リフトチャート¶
| タブ | 説明 |
|---|---|
| パフォーマンス | モデルがターゲット母集団をどの程度適切にセグメント化しているか、またターゲット特徴量の値のさまざまな範囲に対して、モデルのパフォーマンスがどの程度良好であるかを示します。 |
The Lift Chart depicts how well a model segments the target population and how capable it is of predicting the target, letting you visualize the model's effectiveness. チャートは、最もリスクの高いものから最もリスクの低いもののように予測値ごとにソートされるので、ターゲット特徴量の値の異なる範囲においてモデルのパフォーマンスがどの程度良好かを見ることができます。
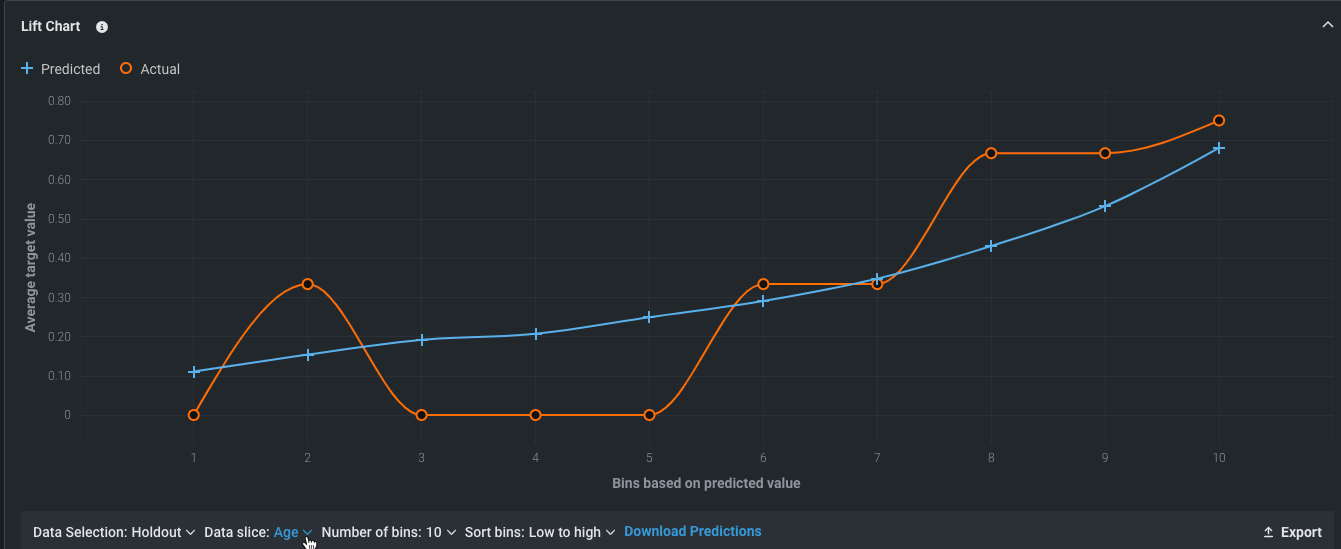
Looking at the Lift Chart, the left side of the curve indicates where the model predicted a low score on one section of the population while the right side of the curve indicates where the model predicted a high score. In general, the steeper the actual line is—and the more closely the predicted line matches the actual line—the better the model is. 一貫した増加を見せる線は、もう1つの望ましい指標です。
- 任意のポイントにカーソルを合わせると、そのビンの行の予測値スコアと実測値スコアが表示されます。
- 表示条件を変更するにはコントロールを使用します
- Compare model lift charts from the Model Comparison tile.
表示の変更¶
Use the Lift Chart controls to modify the display:
| 要素 | 説明 |
|---|---|
| データ選択 | データソースを変更します。 変更内容は、指定された実行タイプ内でのそのモデルに対する予測対実結果の表示内容に影響します。 Options are dependent on the type(s) of validation completed—validation, cross-validation, or holdout. 時間認識モデリングは、バックテストベースの選択を可能にします。 |
| データスライス | 二値分類と連続値のみ インサイト内に表示する部分母集団を定義するフィルターを選択します。 Read more about data slices. |
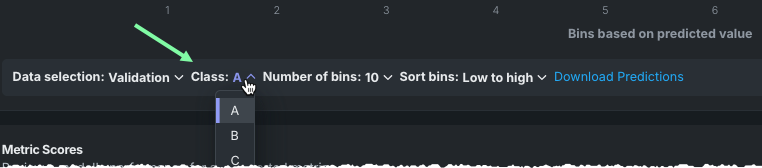
| クラスを選択 | 多クラスのみ。 可視化で結果を表示するクラスを設定します。 |
| ビンの数 | 表示される値のきめ細かさを調整します。 予測をソートする際、幾つのビンにソートするかその数を設定します(初期設定では10ビン)。 |
| ビンを並べ替え | ビンのソート順を設定します。 |
| ドリルダウンを有効化 | モデルフィットプロセス中に作成された予測を使用します。 ドリルダウンでは、リフトチャートの上位100件と下位100件の予測の合計200件が表示されます。 ドリルダウンは、すべてのデータ スライスでのみサポートされます。 |
| 予測をダウンロード | When drill down is enabled, transfers to the Make Predictions tab where you can compute and then download predictions for the top and bottom 100 predictions. |
| エクスポート | チャートのPNG、データのCSV、または両方を含んだZIPをダウンロードします。 詳しくは、エクスポートに関するセクションを参照してください。 |
| バイアスされた予測につながる最適化指標でプロジェクトが構築されたことを示します。 アイコンの上にカーソルを置いて推奨を表示します。 | |
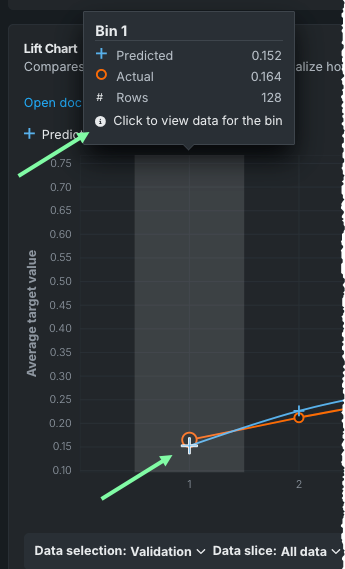
| ビンサマリーヒント | ビンの上にカーソルを置くと、要素行の数に加えて、これらの行の平均実測ターゲット値および平均予測ターゲット値が表示されます。 |
データの掘り下げ¶
The Lift Chart only shows subsets of the data—just the predictions needed for the particular Lift Chart you are viewing based on the Data Source dropdown selection.
ドリルダウンを有効化をクリックすると、モデルフィットプロセスで作成された予測を使用し、データセットの列の全てをそれら予測に追加するようにDataRobotを設定できます。 (This is the source of the raw data displayed when you click the bins in the Lift Chart.)
ドリルダウンを有効化した時点で、DataRobotは、データを演算し、完了した時点でラベルが予測をダウンロードに変化します。 予測をダウンロードをクリックすると、DataRobotは予測の作成タブに移動し、予測の演算またはダウンロードを行います。 予測を作成タブを使用して予測を演算するオプションは、データソースドロップダウンを使用して選択されたサブセットではなく、データセット全体を対象にしています対す。
元のデータの表示¶
ドリルダウンを有効にした後、グラフのプラス記号をクリックして、ビンでに含まれているデータのテーブルを表示できます。 プラス記号のないビンのデータを表示するには予測をダウンロードする必要があります。
When exposure is set
連続値プロジェクトのモデル構築にエクスポージャーパラメーターを使用した場合、インライン表の予測列には、エクスポージャーで調整された予測(エクスポージャーを除数として割られた予測)が表示されます。 インラインテーブルの実測値列には、エクスポージャーで調整された列値(エクスポージャーで分割された実測値)が表示されます。 その結果、予測および実測値列の名前は、予測値/エクスポージャーおよび実測値/エクスポージャーに変わります。
元のデータ表示の計算¶
ドリルダウンは、ランクの最も低い予測と最も高い予測をそれぞれ100件だけ表示します。 This corresponds to the far left and far right sides of the Lift Chart. 表示中のデータソースの大きさによって、元のデータを表示するのに利用可能な強調表示されたビンの数は異なり、チャートの各側に同じ数のビンが表示されます。 より大きなデータセットについては、各側に一つだけの強調表示されたビンが存在することがあります。 (これをテストするには、ビンの数を増やすことができ、その際、強調表示される箇所の数が増える可能性が非常に高くなります。
下記の例について見てみましょう。 検定サブセットに5000列が含まれています。 When you view the chart with 10 bins, each bin contains 500 rows. ドリルダウンを有効化する際、予測の最下位100件の全てがビン1に入ります。ビンの数を60に増やすと、各ビンに含まれる列は83になります。 したがって、左の2つの(および右端の2つの)ビンが強調表示されます。
多クラスプロジェクトを含むリフトチャート¶
For multiclass projects, you can set the Lift Chart display to focus on individual target classes—a chart for each individual class. Use the Select class dropdown below the chart to visualize how well a model segments the target population for a class and how capable it is of predicting the target. ドロップダウンには、選択のための最も一般的な20のクラスが表示されます。
エクスポートボタンを使用して以下をエクスポートします。
- A PNG of the selected class.
- CSV data for the selected class.
- A ZIP archive of data for all classes.
Lift Chart binning¶
The Lift Chart groups numeric feature values into equal sized "bins", sometimes called a decile chart, which DataRobot creates by sorting predictions in increasing order and then grouping them. The results are plotted as the Lift Chart, where the x-axis plots the bin number and the y-axis plots the average value of predictions within each the bin. これは2ステップのプロセスです。最初に、モデルでターゲットに近似すると考えられる要素によって行がグループ化され、次に実際の出現数が演算されます。 Both values are plotted on the chart.
たとえば、不良債務情報のデータベースに100行が含まれる場合、予測されたスコアリングでソートされ、これらのスコアをユーザーが指定した数のビンに分割します。 10のビンがある場合、各グループには10のグループが含まれます。 最初のビン(またはデシル)には最低の予測スコアが含まれ、不良債務者になる可能性が最も低いと考えられます。 10番目のビンには最高の予測スコアが含まれ、不良債務者になる可能性が最も高いことが示唆されます。ビンの数(およびビンあたりの行数)に関係なく、考え方は同じで「ビンに含まれる人のパーセンテージが実際に不良債務に陥ったか」がポイントになります。
不良債務の例では、チャート上のポイントの意味を考えた場合、各ビンのポイントは以下のことを意味します。
- リーダーボードでは、不良債務に陥ると予測された人の数(青い線)と実際に不良債務に陥った人の数(オレンジの線)が示されています。 このチャートを使用して、モデルの精度を評価します。
- モデル比較では、各モデルで実際に不良債務者になった人の数が表示されます。
では、実際の値は何でしょうか? 左側のチャートにプロットされた実際の値は、ターゲット値が適用される該当ビンの行の数またはパーセンテージです。 この区別は、モデル比較ページのモデルを考慮する際に非常に重要です。 DataRobotではモデルのスコアリングに基づいて行がソートされ、そのソート済みリストから行がビンにグループ化されます。 各モデルのビンには、それぞれ異なる内容が含まれます。その結果、各モデルのビンには同じ数のエントリーが含まれますが、各ビンの実測値は異なります。
エクスポージャーと加重の詳細¶
連続値プロジェクトでエクスポージャーを設定した場合、観測値は、エクスポージャーで調整された「年次」予測(つまり、エクスポージャーを除数として割られた予測など)に従ってソートされ、ビンの境界はこれらの調整された予測に基づいて決定されます。 y軸には、ビン内のエクスポージャーの合計を除数として割られた調整済みの予測の合計がプロットされます。 実測値は同じ方法で調整およびプロットされます。
エクスポージャーとサンプル加重の両方が指定されている場合、エクスポージャーは上記のようにビンの境界を決定するために使用されますが、サンプル加重は使用されません。 DataRobotは、composite_weight = weight * exposureの積に等しい複合加重を使用して、各ビンの予測値と実測値の加重平均を計算します。 次に、y軸は調整された予測値の加重合計を複合加重の合計で割ったものをプロットします。実測値の場合も同様です。
この調整は、保険契約の年間コストと予測の間の関係性を理解する場合などに便利です。