Manage JDBC drivers¶
You manage Java Database Connectivity (JDBC) drivers by:
- Working with JDBC drivers
- Restricting access for Kerberos authentication systems
Availability information
This feature is only available on the Self-Managed AI Platform.
Required permission: Can manage JDBC database drivers
A driver allows DataRobot to provide a way for users to ingest data from a database via JDBC. The administrator can upload JDBC driver files (JAR files) for their organization's users to access when creating data connections. As part of driver creation, the administrator can also upload additional JAR files containing library dependencies. Once uploaded, drivers can be modified or deleted only by administrators.
By default, all users have permissions to create, modify (depending on their roles), and share data connections and data sources. (See more information about user data connection roles) If needed, you can prevent access to data stores and data sources for a specific user with the "Disable Database Connectivity" user permission; this prevents that user from creating new JDBC data connections or importing data from any defined JDBC data sources (from the new project page).
Additionally, for cluster deployments using Kerberos authentication, you can control access to data stores through validation and variable substitution.
Predefined driver configurations¶
When users create data connections for a selected JDBC driver, they specify how to retrieve the data. This may be a defined JDBC URL or a set of parameters. Because creating the JDBC URLs for data connections can be complicated, DataRobot provides predefined configurations for some supported drivers that have parameter support. Driver configurations specify the information users need to provide to retrieve data from their data sources.
Each predefined configuration includes typical information needed to create connections using that type of driver. For example, while connections to Presto driver typically require the catalog and schema, connections to Snowflake driver often need the database and warehouse.
Predefined configurations are available for the following drivers:
- AWS Athena
- Azure SQL
- Azure Synapse
- Google BigQuery
- Intersystems
- kdb+
- Microsoft SQL Server
- MySQL
- Postgres
- Presto
- Redshift
- SAP HANA
- Snowflake
- Treasure Data: Hive
When you add a new driver, you can select to use a predefined configuration (if one exists for that driver), or you can create a custom driver which does not include a configuration.
The steps below describe how to create an instance of a driver.
Upload drivers¶
The steps below describe how to create a driver instance.
-
Click the profile icon in the top right corner of the application screen, and select Data Connections from the dropdown menu.
-
Select the Connectors & Drivers tab.
-
In the left-panel Drivers list, click Add new driver.
-
In the displayed dialog, select the type of configuration you are using for this driver:
- Predefined—use a configuration provided by DataRobot
- Custom—create a configuration when creating data connections
-
If you are adding a driver that has a configuration (Predefined), complete the following fields as prompted:
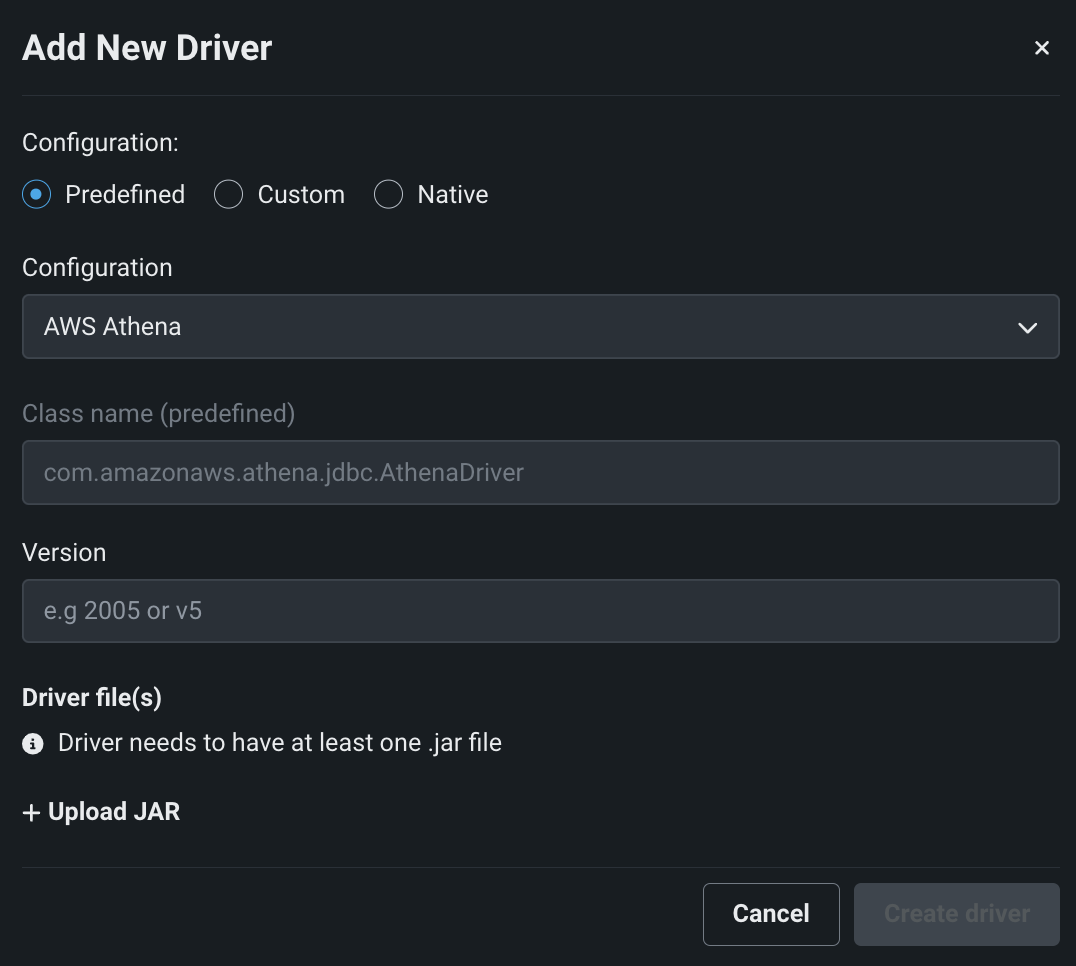
Field Description Configuration Select the configuration to use for the driver you are creating. Configurations for some supported drivers with parameter support in DataRobot are provided for selection. If you don't see the configuration you want then create this as a custom driver and specify driver name and driver class. Class name (Predefined) Shows the driver class name defined in this configuration. Version Enter the version (user-defined) for the driver. This value is required. The combination of driver name and version are used to identify the driver configuration for users. Driver Files * Click + UPLOAD JAR to add the driver JAR file. Follow the same process for each additional library dependencies. When uploaded successfully, the JAR filename(s) appear in this field. -
If you are adding a driver that does not include a configuration (Custom), complete the following fields as prompted:
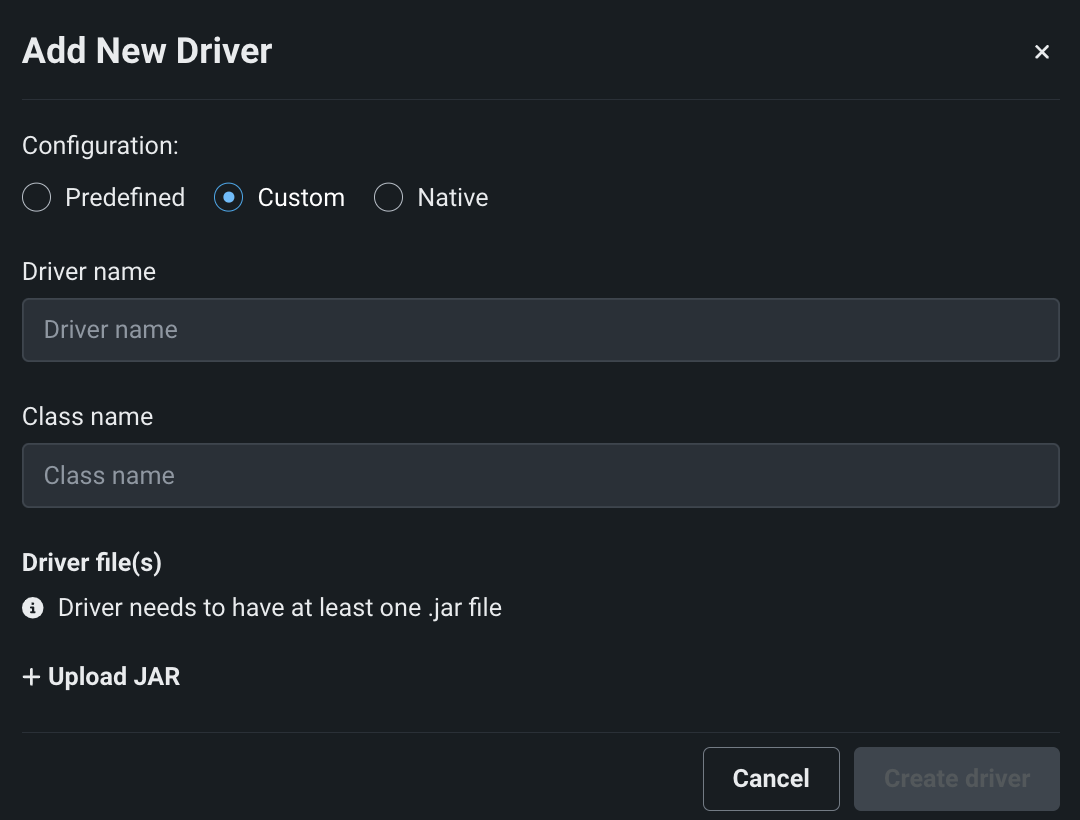
Field Description Driver name Enter a display name for the driver. Class name Enter the driver class name. If unknown, refer to the driver documentation. Driver Files * Click + UPLOAD JAR to add the driver JAR file. Follow the same process for each additional library dependencies. When uploaded successfully, the JAR filename(s) appear in this field. * The JAR driver and dependency file size limit is 100MB. That is, each file upload can be a maximum of 100MB, but totals may exceed that limit.
Note
DataRobot does not validate uploaded drivers (other than simple extension checking).
-
Click Create driver to add the driver. The new driver is shown in the left-panel Drivers list, and the driver configuration is now available to all users in your organization. Drivers created with predefined configurations are named in the format driver name (version).
Modify drivers¶
If you are modifying drivers that use predefined configurations, you can change only the version and JAR files for the driver configuration. (The driver name is created automatically as a combination of selected configuration and version.) Also, note that removing the predefined configuration for a driver makes it a driver with a custom configuration (i.e., connections using this driver will require a JDBC URL).
If you are modifying drivers that use custom configurations, you can change the driver name, configuration, class name, or JAR file(s). Adding a configuration to a driver makes it a driver with a predefined configuration. If you do select to add a configuration for the driver, DataRobot automatically verifies that any JDBC URLs for existing data connections are not affected. If that is not necessary, then you can select to skip the URL validation.
Note
DataRobot recommends that you notify your users about driver configuration modifications that will affect JDBC URLs for existing data connections, so they can recreate them, if needed.
-
Select the driver from the left-panel Drivers list. The information for the driver configuration is added to the main window.
-
If this driver has a predefined configuration:
- You can modify the version.
- You can remove the configuration. This changes it to a custom driver, with no configuration.
-
If this driver has a custom configuration:
- You can modify the driver name or class name.
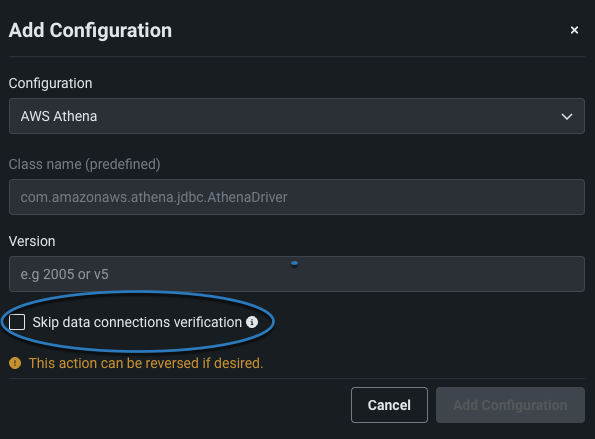
- You can add a (predefined) configuration to the driver (+ Add Configuration). This changes it to a driver with a predefined configuration.
If there are existing connections to the driver and the new configuration will affect the JDBC URLs (and you still want to make this change), select Skip data connections verification. This ensures DataRobot does not validate JDBC URLs for existing data connections.
As shown in the below image, if existing JDBC URLs are affected by the new configuration and Skip data connections verification is not selected, the configuration cannot be added to the driver.
-
For either type of driver, you can click UPDATE JAR FILE to replace the JAR file(s).
-
Click Save changes to save modifications to this driver. You see the updated driver listing in the left-panel Drivers list. Any existing data connections for this driver are updated with these changes automatically.
Delete drivers¶
You can delete any driver that is not being used by existing data connections. If it is being used, you must first delete the dependencies.
- Select the driver in the left-panel Drivers list.
- In the upper right, click Delete Driver. If there are no existing data connections for the driver, DataRobot prompts for confirmation (if there are existing data connections using the driver, DataRobot provides a warning).
- Click Delete to remove the driver.
If you see the connector warning, the dependencies first need to be removed (in the Data Connections tab). Then, you can try again to delete the driver.
Restrict access to JDBC data stores¶
Availability information
Required permission: Can manage users, Can manage JDBC database drivers
When using Kerberos authentication for JDBC, you can control access to data stores through validation and variable substitution.
Control user access¶
You can restrict the ability to create and modify JDBC data stores that utilize impersonation to only those users with the admin setting "Can create impersonated Data Store."
Within cluster configuration (config.yaml), you can define impersonated keywords that are used by any installed drivers that support impersonation. These keywords could be used to define operations considered "dangerous" and therefore permitted to only select users. By default, no impersonation keywords are defined.
When a user attempts to create or modify a JDBC data store and there are impersonation keywords defined for the installation, DataRobot determines if the URI includes any of the keywords. If the URI includes one or more of the keywords and the "Can create impersonated Data Store" admin setting is enabled for the user, they are allowed to create or modify it. If keywords are included in the URI but the user does not have the "Can create impersonated Data Store" setting enabled, then DataRobot does not allow the request to create or modify it.
Variable substitutions¶
The variable substitution syntax,${datarobot_read_username}, provides another way to control access to drivers. If that variable is included in the URI when trying to ingest from the data source/data store, DataRobot replaces it with the impersonated account associated with the logged in user.