カスタムモデルのトレーニングデータ割り当てを変更¶
モデルデプロイで特徴量ドリフト追跡を有効にするには、トレーニングデータを追加する必要があります。 これまで、トレーニングデータはカスタムモデルに直接割り当てていたため、そのモデルのすべてのバージョンで同じデータが使われていました。しかし、この割り当て方法はDataRobotバージョン9.1で使用非推奨になり(DataRobotバージョン10.0で追加アナウンス)、DataRobotバージョン10.1で削除されました。
モデルデプロイで特徴量ドリフト追跡を有効にするには、トレーニングデータを追加する必要があります。 これまで、トレーニングデータはカスタムモデルに直接割り当てていたため、そのモデルのすべてのバージョンで同じデータが使われていました。しかし、この割り当て方法は2023年3月に使用非推奨になり、2024年4月に削除されました。
このページでは、2023年3月から2024年4月までの使用非推奨の期間中に必要となった変換処理と、削除された「モデルごと」の割り当て方法での処理について、概要を確認できます。
2023年3月から2024年4月までの使用非推奨の期間中、トレーニングデータをモデルのバージョンに割り当てるには、変換処理が必要でした。
変換が不要に
「モデルごと」の割り当て方法が削除されたため、変換手順は不要になりました。 カスタムモデルにトレーニングデータを割り当てる現在のプロセスの詳細については、ドキュメントを参照してください。
-
モデルレジストリ > カスタムモデルワークショップのモデルリストで、トレーニングデータを追加するモデルを選択します。
-
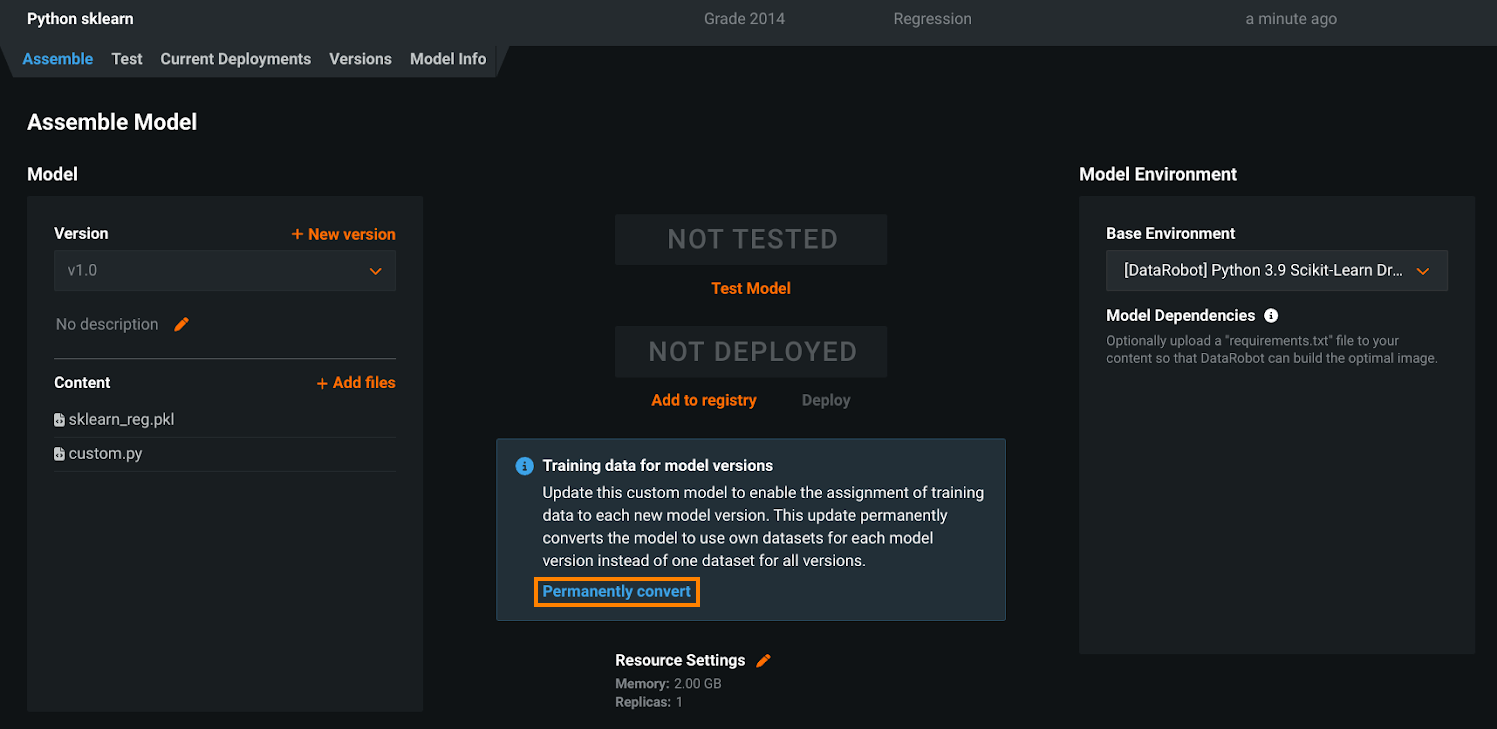
カスタムモデルのバージョンにトレーニングデータを割り当てるには、モデルを変換する必要があります。 アセンブルタブで、モデルバージョン用のトレーニングデータのアラートを見つけて、恒久的に変換をクリックします。
トレーニングデータの割り当て方法の変換
モデルのトレーニングデータの割り当て方法を変更することは、一方向の操作です。 元に戻すことはできません。 変換後は、モデルレベルでトレーニングデータを割り当てることはできません。 この変更はUIおよびAPIに適用されます。 「モデルごと」 のトレーニングデータの割り当てに基づく自動化を組織内で行っている場合は、モデルを変換する前に、関連する自動化を更新して新しいワークフローをサポートする必要があります。 別の方法として、新しいカスタムモデルを作成して 「バージョンごと」 のトレーニングデータの割り当て方法に変更し、自動化に必要なモデルで使用非推奨の 「モデルごと」 の方法を維持することもできます。ただし、機能のギャップを避けるために、使用非推奨のプロセスが終了する前に自動化を更新する必要があります。
モデルにトレーニングデータがすでに割り当てられている場合は、モデルを変換した後、データセットセクションに既存のトレーニングデータセットに関する情報が表示されます。
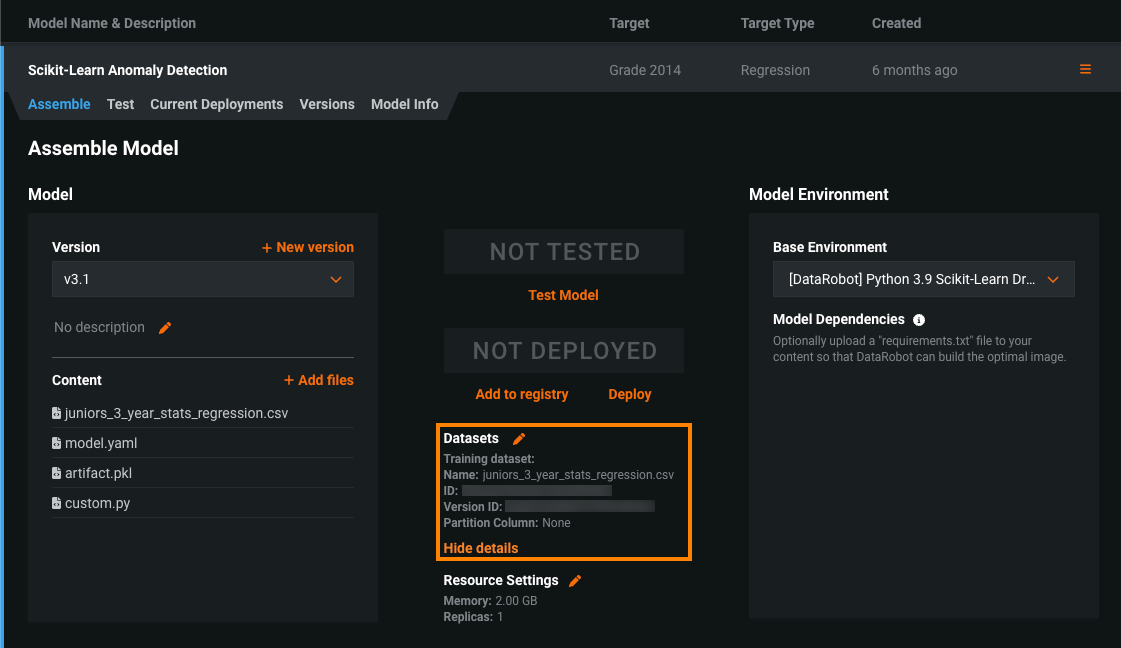
-
アセンブルタブのデータセットの隣:
-
モデルのバージョンにトレーニングデータが割り当てられていない場合は、割り当てるをクリックします。
-
モデルのバージョンにトレーニングデータが割り当てられている場合は、編集アイコン(
 )をクリックし、トレーニングデータを変更ダイアログボックスで、削除アイコン(
)をクリックし、トレーニングデータを変更ダイアログボックスで、削除アイコン( )をクリックして既存のトレーニングデータを削除します。
)をクリックして既存のトレーニングデータを削除します。
-
-
トレーニングデータを追加(またはトレーニングデータを変更)ダイアログボックスで、トレーニングデータセットファイルをクリックしてトレーニングデータボックスにドラッグするか、ファイルを選択をクリックして以下のいずれかを実行します。
-
ローカルファイルをクリックし、ローカルストレージからファイルを選択して、開くをクリックします。
-
AIカタログをクリックし、以前にDataRobotにアップロードしたトレーニングデータセットを選択して、このデータセットを使用をクリックします。
スコアリングに必要な特徴量を含める
カスタムモデルのトレーニングデータの列は、デプロイされたカスタムモデルへのスコアリングリクエストにどの特徴量が含まれるかを示します。したがって、トレーニングデータが使用可能になると、トレーニングデータセットに含まれない特徴量はモデルに送信されません。 この要件は、 カスタムモデルのテスト中に行われた予測には適用されません。 プレビュー版の機能です。NextGenエクスペリエンスで カスタムモデルを構築する場合、 列のフィルター設定を使用して、この動作を無効にできます。
-
-
(オプション)(トレーニング/検定/ホールドアウトのパーティションに基づいて)データのパーティション情報を含む列名を指定します。 カスタムモデルをデプロイし、そのデータドリフトと精度を監視する予定であれば、列にホールドアウトパーティションを指定して、精度のベースラインを確立します。
パーティション列の指定
パーティション列を指定しなくても、データのドリフトと精度を追跡できます。ただし、このシナリオでは、DataRobotにベースライン値はありません。 選択されたパーティション列は
T、V、Hのいずれかの値のみを含む必要があります。 -
アップロードが完了したら、トレーニングデータを追加をクリックします。
トレーニングデータの割り当てエラー
トレーニングデータの割り当てに失敗すると、新しいカスタムモデルバージョンのデータセットの下にエラーメッセージが表示されます。 このエラーが存在する間は、影響を受けるバージョンをデプロイするモデルパッケージを作成できません。 エラーを解決してモデルパッケージをデプロイするには、トレーニングデータを再割り当てして新しいバージョンを作成するか、新しいバージョンを作成してからトレーニングデータを割り当てます。
サポート終了のお知らせ
これまで、トレーニングデータはカスタムモデルに直接割り当てていたため、そのモデルのすべてのバージョンで同じデータが使われています。しかし、この割り当て方法は2023年3月に使用非推奨になり、2024年4月に削除されました。
このワークフローは_削除され_、使用できません。
-
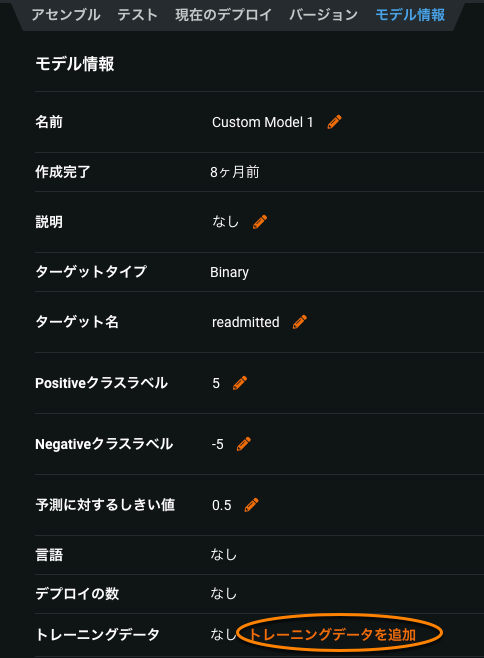
モデルレジストリ > カスタムモデルワークショップのモデルリストで、トレーニングデータを追加するモデルを選択します。
-
モデル情報タブをクリックし、トレーニングデータを追加をクリックします(この方法は今後削除されるため、カスタムモデルを恒久的に変換するための代わりの方法を準備する必要があります)。
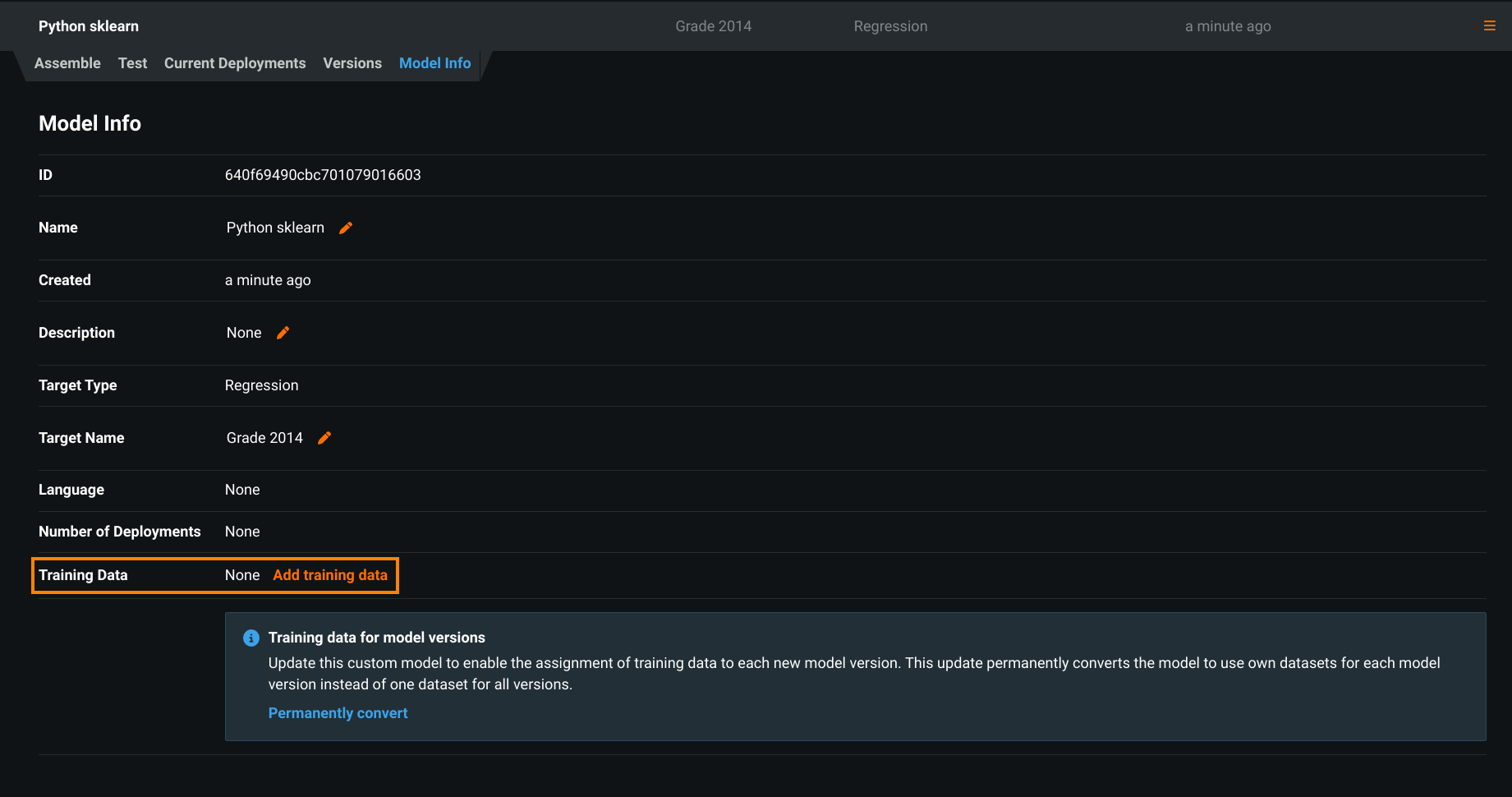
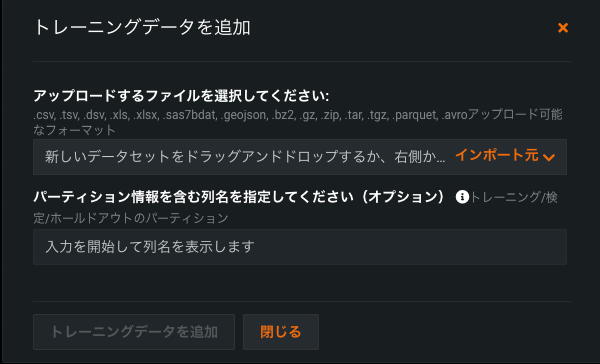
トレーニングデータを追加ダイアログボックスが表示され、トレーニングデータをアップロードするよう求められます。
-
ファイルを選択をクリックし、トレーニングデータをアップロードします。 (オプション)(トレーニング/検定/保留分割に基づき)データの分割情報を含む列名を指定できます。 カスタムモデルをデプロイして精度を監視する場合、列にホールドアウトパーティションを指定して、精度のベースラインを規定します。 パーティション列を指定しなくても精度は追跡できますが、精度のベースラインはありません。 アップロードが完了したら、トレーニングデータを追加をクリックします。
スコアリングに必要な特徴量を含める
カスタムモデルのトレーニングデータの列は、デプロイされたカスタムモデルへのスコアリングリクエストにどの特徴量が含まれるかを示します。したがって、トレーニングデータが使用可能になると、トレーニングデータセットに含まれない特徴量はモデルに送信されません。 この要件は、 カスタムモデルのテスト中に行われた予測には適用されません。 プレビュー版の機能です。NextGenエクスペリエンスで カスタムモデルを構築する場合、 列のフィルター設定を使用して、この動作を無効にできます。