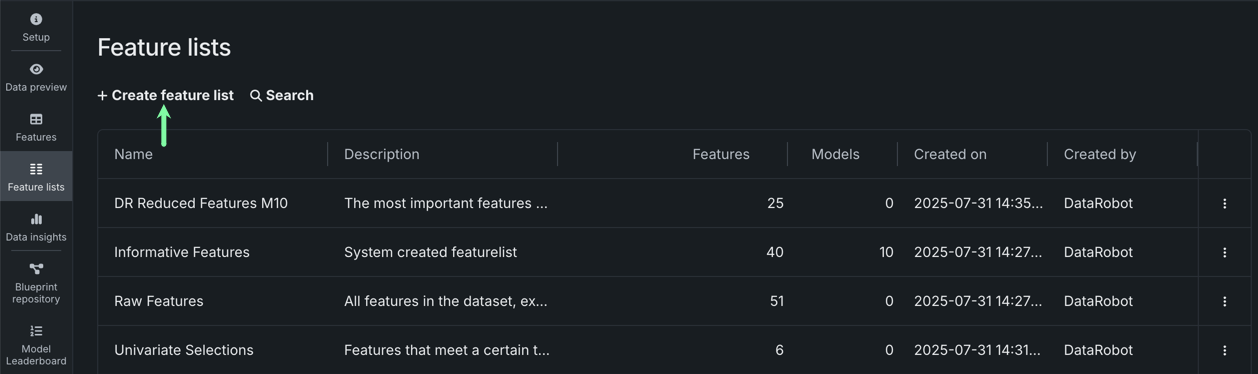
特徴量セット¶
特徴量セットは、DataRobotでモデルの構築と予測に使用する特徴量のサブセットを制御します。 自動的に作成されたセットのいずれかを使用したり、手動で特徴量を追加してカスタム特徴量セットを作成したりできます。 また、カスタム特徴量セットは、確認、名前の変更、削除も可能です。
特徴量セットを使用して、次のようなことができます。
- ターゲットリーケージの原因になっている特徴量など、何らかの理由でモデルで使用できない特徴量を削除する。
- 有用でない特徴量(モデルのパフォーマンスを向上させない特徴量)を削除して、予測を高速化する。
自動作成された特徴量セット¶
時間を認識する特徴量セット
以下の情報は、時間を認識しない特徴量セットに適用されます。 時間を認識する特徴量セットの詳細については、時系列特徴量セットを参照してください。
各データセットおよびエクスペリメントに対して、複数の特徴量セットが自動的に作成されます。 以下の点に注意してください。
- 時系列特徴量セットは予測特徴量セットとは異なります。
- 交互作用の検索から作成された特徴量については、異なる特徴量セットになります(プラス(+)記号が付加されます)。
- エクスペリメントのターゲット特徴量は、すべての特徴量セットに自動的に追加されます。
以下に、時系列以外のエクスペリメントで自動的に作成される特徴量セットについて説明します。
| 特徴量セット | 説明 | 可用性 |
|---|---|---|
| すべての特徴量 | 特徴量セットでなくても(モデル構築で使用できなくても)、すべての特徴量を選択すると、データセット内のすべての列に加えて、追加の変換済み特徴量がプロジェクトのデータにリストされます。 | |
| 有用な特徴量 | DataRobotでターゲットリーケージが検出されない場合のデフォルトの特徴量セットです。 このセットには「妥当性」チェックを通過した特徴量が含まれています。このチェックでは、一般化が可能なモデルの構築に有用な情報が含まれているかどうかが判断されます。 たとえば、重複した列、すべてが1または参照IDである列、値が少なすぎる特徴量など、情報量が少ない、または冗長であるとDataRobotが判断した特徴量は除外されます。 | EDA1の後 |
| 有用な特徴量 - リーケージ除去済 | DataRobotでターゲットリーケージが検出された場合のデフォルトの特徴量セットです。 このセットでは、ターゲットリーケージを発生させるリスクのある特徴量およびモデリングに有用な情報を提供しない(またはほとんど提供しない)特徴量が除外されます。 何が除外されたかを判断するには、データテーブルのすべての特徴量を選択した状態で、ラベル付けされた特徴量を確認できます。 | ターゲットリーケージが検出された場合、EDA1の後 |
| 有用な特徴量 + | オートパイロットが有用な特徴量セットでの実行に設定されていて、組み合わせ特徴量の探索が有効になっている場合、有用な特徴量 +が作成されます。これには元の特徴量セットと同じ数の特徴量が含まれない場合があります。古い特徴量から新しい特徴量を派生させるときに、両方を保持すると冗長になる可能性があるためです。 その場合、親特徴量の1つが削除されます。 | (Classicのみ)組み合わせ特徴量の探索を有効にしたEDA2の後 |
| 元の特徴量 | データセットのすべての特徴量(ユーザーが派生した特徴量を除き、有益な特徴量セットから除外された特徴量を含む)(重複、高い欠損値など)。 | EDA1の後 |
| 有用性上位の選抜 | 選択したターゲットとの一定の非線形相関のしきい値(0.005を超えるACEスコア)を満たす特徴量。 有用な特徴量セットの各エントリーに関して、ターゲットに対する特徴量の個々の関係性が計算されます。 | EDA2の後 |
| DataRobotで削減した特徴量 | 特徴量のサブセット(リーダーボード内のベストな非アンサンブルモデルの特徴量のインパクトの計算に基づいて選択されます)。 その後、このDataRobotで削減した特徴量セットを使って、最適な非ブレンダーモデルが自動的に再トレーニングされ、新しいモデルが作成されます。 元のモデルと新しいモデルが比較され、より優れたモデルが選択されます。このモデルは、モデルを推奨する目的で、より高いサンプルサイズで再トレーニングされます。 ほとんどの場合、DataRobotにより数を削減した特徴量セットは、モデルに対して累積インパクトの95%を与える特徴量で構成されます。 この数値が100以上の場合、上位100の特徴量だけが含まれます。 プロジェクトで冗長な特徴量の識別がサポートされている場合、DRの削減済み特徴量から冗長な特徴量が除外されます。 | EDA2の後、ただしクイックモード以外 |
DataRobotにより数を削減した特徴量セットでのモデルの再トレーニング
DataRobotにより数を削減した特徴量セットでモデルを再トレーニングすると、特徴量のインパクトはトレーニングデータからサンプリングされたデータで生成されるため、交差検定のスコアが楽観的になる可能性があります。 これにより、その他の交差検定分割のサンプルデータを使用すると、交差検定スコアがさらに楽観的になります。
この影響は、サンプルサイズが小さく分散が大きい場合に顕著になります。
このため、リーケージの最終チェックとなるホールドアウトセットがあると便利です。
カスタム特徴量セットの作成¶
必要な権限
特徴量セットを作成するには、データセットへのオーナーまたはエディターアクセス権が必要です。
自動作成された特徴量セットを使用しない場合は、カスタム特徴量セットを作成してモデルのトレーニングを行い、モデルが向上するかどうかを確認します。
カスタム特徴量セットを作成する機能は、以下から利用できます。
| 位置 | 説明 |
|---|---|
| モデリングの前 / EDA1の後 | |
| レジストリのデータタブ | ユースケースに追加してモデリングに使用する前の登録済みデータセットに対して、カスタム特徴量セットを作成します。 ここから、単一の特徴量に対して特徴量の型変換を行うこともできます。 |
| データ探索ページ | データセットのプロファイリングからモデリングまでの間に、ユースケースのデータセットでカスタム特徴量セットを作成します。 この段階で作成された特徴量セットは、データセットに基づくエクスペリメントに表示されます。 |
| モデリングの後 / EDA2の後 | |
| データプレビュータイル | 予測モデリング用のポストモデリング特徴量と、時間認識モデリング用の派生モデリングデータ。 |
| 特徴量セットタイル | エクスペリメントには、自動作成されたリストとカスタムリストを利用できます。 |
| 特徴量のインパクトインサイト | インパクトベースの特徴量選択のオプション(予測のみ)。 |
| クラスターインサイト | インサイトの表示を変更するか、予測クラスタリングエクスペリメントからリストを作成します。 |
エクスペリメントから作成されたリストは以下の通りであることに注意してください。
- エクスペリメント内で、モデルの再トレーニングやブループリント リポジトリから新しいモデルのトレーニングに使用されます。
- ユースケースのすべてのエクスペリメントにわたってではなく、そのエクスペリメント内でのみ使用できます。
- データ探索ページでは使用できません。
特徴量を追加¶
カスタム特徴量セットを作成するには、上のテーブルにリストされているタブまたはインサイトのいずれかに移動し、+ 特徴量セットを作成をクリックします。
その後、次の操作を行うことができます。
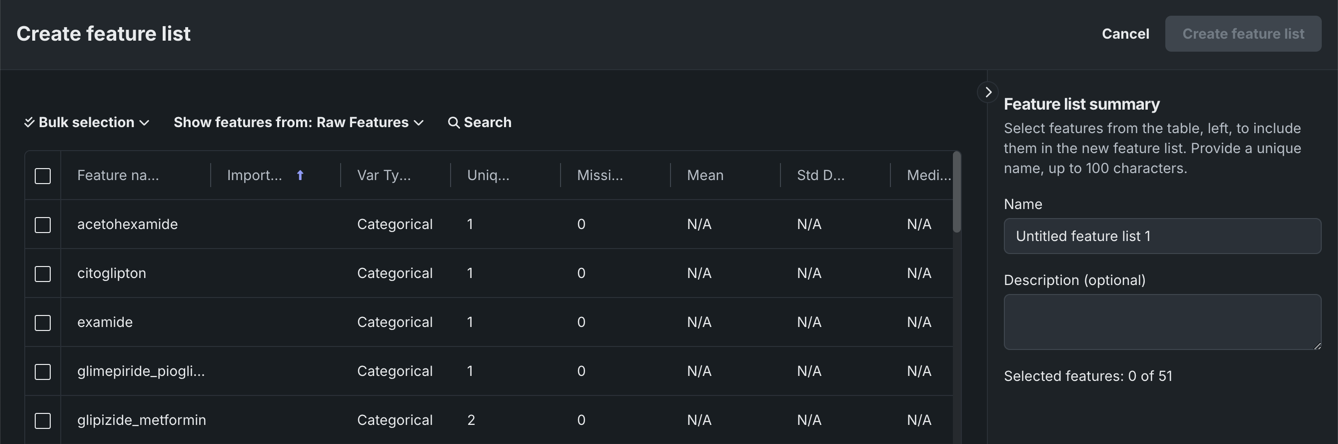
特徴量を個別に選択する¶
特徴量を個別に選択するには:
-
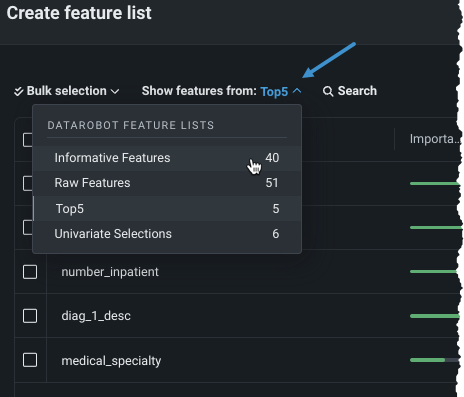
特徴量の表示元:ドロップダウンを使用して、選択可能な表示済み特徴量を変更します。 デフォルトでは、元の特徴量セットから特徴量をリスト表示します。 すべての自動生成されたカスタムリストは、ドロップダウンから使用できます。
-
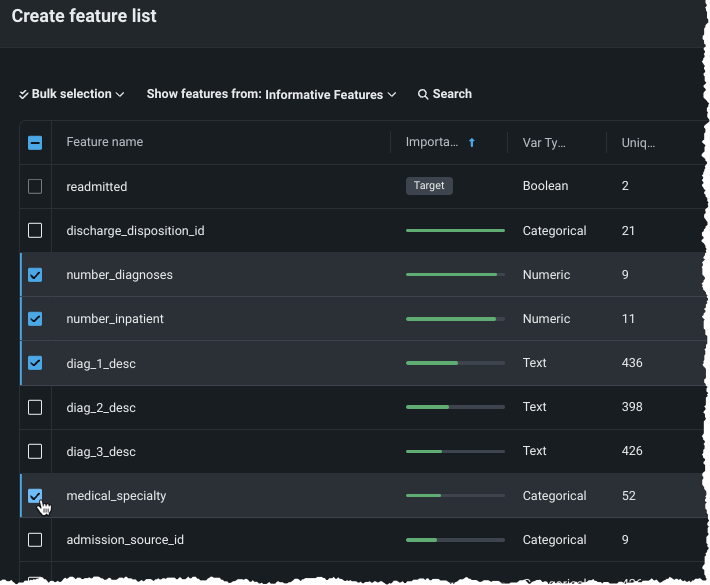
特徴量名の左側にあるチェックボックスを使用して、選択を追加または消去します。
-
オプションで検索フィールドを使用して、特徴量の表示元:の選択範囲で検索文字列に一致する特徴量のみを表示するように更新します。
備考
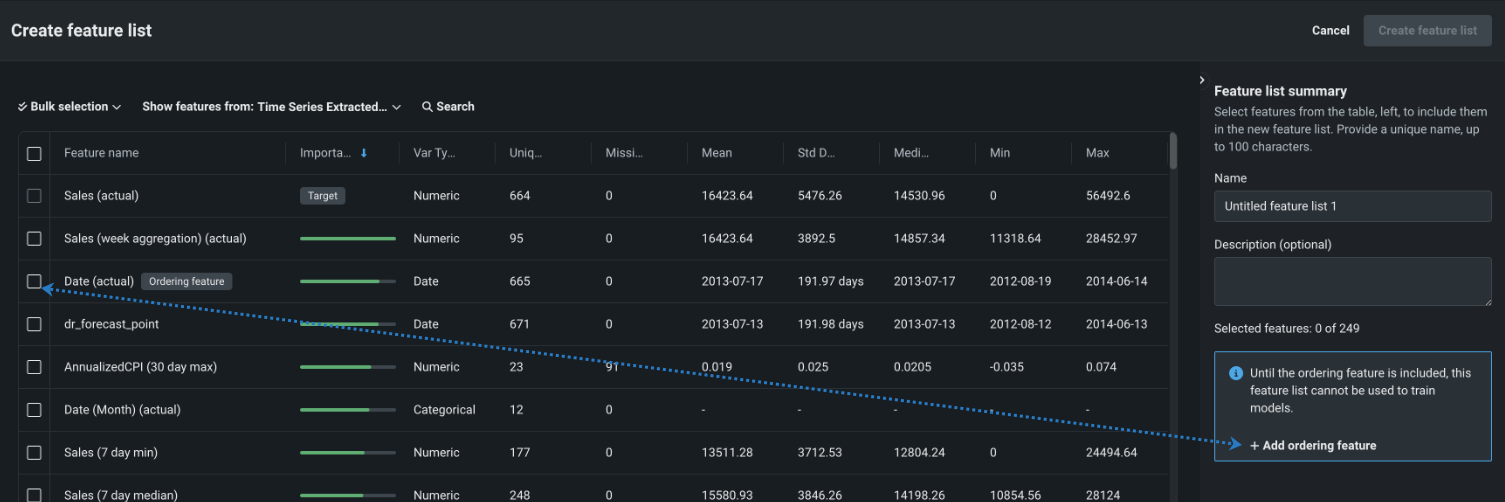
時系列モデルの新しい特徴量セットを作成する際に、順序付け特徴量を含めることも除外することもできるようになりました。 単調制約リストなど、リストがトレーニングに直接使用されていない場合、順序付け特徴量は必要ありません。
特徴量を個別に選択するには:
-
特徴量の表示元:ドロップダウンを使用して、選択可能な表示済み特徴量を変更します。 デフォルトでは、時系列で抽出された特徴量セットから特徴量をリスト表示します。 すべての自動生成されたカスタムリストは、ドロップダウンから使用できます。
-
(オプション)新しい特徴量セットを使用してモデルをトレーニングする場合は、+ 順序付け特徴量を追加をクリックするか、特徴量の左側にあるチェックボックスをオンにして、順序付け特徴量を追加する必要があります。
-
特徴量名の左側にあるチェックボックスを使用して、選択を追加または消去します。
特徴量セットの一括アクション¶
一度に複数の特徴量を追加するには、一括選択ドロップダウンから方法を選択します。
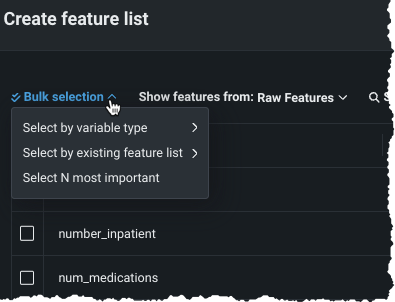
特徴量の型で選択を使用して、選択した特徴量の型のデータセットのすべての特徴量を含むリストを作成します。 選択できる特徴量の型は1つだけですが、その後に他の特徴量(任意の型)を個別に追加することができます。
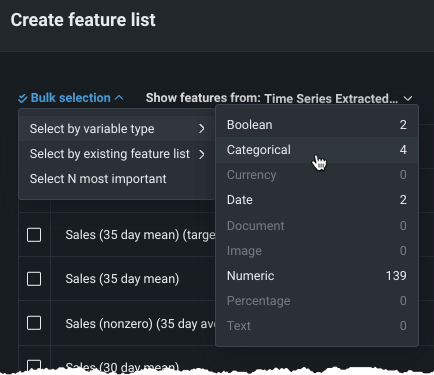
既存の特徴量セットで選択を使用して、選択したセット内のすべての特徴量を追加します。
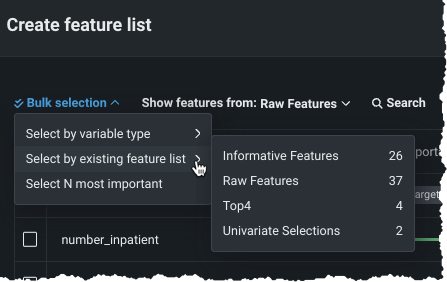
一括アクションは、特徴量の表示元:ドロップダウンの補助的なものであることに注意してください。 たとえば、"Top5"リストから特徴量を表示すると、カスタムリストに追加された5つの特徴量が表示されます。 次に、既存の特徴量セットで選択 > 有用な特徴量(または時系列の有用な特徴量)を使用すると、「有用な特徴量」にも含まれる「上位5」内のすべての特徴量が選択されます。 逆に、特徴量を表示:有用な特徴量に設定し、既存の特徴量セットから選択 > 上位4を選択すると、それら5つの特徴量が選択されます。
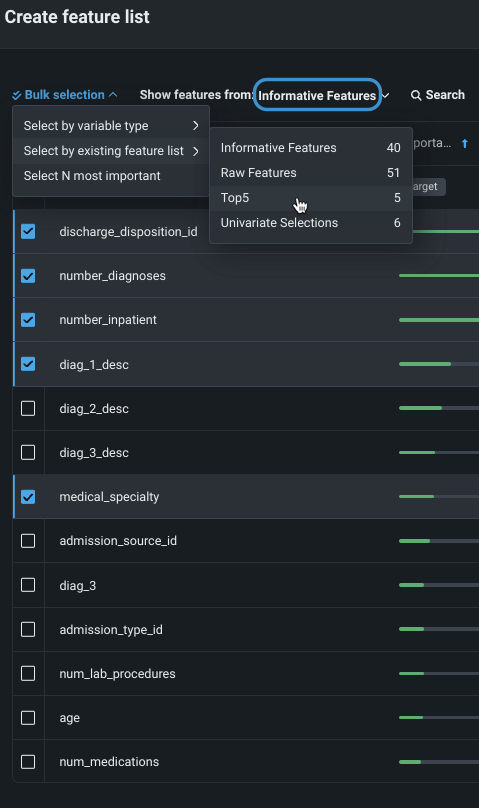
最も重要なN個を選択を使用し、特徴量の表示元:ドロップダウンで選択したリストで使用可能な特徴量から、指定された数の「最も有用性の高い」特徴量を追加します。 有用性スコアは、その特徴量だけを使用してターゲットを予測する場合、特徴量が予測能力の指標を表すターゲットと相関する度合いを示します。

特徴量セットの保存¶
リストのすべての特徴量を選択した後、オプションでリスト名を変更し、特徴量セットのサマリーに説明を入力します。 サマリーには、リストに含まれる特徴量の数とタイプも表示されます。
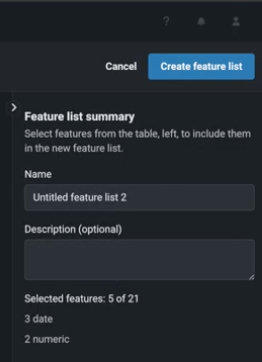
次に、特徴量セットを作成をクリックして情報を保存します。 新しいセットは、特徴量セットタブのリストに表示されます。