データ、モデリング、アプリ(V10.0)¶
2024年4月29日
DataRobot v10.1.0リリースには、以下で説明するように、データ、モデリング、アプリ、管理に関する多くの新機能と機能強化が含まれています。 リリース10.0のその他の詳細については、MLOpsおよびコードファーストのリリースノートをご覧ください。
注目の新機能¶
拡張性が高く、フルカスタマイズ可能で、特定のクラウドに依存しないGenAI機能を導入¶
DataRobot GenAI機能を使用すると、事前にトレーニングされたさまざまな大規模言語モデル(LLM)を使用してテキストコンテンツを生成できます。 さらに、ベクターデータベースを構築し、LLMブループリントで活用することで、データに合わせてコンテンツを調整することができます。 DataRobotの生成AI製品では、DataRobotの予測AIエクスペリエンスに基づいて信頼度スコアを作成し、お気に入りのライブラリの使用、LLMの選択、サードパーティのツールの統合を行うことができます。 ホストされたノートブックまたはDataRobotのUIを使用して、ビジネスの価値を高めるあらゆる場所にAIを埋め込むかデプロイし、パイプライン内の各資産に組み込みのガバナンスを活用できます。 DataRobotのUIからは、以下のことができます
-
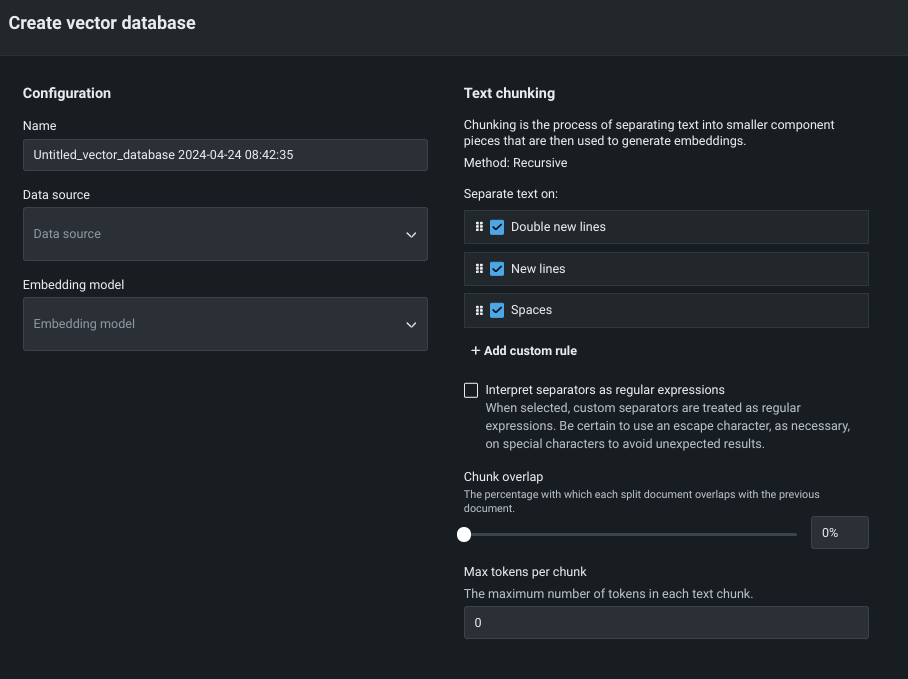
UIと、デプロイされたChromaDBベクターデータベースなどの両方で、コードを使用してベクターデータベースを構築します。
-
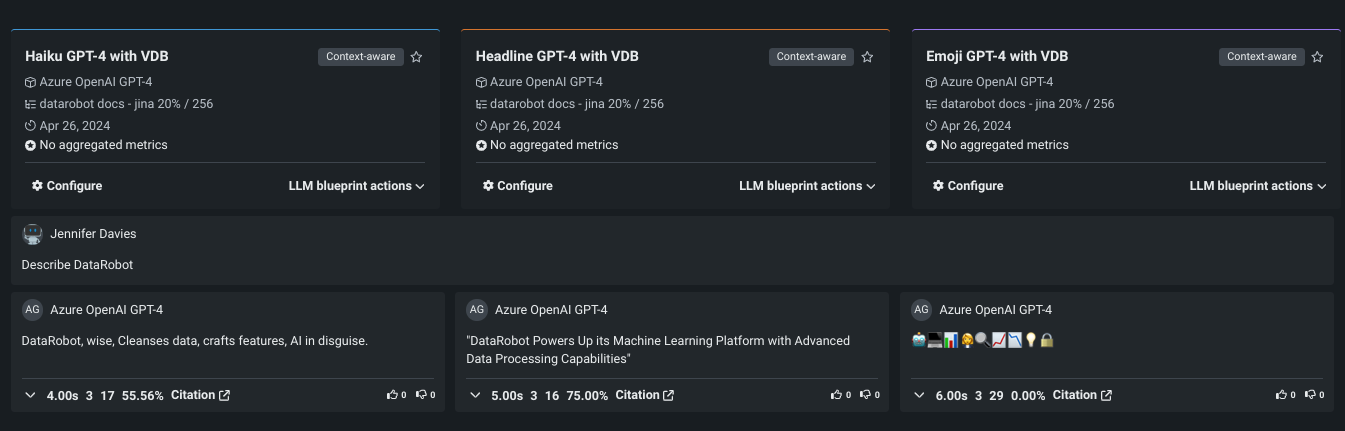
LLMブループリントの構築や比較が可能なプレイグラウンドを作成できます。
-
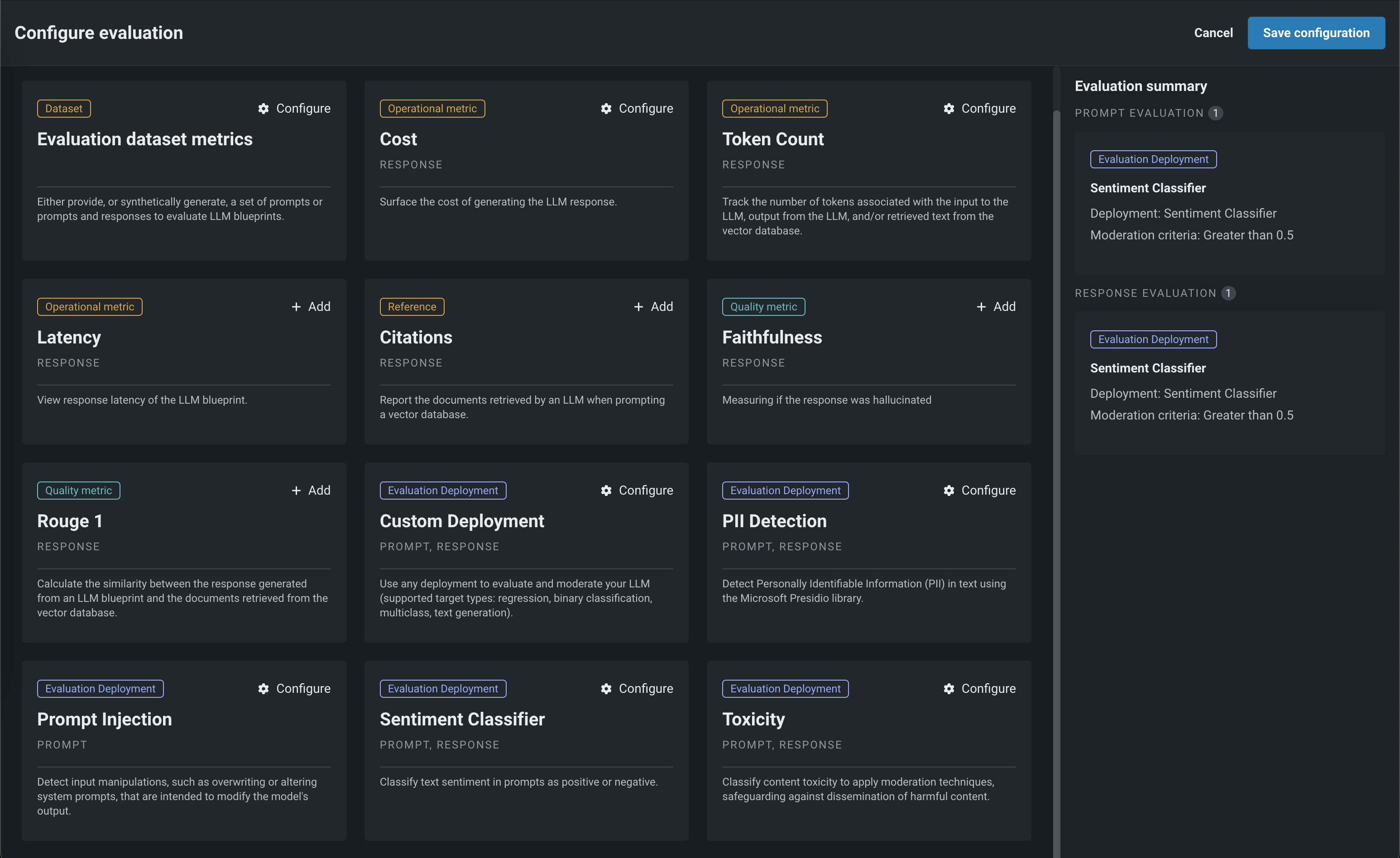
評価とモデレーションのガードレールを設定できます。
さらに多くのことができます。
エンドツーエンドの生成AIソリューションを大規模に構築するユースケースの例をご覧ください。
さらに多くのドキュメントを準備中
生成AIのドキュメントは「継続的に提供」していきます。最も完全なコンテンツは、DataRobotの公開ドキュメントサイトにあります。
リリース10.0¶
リリースv10.0では、以下の言語のUI文字列の翻訳が更新されています。
- 日本語
- フランス語
- スペイン語
- 韓国語
- ブラジルポルトガル語
目的別にグループ化された機能
期限切れの古い機能に対するサポートの変更については、サポート終了に関する重要なお知らせをご覧ください。 このドキュメントでは、DataRobotの修正された問題についても説明します。
データの強化¶
一般提供¶
ネイティブDatabricksコネクターを追加¶
AzureやAWSでDatabricksのデータにアクセスできるネイティブDatabricksコネクターが、DataRobotで一般提供されました。 この新しいコネクターでは、パフォーマンスの向上に加えて、次のことが可能になります。
- データ接続を作成して設定する。
- サービスプリンシパルによる接続の認証と、セキュアな設定によるサービスプリンシパルの資格情報の共有。
- ユースケースにDatabricksデータセットを追加する。
- Databricksのデータセットをラングリングし、Databricksにレシピをパブリッシュして、データレジストリで出力をマテリアライズ。
- パブリックPython APIクライアントを使用して、Databricksコネクター経由でデータにアクセスする。
ネイティブAWS S3コネクターを追加¶
新しいAWS S3コネクターが、DataRobotで一般提供されました。 このコネクターでは、パフォーマンスの向上に加えて、ワークベンチでのAWS S3のサポートを有効にし、次のことが可能になります。
- データ接続を作成して設定する。
- ユースケースにAWS S3データセットを追加する。
ワークベンチでのレシピ管理を改善¶
このリリースでは、ワークベンチでのデータラングリングに対して以下の機能強化が行われています。
- ユースケースでデータセットをラングリングする)際(同じデータセットを再度ラングリングする場合も含む)、操作を追加したかどうかに関係なく、データタブにレシピのコピーが作成されて保存されます。 その後、レシピを変更するたびに、変更内容が自動的に保存されます。 さらに、保存されたレシピを開いて変更を続けることができます。
- ユースケースにおいて、データセットタブはデータタブに置き換えられ、データセットとレシピの両方が表示されるようになりました。 また、データセットとレシピをすばやく区別できるように、データタブに新しいアイコンが追加されました。
- ラングリングセッション中に、将来レシピを再ラングリングする際に役立つ名前と説明をレシピに追加します。
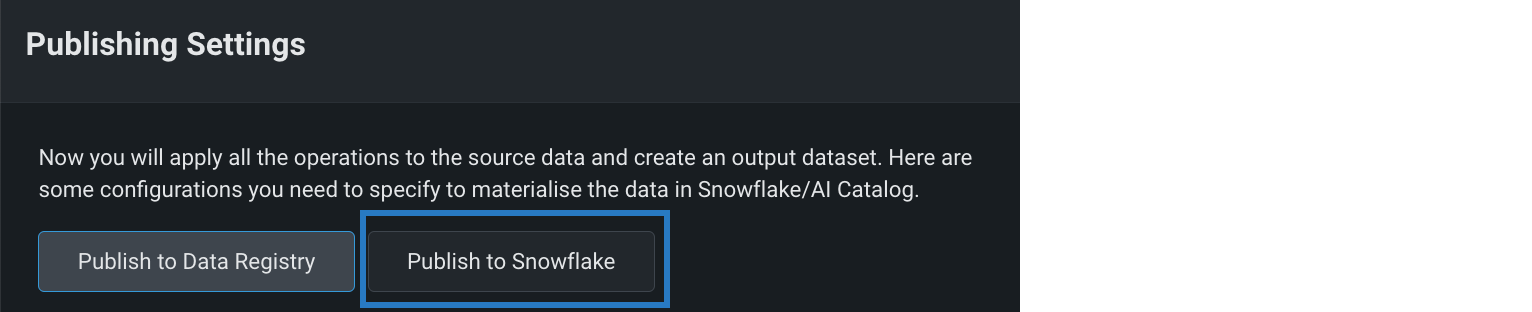
ラングリングされたBigQueryおよびSnowflakeデータセットのソース内マテリアライズを有効化¶
BigQueryとSnowflakeのデータセットをラングリングする際のソース内マテリアライズが一般提供機能になりました。 パブリッシュ設定で、データソースに応じてBigQueryにパブリッシュまたはSnowflakeにパブリッシュのいずれかをクリックします。 このオプションを選択すると、データソースと同様に、データレジストリの出力動的データセットがマテリアライズされます。 これにより、その環境内で指定されたセキュリティ、コンプライアンス、財務管理を活用できます。
すべてのラングリング操作を一般提供¶
これまでプレピュー機能だったラングリング操作の結合と集計が、ワークベンチで一般提供されました。
Parquetファイルの取込みをサポート¶
AIカタログ、トレーニングデータセット、予測データセットにおいて、Parquetファイルの取込みが一般提供機能になりました。 サポートされるParquetファイルタイプは以下のとおりです。
- 単一のParquetファイル
- zip圧縮された単一のParquetファイル
- 複数のParquetファイル(別々のデータセットとして登録)
- zip圧縮された複数のParquetファイル(DataRobotで単一のデータセットを作成するためにマージ)
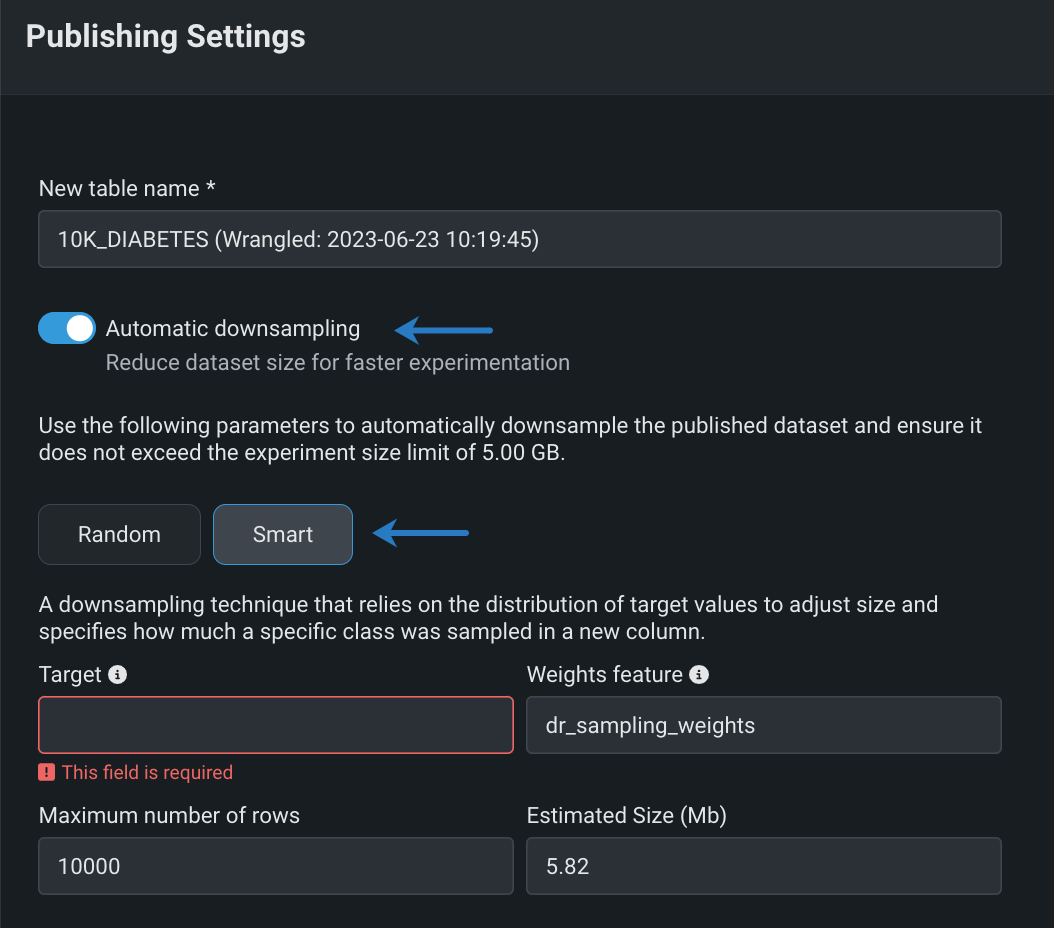
ラングリングレシピのパブリッシュ時にスマートダウンサンプリングを実行¶
ワークベンチでラングリングレシピを構築した後、パブリッシュ設定でスマートダウンサンプリングを有効にすると、出力データセットのサイズを縮小し、モデルトレーニングを最適化することができます。 スマートダウンサンプリングは、クラスごとにサンプルを層別化することでクラスの不均衡を考慮するだけでなく、精度を犠牲にせずにモデルの適合にかかる時間を短縮するデータサイエンスのテクニックです。
プレビュー¶
ワークベンチでの特徴量探索の実行¶
プレビュー版の機能です。ワークベンチで特徴量探索を実行し、複数のデータセットから新しい特徴量を発見および生成できるようになりました。 特徴量探索は、次の2つの場所で開始できます。
- データタブで、プライマリーデータセットとなるデータセットの右側にあるアクションメニュー > 特徴量探索をクリックします。
- 特定のデータセットのデータ探索ページで、データのアクション > 特徴量探索を開始をクリックします。
このページでは、セカンダリーデータセットを追加して、データセット間の関係性を設定できます。
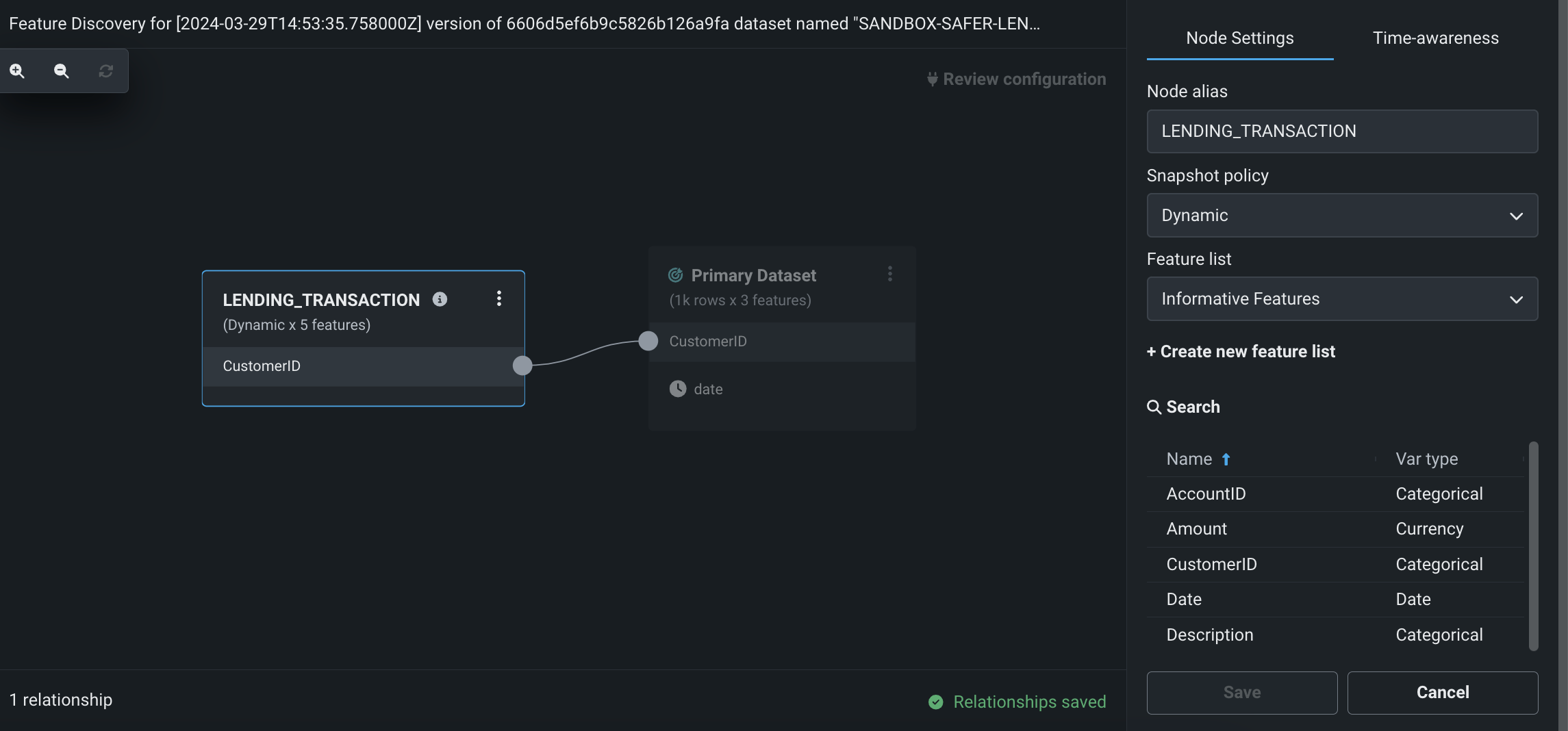
特徴量探索のレシピをパブリッシュすると、DataRobotは特定の結合と集計を実行し、新しい出力データセットを生成してデータレジストリに登録し、現在のユースケースに追加します。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ: ワークベンチで特徴量探索を有効にする
ワークベンチでのデータ操作を改善¶
このリリースでは、ワークベンチでのデータ操作に対して以下の機能強化が行われています(プレビュー版の機能です)。
- データ探索ページでは、データセットのバージョン管理、およびデータセットの名前変更とダウンロードができるようになりました。
- 特徴量セットのドロップダウンは、データ探索ページで独立したタブになりました。
- 新しい特徴量の計算で、オートコンプリート機能が改善されました。
- 動的データセットを使ってエクスペリメントを設定できるようになりました。
デフォルトではオフの機能フラグ:データ探索ビューの機能強化を有効にする
ワークベンチでのレシピ管理を改善¶
プレビュー版の機能です。ユースケースでデータセットをラングリングする際(同じデータセットを再度ラングリングする場合も含む)、操作を追加したかどうかに関係なく、データタブにレシピのコピーが作成されて保存されます。 その後、レシピを変更するたびに、変更内容が自動的に保存されます。 さらに、保存されたレシピを開いて変更を続けることができます。
データセットとレシピをすばやく区別できるように、データタブに新しいアイコンが追加されました。
ラングリングセッション中に、将来レシピを再ラングリングする際に役立つ名前と説明をレシピに追加します。

プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:ワークベンチでのレシピ管理を有効にする
DataRobotにADLS Gen2コネクターを追加¶
DataRobot Classicとワークベンチの両方にADLS Gen2ネイティブコネクターのサポートが追加され、次のことが可能になりました。
- データ接続を作成して設定する。
- ADLS Gen2データセットを追加する。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ:** ADLS Gen2コネクターを有効にする
特徴量探索での関係性の自動生成¶
パブリックプレビュー版の機能です。DataRobotでは、特徴量探索プロジェクトでデータセット間の関係性を自動的に検出および生成できます。これにより、データセットのつながりが不明な場合に、潜在的な関係性をすばやく調べることができます。 関係性を自動生成するには、すべてのセカンダリーデータセットがプロジェクトに追加されていることを確認してから、関係性を定義するページの上部にある関係性を生成をクリックします。
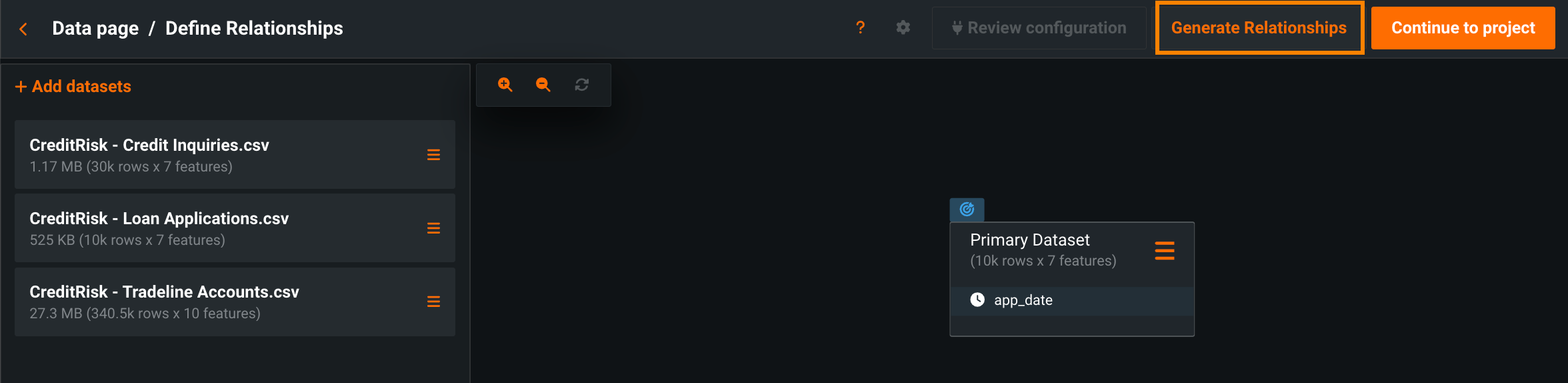
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:特徴量探索での関係性検出を有効化
モデリング特徴量¶
一般提供¶
ワークベンチでの予測プロジェクトに2つのパーティション分割方法を追加¶
一般提供機能です。ワークベンチで、ユーザー定義の分割(Classicでは「列ベース」つまり「パーティション特徴量」)と自動グループ化(Classicでは「グループパーティション」)をサポートするようになりました。 あまり一般的ではありませんが、ユーザー定義および自動化されたグループパーティション分割では、パーティション特徴量(グループ化の基礎となるデータセットの特徴量)によってパーティション分割する方法を利用できます。 グループ化を使用するには、パーティション特徴量のカーディナリティに基づいて方法を選択します。 選択したら、検定タイプを選択します。適切な検定タイプの選択方法や、パーティション分割にグループ化を使用する方法について詳しくは、ドキュメントを参照してください。

DataRobot Classicでの時間認識エクスペリメントにおいて、スライスされたインサイトの一般提供を開始¶
このデプロイでは、DataRobot Classicのリフトチャート、ROC曲線、特徴量ごとの作用、特徴量のインパクトで、OTVおよび時系列プロジェクトのスライスされたインサイト が一般提供されました。 スライスされたインサイトは、特徴量値に基づいて、モデルの派生データの部分母集団を表示するオプションを提供します。 スライスされたインサイトから取得したセグメントベースの精度情報を使用するか、セグメントを「グローバル」スライス(すべてのデータ)と比較して、トレーニングデータを改善、セグメントごとに個別モデルを作成、またはデプロイ後の予測を補強します。
時間認識エクスペリメントで日付/時刻パーティションの一般提供を開始¶
時間認識エクスペリメントの作成機能(予測または時系列予測)が一般提供されました。 行ごとの予測のためのセットアップの多くを共有する簡素化されたワークフロー、より明確なバックテスト修正ツール、構築前に変更をリセットする機能により、時間に関連するデータをすばやく簡単に操作できるようになりました。
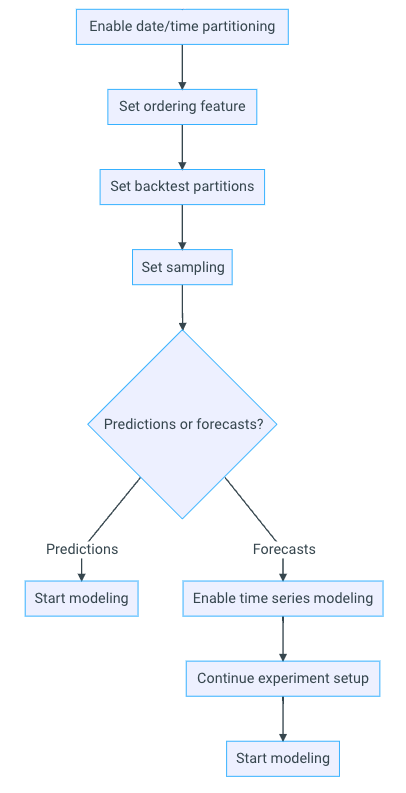
エクスペリメントのドラフト保存¶
ワークベンチでエクスペリメントを作成する際、 作業内容をドラフトとして保存し、エクスペリメントのセットアップページから離れても、後でセットアップに戻れるようになりました。 ドラフトのステータスはユースケースのホームページに表示されます。

OTVエクスペリメントにおける10GBまでのデータセットのアップロード、モデリング、インサイト生成¶
OTV(時間外検定)エクスペリメントのスケーラビリティとユーザーエクスペリエンスを向上させるため、大規模データセットにスケーリングを導入しました。 分割手法として時間外検定を使用する場合、DataRobotは10GBほどのデータセットでもダウンサンプリングを行う必要がなくなりました。 代わりに、多段階のオートパイロットプロセスで、大幅に拡大された入力許容量に対応します。
プレビュー¶
ワークベンチでGPUのサポートを開始¶
追加の自動化設定では、テキストや画像を含み、ディープラーニングモデルを必要とするワークベンチのエクスペリメントで、GPUワーカーを有効にできるようになりました。 GPUでのトレーニングにより、トレーニング時間が短縮されます。 DataRobotは、特定のタスクを含むブループリントを検出します。これらのブループリントが検出されると、オートパイロットとブループリントのリポジトリの両方にGPU対応のブループリントが含まれます。
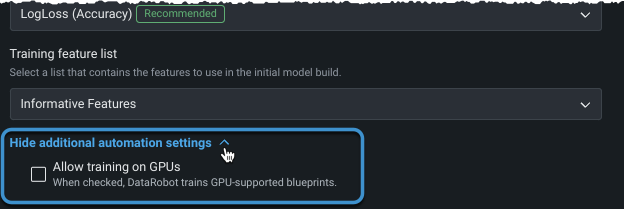
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:GPUワーカーを有効にする
SHAPベースの個々の予測説明をワークベンチに追加¶
SHAPベースの説明は、特定の予測が平均とは異なることに各特徴量がどの程度関与しているかを推定するため、何が予測の根拠となっているかを行単位で理解するのに役立ちます。 ワークベンチに導入されたことで、SHAPベースの説明は、すべてのモデルタイプで利用可能になりました。ただし、XEMPベースの説明は、ユースケースのエクスペリメントでは利用できません。 インサイトのコントロールを使用して、データパーティションを設定し、スライスを適用して、予測範囲を設定します。
備考
個々の行ごとにSHAP値を計算するローカルな説明方法として、この機能をよりわかりやすく伝えるため、SHAPベースの予測説明から個々の予測説明に名称を変更しました。
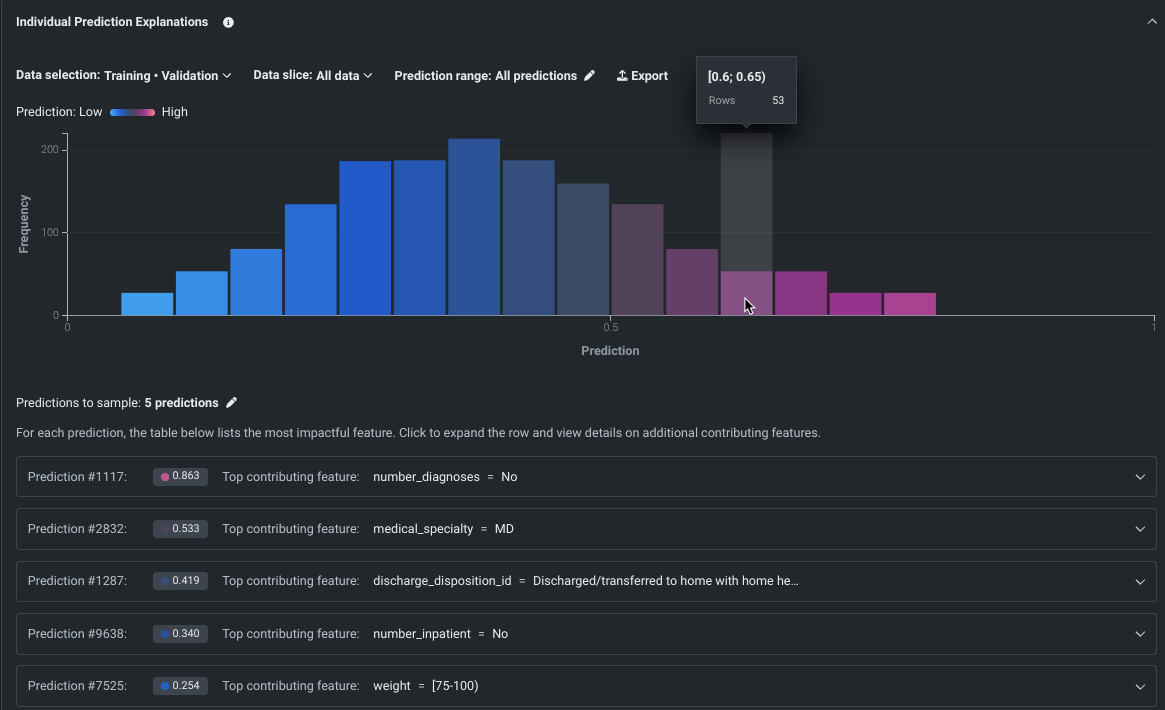
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ: NextGenでのユニバーサルSHAP
ワークベンチでワードクラウドのサポートを開始¶
分類と連続値のプロジェクトのためのテキストベースのインサイトであるワードクラウドが、ワークベンチでプレビュー機能として利用できるようになりました。 最も影響力のある単語や短いフレーズが最大200個表示され、ターゲットと単語の相関関係を理解するのに役立ちます。 ワードクラウドでは、個々の単語の詳細を表示したり、表示をフィルター処理したり、インサイトをエクスポートしたりできます。
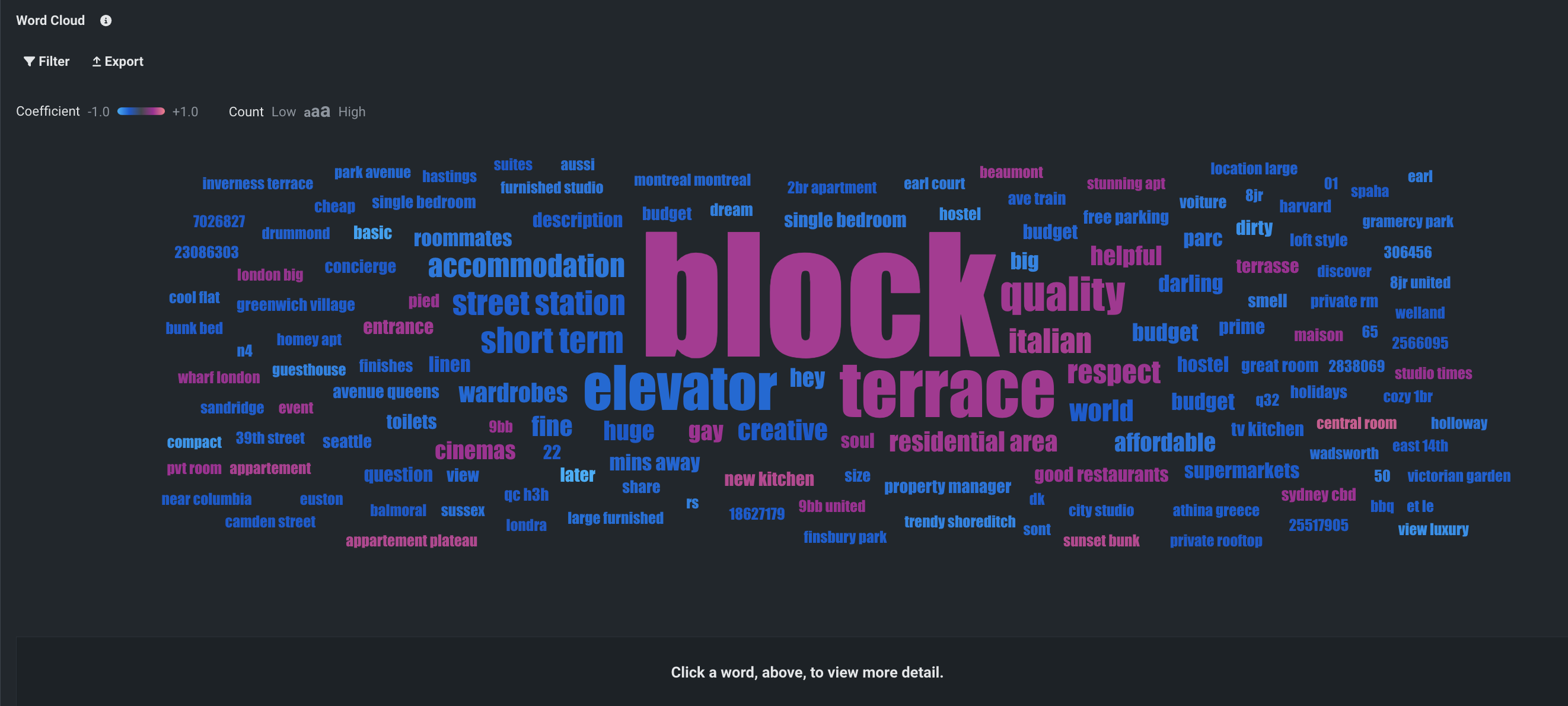
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ:ワークベンチでのワードクラウド
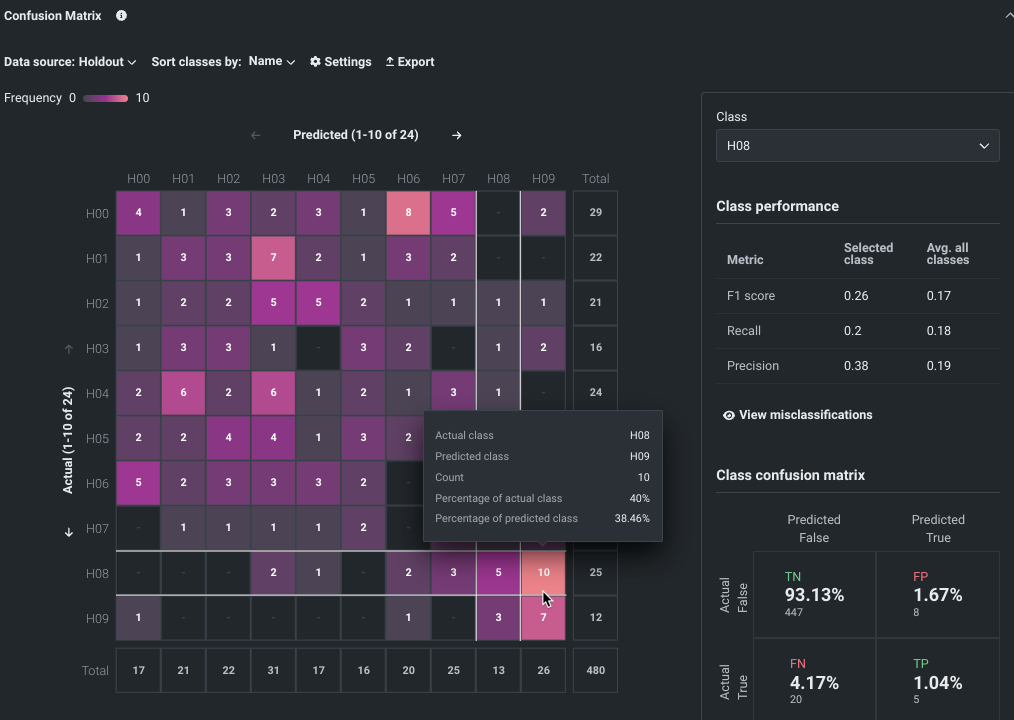
ワークベンチで多クラスエクスペリメントのサポートを開始¶
プレビュー版の機能です。ワークベンチで多クラスエクスペリメントを作成できるようになりました。 DataRobotは、指定されたターゲット特徴量での値の数に基づいて、エクスペリメントのタイプを決定します。 3つ以上であれば、エクスペリメントは多クラスまたは連続値 (数値ターゲットの場合) として処理されます。 DataRobotによる特別な処理により、以下のことが可能です。
- 連続値エクスペリメントを多クラスに変更する。
- 設定の変更が可能な集計を使用して、1000を超えるクラスをサポートする。
モデルが構築されると、多クラス混同行列によって、モデルがあるクラスを別のクラスと誤ってラベル付けしている箇所を目で確認することができます。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ:無制限の多クラス
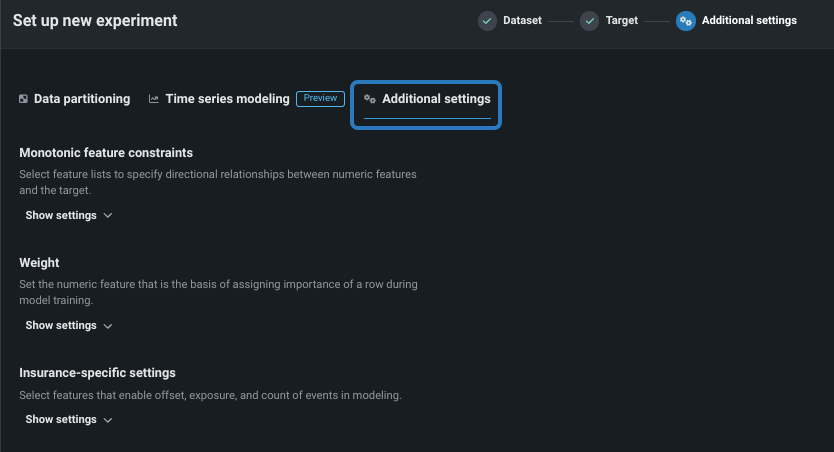
ワークベンチに新しい設定オプションを追加¶
このデプロイでは、エクスペリメントのセットアップ時に行える設定(パブリックプレビュー版)がいくつか追加され、ユーザーにとって一般的なケースの多くがカバーされます。 新しい設定では以下のことができます。
- モデリングモードを変更します。 これまでのワークベンチではクイックオートパイロットのみが実行されていましたが、手動モード(ブループリントリポジトリ経由でモデルを構築する場合)や包括モード(時間認識プロジェクトでは使用できません)に設定できるようになりました。
- 最適化指標(DataRobotによるモデルのスコアリング方法を定義する指標)を、DataRobotによって選択された指標から、エクスペリメントに適したサポート対象の指標に変更します。
- オフセット/ウェイト/エクスポージャー、単調特徴量制約、Positiveクラスの選択などの追加設定を行います。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ:UXRの高度なモデリングオプション
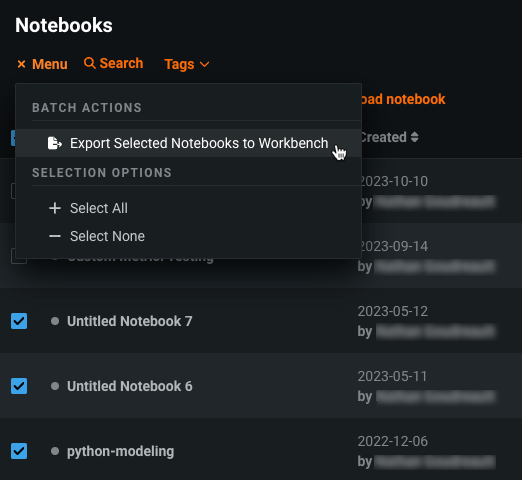
プロジェクトとノートブックをDataRobot ClassicからNextGenに移行¶
プレビュー版の機能です。DataRobot Classicで作成したプロジェクトやノートブックをDataRobot NextGenに移行することができます。 DataRobot Classicでプロジェクトをエクスポートし、エクスペリメントとしてワークベンチのユースケースに追加できます。 ノートブックも、Classicからエクスポートして、ワークベンチのユースケースに追加できます。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:アセットの移行を有効にする
OTVおよび時系列プロジェクトのデータで予測の説明を計算¶
プレビュー版の機能です。時系列およびOTVプロジェクトで予測の説明を計算できます。 具体的には、トレーニングデータのホールドアウトパーティションおよびセクションでXEMPベースの予測の説明を取得できます。 DataRobotは、トレーニングデータのバックテスト1の検定パーティションに対してのみ予測の説明を計算します。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:時間認識プロジェクトで、トレーニングデータを用いた予測の説明を有効にする
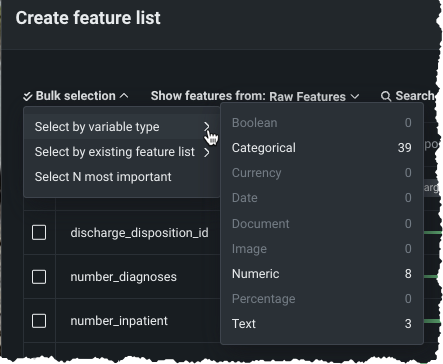
既存のエクスペリメントでカスタム特徴量セットを作成¶
ワークベンチでは、UIを使用して、既存の予測エクスペリメントに新しいカスタム特徴量セットを追加できるようになりました。 DataRobotでは、データの取込み時に、複数の特徴量セットが自動的に作成されます。これらは、モデルの構築と予測に使われる特徴量のサブセットを制御します。 リーダーボードからアクセスできるエクスペリメント情報ウィンドウの特徴量セットまたはデータタブから、独自の特徴量セットを作成できるようになりました。 一括選択を利用すると、ワンクリックで複数の特徴量を選択できます。
デフォルトではオンの機能フラグ:ワークベンチでデータタブと特徴量セットタブを有効にする、ワークベンチのプレビューで特徴量セットを有効にする、ワークベンチで特徴量セットの作成を有効にする
増分学習で最大100GBのデータを使用可能¶
プレビュー版の機能です。二値および連続値タイプのプロジェクトで、増分学習(IL)を使って最大100GBのデータでモデルをトレーニングできるようになりました。 ILは大規模なデータセットに特化したモデルトレーニング方法であり、データをチャンク化してトレーニングのイテレーションを作成します。 設定オプションにより、上位モデルが1つのイテレーションでトレーニングを行うか、すべてのイテレーションでトレーニングを行うか、また精度の向上が頭打ちになった場合にトレーニングを停止するかどうかを制御できます。 モデルの構築が開始されたら、トレーニング済みのイテレーションを比較し、必要に応じて、別のアクティブバージョンを割り当てるか、トレーニングを継続することができます。 アクティブなイテレーションは、他のインサイトのベースとなり、予測に使用されます。

プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:増分学習を有効にする、データのチャンキングサービスを有効にする
アプリ¶
MLOpsの機能強化についてのページでチャット生成Q&Aアプリケーションを参照してください。
管理機能の強化¶
一般提供¶
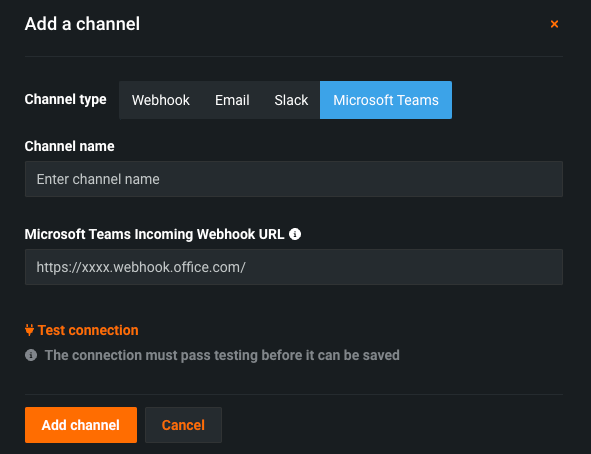
Microsoft Teams通知チャネルの追加¶
管理者はMicrosoft Teamsの通知チャネルを設定できるようになりました。 通知チャネルは、管理者が作成した通知配信メカニズムです。 各種類の通知には複数のチャネルを設定することができます(デプロイ関連イベントのURLを含むWebhook、すべてのプロジェクト関連イベントのWebhookなど)。
ユーザー設定の画面のアップデート¶
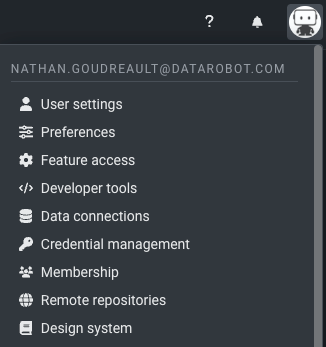
DataRobot NextGenの一部として、ユーザー設定のインターフェイスが、データ接続と開発者ツールのページを含めて一新されました。 一部の設定の名前が変更され、設定ページが新しくなりました。 最新の設定を確認するには、ユーザーアイコンを選択し、メニュー内の設定を参照します。
シングルテナントSaaS¶
DataRobotは、公衆インターネット接続のネットワークオプションを備えた、シングルテナントSaaSソリューションをリリースしました。 この機能強化により、DataRobotのAI機能をシームレスに活用しながら、ウェブ上で安全に接続し、これまでにない柔軟性とスケーラビリティを実現できます。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。