SHAP分布:特徴量ごと¶
| タブ | 説明 |
|---|---|
| 説明 | 各予測が平均からどのように異なるかに対して、各特徴量がどれだけ寄与しているかを推定することで、予測の要因を理解するのに役立ちます。 |
このインパクトを別の方法で視覚化するために、2つのインサイトが用意されています。
| インサイト | 説明 |
|---|---|
| SHAP分布:特徴量ごと(このページ) | バイオリンプロットを使用して、特徴量ごとのスコアの分布と密度を視覚化します。 |
| SHAPベースの個々の予測説明 | 各特徴量の予測に対する影響を行ごとに表示します。 |
方法論と解釈可能性の詳細については、 詳細を参照してください。 DataRobotでのSHAPの操作について詳しくは、関連する注意事項と、予測および時間認識エクスペリメントのSHAPリファレンスを参照してください。
視覚化の概要¶
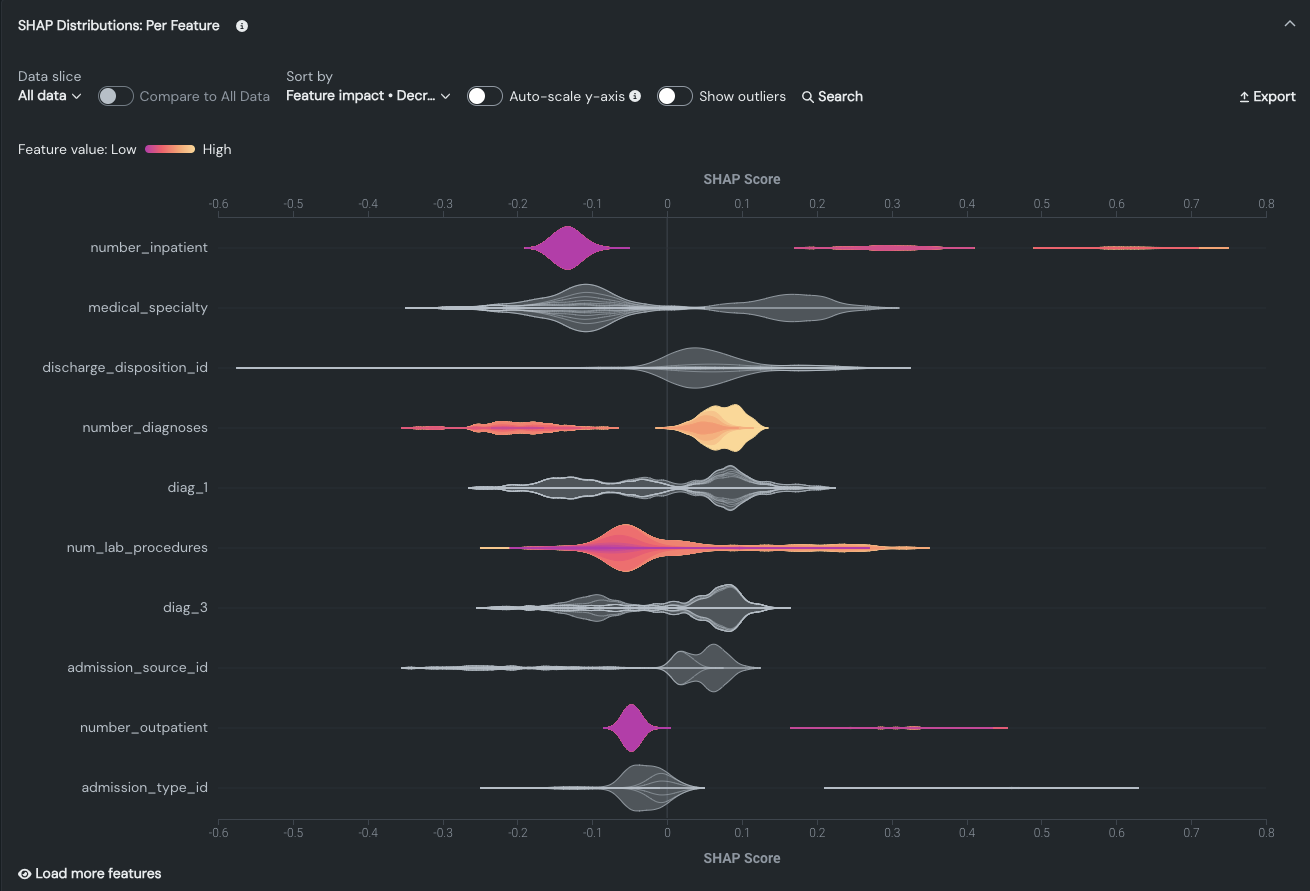
SHAP分布:特徴量ごとは、バイオリン図とも呼ばれ、さまざまなカテゴリー間でデータセットの確率分布を比較するための統計図です。 データの滑らかで連続的な形状を示します。 縦軸はデータセットの特徴量を表し、横軸はSHAPスコアを表します。 その結果、プロットされた密度形状は、異なる値におけるデータの最大1,000行のサンプリングに基づく分布を表しています。 ある値における「バイオリン」の幅は、その値の周辺にどれだけのデータ点が集まっているか、ピークがあるか、均等に広がっているかを示しています。 分布の具体例を参照してください。
視覚化では、並べ替え順に基づいて上位10の特徴量が表示され、さらに多くの特徴量をロードするオプションがあります。
インサイトフィルター¶
予測分布図を変更するには、インサイト内のコントロールを使用します。 オプションはエクスペリメントのタイプによって異なります。
| オプション | 説明 | タイプ |
|---|---|---|
| データスライス | データスライスを選択または作成(スライスを作成を選択)して、特定のコホートが予測結果にどのように影響するかを確認します。 | 予測 |
| すべてのデータと比較 | 部分母集団(スライス)に対する特徴量のインパクトを表示します。 結果は、完全な母集団を考慮した場合の影響と重ねて表示されます。 | 予測 |
| 系列ID | 系列識別子を選択して、その系列のみの説明を表示するか、なしを選択して、すべての系列の説明を表示します。 | 時間認識 |
| 予測距離 | なしまたは特定の予測距離を選択します。 使用可能な値は、予測ウィンドウの設定で予測する値の数を設定したときに作成された時間ステップの範囲から導き出されます。 | 時間認識 |
| ソート条件 | ソート方法(インパクト(有用性)またはアルファベット順の名前)およびソート順を設定します。 デフォルトは、インパクトの降順なので、最もインパクトの大きい特徴量が最初に表示されます。 | すべて |
| Y軸のオートスケール | 最も多くの行が存在する特徴量を基準として、特徴量の分布をスケーリングします。 | すべて |
| 外れ値を表示 | 外れ値を含めるようにスケールを調整します。 | すべて |
| 検索 | 検索文字列に一致する特徴量のみを表示するように調整します。 | すべて |
| エクスポート | 視覚化のためにデータ、画像、またはその両方をダウンロードします。 | すべて |
データスライス¶
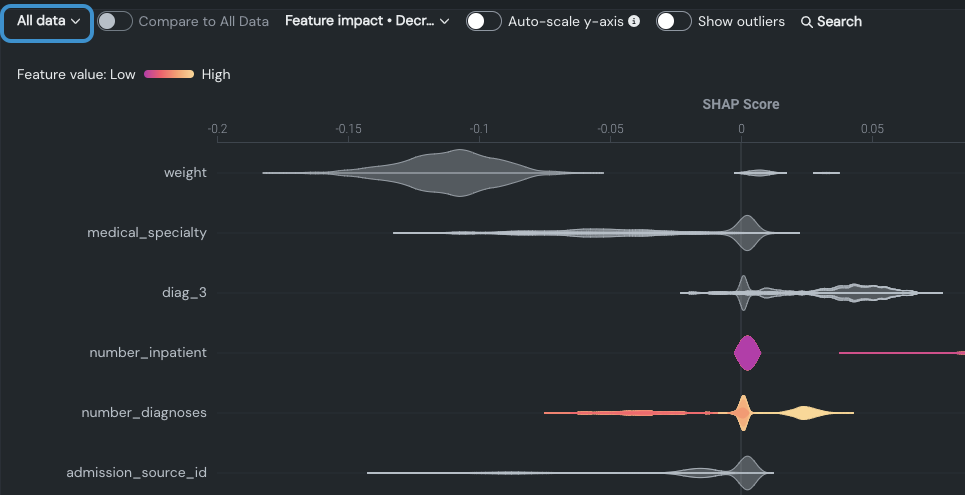
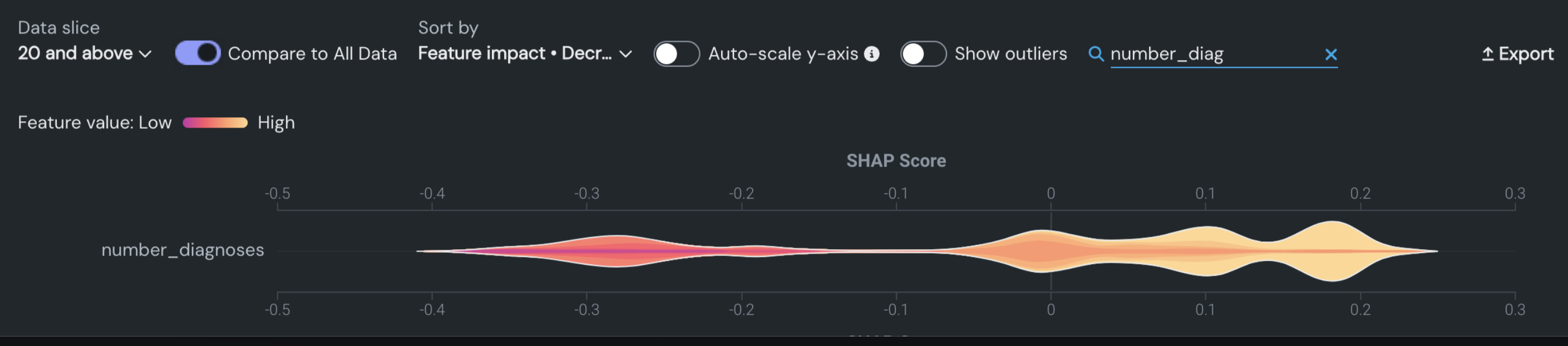
予測エクスペリメントでは、データスライスは、特徴量の値に基づいてモデルのデータの部分母集団を表示する方法です。 スライスが選択されると、新しい母集団に従った並べ替え選択に合わせて特徴量の順序が変わることに注意してください。 例:
スライスがない場合、プロットは以下の情報を表示します。
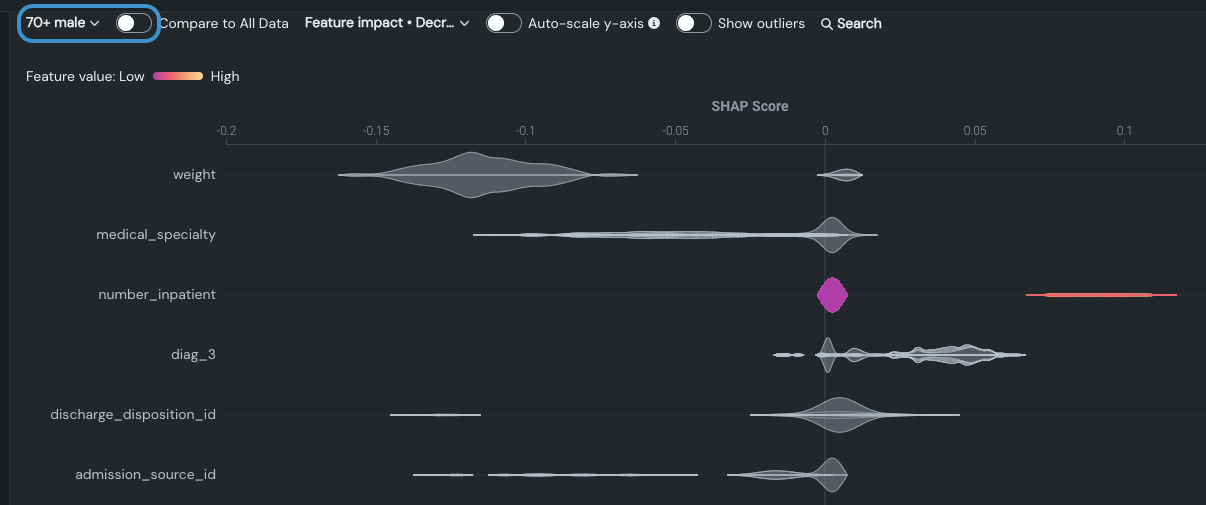
70歳以上の男性の表示:
すべてのデータと比較¶
1つ以上のスライスを設定したら、すべてのデータと比較トグルを有効にします。 これにより、選択したスライスを完全なデータセットオプションと比較することができ、スライスしていないデータと比較したときに分布がどのように異なるか(あるいは異ならないか)を視覚化するのに役立ちます。
トグルをオンにすると、白い輪郭付きの透明なバイオリンプロットがスライスされていないデータを表し、その内側にある色付きのバイオリンのプロットが選択されたスライスを表します。
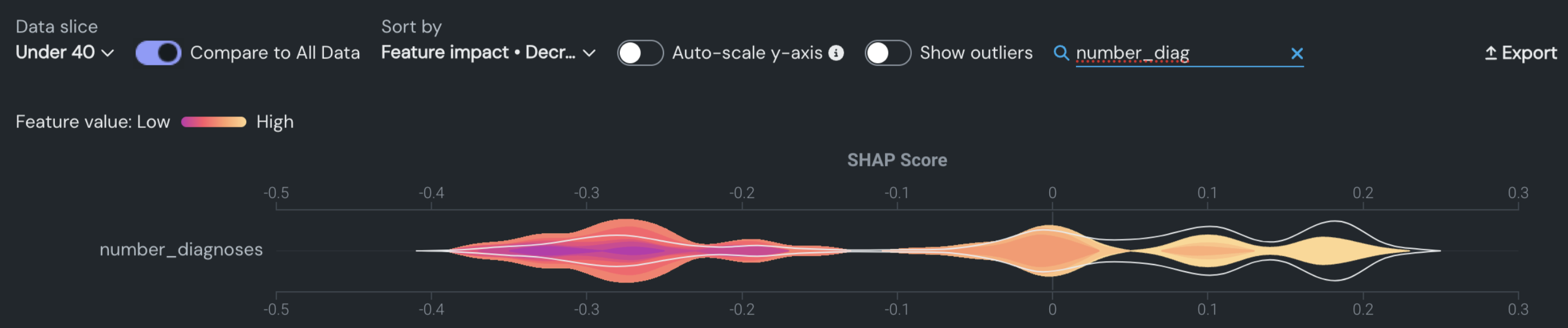
スライスが すべてのデータ に非常に近い場合、スライスされたサブセットに近いため、バイオリンプロットの白い輪郭が透明に見えます。
Y軸のオートスケール¶
トグルを使用して、垂直方向のスケーリングを正規化します。 この設定では、インサイトが各バイオリンプロットのすべての分布詳細を表示するか、または最も分布が少ない(一貫性が高い)特徴量の値のカウントに比例して、スケーリングされた分布を表示するかを制御します。 高い、短い、広い、狭い分布が一目でわかります。 このオプションは、分布がどの程度影響力を持つかの大まかな目安を提供します。 バイオリンプロットが広がれば広がるほど、値は分散します。 例:
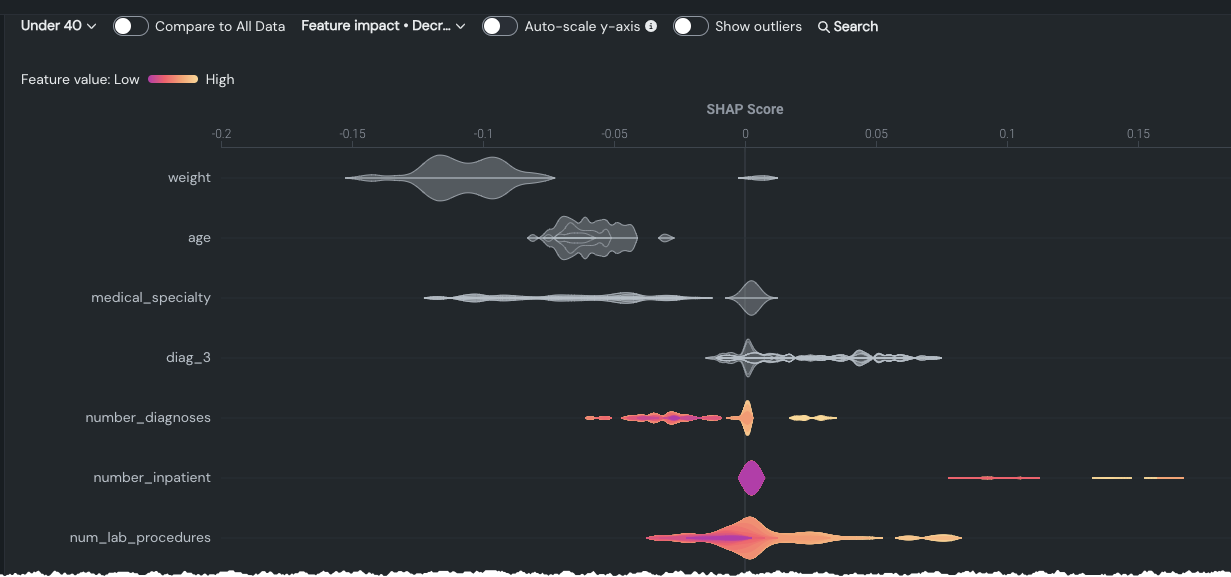
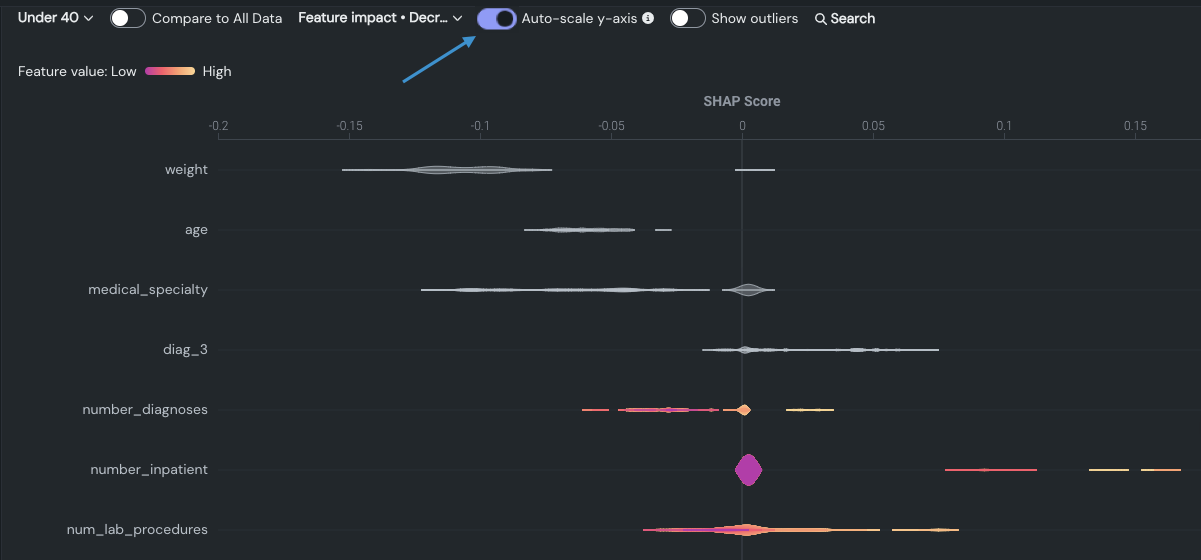
自動スケーリングの詳細については、 以下を参照してください。
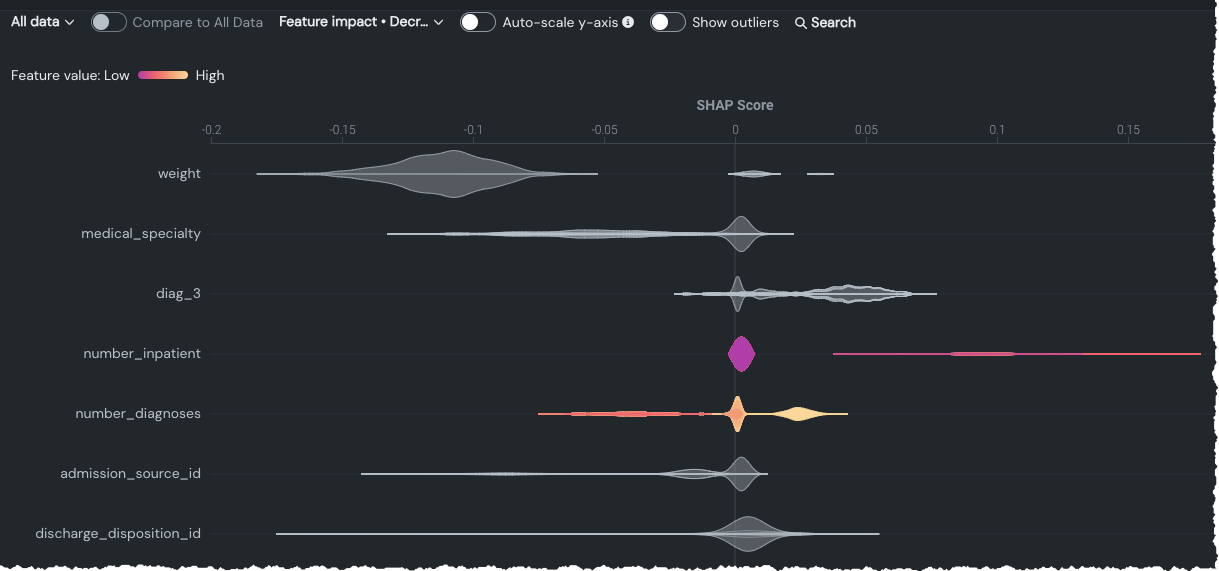
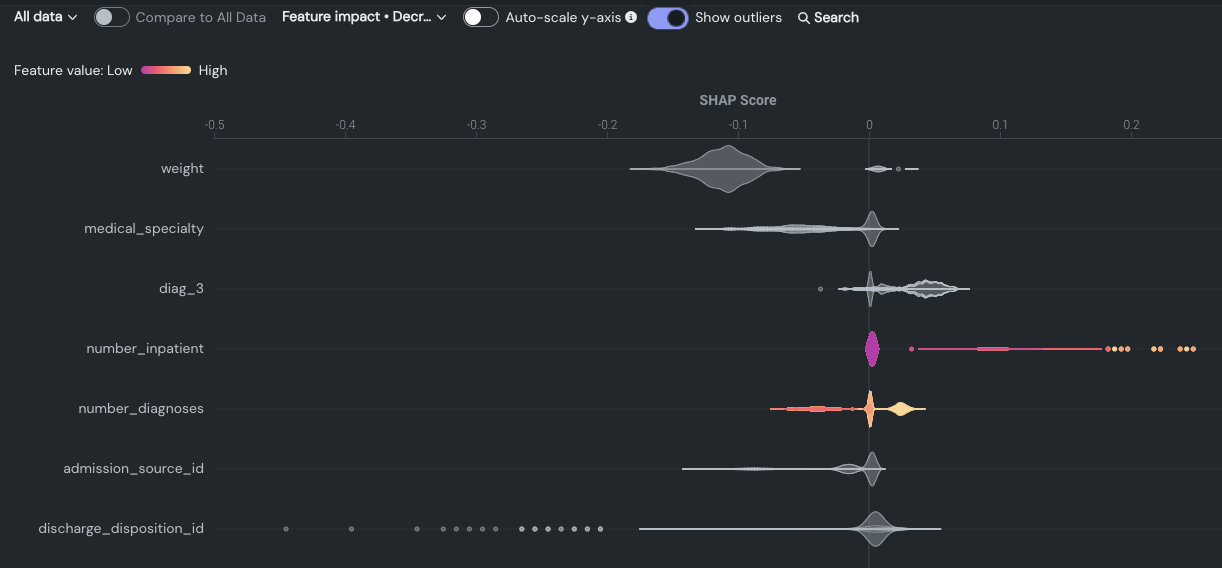
外れ値を表示¶
自動スケーリングが垂直アクセス(分布の高さ)に適用される場合、外れ値は横軸に適用されます。 外れ値は、主たるバイオリンから相対的に遠い値を示し、ビニング後に計算されます。 例:
外れ値の計算の詳細については、 以下を参照してください。
詳細:SHAP分布の解釈¶
表示される各バイオリンプロットは、最大1,000行のSHAP値に基づいています。 データセット全体またはデータセットのスライスされたサブセットのいずれかに1,000行未満の行しかない場合、バイオリンプロットはそれより少なくなります。 各特徴量について、DataRobotは1,000のデータポイントを均一なビンに分割します。 一般的に、分布を表す形状を比較するのにインサイトを使用します。 バイオリンプロットがクラスター(コホート)なのか、それとも一様なのかを評価することで、特徴量が強く影響する値のグループを持つのか、正の影響を与えるのか、またはほとんど影響しないのかを判断できます。
特徴量ごとのSHAPの視覚化では、色を使用して、予測にインパクトを与える特徴量の密度と分布を表します。
- 数値および二値(連続)特徴量は、紫色(低頻度)~黄色(高頻度)のカラースペクトル上にプロットされ、特徴量値の高い位置と低い値の位置を示します。
- カテゴリー(離散)特徴量はグレーで表示され、各バイオリンには異なるカテゴリーを表すバイオリンが埋め込まれています。
- その他の値はすべて青で表示されます。
水平軸は予測結果に対する特徴量の影響を表し、0は影響がないことを表します。 バイオリンプロットの大きなコホートがゼロの左側(すなわち、ゼロ未満)に位置している場合、その特徴量が予測結果から差し引かれることを意味し、ゼロより右側のコホートは予測結果に追加されます。 特徴量は、個々の行の値に応じて、両側に分布することがよくあります。 視覚化の解釈の詳細については、 以下を参照してください。
特徴量分布の視覚化¶
以下の例の連続特徴量num_lab_proceduresでは、コホートの大半が右側に位置すること、つまり予測結果に追加されることがわかります。
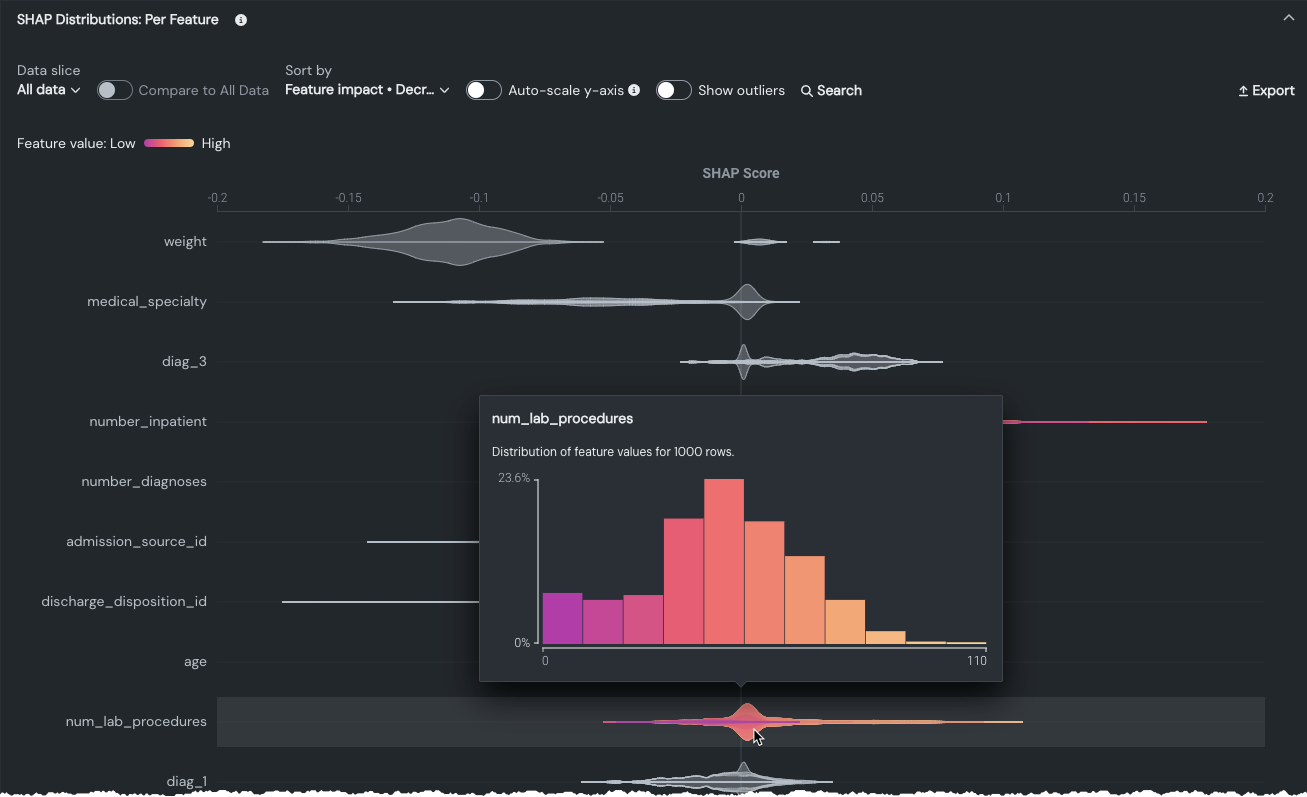
- バイオリンプロット全体で紫色が多いほど、検査手続きの回数が少ないことを示し、黄色が多いほど、検査手続きの回数が多いことを示します。
- ゼロの両側が紫一色や黄色一色というわけではありませんが、色分けは、検査手順の数が多いほど予測値に追加される傾向があることを示しています。 表示されたデータ(全データまたは選択されたスライス)のコンテキストで、個々の分布(最大1,000行)を理解するために特徴量にカーソルを合わせます。
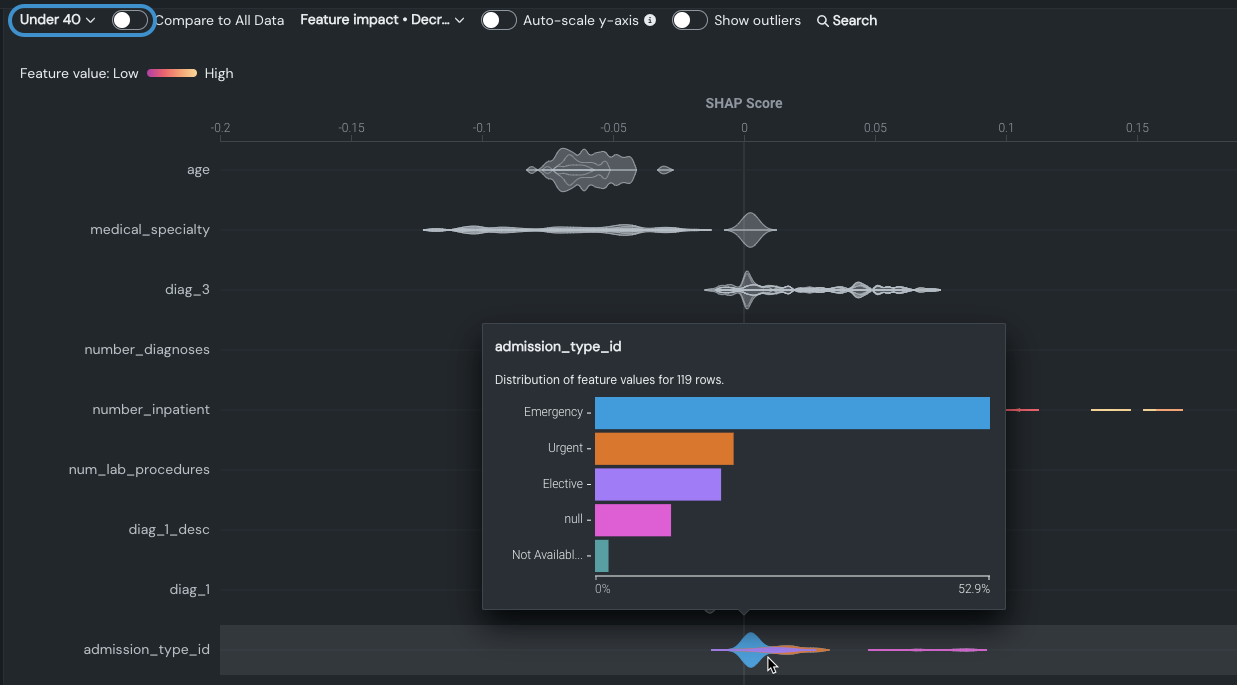
離散特徴量(フルプロットではグレー)にカーソルを合わせると、完全な分布の上位7クラスまでが表示されます。 他のすべての画像はグレーで表示されます。 たとえば、40歳未満の患者のadmission_type_idを見ると、emergencyの値は結果にほとんど影響を与えていないように見えますが、urgentは予測結果により強く影響していることがわかります。
自動スケーリング¶
DataRobotは、同じ行数(最大1,000行)をビニングしてバイオリンをプロットし、各バイオリン行は同じ垂直ピクセル高を使用します。 プロット上の最大の高さは、最も多くの行を含むビンを反映しており、いわゆる「最も高いピーク」を示します。
各バイオリン行の分布は異なり、時にはかなり大きな差があります。 1つの行は、その値の大部分が(水平方向に)狭いスパンにある場合があり、その結果、分布の高さとして高いピークが生じます。 また、行が水平方向に広く分布している場合があり、その結果、分布高さのピークが低くなります。
最大の高さは、任意の時点で視覚化に含まれる特徴量に基づいて動的に計算されます。 たとえば、スライスの適用、検索、より多くの特徴量の読み込みなどで表示を変更すると、最大の高さが更新され、それに応じて他のバイオリンプロットも再スケーリングされます。
外れ値を計算中¶
次の条件の両方を満たす場合、そのビンは 外れ値と見なされます。
- そのビンには、最大ビンのメンバーシップの2%未満しか含まれていない。
- そのビンは、最も近いビンから少なくとも1つの空のビンを挟んで離れている。
外れ値ビン内にある外れ値の数に関係なく、外れ値は常に同じサイズの円でマークされます。 つまり、メンバーシップが0.3%のビンとメンバーシップが0.7%のビンは区別されません。
