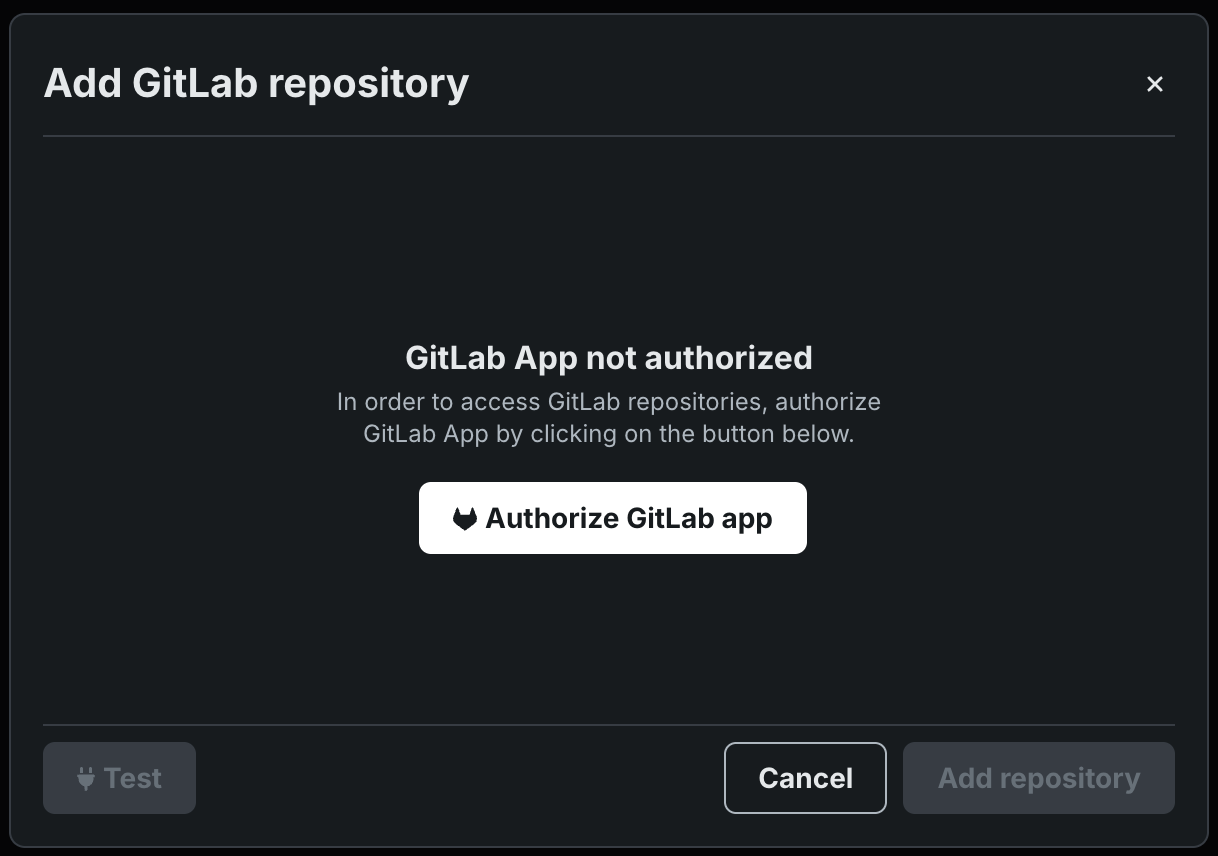
GitLabリポジトリとの連携¶
GitLabおよびGitLab Enterpriseリポジトリに接続し、カスタムモデルファイルをワークショップにプルすることで、カスタムモデルやカスタムエージェントワークフローの開発と構築を加速します。
プロンプトクエリーをフィルターするためにメタデータを添付する¶
追加のファイルを選択して、ベクターデータベース内のチャンクに添付するメタデータを定義できます。 重複を置換するか、保持するかを選択します。
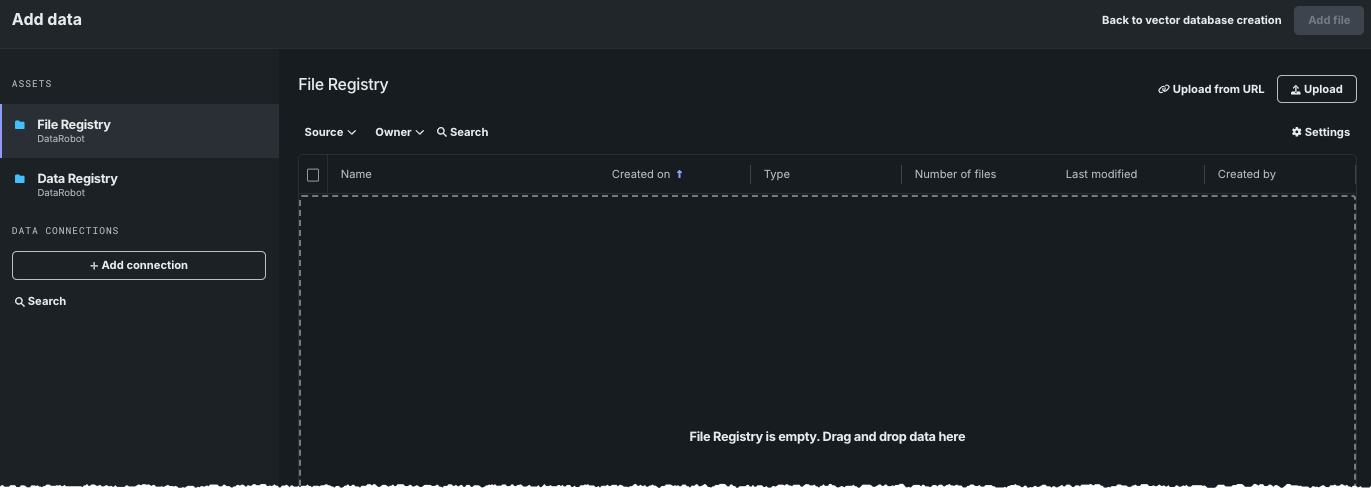
ベクターデータベースのファイルレジストリ¶
ファイルレジストリは、あらゆるタイプのデータを保存できる「汎用」ストレージシステムです。 データレジストリとは異なり、ファイルレジストリにアップロードされたファイルはCSV変換されません。 UIでは、ベクターデータベースの作成はファイルレジストリを使用できる唯一の場であり、データを追加モーダルからのみアクセスできます。 どのようなファイルタイプでも保存できますが、ベクターデータベースの作成では、レジストリのタイプに関係なく、同じファイルタイプがサポートされています。
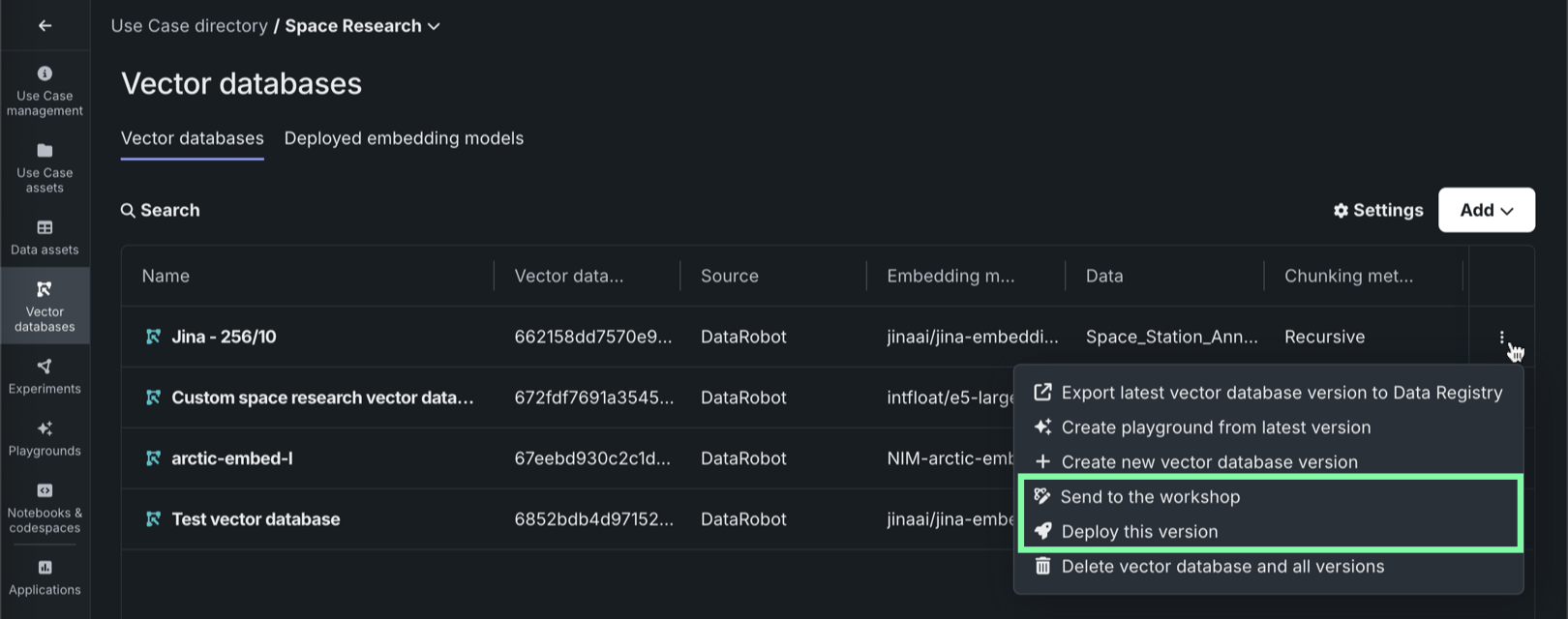
ベクターデータベースの登録とデプロイ¶
このリリースから、レジストリでのベクターデータベースの作成と登録に加えて、ワークベンチから本番環境にベクターデータベースを送信できるようになりました。 DataRobotでは、ベクターデータベースのデプロイを監視することもでき、デプロイプロセス中にベクターデータベースに関連するカスタム指標が自動的に生成されます。
レジストリでは、ワークショップでベクターデータベースをターゲットタイプとすることで、他のカスタムモデルと同じように、ベクターデータベースを登録およびデプロイできます。

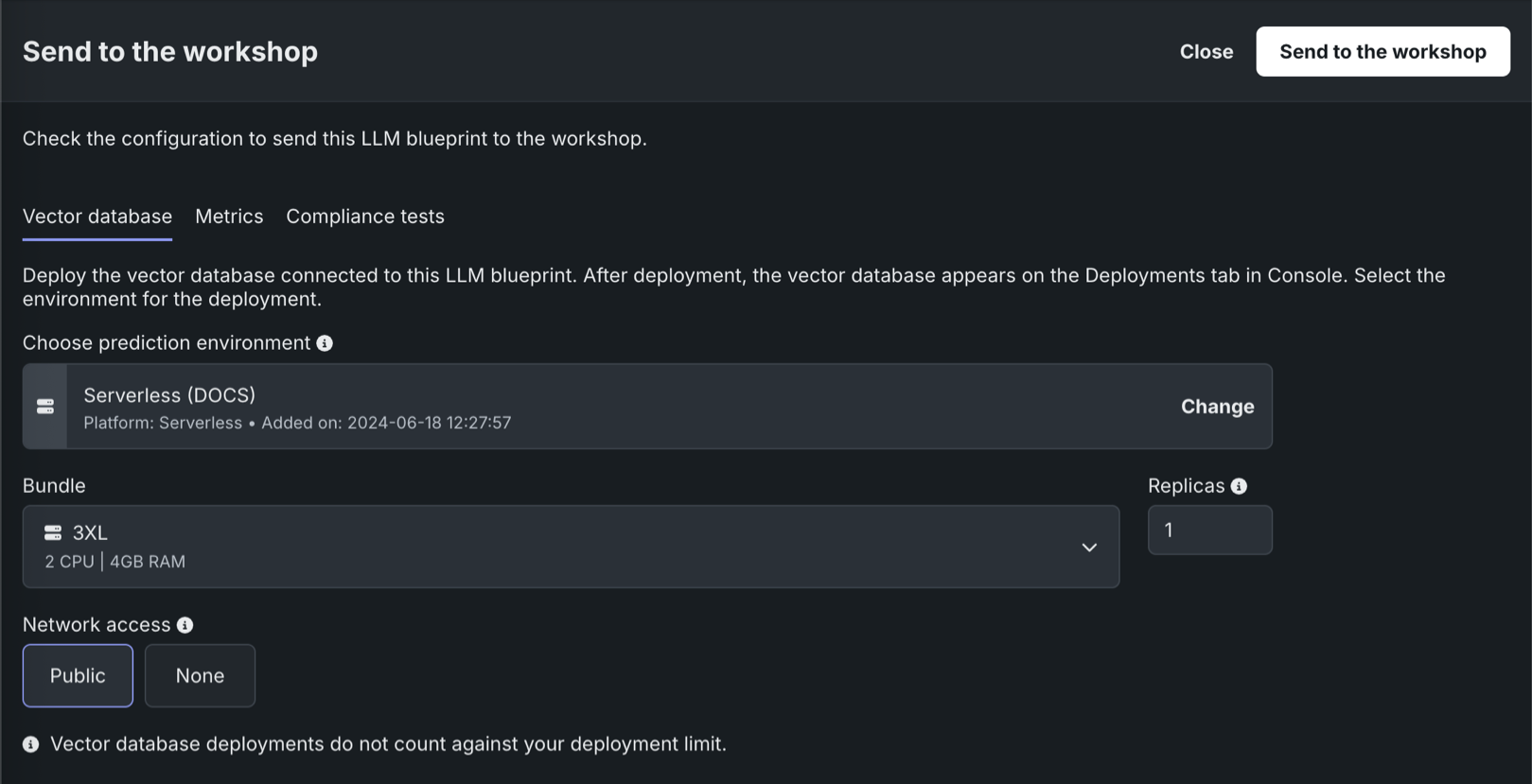
ワークベンチでは、ベクターデータベースタブの各ベクターデータベースを次の2つの方法で本番環境に送信できます。
| 方法 | 説明 |
|---|---|
| ワークショップに送信 | ベクターデータベースをレジストリのワークショップに送信して、変更およびデプロイします。 |
| このバージョンをデプロイ | 選択した予測環境にこのバージョンのベクターデータベースをデプロイします。 |
ワークベンチのLLMプレイグラウンドでは、ベクターデータベースに関連付けられたLLMを本番環境に送信する際に、そのベクターデータベースの登録とデプロイもできます。
ワークショップの設定を改善してNeMoガードNIMに対応¶
ワークショップに、NVIDIA NeMoのジェイルブレイクとコンテンツセーフティのガードを設定するオプションが追加されました。 これらのモデレーション指標を設定するには、デプロイ済みのLLMを選択するだけです。

Geminiの新バージョンをリリース、Bisonのサポートを終了¶
Gemini 1.5 Pro v001およびGemini 1.5 Flash v001は、2025年5月24日にv002に置き換えられます。セルフマネージド環境で、これらの埋め込みモデルを引き続きご利用いただくには、DataRobotリリース11.0.1へのアップグレードが必要です。 Gemini 1.5 Pro v002およびGemini 1.5 Flash v002のサポートは、2025年9月24日で終了します。 アップグレード後、プレイグラウンド内のすべてのLLMブループリントは自動的にv002に切り替わります。v001を使用している登録モデルまたはデプロイがある場合は、LLMブループリントをレジストリのワークショップに再度送信し、再デプロイして、v002の使用を開始する必要があります。または、推論にボルトオンのガバナンスAPIを使用している場合は、LLMブループリントを再デプロイせずに、推論リクエストでモデルIDにgemini-1.5-flash-002 / gemini-1.5-pro-002を指定します。
また、Google Bisonのサポートを終了しました。 代替の埋め込みモデルの選択については、DataRobotで利用可能なLLMの全リストをご覧ください。開発者向けドキュメントへのリンクも掲載されています。
LLMモデルのサポートを拡大¶
DataRobotでは、LLMブループリントの作成時にサポートされるLLMモデルが新たに多数追加されました。 新たに加わったモデルの中には、以下に示すように、モデルパラメーターが追加されているものもあります。
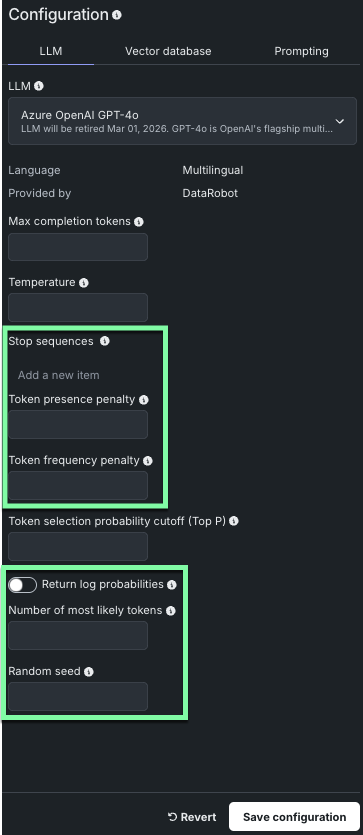
備考
使用できるパラメーターは、選択したLLMモデルによって異なります。
新しいモデルとパラメーターの使用手順については、LLMブループリントの構築を参照してください。
モデレーションフレームワークにおけるストリーミングのサポート¶
ストリーミングLLMチャット補完のモデレーションサポートが改善されました。 デプロイが2つの要件(実行環境イメージにモデレーションライブラリが含まれていること、カスタムモデルコードにmoderation_config.yamlが含まれていること)を満たす場合、チャット補完にdatarobot_moderationsが含まれるようになりました。 モデレーションが有効なストリーミングレスポンスの場合、最初のチャンクは、設定されているプロンプトと回答のガードに関する情報を提供するようになりました。
カスタムモデルでモデルのリストをサポート¶
カスタムモデルは、OpenAIクライアントの.models.list ()メソッドをサポートするようになりました。このメソッドは、デプロイで使用可能なモデルと、オーナーや可用性などの基本情報を返します。 この機能は、マネージドRAG、NIM、およびホストされたLLMですぐに利用できます。 カスタムモデルの場合は、custom.pyにget_supported_llm_models()フックを実装することで、回答をカスタマイズできます。
プラットフォームの機能強化¶
以下の新機能により、DataRobot GenAIがさらに強化されました。
非構造化データのサポート¶
このリリースでは、非構造化データをサポートするS3およびADLSのコネクターが追加され、ファイル、ドキュメント、メディア、その他の表形式以外の形式に対して一貫した読み取りアクセスが可能になりました。 新しいエンドポイントは、非構造化データの効率的なチャンク転送をサポートし、大規模なファイルのスケーラブルな取り込みと提供を可能にします。これにより、既存の構造化データのサポートを補完する、スケーラブルで維持管理が容易な統一されたデータ接続アプローチを実現します。
ワークベンチで動的データセットのサポートを一般提供¶
ワークベンチで動的データセットのサポートが一般提供されました。 動的データとは、たとえばプレビュー用のライブサンプルを作成する際に、DataRobotがリクエストに応じてプルするソースデータへの「ライブ」接続のことです。
外部OAuthサーバー設定のサポート¶
今回のリリースでは、OAuthプロバイダーの管理ページが新たに追加され、クラスターのOAuthプロバイダーを設定、追加、削除、変更できます。

さらに、GoogleとBoxという2つの新しいOAuthプロバイダーのサポートが追加されました。 詳しくは、ドキュメントをご覧ください。
Snowflake接続のFIPSパスワード要件を更新¶
FIPS認証要件の改定に伴い、DataRobotでは、資格情報が連邦情報処理標準(FIPS)に準拠することが必須となりました。FIPSは、暗号モジュールが特定のセキュリティ要件の検証をクリアしていることを保証する米政府の規格です。 DataRobotで使用されるすべての資格情報、特にSnowflakeの基本資格情報とキーペアは、以下に示すFIPS準拠の形式に従う必要があります。
- RSAキーの長さは2048ビット以上で、パスフレーズは14文字以上である必要があります。
- Snowflakeのキーペア認証では、FIPS承認のアルゴリズムを使用し、ソルト長を16バイト(128ビット)以上にする必要があります。
詳細については、FIPS検証に関するFAQを参照してください。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。