2022年11月
2022年11月¶
2022年11月22日
今回のデプロイにより、DataRobotのマネージドAIプラットフォームには、以下の一般提供およびプレビューの新機能が提供されました。 過去の新機能のお知らせについては、デプロイ履歴をご覧ください。 こちらもご覧ください。
目的別にグループ化された機能
| 名前 | 一般提供 | プレビュー |
|---|---|---|
| モデリング | ||
| テキスト予測の説明を一般提供 | ✔ | |
| アンサンブルモデルのデフォルト設定を変更 | ✔ | |
| 日本語のコンプライアンスドキュメント作成機能を一般提供し、内容を充実化 | ✔ | |
| クラスターモデルでの予測の説明 | ✔ | |
| [ユースケース]タブを[バリュートラッカー]に名称変更 | ✔ | |
| 予測とMLOps | ||
| カスタムモデル環境数の上限管理 | ✔ | |
| Javaアプリケーションで必要なエージェントスプーラーを動的にロード | ✔ | |
| APIの機能強化 | ||
| Rクライアント v2.29 | ✔ | |
NumPyライブラリを12月にアップグレード¶
DataRobotは2022年12月11日の週にPythonライブラリnumpyをアップグレードします。この変更によって下位互換性の問題が発生することはありません。
numpyライブラリは、プラットフォームでのデータ処理と準備に関連するさまざまな数値変換を処理します。 numpyライブラリのアップグレードは、共通脆弱性識別子(CVE)に対処するための先行的な措置です。 DataRobotでは、速度、セキュリティ、予測パフォーマンスを向上させるため、定期的にライブラリのアップグレードを行っています。
テストの結果、一部のユーザーでは、アップグレードによってモデルの予測にわずかな変化が生じる可能性があることがわかっています。 予測が変化する可能性があるのは、.xptまたは.xportファイル形式を使用してモデルをトレーニングおよびデプロイした場合だけです。 予測に変化が生じたとしても、予測値の差は通常1%未満です。 この原因は、numpyライブラリの現行バージョンからアップグレード対象バージョンまでの間に、浮動小数点の処理方法が変更されたためです。
一般提供¶
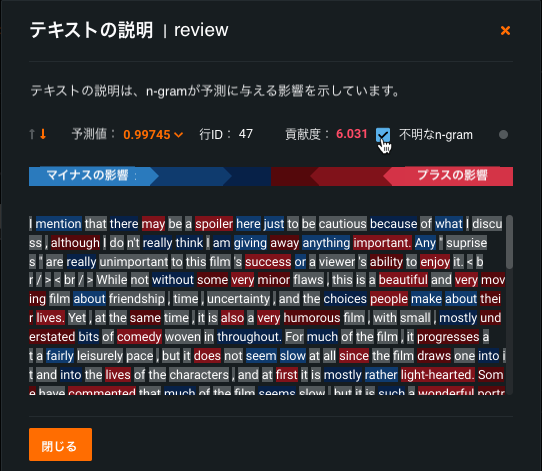
テキスト予測の説明を一般提供¶
テキスト予測の説明を使用すると、テキスト特徴量内の個々の単語 (n-gram) が予測にどのように影響するかを理解し、モデルとそれが単語に与える重要性を検証および理解するのに役立ちます。 テキスト予測の説明では、青(ネガティブ)から赤(ポジティブ)への標準的なカラーバースペクトルでインパクトを表すため、テキストを簡単に視覚化して理解できます。また、モデルで認識できないn-gramはグレーで表示されます。 テキスト予測の説明(XEMPまたはSHAP)は、データセットにテキストが存在する場合、デフォルトで実行されます。
アンサンブルモデルのデフォルト設定を変更¶
このリリースでは、アンサンブルモデルのデフォルトの動作に変更が加えられています。 アンサンブルモデルは、2つ以上のモデルの予測を組み合わせることで、精度を向上させる可能性があります。 DataRobotでは、高度なオプション上位モデルからアンサンブルを作成を有効にすると、オートパイロットの終了時に自動的にアンサンブルモデルを作成できます。 以前のデフォルト設定では、アンサンブルモデルが自動的に作成されました。現在、デフォルトではアンサンブルモデルは構築されません。
また、自動または手動でアンサンブルモデルを作成するときに使用できるモデルの数が変更されました。 当初は自動・手動ともにモデル数に制限はなく、その後、寄与するモデル数が3モデルまでに制限されましたが、この制限は1アンサンブルモデルにつき最大8モデルまでに変更されました。
今回、高度なアンサンブルモデルの自動作成が削除されました。 これらのアンサンブルモデルは逆段階的なプロセスを使用し、アンサンブルの交差検定スコアにメリットがある場合にはモデルを除外しました。
- Advanced Average (AVG) Blend
- Advanced Generalized Linear Model (GLM) Blend
- Advanced Elastic Net (ENET) Blend
以下のアンサンブルタイプは、使用非推奨になる予定です。
| アンサンブル | 非推奨の状況 |
|---|---|
| Random Forest Blend (RF) | 既存のRFアンサンブルは引き続き動作しますが、新規作成はできません。 |
| Light Gradient Boosting Machine Blend (LGBM) | 既存のLGBMアンサンブルは引き続き動作しますが、新規作成はできません。 |
| TensorFlow Blend (TF) | 既存のTFアンサンブルは動作せず、新規作成もできません。 |
これらの変更は、お客様の声に応えて行われたものです。 アンサンブルは構築時間を長引かせ、デプロイの問題を引き起こす可能性があります。今回の変更により、この機能を必要とするユーザーだけがそうした影響を受けるようになりました。 テストの結果、ほとんどの場合、精度の向上は、オートパイロットでの実行時間の増加を正当化する理由にはならないことがわかりました。 また、アンサンブル機能を必要とするデータサイエンティストの場合、手動でのアンサンブルは影響を受けません。
日本語のコンプライアンスドキュメント作成機能を一般提供し、内容を充実化¶
このリリースから、日本語でのモデルコンプライアンスドキュメントの作成が一般提供機能になりました。 モデルごとに、効果的なモデルリスク管理に関する包括的なガイダンスとなる文書を日本語で作成し、編集可能なMicrosoft Word文書としてダウンロードすることができます。 プレビュー版では、未翻訳のためにレポートから削除されたセクションがありました。 今回、以下のセクションが翻訳され、二値分類および多クラスプロジェクトで利用できるようになりました。
- バイアスと公平性
- リフトチャート
- 精度
異常検知のコンプライアンス情報はまだ翻訳されていないため、含まれていません。 この情報が必要な場合は、英語版で入手できます。 コンプライアンスレポートはプレミアム機能です。利用可能かどうかについては、DataRobotの担当者にお問い合わせください。
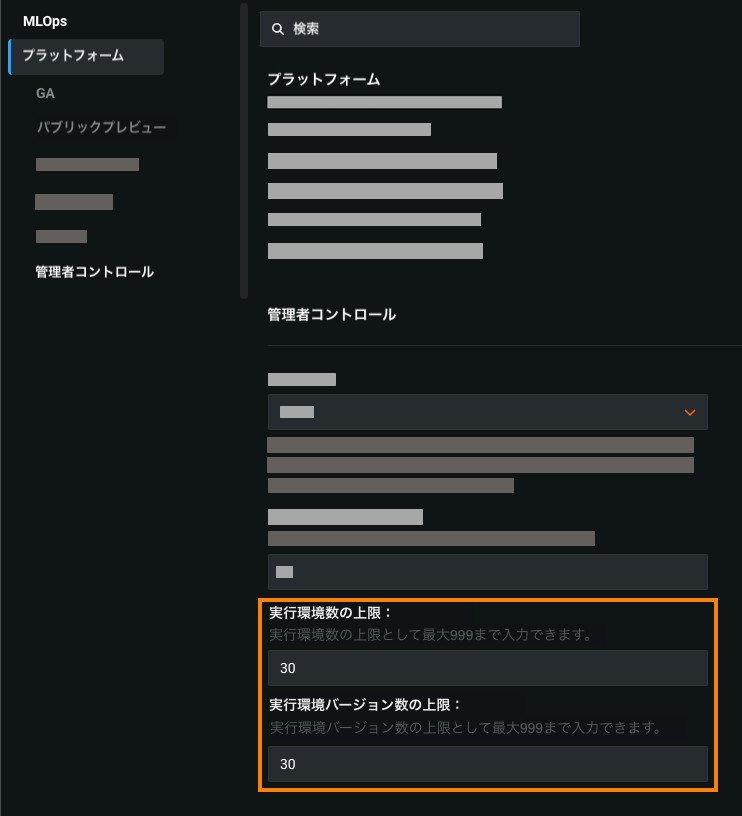
カスタムモデル環境数の上限管理¶
実行環境数に上限を設定することで、管理者は、ユーザーがカスタムモデルワークショップに追加できるカスタムモデル環境の数を制御できます。 また、実行環境のバージョン数に上限を設定することで、管理者は、ユーザーが実行環境のそれぞれに追加できるバージョンの数を制御できます。 次のように制限します。
-
ユーザーに直接適用:ユーザーの権限で設定します。 グループおよび組織の権限で設定された上限値よりも優先されます(ユーザーに対する上限値の方が低い場合)。
-
ユーザーグループから継承:ユーザーが所属するグループの権限で設定します。 組織の権限で設定された上限値よりも優先されます(ユーザーグループに対する上限値の方が低い場合)。
-
組織から継承:ユーザーが所属する組織の権限で設定します。
環境数または環境バージョン数の上限が組織またはグループに対して定義されている場合、その組織またはグループ内のユーザーは定義されている上限を継承します。 ただし、下位レベルでこれらの上限をより具体的に定義している場合は、そちらが優先されます。 たとえば、環境数の上限を組織で5、グループで4、ユーザーで3に設定した場合、個々のユーザーに対する最終的な上限は3です。カスタムモデル実行環境の追加について詳しくは、カスタムモデル環境のドキュメントを参照してください。
どのユーザーも、環境数と環境バージョン数の上限設定を確認できます。 カスタムモデル > 環境タブの新しい環境を追加ボタンと新しいバージョンボタンの横に、追加した環境(または環境バージョン)の数と、上限設定に基づき追加できる環境(または環境バージョン)の数を示すバッジが表示されます。
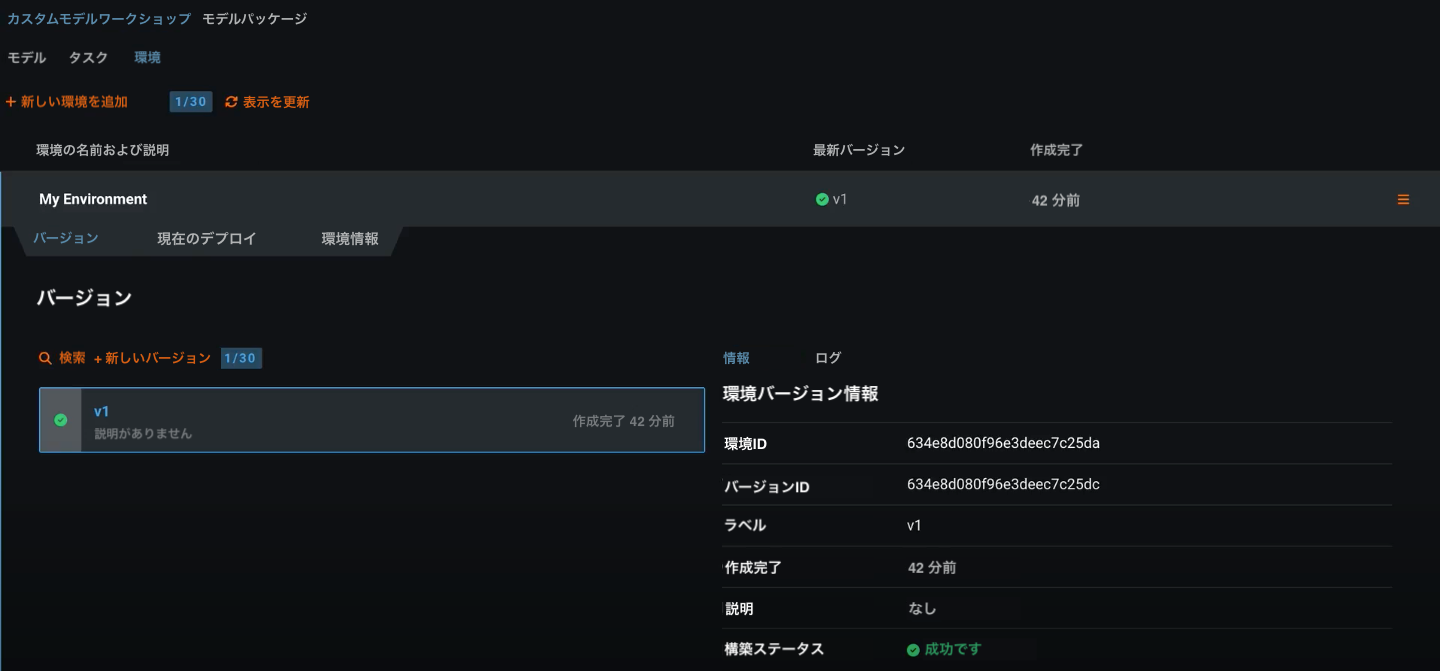
このバッジには、以下のステータスカテゴリーがあります。
| バッジ | 説明 |
|---|---|
| 環境数(またはバージョン数)は上限の75%未満です。 | |
| 環境数(またはバージョン数)は上限の75%以上です。 | |
| 環境数(またはバージョン数)は上限に達しています。 |
詳細については、ユーザーの実行環境数の上限管理のドキュメント(またはグループの実行環境数の上限管理のドキュメント)を参照してください。
Javaアプリケーションで必要なエージェントスプーラーを動的にロード¶
サードパーティーの監視エージェントスプーラーをJavaアプリケーションに動的にロードすることで、未使用のコードを削除し、セキュリティを向上できます。 この機能は、必要に応じて、Amazon SQS、RabbitMQ、Google Cloud Pub/Sub、およびApache Kafkaスプーラー用に別々のJARファイルをロードすることで使用できます。 ネイティブにサポートされているファイルシステムスプーラーは、引き続きJARファイルをロードせずに設定できます。 以前は、datarobot-mlopsとmlops-agentのパッケージに、すべてのスプーラータイプがデフォルトで含まれていました。
MLOps Javaアプリケーションでサードパーティのスプーラーを使用するには、datarobot-mlopsと一緒に、必要なスプーラーをPOM(Project Object Model)ファイルに依存関係として含める必要があります。
<properties>
<mlops.version>8.3.0</mlops.version>
</properties>
<dependency>
<groupId>com.datarobot</groupId>
<artifactId>datarobot-mlops</artifactId>
<version>${mlops.version}</version>
</dependency>
<dependency>
<groupId>com.datarobot</groupId>
<artifactId>spooler-sqs</artifactId>
<version>${mlops.version}</version>
</dependency>
スプーラーJARファイルは、 MLOpsエージェントのtarballに含まれています。 これらは DataRobot MLOpsエージェントのMaven公開リポジトリで、ダウンロード可能なJARファイルとして個別に入手することもできます。
実行可能なエージェントJARファイルでサードパーティのスプーラーを使用するには、スプーラーへのパスをクラスパスに追加します。
java ... -cp path/to/mlops-agent-8.3.0.jar:path/to/spooler-kafka-8.3.0.jar com.datarobot.mlops.agent.Agent
例として提供されているstart-agent.shスクリプトは、このタスクを自動実行し、libディレクトリにあるスプーラーJARファイルをクラスパスに追加します。 スプーラーJARファイルが別のディレクトリにある場合は、MLOPS_SPOOLER_JAR_PATH環境変数を設定してください。
詳細については、Javaアプリケーションで必要なスプーラーを動的にロードのドキュメントを参照してください。
[ユースケース]タブを[バリュートラッカー]に名称変更¶
このリリースから、DataRobotの上部にあるユースケースタブがバリュートラッカーに名称変更されました。 機能に変更はありませんが、この機能における「ユースケース」はすべて「バリュートラッカー」に置き換えられています。

詳しくは、バリュートラッカーのドキュメントをご覧ください。
プレビュー¶
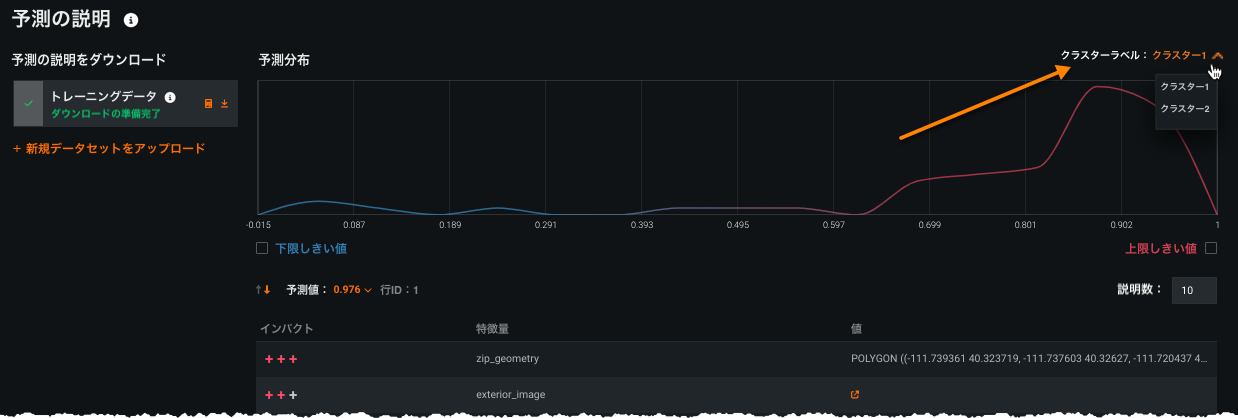
クラスターモデルでの予測の説明¶
今回プレビュー機能として提供されるクラスタリングでの予測説明を使用すると、特定の行のクラスター割り当てに最も貢献した要因が明らかになります。 このインサイトによって、クラスタリングモデルの結果をステークホルダーにわかりやすく説明できます。また、影響の大きい要因が特定されるため、事業戦略に注力できます。
多クラス予測の説明とよく似た機能ですが、クラスではなくクラスターについてレポートします。この機能を有効にすると、クラスターの説明は、リーダーボードとデプロイの両方から入手できます。 この機能は、XEMPベースのすべてのクラスタリングプロジェクトで利用可能ですが、時系列では利用できません。
必要な機能フラグ:クラスタリング予測の説明を有効にする
プレビュー機能のドキュメントをご覧ください。
APIの機能強化¶
以下は、APIの新機能と機能強化の概要です。 各クライアントの詳細については、APIユーザーガイドをご覧ください。
ヒント
DataRobotでは、PythonとRのために最新のAPIクライアントにアップデートすることを強くお勧めします。
プレビュー:Rクライアント v2.29¶
DataRobotは、Rクライアントのバージョン2.29をプレビュー版としてリリースしました。 それにより、RクライアントのバージョンはパブリックAPIのバージョン(2.29)と等しくなりました。 その結果、クライアントの一般的なメソッドと使用方法に大幅な変更が加えられています。 これらの変更は、(datarobotライブラリに加えて)新しいライブラリであるdatarobot.apicoreにカプセル化され、パブリックAPIにアクセスするための自動生成関数が提供されます。 datarobotパッケージは、apicoreパッケージをより使いやすくするために、多数のAPIラッパー関数を提供しています。
インストール方法、詳細なメソッドの概要、リファレンスドキュメントなど、新しいRクライアントについて詳しくは、v2.29のドキュメントを参照してください。
新しいR関数¶
- 生成されたAPIラッパー関数は、OpenAPI仕様のタグに基づいてカテゴリー分けされていますが、関数自体はv2.27でDataRobotパブリックAPI全体に対して再設計されました。
- APIラッパー関数では、パッケージの他の部分と整合性を取るために、キャメルケースの引数名を使用しています。
- ほとんどの関数名は、OpenAPI仕様に基づく
VerbObjectパターンに従っています。 - 一部の関数名は、同じ接続先エンドポイントを呼び出した場合、Rクライアントのv2.18に存在した「レガシー」関数と同じです。 たとえば、ラッパー関数名は
RetrieveProjectsModelsではなくGetModelです。これは、Rクライアントでエンドポイント/projects/{mId}/models/{mId}に対してRetrieveProjectsModelsが実装されたためです。 - 同様に、これらの関数は、対応する 「レガシー」 関数と同じ引数を使用して、DataRobotがこれらの関数を呼び出す既存のコードを壊さないようにします。
- Rクライアント(
datarobotとdatarobot.apicoreの両パッケージ)は、DataRobotプラットフォームのPython 3への移行によって使用非推奨または無効になった特定のリソース(プロジェクト、モデル、デプロイなど)にアクセスしようとすると、警告を出力します。 drconfig.yamlを対話的に修正できるヘルパー関数EditConfigを追加しました。catalogIdを使用してデータセットをCSVファイルとして取得するDownloadDatasetAsCsv関数を追加しました。- プロジェクトで特徴量探索の関係性を取得する
GetFeatureDiscoveryRelationships関数を追加しました。 - Rクライアント(
datarobotとdatarobot.apicoreの両パッケージ)は、DataRobotプラットフォームのPython 3への移行によって使用非推奨または無効になった特定のリソース(プロジェクト、モデル、デプロイなど)にアクセスしようとすると、警告を出力します。
Rの機能強化¶
RequestFeatureImpact関数でrowCount引数を指定できるようになりました。これにより、特徴量のインパクトの計算に使用されるサンプルサイズが変更されます。- 内部ヘルパー関数
ValidateModelはValidateAndReturnModelに名称変更され、apicoreパッケージのモデルクラスで使用できるようになりました。 - 関数
SetTargetからquickrun引数が削除されました。 代わりにmode = AutopilotMode.Quickを設定してください。 - Transferable Modelsファミリーの関数(
ListTransferableModels、GetTransferableModel、RequestTransferableModel、DownloadTransferableModel、UploadTransferableModel、UpdateTransferableModel、DeleteTransferableModel)が削除されました。 (長い間使用非推奨であった)接続先エンドポイントは、スタンドアロンスコアリングエンジン(SSE)の削除に伴い、パブリックAPIから削除されました。 - パブリックAPIのv2.27〜2.29に存在しない部分を表すファイル (コード、テスト、ドキュメント) を削除しました。
Rで使用非推奨になった機能¶
バージョン2.29での大きな変更点:
- 関数SetTargetから
quickrun引数が削除されました。 代わりにmode = AutopilotMode.Quickを設定してください。 -
Transferable Modelsの関数が削除されました。 接続先エンドポイントも、スタンドアロンスコアリングエンジン(SSE)の削除に伴い、パブリックAPIから削除されました。 削除された関数は以下の通りです。
ListTransferableModelsGetTransferableModelRequestTransferableModelDownloadTransferableModelUploadTransferableModelUpdateTransferableModelDeleteTransferableModel
バージョン2.29で使用非推奨となったAPI:
- コンプライアンスドキュメント作成のAPIは使用非推奨です。 代わりにドキュメントの自動作成のAPIを使用してください。
サポート終了のお知らせ¶
Python 2のサポート終了と削除の現在の状況¶
2022年11月リリースの時点で、Python 2の削除の状況は次のとおりです。
-
Python 2のプロジェクトとモデルは無効化され、リーダーボードの予測はすでにサポートされていません。
-
Python 2ベースのモデルデプロイは、フローズン実行の延長をリクエストした組織を除いて無効です。
Python 2のサポート終了とPython 3への移行の詳細については、ガイドを参照してください。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。