2025年6月
6月にリリースされたSaaS機能のお知らせ¶
2025年6月
このページでは、2025年6月に新たにリリースされ、DataRobotのSaaS型マルチテナントAIプラットフォームで利用できる機能についてのお知らせと、追加情報へのリンクを掲載しています。 リリースセンターからは、過去にリリースされた機能のお知らせや、セルフマネージドAIプラットフォームのリリースノートにもアクセスできます。
6月リリースの機能¶
次の表は、新機能の一覧です。
目的別にグループ化された機能
| 名前 | NextGen | Classic |
|---|---|---|
| アプリケーション | ||
| アプリケーションに永続的なストレージを追加 | ✔ | |
| APIキーでアプリケーションへのアクセスを制御 | ✔ | |
| GenAI | ||
| ベクターデータベースの登録とデプロイ | ✔ | |
| モデレーションフレームワークにおけるストリーミングのサポート | ✔ | |
| ワークショップの設定を改善してNeMoガードNIMに対応 | ✔ | |
| LLMモデルのサポートを拡大 | ✔ | |
| データ | ||
| ワークベンチでのJDBCドライバーへの接続 | ✔ | |
| ワークベンチで動的データセットのサポートを一般提供 | ✔ | |
| ワークベンチでのデータ操作をさらに改善 | ✔ | |
| モデリング | ||
| ワークベンチでブレンダーを一般提供 | ✔ | N/A |
| 増分学習の改善によりエクスペリメントの開始を迅速化 | ✔ | |
| 予測とMLOps | ||
| チャレンジャータブでのセグメント化された分析 | ✔ | |
| レジストリでの混同行列の表示 | ✔ | |
| カスタムモデルでモデルのリストをサポート | ✔ | |
| プラットフォーム | ||
| デフォルトのランディングページがNextGenになりました | ✔ | |
| SAML SSOテストの自動化 | ✔ | |
| Snowflake接続のFIPSパスワード要件を更新 | ✔ | |
| 外部OAuthサーバー設定のサポート | ✔ | |
アプリケーション¶
アプリケーションに永続的なストレージを追加¶
DataRobotは、キー値ストアAPIとファイルストレージを使用して、カスタムアプリケーションとアプリケーションテンプレートの両方のアプリケーションに永続的なストレージを提供するようになりました。 これには、ユーザー設定、プリファレンス、特定のリソースへのアクセス権限のほか、チャット履歴、使用状況の監視、大きなデータフレームのデータキャッシュなどを含めることができます。
APIキーでアプリケーションへのアクセスを制御¶
アプリケーションにDataRobotパブリックAPIへのアクセスを提供するアプリケーションAPIキーを使用して、カスタムアプリケーション内からデータにアクセスして使用する権限をユーザーに付与できるようになりました。 ロールを共有すると、アプリケーションをエンティティとして制御できますが、アプリケーションのAPIキーは、アプリケーションが実行できるリクエストを制御します。 たとえば、ユーザーがアプリケーションにアクセスすると、アプリケーションはAPIキーを生成するためにユーザーの同意を求めます。 そのキーには、アプリケーションソースによって制御されるアクセスレベルが設定されます。 認可されると、そのアプリケーションによって行われたリクエストのヘッダーにアプリケーションAPIキーが含まれます。 アプリケーションは、WebリクエストヘッダーからAPIキーを取得し、たとえば、ユーザーがアクセスできるデプロイを調べ、API キーを使用して予測を行うことができます。
GenAI¶
ベクターデータベースの登録とデプロイ¶
このリリースから、レジストリでのベクターデータベースの作成と登録に加えて、ワークベンチから本番環境にベクターデータベースを送信できるようになりました。 DataRobotでは、ベクターデータベースのデプロイを監視することもでき、デプロイプロセス中にベクターデータベースに関連するカスタム指標が自動的に生成されます。
レジストリでは、モデルワークショップでベクターデータベースをターゲットタイプとすることで、他のカスタムモデルと同じように、ベクターデータベースを登録およびデプロイできます。

ワークベンチでは、ベクターデータベースタブの各ベクターデータベースを次の2つの方法で本番環境に送信できます。
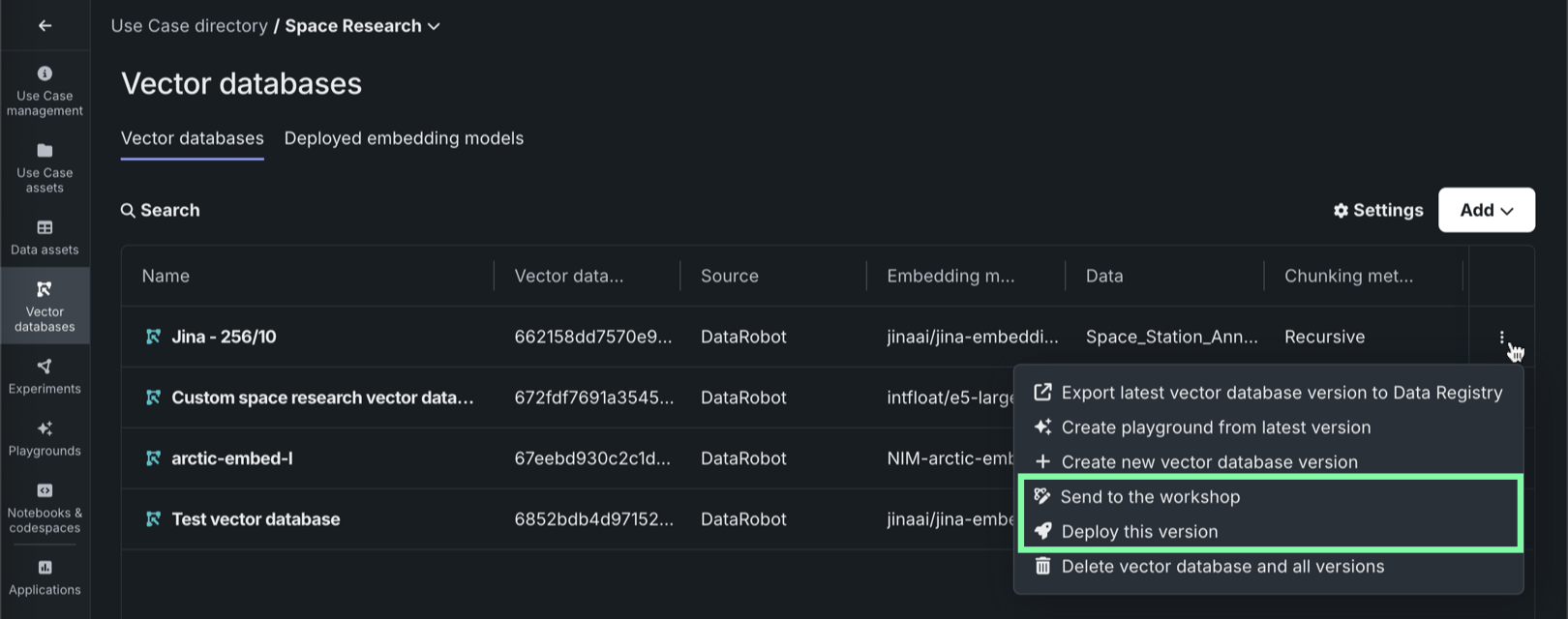
| 方法 | 説明 |
|---|---|
| モデルワークショップに送信 | ベクターデータベースをモデルワークショップに送信して、変更およびデプロイします。 |
| 最新バージョンのデプロイ | 選択した予測環境に最新バージョンのベクターデータベースをデプロイします。 |
ワークベンチのLLMプレイグラウンドでは、ベクターデータベースに関連付けられたLLMを本番環境に送信する際に、そのベクターデータベースの登録とデプロイもできます。
モデレーションフレームワークにおけるストリーミングのサポート¶
ストリーミングLLMチャット補完のモデレーションサポートが改善されました。 デプロイが2つの要件(実行環境イメージにモデレーションライブラリが含まれていること、カスタムモデルコードにmoderation_config.yamlが含まれていること)を満たす場合、チャット補完にdatarobot_moderationsが含まれるようになりました。 モデレーションが有効なストリーミングレスポンスの場合、最初のチャンクは、設定されているプロンプトガードとレスポンスガードに関する情報を提供するようになりました。
ワークショップの設定を改善してNeMoガードNIMに対応¶
ワークショップに、NVIDIA NeMoのジェイルブレイクとコンテンツセーフティのガードを設定するオプションが追加されました。 これらのモデレーション指標を設定するには、デプロイ済みのLLMを選択するだけです。

LLMモデルのサポートを拡大¶
DataRobotでは、LLMブループリントの作成時にサポートされるLLMモデルが新たに多数追加されました。 新たに加わったモデルの中には、以下に示すように、モデルパラメーターが追加されているものもあります。
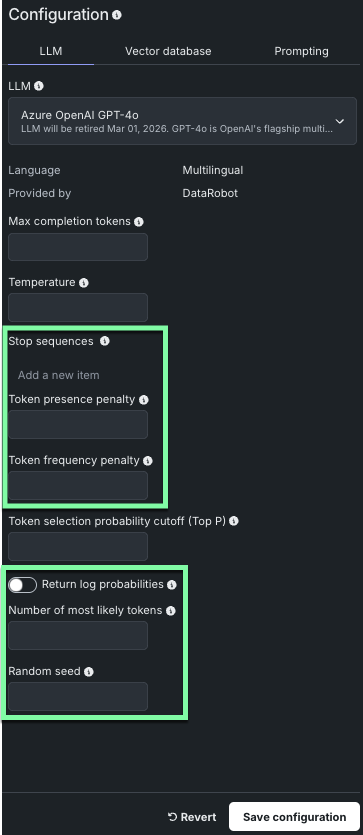
備考
使用できるパラメーターは、選択したLLMモデルによって異なります。
新しいモデルとパラメーターの使用手順については、LLMブループリントの構築を参照してください。
データ¶
ワークベンチでのJDBCドライバーへの接続¶
ワークベンチでは、サポートされているJDBCドライバーからスナップショットデータに接続して追加することができます。 ユースケースにデータを追加する際、JDBCドライバーが使用可能なデータストアにリストされるようになりました。
なお、JDBCドライバーから追加できるのはスナップショットデータだけです。
ワークベンチで動的データセットのサポートを一般提供¶
ワークベンチで動的データセットのサポートが一般提供されました。 動的データとは、たとえばプレビュー用のライブサンプルを作成する際に、DataRobotがリクエストに応じてプルするソースデータへの「ライブ」接続のことです。
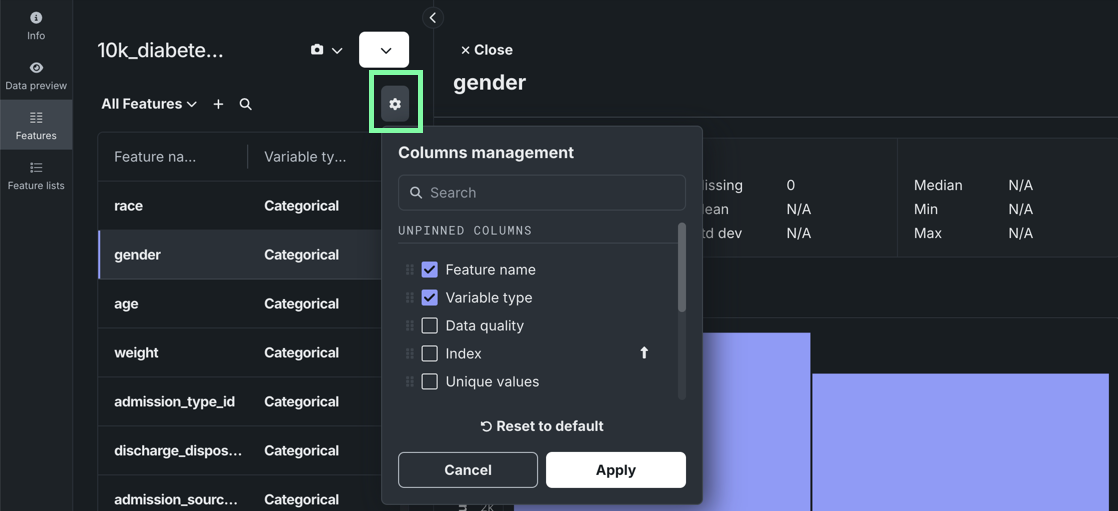
ワークベンチでのデータ操作をさらに改善¶
このリリースでは、ワークベンチのデータ探索機能が以下のようにアップデートされました。
-
データセットを探索する際、サマリーを表示をクリックすると、特徴量数、行数、データ品質評価などの情報が表示されます。

-
個々の特徴量を表示するときに表示する列を管理します。
モデリング¶
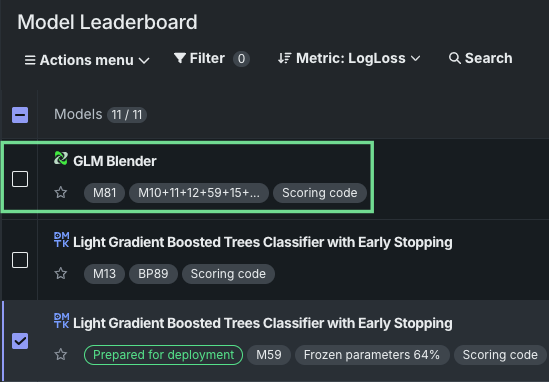
ワークベンチでブレンダーを一般提供¶
アンサンブルモデルとも呼ばれるブレンダーは、ワークベンチでモデリング後の操作として使用できるようになりました。 複数のモデルの基本予測を組み合わせ、それらのモデルの検定セットからの予測でトレーニングすることで、ブレンダーは精度を高め、オーバーフィッティングを削減できる可能性があります。 複数のブレンド方法が用意されているため、時間を認識するエクスペリメントと時間を認識しないエクスペリメントの両方でブレンダーを作成できます。
リーダーボードのアクションメニューから2~8個のモデルを選択し、ブレンド方法を選択して、新しいモデルをトレーニングします。 トレーニングが完了すると、新しいブレンドモデルがリーダーボード上のリストに表示されます。
増分学習の改善によりエクスペリメントの開始を迅速化¶
増分学習(IL)は、10GB〜100GBのデータセットを利用する教師ありエクスペリメントに特化したモデルトレーニング方法です。 データをチャンク化し、トレーニングのイテレーションを作成することで、予測を行うための最適なモデルを特定できます。 このデプロイでは、増分学習に対して大きな改善点が2つあります。
-
静的(スナップショット)データセットの場合、EDA1の完了後にエクスペリメントの設定を開始できるようになりました。エクスペリメントのサマリーは、ほぼすぐに表示されます。 以前は、最初のチャンクがプロジェクトを開始するデータとして使用されていたため、データセットのサイズによっては、最初のチャンクの作成に時間がかかることがありました。 EDAサンプルは、データセット全体を適切に表現しており、これを使用することで、設定を進め、エクスペリメントを迅速化することができます。 また、反復処理の効率と柔軟性が向上するため、データセット全体に設定を適用する前に最適な設定を見つけることができます。
-
時間認識予測を作成するエクスペリメントのサポートが一般提供されました。
予測とMLOps¶
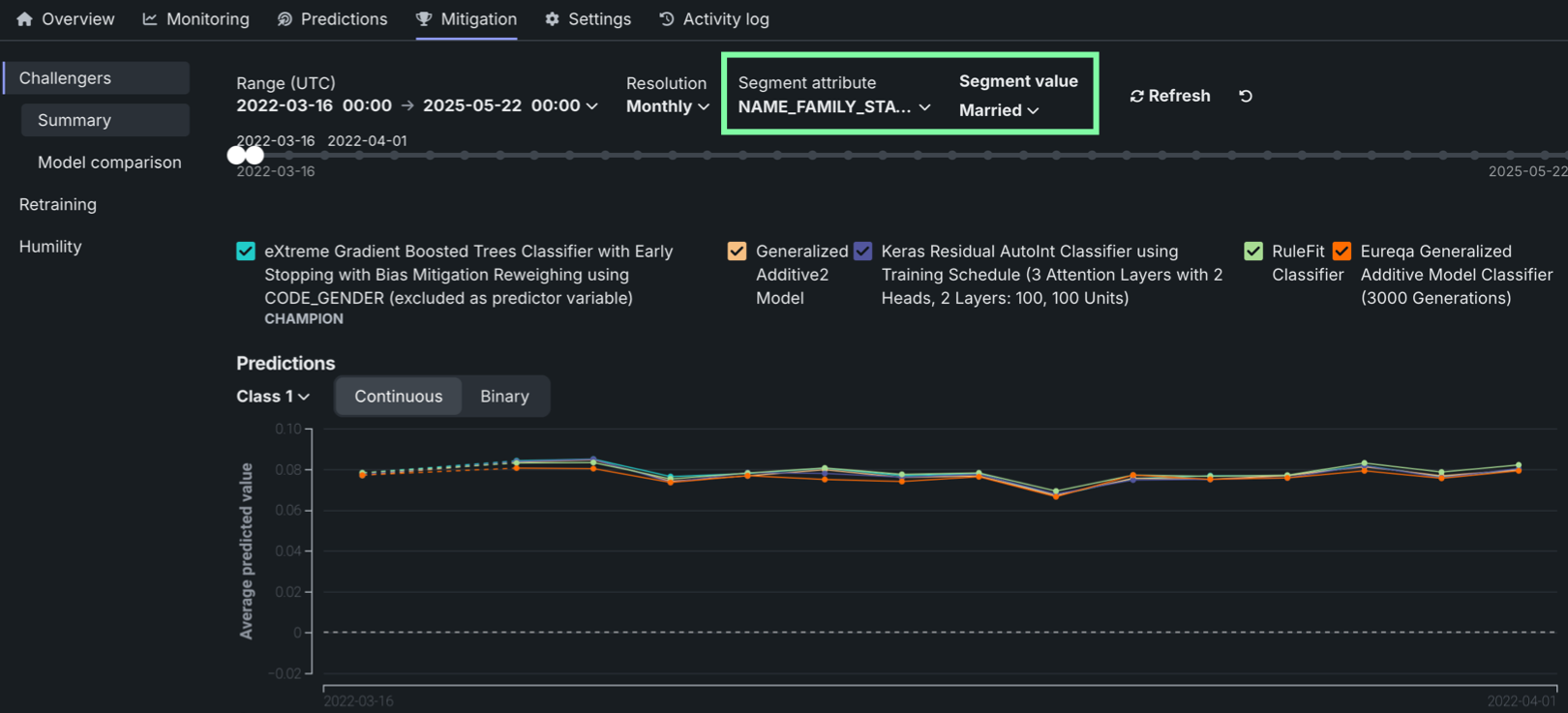
チャレンジャータブでのセグメント化された分析¶
デプロイのチャレンジャータブで、セグメント属性とセグメント値を選択して、チャレンジャーモデルのパフォーマンス指標チャートをフィルターできるようになりました。
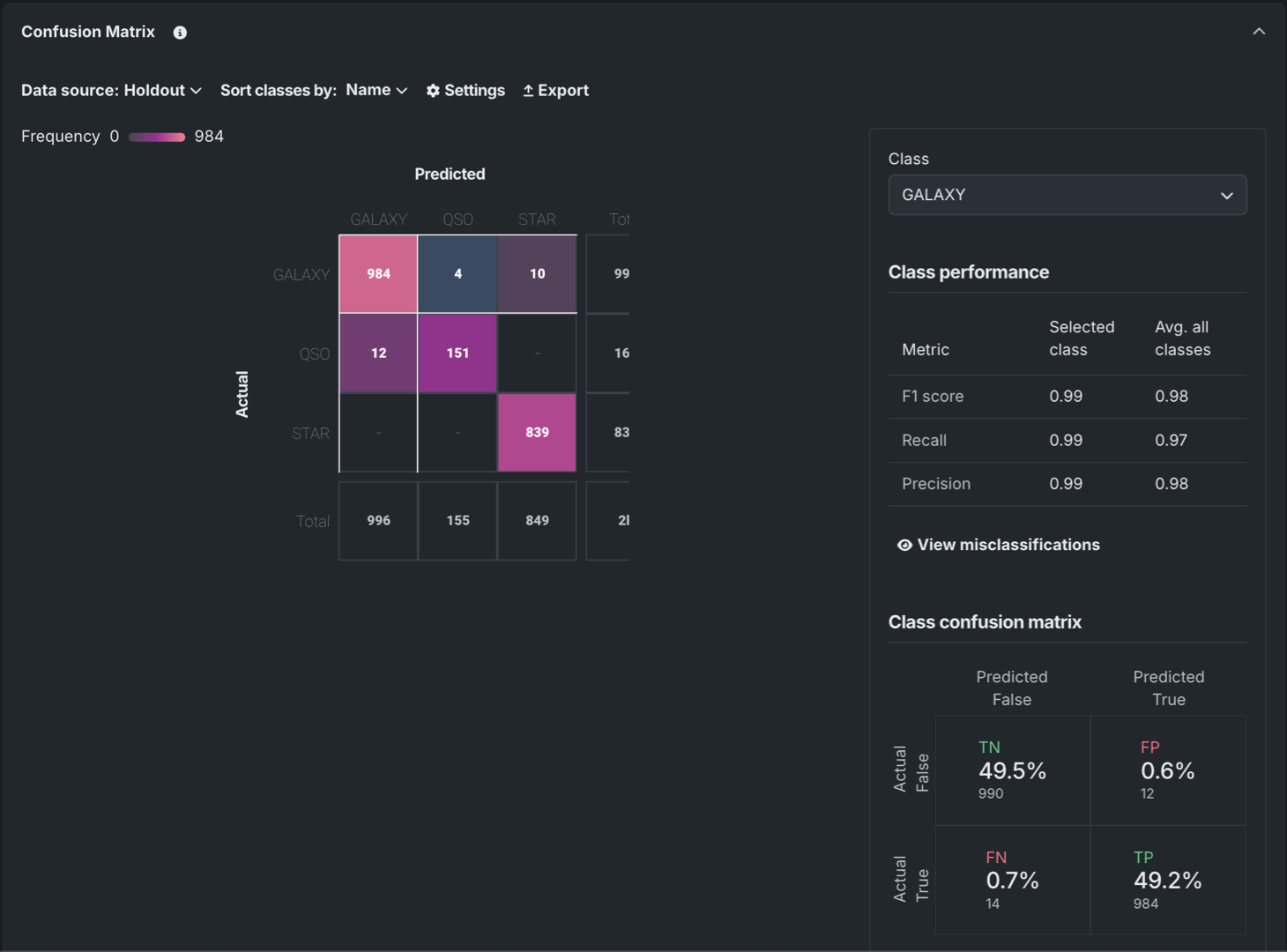
レジストリでの混同行列の表示¶
レジストリのDataRobotモデルとカスタムモデルについて、インサイトタブに混同行列のインサイトを含めることができるようになりました。 詳細については、登録モデルのインサイトのドキュメントを参照してください。
カスタムモデルでモデルのリストをサポート¶
カスタムモデルは、OpenAIクライアントの.models.list ()メソッドをサポートするようになりました。このメソッドは、デプロイで使用可能なモデルと、オーナーや可用性などの基本情報を返します。 この機能は、マネージドRAG、NIM、およびホストされたLLMですぐに利用できます。 カスタムモデルの場合は、custom.pyにget_supported_llm_models()フックを実装することで、回答をカスタマイズできます。
プラットフォーム¶
デフォルトのランディングページがNextGenになりました¶
app.datarobot.comにアクセスしたときのデフォルトのランディングページが、NextGenのホームページになりました。 ただし、特定のページ(たとえば、app.datarobot.com/projects/123abc/models)をリクエストすると、リクエストしたページが表示されます。 ユーザー設定 > システムを選択し、トグルを無効にすることで、NextGenの代わりにDataRobot Classicをデフォルトページにすることができます。
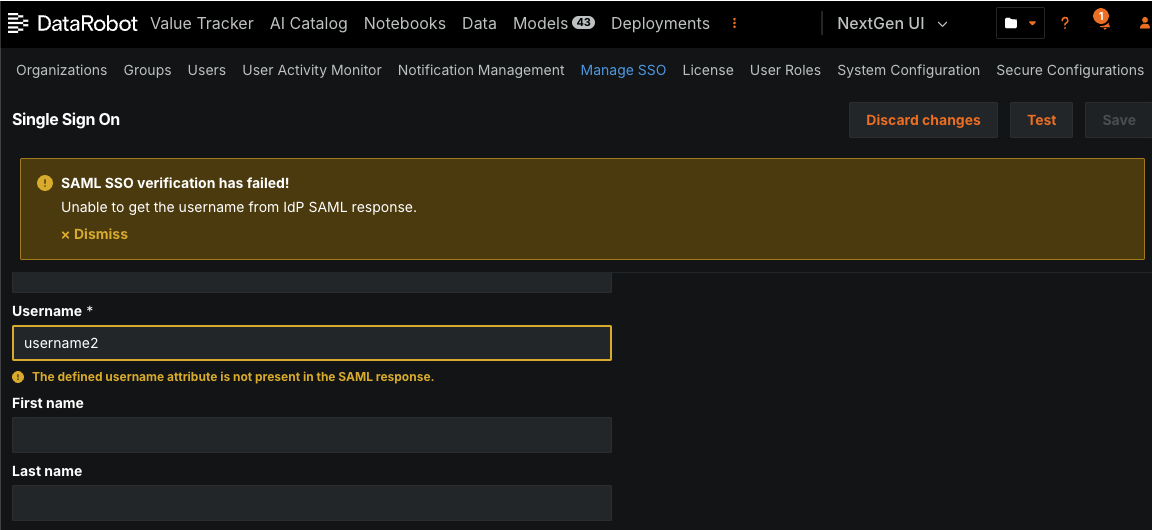
SAML SSOテストの自動化¶
SSO管理ページからSAML SSO接続を設定した後、その接続の自動テストを実施できます。 テストを実行すると、管理者はユーザー資格情報を提供し、IdP側でログインプロセスを実行します。 テストが完了すると、成功メッセージが表示されるか、何が問題だったのかを示す警告メッセージが表示され、フィールドには間違った値がハイライトされます。
Snowflake接続のFIPSパスワード要件を更新¶
FIPS認証要件の改定に伴い、DataRobotでは、資格情報が連邦情報処理標準(FIPS)に準拠することが必須となりました。FIPSは、暗号モジュールが特定のセキュリティ要件の検証をクリアしていることを保証する米政府の規格です。 DataRobotで使用されるすべての資格情報、特にSnowflakeの基本資格情報とキーペアは、以下に示すFIPS準拠の形式に従う必要があります。
- RSAキーの長さは2048ビット以上で、パスフレーズは14文字以上である必要があります。
- Snowflakeのキーペア認証では、FIPS承認のアルゴリズムを使用し、ソルト長を16バイト(128ビット)以上にする必要があります。
詳細については、FIPS検証に関するFAQを参照してください。
外部OAuthサーバー設定のサポート¶
今回のリリースでは、OAuthプロバイダーの管理ページが新たに追加され、クラスターのOAuthプロバイダーを設定、追加、削除、変更できます。

さらに、GoogleとBoxという2つの新しいOAuthプロバイダーのサポートが追加されました。 詳しくは、ドキュメントをご覧ください。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。