コードファースト(V10.2)¶
2024年11月21日
DataRobot v10.2リリースには、コードファーストユーザーに対する多くの新機能が含まれています。以下にそれらの新機能を示します。 リリース10.2のその他の詳細については、以下をご覧ください。
コードファースト機能
* プレミアム機能
アプリケーション¶
一般提供¶
アプリケーションテンプレートギャラリーを使用してDataRobotのアセットをプロビジョニング¶
アプリケーションテンプレートは、DataRobotのリソースをプロビジョニングするためのコードファーストでエンドツーエンドのパイプラインを提供します。 カスタマイズ可能なコンポーネントを備えたテンプレートは、予測と生成のユースケースをサポートするDataRobotのリソースをプログラムで生成することで、ユーザーを支援します。 テンプレートには必要なメタデータが含まれ、依存関係の構成設定の自動インストールを実行し、既存のDataRobotインフラストラクチャとシームレスに連携するので、ソリューションの迅速なデプロイと設定に役立ちます。
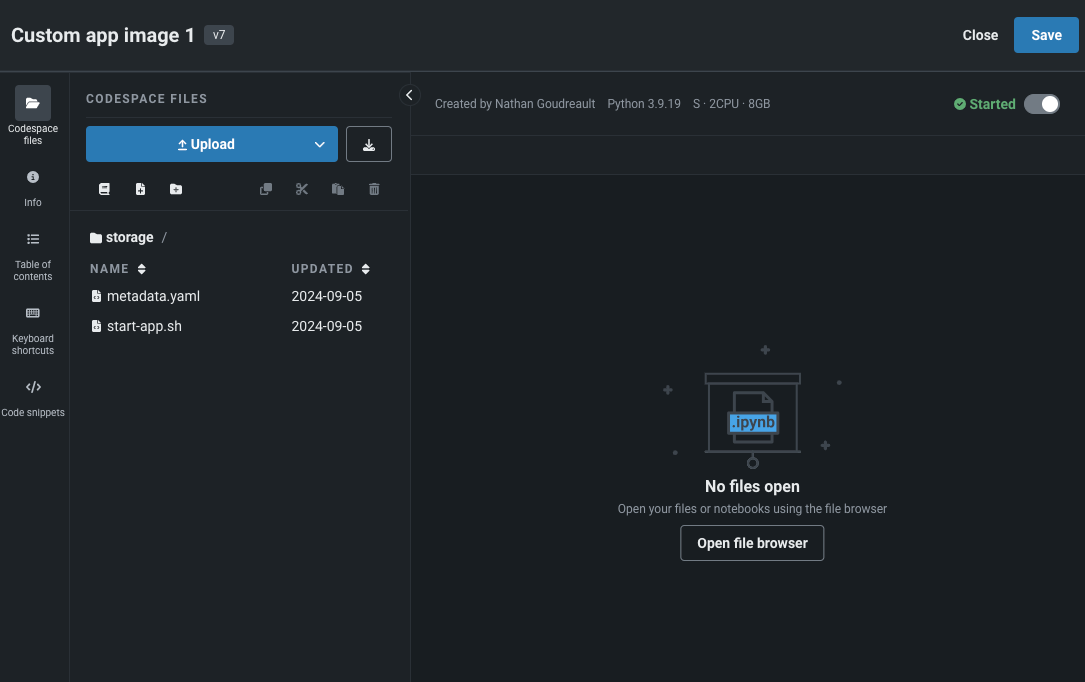
レジストリでのカスタムアプリケーションの管理¶
一般提供機能になりました。NextGenレジストリのアプリケーションページには、利用可能なカスタムアプリケーションとアプリケーションソースがすべて表示されます。 アプリケーションのソース(構築したいカスタムアプリケーションのファイル、環境、およびランタイムパラメーターが含まれます)を作成し、そこから直接カスタムアプリケーションを構築できるようになりました。 アプリケーションページを使って、共有や削除を行うことで、アプリケーションを管理することもできます。
一般提供機能として、codespaceでアプリケーションのソースを開いて管理でき、ソースのファイルを直接編集したり、新しいファイルをアップロードしたり、codespaceのすべての機能を使用したりできます。
テンプレートギャラリーからカスタムアプリケーションを構築¶
DataRobotには、カスタムアプリケーションの構築に使用できるテンプレートが用意されています。 これらのテンプレートにより、すぐに使える状態で構築済みのアプリケーションのフロントエンドを活用できます。 テンプレートは、豊富なカスタマイズオプションをフロントエンドに提供します。 これらのテンプレートは、すでにデプロイ済みのモデルを活用して、Streamlit、Flask、またはSlackアプリケーションをすばやく起動し、アクセスすることができます。 DataRobot内でカスタムコードを構築し実行するための簡単な方法として、カスタムアプリケーションテンプレートをご利用ください。

チャット生成Q&Aアプリケーションのサポートを一般提供¶
一般提供機能になりました。DataRobotでチャット生成Q&Aアプリケーションを作成し、ナレッジベースのQ&Aユースケースを探索しながら、生成AIを活用してビジネス上の意思決定を繰り返し行い、ビジネス価値を示すことができます。 Q&Aアプリは、構築したLLMモデルの結果をプロトタイプ化、調査、および共有するための直感的で応答性に優れた方法を提供します。 Q&Aアプリにより、引用に裏打ちされた生成AIの会話が可能になります。 さらに、DataRobot以外のユーザーとアプリを共有して、使いやすさを広めることもできます。
コードファーストのワークフローを使用して、チャット生成Q&Aアプリケーションを管理することもできます。 フローにアクセスするには、DataRobotのGitHubリポジトリに移動します。 このリポジトリには、アプリケーションコンポーネントのための変更可能なテンプレートが含まれています。
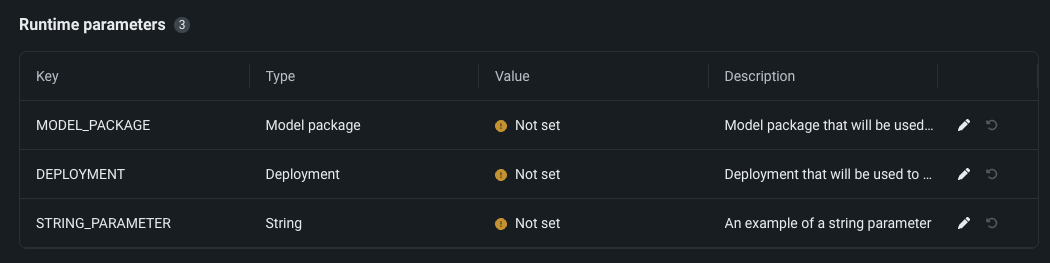
カスタムアプリケーションでランタイムパラメーターを一般提供¶
一般提供機能になりました。NextGenレジストリで、アプリケーションのソースにリソースとランタイムパラメーターを設定できます。 リソースバンドルは、本番環境での潜在的な環境エラーを最小限に抑えるために、アプリケーションが消費できるメモリーとCPUの最大量を決定します。 アプリケーションのソースから構築されたmetadata.yamlファイルに含めることで、カスタムアプリケーションで使用されるランタイムパラメーターを作成および定義できます。
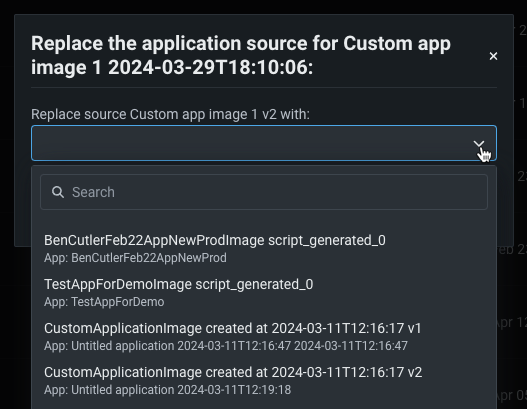
カスタムアプリケーションソースの置換¶
一般提供機能になりました。カスタムアプリケーションのアプリケーションソースを置き換えることができます。 これにより、アプリケーションのコード、基盤となる実行環境、ランタイムパラメーターなど、アプリケーションから多くの特性が引き継がれます。 ソースが置き換えられても、そのアプリケーションにアクセスできるすべてのユーザーは、引き続きアプリケーションを使用できます。
アプリケーションのログインプロセスを簡素化¶
アプリケーションの認証にAPIキーが使用されるようになりました。これにより、ワークベンチやDataRobot Classicでアプリを作成した後、OAuth認証のプロンプトをクリックする必要がなくなりました。 アプリを作成したり、共有されているアプリにアクセスすると、APIキーのリストに新しいキー(AiApp<app_id>)が表示されます。
Notebooks¶
一般提供¶
ノートブックとcodespaceでポート転送のサポートを一般提供¶
一般提供機能になりました。ノートブックとcodespaceでポート転送を有効にして、MLflowやStreamlitなどのツールやライブラリによって起動されるWebアプリケーションにアクセスできるようになりました。 ローカルで開発する場合、Webアプリケーションはhttp://localhost:PORTでアクセスできます。しかし、ホストされたDataRobot環境で開発する場合、Webアプリケーションにアクセスするには、そのアプリケーションが実行されている(セッションコンテナ内の)ポートを転送する必要があります。 1つのノートブックまたはcodespaceで、最大5つのポートを公開できます。

ノートブックのカスタム環境を作成¶
一般提供機能になりました。DataRobot NotebooksはDataRobotのカスタム環境と連携しており、ノートブックセッションを実行するための再利用可能なカスタムDockerイメージを定義できます。 カスタム環境では、環境設定を完全に制御でき、ビルトインイメージで利用可能なもの以外にも、再現可能な依存関係を活用することができます。 カスタム環境を作成したら、他のユーザーと共有したり、そのコンポーネントを更新して新しいバージョンの環境を作成したりすることができます。
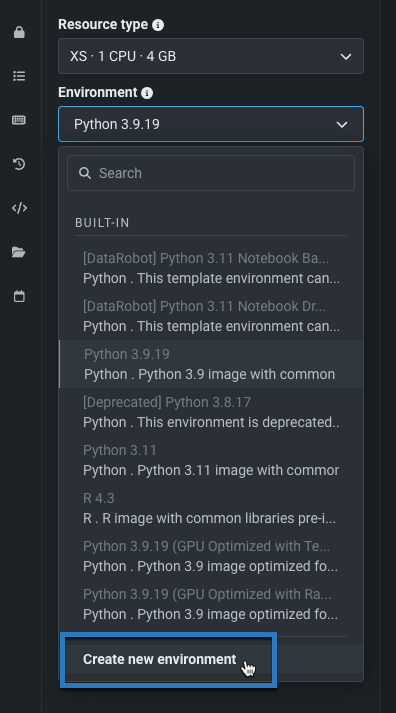
スタンドアロンのノートブックをcodespaceに変換¶
一般提供機能になりました。DataRobotでスタンドアロンのノートブックをcodespaceに変換し、永続的なファイルストレージやGitとの互換性といったワークフローの機能をさらに組み込むことができます。 これらのタイプの機能にはcodespaceが必要です。 ノートブックを変換する際、DataRobotは環境設定、ノートブックの内容、スケジュールされたジョブ定義など、多くのノートブックアセットを保持します。
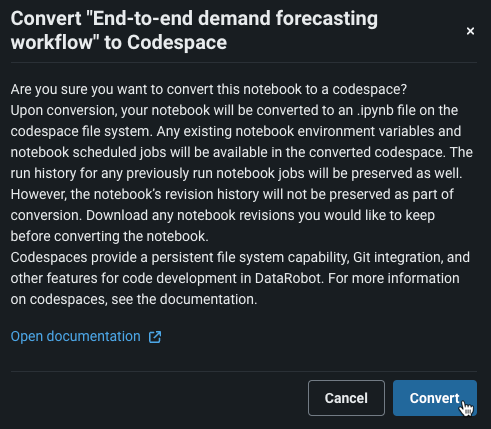
Codespaceでのスケジュール作成¶
一般提供機能になりました。Codespaceでノートブックを非対話モードでスケジュールどおりに実行することで、コードベースのワークフローを自動化できます。 スケジュールはノートブックジョブによって管理され、codespaceがオフラインの場合にのみ、新しいノートブックジョブを作成できます。 また、ノートブックをパラメーター化することで、ノートブックのスケジューリングによって可能になる自動化を強化できます。 Codespace内の特定の値をパラメーターとして定義することで、実行ごとに値を変更するためにノートブック自体を継続的に修正する必要がなく、ノートブックジョブの実行時にこれらのパラメーターに値を入力できます。
ノートブックでGPUのサポートを一般提供¶
一般提供機能になりました(マネージドAIプラットフォームのプレミアム機能)。ノートブックとcodespaceの環境設定で、リソースタイプにGPUが追加されました。
マネージドAIプラットフォームにおいて、一般提供のプレミアム機能として、ノートブックおよびcodespaceセッションでのGPUのサポートを開始しました。 DataRobotでノートブックやcodespaceのセッションに環境を設定する際、リソースタイプのリストからGPUマシンを選択できます。 DataRobotには、セッションで使用するために選択でき、GPU向けに最適化された組み込み環境も用意されています。 これらの環境イメージには、必要なGPUドライバーに加え、TensorFlow、PyTorch、RAPIDSといった、GPUにより高速化されたパッケージが含まれています。
APIの機能強化¶
Pythonクライアントv3.6¶
DataRobotのPythonクライアントのv3.6が一般提供されました。 v3.6で導入された変更の完全なリストについては、 Pythonクライアントの変更履歴を参照してください。
DataRobot REST API v2.35¶
DataRobotのREST API v2.35が一般提供されました。 v2.35で導入された変更の完全なリストについては、 REST APIの変更履歴を参照してください。
非構造化PDFドキュメントからベクターデータベースを作成¶
DataRobotでは、データセットでOCRを実行するサービスを提供し、PDFから非構造化データを簡単に抽出および準備して、ベクターデータベースを作成できるようになりました。これにより、DataRobot内でRAGフローの構築を開始できます。 このサービスでは、PDFドキュメントから抽出されたテキストでデータセットが生成され、出力されます。
宣言型APIを使用してDataRobotのアセットをプロビジョニング¶
DataRobotの宣言型APIは、反復可能かつスケーラブルな方法でリソースをエンドツーエンドでプロビジョニングするためのコードファーストの方法として使用できます。 TerraformとPulumiの両方をサポートする宣言型APIを使って、モデル、デプロイ、アプリケーションなどのDataRobotエンティティをプログラムでプロビジョニングできます。 宣言型APIを使用すると、以下のことができます。
- インフラストラクチャの望ましい最終状態を指定することで、管理を簡単にし、クラウドプロバイダー間での適応性を高めることができます。
- プロビジョニングを自動化することで、環境間の整合性を確保し、実行順序に関する懸念を解消できます。
- バージョン管理を簡単にすることができます。
- アプリケーションテンプレートを使用することで、ワークフローの重複を減らし、一貫性を確保できます。
- DevOpsやCI/CDと連携することで、予測可能かつ一貫性のあるインフラストラクチャを確保し、デプロイのリスクを軽減できます。
宣言型APIを使用して、Pulumi CLIでDataRobotのリソースをプロビジョニングする方法の例を以下に示します。
import pulumi_datarobot as datarobot
import pulumi
import os
for var in [
"OPENAI_API_KEY",
"OPENAI_API_BASE",
"OPENAI_API_DEPLOYMENT_ID",
"OPENAI_API_VERSION",
]:
assert var in os.environ
pe = datarobot.PredictionEnvironment(
"pulumi_serverless_env", platform="datarobotServerless"
)
credential = datarobot.ApiTokenCredential(
"pulumi_credential", api_token=os.environ["OPENAI_API_KEY"]
)
cm = datarobot.CustomModel(
"pulumi_custom_model",
base_environment_id="65f9b27eab986d30d4c64268", # GenAI 3.11 w/ moderations
folder_path="model/",
runtime_parameter_values=[
{"key": "OPENAI_API_KEY", "type": "credential", "value": credential.id},
{
"key": "OPENAI_API_BASE",
"type": "string",
"value": os.environ["OPENAI_API_BASE"],
},
{
"key": "OPENAI_API_DEPLOYMENT_ID",
"type": "string",
"value": os.environ["OPENAI_API_DEPLOYMENT_ID"],
},
{
"key": "OPENAI_API_VERSION",
"type": "string",
"value": os.environ["OPENAI_API_VERSION"],
},
],
target_name="resultText",
target_type="TextGeneration",
)
rm = datarobot.RegisteredModel(
resource_name="pulumi_registered_model",
name=None,
custom_model_version_id=cm.version_id,
)
d = datarobot.Deployment(
"pulumi_deployment",
label="pulumi_deployment",
prediction_environment_id=pe.id,
registered_model_version_id=rm.version_id,
)
pulumi.export("deployment_id", d.id)
Python 3プロジェクトでの時系列の精度データのストレージ¶
DataRobotでは、時系列の精度データのストレージタイプをMongoDBからS3に変更しました。
マネージドAIプラットフォーム(クラウド)では、デフォルトでBlob Storageが使用されます。 機能フラグBLOB_STORAGE_FOR_ACCURACY_OVER_TIMEが、機能アクセス設定から削除されました。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。