モデルを比較¶
| タイル | 説明 |
|---|---|
 |
モデル比較を使用して、1つのユースケース内の任意の数のエクスペリメントから、同じターゲットタイプ(すべて二値、すべて連続値など)の最大3つのモデルを比較します。 (精度指標は異なるモデルタイプ間では直接比較できないため、モデルは同じタイプである必要があります。)このタイルでは、モデル比較表示とモデル系統の両方の情報が提供されます。 フィルターを使うと、比較するモデルをすばやく選択できます。
重要な追加情報については、関連する注意事項を参照してください。
モデル比較表示¶
モデル比較ページは、最初のモデルを選択すると表示され、選択したモデルが最大3つ並べて表示されます。 選択すると、リーダーボードのフィルターが変更されても、削除されるまでモデルはこのページに残ります。 後続のフィルターで選択されたモデルが除外されると、DataRobotは「モデルは適用されたフィルターに一致しません」という警告を表示します。
以降のセクションでは、モデル比較ページから実行できるアクションについて説明します。
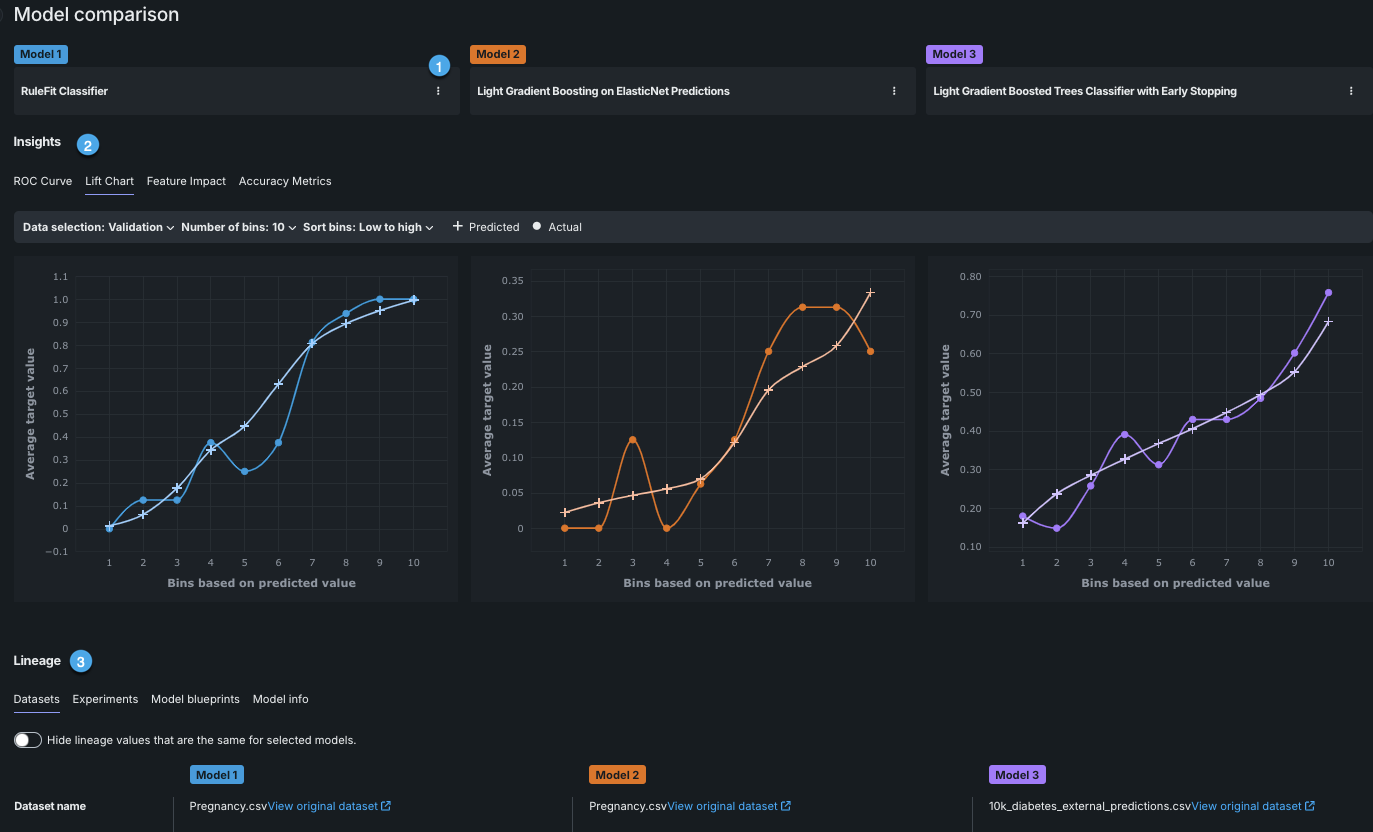
| 設定 | 説明 | |
|---|---|---|
| 1 | モデルのアクション | 個々のモデルに対する操作を行います。 |
| 2 | インサイト | 同じターゲットタイプのモデルを最大3つ並べて表示します。 |
| 3 | 系統 | 全般的なモデルおよびパフォーマンス情報を表示します。 |
モデルの選択¶
比較するモデルを選択するためのコントロールは3つあります。
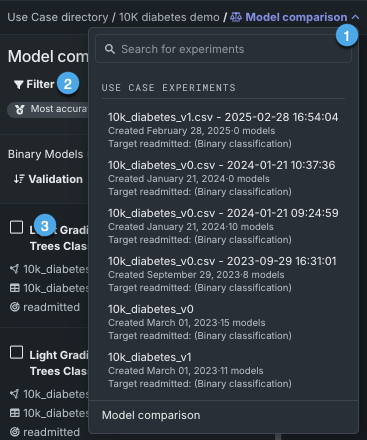
| 設定 | 説明 | |
|---|---|---|
| 1 | パンくず | クリックして、比較可能なユースケース内で最大50のエクスペリメントのリストを表示します。 リストには、作成日付でソートされたエクスペリメントが表示されます。 |
| 2 | フィルター | リーダーボードモデルリストの条件を設定します。 |
| 3 | チェックボックスセレクター | モデルのインサイトとモデル系統の両方の比較で使用するモデルを—最大3つ—選択します。 |
モデルのアクション¶
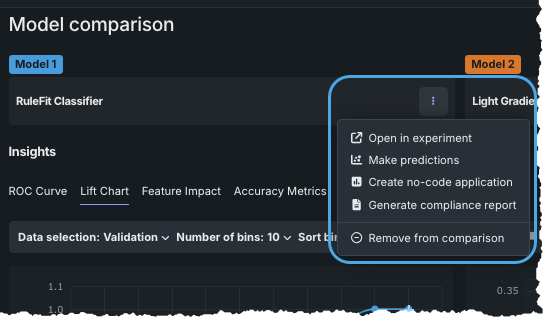
選択したモデルに対して以下のいずれかのアクションを実行するモデル名の横にあるアクションメニュー を使用します。
| アクション | 説明 |
|---|---|
| エクスペリメントで開く | モデルリーダーボードタイルのモデル概要ページに移動します。 |
| 予測の作成 | 予測を作成ページに移動します。 |
| ノーコードアプリを作成 | モデルパッケージを構築し、 アプリケーションを作成するためのツールを開きます。 |
| コンプライアンスレポートを生成 | モデルに対して編集可能な コンプライアンスのテンプレートを作成し、モデルが意図したとおりに機能し、意図したビジネス目的に適切で、概念的に堅牢であることを示すドキュメントを作成します。 |
| 比較から削除 | 比較ページから選択したモデルを削除します。 フィルターを変更してリーダーボードにモデルが表示されなくなった場合でも、このアクションを使用してモデルを削除できます。 |
モデルのインサイト¶
比較ビューには、モデルでサポートされている最大3つのインサイトが表示されます。 リーダーボードリストのチェックボックスを使用して、比較するモデルを選択します。 すべてのインサイトがすべてのモデルで使用できるわけではなく、一部のインサイトを表示する前に追加の計算が必要になることに注意してください。
ROC曲線¶
分類エクスペリメントの場合、 ROC曲線タブは、単一のプロット内の3つのエクスペリメントのそれぞれのFalse Positive率に対してTrue Positive率をプロットします。 付随する表、 混同行列は、実測値と予測値を比較することによって精度を評価します。
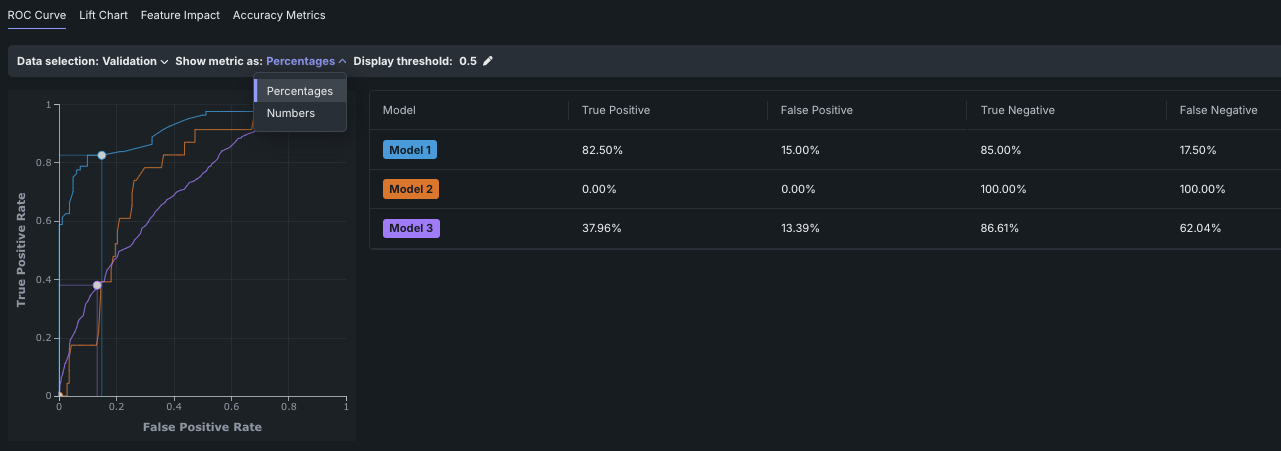
他には、以下の方法もあります。
- 別のデータパーティションを選択します。 そのパーティション(所定のモデル)のスコアリングが計算されていない場合、行列でスコアリンクを使用して計算を開始できます。
- 絶対数とパーセンテージの間の混同行列の表示を変更するには、指標の表示単位を調整します。
- 指標の計算に使用する表示しきい値を調整します。 すべての変更はROCプロットと混同行列にのみ影響し、モデルの予測しきい値は変更されません。
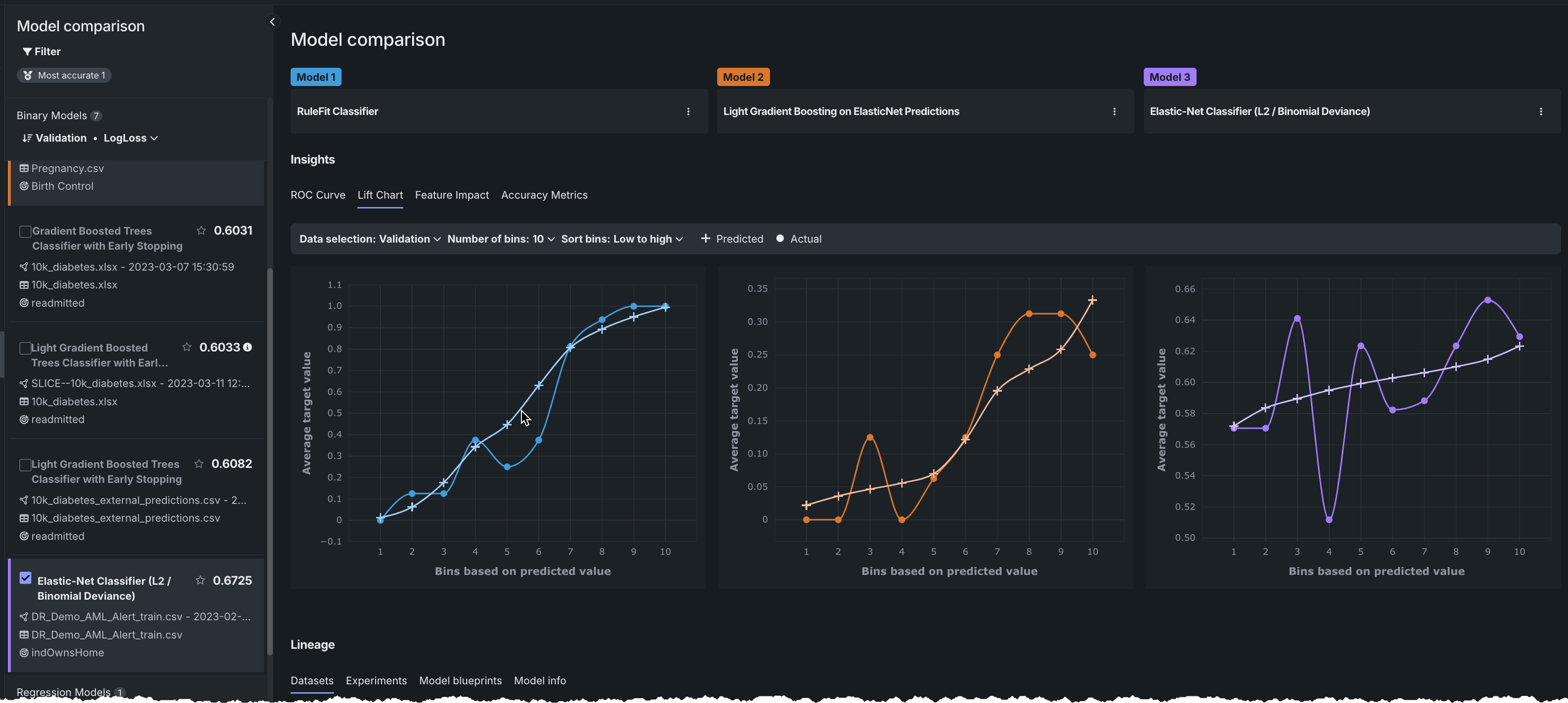
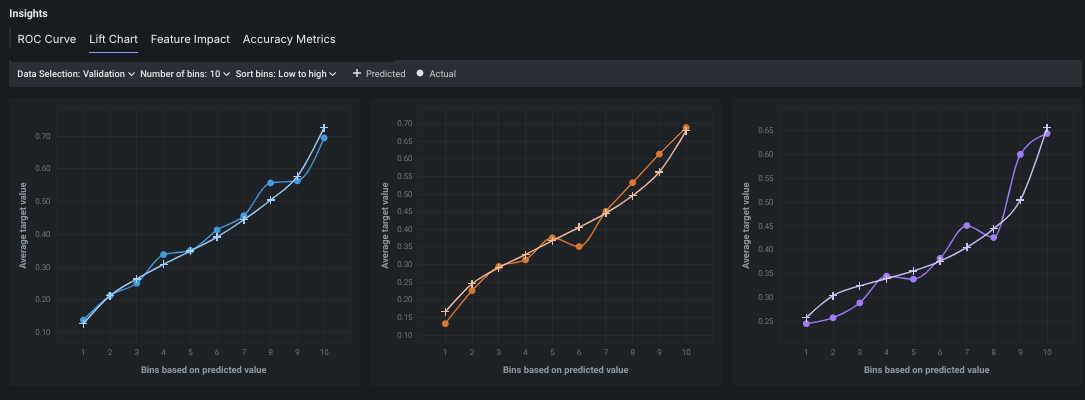
リフトチャート¶
モデルの有効性を視覚化するために、 リフトチャートは、モデルがターゲット母集団をどの程度適切にセグメント化しているか、およびターゲット特徴量の値のさまざまな範囲に対して、モデルのパフォーマンスがどの程度良好かを示します。
- 任意のポイントにカーソルを合わせると、そのビンの行の予測値スコアと実測値スコアが表示されます。
- 表示条件を変更するにはコントロールを使用します
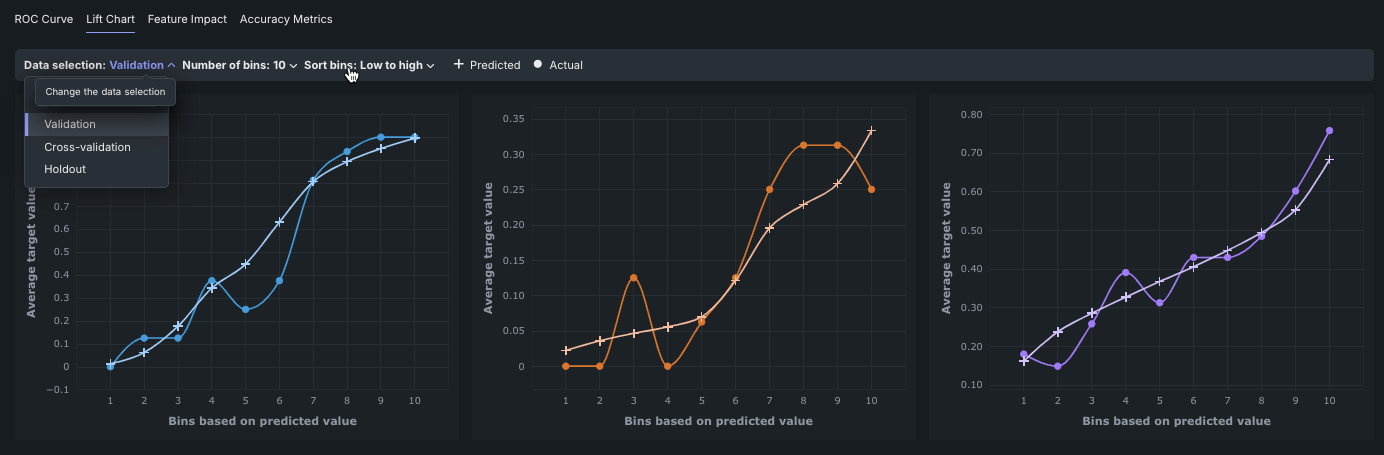
リフトチャートには、最大3つのモデルのリフトチャートが並べて表示されます。 (オプション)データパーティション、ビニングの数、およびビニングのソート順を選択します。
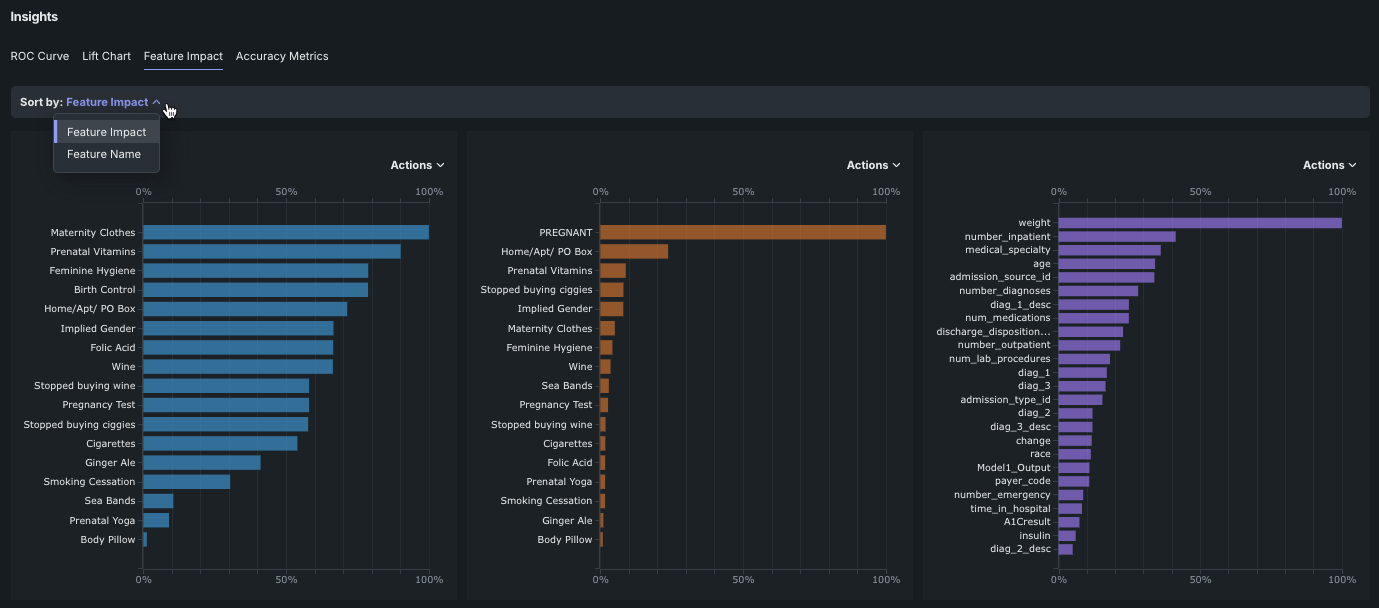
特徴量のインパクト¶
特徴量のインパクトでは、モデルの決定を最も強力に推進している特徴量を識別する概要レベルの視覚化が提供されます。 これはすべてのモデルタイプで使用可能で、オンデマンドの特徴量です。つまり、デプロイ用に準備されたモデルを除くすべてのモデルで、結果を表示するには計算を開始する必要があります。
- 特徴量の名前やバーにカーソルを合わせると、追加情報が表示されます。
- ソート条件を使用して、インパクトまたは特徴量名でソートするように表示を変更します。 When using the comparison tool, DataRobot calculates impact for any uncalculated models when opening the insight.
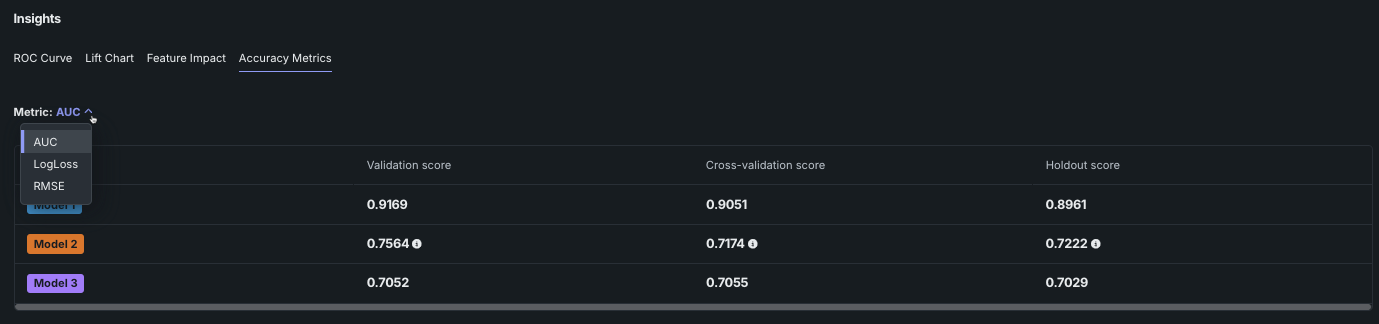
精度指標¶
精度指標には、各モデルの計算されたパーティションごとの精度スコアの表が表示されます。 適用された指標は、表示の上にあるドロップダウンから変更できます。
比較リーダーボードを使用する際、必要に応じて表示を フィルターしてから、モデルを比較することができます。
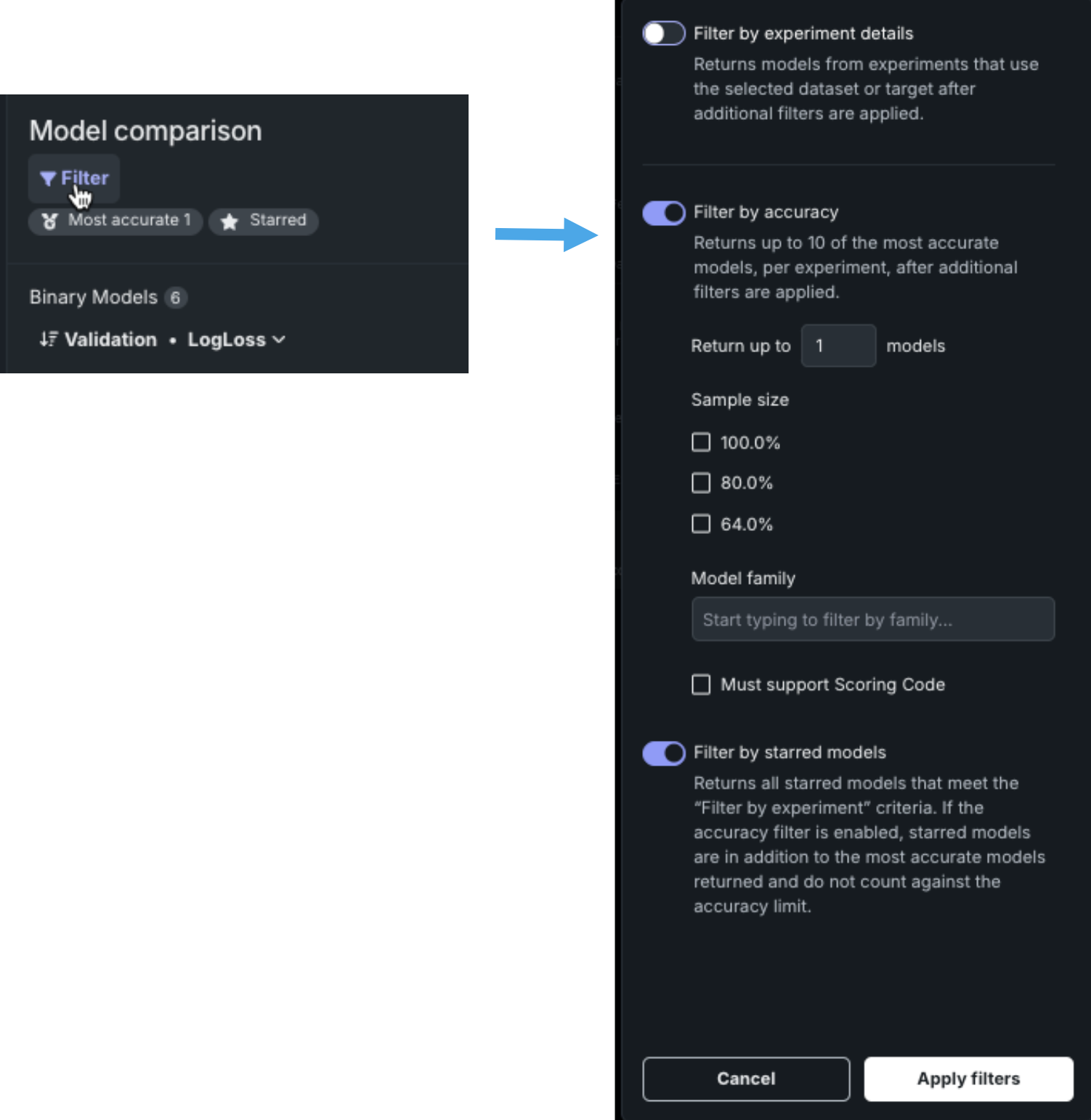
フィルターの設定¶
フィルターを選択して、ワークベンチの比較リーダーボードに表示されるモデルの条件を設定します。
比較リーダーボードには、フィルター条件を満たすすべてのモデルがターゲットタイプ(二値分類、連続値)別にグループ化されて表示されます。 標準の ソートロジックが適用されることに注意してください。
すべてのエクスペリメントからどのモデルを比較リーダーボードに追加するかを決定する方法は3つあります。
比較フィルターは、別のページに移動したときに保存されます。 これにより、このページに戻って比較を再開できます。 表示されたモデルが現在のリーダーボードモデルリストに表示されない場合、DataRobotは「モデルは適用されたフィルターに一致しません」というメッセージを表示します。モデルのモデルのアクションオプションの比較から削除オプションを使用して、比較から削除します。
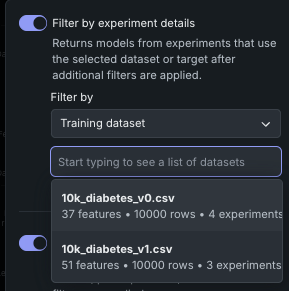
エクスペリメントの詳細でフィルター¶
オンに切り替えると、エクスペリメントの詳細でフィルターは、選択したデータセットまたはターゲットでトレーニングされたエクスペリメントのモデルのみを表示するようにリーダーボードを制限します。 このフィルターは、追加のフィルターが適用された 後 に適用されます。 1つまたは複数の特定のデータセットを使用するモデルのみを比較する場合などに、このフィルターを使用します。
精度でフィルター¶
精度でフィルターを有効にすると、エクスペリメントごとに最も精度の高いモデルがリーダーボードに追加されます。 このカテゴリー内で追加のフィルターを選択して、DataRobotが最も精度の高いモデルを選択する方法を制約します。 精度ランキングは、設定された最適化指標(二値分類モデルのLogLoss、連続値モデルのRMSEなど)に基づいています。
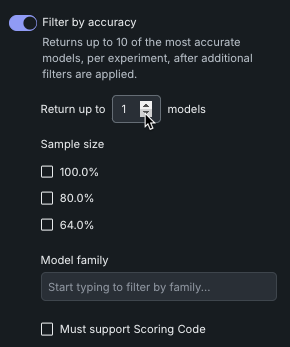
追加の条件を以下に示します。
| フィルター | 説明 |
|---|---|
| 最大n個のモデルを返す | 各エクスペリメントから比較するモデルの数を設定します。 DataRobotは、最高の精度に基づいてモデルを返します。 |
| モデルのサンプルサイズ | 返されたモデルがトレーニングされたサンプルサイズを設定します。 |
| モデルファミリー | 選択したモデルファミリーの一部であるモデルのみを返します。 入力を開始して、 モデルファミリー名を自動入力します。 |
| スコアリングコードに対応する必要があります | 選択すると、 スコアリングコードのエクスポートをサポートするモデルのみが返され、DataRobotで生成されたモデルをプラットフォーム外で使用できます。 |
モデルファミリーの選択¶
比較リーダーボードは、「ファミリー」に基づいてモデルを返すことができます。以下のリストは、オートパイロット中に実行されるファミリーと、そのメンバーであるモデルの例です。
| ファミリー | 例 |
|---|---|
| Gradient Boosting Machine | Light Gradient Boosting on ElasticNet Predictions、eXtreme Gradient Boosted Trees Classifier |
| ElasticNet Generalized Linear Model | Elastic-Net Classifier、Generalized Additive2 |
| Rule Induction | RuleFit Classifier |
| Random Forest | RandomForest ClassifierまたはRegressor |
| Neural Network | Keras |
リポジトリを介して構築された以下のモデルのファミリーは、フィルターとして使用できます。
- Adaptive Boosting
- Decision Tree
- Eureqa
- K Nearest Neighbors
- Naive
- ナイーブベイズ
- Support Vector Machine
- Two Stage
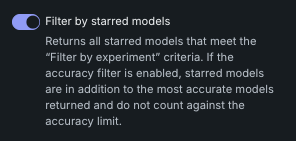
スター付きモデルでフィルター¶
スター付きでフィルターを有効にすると、 エクスペリメントの詳細でフィルターによってエクスペリメントのセットが低減されていない限り、エクスペリメントのすべての スター付きモデルが追加されます。 このフィルターは、 精度でフィルターからの選択には影響しません。
リーダーボードの結果¶
フィルターを適用すると、リーダーボードに再表示され、複数のエクスペリメントを含む各ターゲットタイプの上位20件の結果が表示されます。 20を超えるモデルがフィルター基準を満たしている場合、追加ロードリンクが使用可能になり、最大20のモデルが追加でロードされます(必要に応じて、追加のモデルをロードするオプションがあります)。
例:
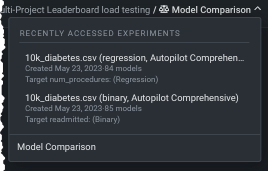
- フィルターの結果、ユースケースの8つのエクスペリメントのそれぞれから、最も精度の高い上位2つのモデルが選ばれました(1)。
- 10K diabetesのデータは、二値分類と連続値のエクスペリメントとしてトレーニングされました(2)。
- グループ化に適用されたパーティションと指標が表示されます。 いずれかの値を変更すると、そのターゲットタイプのモデルの表示が更新されます。
- エクスペリメント、データセット、ターゲットの名前(4)。
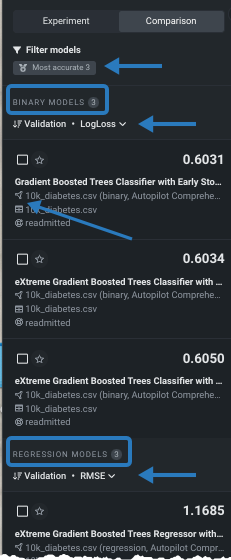
モデル名の左側にあるチェックボックスを使用して、比較表示用にそのモデルを選択します。 最大3つのモデルを比較できますが、同じターゲットタイプ(すべてが二値またはすべてが連続値)である必要があります。
モデル系統¶
系統セクションには、比較対象として選択されたモデルのメタデータが表示されます。 オプションにより、モデルトレーニング入力の詳細が取得できます。
| オプション | 説明 |
|---|---|
| データセット | データセット、特徴量、特徴量セットのメタデータ。 |
| エクスペリメント | エクスペリメント設定と作成に関するメタデータ。 |
| モデルのブループリント | 各モデルの前処理のステップ(タスク)、モデリングアルゴリズム、後処理ステップの視覚化。 |
| モデル情報 | モデルに関する追加の一般情報およびパフォーマンス情報。 |
| 選択したモデルで同じ系統値を非表示にする | 系統出力の制御に切り替えます。 |
データセット¶
「データ」タブには、さまざまなデータ関連情報が表示されます。
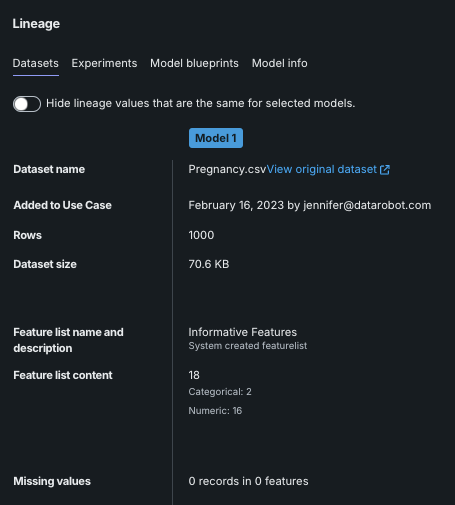
| フィールド | 説明 |
|---|---|
| データセット名 | データセットエクスプローラーでデータをプレビューするためのリンクなど、モデルに使用されるデータセットの名前。 |
| ユースケースに追加されました | データセットがユースケースに追加された日付と、それを追加したユーザー。 |
| 行 | データセット内の行数。 |
| データセットサイズ | データセットのサイズ。 |
| 特徴量セットの名前と説明 | モデルの構築に使用される 特徴量セットおよび説明。 |
| 特徴量セットの内容 | 適用された特徴量セット内の特徴量の総数、および特徴量のタイプ別の内訳と数。 |
| 欠損値 | 欠損値と影響を受ける特徴量の総数、個々の特徴量のカウントなど、モデルの構築に使用されたデータの欠損値のメタデータ。 |
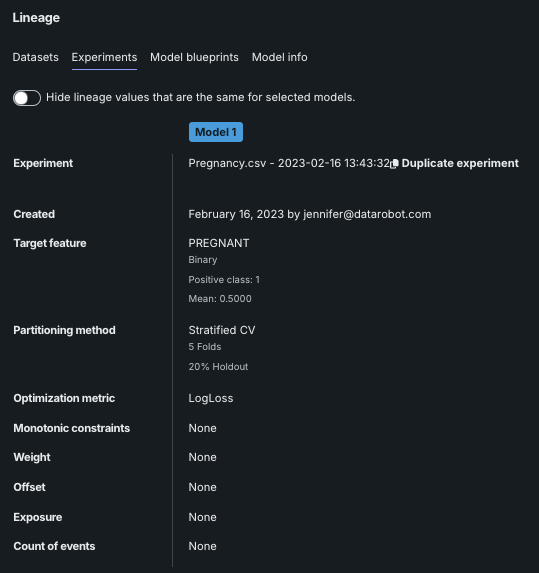
エクスペリメント¶
エクスペリメントタブには、 エクスペリメントの設定タブに表示される情報と同様に、エクスペリメントの設定に関連するさまざまな情報が表示されます。
| フィールド | 表示... |
|---|---|
| エクスペリメント | エクスペリメントの名前。 |
| 作成 | エクスペリメントの作成日付と作成者。 |
| ターゲット特徴量 | ターゲット、結果のプロジェクトタイプ、Positiveクラス(二値分類の場合)などのターゲット特徴量の情報。 さらに、連続値プロジェクトの平均(代表値)スコアが表示され、二値の場合、ターゲットが数値ターゲットに変換された後のターゲットの平均が表示されます。 たとえば、ターゲットが [yes, no, no] で、yesがPositiveクラスの場合、ターゲットは変換後に [1, 0, 0] になり、平均値は0.3333になります。 |
| 分割の方法 | エクスペリメントに対して行われたパーティション分割の詳細(デフォルトまたは変更済み)。 |
| 最適化指標 | エクスペリメントのモデルのスコアリング方法を定義するために使用される指標。 リーダーボードのソート基準となる指標を変更できますが、サマリーに表示される指標は最適化指標としてエクスペリメントで使用される指標です。 |
| 追加設定 | 追加設定の単調制約、加重、オフセット、エクスポージャー、イベント数で使用可能な設定パラメーターの設定。 |
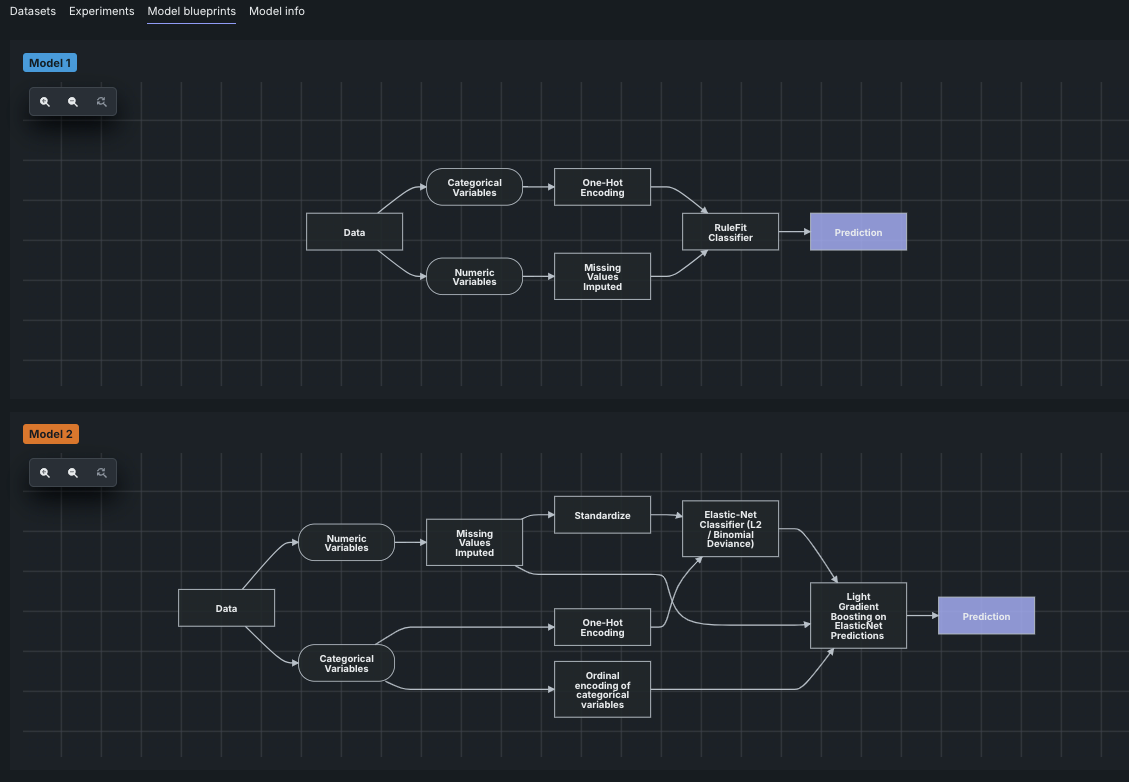
モデルのブループリント¶
モデルブループリントタブには、各モデルの前処理ステップ(タスク)、モデリングアルゴリズム、後処理ステップが示されます。 完全な情報については、ブループリントのドキュメントを参照してください。 このタブからブループリントを編集することはできません。
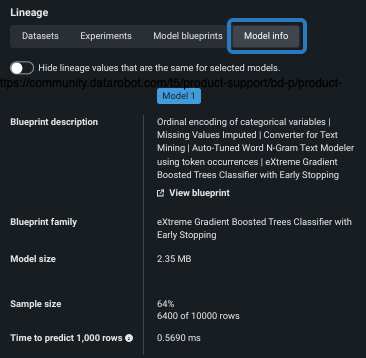
モデル情報¶
モデル情報タブには、さまざまな一般的なモデルおよびパフォーマンス情報が表示されます。
| フィールド | 説明 |
|---|---|
| ブループリントの説明 | モデル ブループリントで視覚化された前処理タスクと後処理タスクを一覧表示します。ブループリントをグラフィカルに表示するオプションもあります。 |
| ブループリントファミリー | 比較ボードの フィルターの一部として使用できるブループリントファミリーを一覧表示します。 |
| モデルのサイズ | モデルデータを保存するのにDataRobotが使用するファイルの合計サイズをレポートします。 この数は、モデルのダウンロードと保存が必要なセルフマネージドAIプラットフォームのデプロイで特に便利です。 |
| サンプルサイズ | モデルのトレーニングに使用される行数とパーセンテージとして示されるサイズをレポートします。 DataRobotでプロジェクトがダウンサンプリングされた場合、サンプルサイズは、モデルのトレーニングに使用された行の総数ではなく、マイノリティークラスに含まれる行の数をレポートします。 |
| 1,000行の予測に要する時間 | データセットから1000行をスコアリングする際の推定時間(秒)が表示されます。 実際の予測時間は、モデルがどこにどのようにデプロイされるかによって異なる可能性があります。 |
機能に関する注意事項¶
モデル比較ツールの機能を使用する際は、以下の点に注意してください。
-
時間認識プロジェクトはサポートされていません。
-
モデルフィルター設定に基づいて、エクスペリメントごとに最大10個のモデルが返されます。
-
"N/A"スコアまたは計算されていないスコア(計算されていないCVスコアなど)を持つモデルは、モデルリストの下部でソートされます。
-
各ターゲットタイプセクションには、100モデルまでの制限があります。
-
異なるエクスペリメントの同じモデルタイプでスコアがまったく同じ場合、最も最近に作成したエクスペリメントのモデルがソート順の最初に表示されます。