MLOpsと予測(V10.2)¶
2024年11月21日
DataRobot MLOps v10.2リリースには、以下に示す多くの新機能が含まれています。 リリース10.2のその他の詳細については、以下をご覧ください。
リリース10.2¶
目的別にグループ化された機能
* プレミアム機能
予測とMLOps¶
一般提供¶
テキスト生成モデルの評価とモデレーション¶
評価とモデレーションのガードレールは、組織がプロンプトインジェクションや、悪意のある、有害な、または不適切なプロンプトや回答をブロックするのに役立ちます。 また、ハルシネーションや信頼性の低い回答を防ぎ、より一般的には、モデルをトピックに沿った状態に保つこともできます。 さらに、これらのガードレールは、個人を特定できる情報(PII)の共有を防ぐことができます。 多くの評価およびモデレーションガードレールは、デプロイされたテキスト生成モデル(LLM)をデプロイされたガードモデルに接続します。 これらのガードモデルはLLMのプロンプトと回答について予測し、これらの予測と統計を中心的なLLMデプロイに報告します。 評価とモデレーションのガードレールを使用するには、まず、LLMのプロンプトや回答について予測するガードモデルを作成してデプロイします。たとえば、ガードモデルは、プロンプトインジェクションや有害な回答を識別することができます。 次に、ターゲットタイプがテキスト生成のカスタムモデルを作成する場合、評価とモデレーションのガードレールを1つ以上定義します。 この機能は一般提供のプレミアム機能としてリリースされ、モデレーションのタイムアウトおよび評価とモデレーションのログに関する全般的な設定が導入されています。
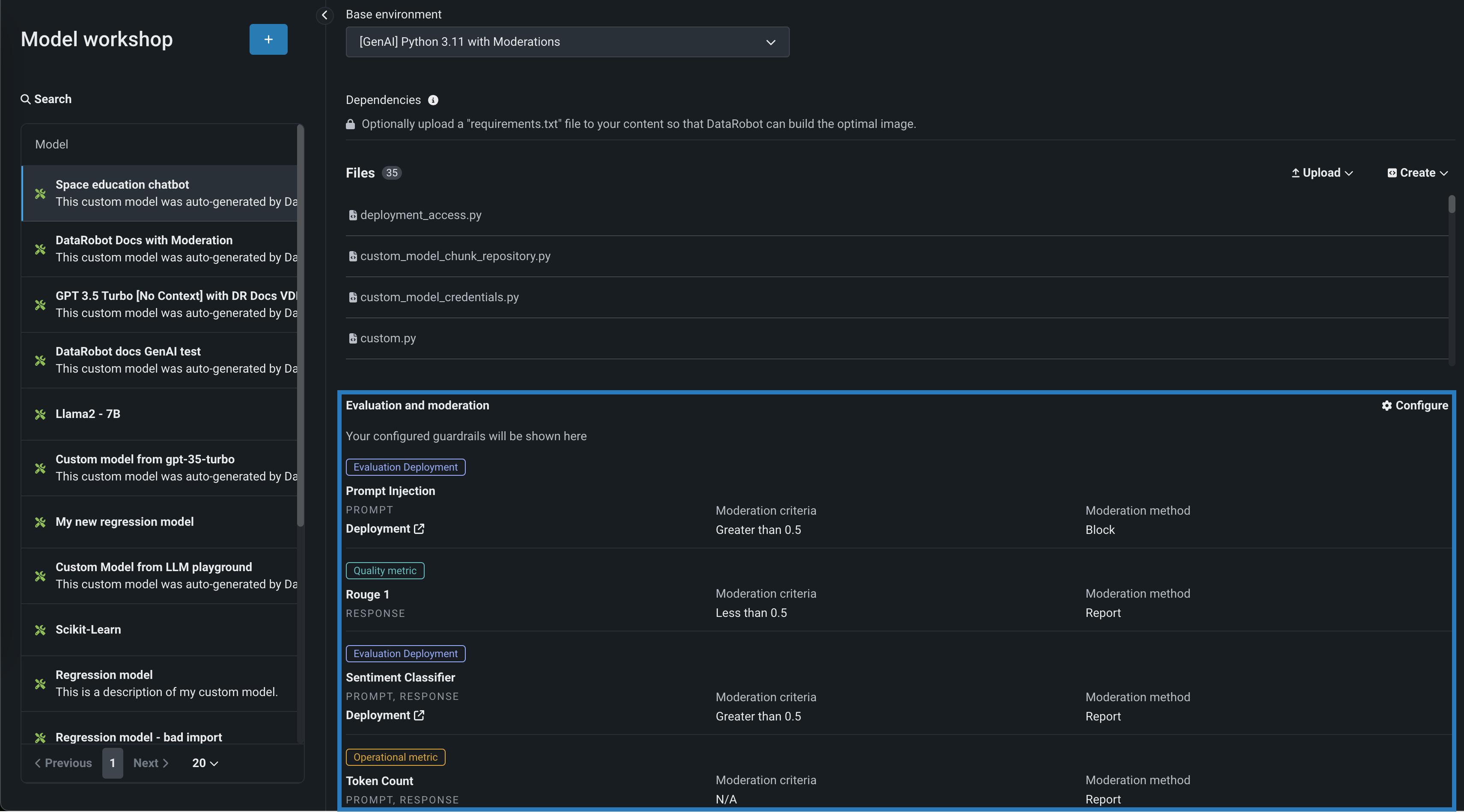
デフォルトではオフの機能フラグ:モデレーションのガードレールを有効にする(プレミアム機能)、モデルレジストリでグローバルモデルを有効にする(プレミアム機能)、予測応答で追加のカスタムモデル出力を有効にする
詳しくはドキュメントをご覧ください。
登録されたテキスト生成モデルでコンプライアンスドキュメントのサポートを開始¶
DataRobotは、予測モデルの法的検証に使用できるモデル開発ドキュメントを以前から提供しています。 今回、コンプライアンスドキュメントの機能が拡張され、レジストリのモデルディレクトリにあるテキスト生成モデルに対してドキュメントが自動生成されるようになりました。 DataRobotがネイティブにサポートするLLMの場合、このドキュメントは、モデルの概要、有用なリソース、そして特に注目すべきはモデルのパフォーマンスと安定性のテストなど、レポートの生成にかかる時間を短縮するのに役立ちます。 ネイティブにサポートしていないLLMの場合、生成されるドキュメントは、必要なセクションがすべて揃ったテンプレートとして使用できます。 テキスト生成モデルのコンプライアンスドキュメントを生成するには、機能フラグコンプライアンスドキュメントを有効化およびGenAIのエクスペリメントを有効にするが必要です。
バッチ予測でのSAP Datasphereの連携¶
プレミアム機能です。SAP Datasphereは、バッチ予測ジョブの取込み元および出力先としてサポートされています。
デフォルトではオフの機能フラグ:SAP Datasphereコネクターを有効にする(プレミアム機能)、SAP Datasphereとバッチ予測の連携を有効にする(プレミアム機能)
詳しくは、予測の入力および出力オプションに関するドキュメントをご覧ください。
NextGenコンソールでフィルターとモデル置換を改善¶
今回のNextGenコンソールのアップデートでは、デプロイのフィルターが改善され、モデル置換の操作性が一新されたことで、より直感的な置換ワークフローになりました。
コンソール > デプロイタブにおいて、自分が作成、タグ、およびモデルタイプ**でフィルターできるようになりました。
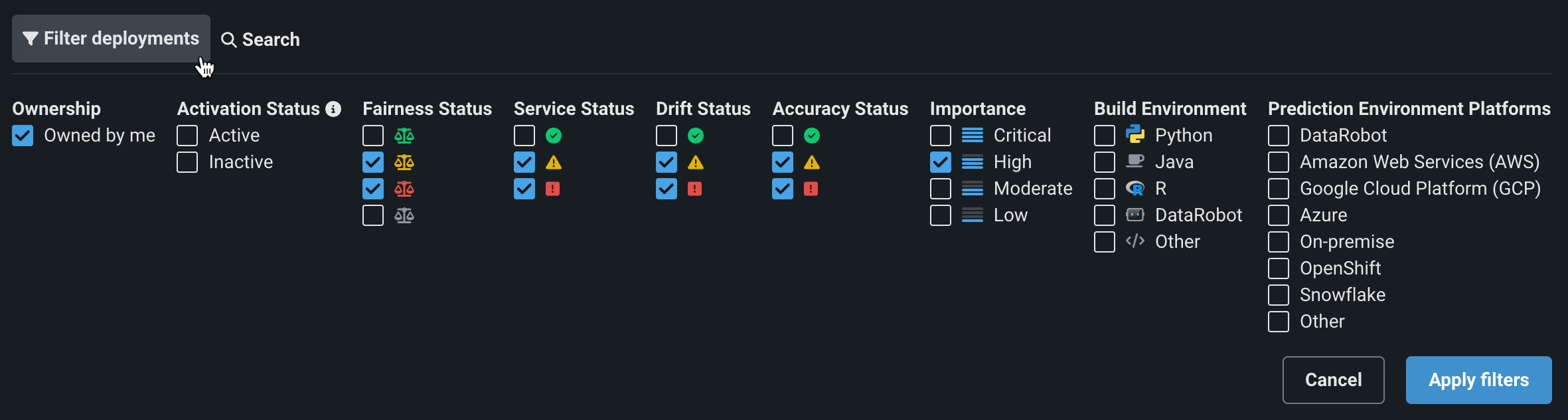
コンソール > デプロイタブ、またはデプロイの概要で、モデルのアクションメニューから、最新のモデル置換ワークフローにアクセスできます。

NextGenレジストリでカスタム実行環境を管理¶
NextGenレジストリに環境タブが提供されました。このタブでは、カスタムモデル、ジョブ、アプリケーション、ノートブックのカスタム実行環境を作成および管理できます。
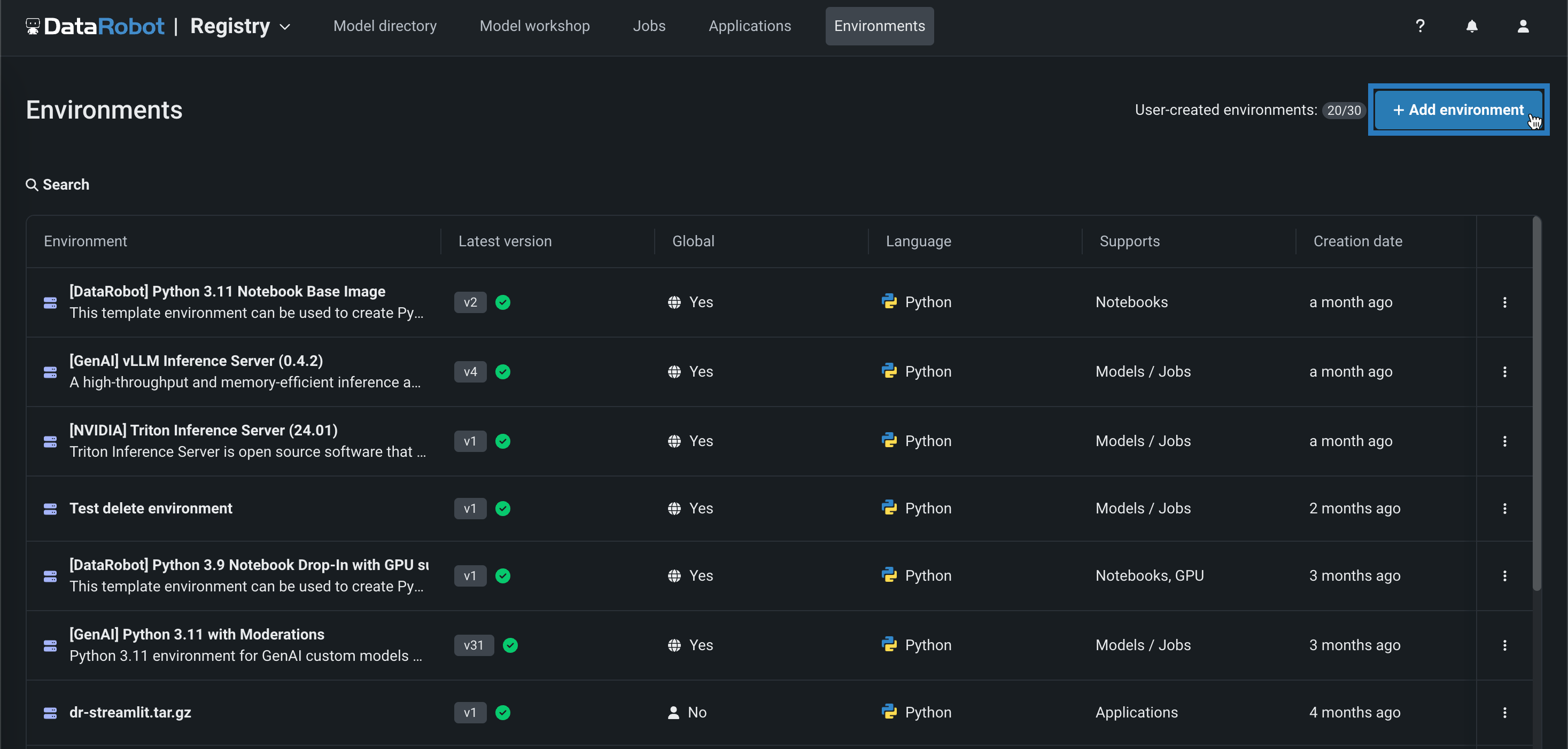
詳しくはドキュメントをご覧ください。
特徴量ドリフト追跡のカスタマイズ¶
デプロイの特徴量ドリフト追跡を有効にした場合、追跡対象として選択した特徴量をカスタマイズできるようになりました。 デプロイプロセス中またはその後に、デプロイ設定の特徴量ドリフトセクションで、特徴量の選択方法(自動的に25個の特徴量を選択する、または最大25個の特徴量を手動で選択する)を選択します。
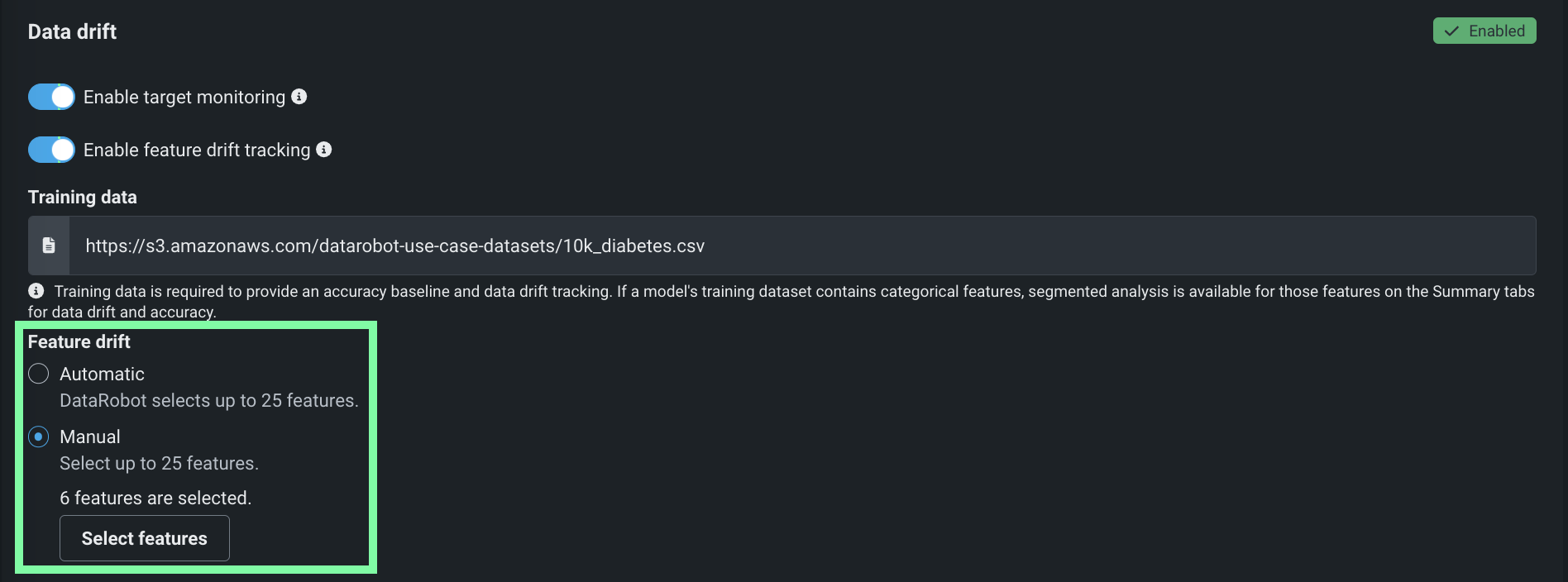

詳しくはドキュメントをご覧ください。
カスタムモデルの登録時にインサイトを計算¶
トレーニングデータが割り当てられたカスタムモデルでは、モデルのデプロイ時ではなく、モデルの登録時にモデルのインサイトと予測説明のプレビューが計算されるようになりました。 さらに、モデルワークショップからアクセスできる新しいモデルログは、インサイトの計算プロセス時のエラー診断に役立ちます。

詳しくはドキュメントをご覧ください。
レジストリとコンソールのアセットをユースケースにリンク¶
新しいユースケースリンク機能を使って、登録モデルのバージョン、モデルのデプロイ、カスタムアプリケーションをユースケースに関連付けます。 これらのアセットを既存のユースケースにリンクしたり、新しいユースケースを作成したり、リンクされたユースケースのリストを管理したりできます。



詳しくは、登録モデル、デプロイ、およびアプリケーションのリンクに関するドキュメントをご覧ください。
コードベースの再トレーニングジョブ¶
手動またはテンプレートから、コードベースの再トレーニングポリシーを実行するジョブを追加します。 再トレーニングジョブを表示および追加するには、ジョブ > 再トレーニングタブに移動し、以下の操作を行います。
-
新しい再トレーニングジョブを手動で追加するには、+ 新しい再トレーニングジョブを追加(またはジョブパネルが開いている場合は最小化された追加ボタン )をクリックします。
-
テンプレートから再トレーニングジョブを作成するには、追加ボタンの横にある をクリックし、再トレーニングの下にあるテンプレートから新規作成をクリックします。
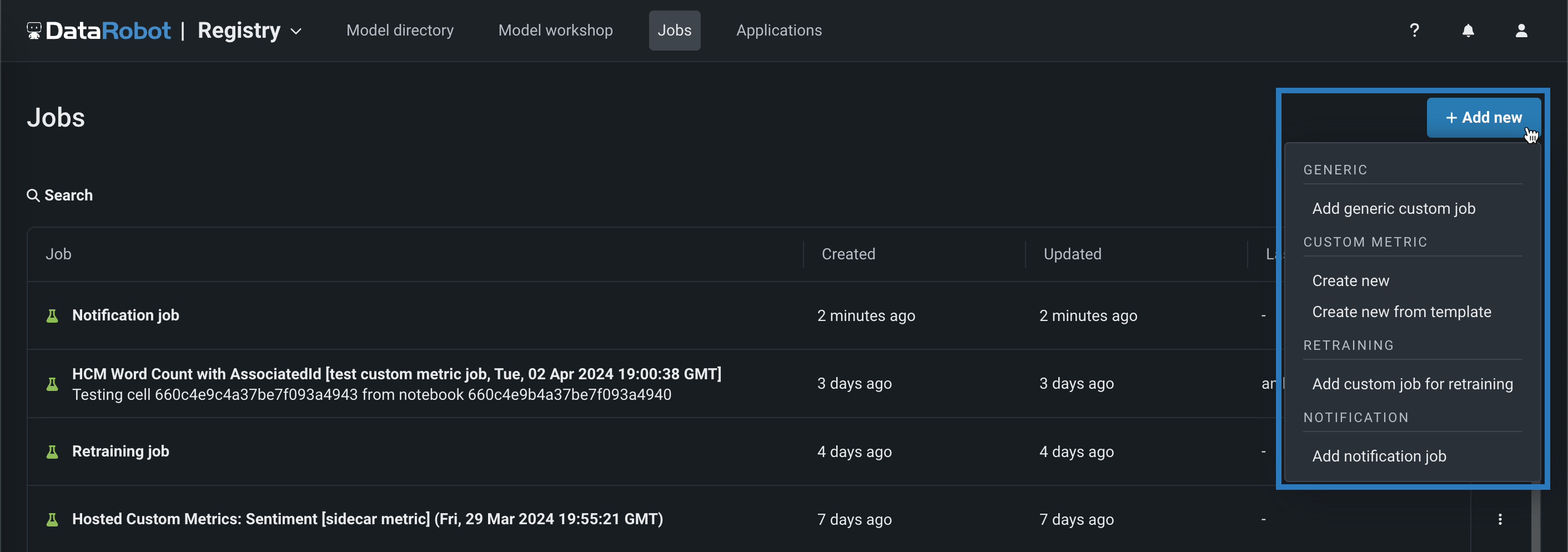
詳しくはドキュメントをご覧ください。
カスタムモデルのワーカーのランタイムパラメーター¶
カスタムモデルの設定に、DataRobotの新しい予約ランタイムパラメーターCUSTOM_MODEL_WORKERSを使用できます。 この数値ランタイムパラメーターにより、各レプリカは、設定された数の同時プロセスを処理できます。 このオプションは、主に生成AIのユースケースで、プロセスセーフなカスタムモデルを対象としています。
カスタムモデルプロセスの安全性
CUSTOM_MODEL_WORKERSを有効にして設定する場合、モデルがプロセスセーフであることを確認してください。 この設定オプションは、プロセスセーフなカスタムモデルのみを対象としています。リソース効率を向上させるためにカスタムモデルで一般的に使用するためのものではありません。 この方法でCPUリソースを利用するメリットがあるのは、I/Oバウンドタスクを持つプロセスセーフなカスタムモデル(プロキシモデルなど)だけです。
詳しくはドキュメントをご覧ください。
時系列モデルパッケージの予測間隔¶
リモート予測環境でDataRobotの時系列モデルを実行し、そのモデルの時系列予測間隔(1~100)を計算するには、予測間隔の計算を有効にして、モデルのデプロイまたはリーダーボードからモデルパッケージ(.mlpkgファイル)をダウンロードします。 その後、DataRobotの外でポータブル予測サーバー(PPS)を使って予測ジョブを実行できます。
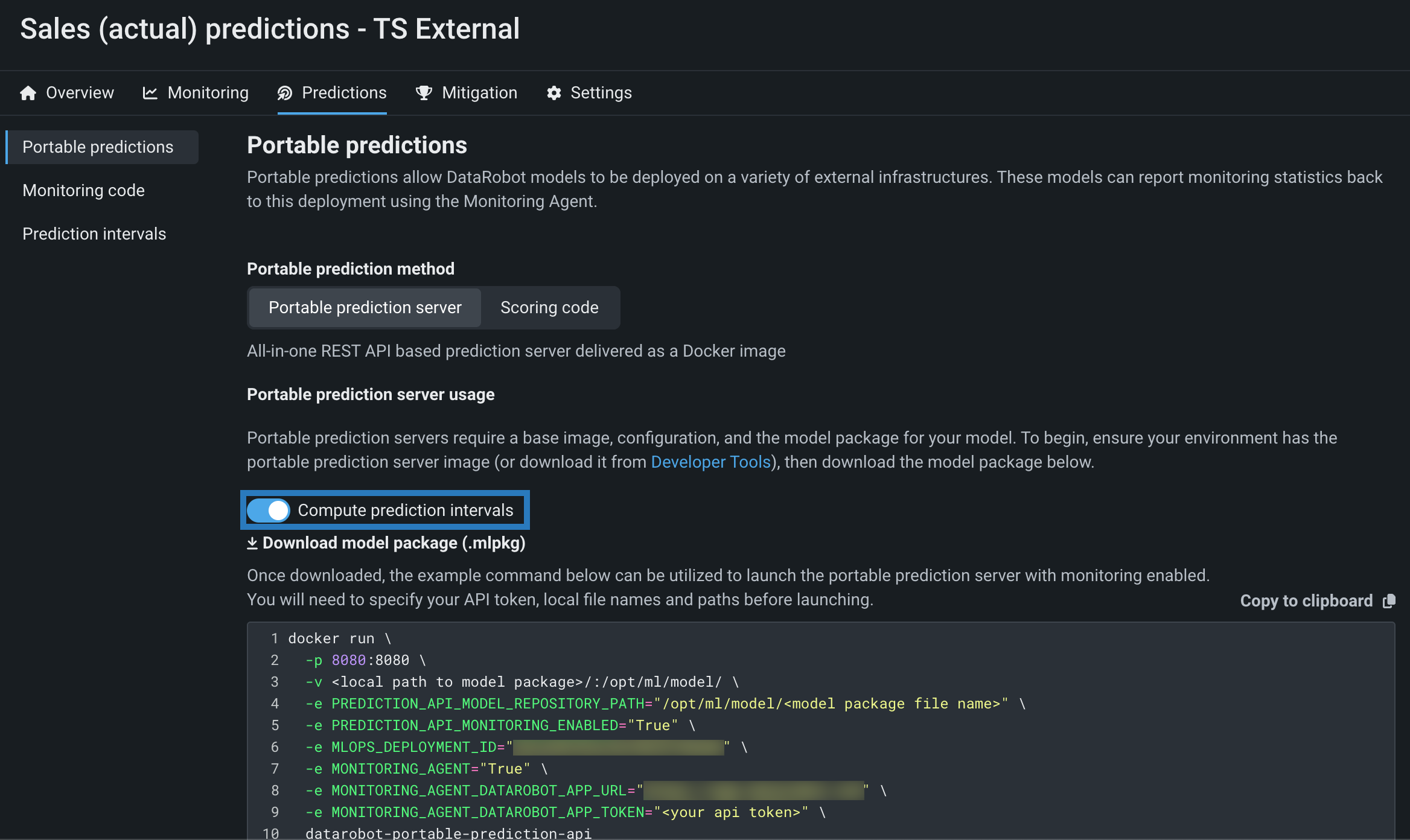
詳しくはドキュメントをご覧ください。
デプロイのデータトレース¶
プレミアム機能です。生成AIデプロイのデータ探索タブで、トレースをクリックすると、関連付けIDが一致するプロンプト、回答、ユーザー評価、カスタム指標を調べることができます。 このビューでは、生成AIモデルの回答の品質に関するインサイトが、ユーザーによる評価と、実装した生成AIのカスタム指標に基づいて提供されます。 プロンプト、回答、および利用可能な指標は、関連付けIDによって対応付けられます。
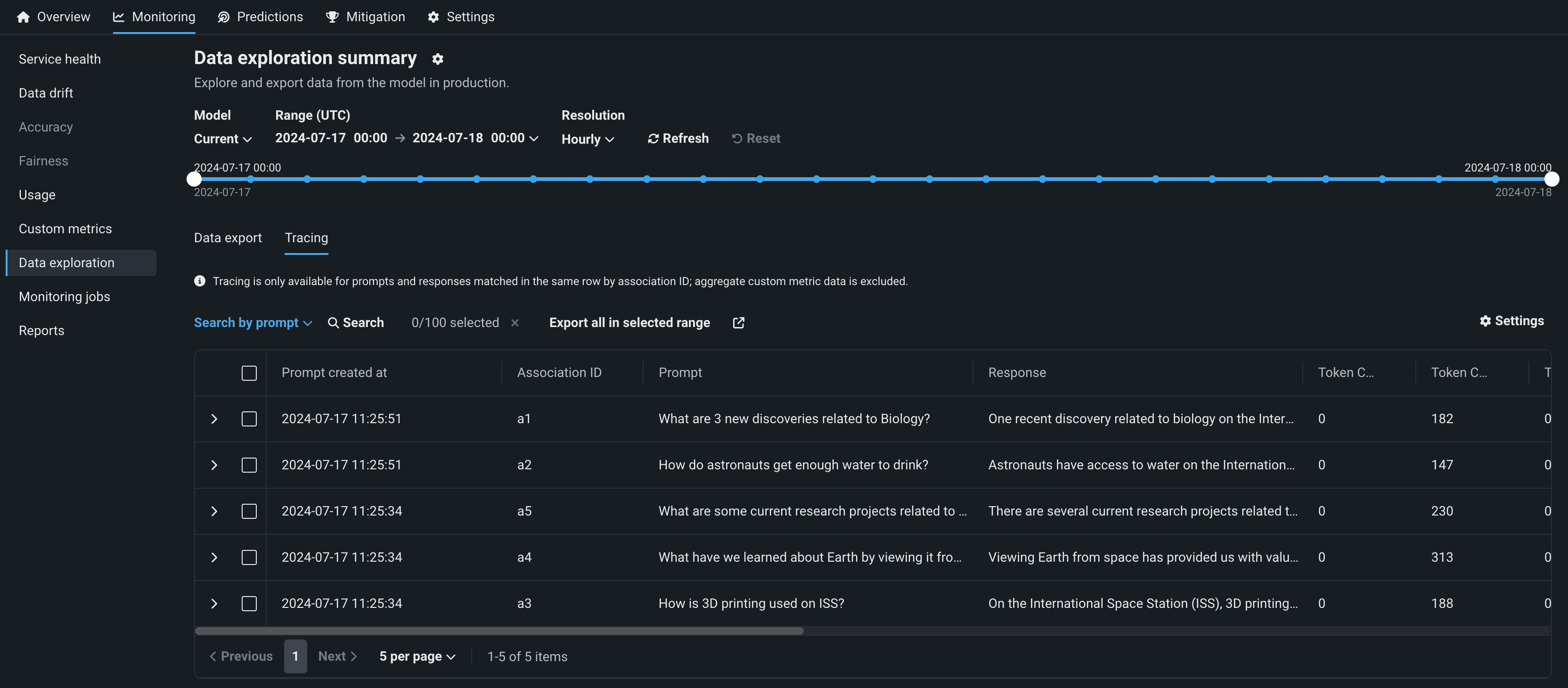
デフォルトではオフの機能フラグ:テキスト生成のターゲットタイプでデータ品質テーブルを有効にする(プレミアム機能)、生成モデルで実測値の保存を有効にする(プレミアム機能)
バッチ予測のラングラーレシピ¶
デプロイの予測 > 予測を作成タブを使用して、バッチ予測を行うことで、デプロイされたモデルでラングラーデータセットを効率的にスコアリングできます。 バッチ予測とは、大規模なデータセットで予測を行う方法で、入力データを渡すと各行の予測結果が得られます。 予測データセットボックスで、ファイルを選択 > ラングラーをクリックし、ラングラーデータセットで予測を行います。
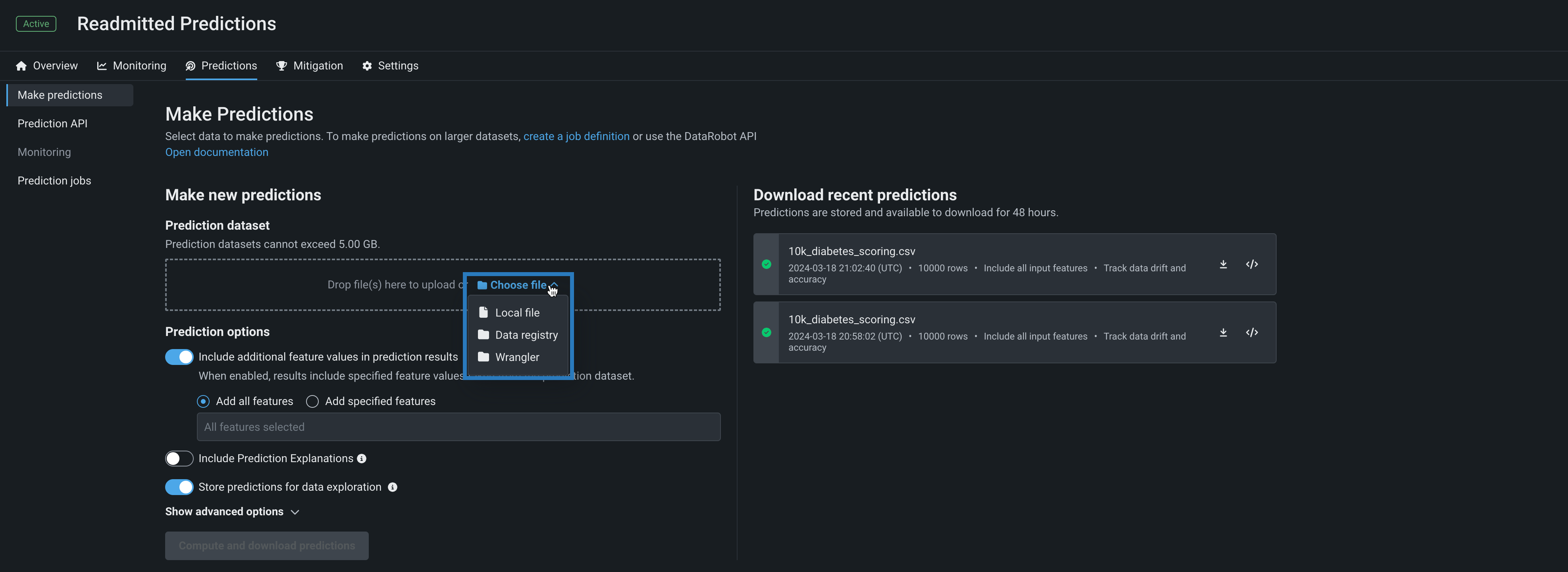
ワークベンチでの予測
ラングラーは、ワークベンチでは予測データセットソースとしても使用できます。 デプロイ前のモデルで予測を行うには、エクスペリメントのモデルリストからモデルを選択し、モデルのアクション > 予測を作成をクリックします。
予測データの送信元と送信先を指定し、予測が実行されるタイミングを決定することで、バッチ予測ジョブをスケジュールすることもできます。
バッチ予測APIのマルチパートアップロード¶
バッチ予測APIでは、マルチパートアップロードで複数のファイルを使用してスコアリングデータをアップロードすることで、大規模なデータセットのファイル取込みを改善できます。 マルチパートアップロードプロセスでは、複数のPUTリクエストの後に、手動でアップロードを完了するためのPOSTリクエスト(finalizeMultipart)が必要です。 マルチパートアップロードプロセスは、低速接続で大規模なデータセットをアップロードしたい場合や、ネットワークが頻繁に不安定になる場合に役立ちます。
この機能により、バッチ予測APIに2つのエンドポイントが追加され、ローカルファイルアダプターに2つの新しい取込み設定が追加されました。
DataRobotでHugging Face HubからLLMをデプロイ¶
モデルワークショップを使用して、一般的なオープンソースLLMを Hugging Faceハブから作成およびデプロイし、DataRobotのエンタープライズグレードのGenAI 可観測性とガバナンスでAIアプリを保護します。 新しい [GenAI] vLLM Inference Server実行環境および vLLM Inference Server Text Generation Templateは、DataRobotが提供するGenAIモニタリング機能および追加のガバナンスAPIとすぐに統合できます。

このインフラストラクチャは、LLMの推論と提供のためのオープンソースフレームワークであるvLLMライブラリを使用して、Hugging Faceライブラリと連携し、一般的なオープンソースLLMをHugging Face Hubからシームレスにダウンロードして読み込みます。 まず、テキスト生成モデルのテンプレートをカスタマイズしてください。 デフォルトではLlama-3.1-8b LLMが使われますが、engine_config.jsonファイルを修正して、使用したいOSSモデルの名前を指定することで、選択されているモデルを変更できます。
デフォルトではオフの機能フラグ:カスタムモデルでGPUを使用した推論を有効にする (プレミアム機能)
DataRobot Serverlessでのモデルデプロイ¶
一般提供機能になりました。DataRobotサーバーレス予測環境を使用することで、スケーラブルなデプロイを作成し、利用可能なコンピューティング量をデプロイごとに設定できます。 サーバーレス予測環境では、AutoMLとAutoTSモデル、カスタムモデル、GenAIブループリント、およびベクターデータベースのデプロイがサポートされています。 予測については、すべてのデプロイでバッチおよびリアルタイムAPIを提供しています。 DataRobotのサーバーレス予測環境を新たに作成するには、予測環境を追加する際に、DataRobotサーバーレスプラットフォームを選択します。
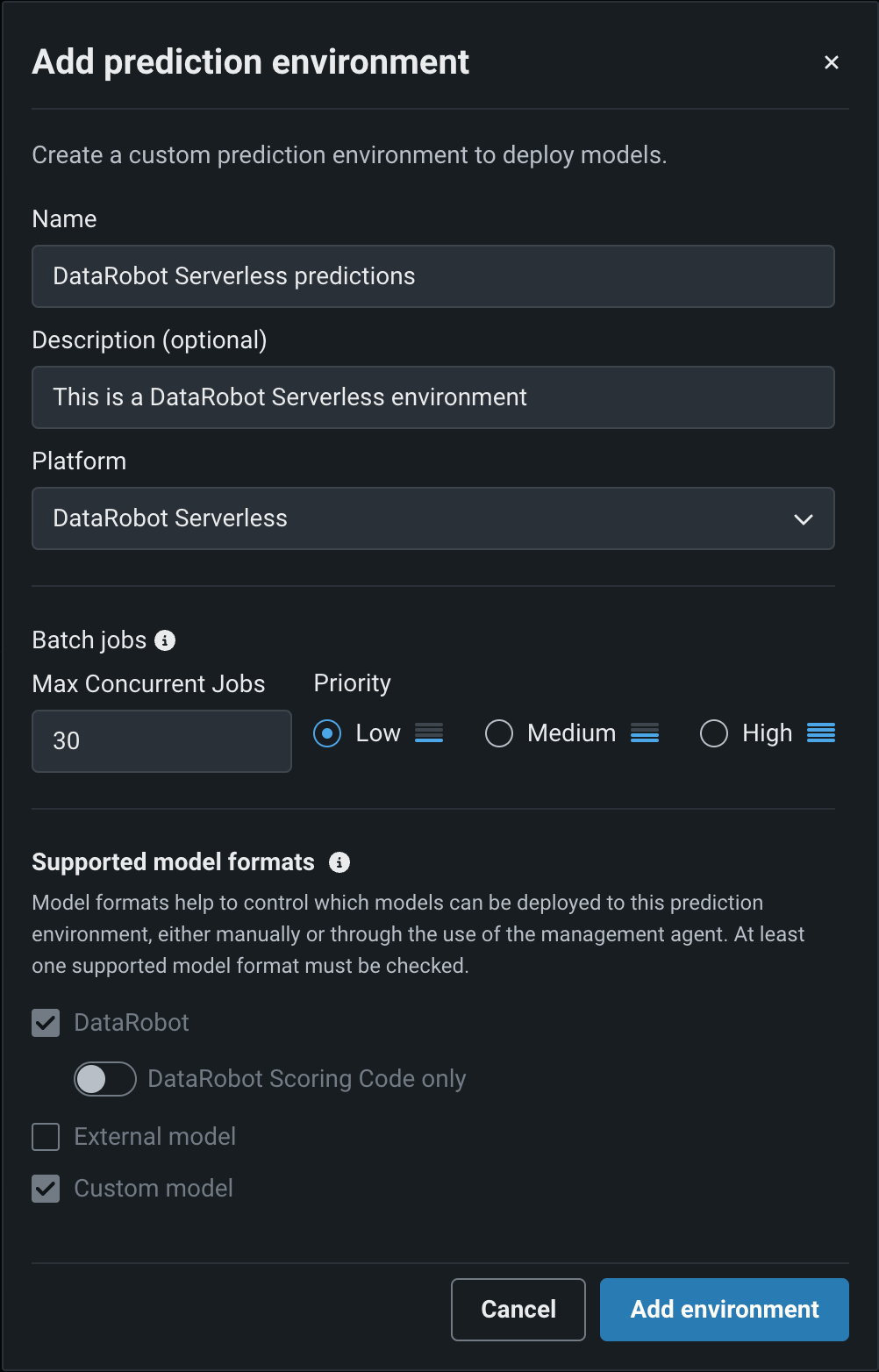
DataRobot Serverless環境でのゼロスケールポリシーの管理¶
プレミアム機能です。DataRobotサーバーレス予測環境でデプロイを作成する際、最小コンピューティングインスタンス数の設定をデフォルトの0から増やすことができます。 最小コンピューティングインスタンス数を0(デフォルト)に設定すると、推論サーバーは、7日間の非アクティブ期間の後に停止します。
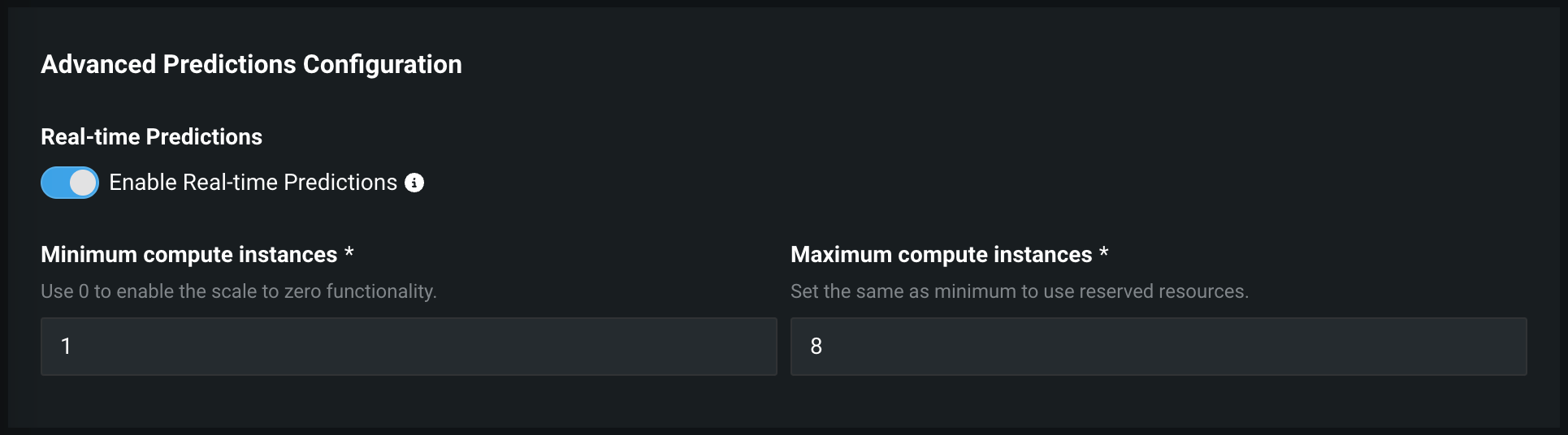
デフォルトではオフの機能フラグ:デプロイの自動スケーリング管理を有効にする(プレミアム機能)
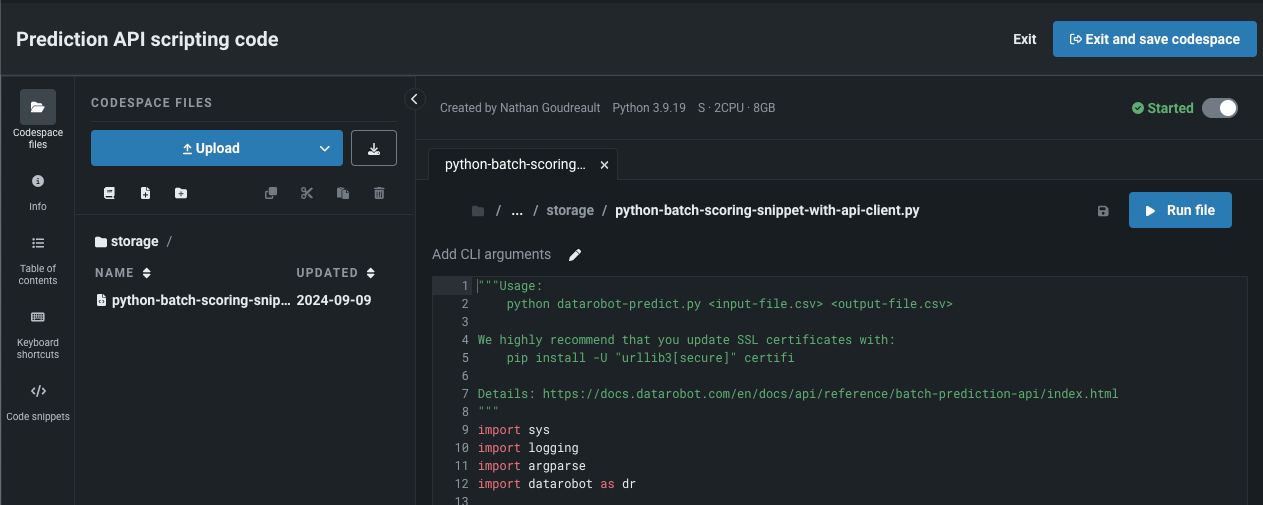
Codespaceで予測APIスニペットを開く¶
Codespaceで予測APIのコードスニペットを開いて、スニペットを直接編集したり、他のユーザーと共有したり、追加のファイルを組み込んだりできるようになりました。 選択すると、codespaceのインスタンスが生成され、その中にスニペットがPythonファイルとして格納されます。 Codespaceでは、ファイルストレージに完全にアクセスできます。 アップロードボタンを使ってスコアリング用のデータセットを追加したり、スニペット実行後に予測出力(output.json、output.csvなど)をcodespaceファイルのディレクトリに戻したりすることができます。
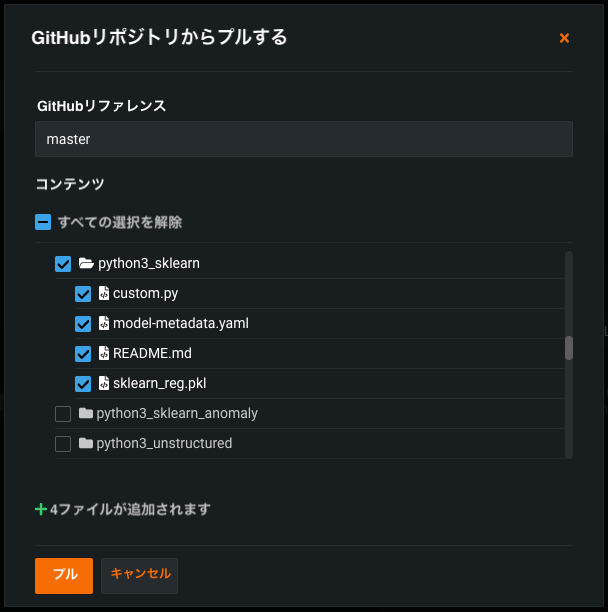
カスタムモデルやタスクのためのリモートリポジトリファイルブラウザー¶
このリリースから、DataRobot Classicのカスタムモデルワークショップにモデルやタスクを追加する際に、Bitbucket、GitHub、GitHub Enterprise、S3、GitLab、GitLab Enterpriseなどのリモートリポジトリ内のフォルダーやファイルを参照して選択できます。 リモートリポジトリからプルする場合、カスタムモデルにプルしたいファイルやフォルダーのチェックボックスをオンにしたり、リポジトリ内のすべてのファイルを選択したりすることができます。 この例ではGitHubを使用していますが、各リポジトリタイプで手順は同じです。
TTSモデルとLSTMモデルでのバッチ予測¶
時系列予測では、従来の時系列モデル(TTS)や長・短期記憶モデル(LSTM)(自己回帰(AR)や移動平均(MA)の手法を用いたシーケンスモデル)が一般的です。 ARモデルもMAモデルも、予測を行うためには、通常、過去の予測の完全な履歴を必要とします。 それに対して、他の時系列モデルでの予測に必要なのは、特徴量派生後の1行のみです。 これまで、バッチ予測では、履歴が各バッチの最大サイズを超える場合、有効な特徴量派生ウィンドウ(FDW)を超えて履歴データを受け入れることができませんでしたが、シーケンスモデルではFDWを超える完全な履歴データが必要でした。 これらの要件により、シーケンスモデルはバッチ予測とは相容れないものとなりました。 この機能によって、それらの制限が解除されるため、TTSおよびLSTMモデルでのバッチ予測が可能になります。
プレビュー¶
SAP AI Coreでのスコアリングコードの自動デプロイと置換¶
DataRobotのスコアリングコードをSAP AI Coreにデプロイするには、DataRobotが管理するSAP AI Coreの予測環境を作成します。 DataRobotの管理を有効にすることで、外部のSAP AI Coreにデプロイされたモデルは、スコアリングコードの自動置換を含むMLOpsの機能を利用できます。 SAP AI Coreの予測環境を作成したら、レジストリからその環境にスコアリングコード対応モデルをデプロイできます。
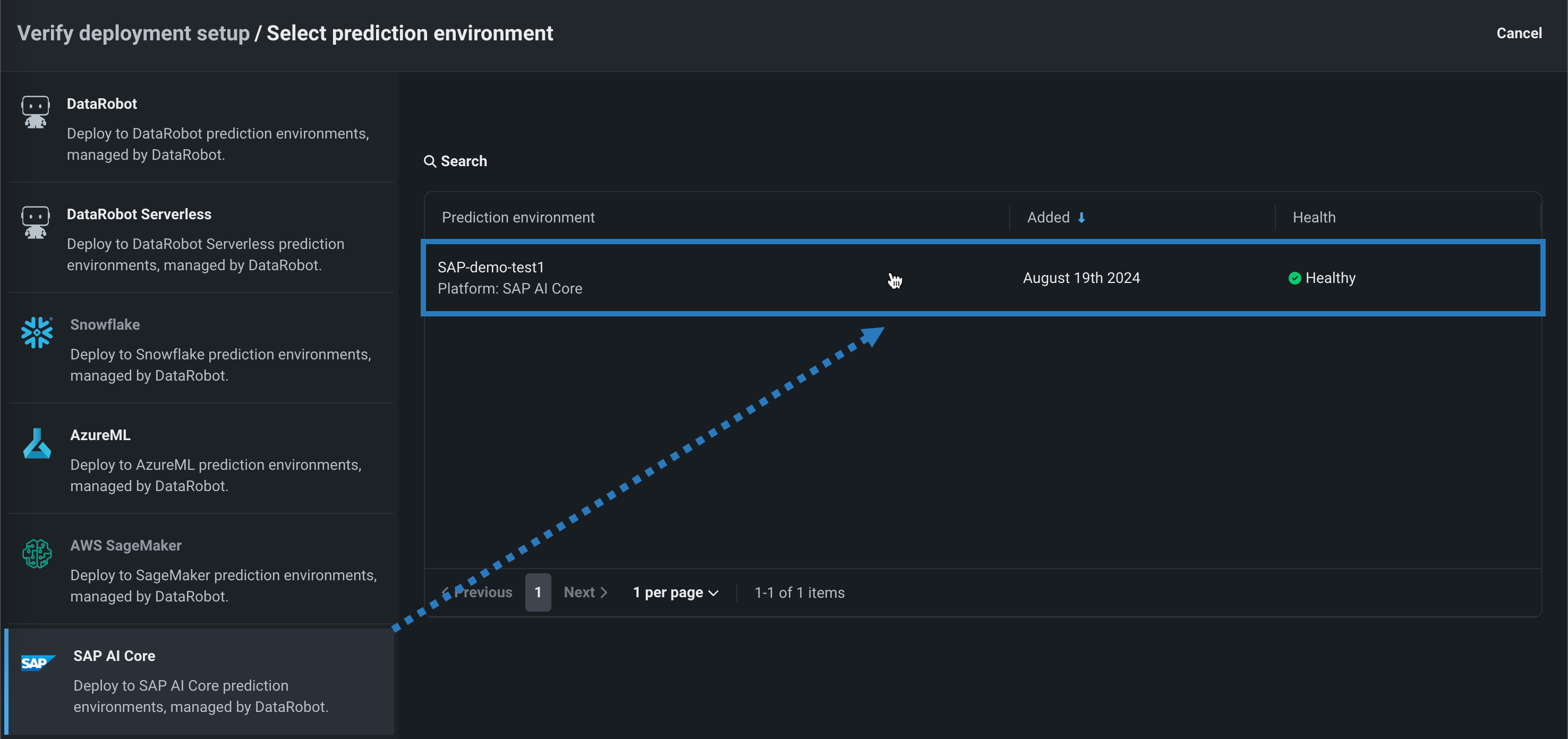
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:SAP AI Coreでのスコアリングコードの自動デプロイと置換を有効にする
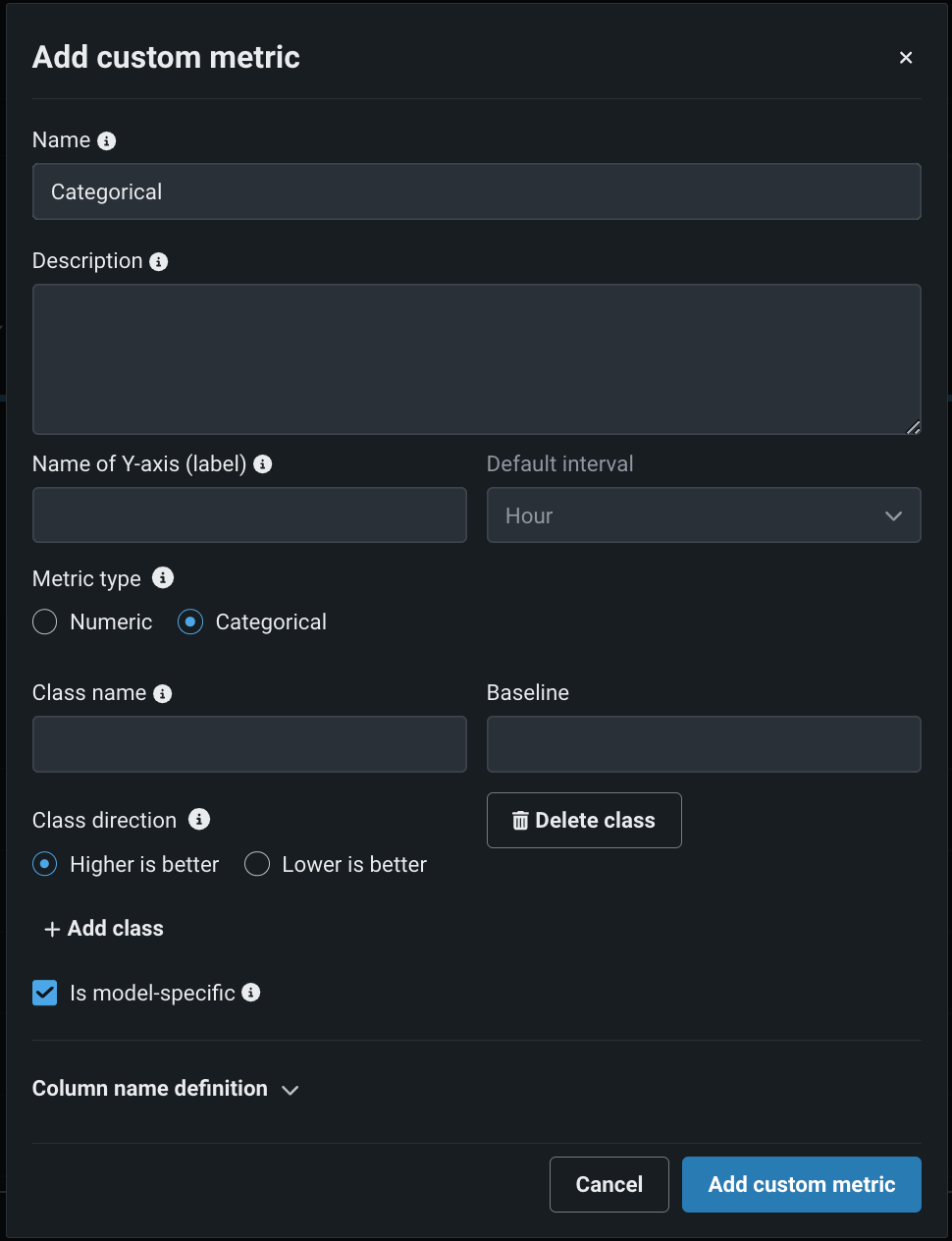
カスタムカテゴリー指標の作成¶
NextGenコンソールでは、外部指標の作成時に、デプロイのカスタム指標タブでカテゴリー指標を定義できます。 カテゴリー指標ごとに、最大10クラスまで定義できます。
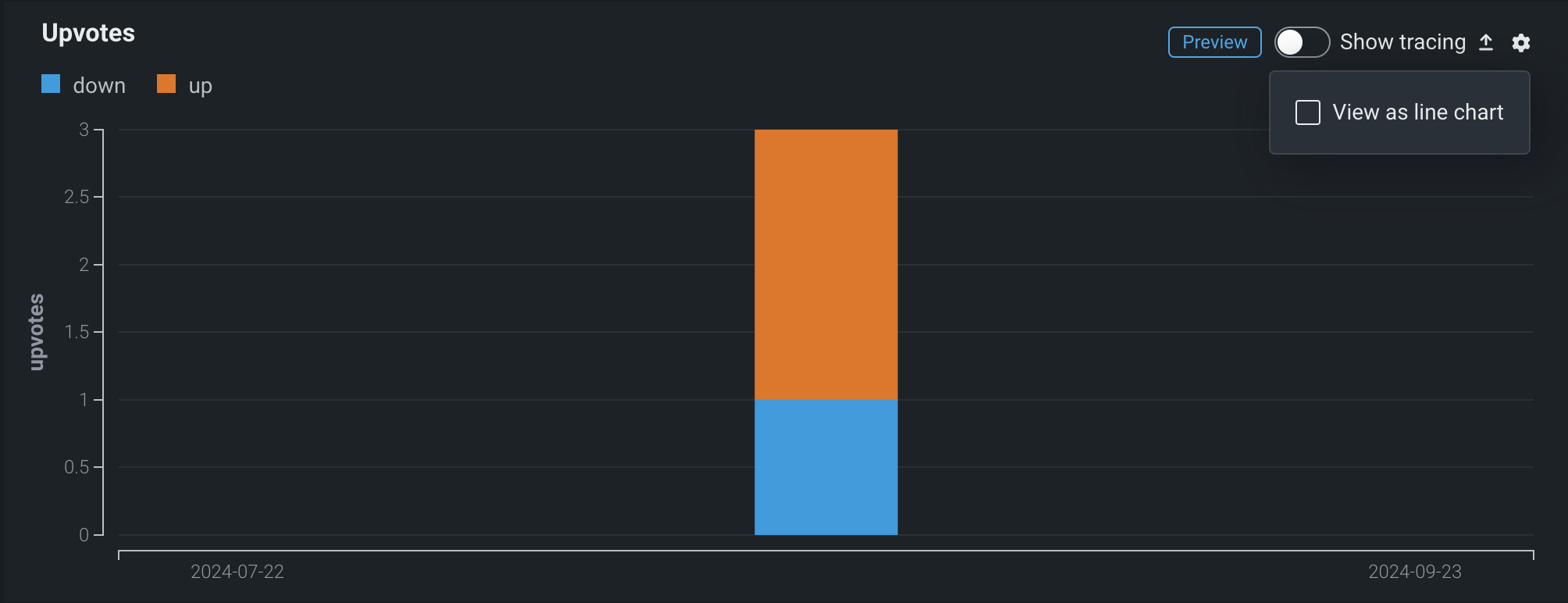
デフォルトでは、これらの指標はカスタム指標タブの棒グラフに表示されます。ただし、 設定メニューからチャートタイプを設定できます。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ:カテゴリーのカスタム指標を有効にする
カスタムジョブのテンプレートギャラリー¶
カスタムジョブテンプレートギャラリーは、カスタム指標ジョブに加えて、汎用、通知、再トレーニングのジョブタイプでも利用できるようになりました。 新しいテンプレートギャラリーにアクセスするには、レジストリ > ジョブタブで、任意のジョブタイプのテンプレートからジョブを作成します。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ:カスタムジョブのテンプレートギャラリーを有効にする、カスタムテンプレートを有効にする
ベクターデータベースの作成とデプロイ¶
モデルワークショップでベクターデータベースをターゲットタイプとすることで、他のカスタムモデルと同じように、ベクターデータベースを登録およびデプロイできます。

プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:ベクターデータベースのデプロイタイプを有効にする(プレミアム機能)
デプロイでの地理空間の監視¶
トレーニングデータセット内の位置データを使用して構築し、デプロイした二値分類、連続値、または多クラスモデルでは、DataRobotのLocation AIを活用して、デプロイのデータドリフトおよび精度タブで地理空間の監視ができるようになりました。 プロイで地理空間分析を有効にするには、セグメント化された分析を有効化し、位置データの取込み中に生成される位置特徴量geometryのセグメントを定義します。 geometryセグメントには、世界をH3セルのグリッドに分割する際に使われる識別子が含まれています。

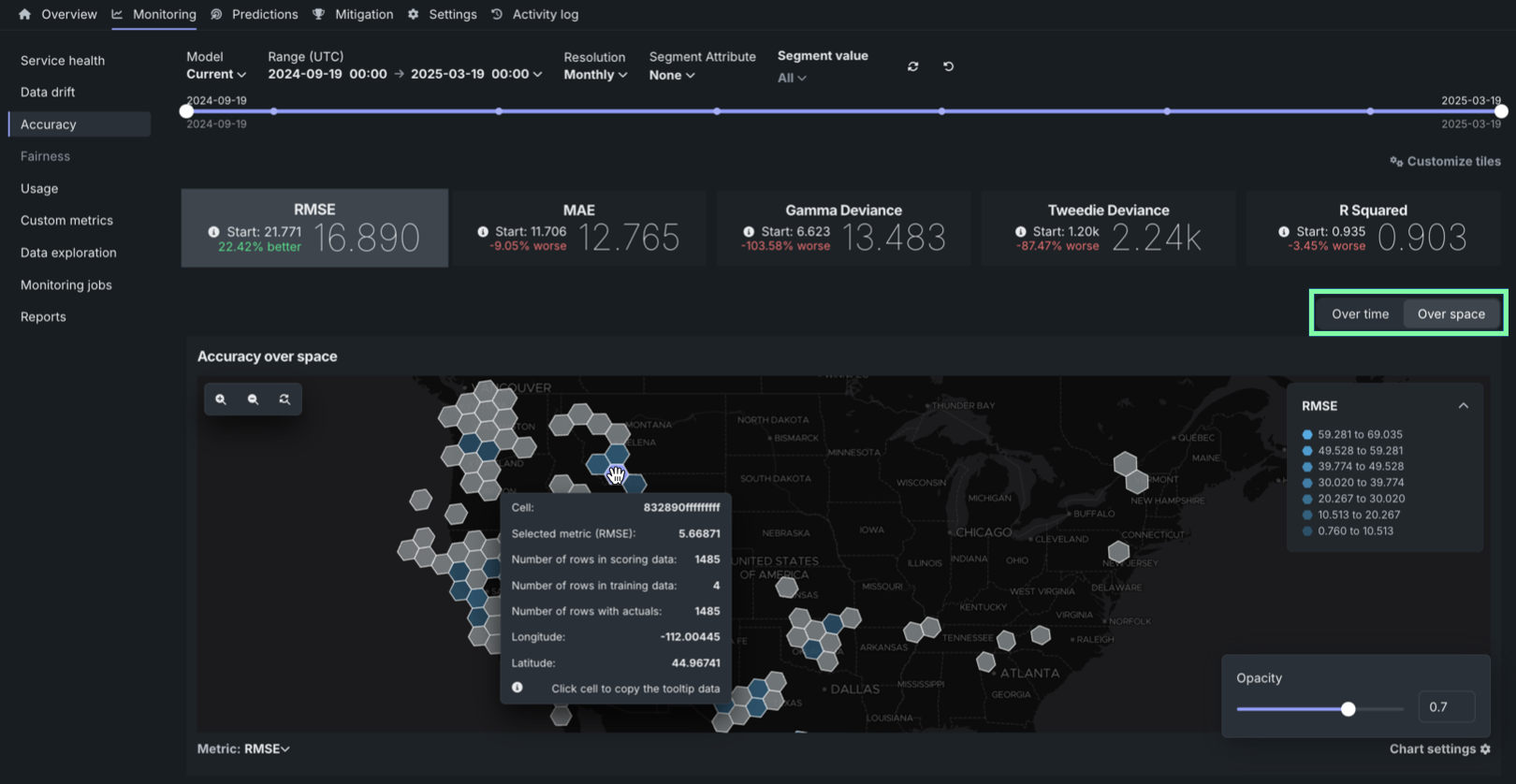
デフォルトではオンの機能フラグ:地理空間特徴量の監視を有効にする、ワークベンチで特徴量探索を有効にする
デプロイでのプロンプト監視の改善¶
デプロイされたテキスト生成モデルでは、モニタリング > データ探索タブのトレーステーブルに、追加のソートおよびフィルターオプションが含まれています。これにより、新たな方法で、生成AIデプロイの保存されたプロンプトおよび回答データを操作し、設定されたカスタム指標を通じてモデルのパフォーマンスに関するインサイトを得ることができます。 さらに、今回のリリースでは、コサイン類似度とユークリッド距離のカスタム指標テンプレートが導入されました。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:テキスト生成のターゲットタイプでデータ品質テーブルを有効にする(プレミアム機能)、生成モデルで実測値の保存を有効にする(プレミアム機能)
デフォルトではオンの機能フラグ:カスタムジョブのテンプレートギャラリーを有効にする、カスタムテンプレートを有効にする
デプロイでの編集可能なリソース設定とランタイムパラメーター¶
デプロイされたカスタムモデルでは、カスタムモデルのCPU(またはGPU)リソースバンドルとカスタムモデルの構築時に定義されたランタイムパラメーターが、構築後に編集可能になりました。

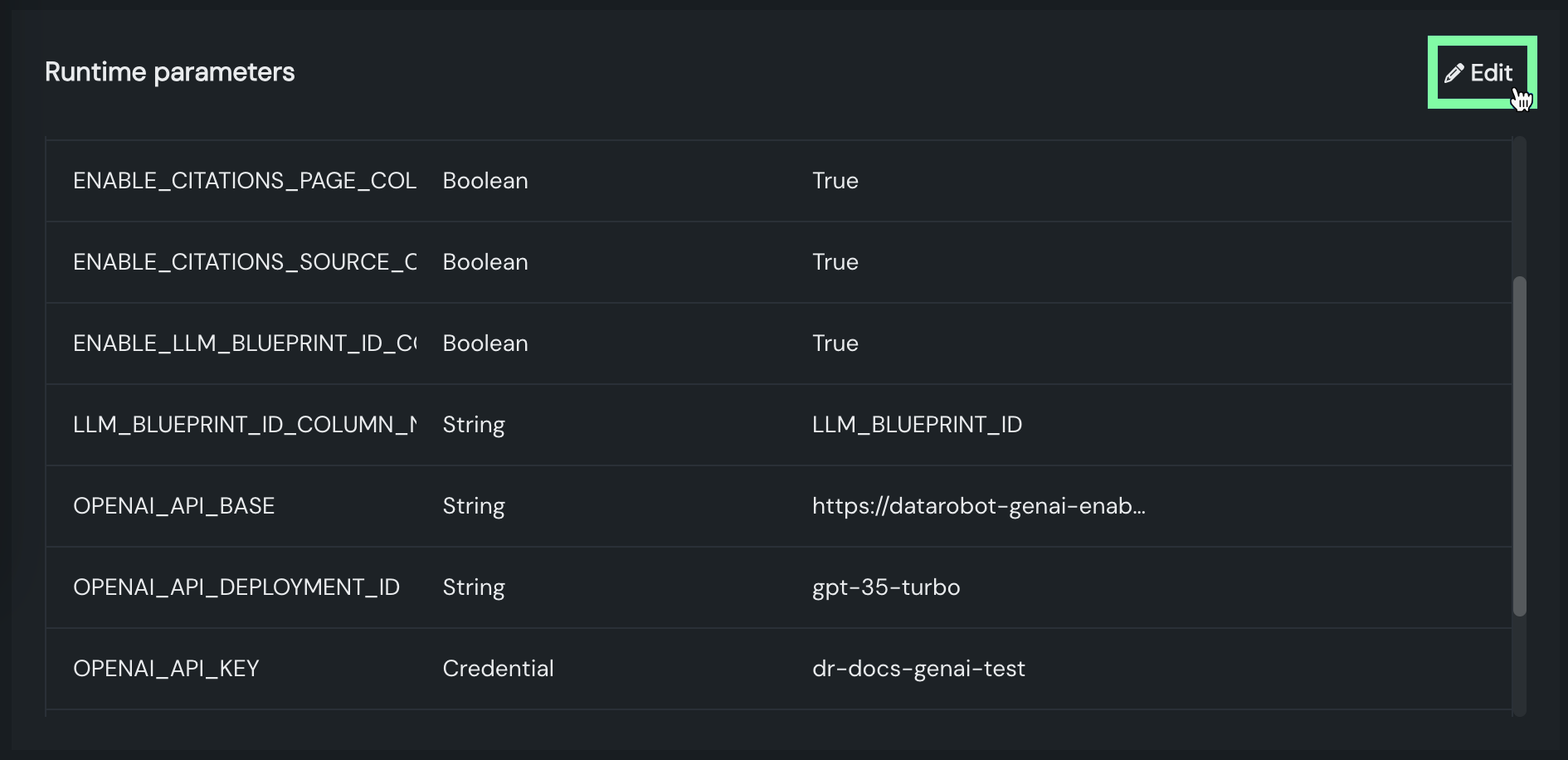
デフォルトではオンの機能フラグ:デプロイでカスタムモデルのランタイムパラメーターの編集を有効にする
デフォルトではオフの機能フラグ:リソースのバンドルを有効にする、カスタムモデルでGPUを使用した推論を有効にする(プレミアム機能)
データレジストリでのバッチ予測のためのラングリング¶
データレジストリからラングリングされたレシピでバッチ予測を行うには、デプロイの予測 > 予測を作成タブを使用します。 バッチ予測とは、大規模なデータセットで予測を行う方法で、入力データを渡すと各行の予測結果が得られます。 予測データセットボックスで、ファイルを選択 > ラングラーレシピをクリックし、データレジストリからレシピを選びます。
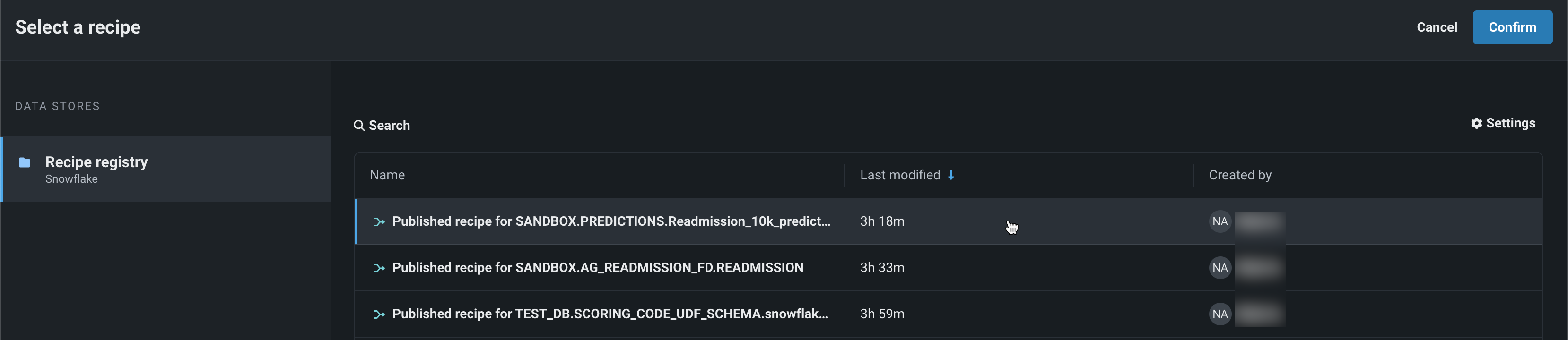
ワークベンチでの予測
データレジストリからラングリングされたレシピでのバッチ予測も、ワークベンチで利用できます。 デプロイ前のモデルで予測を行うには、エクスペリメントのモデルリストからモデルを選択し、モデルのアクション > 予測を作成をクリックします。
予測データの送信元と送信先を指定し、予測が実行されるタイミングを決定することで、バッチ予測ジョブをスケジュールすることもできます。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:データレジストリのデータセットでラングリングのプッシュダウンを有効にする
カスタムモデルでのボルトオンのガバナンスAPIの連携¶
chat()フックを使用すると、カスタムモデルにボルトオンのガバナンスAPIを実装して、チャット履歴やストリーミングレスポンスにアクセスできるようになります。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。