AutoML (V7.0)¶
2021年3月15日
DataRobot v7.0.0のリリースでは、以下のように多くの新しいUIおよびAPI機能が追加されました。 詳細については、時系列の新機能も参照してください。
期限切れの古い機能に対するサポートの変更については、サポート終了に関する重要なお知らせをご覧ください。
リリースv7.0.0では、以下の言語のUI文字列の翻訳が更新されています。
- 日本語
- フランス語
- スペイン語
注目の新機能...¶
リリース7.0の主な新機能には以下が含まれます。
一般提供:バイアスの検出および分析ツール¶
バイアスと公平性テスト(一般公開機能)は、二値分類モデルの公平性を計算し、モデルの予測動作のバイアスを特定する方法を提供します。
モデル構築の前に高度なオプション > バイアスと公平性を使用して、保護された特徴量を定義し、ユースケースに適した公平性指標を選択できます。 選択の目安アンケートを使用すると、DataRobotで推奨される指標を参照できます。 モデルが構築されると、バイアスと公平性のインサイトを活用して、モデルに含まれるバイアスを特定したり、モデルがトレーニングデータのどこからなぜバイアスを学習しているかといった根本原因分析の結果を視覚化することができます。
-
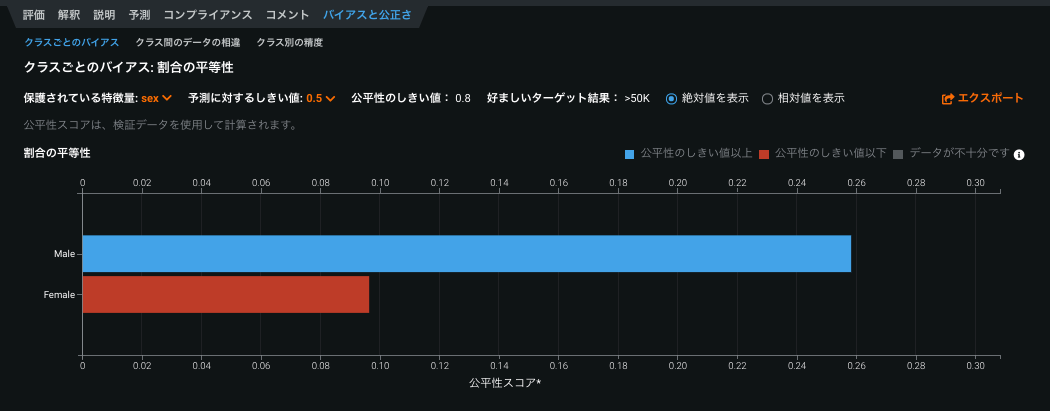
クラスごとのバイアスでは、各クラスの公平性しきい値と公平性スコアを使用して、モデルの予測動作時に特定のクラスでバイアスが発生しているかどうかが判断されます。
-
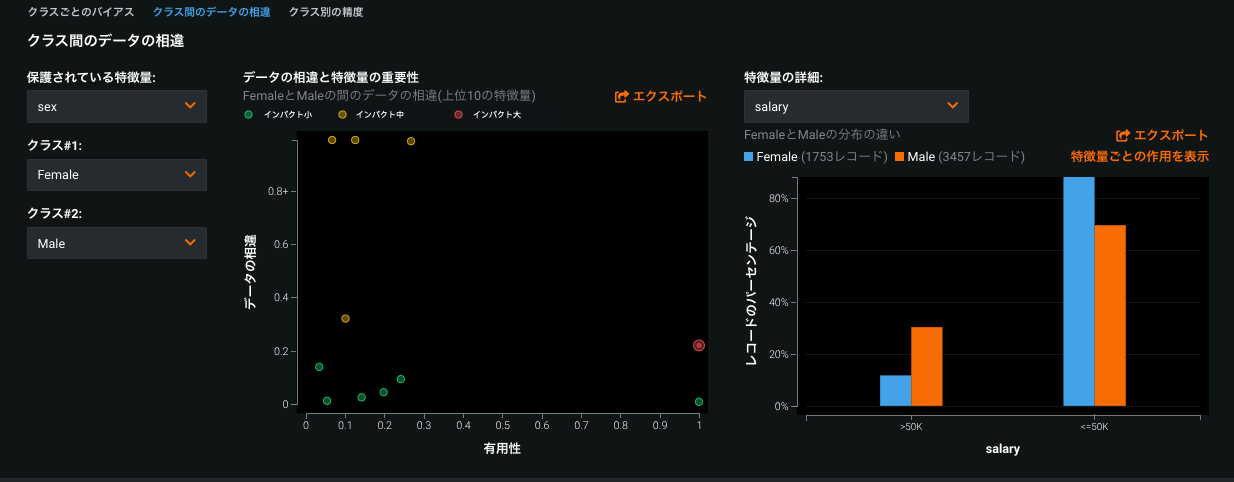
クラス間のデータの相違では、選択したクラスのモデルのバイアスの根本原因分析が実行されます。 データの相違と特徴量の有用性チャートでは、バイアスに最も影響を与えている特徴量を特定できます。特徴量の詳細チャートは、特徴量内にバイアスが存在する場所を報告します。
-
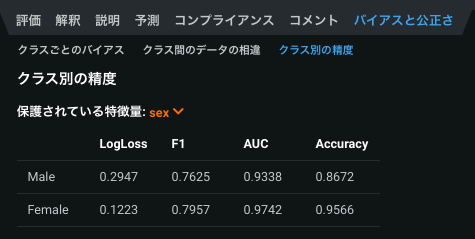
クラス別の精度は、特定の保護された特徴量/クラスセグメントでのモデルのパフォーマンスとその動作を理解するのに役立ちます。
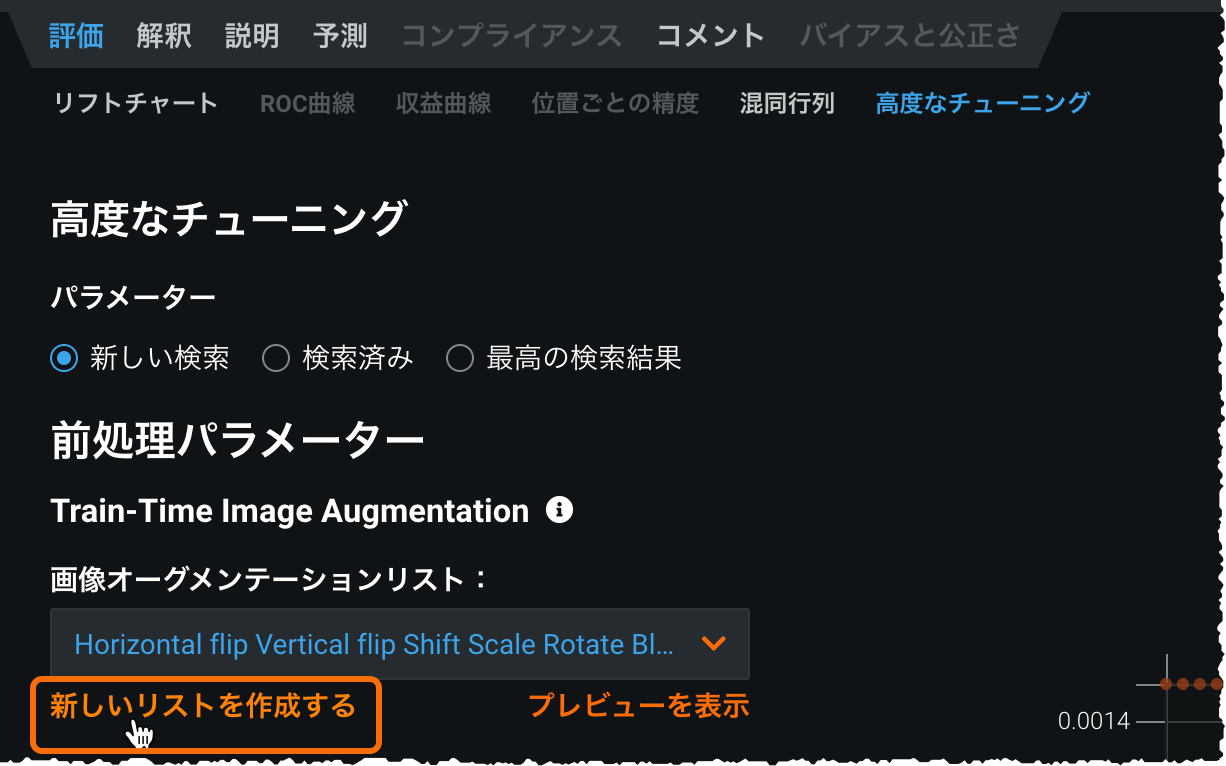
一般提供:精度を高めるトレーニング時の画像オーグメンテーション¶
Visual Artificial Intelligence (AI)プロジェクトで利用できる機能のトレーニング時間のイメージオーグメンテーションでは、イメージデータセット(特に行数が少ないデータセット)の精度を高めることができます。 通常、データが多いほど精度と一般化が向上しますが、データを簡単に取得するためのリソース(時間、費用、イメージの可用性、ラベル付けの専門知識など)がない場合があります。 画像オーグメンテーションを使用すると、変換を適用することにより、既存のイメージから新しい画像データを作成できます。
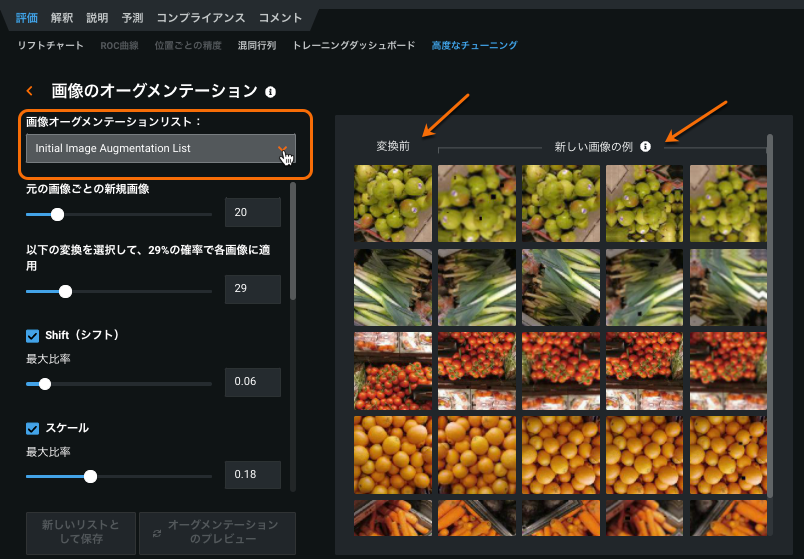
モデル構築の前に、高度なオプションからイメージ変換を作成できます。 あるいは、モデルの構築が完了した後、リーダーボードの評価 > 高度なチューニングタブからイメージデータセットのチューニングに進むこともできます。 新しい「画像オーグメンテーション」タスクはイメージのブループリントに表示されます。 ベータ版のフィードバックに基づくオーグメンテーションの改善には、マルチモーダルプロジェクトのサポート、DataRobotが実行できるオーグメンテーションのサイズの増加、およびオーグメンテーション戦略をプレビューするためのUIの改善が含まれます。 また、モデリング後のチューニングと新しいオーグメンテーションリストの作成は高度なチューニングに移動しました。
新機能と機能強化¶
特徴量探索の機能強化¶
特徴量探索の機能強化に関する以下の項目を参照してください:
- 集計されたカテゴリ特徴量のブループリントサポートの強化
- 集計されたカテゴリのインサイトでのストップワードのフィルター
- ベータ:利用可能になった教師なしプロジェクトの特徴量探索
- Beta: Feature Discovery deployments support governance workflow to manage secondary datasets)
- ベータ:特徴量探索で利用可能になった動的データセットでのSpark SQLクエリーのサポート
その他の新機能¶
以下のその他の新機能の詳細を参照してください。
- 予測しきい値のUXアップグレード
- 追加のスコアリングコードモデルへのアクセス
- 開発者ツールのページからアクセス可能になったRおよびPythonクライアント
- 多クラスにおける特徴量のインパクトでのカスタムサンプルサイズのサポート
- ベータ:多ラベル分類機能による分類オプションの拡張
- Beta: New TinyBERT pre-trained featurizer implementation extends NLP
- ベータ:Kerasモデルに対するスコアリングコードのサポート
管理者向けの変更¶
新しい特徴量探索機能¶
集計されたカテゴリ特徴量のブループリントサポートの増加により、精度とリーダーボードの多様性が向上します¶
集計されたカテゴリ型特徴量は、複数のカテゴリ値を持つ特徴量に使用されます(同一製品のカテゴリーまたは部門ごとの数量など)。 この型の特徴量が元のデータセットにない場合、DataRobotは特徴量探索プロセスの一部として(セカンダリーデータセットから)作成されます。 このリリースでは、DataRobotはこの型の特徴量のサポートをブループリントの幅広い選択肢に追加し、オートパイロット中に実行されるモデルの数を増やします。 この追加の影響は、セカンダリーデータセットを持つ特徴量探索プロジェクトで特に顕著です。
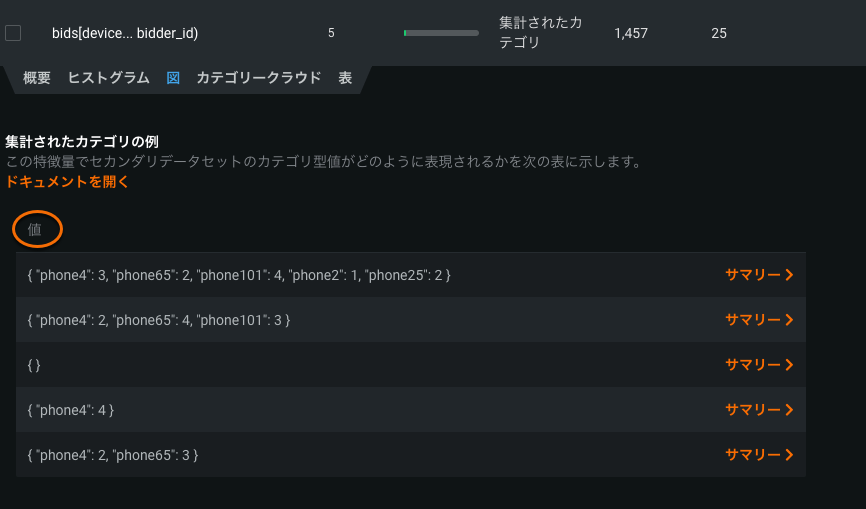
集計されたカテゴリのインサイトでのストップワードのフィルター¶
このリリースでは、集計されたカテゴリ特徴量のインサイトのシングルトークンテキストについて、オンデマンド(カテゴリクラウド)とデフォルト(ヒストグラム)でストップワードが除外されるようになりました。 ストップワード(よく使用される用語のうち検索対象から除外できる用語)がモデルに有用でない場合、それらのワードが除外されることにより、解釈性が向上します。 フィルターすることで有用なノンストップワードに集中し、データをより理解できるようになります。

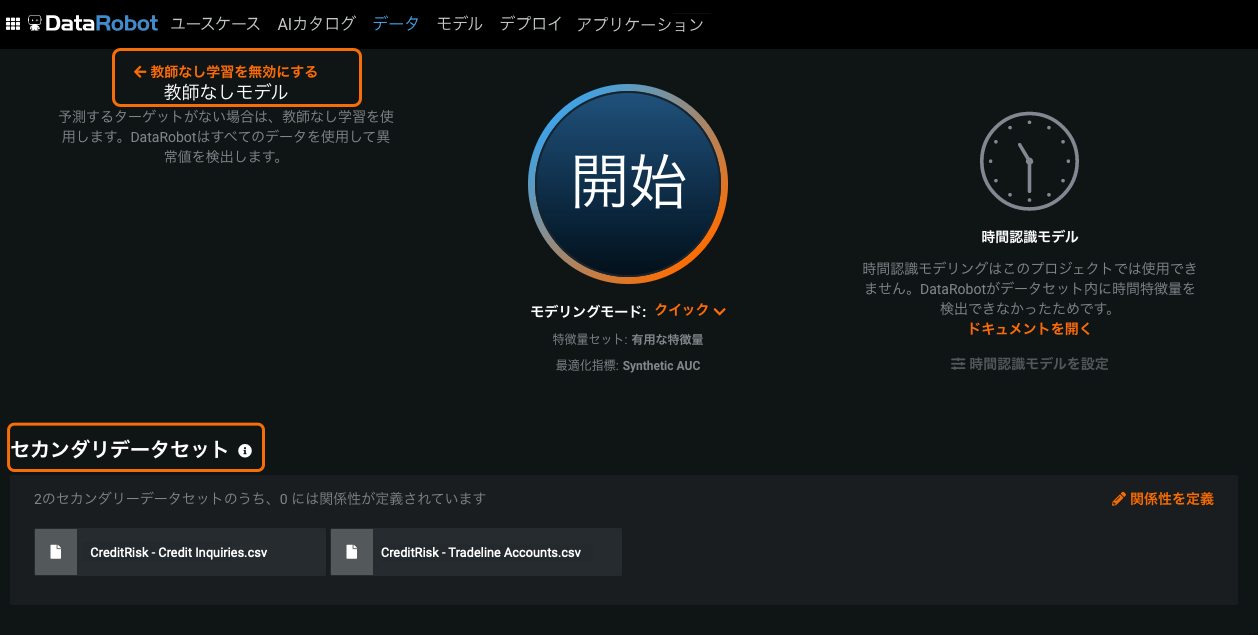
ベータ:利用可能になった教師なしプロジェクトの特徴量探索¶
以前は、特徴量探索は教師なし学習プロジェクトはサポートされていませんでした。 「ターゲットなし」を選択した場合、プロジェクトの開始時にオプションが表示されていましたが、特徴量探索設定を構成しようとすると、UIからエラーメッセージが返されていました。 ベータ機能。教師なしモードの設定、セカンダリーデータセットの追加、関係性の定義を行って、プロジェクトを開始できます。 DataRobotは、監視ありプロジェクトの場合と同様にセカンダリー特徴量を生成しますが、教師あり特徴量の削減(ターゲットが必要)は廃止されます。
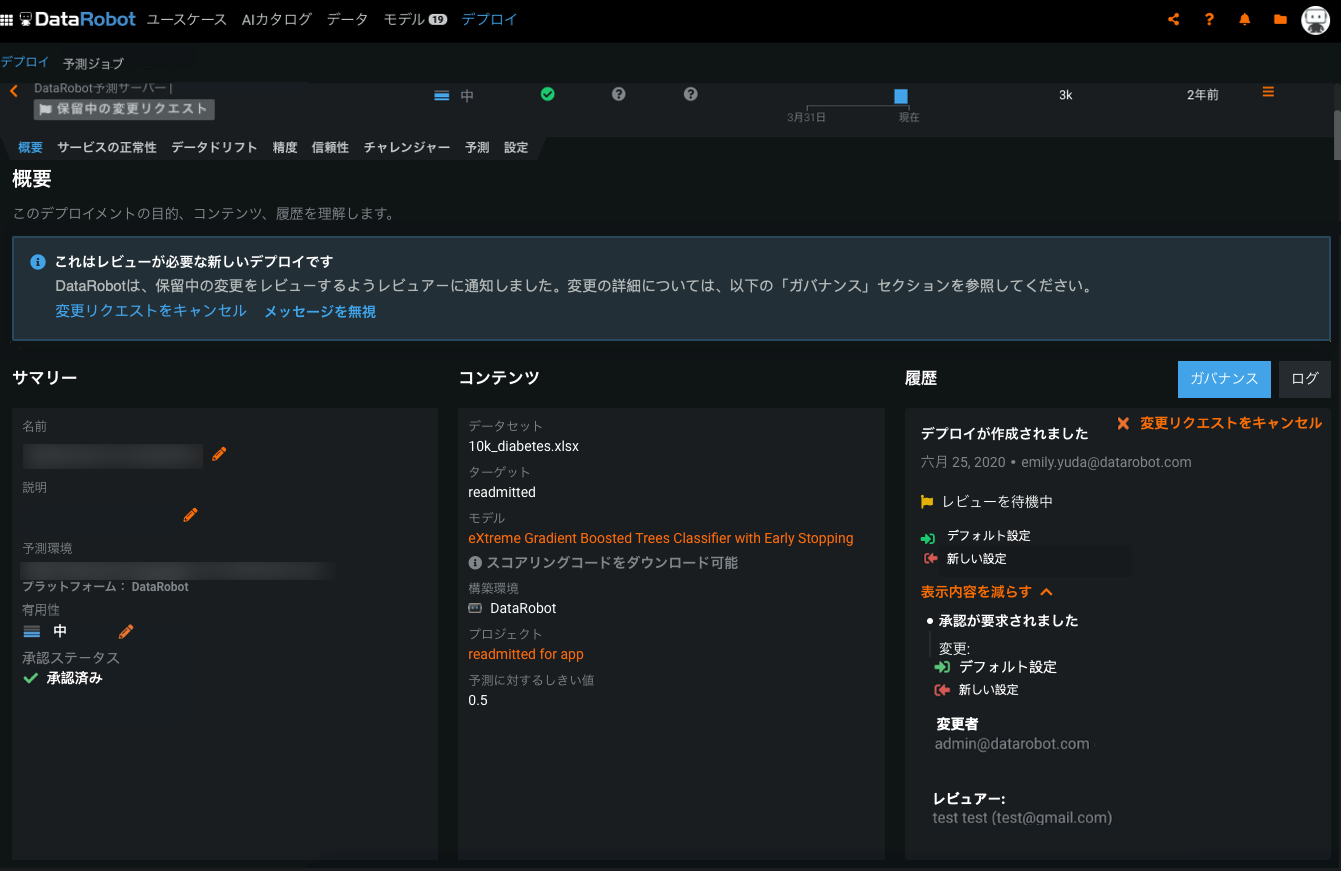
ベータ:特徴量探索のデプロイでは、セカンダリーデータセットを管理するガバナンスワークフローがサポートされています(MLOpsが必要)¶
このリリースでは、ガバナンスワークフローを使用して、特徴量探索のデプロイのセカンダリーデータセットに対する更新を管理できます。 管理者が「セカンダリーデータセット設定の変更」承認ポリシートリガーをユーザー設定 > 承認ポリシーで設定した後にセカンダリーデータセットに変更を加えようとすると、承認プロセスが必要な変更リクエストのプロンプトが表示されます。 変更リクエストの作成者は、そのステータスを履歴(デプロイ > 概要内)に表示でき、レビュー担当者には、保留中の変更のレビューを要求する通知が表示されます。
ベータ:特徴量探索セカンダリーデータセットで、動的データセットでのSpark SQLクエリーのサポートを利用できるようになりました¶
DataRobotは、AIカタログ内からSpark SQLクエリーを使用して、スナップショット(静的)データセットを強化、変換、整形、およびアンサンブルする機能を提供します。 この新機能により、特徴量探索プロジェクトのセカンダリーデータセットで動的Spark SQLのサポートが追加されています。 ベータ機能(「動的Spark SQLの特徴量探索サポートを有効にする」)として有効にすると、この新機能により、基本的なデータ準備を実行する際の柔軟性が向上します。 認証要件は同じままです。
その他の新機能¶
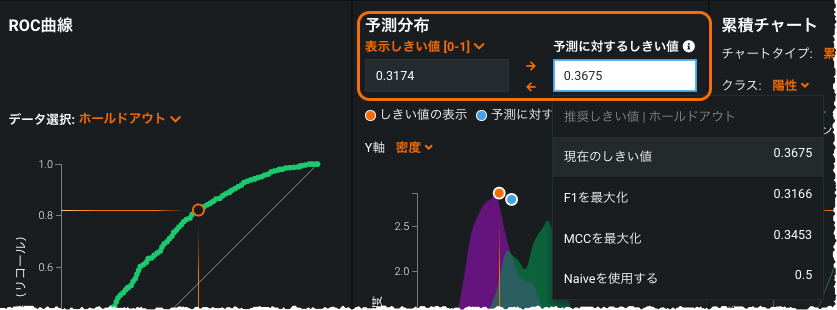
予測しきい値のUXアップグレード¶
このリリースでは、リーダーボードに予測しきい値を設定するためのユーザー体験がアップグレードされました。 第一に、ROC曲線、収益曲線、予測の作成およびデプロイタブのコンポーネントアップグレードしておくと、推奨される予測しきい値の割り当てまたは選択が簡単になっています。 第二に、ROC曲線と収益曲線タブの表示しきい値と予測しきい値との間に便利なワンクリックコピーを利用できるようになっています。 そして最後に、選択した予測しきい値が、モデル内のすべてのタブとモデルのダウンロード(モデルパッケージ(.mlpkg)ファイルなど)の間で同期されるようになっています。
追加のスコアリングコードモデルへのアクセス¶
7.0では、スコアリングコード範囲が拡張されています。 次のモデルは、スコアリングコードを含むように書き直されました。
開発者ツールのページからアクセス可能になったRおよびPythonクライアント¶
New in this release, Developer tools now provides quick links to developer documentation. 以下のリンクが含まれています。
- 現在のREST API、PythonクライアントAPI、およびRクライアントAPIのドキュメント。
- 開発者ポータル。
- Githubコミュニティのリポジトリ。
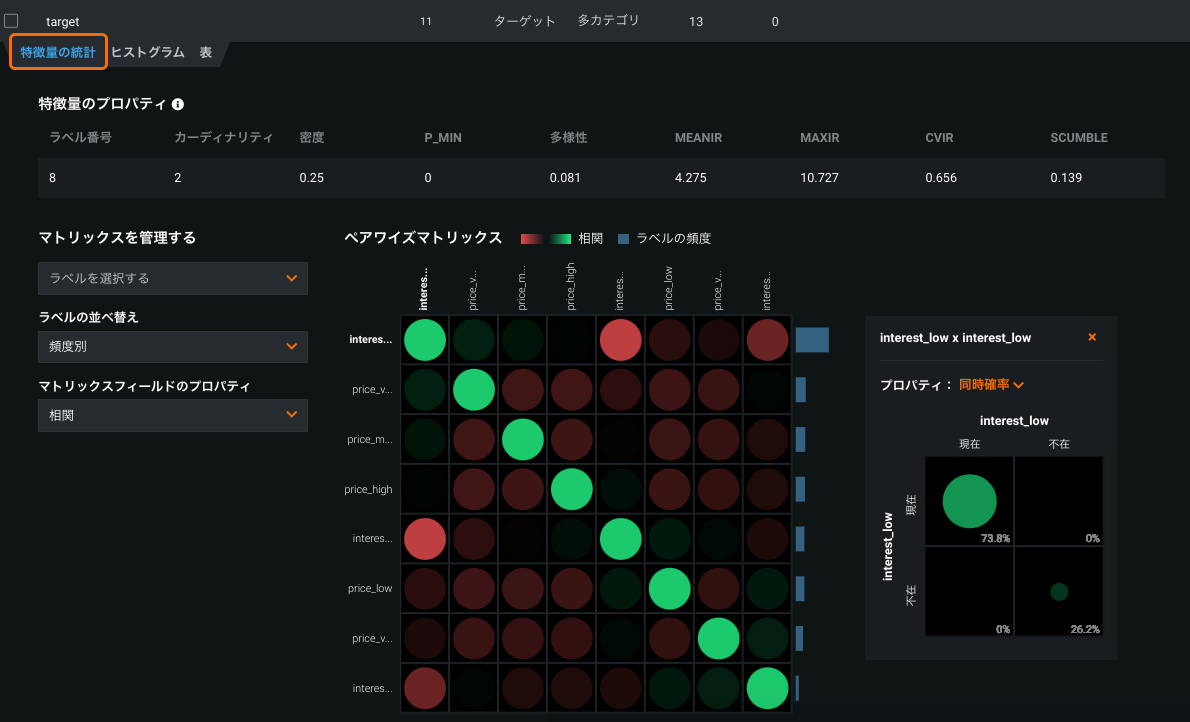
多クラスにおける特徴量のインパクトでのカスタムサンプルサイズのサポート¶
多クラスプロジェクトがカスタムサンプルサイズを使用して、特徴量のインパクトを計算できるようになりました。 特徴量のインパクトの結果の不整合に対処し、それらの結果をはるかに一貫した方法で再現することで、モデル検定プロセス中の摩擦を軽減します。
ベータ:多ラベル分類機能による分類オプションの拡張¶
[多ラベルモデリング](multilabel-classic, now available as a public beta feature, is a kind of classification task where each data instance (row in a dataset)は、ラベルに関連付けられていないか、1つまたは複数のラベルに関連付けられています。 一般的な用途としては、トピックのリスト(食品、ボストン、イタリアン)を含むテキスト型特徴量や、オブジェクトのリストを含む画像(1匹の猫、2匹の犬、1頭のクマ)などがあります。 行内のすべてのラベルは、その行の「ラベルセット」を構成します。 多ラベル分類では、新しい観測値が指定されるとラベルセットが予測されます。 多クラスモデリングと似ていますが、多ラベルモデリングは高い柔軟性が提供されます。
| データ型 | 説明 | ターゲットとして許可しますか? | プロジェクトタイプ |
|---|---|---|---|
| カテゴリー | 1行に単一のカテゴリー、相互排他的 | はい | 多クラス |
| 多カテゴリー | 1行に複数のカテゴリー、非排他的 | はい | 多ラベル |
| 集計されたカテゴリー型特徴量 | 1行に複数のカテゴリー、各カテゴリーの複数のインスタンスを許可 | いいえ | 重回帰(未提供) |
Beta: New TinyBERT pre-trained featurizer implementation extends NLP with no fine-tuning needed¶
BERT(Transformersからの双方向エンコーダー表現)は、自然言語処理(NLP)転移学習に関するトランスフォーマーに基づくGoogleのデファクトスタンダードです。 TinyBERT (or any distilled, smaller, version of BERT) is now available with certain blueprints in the DataRobot Repository. These blueprints provide pre-trained feature extraction in the NLP field, similar to Visual Artificial Intelligence (AI) featurizers. ただし、最大限の柔軟性を実現するために、DataRobotの実装には2つの調整可能な追加のプーリングパラメーター(最大プーリングと平均プーリング)が用意されています。 TinyBERT blueprints are available for both UI and API users.
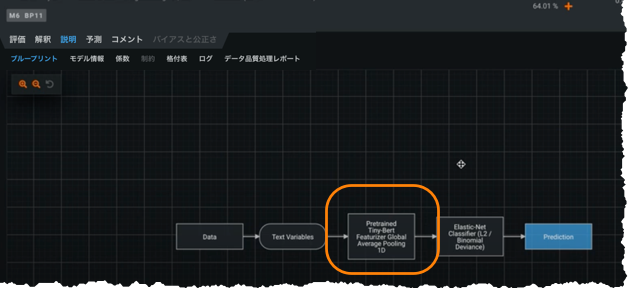
ベータ:Kerasモデルに対するスコアリングコードのサポート¶
現在、一般公開されているKerasモデルはスコアリングコードを含むように再記述されています。
新しい管理機能¶
拡張SAML SSOによるUIを介した追加の設定オプションの提供¶
Self-Managed only: Using their existing identity provider (IdP)/SSO solution—Active Directory, OneLogin, Okta, for example—users can now seamlessly access DataRobot as long as they are logged in to their organization's IdP system. また、拡張SSOでは、セキュリティパラメーター、SAMLシークレット、ユーザー属性、ロール、グループのマッピングなど、IdPメタデータを柔軟にパラメーター化することができます。
Enhanced SAML SSO replaces SAML SSO, which will be deprecated in an upcoming release.
APIの機能強化¶
The following is a summary of API enhancements. See the changelog for more details and fixed issues.
新機能¶
-
The lists of allowed and forbidden operations over DataStores and DataSources are now provided by new routes.
-
A new field
canDelete, has been added to the response of theGET /api/v2/externalDataSources/route, which lists all viewable data sources.
機能強化¶
-
Models can be retrained with custom monotonic constraints.
-
Models can be retrained with cross validation.
-
Creating a datetime model using POST /api/v2/projects/(projectId)/datetimeModels/ without specifying a featurelist will result in using the recommended featurelist for the specified blueprint. If there is no recommended featurelist, the project’s default featurelist will be used instead.
-
The new string field parameter
unsupervisedTypehas been added to two endpoints to set the type of unsupervised project as anomaly or clustering when a project is run in unsupervisedMode. -
A new field,
canUseDatasetData, indicates whether a user can use dataset data for download, project creation, custom models training, or providing predictions.
ヒント
DataRobotでは、PythonとRのために最新のAPIクライアントにアップデートすることを強くお勧めします。
サポート終了のお知らせ¶
Scaleout models deprecated¶
Scaleout models will be deprecated in a future release and should not be used to train new models.
Customer-reported issues fixed in v7.0.0¶
The following issues have been fixed since release v6.3.4.
プラットフォーム¶
-
DM-4525: Data Connections are now properly listed in Credentials Management Page when the UI language is set to non-English.
-
DM-4637: Adds a new config setting,
KERBEROS_PEM_ENABLE, which when set toTruewill allow thekinitcommand to use a service ticket usingPKINITpreauth instead of using a keytab. -
DM-4696: The following variables have changed:
AZURE_BLOB_STORAGE_CHUNK_SIZEenv variable is configurable (99MB default).AZURE_BLOB_STORAGE_TIMEOUTenv variable is configurable (20 second default).
- EP-506: Fixes an issue with database timeout during index create/update.
プラットフォーム¶
- EP-750: Fixes an issue with systems using external directory services where some DataRobot containers were unable to resolve the
datarobot_useruser. This change introduces theos_configuration.remote_user_credentialsparameter by mapping the external directory service credentials into DataRobot containers when set totrue. -
EP-795: For third-party tools, the admin interface for RabbitMQ now can have additional headers.
-
PLT-3052: Fixed LDAP group mapping for groups with special symbols in the name.
モデリング¶
- MODEL-5033: Modified certain Keras Repository blueprints that make use of One Hot Encoding numerics so that they perform NDC before One Hot Encoding. This fix ensures prediction consistency between the ModelingAPI and BatchAPI.
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。