データインサイトの分析¶
| タイル | 説明 |
|---|---|
 |
頻出値など、データセット内の特徴量をより視覚的に表示します。 |
 |
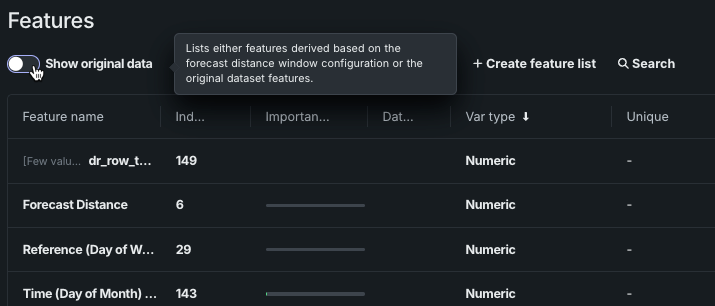
特徴量を表形式で、特徴量の有用性やサマリー統計とともに表示します。 特定の特徴量を選択すると、データプレビュータイルに表示されるものよりも詳細なデータインサイトが表示されます。 |
 |
新しい特徴量セットの作成、既存の特徴量セットの管理、異なる特徴量セットでのエクスペリメントの全モデルの再トレーニングができます。 |
 |
特徴量の関連性のインサイトを使用して、データ内の関連性を追跡および視覚化できます。 |
データプレビュータイル¶
データプレビュータイルでは、データセット内の特徴量が簡潔かつ視覚的に表示されます。
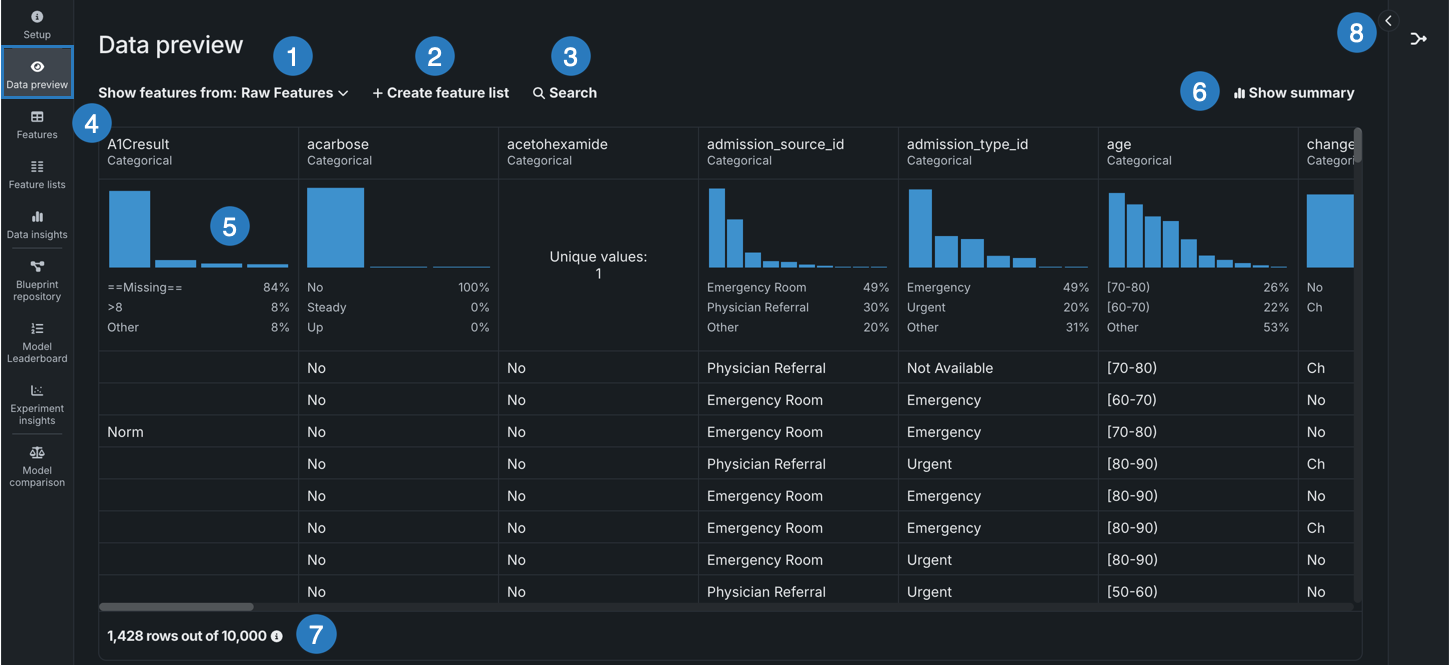
| 要素 | 説明 | |
|---|---|---|
| 1 | ドロップダウンから特徴量を表示 | 特定の特徴量セットに含まれる特徴量を表示できます。 |
| 2 | + 特徴量セットを作成 | 新しい特徴量セットを作成します。 |
| 3 | 検索 | 現在表示しているデータセットまたは特徴量セットで特定の特徴量を検索します。 |
| 4 | 特徴量 | 選択された特徴量セットについて各特徴量行と列を表示します。 |
| 5 | 頻出値チャート | 特徴量の最大頻出値に対する個々の値のカウントがプロットされます。 |
| 6 | サマリーを表示 | データセットの以下のサマリー情報を表示します。
|
| 7 | プレビューサンプル | データセットの全行数のうち、プレビューの生成に使われた行数を表示します。 |
| 8 | ラングリングレシピ | データセットに関連付けられたラングリングレシピ(該当する場合)を表示したり、データセットのラングリングを続行したりできます。 |
追加のサマリー統計およびインサイトを表示する特徴量を選択します。
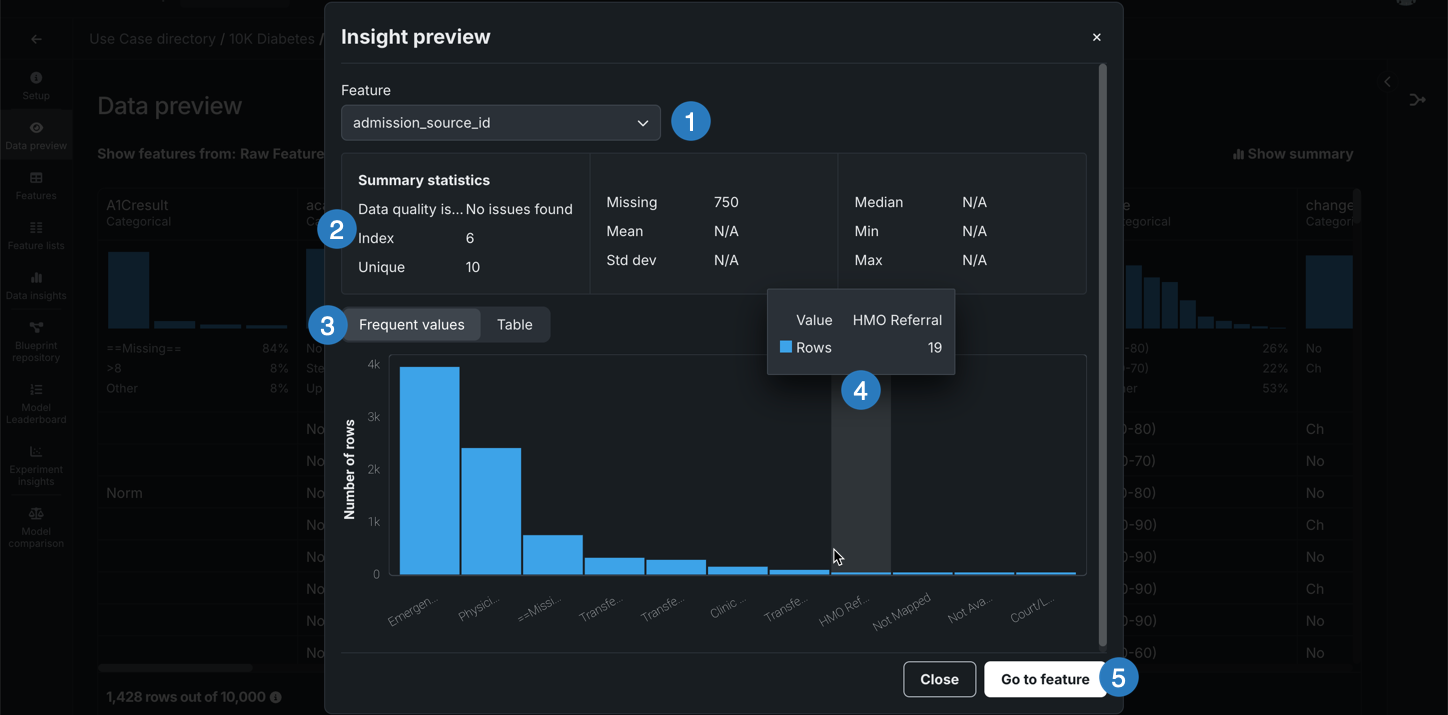
| 要素 | 説明 | |
|---|---|---|
| 1 | 特徴量ドロップダウン | 現在表示中の特徴量を変更できます。 |
| 2 | サマリー統計 | データ品質の問題や一意の値など、特徴量のサマリー統計を表示します。 |
| 3 | インサイト | その特徴量の型で取得可能なインサイトを表示できます。 |
| 4 | 詳細を表示 | チャートにカーソルを合わせると、追加情報が表示されます。 |
| 5 | 特徴量に移動 | 特徴量タイルを開き、表示していた特徴量を展開します。 |
特徴量タイル¶
特徴量タイルには、データセットの特徴量とサマリー統計が表示され、データをより深く理解するための追加のインサイトや情報も確認できます。
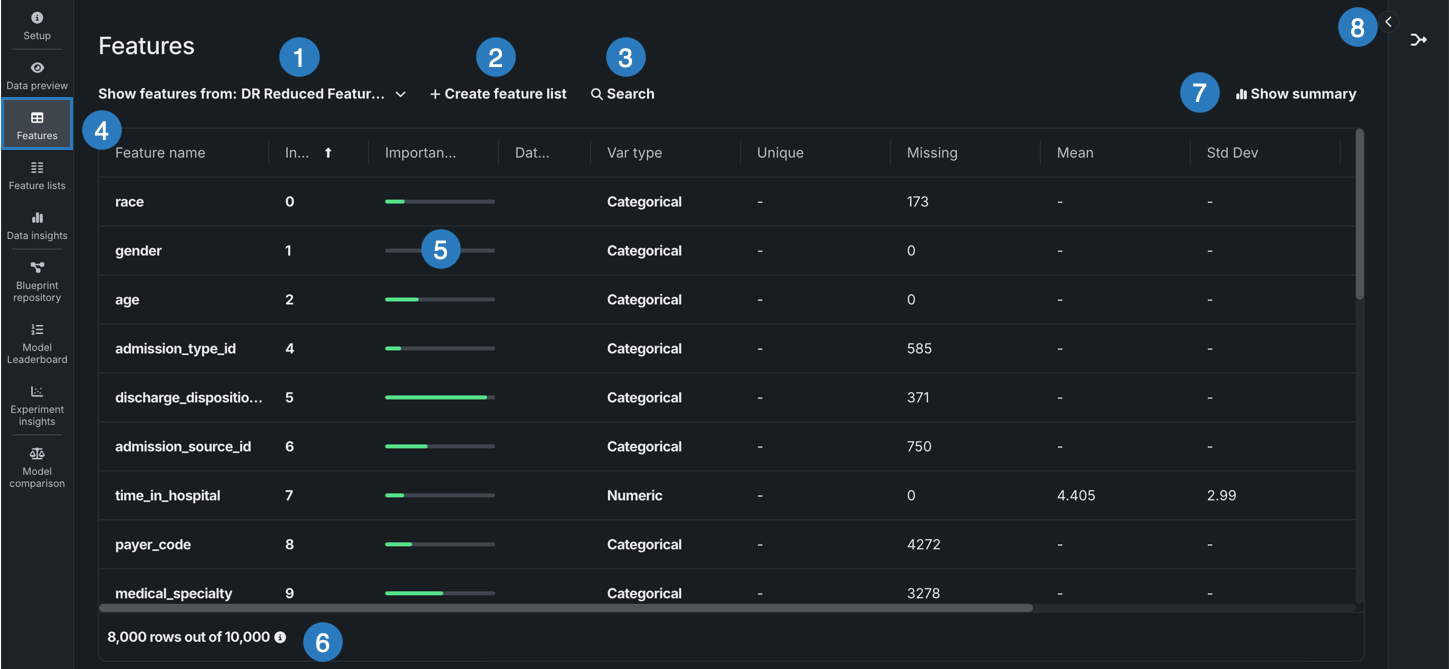
| 要素 | 説明 | |
|---|---|---|
| 1 | ドロップダウンから特徴量を表示 | 特定の特徴量セットに含まれる特徴量を表示できます。 |
| 2 | + 特徴量セットを作成 | 新しい特徴量セットを作成します。 |
| 3 | 検索 | 現在表示しているデータセットまたは特徴量セットで特定の特徴量を検索します。 |
| 4 | 特徴量 | 選択された特徴量セットに含まれる各特徴量、および各特徴量のサマリー統計を表示します。 |
| 5 | 有用性列 | 有用性列に緑色のバーを表示します。これは、1つの特徴量自体がターゲット特徴量の有用性とどの程度相関しているかを示す尺度です。 |
| 6 | プレビューサンプル | データセットの全行数のうち、プレビューの生成に使われた行数を表示します。 |
| 7 | サマリーを表示 | データセットの以下のサマリー情報を表示します。
|
| 8 | ラングリングレシピ | データセットに関連付けられたラングリングレシピ(該当する場合)を表示したり、データセットのラングリングを続行したりできます。 |
追加のサマリー統計およびインサイトを表示する特徴量を選択します。
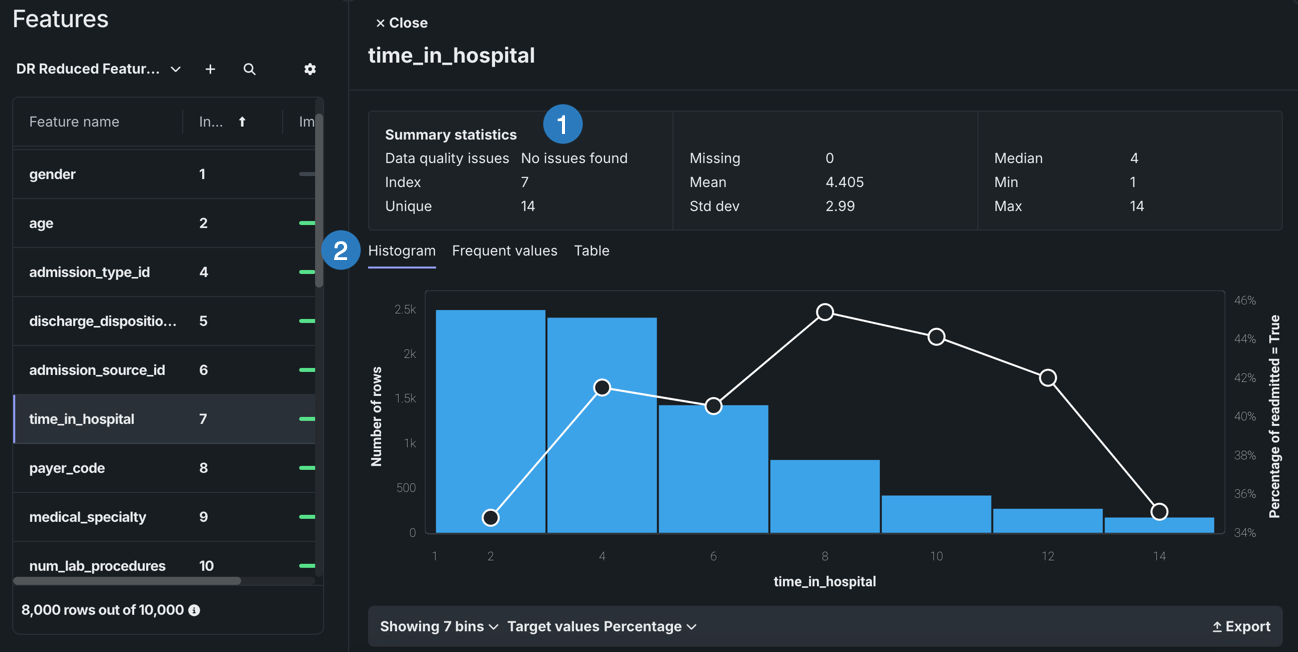
| 要素 | 説明 | |
|---|---|---|
| 1 | サマリー統計 | データ品質の問題や一意の値など、特徴量のサマリー統計を表示します。 |
| 2 | インサイト | その特徴量の型で取得可能なインサイトを表示できます。 |
特徴量セットタイル¶
特徴量セットタイルには、エクスペリメントに関連付けられたすべての特徴量セットが表示されます。 特徴量セットは、DataRobotでモデルの構築と予測に使用する特徴量のサブセットを制御します。 ターゲットリーケージの原因となる特徴量を除外したり、または重要でない特徴量を削除して予測を高速化したりできます。
特徴量セットタイルを選択すると、DataRobotによって自動的に作成されたセットとカスタム特徴量セット(この例では"demographics"と"FiveFeatures")の両方が表示されます。
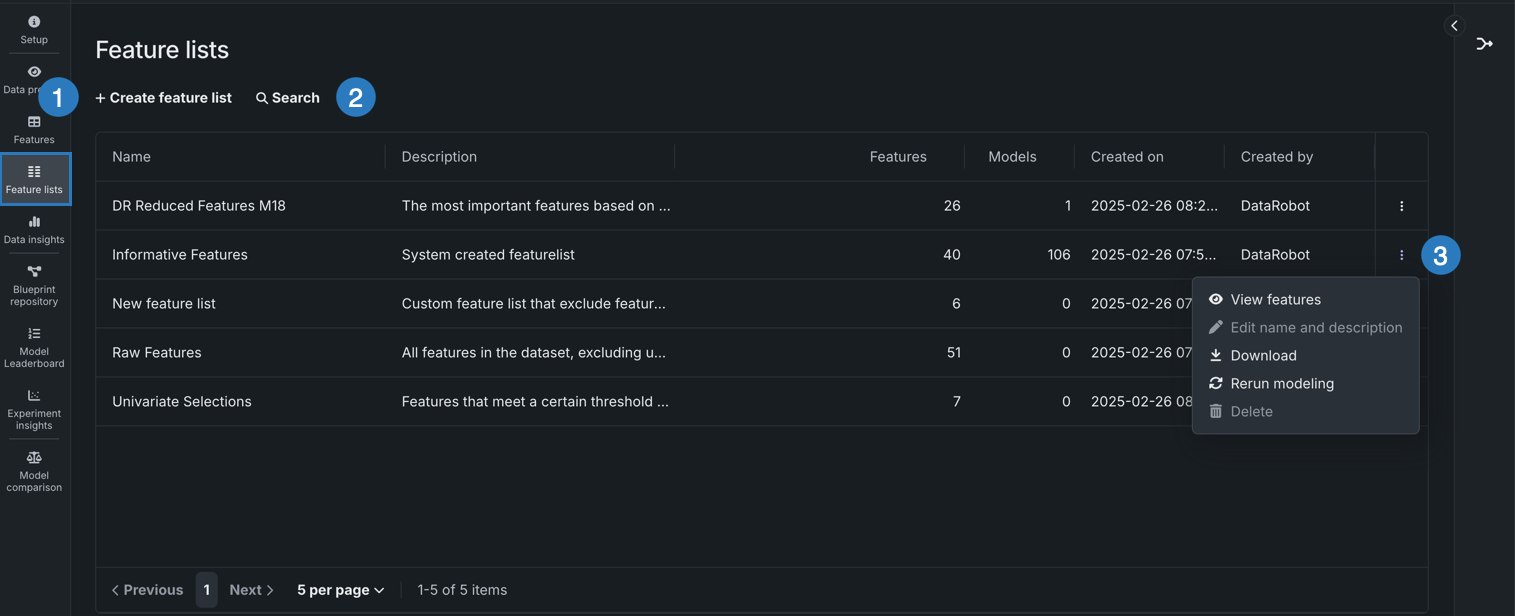
| 要素 | 説明 | |
|---|---|---|
| 1 | + 特徴量セットを作成 | カスタム特徴量セットを作成できます。 詳細については特徴量セットを作成を参照してください。 |
| 2 | 検索 | 検索バーに入力されたキーワードに基づいて、既存の特徴量セットをフィルターします。 |
| 3 | アクションメニュー | 特定の特徴量セットのアクションメニュー を開きます。 |
アクションメニュー から、特徴量セットに対して以下のアクションを実行できます。
| アクション | 説明 |
|---|---|
| 特徴量を表示 | 特徴量セットのインサイトを探索します。 この選択により、フィルターが選択したセットに設定された特徴量タブが開きます。 |
| 名前と説明の編集 | (カスタムリストのみ)リスト名を変更し、説明を変更または追加するダイアログが開きます。 |
| ダウンロード | そのセットに含まれる特徴量を.csvファイルとしてダウンロードします。 |
| モデリングを再実行 | モデリングを再実行モーダルが開き、新しい特徴量セットの選択、GPUワーカーによるトレーニング、オートパイロットの再起動が可能になります。 |
| 削除 | (カスタムリストのみ)選択したリストがエクスペリメントから完全に削除されます。 |
カスタム特徴量セットは、モデリング前にデータエクスプローラーから、またはモデリング後にデータプレビュー、特徴量、またはこのタイルから作成できます。 新規リストの作成については、 カスタム特徴量セットのリファレンスを参照してください。
エクスペリメントから作成されたリストは以下の通りであることに注意してください。
- エクスペリメント内で、モデルの再トレーニングやブループリント リポジトリから新しいモデルのトレーニングに使用されます。
- ユースケースのすべてのエクスペリメントにわたってではなく、そのエクスペリメント内でのみ使用できます。
- データエクスプローラーでは使用できません。
データインサイトタイル¶
データ内での関連性を追跡および視覚化するのに役立つ特徴量の関連性のインサイトを表示します。
使用可能なインサイト¶
モデリングが完了したら、特徴量名をクリックして詳細を表示し、(場合によっては)タイプを変更することもできます。 使用可能なオプションは特徴量の型に応じて異なります。
| インサイト | 説明 | 特徴量の型 | | |-----------|-------------|-----------------| | ヒストグラム | 数値特徴量値を均等なサイズの複数の範囲にバケット化して、特徴量の大まかな分布を示します。 | 数値、集計されたカテゴリー型特徴量、多カテゴリー | | 頻出値 | 特徴量の最大頻出値に対する個々の値のカウントがプロットされます。 10以上のカテゴリーがある場合、DataRobotにはデータの95%を占める値が表示されます。残りの5%の値は、単一の「その他すべて」カテゴリーに区分けされます。 | 数値、分類、テキスト、ブール型 | | 表 | 特徴量の値とその発生数の表が表示されます。 表示される値の先頭にスペースが含まれる場合、その旨を示すタグ(先頭にスペース)が表示されます。 これは、特定の同じに見える値がヒストグラムで2回表示される理由を明確にする際に役立ちます(36か月と36か月の両方が表示される場合など)。 | 数値、カテゴリー、テキスト、ブーリアン、集計されたカテゴリー型特徴量、多ラベル | | 例示 | 集計されたカテゴリーデータ(カテゴリーのコレクションをホストする特徴量)が特徴量としてどのように表されるかを示します。 概要とヒストグラムに関する詳細については、集計されたカテゴリータブの差異も参照してください。 | 集計されたカテゴリー型特徴量 | | カテゴリークラウド | EDA2が完了すると、対応する特徴量に最も関連性が高いキーがワードクラウド形式で表示されます。 これはカテゴリークラウドからアクセスできるワードクラウドと同じです(インサイトページ)。 | 集計されたカテゴリー型特徴量 | | 特徴量の統計 | 多ラベルデータセットの全体的な特性に加え、ラベルのペアに対するペア単位の統計や各ラベルのデータセット内への出現率を報告します。 | 多ラベル | | 時間の経過(時間認識のみ) | 元のモデリングデータと派生データの両方でプライマリー日付/時刻特徴量で特徴量がどのように変化するかを表示することによって、トレンドと潜在的なギャップを識別できます。 | 数値、分類、テキスト、ブール型 | | 特徴量の系統 (時系列) または (特徴量探索) | 派生した特徴量がどのように作成されたかを視覚的に説明します。 | 数値、分類、テキスト、ブール型 | | 特徴量の関連性 | データインサイトタイルからのみ取得できます。 有用性スコアを使用した行列を提供し、データ内の関連性を追跡および視覚化するのに役立ちます。 X軸とY軸の両方に、クラスター別にソートされた上位50の特徴量がリストアップされます。 | N/A | | データ品質評価 | 一般的なデータ品質の問題を検出して表示し、多くの場合、ユーザーによる操作を最小限に抑えて、あるいはまったく操作を必要とせずに処理します。 | N/A |
備考
特徴量の値と表示は、EDA1(データアセットから表示)とEDA2(エクスペリメントから表示)で異なる場合があります。 EDA1の場合、チャートはデータセットから直接取得したデータを表します。 ターゲットと構築モデルを選択した後、ホールドアウトや欠損値などが原因で、データの計算において行数が少なくなることがあります。 また、EDA2 の後、平均ターゲット値が表示されます。(EDA1では計算されません。)
ヒストグラム¶
ヒストグラムチャートは数値特徴量のデフォルト表示です。 数値特徴量の値を同じサイズの各範囲に「バケット化」して特徴量の度数分布を示し、値の頻度(X軸)に対してターゲット観測値(左Y軸)をプロットします。 それぞれの棒の高さは、その範囲内の値を持つ行数を表します。
EDA2が完了すると、ヒストグラムに平均ターゲット値オーバーレイも表示されます。
詳細については、特徴量の詳細とヒストグラムチャートのドキュメントを参照してください。
頻出値¶
頻出値チャートはヒストグラムで、特徴量の各値を含む行の数と、ターゲットの値ごとの行の割合を示すだけでなく、インライア、偽装欠損値、および過剰なゼロも報告します。
頻出値チャートは、カテゴリー、テキスト、ブール型の特徴量のデフォルト表示です(その他の特徴量タイプでも使用可能です)。 表示は、データ品質チェックの結果に応じて異なります。 カテゴリー特徴量やブーリアン特徴量などの一部の特徴量では、頻出値インサイトがデフォルトです。
EDA2が完了すると、頻出値チャートには平均ターゲット値オーバーレイも表示されます。
特徴量値チャートには、データセットにある特徴量の各値と、その値を持つ行の数が表示されます。 データ品質の問題がない場合:
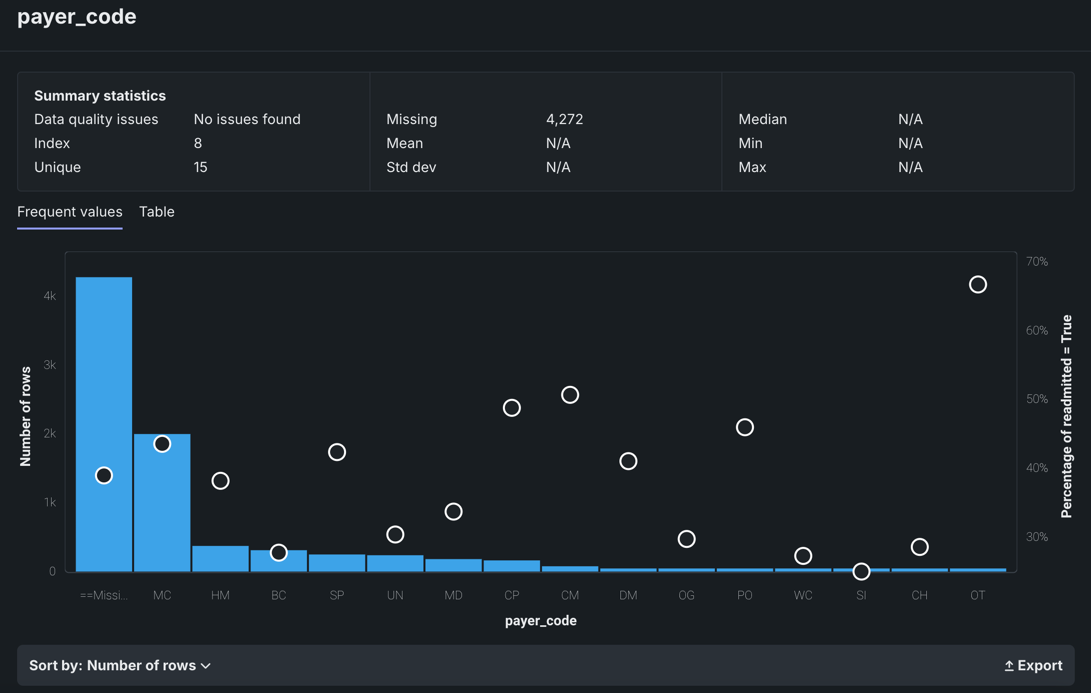
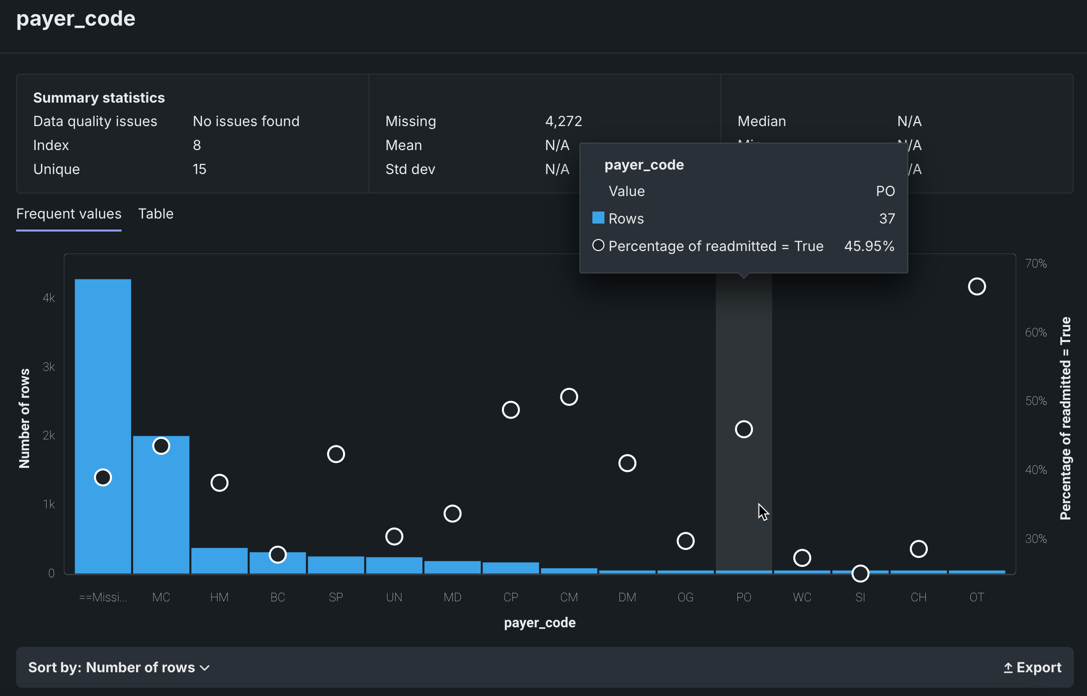
多くの場合、ソート順ドロップダウンで表示を変更できます。 デフォルトでは、頻度(行数)で降順にソートされます。 また、<feature_name>で並べ替えることもできます。この場合は、アルファベット順、または数値の場合は小さい順に表示されます。 エクスポートリンクを使用すると、頻出値チャートの画像をPNGファイルとしてダウンロードできます。
ヒストグラムに重ねて表示された白い円に注目してください。 円はビンの平均ターゲット値を示します。
特徴量の系統¶
特徴量の系統インサイト(特徴量探索と時系列エクスペリメントで取得可能)は、特徴量がどのように派生したか、および特徴量派生プロセスに関係したデータセットを視覚的に説明します。 ここでは、元のデータセット(左側)から特徴量(右側)を生成するために使用された手順が可視化されます。 各要素は、アクションまたはJOINを表します。
詳細については、特徴量探索と時系列のドキュメントを参照してください。
時間経過¶
時間経過チャートでは、元のモデリングデータと派生データの両方について、プライマリー日付/時刻特徴量に対する特徴量の変化を表示することで、データの傾向や潜在的なギャップを特定できます。 すべての時間認識エクスペリメント(OTV、単一系列、複数系列)で利用できます。 時系列の場合、ユーザー設定の各予測距離に使用できます。
詳細については、特徴量の時間経過チャートを理解するを参照してください。
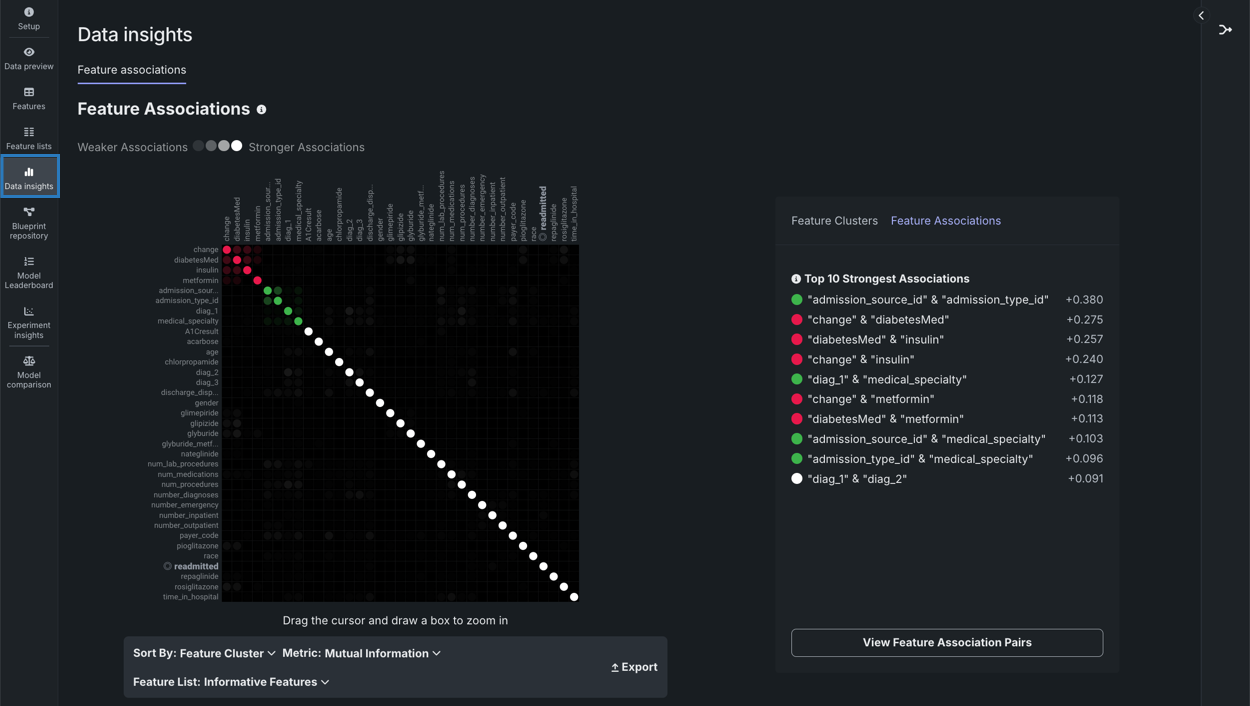
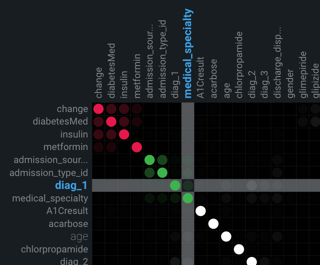
特徴量の関連性¶
データインサイトタイルからアクセスできる特徴量の関連性のインサイトでは、データ内での関連性を追跡および視覚化するのに役立つ行列が提供されます。 この情報は、次のようなさまざまな指数から派生します。
- 複数の特徴量が相互にどれだけ依存するかを決定するために役立つ指標。
- 特徴量を個別のクラスターまたは「ファミリー」にパーティション分割するプロトコルを提供します。
行列は次のとおりです。
行列を使用するには、エクスペリメント内でデータインサイトタイルをクリックします。
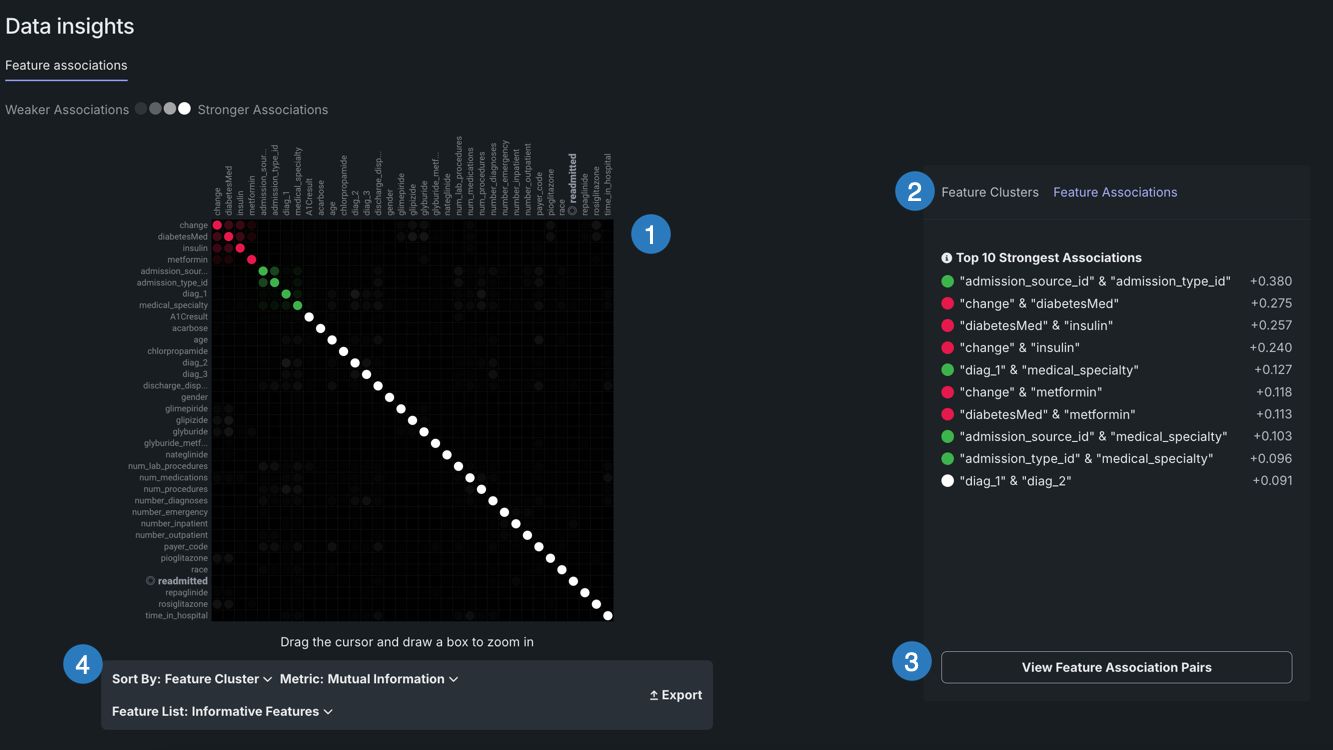
| 要素 | 説明 | |
|---|---|---|
| 1 | 行列 | X軸とY軸の両方で、クラスター別に上位50個までの特徴量を一覧表示します。 |
| 2 | 詳細ペイン | クラスター、一般的な関連性、および関連性ペアに関するより具体的な情報を表示します。 |
| 3 | 特徴量ペア | 特定の特徴量ペア間の関連性と関係性を表示します。 |
| 4 | 行列のコントロール | ビューを変更できます。 |
特徴量の関連性の行列は、数値およびカテゴリー特徴量と特徴量クラスターのペア(数値/カテゴリー、数値/数値、カテゴリー/カテゴリー)の間の関連性の強さに関する情報を提供します。 クラスターは、行列上で色分けされた特徴量のファミリーであり、類似性に基づいてグループに分割された特徴量です。 行列の直感的な可視化により、以下のことが可能になります。
- 関連性分析をすばやく実行し、データに関する理解を深める。
- 関連性の強さと本質を理解する。
- ペア単位の関連性クラスターの群を検出する。
- モデル構築の前に高関連性の特徴量のクラスターを識別する(モデル入力に各グループ内の1つの特徴量を選択する一方でその他の特徴量を差分化するなど)。
行列の表示¶
EDA2が完了すると行列が使用可能になります。 X軸とY軸の両方に、クラスター別にソートされた上位50の特徴量がリストアップされます。 特徴量ペアの交点は、特徴量の同時生起のレベルを示します。 デフォルトでは、行列は相互情報量の値で表示されます。
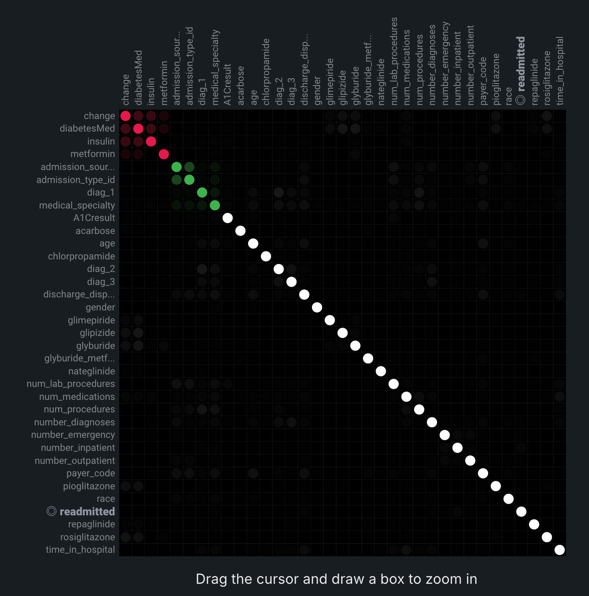
デフォルトの行列からは、一般的に次のような結論が得られます。
- ターゲット特徴量は白の太字で表示されます。
- 個々の点は、2つの特徴量(特徴量ペア)の間の関連性を表します。
- 各クラスターは異なる色で表されます。
- 色の不透明度は、特徴量ペアの間における0~1の同時生起(関連または依存)を示します。 レベルは、相互情報量またはクラメールのVのいずれかの設定指標によって測定されます。
- 灰色の網掛けの点は、2つの特徴量が何らかの依存を示しているものの、同じクラスターに入っていないことを示します。
- 白い点は、クラスターに分類されなかった特徴量を表します。
- 「弱い ... 強い」の関連凡例は、指標内の点の不透明度が指標スコアの強さを表すことを示します。
行列内の点をクリックすると、右側の詳細ペインが更新されます。 デフォルトビューをリセットするには、選択したセルを再度クリックします。 表示条件を変更するには、行列の下のコントロールを使用します。
行列は、二値分類、連続値エクスペリメント、および多クラスのACE(有用性)スコアで上位50の特徴量をランク付けする有用性でフィルターすることもできます。
行列内の点をクリックすると、2つの特徴量の間の関連性がハイライトされます。
カーソルをドラッグすると、行列の任意のセクションの周囲に境界を描画できます。 行列がズームされ、描画した境界内のポイントだけが表示されます。 行列全体の表示に戻るには、行列の下にあるズームをリセットをクリックします。
行列ビューは、ソート条件を変更するか、関連性を計算する指標を変更することによって変更できます。 これらのコントロールは、行列の下にあります。
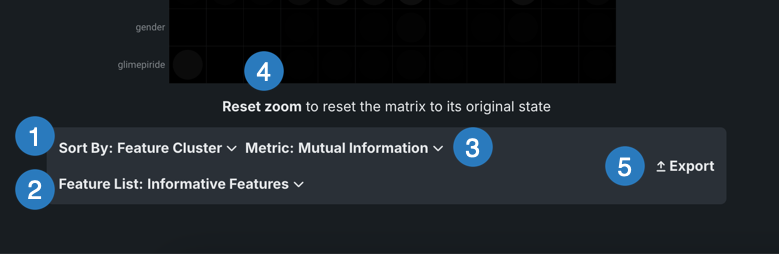
| 要素 | 説明 | |
|---|---|---|
| 1 | ソート条件ドロップダウン | 以下の条件で並べ替えできます。
|
| 2 | 特徴量セットのドロップダウン | エクスペリメントの特徴量セットで特徴量の関連性を計算できます。 リストを選択すると、ページがリフレッシュされ、選択した特徴量セットのマトリクスが表示されます。 |
| 3 | 指標ドロップダウン | 相互情報量またはクラメールのVの相関アルゴリズムを使用して、特徴量ペア間の関連性の計算方法を決定します。 |
| 4 | リセットズーム | 行列の一部を強調表示して詳細を確認した場合は、行列全体の表示に戻ります。 |
| 5 | エクスポート | 行列全体またはズームされた行列をエクスポートします。 |
詳細ペイン¶
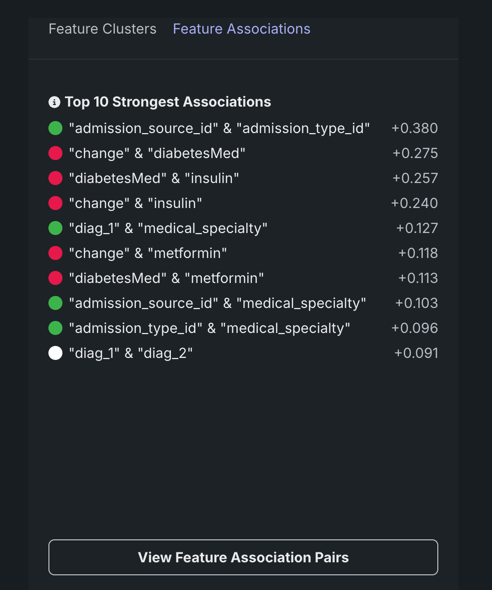
デフォルトでは、行列セルが選択されていない状態で詳細ペインは、以下のように動作します。
- 最も強い関連性を、関連性指標スコアでランク付けして表示します。
- 識別されたすべてのクラスターのリスト(特徴量クラスタータブ)とその平均指標(wb-feat-associate){ target=_blank }スコアを表示します。
- 特徴量ペアの関連性の詳細のチャートへのアクセスを提供します。
リストは、行列を計算するときにDataRobotで実行される内部計算に基づきます。
行列でセルが選択されると、特徴量の関連性タブが更新され、選択された特徴量のペアに固有の情報が反映されます。
フィールドの説明を次の表示示します。
| カテゴリー | 説明 |
|---|---|
| 「特徴量_1」および「特徴量_2」 | |
| クラスター | ペアの両方の特徴量が属するクラスター(または別のクラスターからの場合)には「なし」と表示されます。 |
| 指標名 | 依存特徴量が相互に有する指標。 値は指標セット(相互情報量またはクラマーのVのいずれか)に依存します。 |
| 「特徴量_1」の詳細 「特徴量_2」の詳細 |
|
| 有用性 | 正規化された有用性スコア(3桁)は、ターゲットに対する特徴量の有用性を示します。 |
| タイプ | 特徴量のデータ型(数値または分類)。 |
| 平均 | 特徴量の平均値。 |
| 最小/最大 | 特徴量の最小値と最大値。 |
| 「特徴量_1」との強い関連性 | |
| 特徴量_1 | 行列上の特徴量の交点を選択すると、指標スコアに基づいて関連性が最も強い5つの特徴量のリストが表示されます。 |
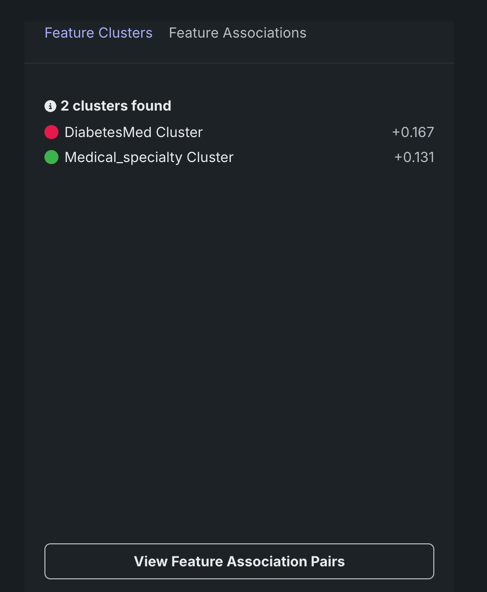
デフォルトでは、見つかったすべてのクラスターが平均指標スコアでランク付けされて表示されます。 これらのランク付けは、相互依存が最も強いクラスターを示します。 表示名は、クラスター内でターゲットに相対的な有用性スコアが最も高い特徴量に基づきます。 行列内のポイントをクリックすると、特徴量クラスタータブの表示が変更されて、以下の内容がレポートされます。
- クラスターのスコアの詳細。
- クラスター内のすべての特徴量のリスト。
特徴量の関連性ペア¶
特徴量の関連性ペアを表示をクリックして、特徴量ペアの2つの特徴量の間の個々の関連性のプロットを表示するモデルを開きます。 結果のインサイトでは、計算にインパクトを与える値「関連性の測定基準」を確認できます。 最初、プロットは、行列内で選択された点に自動入力されます(これらの点は詳細ペインでもハイライトされます)。 各表示では、指標スコアが最も高い特徴量が属するクラスターに加えて、特徴量ペアの指標関連性スコアが表示されます。特徴量は、モデル(およびクラスターとスコア更新)から直接変更できます。

特徴量クラスタータブからアクセスしても、特徴量の関連性タブからアクセスしても、インサイトは同じです。 表示されたインサイトは、PNGをダウンロードをクリックして保存できます。
表示されるプロットは、データ型に応じて3つの種類があります。
- 数値特徴量と数値特徴量を比較する散布図。
- 数値特徴量とカテゴリー特徴量を比較する箱ひげ図。
- カテゴリー特徴量とカテゴリー特徴量を比較する分割表。
各種類の例と共にインサイトから取得できる内容を以下に示します。
数値特徴量と数値特徴量を比較する場合、散布図では、X軸に結果の範囲が示されます。 点のサイズ(または重複する点)は、値の頻度を表します。
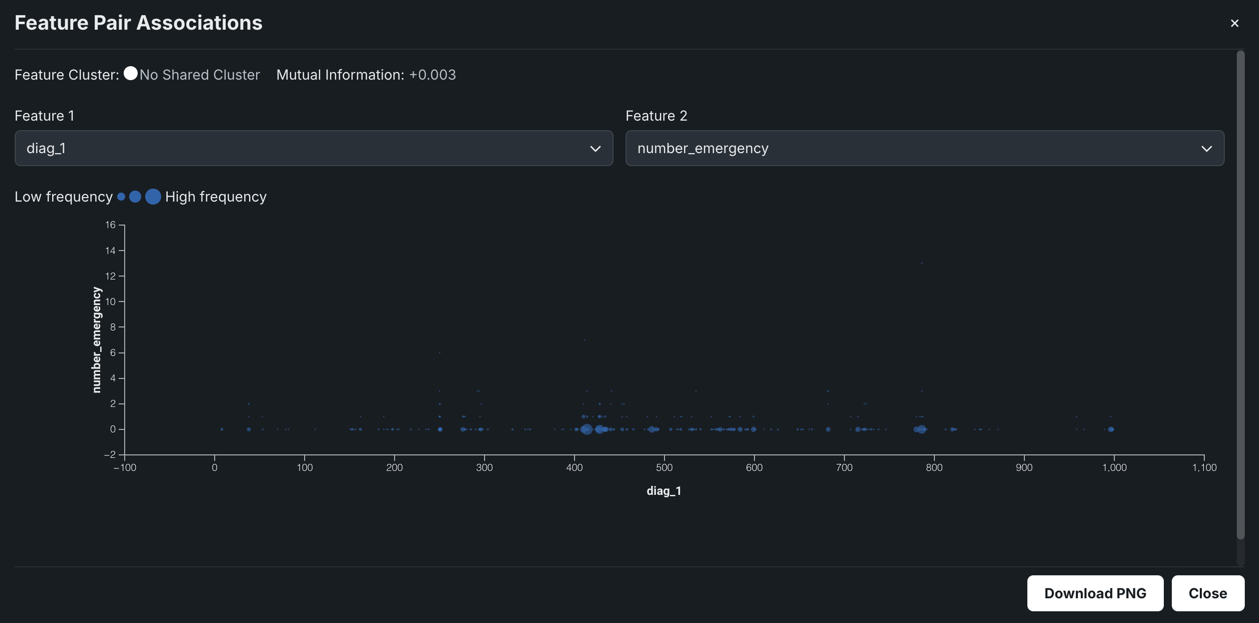
たとえば、上記のチャートでは、12m_interestとreviews_seasonalで明らかな関連が認められないので、2つの特徴量が共有する相互情報量は非常に低いと考えられます。
箱ひげ図は、データのグループの上位四分位点と下位四分位点をグラフィカルに表示します。 箱ひげ図は、分布が歪んでいるかどうか、およびデータセットに多くの外れ値が含まれているかどうかを判断する際に役立ちます。 X軸またはY軸にどの特徴量を設定するかに応じて、プロットは垂直または水平方向の形になります。 いずれの場合でも、エンドポイントは最大値と最小値を示し、箱は値の最高発生数を示します。 DataRobotでは、数値特徴量とカテゴリー特徴量のペアのインサイトを作成するために箱ひげ図が使用されます。
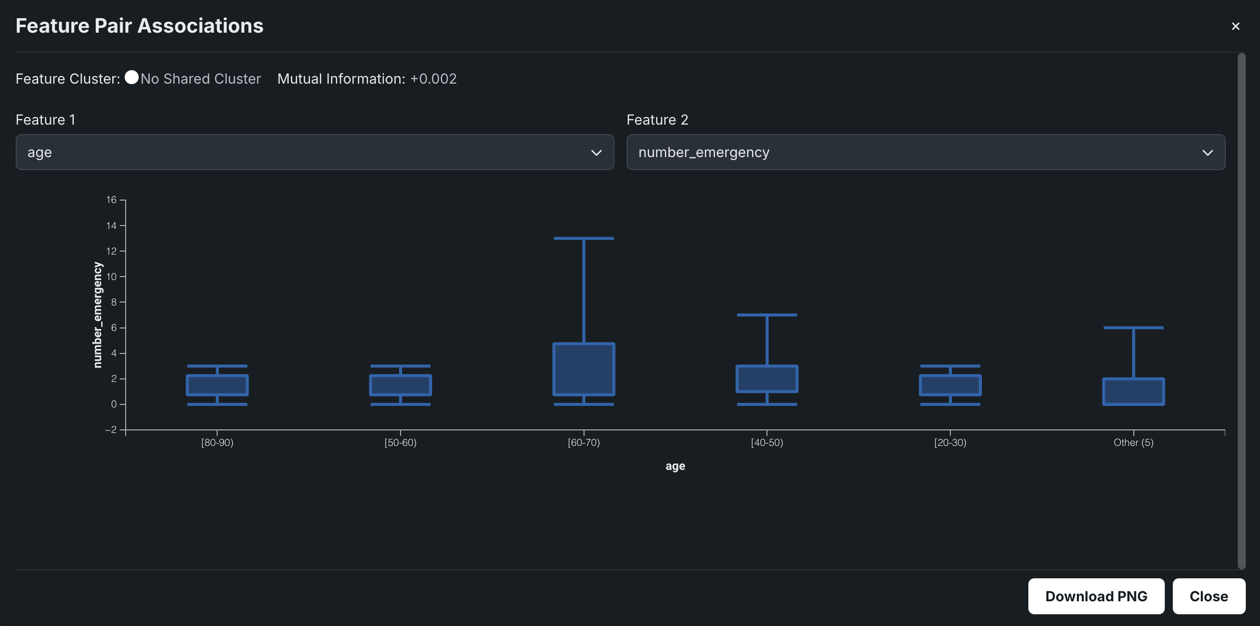
上の例では、プロットはonline_sitesの特徴量がバラつくのはE1の箇所であることを示してします。 その他の地域間では、はらつきはほとんどありません。
両方の特徴量がカテゴリー特徴量である場合、選択した特徴量の値の頻度分布を示す分割表が作成されます。 分割表には、最大6つのビンが含まれます。 各ビンは一意の特徴量値を表します。5つ以上の一意の値のある特徴量の場合、上位の5つが表示されます。残りの値は、「その他」という名前のビンに集約されます。
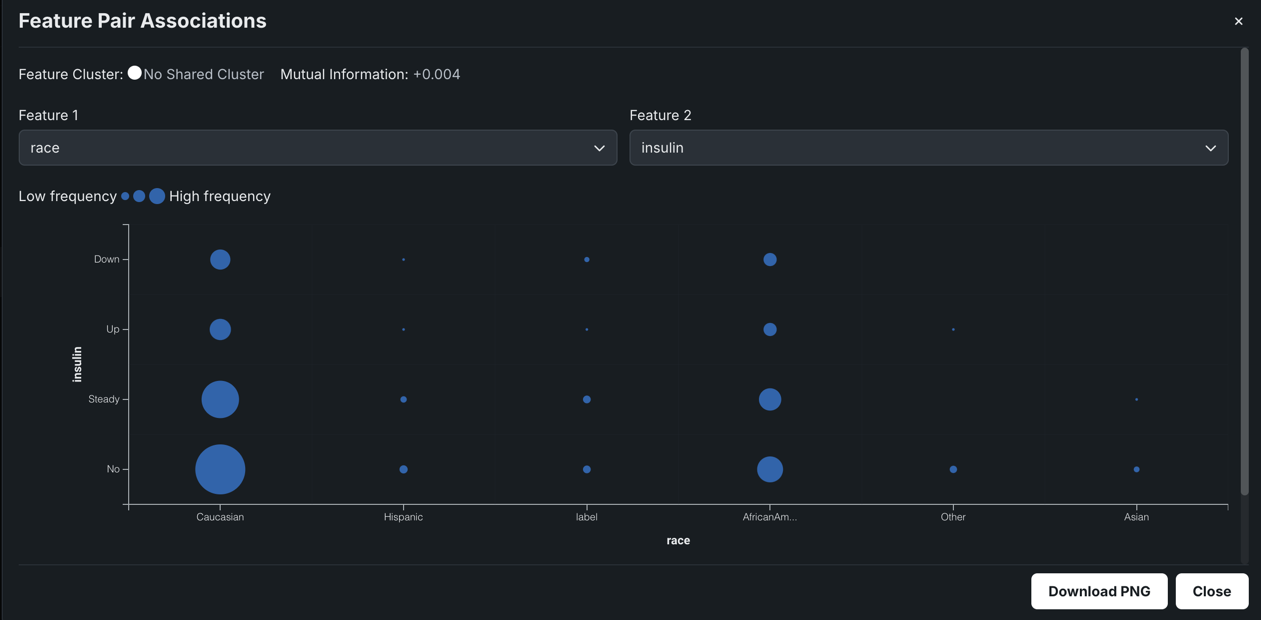
分割表の意味を以下に示します。9か月のバケットよりも多くの合計レビューがあるので、12か月のバケット内の点はすべて大きく表示されます。 レビュー_部門バケット全体の点のサイズに多くのばらつきはないので、最新の_応答に関するナレッジによってレビュー_部門に関するナレッジは向上しません。 結果は低い指標スコアです。
有用性スコア¶
特徴量タイルの有用性列に表示されている緑色のバーは、1つの特徴量が単独でターゲット特徴量とどの程度相関しているかを示します。 バーにカーソルを合わせると、正確な値が表示されます。
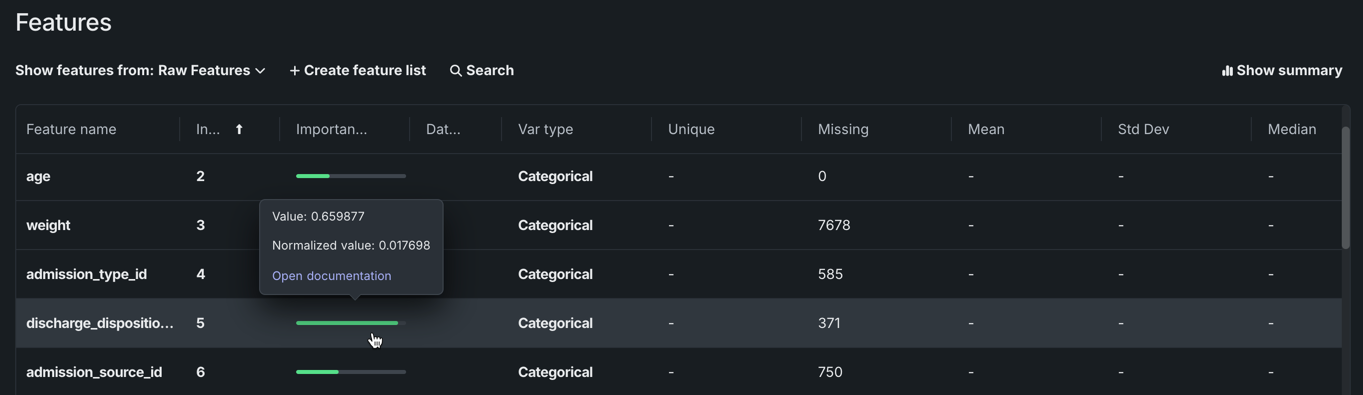
有用性とは?
有用性バーは、特徴量がターゲットと相関している度合いを示します。 これらのバーは、「交替条件付き期待値」(ACE)スコアに基づいています。 ACEスコアは、ターゲットとの非線形関係性を検出できますが、単変量であるため、特徴量間の交互作用効果を検出できません。 有用性は、変数の情報内容を測定するアルゴリズムを使用して計算されます。計算はそれぞれの特徴量ごとに行われます。 有用性スコアは、2つのコンポーネント(ValueおよびNormalized Value)が含まれます。
Value:これにより、その特徴量だけを使用してモデルを構築する場合に期待される指標スコアが(概ね)分かります。 多クラスの場合、Valueは各クラスの二値有用性上位モデルからの加重平均として計算されます。 二値分類および連続値の場合、選択したプロジェクト指標を使用して検定セットで評価された有用性上位モデルからの予測です。Normalized Value:正規化されたValue。1までのスコア(スコアが高いほど良い)。 0は、精度がトレーニングターゲットの平均を予測することと同じであることを意味します。 スコアが0未満の場合は、ACEモデルの予測がターゲットの平均モデルよりも劣っていること(過剰適合)を意味します。
これらのスコアは、その特徴量だけを使用してターゲットを予測するシンプルなモデルの予測能力の指標を示します。 (スコアはエクスポージャーによって調整されますが、これはエクスポージャーパラメーターを使用している場合のみ行われます。) スコアは、プロジェクトの精度指標を使用して測定されます。
特徴量は、最も有用性の高いものから低い順にランク付けされています。 各特徴量の横にある緑色のバーの長さは、その相対的な有用性を示しています。—バーの全長と比較したバーの緑色の量は、潜在的な特徴量の最大の有用性を示しています(Normalized Valueに比例しています)。—バーの緑色が強いほど、その特徴量がより高い有用性であることを示しています。 緑色のバーの上にマウスを置くと両方のスコアが表示されます。 これらの数値は、その特徴量だけを使用するモデルのプロジェクト指標(プロジェクトが実行されたときに選択された指標)に関するスコアを表しています。 リーダーボードで指標を変更してもツールチップに表示されるスコアには影響しません。
データ品質評価¶
データ品質評価機能は、一般的なデータ品質の問題を自動的に検出して表面化し、多くの場合、ユーザーのアクションを最小限(または完全)に抑えて、それらを処理します。 評価は、問題の発見と対処にかかる時間を節約するだけでなく、自動化されたデータ処理に対する透明性を提供します(適用された自動化処理を確認できます)。 これには問題の重大度を判別するのに役立つ警告レベルが含まれています。
重要な追加情報については、関連する注意事項を参照してください。
EDA1の一部として、DataRobotは、日付/時刻やターゲット情報を必要としない特徴量でチェックを実行します。 EDA2が起動すると、以下が実行されます。
DataRobotでは、常に以下のベースラインデータ品質チェックが実行されます。
- 外れ値
- 多カテゴリー形式エラー
- インライア
- 過剰なゼロ
- 偽装欠損値
- ターゲットリーケージ
- 欠損画像(Visual Artificial Intelligence (AI)エクスペリメントの場合)
時系列エクスペリメントでは、ベースラインデータを対象としたすべての品質チェックに加えて、以下のチェックが行われます。
- 補完リーケージ
- 事前に派生したラグ特徴量
- 不規則な時間ステップ(一貫性のないギャップ)
- 先行または後続ゼロ
- まれな負の値
- 検定の新しい系列
Visual Artificial Intelligence(AI)エクスペリメントのデータ品質評価では、同じベースラインチェックと追加の欠損画像チェックが実行されます。
モデルの構築が完了した後、 データ品質処理レポートで追加の補完情報を表示できます。
ターゲットリーケージの特定
EDA2の計算時に、DataRobotはターゲットリーケージをチェックします。ターゲットリーケージは、予測時にその値を知ることができない特徴量を指し、過度に楽観的なモデルにつながります。 これらの特徴量の横にはバッジが表示されるため、簡単に識別して新しい特徴量セットから除外できます。
![]()
評価の調査¶
データ品質評価は、モデル構築のステージに関連するデータ品質の問題に関する情報を提供します。 最初はEDA1(データ取込み)の一部として実行され、すべての特徴量セットに結果が表示されます。 再度実行されてEDA2の後に更新され、選択された特徴量セット(または、デフォルトでは、すべての特徴量)の情報が表示されます。 個々の特徴量に適用できないチェック(一貫性のないギャップなど)の場合、レポートは一般的なサマリーを提供します。
データ品質評価には、データプレビューまたは特徴量タイルのサマリーを表示(まだ開いていない場合、ボタンにはサマリーを表示しないと表示されます)をクリックすることでアクセスできます。

次に、詳細を表示をクリックして詳細なレポートを開きます。
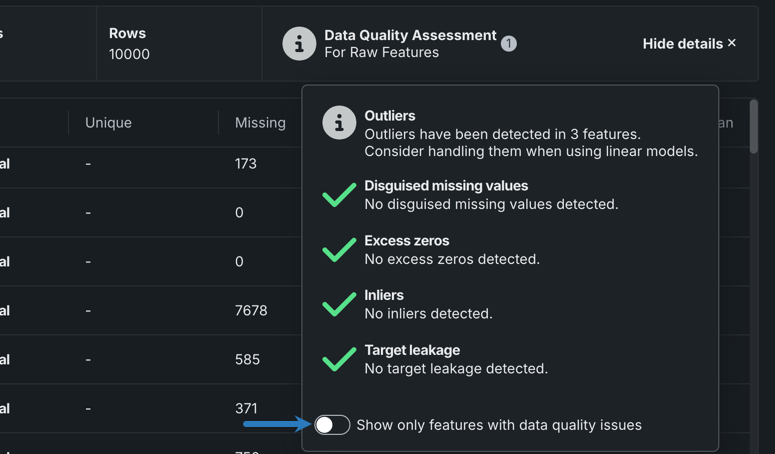
各データ品質チェックは、問題のステータスフラグ、問題の短い説明、および推奨メッセージ(適切な場合)を提供します。
| ステータス | 説明 |
|---|---|
| Warning | 注意または対応が必要です |
| Informational | 対応は不要です |
| Passing | 問題は検出されませんでした |
結果は特徴量セットに基づいているため、選択された特徴量セットを変更すると、新しいチェックが表示されたり、現在のチェックが評価から消えたりする可能性があります。 たとえば、特徴量セットList 1に外れ値を含む特徴量problemが含まれる場合、評価には外れ値チェックが表示されます。 セットをproblem(または外れ値を持つ他の特徴量)が含まれないList 2に変更すると、外れ値チェックで「問題なし」 と報告されます。
評価モーダル内から、問題のタイプでフィルターして、チェックをトリガーした特徴量を確認できます。 影響を受ける特徴量だけを表示をオンに切り替え、チェック名の横にあるチェックボックスを選択して、表示するチェックを選択します。
選択した特徴量セット内で、選択したデータ品質チェックに違反している特徴量だけが表示されます。 アイコンにカーソルを合わせると、詳細が表示されます。
多ラベルおよびVisual Artificial Intelligence (AI)エクスペリメントの場合、評価により、データセット内に多カテゴリー形式エラー または欠損画像が検出された場合は、プレビューログが上部に表示されます。 プレビューログをクリックすると、各エラーの詳細ビューが表示されたウィンドウが開き、データセット内のエラーを簡単に見つけて修正できます。
集計されたカテゴリー特徴量¶
集計されたカテゴリー型特徴量は、複数のカテゴリーのコレクション(同一製品のカテゴリーまたは部門ごとの点数など)を持つ特徴量に使用されます。 元のデータセットにこの型の特徴量がない場合、EDA2の一部として作成されます(後述のように適切な場合)。集計されたカテゴリー型特徴量では、概要、ヒストグラム、カテゴリークラウド、例示、表の各インサイトで独自の詳細を提供します。
備考
集計されたカテゴリー特徴量はモデリングのターゲットとして使用することはできません。
必要なデータセットの形式¶
特徴量が集計されたカテゴリー型特徴量として検出されるには(データタブの「特徴量の型」列に表示)、データセットの列が有効なJSON形式のディクショナリである必要があります。
"Key1": Value1, "Key2": Value2, "Key3": Value3, ...
"Key":は、文字列である必要があります。Valueは、0よりも大きい数値(整数または小数値)である必要があります。- 各キーには対応する1つの値が必要です。 キーの値がない場合、データを使用できません。
- 列は、JSONでのシリアル化が可能である必要があります。
有効な集計されたカテゴリー列の例を以下に示します。
{“Book1”: 100, “Book2”: 13}
無効な集計されたカテゴリー列は、以下のいずれかの例のようになります。
-
{‘Book1’: 100, ‘Book2’: 12}- キーは引用符内にありません(JSONでシリアル化可能ではありません)。
-
{‘Book1’: ‘rate’,‘Book2’: ‘rate1’}- これらの値は正の数値ではなく、文字列です。
-
{“Book1”, “Book2”}- この例はJSONディクショナリ形式ではありません。
平均ターゲット値¶
EDA2の後、ヒストグラムおよび頻出値チャートにグラフのオーバーレイとしてオレンジ色の円が表示されます。 円はビンの平均ターゲット値を示します。 (カテゴリー型特徴量の順序付けは便宜的であり、ヒストグラムは値の連続範囲を表示するので、これらの円は分類ではなく数値特徴量に関連付けられています。)
たとえば、特徴量num_lab_proceduresを考えてみます。
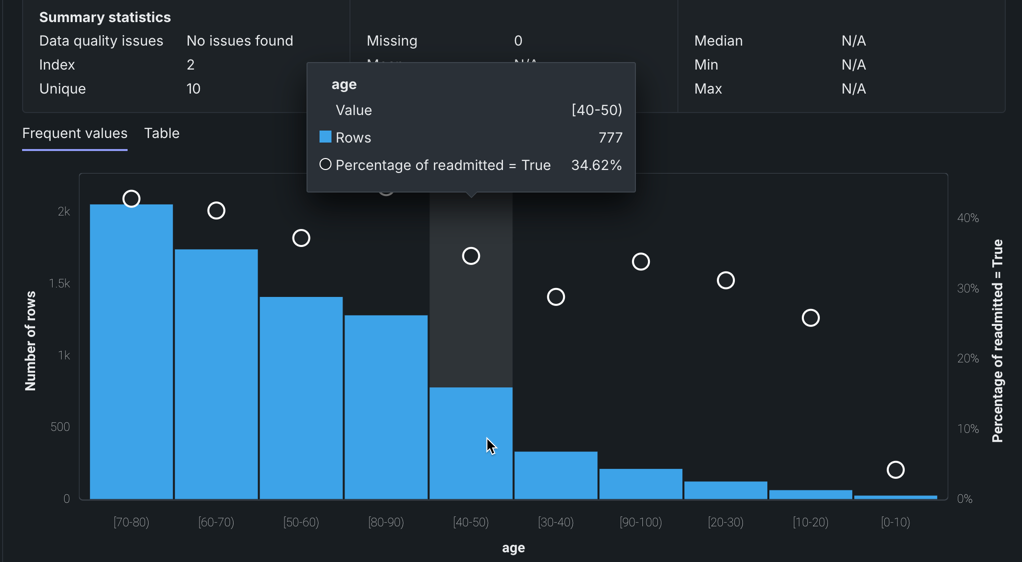
この例では、44から49.999999の検査手順を持つ人物が846名います。 円によって表現される平均ターゲット値(この場合、再入院の割合)は37.23%です。 (オレンジの点はヒストグラムの右軸に対応します。)
エクスポージャーによる出力の変化¶
エクスペリメントのモデルを構築するときにエクスポージャーパラメーターを使用した場合、エクスポージャーに合わせて調整されたグラフがヒストグラムおよび頻出値タブに表示されます。 この場合:
- 各ビンの行数。
- 各ビンでのエクスポージャーの合計。 これは、エクスポージャーによって加重されたすべての行の加重の合計です。
- ターゲットの合計値をビン内のエクスポージャーの合計で割ったもの。
加重による出力の変化¶
エクスペリメントにウェイトパラメーターを設定すると、行数と平均ターゲット値がウェイトで加重されます。