2022年9月¶
2022年9月27日
9月のデプロイにより、DataRobotのマネージドAIプラットフォームには、以下の一般提供およびプレビューの新機能が提供されました。 最新のデプロイについては今月のリリースノートを、過去の新機能のお知らせについてはデプロイ履歴をご参照ください。 こちらもご覧ください。
目的別にグループ化された機能
| 名前 | 一般提供 | プレビュー |
|---|---|---|
| データとインテグレーション | ||
| 特徴量探索デプロイでの特徴量キャッシュ | ✔ | |
| モデリング | ||
| ROC曲線の機能強化によるモデル解釈の支援 | ✔ | |
| 時系列のWhat-if AIアプリの作成 | ✔ | |
| 時系列 | ||
| 時系列の精度の強化 | ✔ | |
| 時系列クラスタリングを一般提供 | ✔ | |
| 予測とMLOps | ||
| 時間経過に伴うドリフトチャート | ✔ | |
| 時系列セグメントモデリングのデプロイ | ✔ | |
| MLOpsライブラリによる大規模監視 | ✔ | |
| チャレンジャーのバッチ予測ジョブ履歴 | ✔ | |
| 時系列モデルパッケージの予測間隔 | ✔ | |
| ドキュメントの変更 | ||
| ドキュメント変更の概要 | ✔ | |
| APIの機能強化 | ||
| Pythonクライアントv3.0 | ✔ | |
| Pythonクライアントv3.0の新機能 | ✔ | |
| DataRobotプロジェクト用の新しいメソッド | ✔ | |
| バックテストごとに特徴量のインパクトを計算 | ✔ | |
目的別にグループ化された機能
| 名前 | 一般提供 | プレビュー |
|---|---|---|
| データとインテグレーション | ||
| 特徴量探索デプロイでの特徴量キャッシュ | ✔ | |
| モデリング | ||
| ROC曲線の機能強化によるモデル解釈の支援 | ✔ | |
| 時系列のWhat-if AIアプリの作成 | ✔ | |
| 特徴量探索プロジェクトからのAIアプリの作成 | ✔ | |
| 時系列 | ||
| 時系列の精度の強化 | ✔ | |
| 時系列クラスタリングを一般提供 | ✔ | |
| 予測とMLOps | ||
| 時間経過に伴うドリフトチャート | ✔ | |
| 時系列セグメントモデリングのデプロイ | ✔ | |
| MLOpsライブラリによる大規模監視 | ✔ | |
| チャレンジャーのバッチ予測ジョブ履歴 | ✔ | |
| 時系列モデルパッケージの予測間隔 | ✔ | |
| ドキュメントの変更 | ||
| ドキュメント変更の概要 | ✔ | |
| APIの機能強化 | ||
| Pythonクライアントv3.0 | ✔ | |
| Pythonクライアントv3.0の新機能 | ✔ | |
| DataRobotプロジェクト用の新しいメソッド | ✔ | |
| バックテストごとに特徴量のインパクトを計算 | ✔ | |
一般提供¶
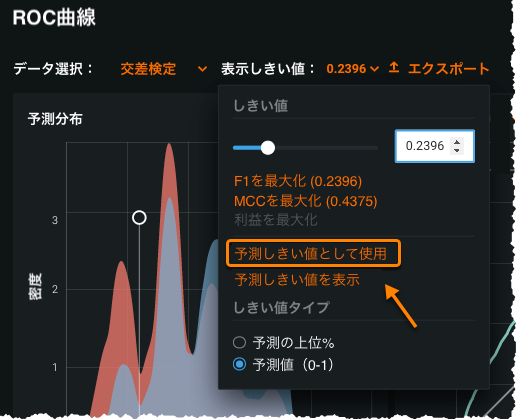
ROC曲線の機能強化によるモデル解釈の支援¶
このリリースでは、ROC曲線タブが改善され、確率スケール上のどのポイントにおいても、モデルパフォーマンスの理解を深めることができます。 視覚化を用いると、次のことがわかります。
- 行と列の合計が、混同行列に表示されます。
- 指標セクションに最大6つの精度指標が表示されるようになりました。
- 表示しきい値 > 予測しきい値を表示を使用して、視覚化コンポーネント(グラフおよびチャート)をモデルのデフォルトの予測しきい値にリセットできます。
時系列のWhat-if AIアプリの作成¶
一般提供機能になりました。時系列プロジェクトからWhat-ifシナリオのAIアプリを作成できます。これにより、強化された視覚的およびインタラクティブなインターフェイスでアプリケーションを起動して簡単に設定を行えます。 さらに、What-ifシナリオアプリをコンシューマーと共有することで、コンシューマーはビルダーで生成済みのものから簡単に構築したり、同じ予測ファイルで独自のシナリオを作成したりすることができます。
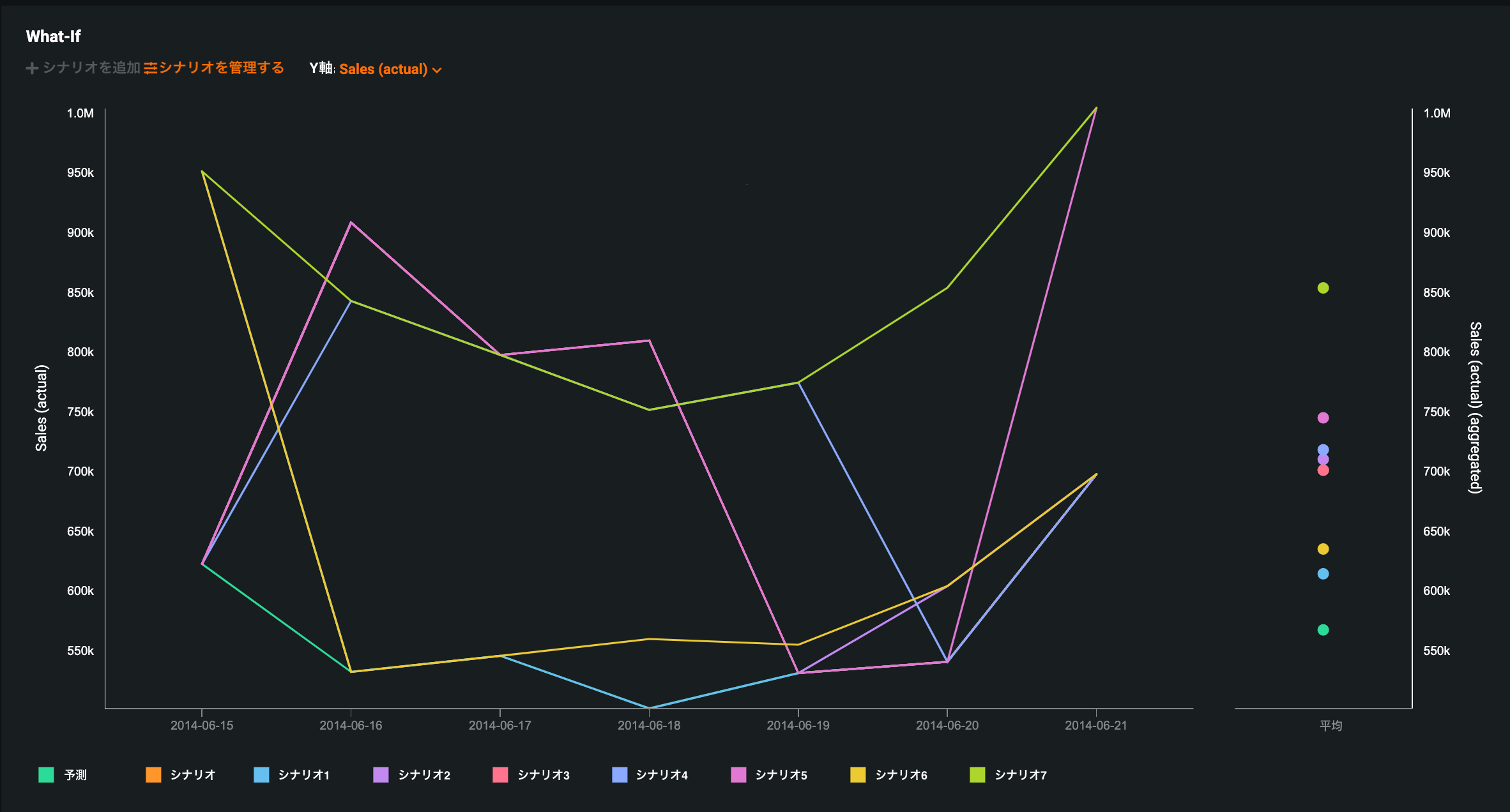
さらに、シナリオ管理機能を使えば、事前に既知の特徴量を複数のシナリオで一度に編集することができます。

詳細については、時系列アプリケーションのドキュメントを参照してください。
時系列の精度の強化¶
複数系列モデリングでは最大100万系列、1000予測距離まで対応しているため、これまで、DataRobotは、オートパイロットの一部として精度計算を行う系列数を制限していました。 現在、これらの計算を使用する視覚化では、いくつかの系列(特定のしきい値まで)を自動的に実行してから、個別または一括で追加の系列を実行することができます。

この機能を活用できる視覚化は、次のとおりです。
- 時系列の精度
- 時間経過に伴う異常
- 予測値と実測値の比較
- モデル比較
詳細については、複数系列の時系列の精度のドキュメントを参照してください。
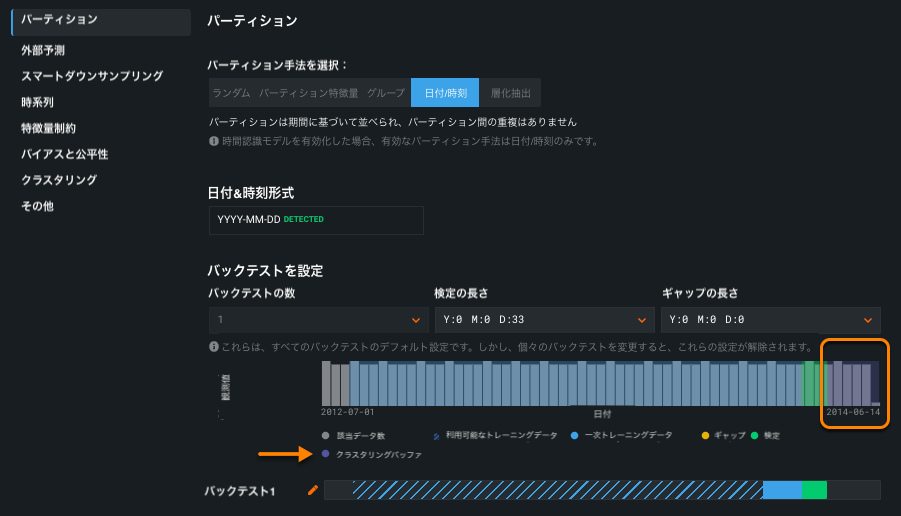
時系列クラスタリングを一般提供¶
時系列クラスタリングでは、DataRobotプラットフォーム内から、複数系列のデータセット間で類似の系列を簡単にグループ化することができます。 探索されたクラスターを使用して、データの理解を深めたり、時系列のセグメントモデリングへの入力にしたりします。 クラスタリングの一般提供により、プレビュー版から以下の点を改善しました。
-
クラスタリング専用の新しい系列のインサイトタブは、系列/クラスターの関係性や詳細に関する情報を提供します。
-
クラスターバッファはデータリーケージを防ぎ、セグメンテーションでホールドアウトパーティションになるものに対してクラスタリングモデルをトレーニングしないようにします。
時間経過に伴うドリフトチャート¶
デプロイのデータドリフトダッシュボードでは、時間経過に伴うドリフトチャートにより、デプロイされたモデルのトレーニングデータセットと、本番環境での予測生成に使用されるデータセットの間の、時間経過に伴う分布の差異が視覚化されます。 トレーニングデータセットで確立されたベースラインからのドリフトは、PSI(Population Stability Index)を用いて測定されます。 モデルが新しいデータで予測を続けると、追跡対象の特徴量ごとにPSIの経時変化が視覚化されるので、データドリフトの傾向を把握することができます。
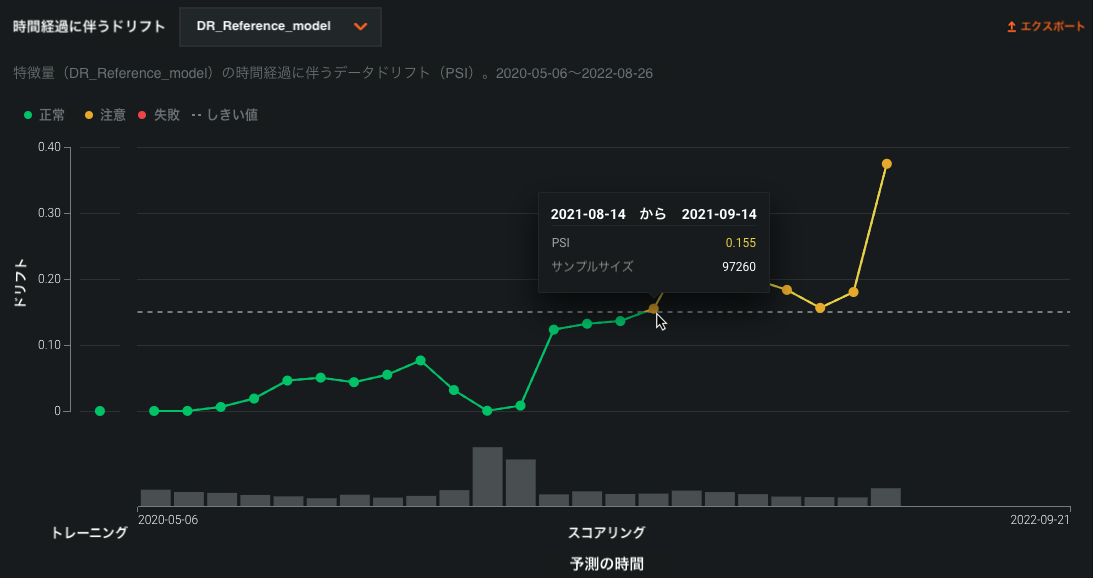
データドリフトはモデルの予測能力を低下させる可能性があるため、ある特徴量がいつドリフトし始めたかを見極め、(モデルが新しいデータで予測を続ける中で)そのドリフトがどのように変化するかを監視することは、問題の深刻度を推測するのに役立ちます。 これにより、デプロイ内の特徴量間でデータドリフトの傾向を比較し、特定の特徴量間で相関するドリフト傾向を特定することができます。 さらに、このチャートによって季節的な影響(時間認識モデルでは重要)を特定することができます。 この情報は、データ品質の問題、特徴量構成の変化、ターゲット特徴量のコンテキストの変化など、デプロイされたモデルでのデータドリフトの原因を特定するのに役立ちます。 以下の例では、PSIが時間の経過とともに一貫して増加しており、選択した特徴量のデータドリフトが悪化していることを示しています。
詳細については、時間経過に伴うドリフトチャートのドキュメントを参照してください。
時系列セグメントモデリングのデプロイ¶
セグメントモデリングの価値を最大限に活用するために、他の時系列モデルをデプロイする場合と同様に、統合されたモデルをデプロイできます。 含まれているプロジェクトごとにチャンピオンモデルを選択した後、統合モデルをデプロイし、複数のセグメントに対して「1つのモデル」デプロイを作成できます。ただし、デプロイされた統合モデル内の各セグメントでは、引き続きセグメントチャンピオンモデルがデプロイで(バックグラウンドで)実行されています。 デプロイを作成すると、精度監視、予測間隔、チャレンジャーモデル、および再トレーニングにDataRobot MLOpsを使用できます。
備考
時系列セグメントモデリングのデプロイでは、データドリフトの監視や予測の説明には対応していません。
セグメントモデリングのワークフローを完了し、オートパイロットが終了すると、モデルタブに1つのモデルが表示されます。 このモデルが完成した統合モデルです。 デプロイするには、統合されたモデル、予測 > デプロイ、モデルをデプロイの順にクリックします。
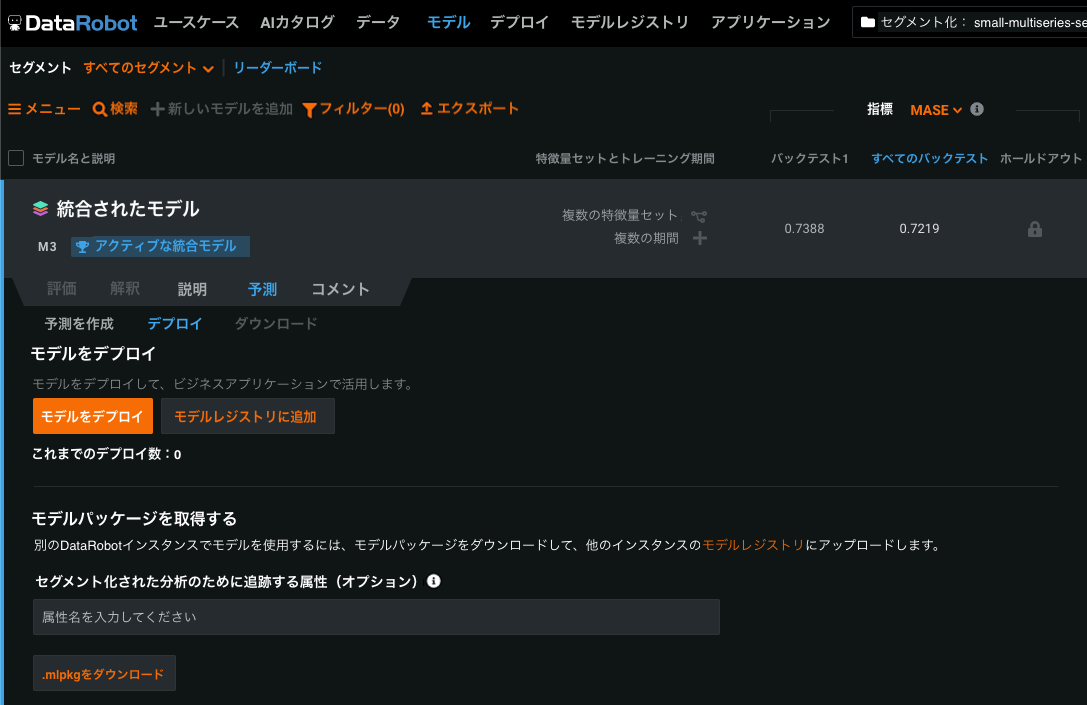
統合モデルをデプロイした後、デプロイされた統合モデルのクローンを作成し、クローンが作成されたモデルを修正することで、セグメントのチャンピオンを変更できます。 この処理は自動的に行われ、デプロイされた統合モデル内でセグメントのチャンピオンを変更しようとすると発生します。 クローンが作成され、修正可能なモデルが、アクティブな統合モデルになります。 このプロセスにより、デプロイされたモデルの安定性を確保しながら、同じセグメントプロジェクト内で変更をテストすることが可能になります。
備考
プロジェクトのリーダーボードでアクティブな統合モデル(バッジ付き)になれる統合モデルは1つだけです。
統合されたモデルがデプロイされると、予測APIは有効というラベルが設定されます。 このモデルを修正するには、アクティブでデプロイ済みの統合モデルをクリックし、セグメントタブで修正したいセグメントをクリックします。
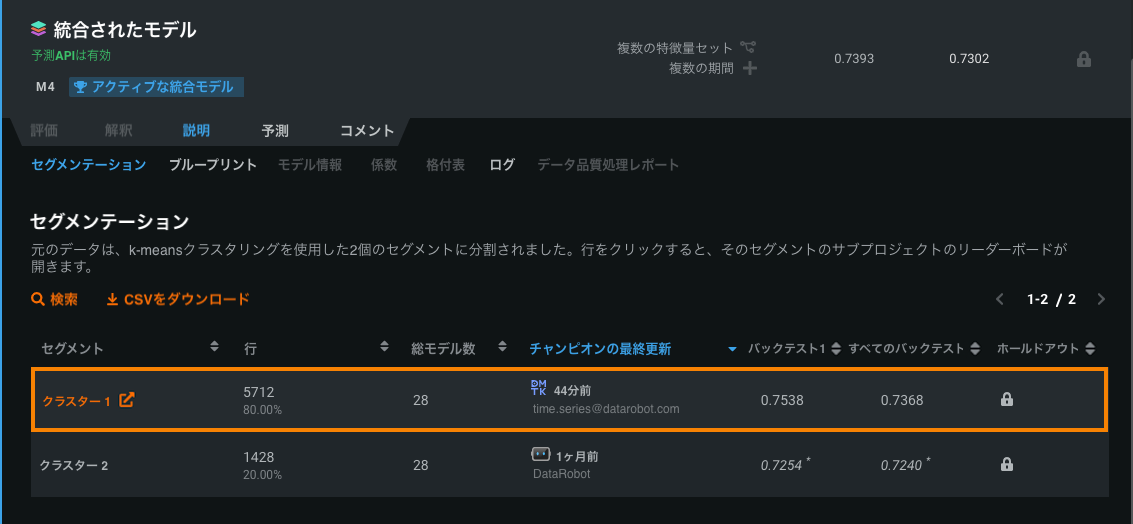
次に、セグメントチャンピオンを再割り当てし、表示されるダイアログボックスではい、新しい統合モデルを作成しますをクリックします。
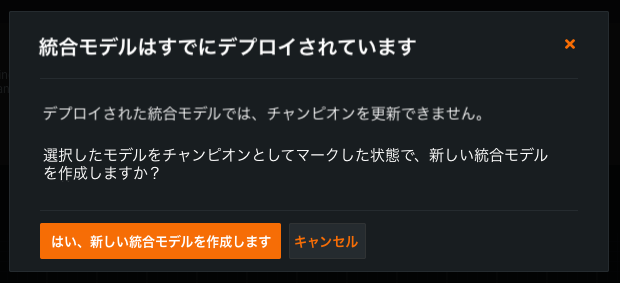
セグメントのリーダーボードで、アクティブな統合モデルにアクセスして修正できるようになりました。
詳細については、統合されたモデルのデプロイのドキュメントを参照してください。
MLOpsライブラリによる大規模監視¶
大規模な監視をサポートするために、MLOpsライブラリは、クライアント側で元のデータから統計情報を計算する方法を提供します。 そして、DataRobot MLOpsサービスに元の特徴量と予測値を報告する代わりに、クライアントは特徴量と予測データを含まない匿名化された統計情報を報告することができます。 クライアント側で計算された予測データの統計情報を報告することは、元データの報告と比較して、特に大規模な場合(数十億行の特徴量と予測値)に最適(かつ高パフォーマンスな)方法です。 また、クライアント側の集計では、特徴量値の集計を送信するだけなので、実際の特徴量値を公開したくない環境に適しています。
これまで、この機能はJava SDKとMLOps Spark Utils Library向けにリリースされていました。 このリリースから、大規模監視機能をPythonで利用できるようになりました。
Pythonコードで大規模監視を利用するには、report_predictions_data()の呼び出しを以下の呼び出しに置き換えてください。
report_aggregated_predictions_data(
self,
features_df,
predictions,
class_names,
deployment_id,
model_id
)
大規模監視機能を有効にするには、特徴量型の設定のいずれかを行う必要があります。 この設定ではデータセットの特徴量型を指定しますが、コード内でプログラム的に(セッターを使用して)、または環境変数を定義することによって行います。
詳細については、大規模監視の有効化のユースケースを参照してください。
チャレンジャーのバッチ予測ジョブ履歴¶
チャレンジャーモデルのエラー表示と操作性を向上させるため、デプロイ > チャレンジャータブからチャレンジャーの予測ジョブ履歴にアクセスできるようになりました。 1つまたは複数のチャレンジャーモデルを追加し、予測を再実行したら、ジョブ履歴をクリックします。

デプロイ > 予測ジョブページが開き、ジョブ履歴にアクセスしたデプロイのチャレンジャージョブが表示されるようにフィルターされます。 このフィルターは、予測ジョブページから直接適用することもできます。
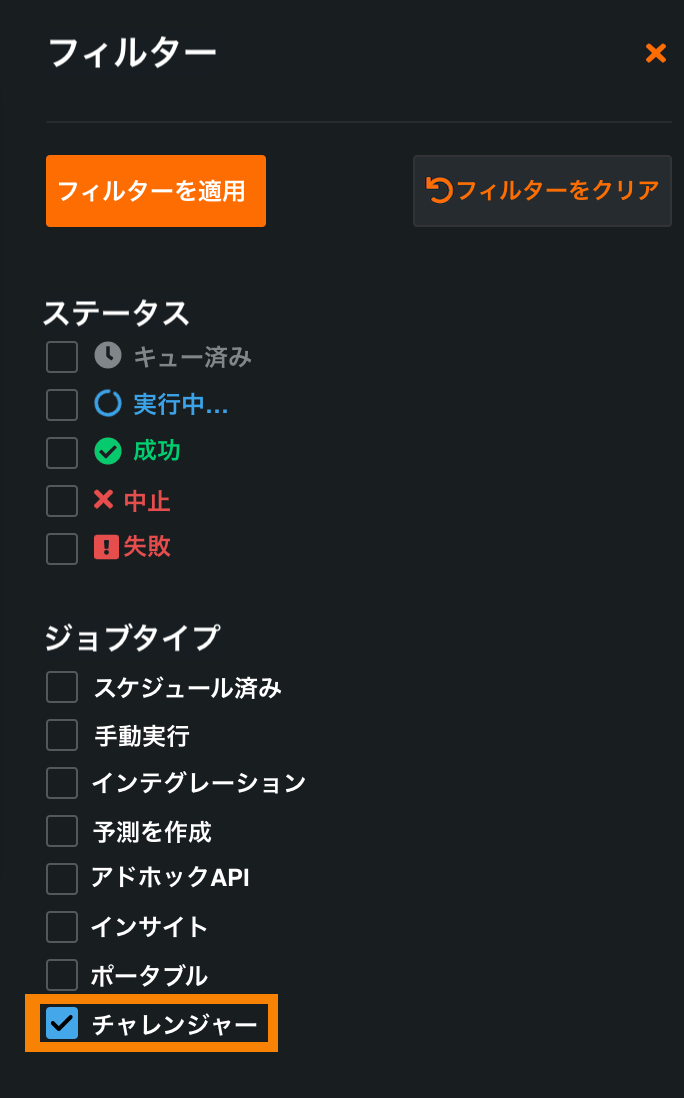
詳細については、チャレンジャージョブの履歴表示に関するドキュメントを参照してください。
ドキュメント変更の概要¶
このリリースでは、アプリ内および一般向けのドキュメントに以下の改善を行いました。
-
時系列のドキュメントを強化:高度なモデリングに関するセクションは、時系列プロジェクトでデフォルト設定を変更することを計画している場合、最適なウィンドウとバックテストの設定を決定する方法について理解するのに役立ちます。 さらに、資料を少し整理し、モデリングプロセスの各ステップごとにページを設け、段階別に解説するようにしました。
-
[詳細]セクションを追加:ユーザードキュメントのトップページに「詳細」セクションが追加されました。 ここから、DataRobot用語集やチュートリアル(英語のみ)などにアクセスできます。 さらに、「リリース」セクションが「UIドキュメント」からトップページに移動したことで、リリースに関する資料にアクセスしやすくなりました。
-
価格弾力性のユースケース:APIユーザーガイドで、需要の価格弾力性のユースケースが追加されました。これは、価格の変更が特定の商品に対する消費者の需要に与える影響を理解するのに役立ちます。 ユースケースのノートブックにあるワークフローに従って、価格と需要の関係性を特定し、商品に適切な価格を設定して収益を最大化し、価格と需要の変化について価格弾力性を監視し、価格弾力性の取得と更新に使用する手動プロセスを削減する方法を理解します。
プレビュー¶
時系列モデルパッケージの予測間隔¶
プレビュー版の機能です。モデルパッケージ生成時に、モデルの時系列予測間隔(1~100)の計算を有効にすることができます。 モデルパッケージ生成時に、モデルの時系列予測間隔(1~100)の計算を有効にすることができます。 DataRobotの時系列モデルをリモート予測環境で実行するには、モデルのデプロイまたはリーダーボードからモデルパッケージ(.mlpkgファイル)をダウンロードします。 その後、DataRobotの外でポータブル予測サーバー(PPS)を使って予測ジョブを実行できます。
デプロイから予測間隔を含むモデルパッケージをダウンロードする前に、デプロイがモデルパッケージのダウンロードをサポートしていることを確認します。 デプロイには、DataRobotの構築環境と外部予測環境が必要です。これは、デプロイインベントリのガバナンスレンズを使用して確認することができます。

予測間隔を含むモデルパッケージをデプロイ(外部デプロイ)からダウンロードするには、予測 > ポータブル予測タブを使用します。
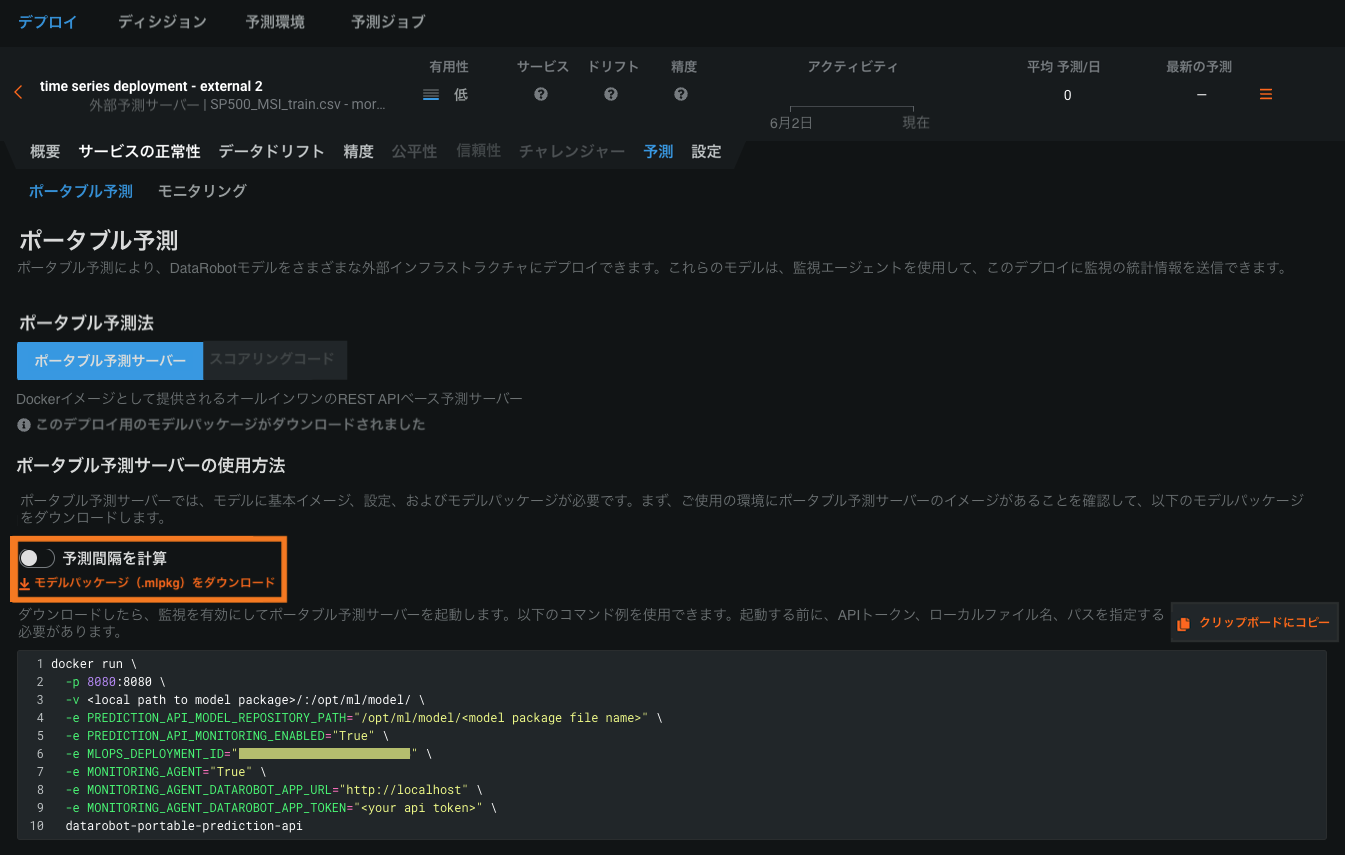
予測間隔を含むモデルパッケージをリーダーボードにあるモデルからダウンロードするには、予測 > デプロイまたは予測 > ポータブル予測タブを使用できます。
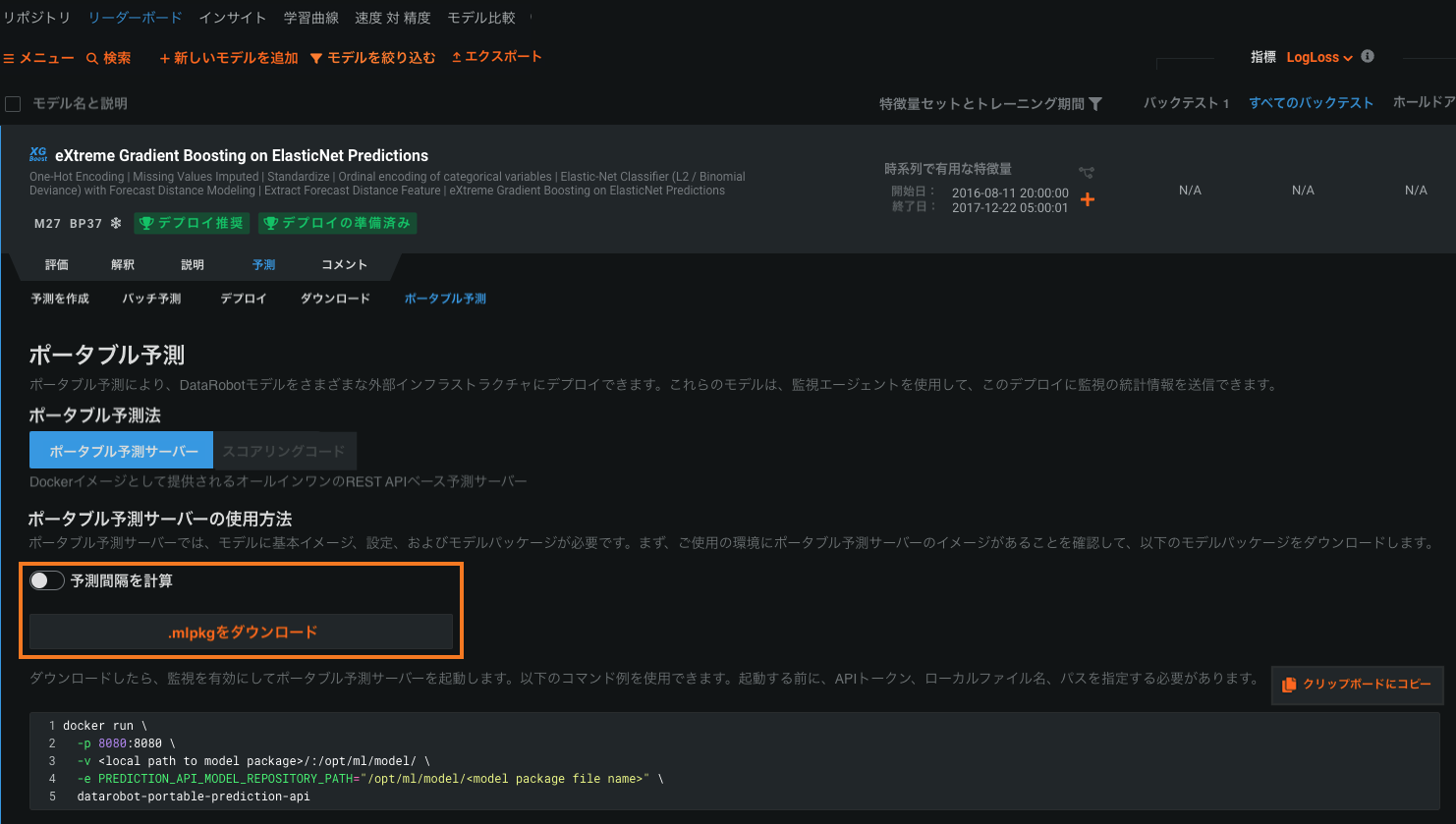
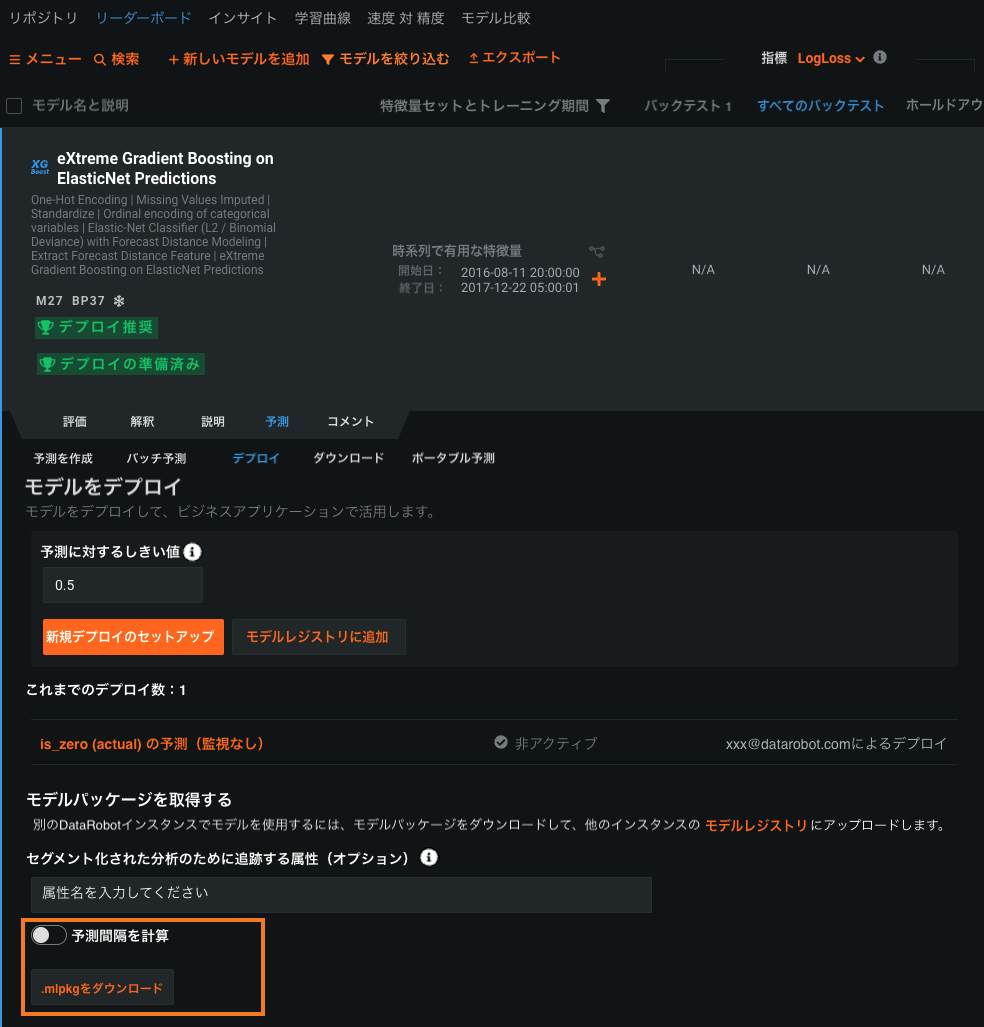
詳しくはドキュメントをご覧ください。
特徴量探索プロジェクトからのAIアプリの作成¶
SaaSユーザーのみ。 特徴量キャッシュは、複数のデータセットからデータを取得し、事前に新しい特徴量を生成して「キャッシュ」に格納し、その情報を用いて予測を行うようDataRobotに指示します。
必要な機能フラグ:
- アプリケーションビルダーで特徴量探索のサポートを有効にする
- 特徴量探索で特徴量キャッシュを有効化
プレビュー機能のドキュメントをご覧ください。
特徴量探索デプロイでの特徴量キャッシュ¶
プレビュー版の機能です。特徴量探索のデプロイに特徴量キャッシュをスケジュールすることで、予測を行う前に特徴量を事前に計算して保存するようDataRobotに指示できます。 これらの特徴量を事前に生成しておくことで、特徴量探索プロジェクトにおいて、単一レコード、低レイテンシーのスコアリングが可能になります。
特徴量キャッシュを有効にするには、特徴量探索デプロイの設定タブに移動します。 次に、特徴量キャッシュのトグルをオンにして、DataRobotがキャッシュされた特徴量を更新するスケジュールを選択します。
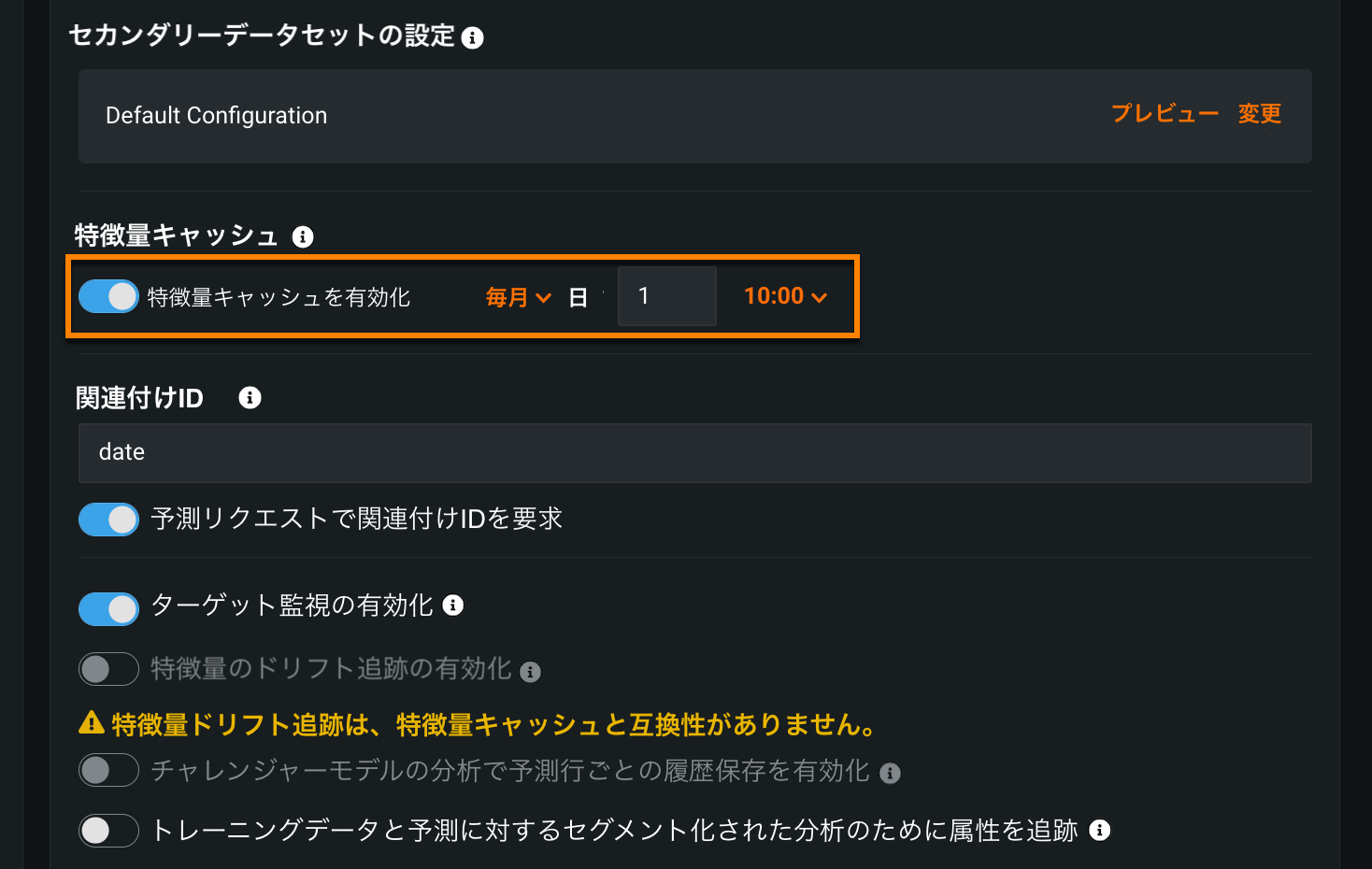
特徴量キャッシュが有効になり、デプロイの設定で定義されると、DataRobotは特徴量をキャッシュし、データベースに保存します。 新しい予測が行われると、プライマリーデータセットが予測エンドポイントに送られます。それにより、キャッシュからのデータが利用され、予測応答が返されます。 その後、特徴量キャッシュは、指定されたスケジュールに基づいて定期的に更新されます。
必要な機能フラグ:特徴量探索で特徴量キャッシュを有効化
プレビュー機能のドキュメントをご覧ください。
APIの機能強化¶
以下は、APIの新機能と機能強化の概要です。 各クライアントの詳細については、APIドキュメントをご覧ください。
ヒント
DataRobotでは、PythonとRのために最新のAPIクライアントにアップデートすることを強くお勧めします。
Pythonクライアントv3.0¶
DataRobotは、Pythonクライアントのバージョン3.0をリリースし、一般提供を開始しました。 このバージョンでは、クライアントの一般的なメソッドと使用方法に大幅な変更が加えられています。 主な変更点は以下の通りですが、バージョン3.0で導入された変更点の完全なリストはchangelogをご覧ください。
Pythonクライアントv3.0の新機能¶
バージョン3.0の新機能の概要は以下のとおりです。
- バージョン3.0のPythonクライアントは、Python 3.6以前のバージョンには対応していません。 バージョン3.0では、現在Python 3.7以降をサポートしています。
project.start_autopilotメソッドのデフォルトのオートパイロットモードがAUTOPILOT_MODE.QUICKに変更されました。- ファイル、ファイルパス、またはDataFrameをデプロイに渡すと、新しいメソッド
Deployment.predict_batchを使って簡単にバッチ予測を行い、結果をDataFrameとして返すことができます。 - 新しいメソッドを使用して、プロジェクト、モデル、デプロイ、またはデータセットの正規URIを取得できます。
Project.get_uriModel.get_uriDeployment.get_uriDataset.get_uri
DataRobotプロジェクト用の新しいメソッド¶
datarobot.models.Projectで利用可能な新しいメソッドをご確認ください。
Project.get_optionsでは、保存されたモデリングオプションを取得できます。Project.set_optionsは、モデリングに使用するAdvancedOptionsの値を保存します。Project.analyze_and_modelは、DataRobotにアップロードされたデータを使用して、オートパイロットまたはデータ解析を開始します。Project.get_datasetは、プロジェクトの作成に使用されたデータセットを取得します。Project.set_partitioning_methodは、入力された引数に基づいて、通常のプロジェクトに適したPartitionクラスを作成します。Project.set_datetime_partitioningは、時系列プロジェクトに適したPartitionクラスを作成します。Project.get_top_modelは、選択した指標について最もスコアの高いモデルを返します。
バックテストごとに特徴量のインパクトを計算¶
特徴量のインパクトは、特にモデルのコンプライアンスドキュメントにおいて、モデルの概要をわかりやすく示します。 さまざまなバックテストとホールドアウトパーティションでトレーニングされた時間依存モデルでは、バックテストごとに異なる特徴量のインパクトの計算を行うことができます。 一般提供機能になりました。DataRobotのREST APIを使用して、バックテストごとに特徴量のインパクトを計算できます。これにより、特徴量のインパクトのスコアをバックテスト間で比較することによって、時間経過に伴うモデルの安定性を検査できます。
サポート終了のお知らせ¶
サポートが終了したAPI¶
バージョン3.0で使用非推奨となったAPIをご確認ください。
Project.set_targetは削除されました。 代わりにProject.analyze_and_modelを使用してください。PredictJob.createは削除されました。 代わりにModel.request_predictionsを使用してください。Model.get_leaderboard_ui_permalinkは削除されました。 代わりにModel.get_uriを使用してください。Project.open_leaderboard_browserは削除されました。 代わりにProject.open_in_browserを使用してください。ComplianceDocumentationは削除されました。 代わりにAutomatedDocumentを使用してください。
DataRobot Primeモデルの使用を非推奨¶
DataRobot Primeは、DataRobotアプリケーションの外で使用するためのダウンロード可能な派生モデルを作成する方法ですが、今後のリリースで削除される予定です。 スコアリングコード機能を使用してRulefitモデルからPythonまたはJavaコードをエクスポートする新しい機能に置き換えられます。 RulefitモデルがPrimeと異なるのは、親モデルからの予測ではなく元のデータを予測ターゲットに使用する点のみです。 他のタイプのブループリントではJavaスコアリングコードの利用について変更はなく、既存のPrimeモデルは引き続き機能します。
オートモデル機能を削除¶
今後のリリースで、プレビュー機能の「オートモデル」が削除される予定です。 既存のプロジェクトに影響はありませんが、この機能は製品からアクセスできなくなりました。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。