AutoML (V7.1)¶
2021年6月14日
DataRobot v7.1.0のリリースでは、以下のように多くの新しいUIおよびAPI機能が追加されました。 詳細については、時系列の新機能も参照してください。
期限切れの古い機能に対するサポートの変更については、サポート終了に関する重要なお知らせをご覧ください。 このドキュメントでは、DataRobotの修正された問題についても説明します。
リリースv7.1.0では、以下の言語のUI文字列の翻訳が更新されています。
- 日本語
- フランス語
- スペイン語
注目の新機能...¶
リリース7.1の主な新機能には以下が含まれます。
- New documentation experience
- Automated AI Reports
- Feature Discovery Snowflake integration
- Beta: Purpose-built AI applications with the AI App Builder
New documentation experience¶
This release introduces a new documentation experience for DataRobot platform application users.
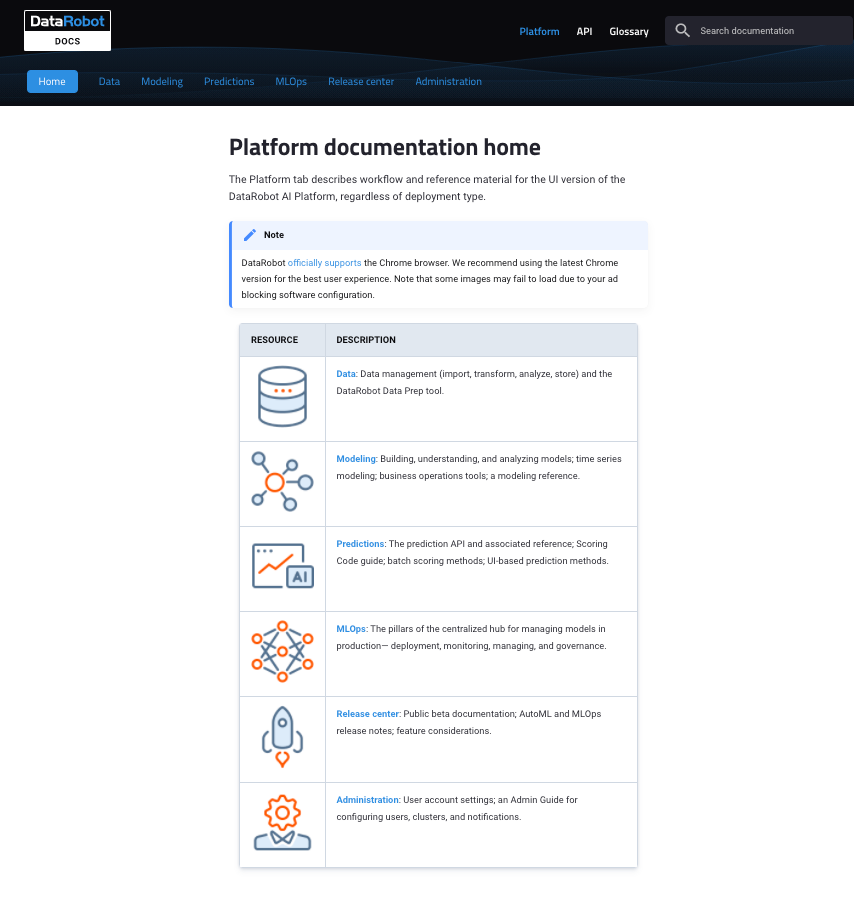
In addition to a new look, the organization has been modified to better reflect the end-to-end modeling workflow. Content has been added—and moved—to provide easier access to documentation resources. 以下に具体例を示します。
-
Content changes:
- A DataRobot glossary, which will grow over time, is available.
- API documentation—a Quickstart and REST API, Python client, and R client documentation—can be launched from within the site.
-
Zoom images for a closer look. When you hover on an image, a magnifier appears. Click once on the image to expand it in-screen, click again to return to the page.
-
Book (left-side) and page-specific (right side) table of contents make navigation easier.
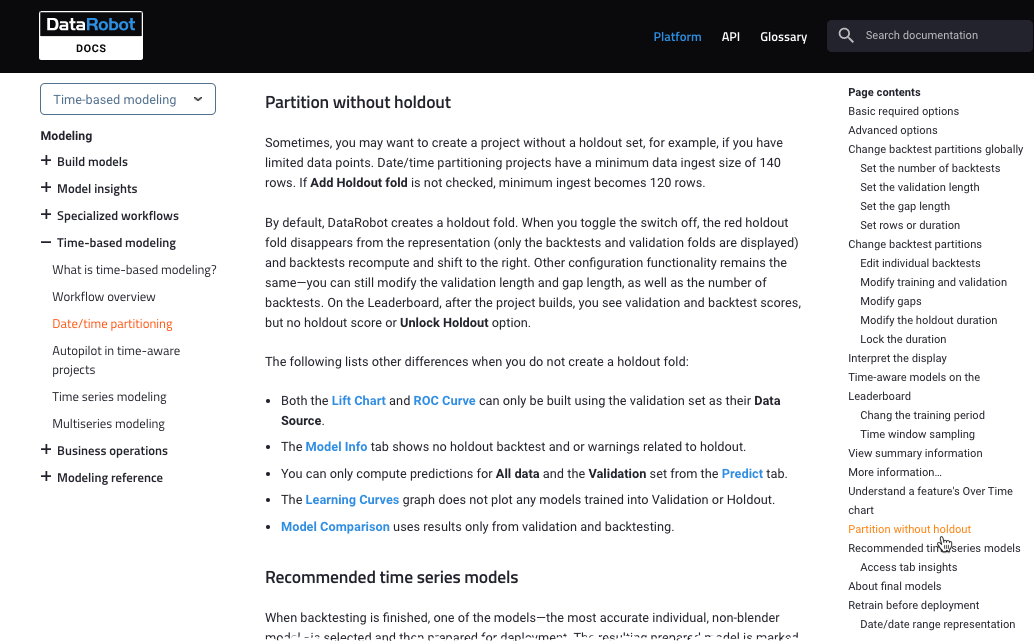
The site will continue to grow, with notebook and tutorial content coming soon. Questions, comments, and suggestions are welcome, send email to docs@datarobot.com.
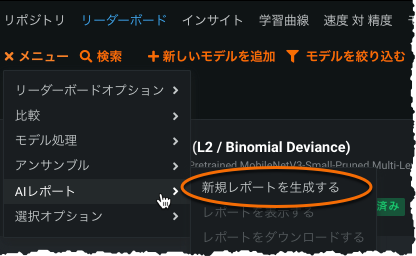
Automated AI reports¶
With this release, you can now create and download the DataRobot AI report—documentation that provides a high-level overview of the modeling building process.

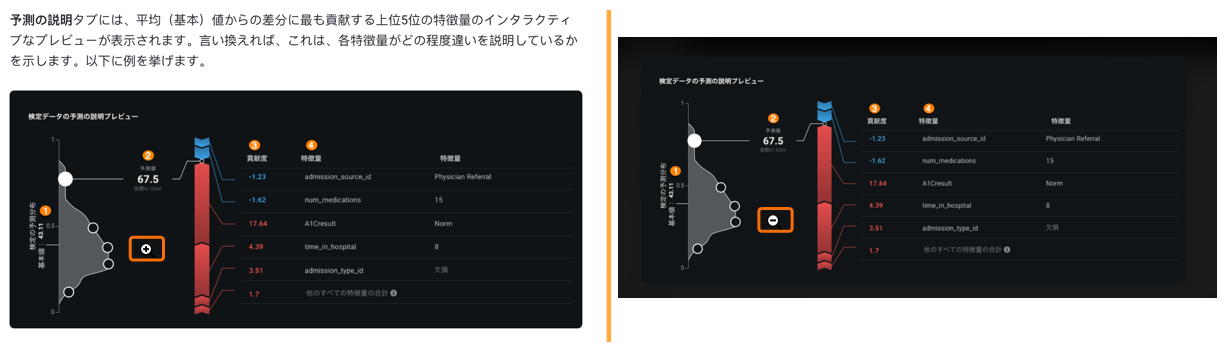
The report summarizes the most important findings of a project, allowing you to present them to stakeholders in an easily consumable format. It provides accuracy insights for the top-performing model, including speed and cross-validation scores. また、最高のパフォーマンスを発揮するモデルの特徴量のインパクトヒストグラムで解釈可能性のインサイトもキャプチャします。 Detailed model explanations, performance metrics, and ethics insights generated in the AI Report help you build overall trust in your AI projects and prove value to your key stakeholders.
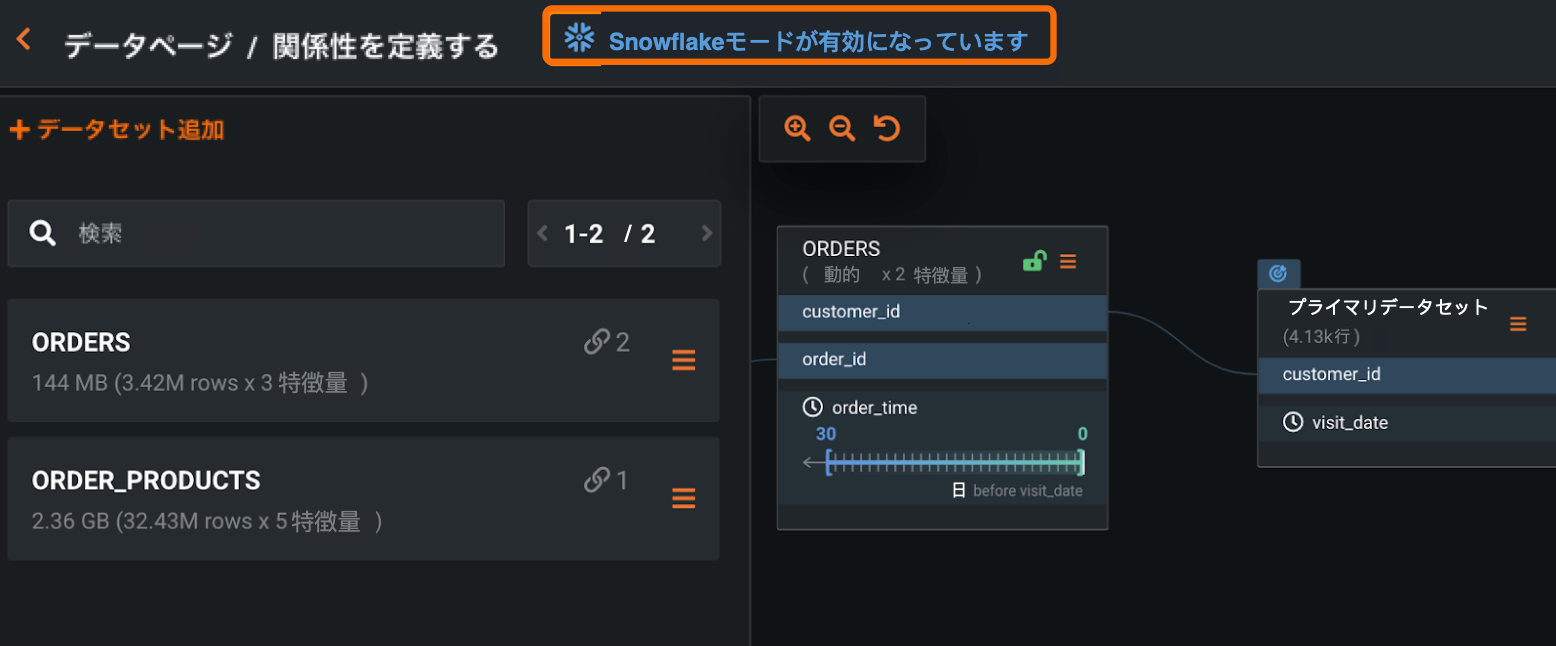
Feature Discovery Snowflake integration¶
An integration between DataRobot and Snowflake allows joint users to execute Feature Discovery projects in DataRobot while performing computations in Snowflake, when beneficial. The integration minimizes data movement, making the computation of new model features faster, more accurate, and more cost-effective. DataRobot detects whether all secondary datasets configured for the project are dynamic and are referencing tables in Snowflake. If they are, DataRobot automatically pushes joins and filtering operations into Snowflake, and then loads the smaller result set back into DataRobot. Because Feature Discovery is now starting with smaller datasets, DataRobot project runtimes are reduced.
Beta: Purpose-built AI applications with the AI App Builder¶
The AI App Builder provides a way for users without coding experience to launch, configure, and share AI-powered applications in a visual and interactive interface so that predictions can be easily shared and consumed—optimizing decision-making for a machine learning use case and delivering increased value from data.
Similar to apps deployed from the Application Gallery, each application starts with an application type and data source—either a deployment or dataset in the AI Catalog. However, in the App Builder, you can then configure additional widgets, custom features, and pages to tailor the application to a specific use case.
In Applications > Current Applications, you can view a list of existing applications and click + Create Application to create a new one in the AI App Builder.

In edit mode, create pages to organize your insights, then drag-and-drop header and chart widgets to tailor the application to a specific use case.
New AutoML features and enhancements¶
The following list the new AutoML features in release v7.1.0, described below.
- Keras-specific training dashboard
- Feature Discovery now supports anomaly detection
- New blueprints and Advanced Tuning parameters for image datasets
- Support for dynamic Spark SQL in Feature Discovery
- TinyBERT pre-trained featurizer implementation extends NLP
- Model compliance documentation for multiclass projects
- Improved Eureqa training behavior
- Beta: Feature Discovery Relationship Quality Assessment
Changes for Administrators¶
- Beta: Custom RBAC roles for users and groups
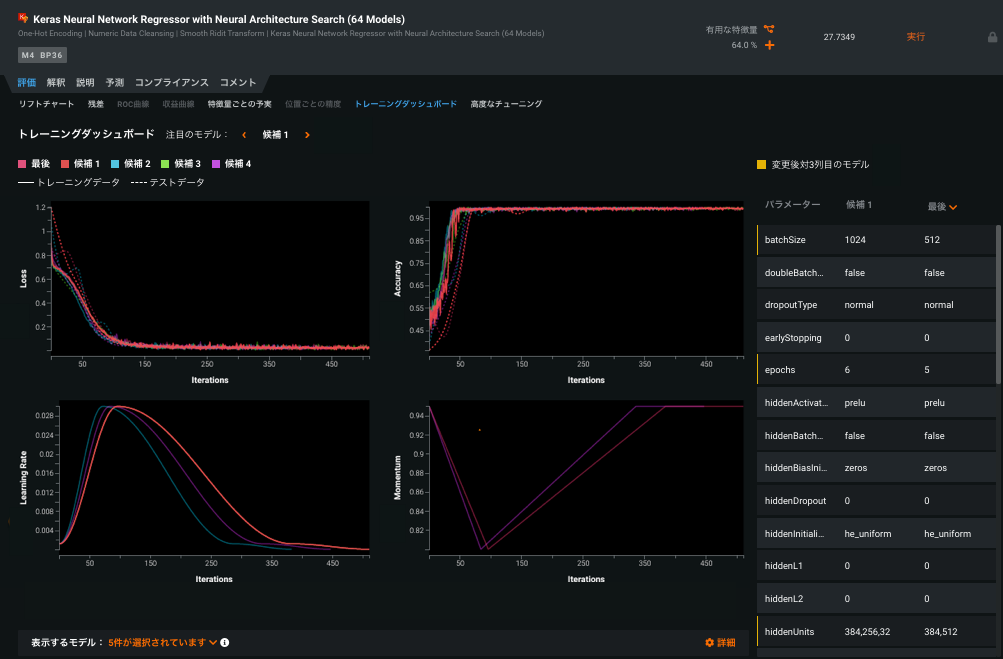
Keras-specific training dashboard¶
The Training Dashboard tab provides, for each executed candidate model, visualizations of varying hyperparameters over time. In other words, it helps to understand what happened during model training, and how well the model fits the data. The tab provides visualization in areas of training and test loss, accuracy, learning rate, and momentum across all iterations. Select candidate models to compare and modify settings to change the displays and help interpretability.
この情報を使用し、最終モデルを改善するためにチューニングするパラメーターについて情報に基づく決定を行えます。 From the dashboard you can assess the impact that each parameter has on model performance, and with direct links to the Advanced Tuning tab, you can further tune and test the model.
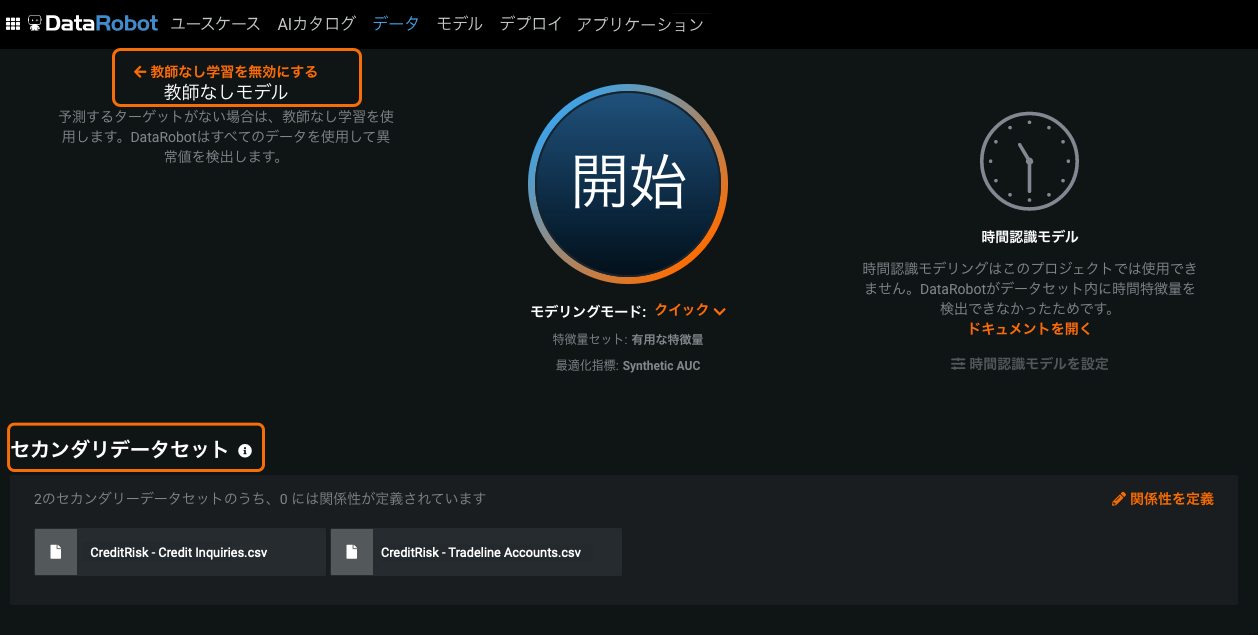
Feature Discovery now supports anomaly detection¶
Now GA: Now available, you can leverage Feature Discovery's secondary dataset capabilities to detect anomalies. When unsupervised learning (i.e., no target) is enabled, and you add a secondary dataset, Feature Discovery will extract features from the secondary datasets to help detect anomalies, removing the need to script feature engineering outside of DataRobot.
New blueprints and Advanced Tuning parameters for image datasets¶
This release makes available fine-tuning of Deep Learning convolutional neural network (CNN) with pre-trained architecture blueprints. Training a CNN on a small dataset greatly affects the deep convolutional network’s ability to generalize, often resulting in overfitting. Fine-tuning is a process that takes a pre-trained network model and applies it to a second similar task, while still allowing further customization of the layer's trainable scope and learning rate. Fine-tuning will often improve the performance and accuracy of a CNN when the project is large and drastically different in context from the pre-trained dataset. At times it even outperforms the base pre-trained CNN featurizer in small datasets that are close in context from the pre-trained dataset. From the Training Dashboard you can investigate metric scores, learning rates of each layer, and general learning rates of each iteration.
Support for dynamic Spark SQL in Feature Discovery¶
Now GA: For Feature Discovery secondary datasets, DataRobot offers the ability to enrich, transform, shape, and blend together snapshotted datasets using Spark SQL queries from within the AI Catalog. First introduced as a beta feature, and now generally available, DataRobot adds support for dynamic Spark SQL in secondary datasets for Feature Discovery projects. This new functionality increases flexibility in performing basic data prep. 認証要件は同じままです。
TinyBERT pre-trained featurizer implementation extends NLP¶
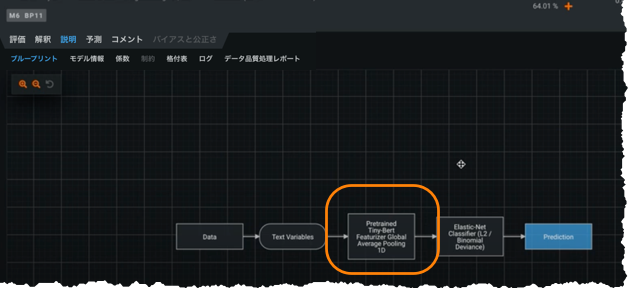
Now GA: BERT (Bidirectional Encoder Representations from Transformers) is Google's transformer-based de-facto standard for natural language processing (NLP) transfer learning. TinyBERT (or any distilled, smaller, version of BERT) is now available with certain blueprints in the DataRobot Repository. These blueprints provide pre-trained feature extraction in the NLP field, similar to Visual Artificial Intelligence (AI) featurizers with no fine-tuning needed. ただし、最大限の柔軟性を実現するために、DataRobotの実装には2つの調整可能な追加のプーリングパラメーター(最大プーリングと平均プーリング)が用意されています。 TinyBERT blueprints are available for both UI and API users.
Model compliance documentation for multiclass projects¶
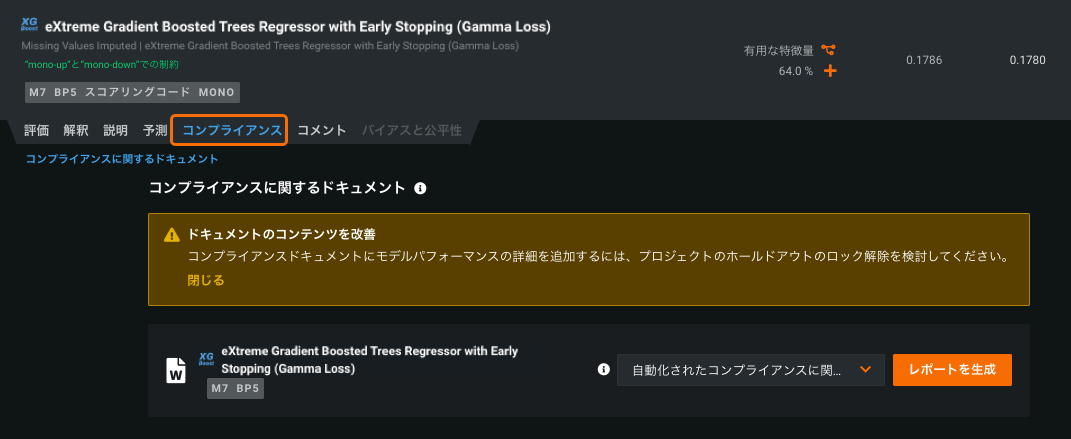
The model compliance documentation, which allows users to automatically generate and download documentation that assists with deploying models in highly regulated industries, now supports multiclass models. If available for your organization, you can generate, for each model, individualized documentation to provide comprehensive guidance on what constitutes effective model risk management. レポートは、編集可能なMicrosoft Wordドキュメント(.docx)としてダウンロードできます。 Previously only available for regression and classification, you can now include this documentation for projects with up to 100 classes. Access the option to build the model compliance documentation from a model’s Compliance tab on the project Leaderboard.
Improved Eureqa training behavior¶
With this release, new Eureqa blueprints have been added that use 250 generations (providing comparable accuracy to 1000 generations) for GAM and classic Eureqa models. The addition of these 250-generation blueprints increases the types of projects that will automatically include Eureqa as part of Autopilot (available as part of full, not quick). Other Eureqa generation-count models are still available from the Repository. See the Eureqa documentation for details on when and which models are available for AutoML and time series projects.
Beta: Feature Discovery Relationship Quality Assessment¶
Introduced as a beta feature with this release, Feature Discovery introduces a tool to automatically assess the quality of a relationship configuration—warn the user of potential problems—early in the creation process. The tool verifies join keys, dataset selection, and time-aware settings. Before EDA2 begins:
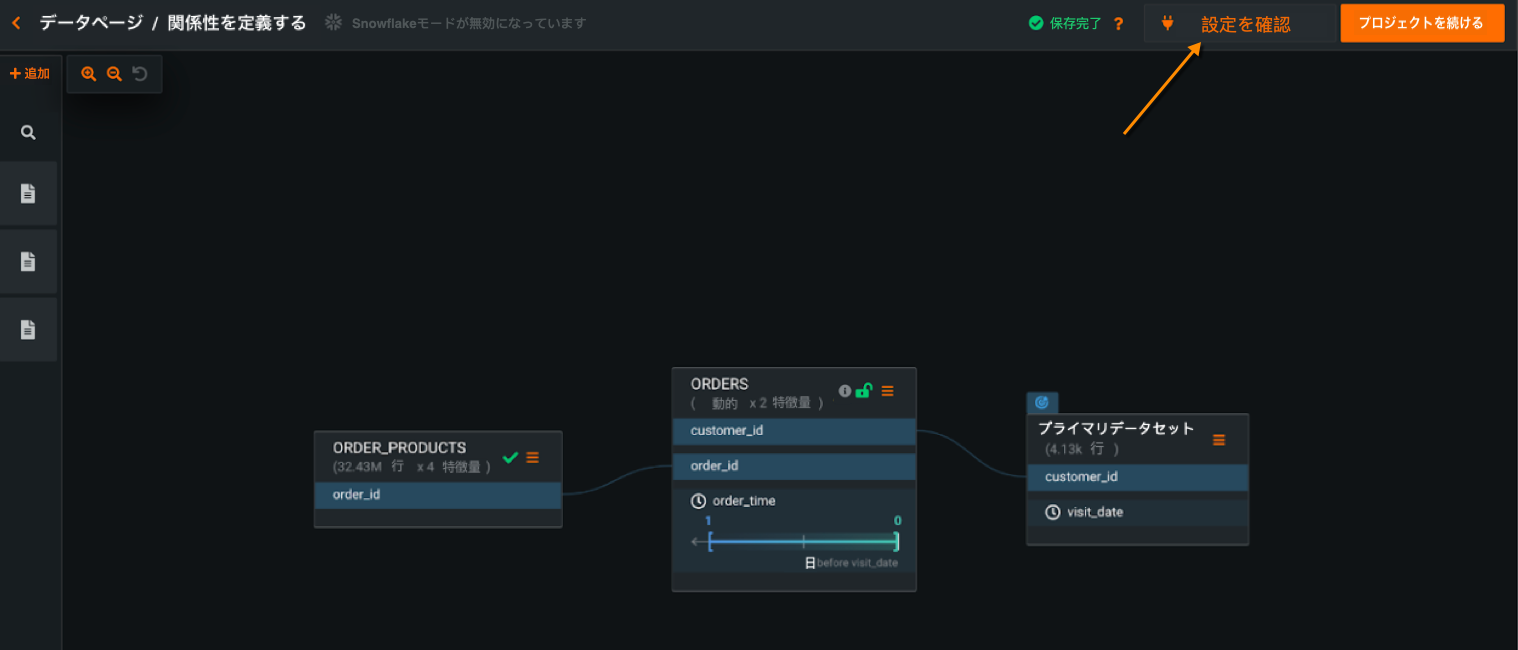
設定を確認ボタンをクリックして、関係性の品質評価をトリガーします。 進行状況インジケーター(スピナーの読み込み)が各データセットと、無効になっている設定を確認ボタンに表示され、評価が現在実行中であることを示します。 評価が完了すると、DataRobotはテストされたすべてのデータセットにマークを付けます。 問題が特定されたものには黄色の注意アイコンが表示され、問題が特定されていないものには緑色のチェックマークが表示されます。
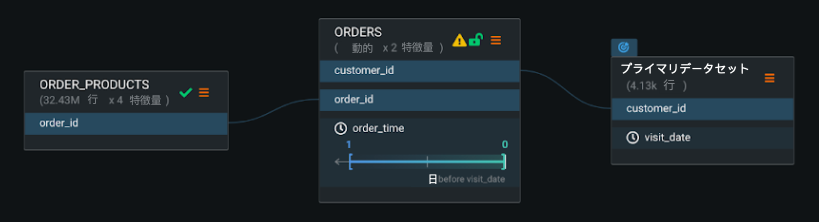
Select the dataset to view a summary of the issues with suggested potential fixes.
新しい管理機能¶
The following new feature is available to system administrators.
Custom RBAC roles for users and groups¶
With this release, DataRobot introduces custom RBAC roles—allowing admins to control user and group permissions at a more granular level. In User Settings > User Roles, admins can now create and define access for new roles when their use case does not align with the default roles in DataRobot.
APIの機能強化¶
以下は、APIの新機能と機能強化の概要です。
新機能¶
The following new functionality has been added for API release v2.25.0.
Changes to anomaly assessment insights¶
Adds the ability to compute, retrieve, and delete anomaly assessment insights for time series unsupervised projects that support calculation of Shapley values.
-
Initialize an anomaly assessment insight for the specified subset:
POST /api/v2/projects/(projectId)/models/(modelId)/anomalyAssessmentInitialization/ -
Get anomaly assessment records, SHAP explanations, predictions preview:
GET /api/v2/projects/(projectId)/anomalyAssessmentRecords/GET /api/v2/projects/(projectId)/anomalyAssessmentRecords/(recordId)/explanations/GET /api/v2/projects/(projectId)/anomalyAssessmentRecords/(recordId)/predictionsPreview/ -
Delete anomaly assessment records:
DELETE /api/v2/projects/(projectId)/anomalyAssessmentRecords/(recordId)/
Cascade sharing of underlying entities for Spark datasets¶
Adds cascade sharing of underlying entities for Spark datasets by means of the following endpoint:
PATCH /api/v2/datasets/(datasetId)/sharedRoles/
Compute and retrieve Anomaly Over Time plots¶
Adds the ability to compute and retrieve Anomaly Over Time plots for unsupervised date/time partitioned models.
-
Computation of Anomaly Over Time plots:
POST /api/v2/projects/(projectId)/datetimeModels/(modelId)/datetimeTrendPlots/ -
Retrieve Anomaly Over Time metadata:
GET /api/v2/projects/(projectId)/datetimeModels/(modelId)/anomalyOverTimePlots/metadata/ -
Retrieve Anomaly Over Time plots:
GET /api/v2/projects/(projectId)/datetimeModels/(modelId)/anomalyOverTimePlots/ -
Retrieve Anomaly Over Time preview plots:
GET /api/v2/projects/(projectId)/datetimeModels/(modelId)/anomalyOverTimePlots/preview/
機能強化¶
The isZeroInflated property, computed during EDA, has been added to the following endpoints:
`GET /api/v2/datasets/(datasetId)/allFeaturesDetails/`
`GET /api/v2/datasets/(datasetId)/versions/(datasetVersionId)/allFeaturesDetails/`
`GET /api/v2/projects/(projectId)/features/`
`GET /api/v2/projects/(projectId)/features/(featurename:featureName)/`
`GET /api/v2/projects/(projectId)/modelingFeatures/`
`GET /api/v2/projects/(projectId)/modelingFeatures/(featurename:featureName)/`
変更¶
The intakeSettings and outputSettings of the Cloud Adapters for Batch Predictions (GCP, S3, Azure) for endpoint POST /api/v2/batchPredictions/ now officially expects an intake and/or output URL field to end with a / if it should be interpreted as a directory. Otherwise, it is interpreted as a single file.
ヒント
DataRobotでは、PythonとRのために最新のAPIクライアントにアップデートすることを強くお勧めします。
サポート終了のお知らせ¶
Note the following to better plan for later migration to new releases.
Scaleout models deprecated¶
Scaleout models will be deprecated in a future release and should not be used to train new models.
お客様から報告された問題の修正¶
v7.0.2以降、以下の問題が修正されています。
特徴量探索¶
- SAFER-3632: Overrides the Spark configuration from env variable to customize app for individual customer deployments and to fix issues with Feature Discovery projects.
プラットフォーム¶
-
PLT-3052: Fixes LDAP group mapping for group names that contain special symbols.
-
EP-872: Allows ingestion of Parquet files via "Enable conversion of binary files inside worker process" when "read_only_containers" is True.
-
EP-1062: Resolves an issue when connecting to AWS Cloudwatch behind an HTTPS proxy due to a Python 3 incompatibility in the Boto library.
-
EP-1307: Adds but comments out example configurations for cluster installations that include
PYTHON3_SERVICES, so that it can be appropriately enabled for new installs where supported.
予測¶
-
PRED-5919: Fixes an issue previously causing multiple downloads when making a prediction request for a test dataset on a deployment from the Deployments page.
-
PRED-5976: Updates the configurable feature set to match Self-Managed AI Platform specifications.
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。