2023年10月¶
2023年10月25日
今回のデプロイにより、DataRobotのAIプラットフォームには、以下の一般提供およびプレビューの新機能が提供されました。 リリースセンターからは、次のものにもアクセスできます。
10月リリース¶
次の表は、新機能の一覧です。
目的別にグループ化された機能
一般提供¶
Document AIがPDFドキュメントをデータソースとしてサポート¶
DataRobot Classicで利用可能なDocument AIの一般提供を開始しました。Document AIは、手作業が多いデータ準備手順を増やさずに、未処理のPDFドキュメントでモデルを構築する方法を提供します。 Document AIは、大規模なコーパスに情報が分散している問題や、ドキュメントをデータソースとして効率的に利用するためのその他の障壁に対処して、データの準備を容易にし、PDFベースのモデルにインサイトを提供します。
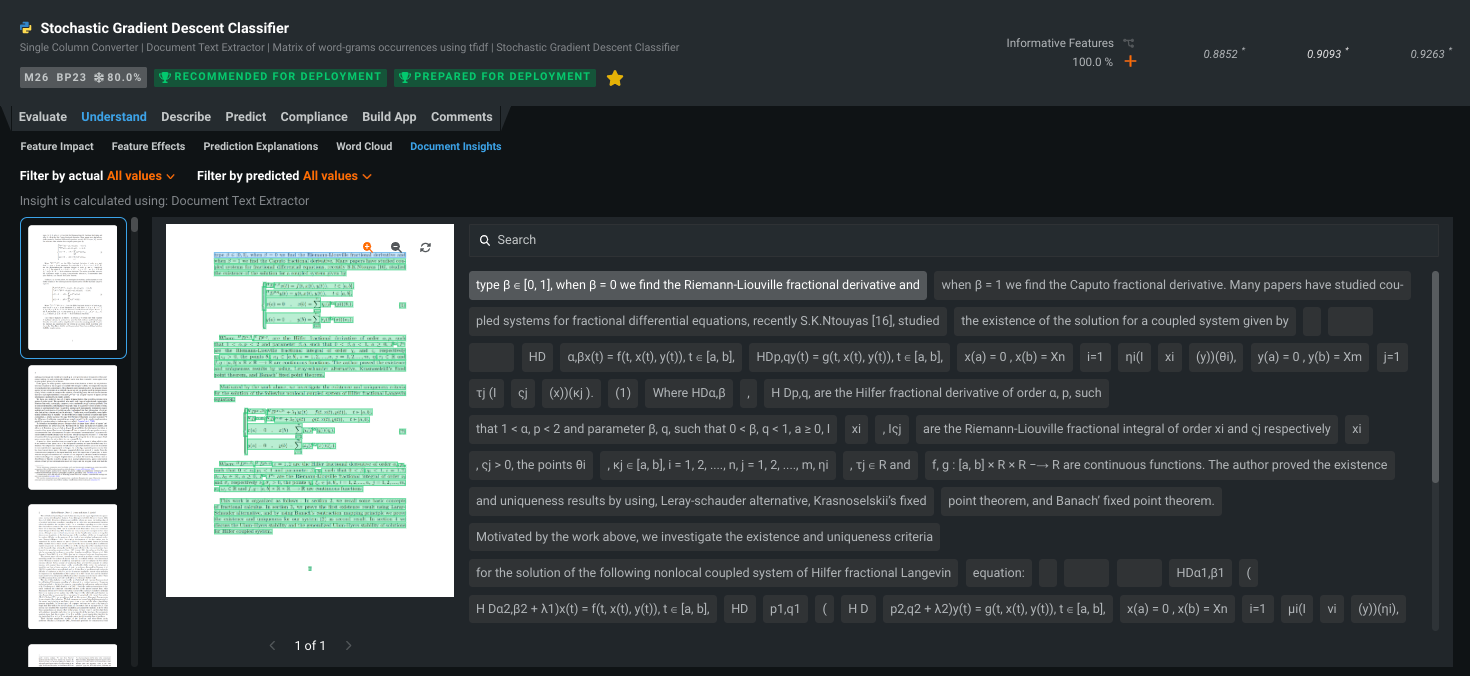
クラスターモデルでの予測の説明の一般提供を開始¶
クラスタリングで予測の説明を使用すると、特定の行のクラスター割り当てに最も貢献した要因が明らかになります。 一般提供機能になりました。このインサイトによって、クラスタリングモデルの結果をステークホルダーにわかりやすく説明できます。また、影響の大きい要因が特定されるため、事業戦略に注力できます。
多クラス予測の説明とよく似た機能ですが、クラスではなくクラスターについてレポートします。クラスターの説明は、リーダーボードとデプロイの両方から入手できます。 この機能は、XEMPベースのすべてのクラスタリングプロジェクトで利用可能ですが、時系列では利用できません。
モデルパッケージアーティファクトの作成ワークフロー¶
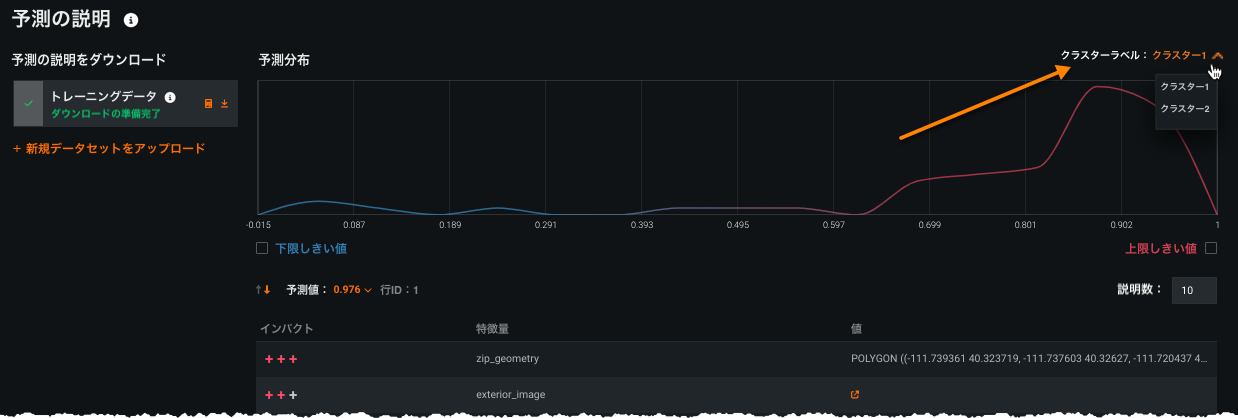
一般提供機能になりました。モデルパッケージアーティファクトの作成ワークフローが改善されて、モデルレジストリ内のモデルとそれに関連付けられたモデルパッケージ間の接続が視覚化され、モデルデプロイへのパスがより明確かつ一貫性のあるものになりました。 この新しいアプローチでは、モデルをデプロイする際、モデルの詳細を提供し、モデルを登録することから始めます。 その後、モデルパッケージを作成し、作成が完了したら、デプロイ情報を追加することでモデルをデプロイできます。
-
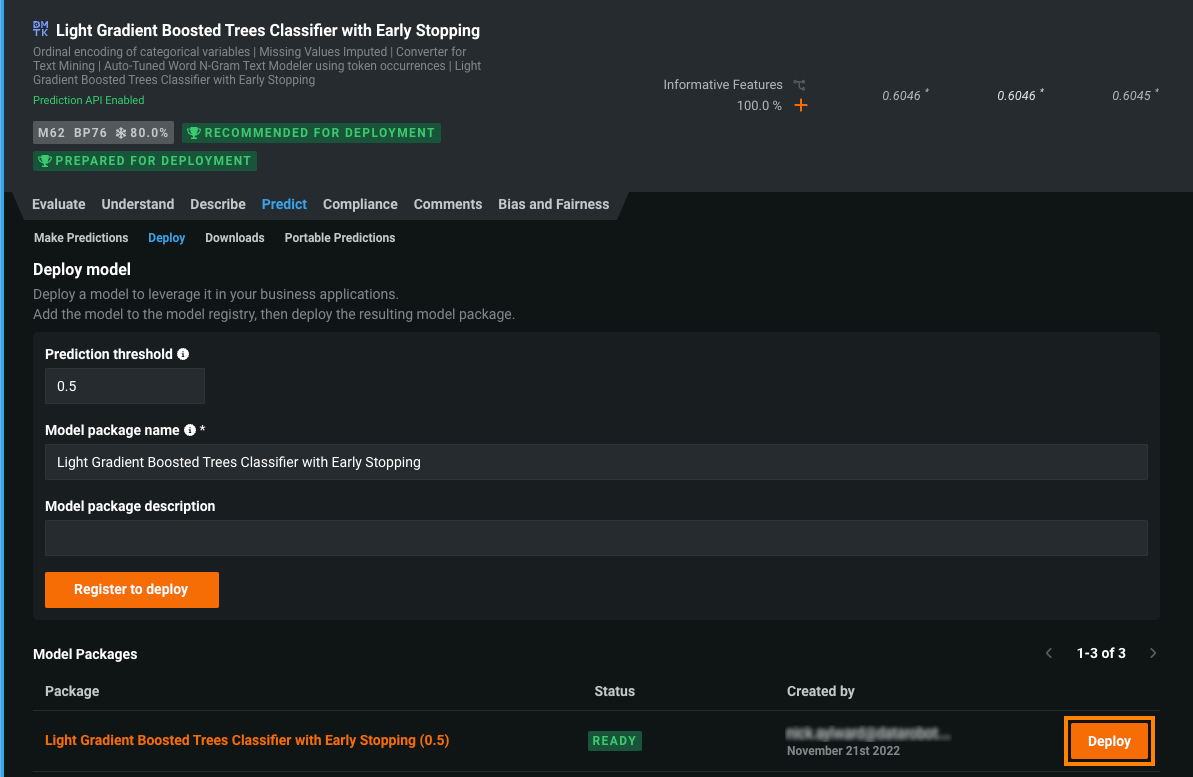
リーダーボードで、予測の生成に使用するモデルを選択します。 デプロイ推奨とデプロイの準備済みのバッジが付いたモデルをお勧めします。 予測 > デプロイをクリックします。 選択したリーダーボードモデルにデプロイの準備済みバッジがない場合、デプロイの準備をクリックして、そのモデルに対してモデル準備プロセスを実行することを推奨します。
-
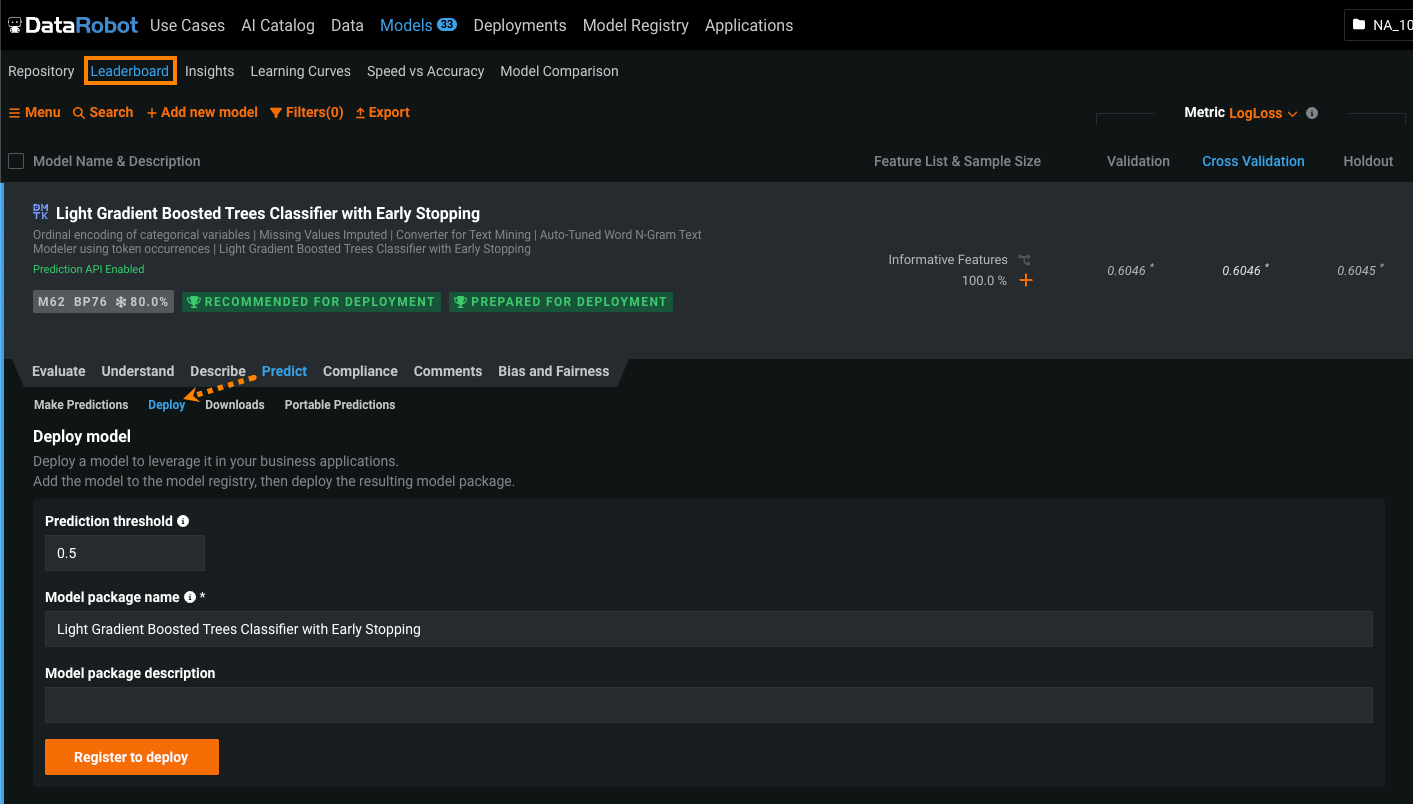
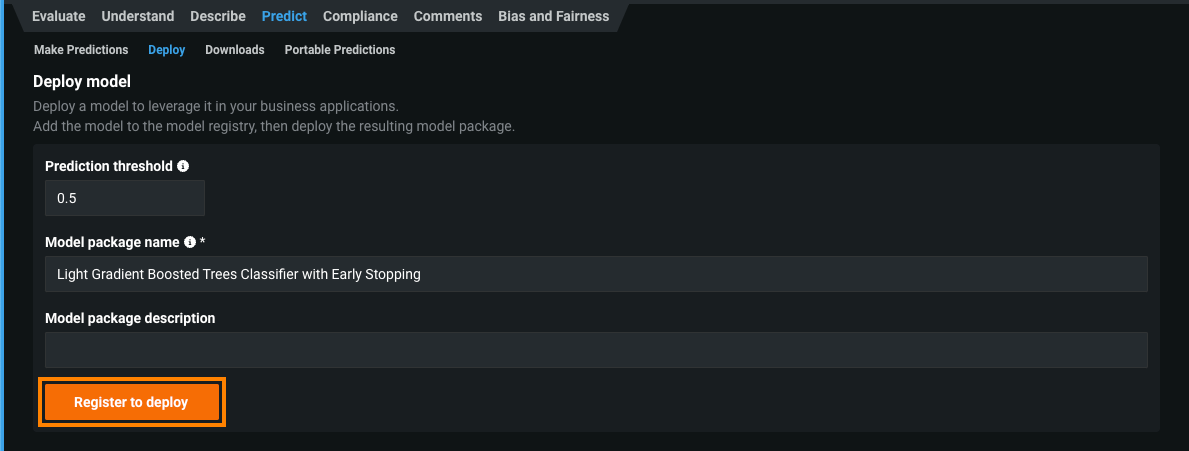
モデルをデプロイタブで、必要なモデルパッケージ情報を提供し、登録してデプロイをクリックします。
-
モデルの構築を許可します。 モデルのサイズによっては、ビルドステータスが反映されるまでに数分かかる場合があります。 デプロイする前に、モデルパッケージが準備完了のステータスになっている必要があります。

-
モデルパッケージリストで、デプロイするモデルパッケージを見つけて、デプロイをクリックします。
詳しくはドキュメントをご覧ください。
新しいモデルレジストリでのバージョン管理のサポート¶
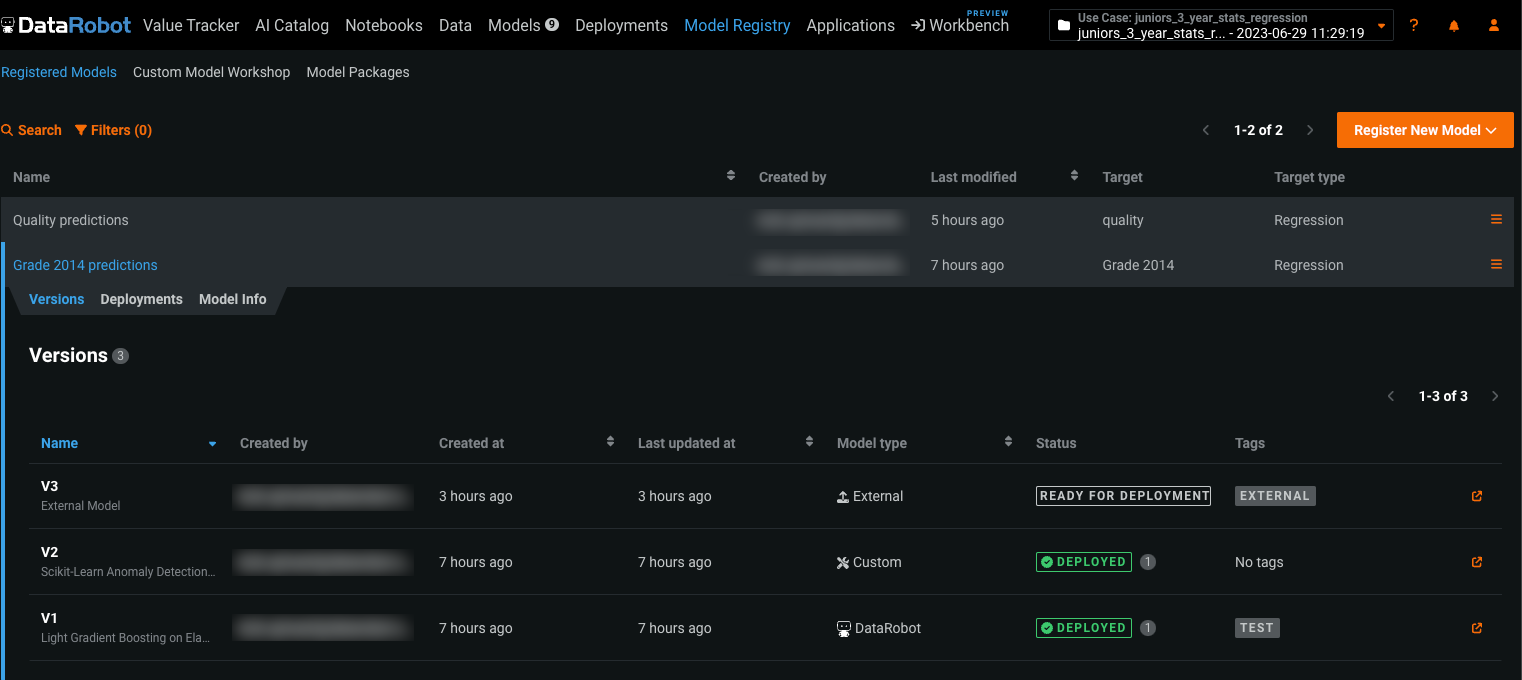
app.eu.datarobot.comで一般提供機能になりました。新しいモデルレジストリは、DataRobotで使用されるさまざまなモデルのための組織的ハブです。 モデルは、デプロイ可能なモデルパッケージとして登録されます。 これらのモデルパッケージは、_登録されたモデルバージョン_を含む_登録モデル_にグループ化され、解決するビジネス問題に基づいて分類できます。 登録されたモデルには、DataRobotのモデル、カスタムモデル、外部モデル、チャレンジャーモデル、および自動的に再トレーニングされたモデルをバージョンとして含めることができます。
この変更では、モデルレジストリ > モデルパッケージタブにあるパッケージは登録モデルに変換され、新しい登録済みのモデルタブに移行されます。 移行された各登録モデルには、登録されたモデルバージョンが含まれています。元のパッケージは、新しいタブでは、登録モデル名に追加されたモデルパッケージID(登録されているモデルバージョンID)によって識別できます。
移行が完了すると、変更されたモデルレジストリでは、新しいバージョン管理機能と一元管理で、予測モデルと生成モデルの進化を追跡できます。 さらに、元のモデルと関連するデプロイの両方にアクセスでき、登録したモデル(およびそのモデルに含まれるバージョン)を他のユーザーと共有することができます。
今回の変更は、以前のモデルパッケージワークフローの変更に基づいており、デプロイするモデルを登録する必要があります。 リーダーボードからモデルを登録してデプロイするには、まずモデルの登録情報を提供する必要があります。
-
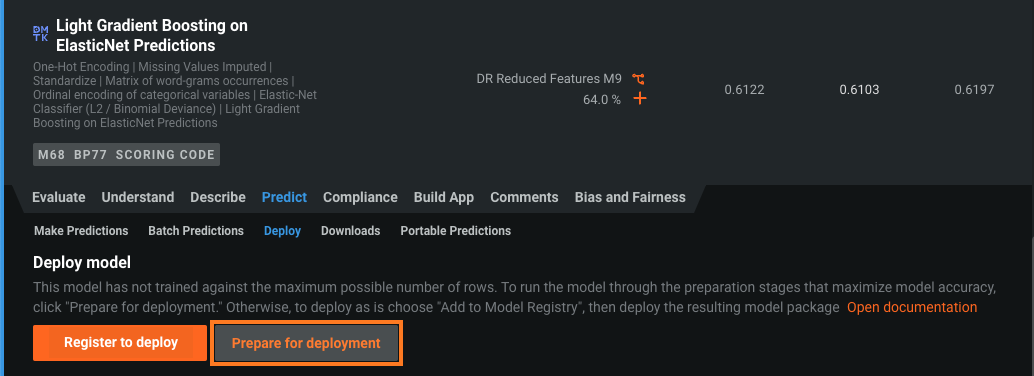
リーダーボードで、予測の生成に使用するモデルを選択します。 デプロイ推奨とデプロイの準備済みのバッジが付いたモデルをお勧めします。 モデル準備プロセスでは、特徴量のインパクトが実行され、特徴量の数を減らした特徴量セットでモデルが再トレーニングされて、より大きなサンプルサイズでトレーニングされた後、サンプル全体(日付/時刻で分割されたプロジェクトの最新データ)でトレーニングされます。

-
予測 > デプロイをクリックします。 リーダーボードモデルにデプロイの準備済みバッジがない場合、デプロイの準備をクリックして、そのモデルに対してモデル準備プロセスを実行することを推奨します。
ヒント
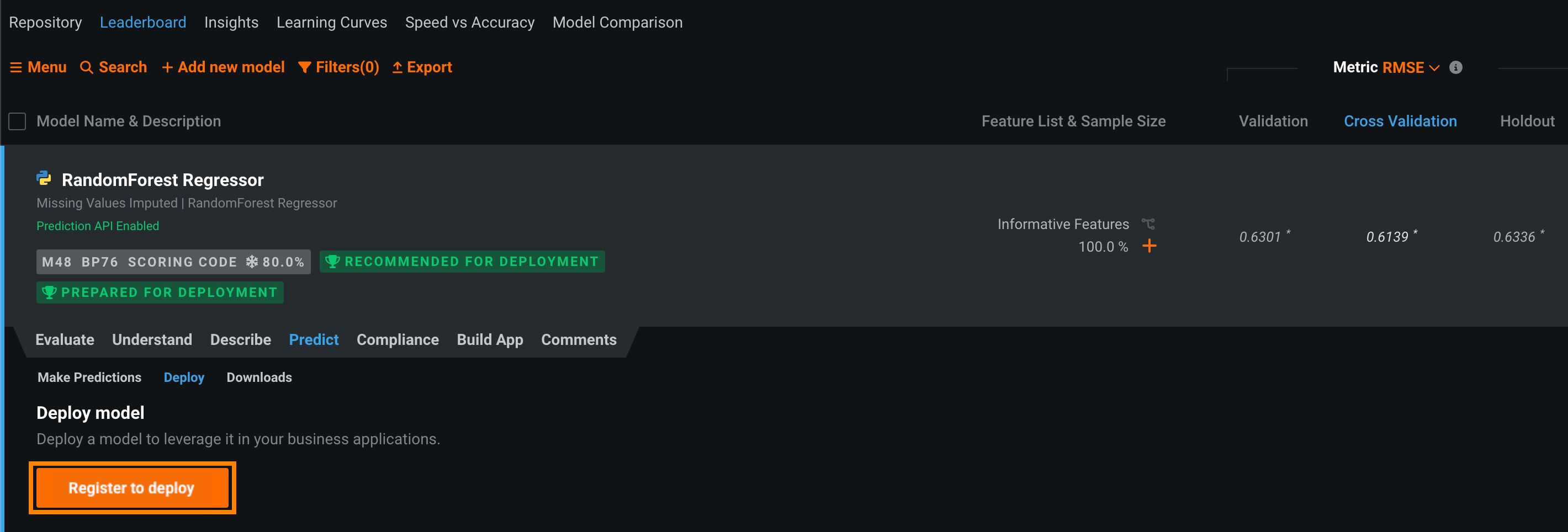
すでにそのモデルをモデルレジストリに追加している場合、登録されているモデルのバージョンがモデルのバージョンリストに表示されます。 モデルの横にあるデプロイをクリックして、このプロセスの残りの部分をスキップできます。
-
モデルをデプロイで、登録してデプロイをクリックします。
-
新規モデルの登録ダイアログボックスで、必要なモデルパッケージのモデル情報を入力します。
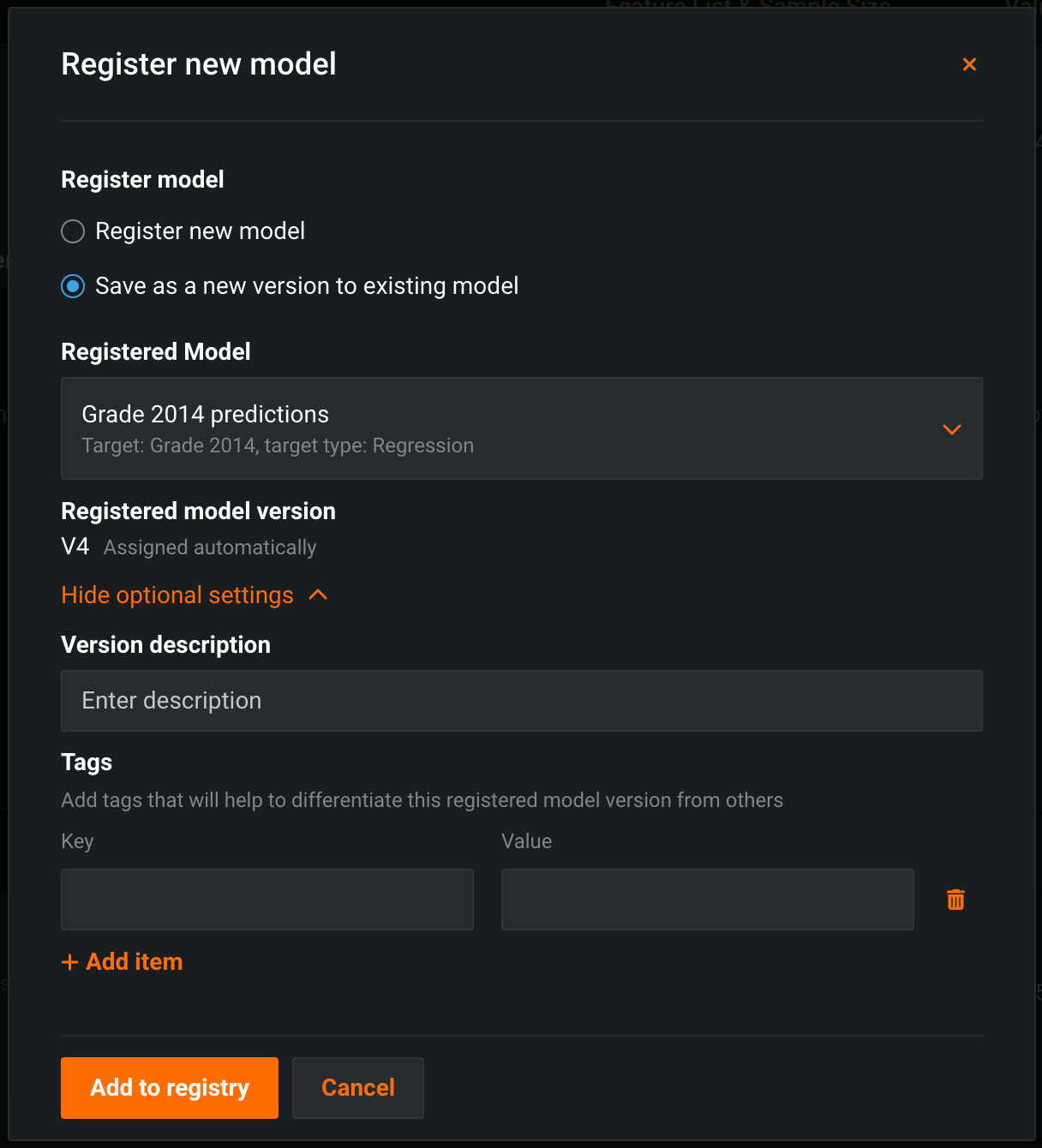
-
レジストリに追加をクリックします。 モデルレジストリ > 登録済みのモデルタブでモデルが開きます。
-
登録モデルの構築中に、デプロイをクリックして、デプロイ設定を行います。
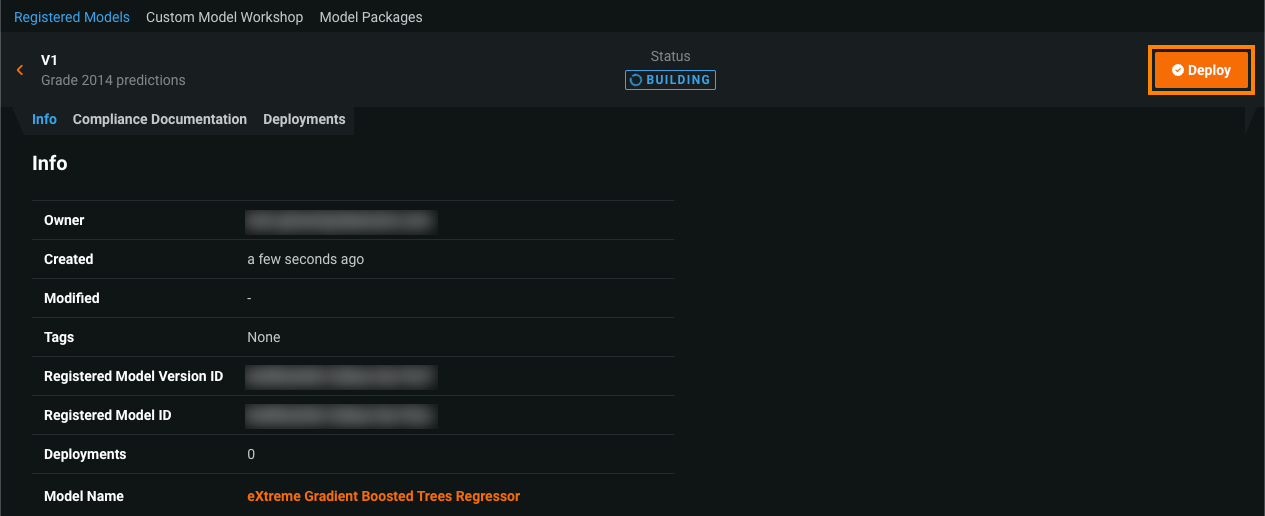
詳しくはドキュメントをご覧ください。
キー値でコンプライアンスドキュメントを拡張する¶
一般提供機能になりました。コンプライアンスドキュメントのテンプレートで参照するキー値を作成できます。 キー値の参照を追加すると、生成されたテンプレートに関連データが含まれるため、コンプライアンスドキュメントを完成させるために必要な手動編集が最小限に抑えられます。 モデルレジストリのモデルに関連付けられたキー値は、登録されたモデルパッケージに関する情報を含むキーと値のペアです。
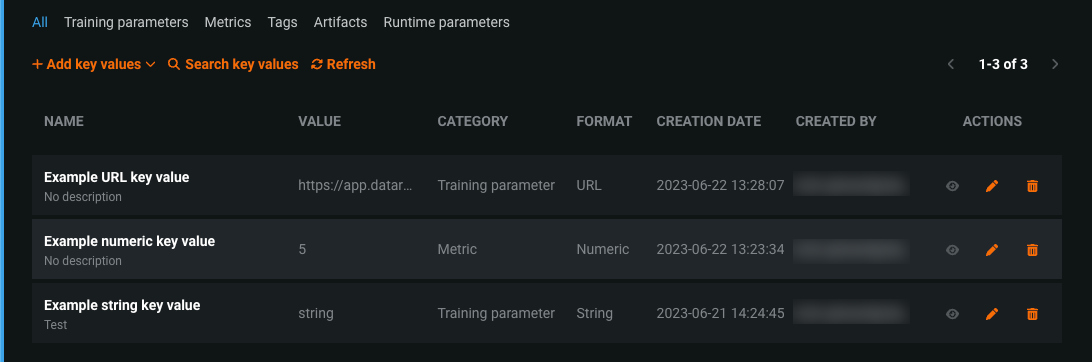
カスタムコンプライアンスドキュメントのテンプレートを作成する際に、文字列、数値、ブール値、画像、データセットのキー値を含めることができます。
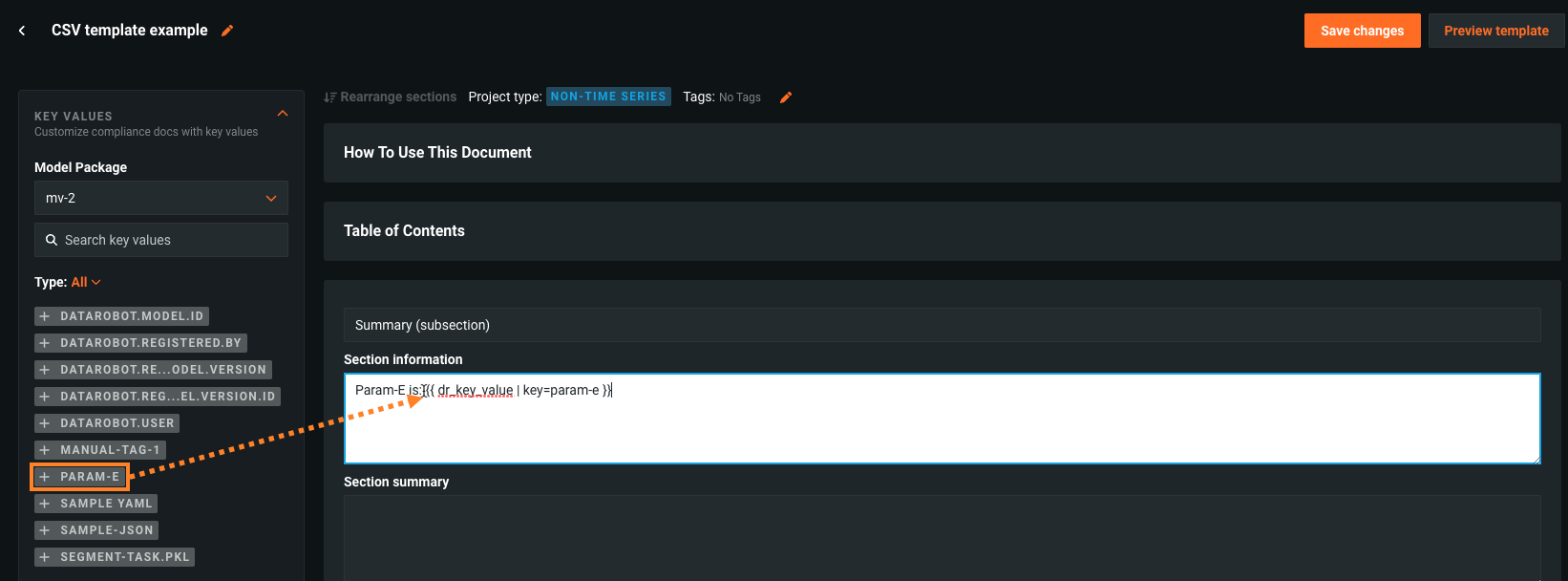
そして、サポートされているキー値を参照するカスタムテンプレートを使用してモデルパッケージのコンプライアンスドキュメントを生成すると、DataRobotは関連するモデルパッケージから一致する値を挿入します。たとえば、キー値に画像が添付されている場合、その画像が挿入されます。
詳しくはドキュメントをご覧ください。
カスタムモデルのパブリックネットワークへのアクセス¶
プレミアム機能として一般提供を開始しました。どのカスタムモデルにも完全なネットワークアクセスを有効にすることができます。 カスタムモデルを作成すると、パブリックネットワーク内の任意の完全修飾ドメイン名(FQDN)にアクセスできるため、サードパーティのサービスをモデルで利用できます。 または、モデルをネットワークから分離し、発信トラフィックをブロックしたい場合は、パブリックネットワークへのアクセスを無効にすると、モデルのセキュリティを強化できます。 カスタムモデルでこのアクセス設定をレビューするには、リソース設定の下のアセンブルタブで、ネットワークアクセスを確認します。
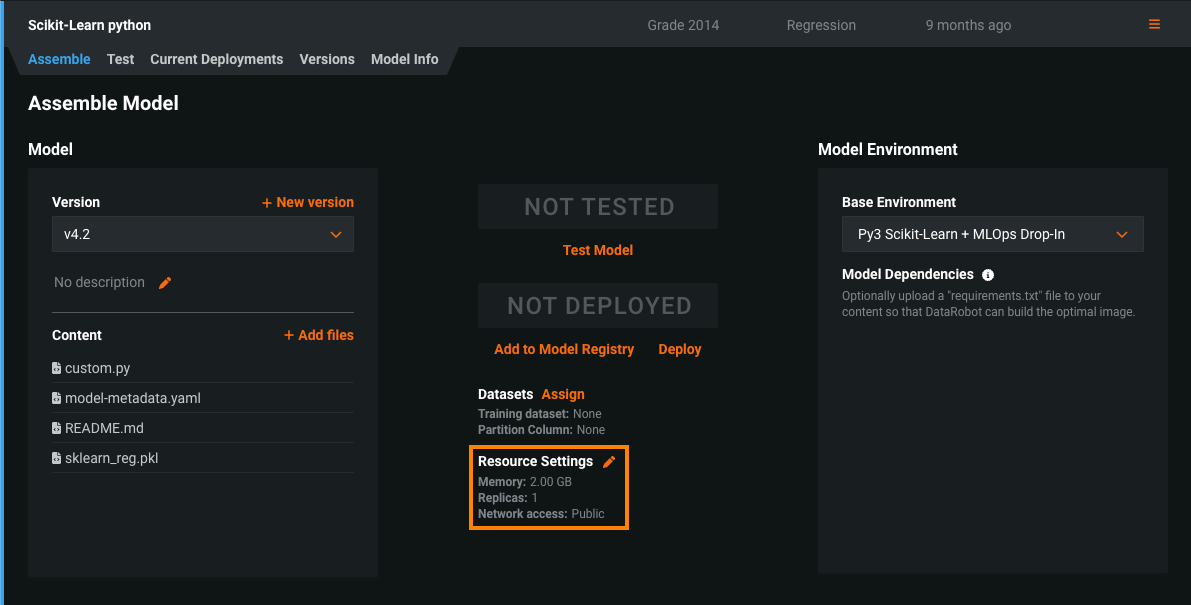
詳しくはドキュメントをご覧ください。
ワークベンチにおけるトレーニングデータでの予測¶
ワークベンチで一般提供機能になりました。エクスペリメントを作成してモデルをトレーニングした後、モデルのアクション > 予測を作成からトレーニングデータで予測を行うことができます。
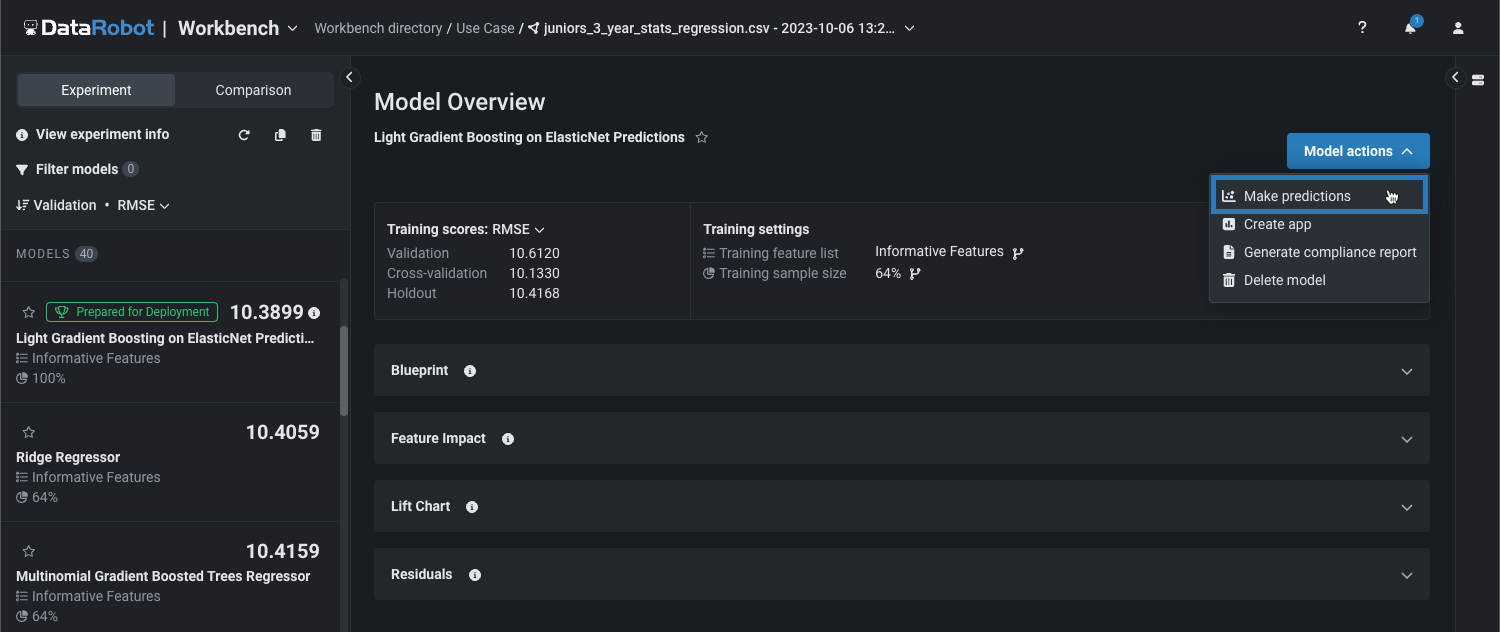
トレーニングデータで予測を行う場合、プロジェクトのタイプに応じて、以下のオプションのいずれかを選択できます。
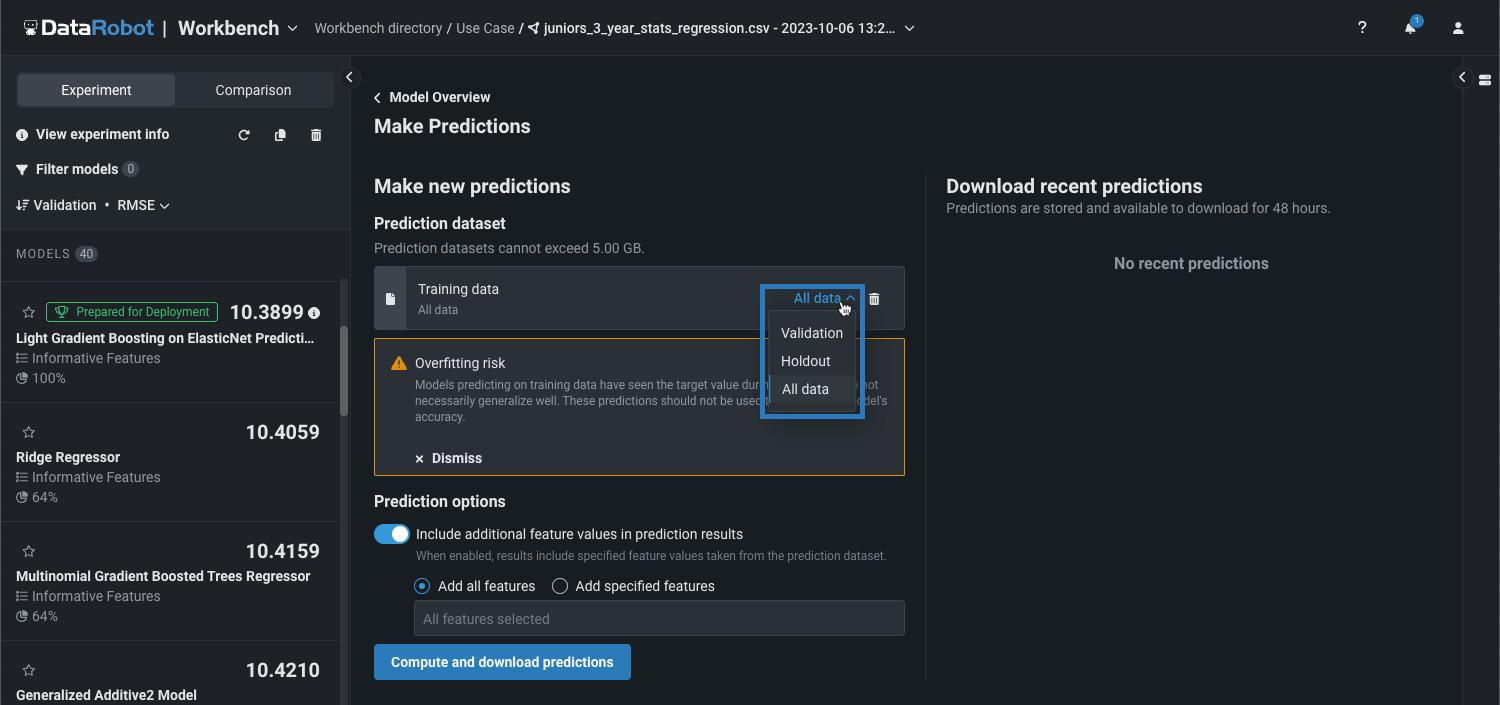
| プロジェクトタイプ | オプション |
|---|---|
| AutoML | 以下のトレーニングデータオプションのいずれかを選択します。
|
| OTV/時系列 | 以下のトレーニングデータオプションのいずれかを選択します。
|
インサンプル予測のリスク
選択したオプションとモデルがトレーニングされたサンプルサイズによっては、トレーニングデータで予測するとインサンプル予測が生成されることがあります。つまり、モデルはトレーニング中にターゲット値が見えており、その予測は必ずしも十分に一般化できるとは限りません。 DataRobotでは、1つ以上のトレーニング行が予測に使用されていると判断された場合、オーバーフィットのリスク警告が表示されます。 これらの予測は、モデルの精度を評価するために使用すべきではありません。
詳しくはドキュメントをご覧ください。
カスタムモデルのデプロイステータス情報¶
一般提供機能になりました。DataRobotでカスタムモデルをデプロイすると、デプロイのステータス情報は、デプロイインベントリの新しいバッジ、デプロイの警告、MLOpsログのイベントに表示されます。
デプロイ情報を追加してカスタムモデルをデプロイすると、デプロイを作成していますモーダルが表示され、デプロイ設定の適用やドリフトベースラインの計算など、デプロイ作成プロセスのステータスを追跡します。 モーダルからデプロイの進捗を監視でき、エラーが発生した場合はデプロイのMLOpsログをチェックするリンクにアクセスすることができます。
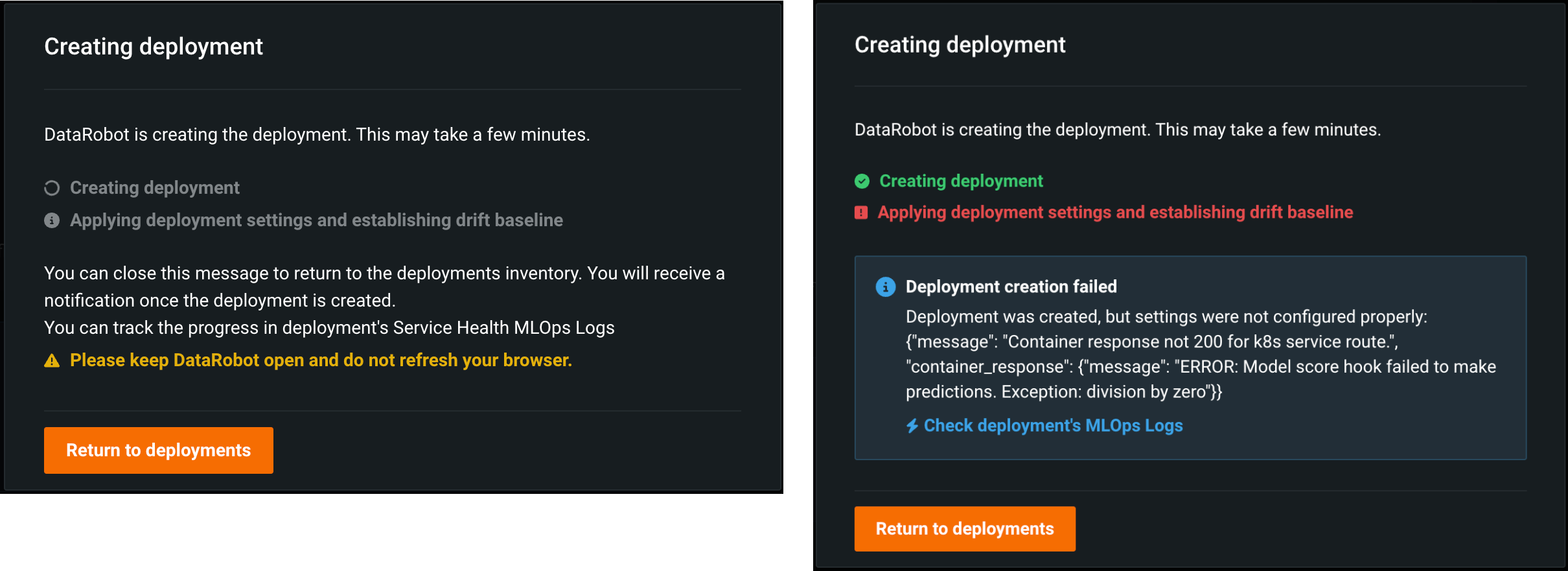
デプロイインベントリでは、デプロイ名列に以下のデプロイステータス値が表示されます。
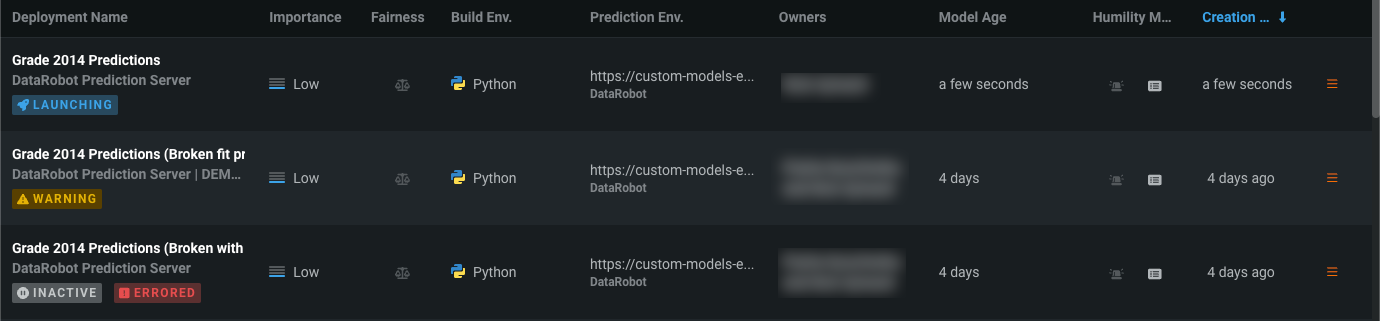
| ステータス | バッジ |
|---|---|
 |
カスタムモデルのデプロイプロセスは、まだ処理中です。 現在、このデプロイを使用して予測を行ったり、アクティブなデプロイを必要とするデプロイタブにアクセスしたりすることはできません。 |
 |
カスタムモデルのデプロイプロセスは、エラーで完了しました。 このデプロイでは予測を行うことができないかもしれません。ただし、このデプロイを非アクティブ化した場合、デプロイエラーを解決するまで再アクティブ化できません。 MLOpsログを確認して、カスタムモデルデプロイのトラブルシューティングを行う必要があります。 |
 |
カスタムモデルのデプロイプロセスは失敗し、デプロイは非アクティブです。 現在、このデプロイを使用して予測を行ったり、アクティブなデプロイを必要とするデプロイタブにアクセスしたりすることはできません。 MLOpsログを確認して、カスタムモデルデプロイのトラブルシューティングを行う必要があります。 |
エラー発生または警告ステータスのデプロイでは、どのタブでもその警告から、サービスの正常性に関するMLOpsログのリンクにアクセスできます。 このリンクをクリックすると、サービスの正常性タブに直接移動します。
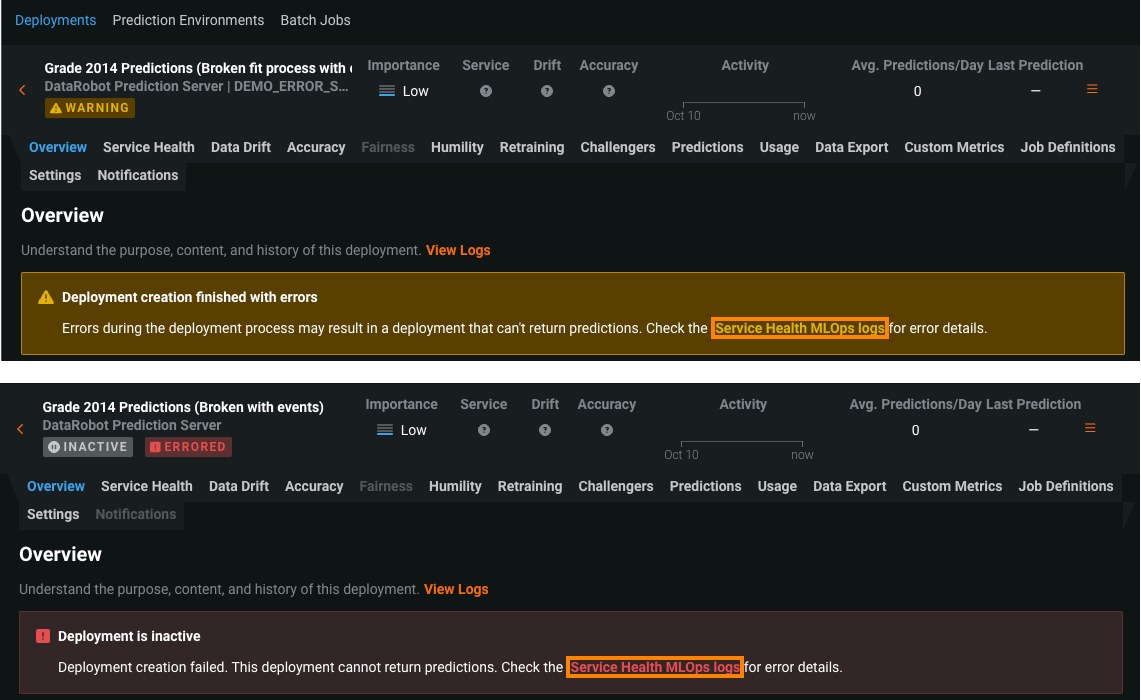
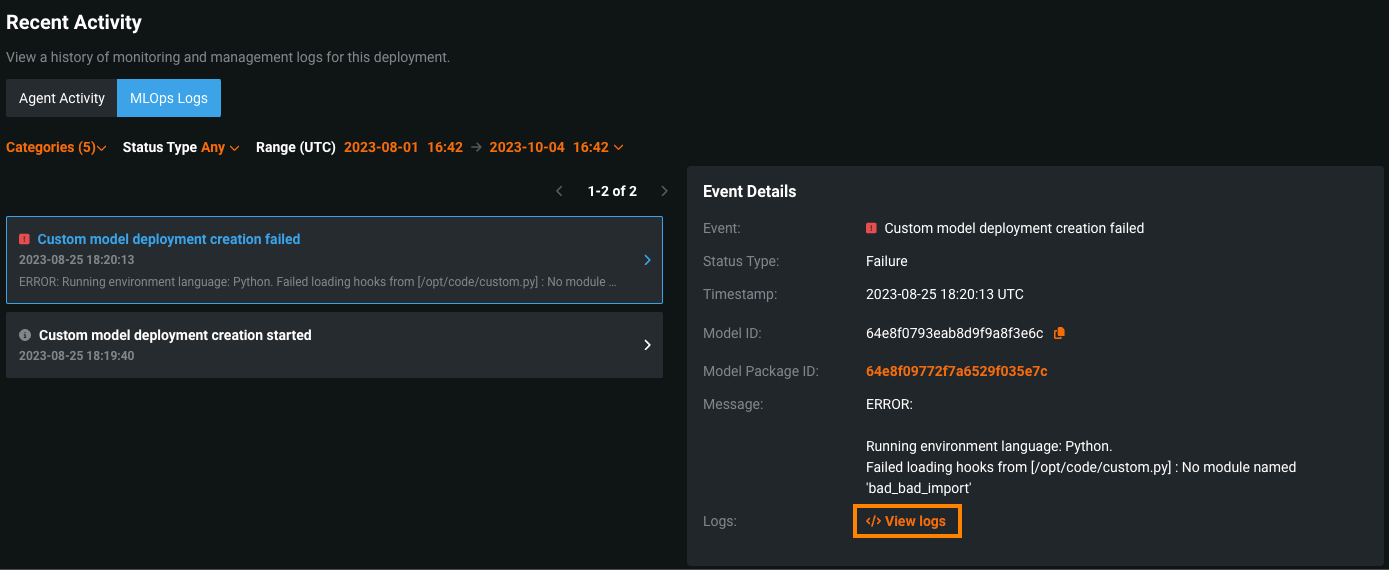
サービスの正常性タブの最近のアクティビティで、MLOpsログタブをクリックすると、イベントの詳細を表示できます。 イベントの詳細では、 "ログを表示"をクリックしてカスタムモデルのデプロイログにアクセスすることで、エラーの原因を診断できます。
クライアント側の集計での自動サンプリング¶
一般提供機能になりました。監視エージェントによる大規模な監視では、元の特徴量、予測値、実測値の自動サンプリングをサポートし、チャレンジャーモデルと精度追跡に対応します。 この機能を有効にするには、大規模監視を設定する際に、MLOPS_STATS_AGGREGATION_AUTO_SAMPLING_PERCENTAGE環境変数を定義し、アルゴリズムによるサンプリングを使ってDataRobotに報告する元データの割合を決定します。 さらに、サンプリングするデータを含む入力データの列を識別するようにMLOPS_ASSOCIATION_ID_COLUMN_NAMEを定義する必要があります。
詳しくはドキュメントをご覧ください。
Apache Airflowの新しい演算子¶
DataRobot MLOpsとApache Airflowの機能を組み合わせることで、モデルの再トレーニングと再デプロイのための信頼性の高いソリューションを実装できます。たとえば、モデルの再トレーニングと再デプロイは、スケジュールに従う、モデルのパフォーマンスが低下したときに行う、新しいデータが存在するときにパイプラインをトリガーするセンサーを使用して行う、のいずれかから選択できます。
Apache AirflowのDataRobotプロバイダーに、新しい演算子が追加されました。
StartAutopilotOperatorDataRobotオートパイロットをトリガーして、モデルのセットをトレーニングします。CreateExecutionEnvironmentOperator実行環境を作成します。CreateCustomInferenceModelOperatorカスタム推論モデルを作成します。GetDeploymentModelOperatorデプロイの現在のモデルに関する情報を取得します。
新しい演算子の詳細については、ドキュメントを参照してください。
バッチ予測でのDatabricks JDBCへの書き戻しをサポート¶
このリリースから、バッチ予測のJDBCデータソースとして、Databricksがサポートされるようになりました。 バッチ予測でサポートされているデータソースの詳細については、ドキュメントを参照してください。
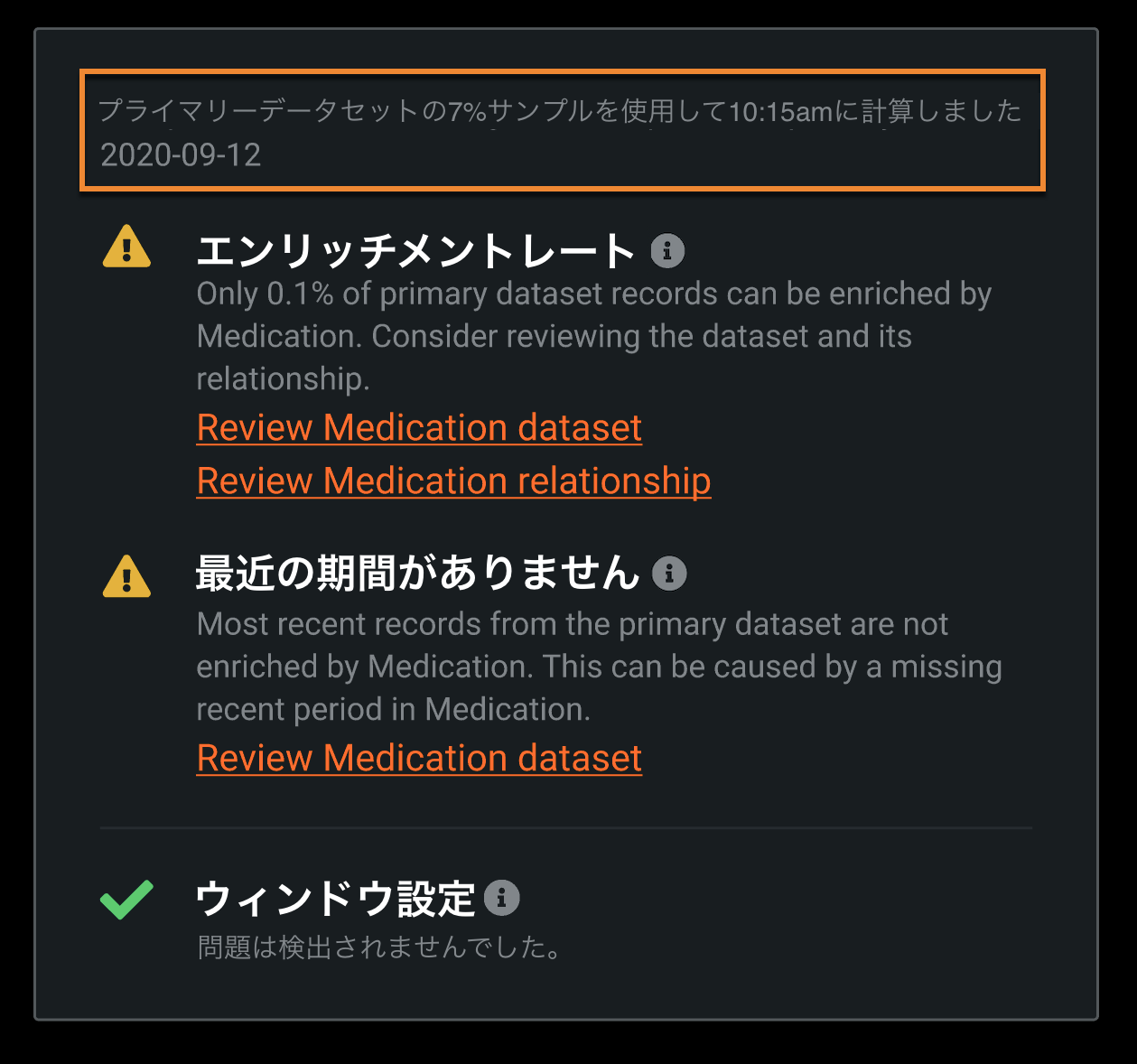
関係性の品質評価を高速化¶
SaaS版で一般提供機能になりました。関係性の品質評価の実行時間を短縮するため、DataRobotはプライマリーデータセットの約10%をサブサンプリングし、エンリッチメントレートの推定精度や評価結果に影響を与えることなく、計算を高速化しました。 評価が終了すると、サンプリングの割合がレポートの上部に表示されます。
Snowflakeのキーペア認証¶
一般提供機能になりました。Basic認証やOAuth認証の代わりに、キーペア認証方式(Snowflakeのユーザー名と秘密キー)を使用して、DataRobot ClassicとワークベンチでSnowflakeデータ接続を作成します。 キーペア認証では、セキュアな構成の共有も可能です。
ワークベンチでの新しいアプリ体験¶
一般提供機能になりました。DataRobotは、新たにワークベンチに効率的なアプリケーションエクスペリエンスを導入しました。貴重な情報のスナップショットを簡単に表示、探索、作成できるユニークな機能を利用できます。 このリリースには、以下の改善が実施されています。
- アプリケーションのインターフェイスと作成ワークフローがシンプルになり、より直感的に操作できるようになりました。
- アプリケーションの作成では、アプリケーションを支えるモデルに基づいて、特徴量のインパクトやROC曲線などのインサイトが自動的に生成されます。
- ワークベンチのエクスペリメントから作成されたアプリケーションは、ワークベンチのアプリケーションビルダー以外では開かれなくなりました。
プレビュー¶
GPUの改善によりディープラーニングモデルのトレーニングを強化¶
今回のデプロイでは、プレビュー版のGPU機能が以下のように強化されました。
-
GPUトレーニング用のブループリントが追加され、MiniLM、RoBERTa、TinyBERTの各フィーチャライザーが利用可能になりました。
-
プロジェクトに応じて:
- クイックオートパイロットの実行中に、Keras Text Convolutional Neural Networkブループリントをトレーニングできます。
- フルオートパイロットの実行中に、Image Finetunerブループリントをトレーニングできます。
-
GPUとCPUのバリアントがリポジトリで利用可能になり、どのワーカータイプでトレーニングするかを選択できるようになりました。
-
GPUバリアントブループリントは、GPUワーカーでより高速にトレーニングできるように最適化されています。
プレビュー機能のドキュメントをご覧ください
デフォルトではオフの機能フラグ:GPUワーカーを有効にする
SHAPベースの予測の説明をワークベンチに追加¶
SHAPベースの予測の説明では、各特徴量が特定の予測にどの程度寄与するかを推定し、平均値との差として報告します。 これらは直感的で、制限がなく(すべての機能について計算されます)、高速で、SHAPのオープンソースの性質上、透過的です。 このデプロイにより、ワークベンチにおいて、SHAPベースの説明が時系列以外のすべてのエクスペリメントでサポートされるようになりました。 モデル概要タブからアクセスできる、SHAPベースの説明には、モデルパフォーマンスに対する全般的な「直観」のプレビューが表示され、データセット全体についての説明を参照するためのオプションも用意されています。
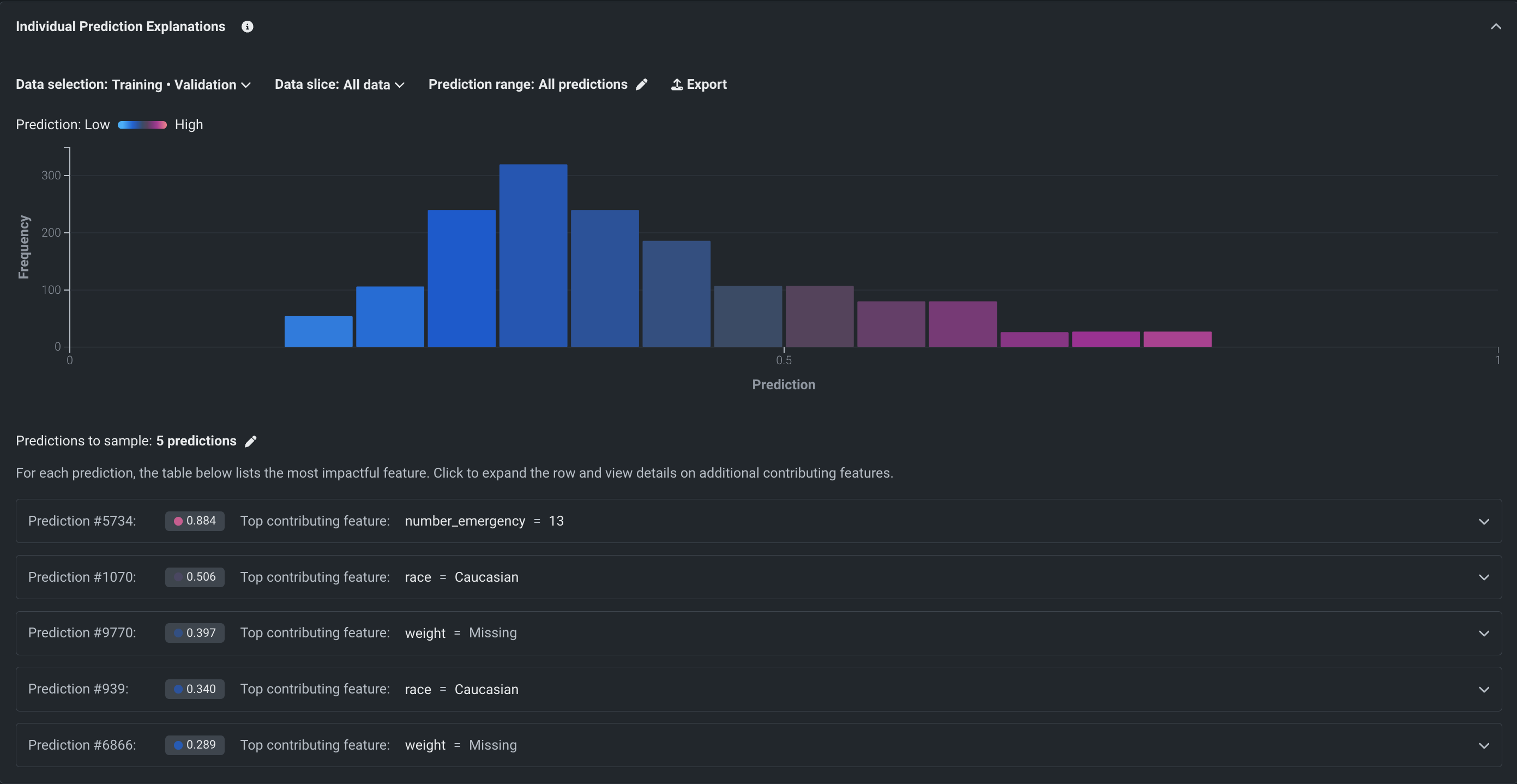
プレビュー機能のドキュメントをご覧ください
デフォルトではオンの機能フラグ:ワークベンチでSHAPを有効にする
Azure Databricksのより幅広いサポートをワークベンチに追加¶
プレビュー版の機能です。Azure Databricksに対する以下のサポートが、ワークベンチに追加されました。
- 接続を介して追加されたデータは、動的データセットとして追加される。
- Azure Databricksのソースデータから直接サンプリングしたライブプレビューでデータを表示する。
- Azure Databricksのデータセットに対してラングリングを実行する。
- Azure Databricksと同様に、データレジストリでパブリッシュされたラングリングレシピをマテリアライズする。
プレビュー機能のドキュメントをご覧ください。
機能フラグ:
- Databricksドライバーを有効にする
- Databricksのラングリングを有効にする
- ワークベンチでDatabricksのソース内マテリアライズを有効にする
- ワークベンチで動的データセットを有効にする
AWS S3との接続の強化¶
新しいAWS S3コネクターがプレビュー版で利用可能になりました。パフォーマンスが強化され、一時的な資格情報やParquetファイルの取込みにも対応しています。
プレビュー機能のドキュメントをご覧ください。
機能フラグ:S3コネクターを有効にする
デプロイ予測のバッチ監視¶
プレビュー版の機能です。時間単位ではなくバッチ単位で整理された監視統計を表示できます。 バッチ対応のデプロイでは、予測 > バッチ管理タブにアクセスし、バッチの作成と管理を行うことができます。 その後、これらのバッチに予測を追加し、デプロイ内のバッチごとにサービスの正常性、データドリフト、精度、カスタム指標の統計情報を表示できます。 バッチを作成して、バッチに予測を割り当てるには、UIまたはAPIを使用します。 さらに、バッチ予測またはスケジュールされたバッチ予測ジョブが実行されるたびに、バッチが自動的に作成され、バッチ予測ジョブからのすべての予測がそのバッチに追加されます。
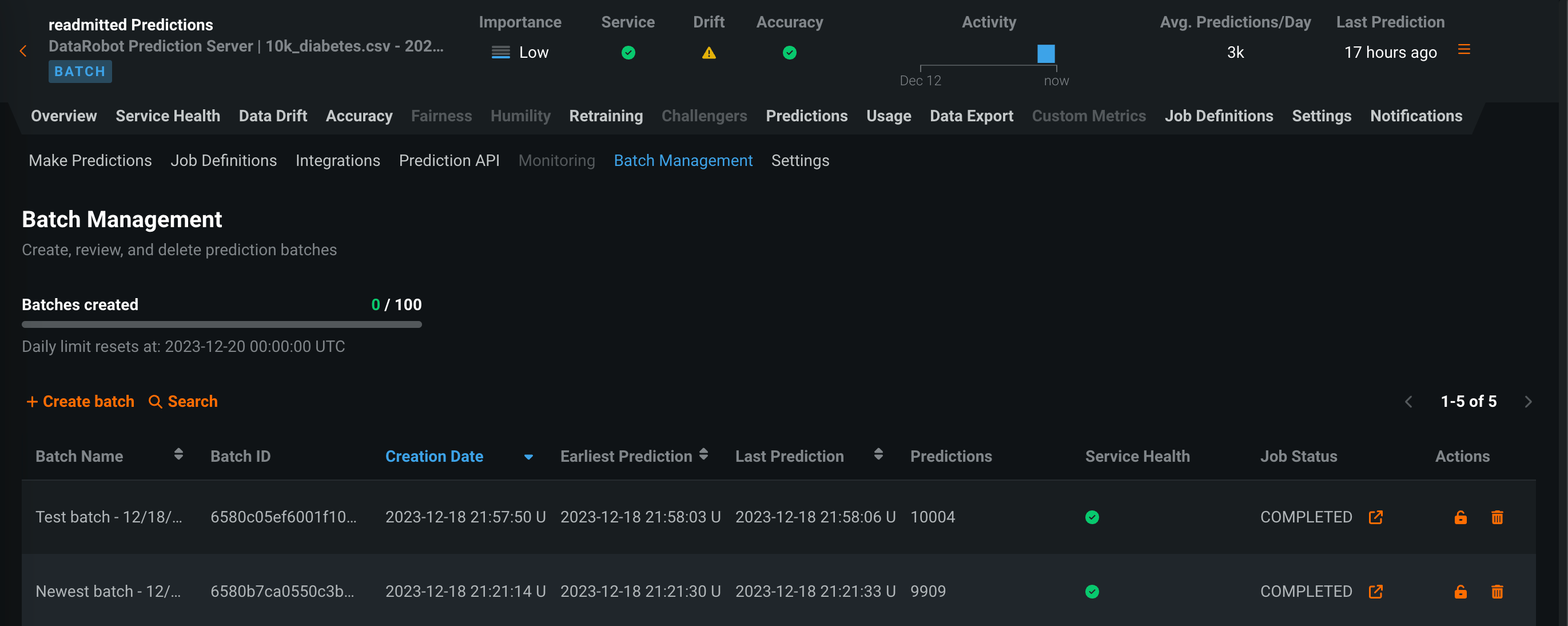
デフォルトではオフの機能フラグ:デプロイのバッチ監視を有効にする、デプロイのバッチカスタム指標を有効にする
プレビュー機能のドキュメントをご覧ください。
集計を有効にした監視ジョブの精度¶
プレビュー版の機能です。集計を有効にした外部モデルの監視ジョブは、精度の追跡に対応できます。 集計を使用するを有効にし、保持設定を行って、データがMLOpsライブラリによって集計されることを示し、チャレンジャーモデルと精度分析のために保持すべき元データの量を定義します。その後、精度監視のために実測値列をレポートするには、予測列と関連付けID列を定義します。
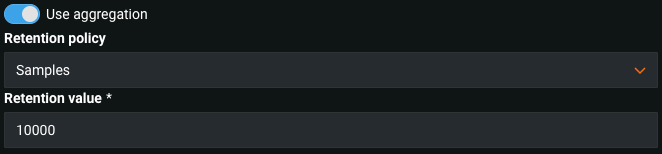
デフォルトではオフの機能フラグ:精度の集計を有効にする
詳しくはドキュメントをご覧ください。
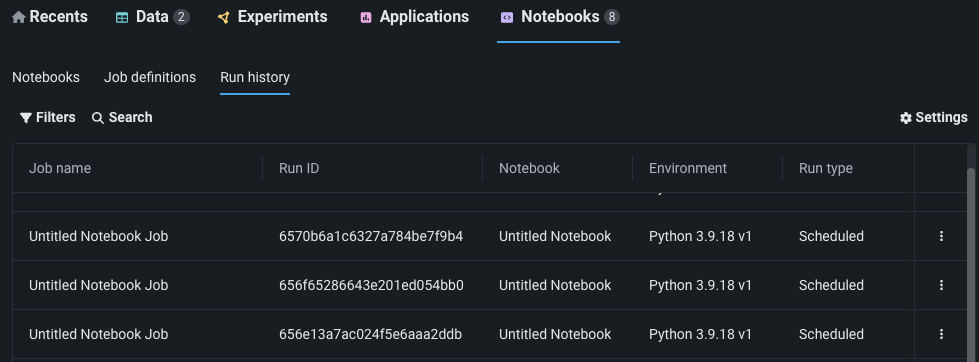
ノートブックジョブのスケジュール¶
プレビュー版の機能です。ノートブックを非対話モードでスケジュールどおりに実行することで、コードベースのワークフローを自動化できます。 ノートブックのスケジューリングは、DataRobot Notebooksインターフェイスから直接作成できるノートブックジョブによって管理されます。 さらに、ノートブックジョブをパラメーター化することで、ノートブックのスケジューリングによって可能になる自動化を強化できます。 ノートブック内の特定の値をパラメーターとして定義することで、実行ごとに値を変更するためにノートブック自体を継続的に修正する必要がなく、ノートブックジョブの実行時にこれらのパラメーターに入力を提供できます。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:Notebooksのスケジューリングを有効にする
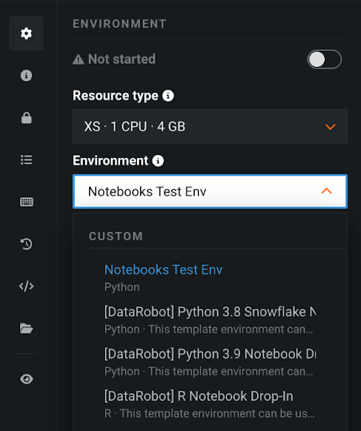
DataRobot Notebooksのカスタム環境イメージ¶
プレビュー版の機能です。DataRobot Notebooksと、ノートブックセッションの実行に使用される再利用可能なカスタムDockerイメージを定義するDataRobotカスタム環境を連携できます。 ノートブックセッションで使用するカスタム環境を作成することで、環境を完全に制御したり、ビルトインイメージで利用可能なもの以外にも再現可能な依存関係を活用したりすることができます。 互換性のあるカスタム環境は、ノートブックインターフェイスから直接選択できます。 DataRobot NotebooksはPythonとRのカスタム環境をサポートしています。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:Notebooksでカスタム環境を有効にする
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。