生成AI(V10.2)¶
2024年11月21日
DataRobot v10.2.0リリースには、GenAIに関する多くの新機能と機能改善が含まれています。 リリース10.2のその他の詳細については、以下をご覧ください。
リリース10.2¶
目的別にグループ化された機能
| 名前 | 一般提供 | プレビュー |
|---|---|---|
| GenAI:全般 | ||
| 新しいLLM | ✔ | |
| 新しい埋め込みモデル | ✔ | |
| プレイグラウンド情報を拡充 | ✔ | |
| GenAI:ベクターデータベース | ||
| BYO埋め込みでサポートされるデータセットのサイズを引き上げ | ✔ | |
| ベクターデータベース作成でのCSVのサポート | ✔ | |
| ベクターデータベースのデータソースにおけるメタデータのサポート | ✔ | |
| BYO埋め込みのサポート | ✔ | |
| ベクターデータベースのバージョニング | ✔ | |
| ベクターデータベースでのデータの追加や置換 | ✔ | |
| ベクターデータベースのエクスポート | ✔ | |
| 「チャンキングなし」オプションの導入 | ✔ | |
| セマンティックチャンキング手法を追加 | ✔ | |
| 新たなRetrieverメソッドによりチャンクの選択を指示 | ✔ | |
| 隣接チャンクを結果に追加 | ✔ | |
| メタデータをフィルターして、返される引用数を制限 | ✔ | |
| LLMの評価 | ||
| 新しい評価指標 | ✔ | |
| 評価指標の管理 | ✔ | |
| コンプライアンステストの設定 | ✔ | |
| モデルワークショップに送る指標とコンプライアンステストを管理 | ✔ | |
プレミアム機能
DataRobotの生成AI機能はプレミアム機能です。詳細については、DataRobotの担当者にお問い合わせください。 DataRobotの試用版では、この機能を制限付きでお試しいただけます。
GenAI全般の機能強化¶
新しいLLM¶
リリース10.1以降、以下のLLMが新しく追加されました。
- Anthropic Claude 3 Haiku
- Anthropic Claude 3 Sonnet
- Anthropic Claude 3 Opus
- Azure OpenAI GPT-4 Turbo
- Azure OpenAI GPT-4o
- Google Gemini 1.5 Flash
- Google Gemini 1.5 Pro
コンテキストウィンドウの最大長と出力トークンの評価を含むLLMの全リストについては、こちらをご覧ください。
新しい埋め込みモデル¶
リリース10.1以降、以下の埋め込みモデルが新しく追加されました。
| モデル | 説明 |
|---|---|
| huggingface.co/infloat/multilingual-e5-small | 多言語RAG処理に使用する小型の言語モデルで、multilingual-e5-baseよりも高速です。 |
| jinaai/jina-embedding-s-en-v2 | Jina Embeddings v2ファミリーの1つであるこの埋め込みモデルは、長いドキュメントの埋め込みに最適です(最大8192の大きなチャンクサイズ)。 |
| BYO埋め込み | 非構造化カスタムモデルとしてデプロイされた埋め込みモデルを選択します。 |
埋め込みモデルの全リストについては、こちらをご覧ください。
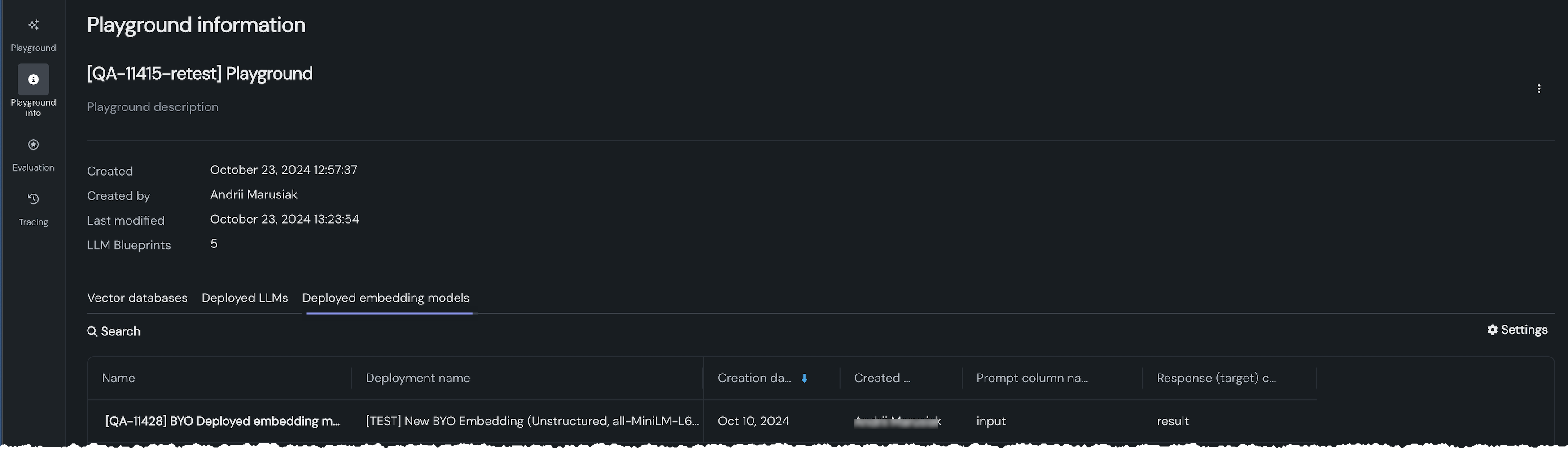
プレイグラウンド情報を拡充¶
新しいプレイグラウンド情報 タブでは、プレイグラウンドに関連付けられているアセット(ベクターデータベース、デプロイされたLLM、デプロイされた埋め込みモデル)にアクセスできます。 また、プレイグラウンドの基本的なメタデータも提供します。 用意されているタブを使用すると、その他の情報を表示できます。
ベクターデータベースに関する機能強化¶
以下の新機能により、ベクターデータベースの作成エクスペリエンスが強化されました。
ベクターデータベースの作成¶
BYO埋め込みでサポートされるデータセットのサイズを引き上げ¶
今回のデプロイから、SaaS環境で独自の埋め込みモデルをプレイグラウンドに持ち込む際、最大10GBのデータセットがサポートされるようになりました。 (埋め込みモデルとは、ベクターデータベースの作成プロセスで使用されるモデルのことです。)セルフマネージドAIプラットフォームでGPU対応のカスタムモデルを持ち込む場合、環境変数CUSTOM_EMBEDDINGS_SUPPORTED_DATASET_SIZEを使用して、BYO埋め込みでサポートされるデータセットの上限を10GBに増やすことができます。 このサイズ拡張機能により、独自の埋め込みモデルを使用する際のスケールやパフォーマンスの制約を回避できます。
ベクターデータベース作成でのCSVのサポート¶
これまでは、アップロードされたZIPファイルを使用してのみベクターデータベースを作成できました。 このリリースから、取り込んだCSVもサポートされるようになりました。 サポートされているデータセットのタイプと処理の詳細については、こちらをご覧ください。
ベクターデータベースのデータソースにおけるメタデータのサポート¶
ベクターデータベースのデータソースに、必須のdocumentおよびdocument_file_path列に加えて、最大50個のメタデータ列を追加できるようになりました。 この追加のメタデータは、LLMとチャットする際にフィルターのベースとして使用できます。 ベクターデータベースのチャンクにメタデータを追加することで、モデルは、検索時にベクターデータベースからこれらのチャンクをより効果的に見つけることができます。
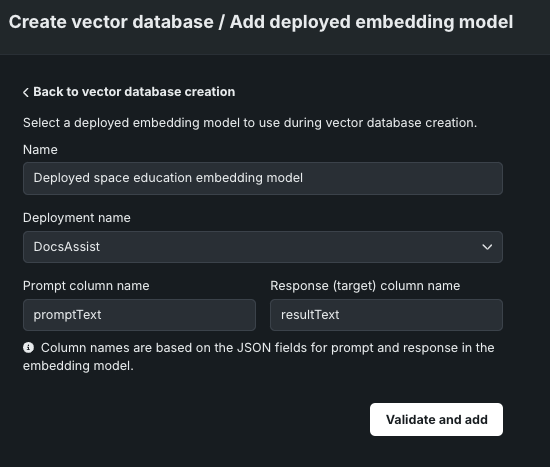
BYO埋め込みのサポート¶
ベクターデータベースを作成する際に、既存の内部埋め込みモデルを使用するか、デプロイされた外部埋め込みモデルを使用するかを選択できるようになりました。 デプロイを指定し、プロンプトと回答の列を追加したら、ベクターデータベースに追加する前にモデルを検証できます。
ベクターデータベースのリフレッシュ¶
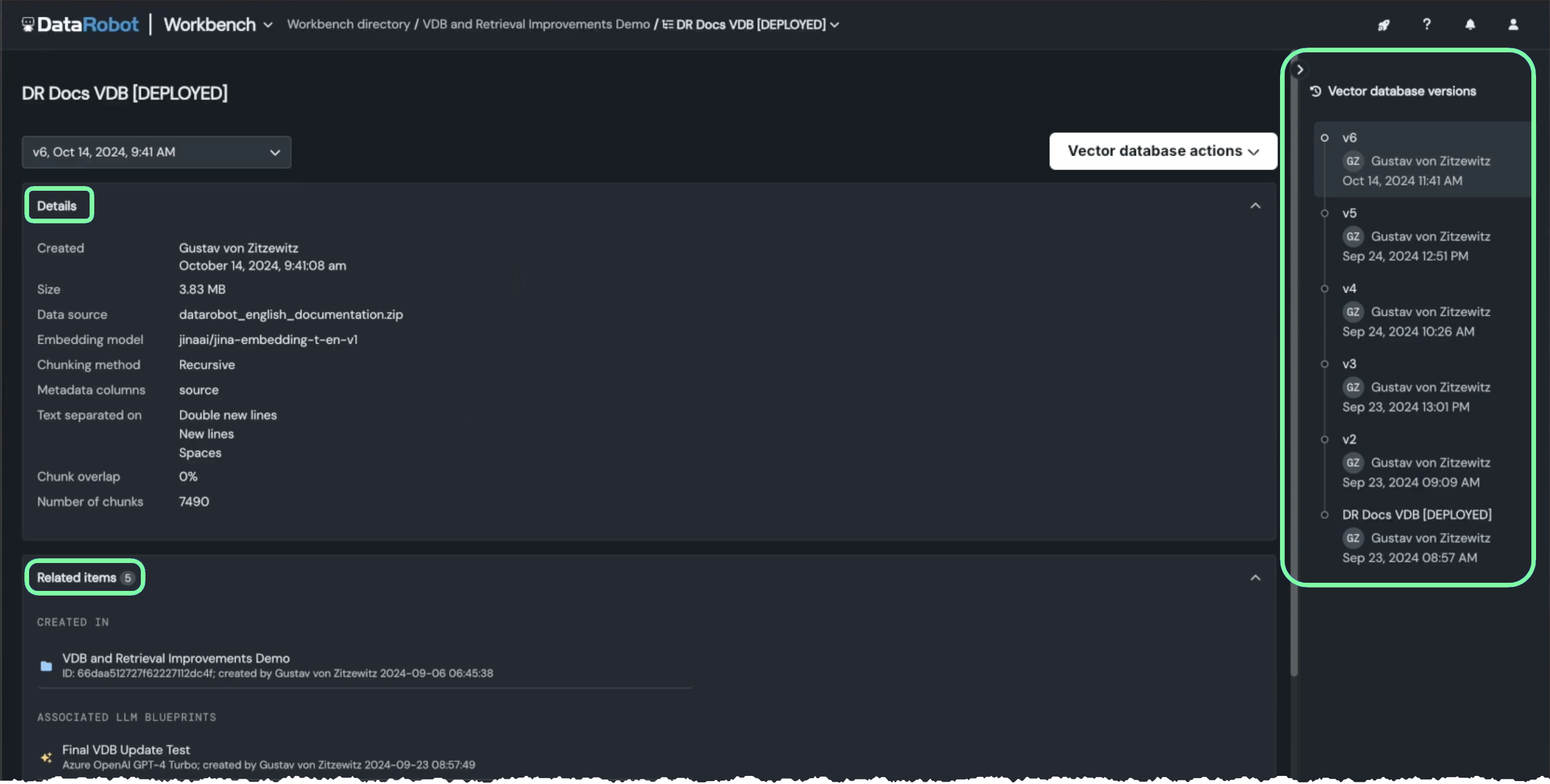
ベクターデータベースのバージョニング¶
プレイグラウンドとデプロイの両方で、既存のベクターデータベースを更新できるようになりました。 ベクターデータベースのバージョニング機能(単一の親に基づいて関連する子エンティティを作成する機能)は、GenAIソリューションの構築に多くのメリットをもたらします。 バージョニングでは、リネージプロセスでメタデータを使用して、結果の評価や以前のバージョンとの結果の比較ができます。 更新ごとに新しいベクターデータベースがバージョンとして作成され、現在のエクスペリメントやそれを利用するダウンストリームアセットに使用するバージョンを選択できます。
バージョニングによって、以下のことができます。
-
ベクターデータベース内のデータを更新して、LLMによる回答の裏付けに最新のデータを使用できます。
-
新しいバージョンを作成して、ベクターデータベースの詳細なリネージを作成できますが、以前のバージョンを選択することもできます。 これにより、ダウンストリームアセットで使用されている古いバージョンを「更新」したり、必要に応じて以前のバージョンにロールバックしたりすることが可能です。
-
既存のベクターデータベースから「実績のある」チャンキングパラメーターや埋め込みパラメーターを新しいデータに適用できます。
-
検索時にデータセットのメタデータを使用することで、データセット内のチャンクをより効果的に検索できます。
さらに、新しい詳細ページには、選択したバージョンのメタデータと関連アセットが一覧表示されます。
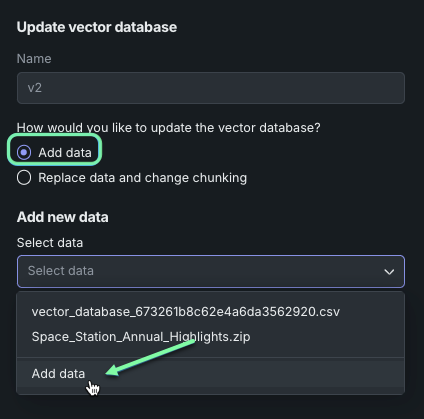
ベクターデータベースでのデータの追加や置換¶
バージョニングの一環として、ベクターデータベース内のデータを更新して、LLMによる回答の裏付けに最新のデータを使用できます。 データを更新する際、現在のデータソースに追加するか、データソースを置き換えるかを選択できます。これにより、ベクターデータベースの作成後も、その内容を調整できます。 データを追加する場合、同じチャンキングおよび埋め込みパラメーターが適用されます。 データを置換する場合、必要に応じてチャンキングや埋め込みを変更することができます。
ベクターデータベースのエクスポート¶
ベクターデータベース、または特定のバージョンのデータベースをデータレジストリにエクスポートし、別のユースケースで再利用できるようになりました。 このデータセットはAIカタログにも保存されます。そこからダウンロードして変更を加え、再びアップロードして、再利用することができます。
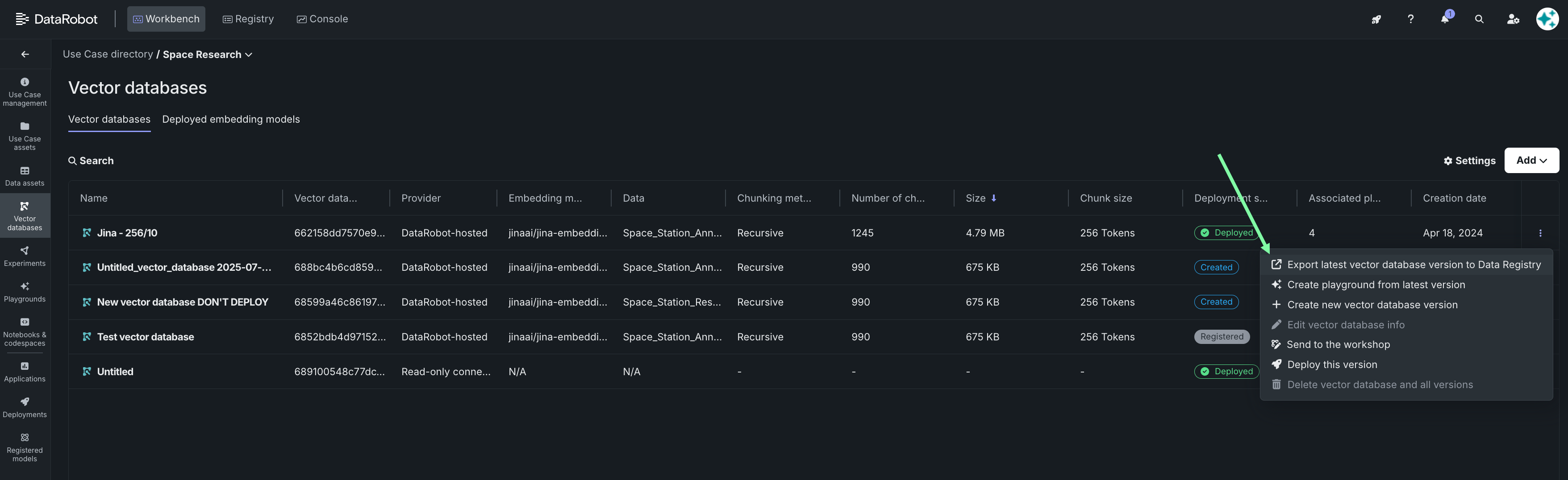
チャンキング¶
「チャンキングなし」オプションの導入¶
今回のリリースでは、ベクターデータベースを作成する際に、入力データソースに対してチャンキングを行わないオプションが追加されました。 テキストチャンキングとは、テキストドキュメントをより小さなテキストチャンクに分割するプロセスであり、これによって埋め込みが生成されます。 チャンキングなし*を選択すると、各行がチャンクとして扱われ、各行に直接埋め込みが生成されます。
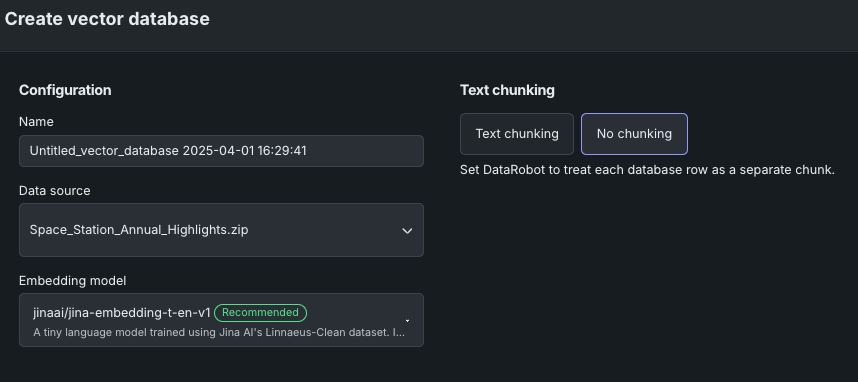
セマンティックチャンキング手法を追加¶
これまで、ベクターデータベースのテキストチャンキング設定では、最大サイズの制限を満たすようにテキストを分割する、再帰的チャンキング手法だけが利用可能でした。 セマンティックチャンキングを導入したことで、テキストを長さではなく内容に基づいて、意味のある小さな単位に分割することができます。これにより、LLMをプロンプトするためのチャンクがより効果的になります。
検索¶
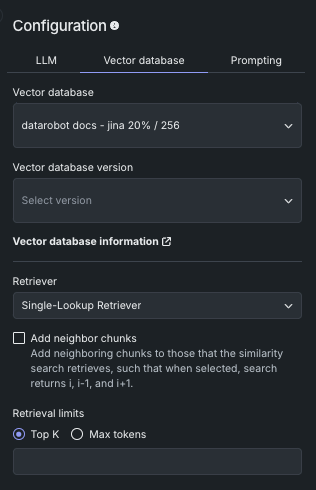
新たなRetrieverメソッドによりチャンクの選択を指示¶
ベクターデータベースを構築する際に、LLMがベクターデータベースから最も関連性の高いチャンクを取得するために使用するRetrieverメソッドを選択できるようになりました。 Single-Lookup、Conversational、Multi-Stepのいずれかを選択します。
隣接チャンクを結果に追加¶
「隣接チャンクを追加」を使用して、類似性検索で取得するチャンクに、ベクターデータベース内の隣接チャンクを追加するかどうかを制御します。 有効にすると、Retrieverはi、i-1、およびi+1(たとえば、クエリーでチャンク番号42を取得すると、チャンク41と43も取得されます)を返します。
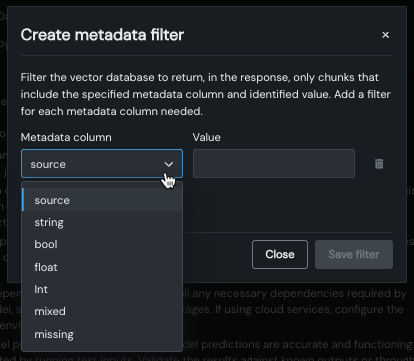
メタデータをフィルターして、返される引用数を制限¶
データソースに追加されたメタデータを使用して、プロンプトクエリーが返す引用数を制限できるようになりました。 メタデータフィルターを適用するには、任意またはすべてのメタデータ列に列と値のペアを作成し、プロンプトクエリーを入力するだけです。 フィルターを適用した場合と適用しない場合の結果を、返された引用で比較できます。
LLM評価の強化¶
評価指標を使用すると、パフォーマンス、安全性、運用に関するさまざまな指標を設定することができます。 これらの指標を設定すると、プロンプトと回答が設定したモデレーション基準を満たした場合に介入するモデレーション方法を定義できます。 この機能は、プロンプトインジェクションや、悪意のある、有害な、トピックから外れた、不適切なプロンプトおよび回答を検出してブロックするのに役立ちます。 また、ハルシネーションや信頼度の低い回答を特定し、個人を特定できる情報(PII)の共有を防ぐのにも役立ちます。 今回のリリースでは、新しい評価指標が追加され、LLM評価ワークフローが改善されました。
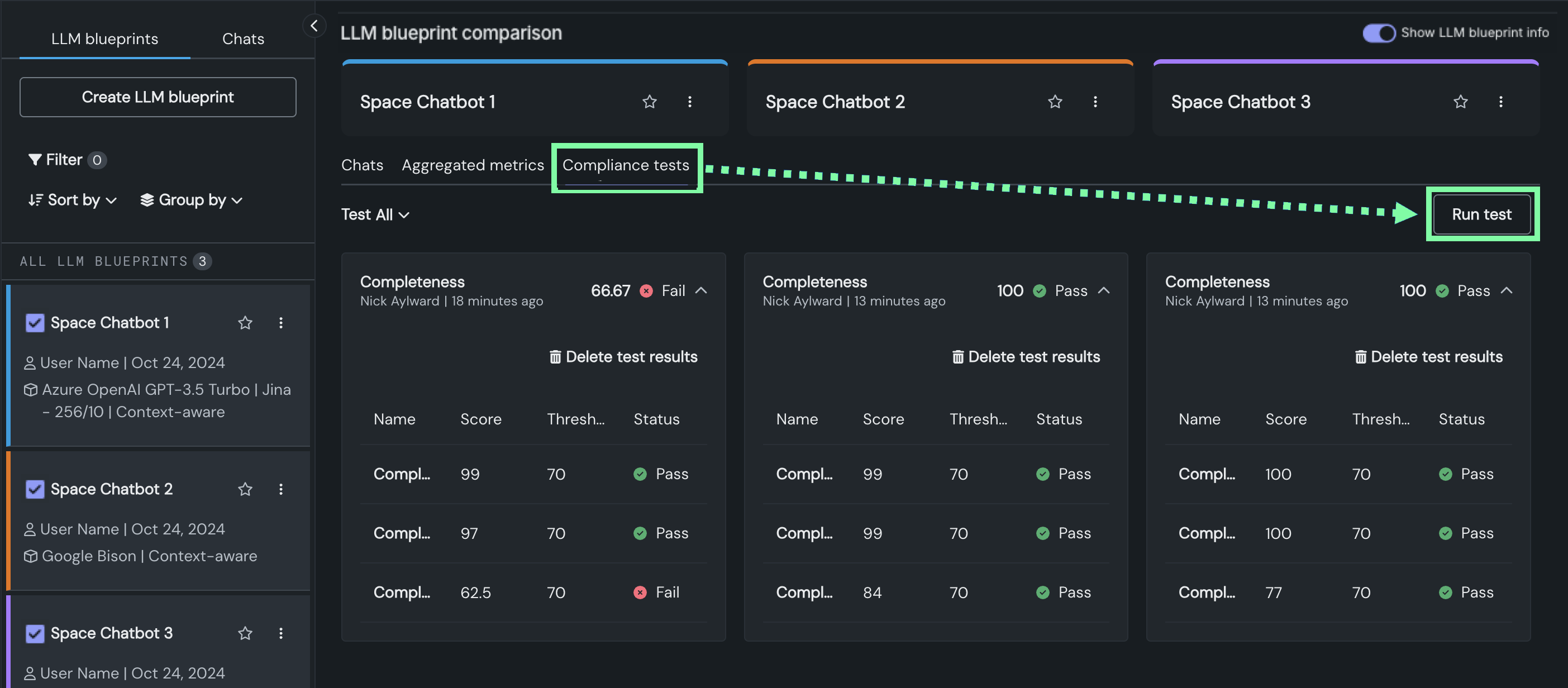
さらに、プレイグラウンドにはコンプライアンステストが導入されました。評価指標と評価用データセットを組み合わせ、テスト用のプロンプトシナリオを通じて、コンプライアンスの問題を自動的に検出することができます。 コンプライアンステストを設定することで、バイアス、ジェイルブレイク、完全性、個人を特定できる情報、毒性について報告できます。 コンプライアンステストは、LLMとともにNextGenレジストリのモデルワークショップに送ると、本番環境でコンプライアンスドキュメントを生成できます。
新しい評価指標¶
リリース10.1以降、以下のLLM評価指標が新しく追加されました。
- 入力のトピックを維持
- 出力のトピックを維持
- 感情分類器(センチメント分類器に代わるもの)
さらに、トークン数は次の4つの指標に分かれました:すべてのトークン、プロンプトトークン、回答トークン、ドキュメントトークン。
評価指標の管理¶
評価タブで評価指標を設定する際、設定のサマリーサイドバーから以前に設定した評価指標を編集できます。 指標の設定(指標名を含む)を編集するには、編集アイコン をクリックします。プレイグラウンドから指標を削除するには、削除アイコン をクリックします。 指標が正しく設定されていない場合は、ヘルパーテキストを表示することもできます。

さらに、評価指標が個々のプレイグラウンドに固有のものとなったため、評価タブから、LLMプレイグラウンドに評価指標の設定をコピーしたり、LLMプレイグラウンドから設定をコピーしたりして、設定をすばやく共有できます。

評価設定は、既存のプレイグラウンドから既存のプレイグラウンドへ、または新しいプレイグラウンドへコピーすることができます。



コンプライアンステストの設定¶
評価指標と評価用データセットを組み合わせ、テスト用のプロンプトシナリオを通じて、コンプライアンスの問題を自動的に検出することができます。 コンプライアンステストは、次の2つの場所で実行できます。
-
プレイグラウンドタイルから、定義済みのコンプライアンステストを変更せずに実行したり、カスタムテストを作成したり、組織のテスト要件に合わせて定義済みのテストを変更したりできます。
-
評価タイルから、定義済みのコンプライアンステストを表示したり、カスタムテストを作成および管理したり、組織のテスト要件に合わせて定義済みのテストを変更したりできます。

リリース10.1以降、以下のLLMコンプライアンステストが追加されました。
- バイアスベンチマーク
- ジェイルブレイク
- 完全性
- 個人を特定できる情報(PII)
- 毒性
- 日本語バイアスベンチマーク
コンプライアンステストの結果を比較するには、プレイグラウンドタイルで、一度に最大3つのLLMブループリントのコンプライアンステストを実行できます。
本番環境では、NextGenコンソールで、デプロイされたLLMについて、設定されたコンプライアンステストの結果を含めて、コンプライアンスドキュメントを生成できます。
モデルワークショップに送る指標とコンプライアンステストを管理¶
LLMブループリントを作成して、ブループリントの設定(評価指標やモデレーションを含む)を行い、回答をテストおよびチューニングしたら、LLMブループリントをモデルワークショップに送ります。 ブループリントをワークショップに送る際、最大12個の評価指標(および設定済みのモデレーション)を選択できます。

次に、ワークショップに送るコンプライアンステストを選択します。 カスタムモデルを登録し、コンプライアンスドキュメントを生成すると、モデルワークショップに送られたコンプライアンステストが含まれます。

評価指標の転送を完了するには、モデルワークショップでカスタムモデルを設定します
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。