2022年7月¶
2022年7月27日
今回のデプロイにより、DataRobotのマネージドAIプラットフォームには、以下の一般提供およびプレビューの新機能が提供されました。 過去の新機能のお知らせについては、デプロイ履歴をご覧ください。 こちらもご覧ください。
目的別にグループ化された機能
目的別にグループ化された機能
一般提供¶
オートパイロットでのネイティブProphetおよび系列パフォーマンスブループリント¶
単一および複数系列の時系列プロジェクトでのネイティブProphet、ETS、TBATSモデルのサポートについては、6月のリリースで一般提供を発表しました。 (モデルの詳細な説明は、モデルのブループリントにアクセスすることで、モデルごとに確認できます。) このリリースでは、これらのモデルがクイックオートパイロットの一部として実行されないように若干の変更が加えられています。 DataRobotは、フルオートパイロットで適宜それらを実行しますが、モデルリポジトリから入手することもできます。
Text AIのパラメーターをComposable MLで一般提供¶
特定のText AI前処理タスク(レンマ化、品詞タグ付け、ステミング)を変更する機能が、[高度なチューニング]タブからComposable MLでアクセス可能なブループリントタスクに移動しました。 Text AIの新しい前処理タスクは、独自のテキストブループリントを作成するための新たな経路を提供します。 たとえば、TF-IDFブループリントに限定されることなく、その前処理タスクをサポートするあらゆるテキストモデルで見出し語認定を使用できるようになりました。 以前はプレビュー機能として提供されていましたが、これらのタスクは機能フラグなしで利用できるようになりました。
Composable MLのタスクカテゴリーを改善¶
このリリースでは、Composable MLとブループリント編集の広範な導入とお客様のご意見をもとに、タスクの分類に改善を加えました。 たとえば、ブースティングタスクが、特定のプロジェクト/モデルタイプで使用できるようになりました。
言語サポートを強化したNLPオートパイロットを一般提供¶
自然言語処理(NLP)に対して実施した多くの改善が一般提供されました。 その中で最も重要な改善点は、データ取込み時の言語検出にFastTextが適用されたことです。それにより、以下のことが実現しました。
-
DataRobotは、その言語用に最適化されたパラメーターで、適切なブループリントを生成できます。
-
検出された言語にトークン化を適応させることで、ワードクラウドと解釈性が向上します。
-
特定のブループリントトレーニングヒューリスティックをトリガーし、精度を最適化した高度なチューニング設定が適用されるようにします。
この機能は、多言語のユースケースでも有効です。オートパイロットは複数の言語を検出し、ブループリントの各種設定を調整して、最高の精度を実現します。
また、以下のNLPの機能強化も一般提供されました。
-
新しい事前学習済みBPEトークナイザー(任意の言語を処理できます)
-
NLPのためのKerasブループリントを改良し、精度とトレーニング時間を改善しました。
-
他のNLPブループリントでもさまざまな改善を行いました。
-
新しいKerasブループリント(BPEトークナイザー付き)をリポジトリに追加しました。
AIアプリのヘッダーを改善¶
このリリースでは、AIアプリのレイアウトとヘッダーを改善しました。 以下のタブを切り替えると、アプリケーションの使用および編集時のUIに加えられた改善点を確認できます。
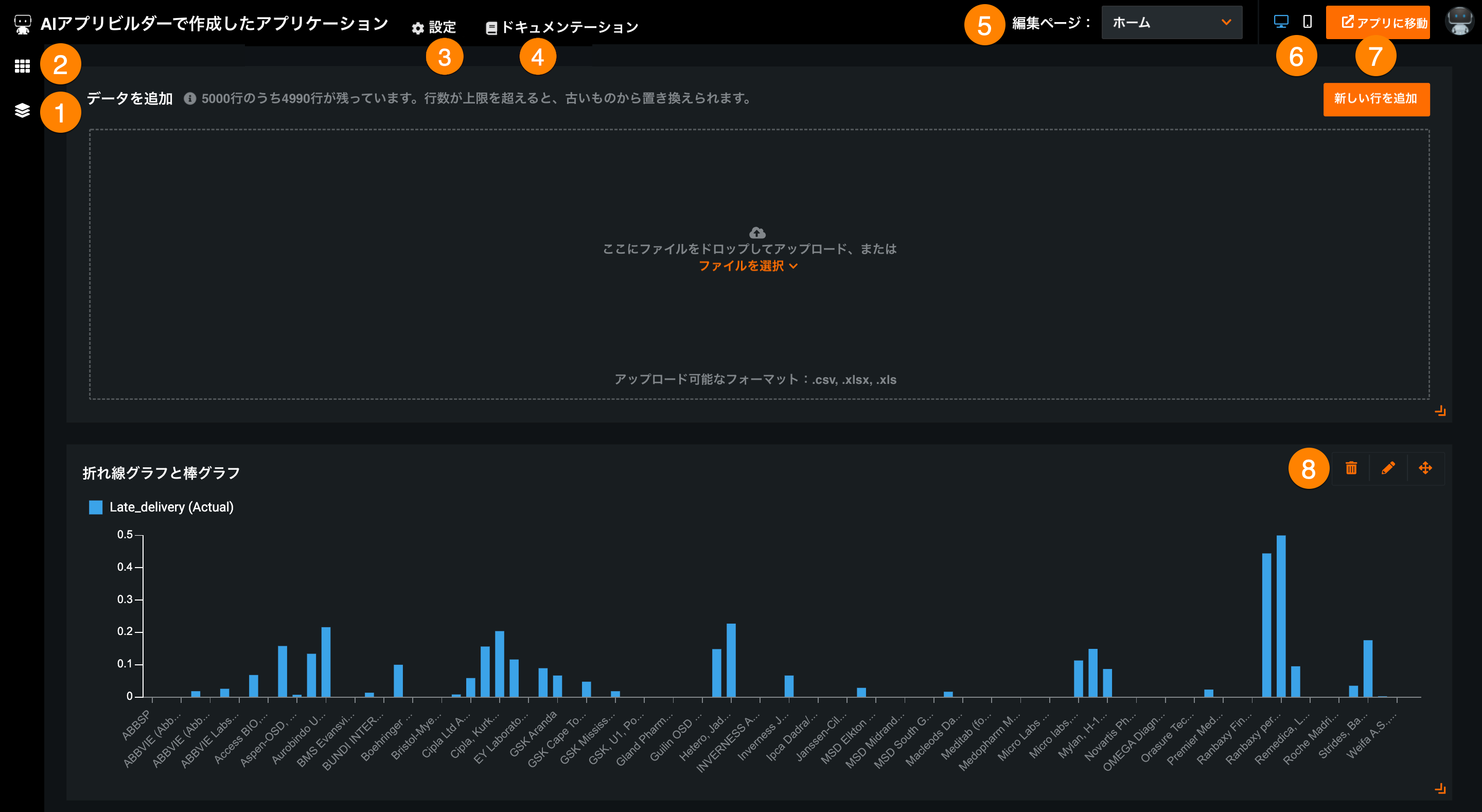
| 要素 | 説明 | |
|---|---|---|
| 1 | ページパネル | アプリケーションページの名前変更、並び替え、追加、非表示、削除が可能です。 |
| 2 | ウィジェットパネル | アプリケーションにウィジェットを追加することができます。 |
| 3 | 設定 | 一般的な設定と権限を変更し、アプリの使用状況を表示します。 |
| 4 | ドキュメンテーション | DataRobotのAIアプリケーションに関するドキュメントを開きます。 |
| 5 | 編集ページのドロップダウン | 現在編集中のアプリケーションページを制御します。 別のページを表示するには、ドロップダウンをクリックして、編集したいページを選択します。 ページを管理をクリックすると、ページパネルが表示されます。 |
| 6 | プレビュー | さまざまなデバイスでアプリケーションをプレビューします。 |
| 7 | アプリに移動 / 公開 | エンドユーザーアプリケーションを開き、新しい予測をしたり、予測結果やウィジェットの視覚化を表示したりできます。 アプリケーションの編集後、このボタンに公開と表示されるので、これをクリックして変更を適用する必要があります。 |
| 8 | ウィジェット操作 | ウィジェットの移動、非表示、編集、削除を行います。 |
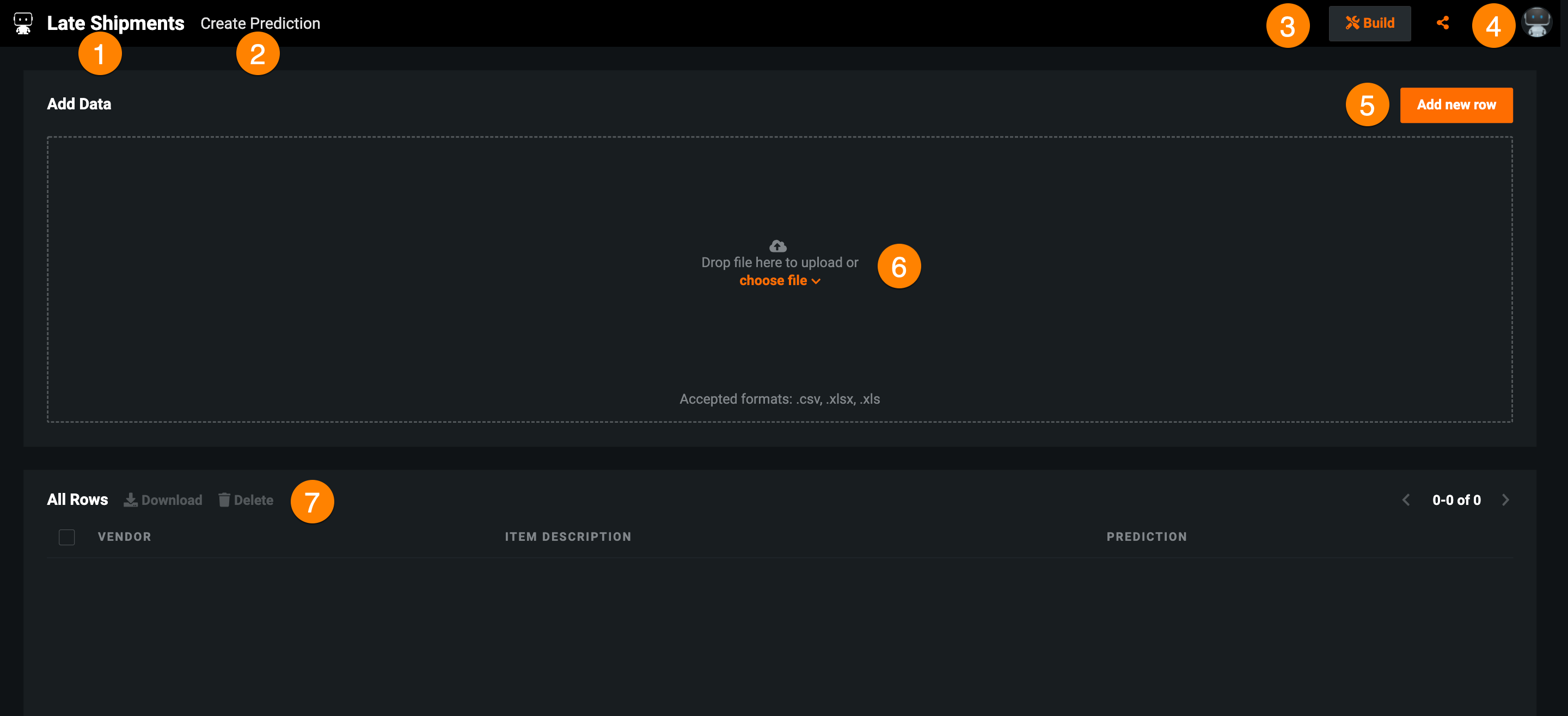
| ウィジェット | 説明 | |
|---|---|---|
| 1 | アプリケーション名 | アプリケーション名を表示します。 クリックすると、アプリのホームページに戻ります。 |
| 2 | ページ | アプリケーションのページを移動します。 |
| 3 | 構築 | アプリケーションを編集できます。 |
| 4 | 共有 | DataRobot内のユーザー、グループ、または組織とアプリケーションを共有します。 |
| 5 | 新しい行を追加 | 予測の作成ページが開き、単一レコードの予測を行うことができます。 |
| 6 | データを追加 | AIカタログまたはローカルファイルからバッチ予測をアップロードします。 |
| 7 | すべての行 | 予測の履歴を表示します。 行を選択すると、そのエントリーの予測結果が表示されます。 |
セグメントモデリングで新たに手動モードをサポート¶
このリリースから、セグメントモデリングで手動モードが使用できるようになりました。 これまでは、クイックまたはフルオートパイロットを選択することができました。 手動モードでセグメントモデリングを行う場合、DataRobotは、セグメントごとに個別のプロジェクトを作成し、モデリング段階まで準備を完了させます。 ただし、DataRobotはプロジェクト単位のモデルを作成しません。 統合されたモデルを(プレースホルダーとして)作成しますが、チャンピオンは選択しません。 手動モードを使用することで、モデル構築に時間をかけることなく、各セグメントでどのモデルをトレーニングし、チャンピオンとして選択するかを完全に手動でコントロールできます。
時系列プロジェクトのスコアリングコード¶
一般提供機能になりました。Javaベースのスコアリングコードパッケージで時系列モデルをエクスポートすることができます。 スコアリングコードは、DataRobotアプリケーションの外でDataRobotモデルを利用するための、ポータブルかつ低レイテンシーな手法です。
モデルの時系列スコアリングコードは、以下の場所からダウンロードすることができます。
-
リーダーボードからダウンロード(リーダーボード > 予測 > ポータブル予測)
-
デプロイからダウンロード(デプロイ > 予測 > ポータブル予測)
セグメントモデリングでは、複数系列プロジェクトのセグメントに対して個別のモデルを構築することができます。 そして、DataRobotはこれらのモデルを統合し、統合モデルを作成します。 完成した統合モデルのスコアリングコードを生成することができます。
スコアリングコードを生成してダウンロードするには、統合モデルの各セグメントチャンピオンにスコアリングコードが必要です。
統合されたモデルの各セグメントチャンピオンにスコアリングコードがあることを確認したら、リーダーボードからスコアリングコードをダウンロードできますが、統合モデルをデプロイしてデプロイからスコアリングコードをダウンロードすることも可能です。
時系列モデルでは、ダウンロードするスコアリングコードJARに予測間隔を含めることができるようになりました。 予測間隔を含むスコアリングコードは、リーダーボードからまたはデプロイからダウンロードできます。
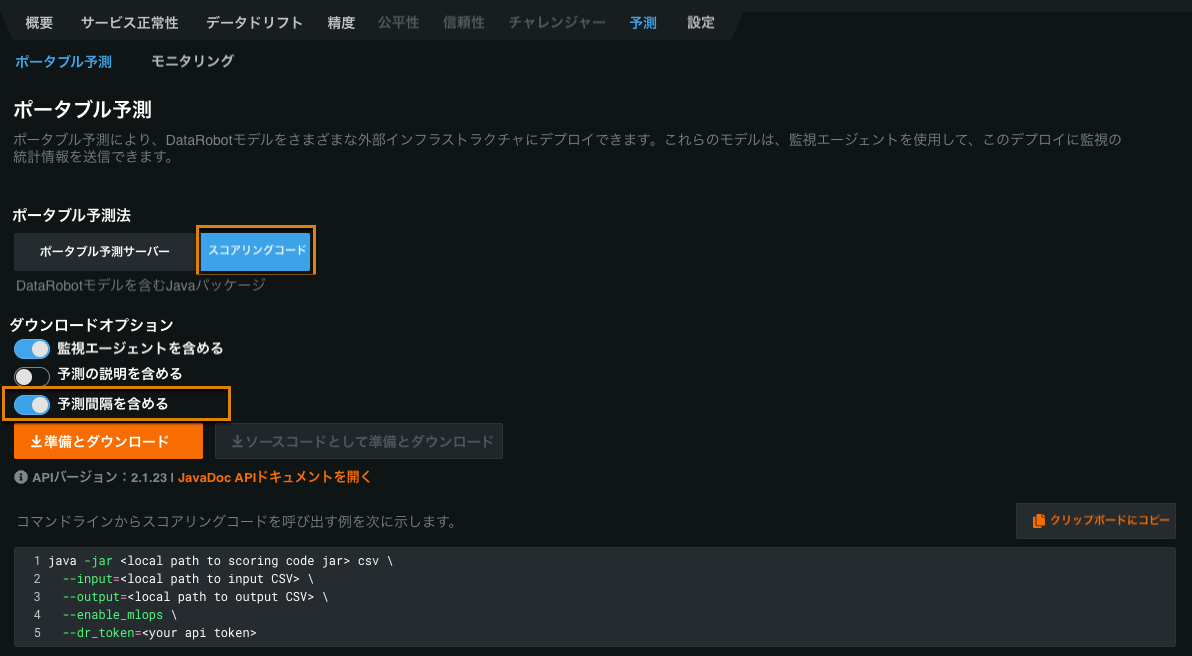
ダウンロードした時系列スコアリングコードを用いて、コマンドラインからデータのスコアリングを行うことができます。 このリリースから、時系列のスコアリングコードに効率的なバッチ処理が導入され、より大規模なデータセットのスコアリングが可能になりました。 詳細については、CLIでのスコアリングのための時系列パラメーターのドキュメントを参照してください。
時系列のスコアリングコードの詳細については、時系列プロジェクトのスコアリングコードを参照してください。
プレビュー¶
時系列プロジェクトとその設定の複製¶
プレビュー版の機能です。時系列、OTV、セグメントモデリングなどの教師なしプロジェクトや時間認識プロジェクトを含め、あらゆる種類のDataRobotプロジェクトを複製(「クローンを作成」)することが可能です。 以前は、この機能はAutoMLプロジェクト(時間を認識しない連続値と分類)でしか利用できませんでした。
プロジェクトの複製には、データセットのみを選択するオプション(データセットを再アップロードするよりも高速)と、データセットとプロジェクトの設定を選択するオプションがあります。 時間認識プロジェクトの複製では、ターゲット、特徴量派生と予測ウィンドウの値、選択されたカレンダー、事前に既知の特徴量、系列IDなど、すべての時系列設定のクローンが作成されます。 データ準備ツールを使って不規則なタイムステップの問題に対処した場合、クローン作成では修正されたデータセット(親プロジェクトでモデル構築に使用されたもの)が使用されます。複製オプションには、プロジェクトのドロップダウン(右上隅)またはプロジェクトの管理ページからアクセスできます。
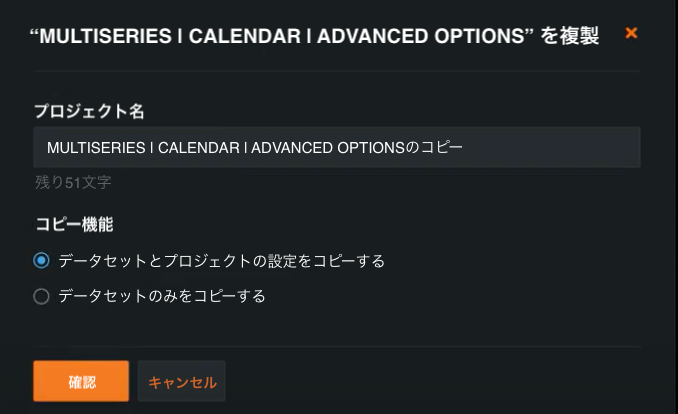
必要な機能フラグ:プロジェクト設定を含めて時間認識プロジェクトと教師なしプロジェクトのクローンを作成できるようにする
AIアプリでの多クラスのサポート¶
AIアプリは、二値分類と連続値問題に加えて、多クラス分類のデプロイを3つのテンプレート(予測実行、最適化、What-If)すべてでサポートするようになりました。 これにより、複数の業界にまたがる広範なビジネス課題に対してAIアプリを活用できるようになり、そのメリットと価値が拡大しました。
必要な機能フラグ:アプリケーションビルダーの多クラスサポートを有効にする
時系列の予測実行アプリケーションに詳細ページを追加¶
時系列の予測実行AIアプリでは、特定の予測や日付に絞って予測情報を表示できるようになり、予測値を見るだけでなく、同じ日付に行われた他の予測との比較も可能になりました。 これまでは、予測値、残差、実測値と、上位3つの予測の説明のみ表示可能でした。
予測の詳細を見るには、予測値対実測値または予測の説明チャートで予測をクリックします。 これにより、予測の詳細ページが開き、以下の情報が表示されます。
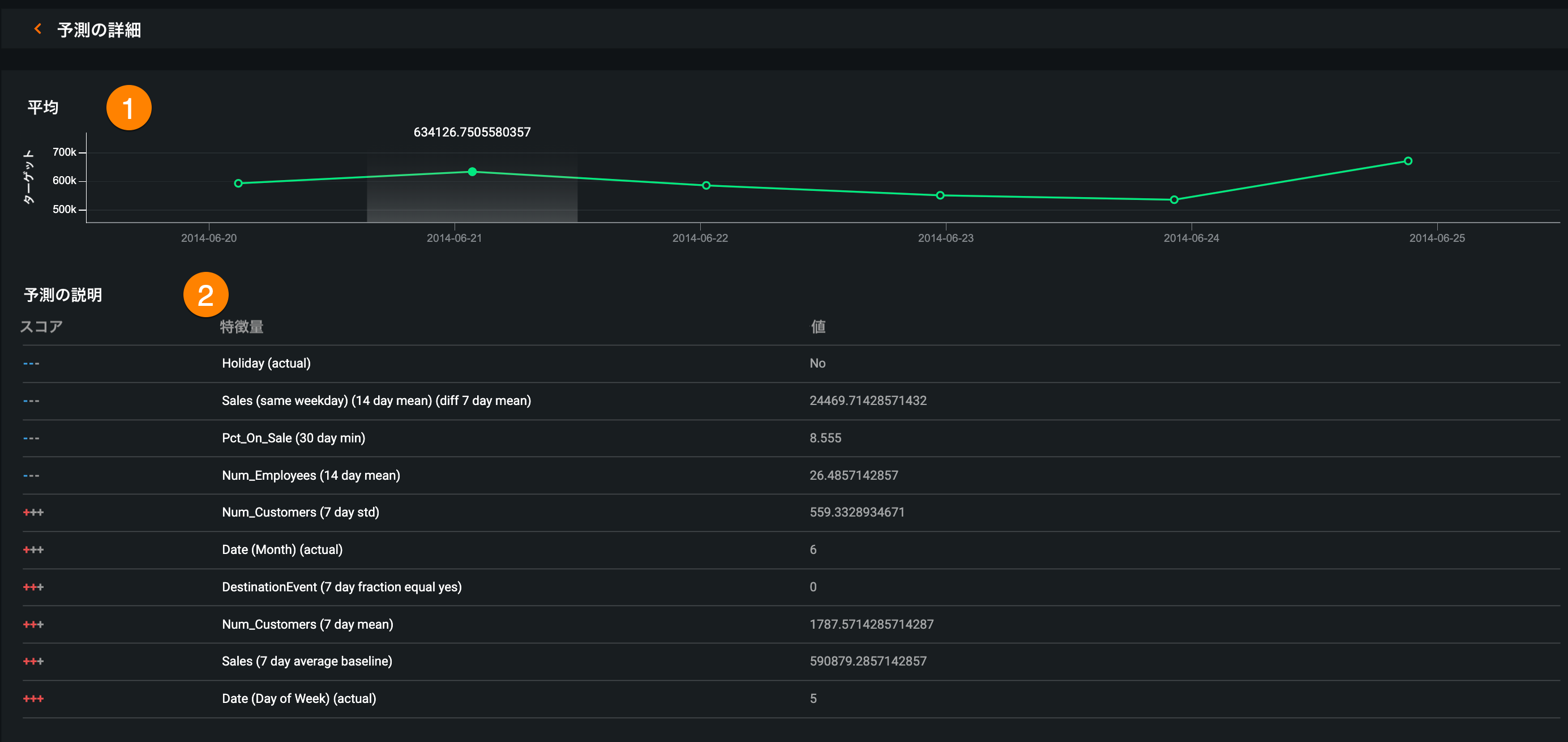
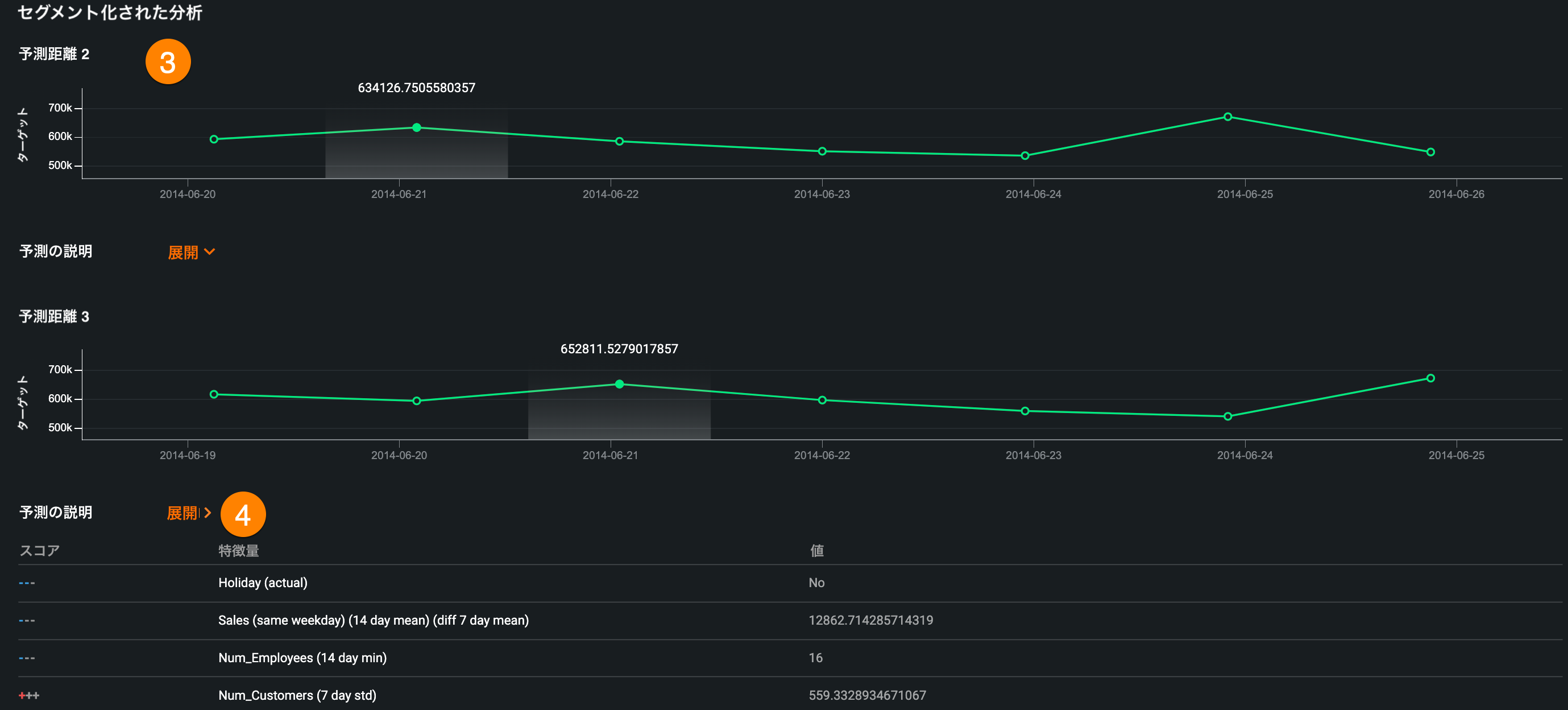
| 説明 | |
|---|---|
| 1 | 予測ウィンドウ内の平均予測値 |
| 2 | 各予測に対して最大10個の予測説明 |
| 3 | 予測ウィンドウ内の予測距離ごとのセグメント分析 |
| 4 | セグメント分析に含まれる、予測距離ごとの予測の説明 |
必要な機能フラグ:アプリケーションビルダーの時系列予測の詳細ページを有効にする
プレビュー機能のドキュメントをご覧ください。
テキスト予測においてn-gramレベルでのインパクトを説明¶
テキスト予測の説明を使用すると、テキスト特徴量内の個々の単語 (n-gram) が予測にどのように影響するかを理解し、モデルとそれが単語に与える重要性を検証および理解するのに役立ちます。 これまで、DataRobotは、データセット内のテキストのインパクトを、テキスト特徴量全体のインパクトとして評価していたため、最良の理解のためには、テキスト全体を読むことが潜在的に求められてきました。 テキスト予測の説明では、青(ネガティブ)から赤(ポジティブ)への標準的なカラーバースペクトルでインパクトを表すため、テキストを簡単に視覚化して理解できます。 不明なn-gramを表示するオプションは、モデルで認識されなかったn-gram(トレーニング中に表示されなかったことが主な理由と思われます)をグレーで識別するのに役立ちます。
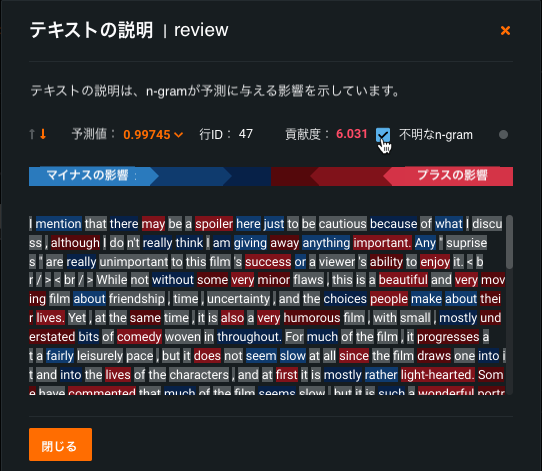
必要な機能フラグ:テキスト予測の説明を有効にする
詳細については、テキスト予測の説明のドキュメントを参照してください。
ブループリントのトグルで、リーダーボードから概要と詳細の表示が可能¶
リーダーボードのブループリントタブから表示されるブループリントは、デフォルトでは読み取り専用の要約ビューであり、最終モデルで使用されたタスクのみが表示されます。
しかし、元のモデリングアルゴリズムにはさらに多くの「ブランチ」が含まれていることが多く、DataRobotは、プロジェクトデータや特徴量セットに適用できないブランチを削除しています。 読み取り専用モードで、トグルによって詳細ビューを表示できるようになりました。 この機能が導入される前は、ブループリント全体を表示するには、ブループリントエディターの編集モードに入る必要がありました。
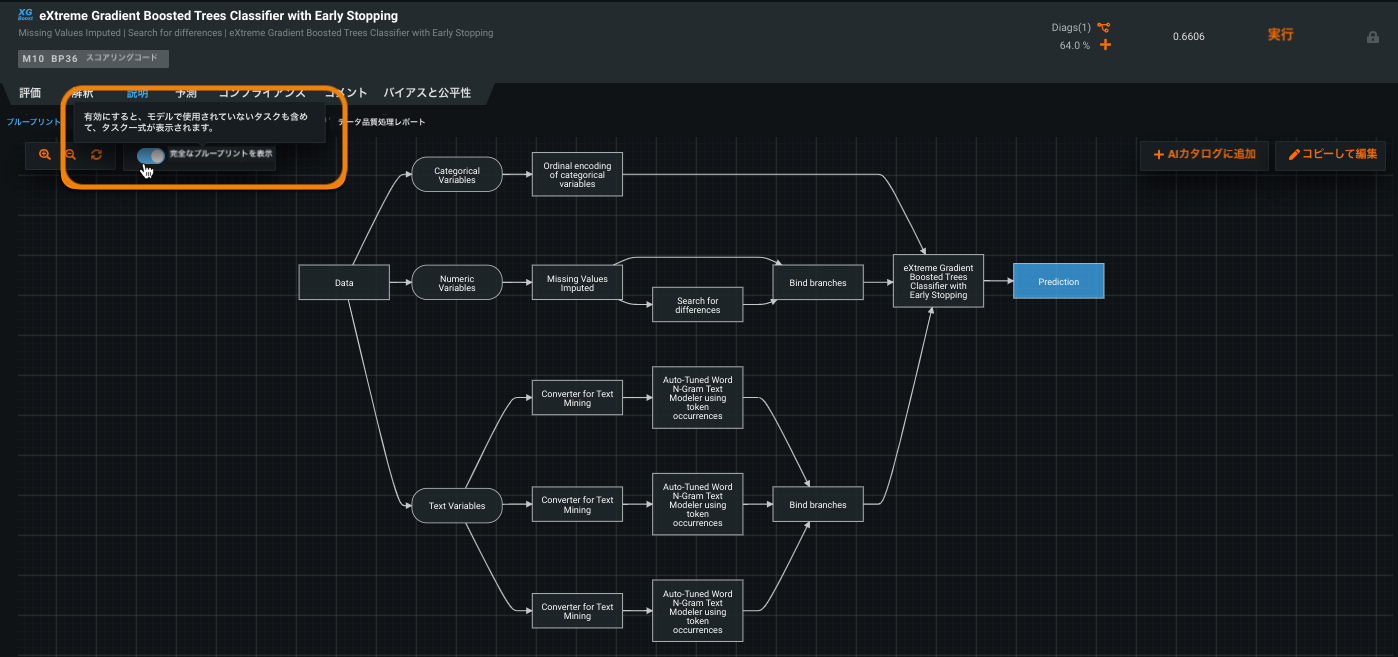
必要な機能フラグ:ブループリントの詳細ビューの切り替えを有効にする
APIの機能強化¶
以下は、APIの新機能と機能強化の概要です。 各クライアントの詳細については、APIドキュメントをご覧ください。
ヒント
DataRobotでは、PythonとRのために最新のAPIクライアントにアップデートすることを強くお勧めします。
バックテストごとに特徴量のインパクトを計算¶
特徴量のインパクトは、特にモデルのコンプライアンスドキュメントにおいて、モデルの概要をわかりやすく示します。 さまざまなバックテストとホールドアウトパーティションでトレーニングされた時間依存モデルでは、バックテストごとに異なる特徴量のインパクトの計算を行うことができます。 一般提供機能になりました。DataRobotのREST APIを使用して、バックテストごとに特徴量のインパクトを計算できます。これにより、特徴量のインパクトのスコアをバックテスト間で比較することによって、時間経過に伴うモデルの安定性を検査できます。
サポート終了のお知らせ¶
Excelアドインを削除¶
DataRobotのExcelアドインは、製品から削除されました。 このアドインをすでにダウンロードされているお客様は、引き続きご利用いただけますが、サポートや今後の開発は行いません。
USER/オープンソースモデルが使用非推奨になり、その後無効化¶
このリリースでは、USER/オープンソース(「ユーザー」)タスクを含むすべてのモデルが使用非推奨です。 既存モデルの非推奨の正確なプロセスは、今後数か月の間に展開され、その影響は後続のリリースでお知らせする予定です。 6月のクラウドリリースで詳細をご確認ください。
特徴量ごとの予実によるインサイトを無効化¶
特徴量ごとの予実による視覚化が無効になりました。 既存のプロジェクトではリーダーボードからこのオプションが表示されず、新規プロジェクトではチャートが作成されません。 組織の管理者は、ツールが完全に削除されるまで、ユーザーに対してこの機能を再び有効にすることができます。 特徴量ごとの予実の代わりに、特徴量ごとの作用によるインサイトを使用すると、同じ出力が得られます。
Auto-Tuned Word N-gram Text Modelerのブループリントをリーダーボードから削除¶
このリリースから、二値分類、連続値、多クラス/マルチモーダルの各プロジェクトでは、Auto-Tuned Word N-gram Text Modelerのブループリントがオートパイロットの一部として実行されません。 ただし、このモデラーのブループリントは、引き続きリポジトリから入手可能です。 現在、Light GBM (LGBM) モデルは、これらの自動チューニングされたテキストモデラーをテキスト列ごとに実行し、それぞれについて、新しいブループリントがリーダーボードに追加されます。 しかし、これらのAuto-Tuned Word N-gram Text Modelerは元のLGBMモデルと相関しません(つまり、これらを修正しても元のLGBMモデルには影響がありません)。 オートパイロットは、テキスト列ごとに1つではなく、すべてのAuto-Tuned Word N-gram Text Modelerタスクに対して1つの大きなブループリントを作成するようになりました。 なお、この変更に下位互換性の問題はなく、新しいプロジェクトにのみ適用されます。
Hadoopのデプロイとスコアリングを削除¶
このリリースから、スタンドアロンスコアリングエンジン(SSE)を含むHadoopのデプロイとスコアリングが完全に削除され、使用できなくなりました。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。