DataRobot Classicの5つのステップ¶
DataRobotでのモデルの構築は、データ処理、モデリングオプション、予測方法、デプロイアクションを問わず、同じ5つの基本的なアクションに集約されます。 以下のステップを参照することで、DataRobot Classicを使いこなす方法をすばやく理解できます。
テスト用のデータセット¶
以下の再入院デモデータセットを使用して、DataRobot機能を試すことができます:
トレーニングデータをダウンロード スコアリングコードをダウンロードする
これらのサンプルデータセットは、70,000人の糖尿病患者の再入院を研究するために、 BioMed Research Internationalによって提供されています。 この調査の研究者は、Cerner社が提供するHealth Factsデータベース(米国医療提供者全体の臨床記録)からこのデータを収集しています。 Cerner社の電子医療システムを利用している組織は、研究目的でHealth Factsのデータを無償で利用できます。 すべてのデータは、HIPAAに従ってPIIが消去されています。
1:新規のDataRobotプロジェクトを作成¶
新規プロジェクトページでいずれかの方法を用いてデータセットをインポートし、新しいDataRobotプロジェクトを作成します。

AIカタログから、接続されたデータソースから直接、ローカルファイルとして、などの方法があります。
学習リソース
このページで説明されているトピックの詳細については、以下を参照してください。
モデリングを開始するには、ターゲットの名前を入力し、以下に説明するオプション設定を設定します。
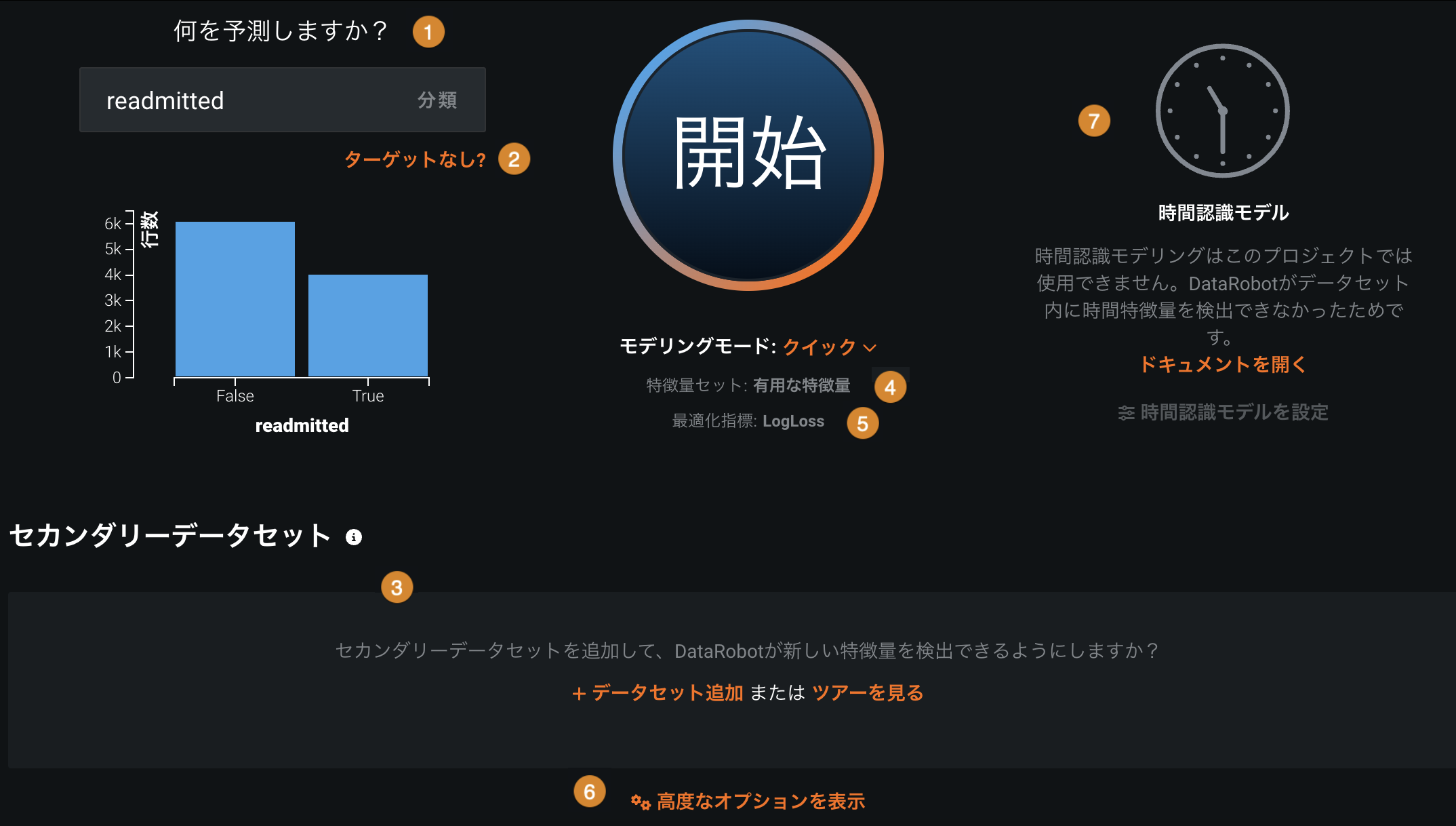
| 要素 | 説明 | |
|---|---|---|
| 1 | 何を予測しますか? | ターゲット特徴量(予測するデータセットの列)の名前を入力するか、以下の特徴量セットの名前の横にあるターゲットとして使うをクリックします。 |
| 2 | ターゲットなし? | クリックして教師なしモデルを構築します。 |
| 3 | セカンダリーデータセット | (オプション)+ データセットを追加をクリックしてセカンダリーデータセットを追加します。 DateRobotは特徴量探索を実行し、データセットとの関係性を作成します。 |
| 4 | 特徴量セット | モデルのトレーニングに使用する特徴量セットを表示します。 |
| 5 | 最適化指標 | (オプション)最適化指標を選択しモデルをスコアリングします。 選択したターゲット特徴量およびモデリングプロジェクトの種類(連続値、分類、多クラス、教師なしなど)に基づいて指標を自動的に選択します。 |
| 6 | 高度なオプションを表示 | パーティショニング、バイアスと公平性、最適化指標などのモデリングオプションを指定します(その他をクリックします)。 |
| 7 | 時間認識モデリング | 時間特徴量に基づいて時間認識モデルを構築します。 |
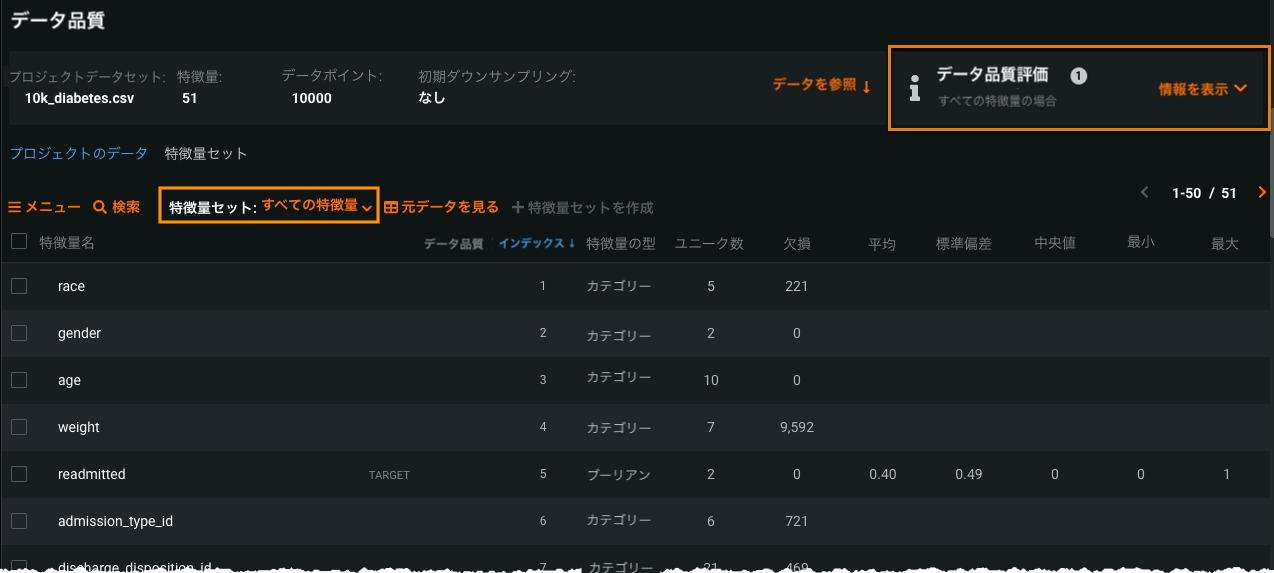
画面の下方向にスクロールして、使用可能な特徴量のリストを表示します。 (オプション)モデルトレーニングに使用する特徴量セットを選択します。 右側のデータ品質評価領域で情報を表示をクリックして、特徴量の品質を調査します。
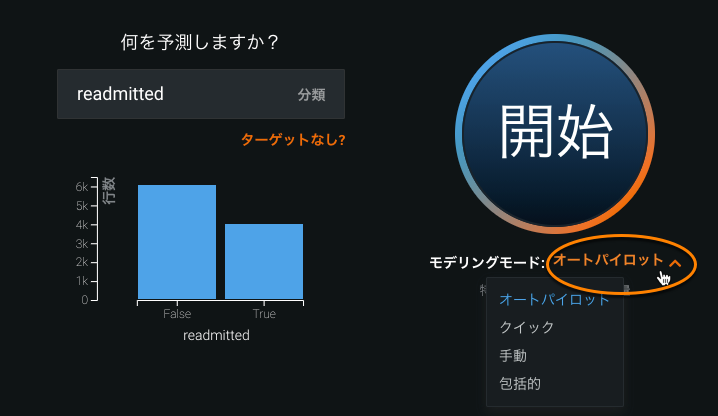
ターゲット特徴量を指定したら、モデリングモードを選択して、DataRobotにより多いまたは少ない数のモデルを構築するように指示し、開始をクリックしてモデリングを開始することができます。
ヒント
データセットが大きい場合は、早期ターゲット選択のセクションを参照してください。
または、各種の高度なオプションを設定して、プロジェクトのモデル構築プロセスを微調整することができます。

プロジェクトが準備され(EDA2)、モデルの実行が開始します。 実行中のモデルの進捗インジケーターが画面右側のワーカーキューに表示されます。 データセットのサイズによっては、モデリング処理を完了するのに数分かかる場合があります。 モデリング処理の結果は(選択した最適化指標に基づいて)パフォーマンスが最も優れているモデルがリストの上位にランク付けされた状態でモデルのリーダーボードに表示されます。
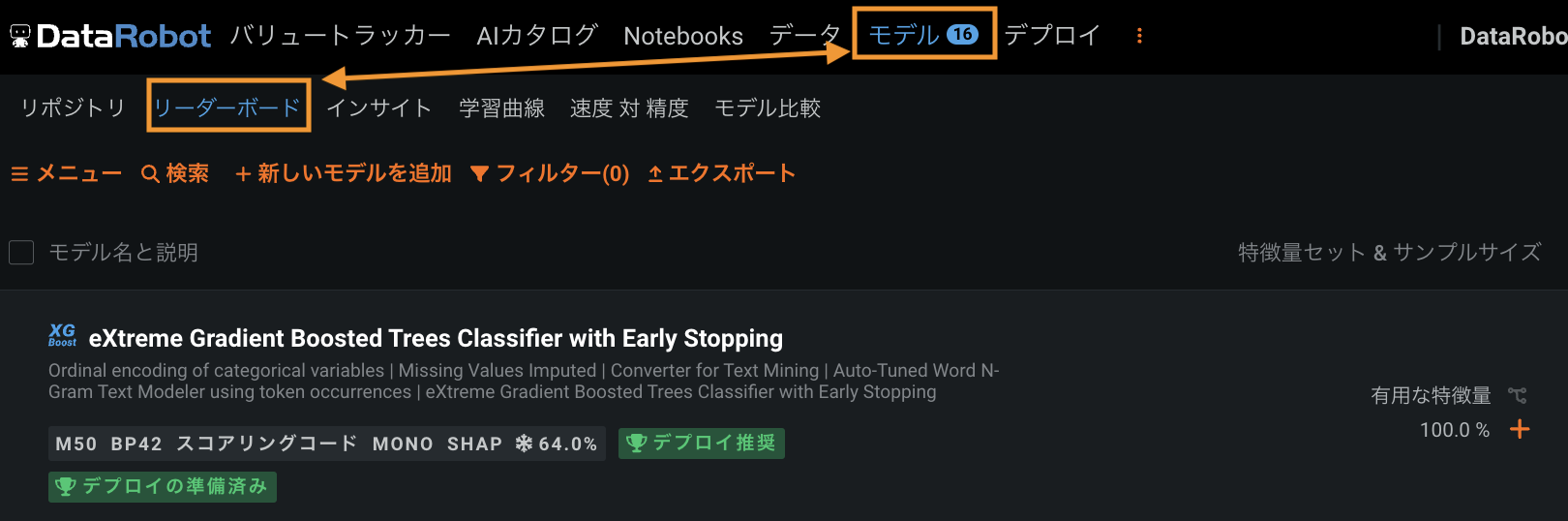
2:モデルの詳細を確認する¶
リーダーボードでモデルをクリックすると、モデルのブループリントが表示され、モデルの情報とインサイトを調査するための多くのタブにアクセスできます。
予測 > 予測を作成を選択することによって、運用環境にデプロイすることなくモデルの予測を手動でテストおよび生成できます。 ファイルを画面にドラッグアンドドロップするか、ドロップダウンのオプションを使用してデータセットを提供します。 データセットのアップロードが完了した後、予測を計算をクリックして新しいデータセットの予測を生成します。完了したら、ダウンロードをクリックして、CSVファイルに結果を表示します。
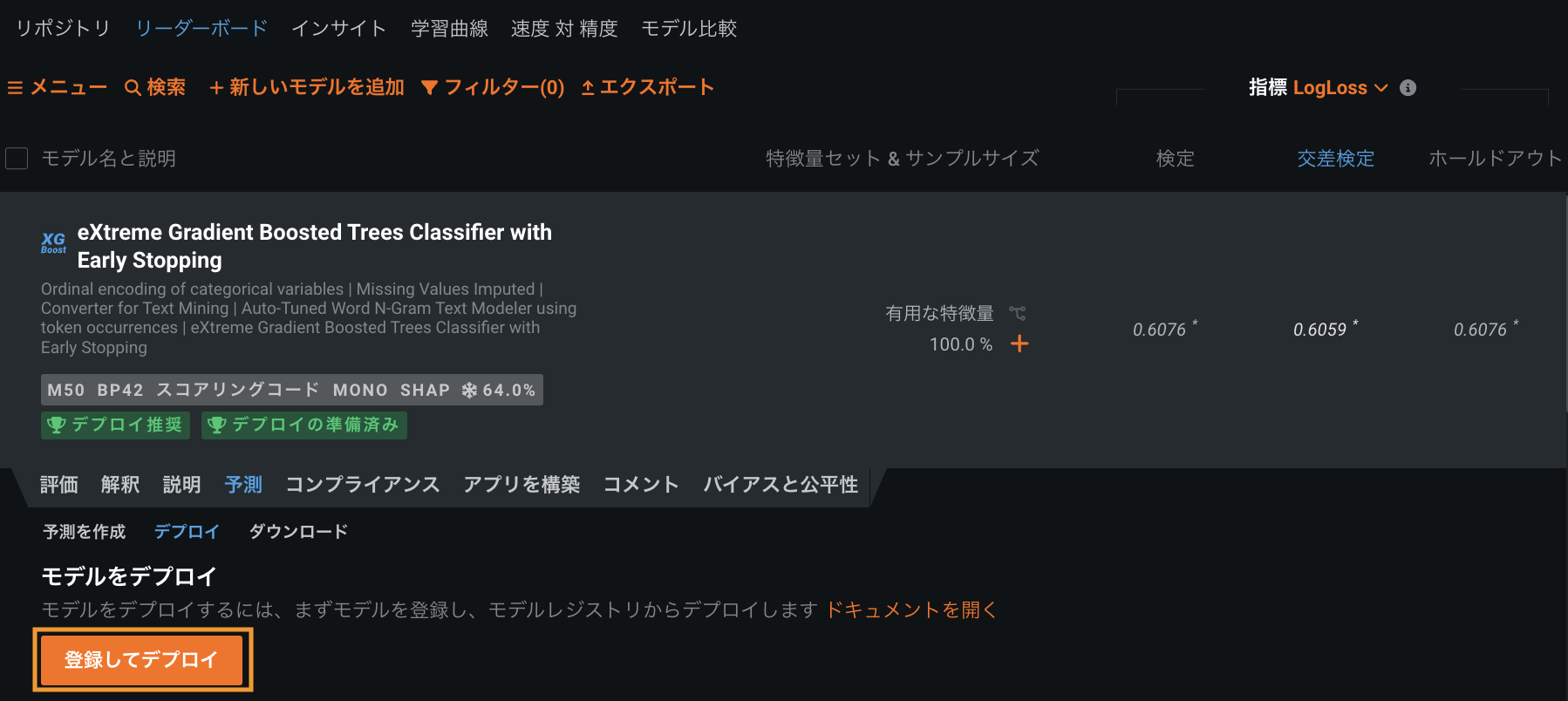
3:モデルのデプロイ¶
DataRobot AutoMLはモデルを自動生成し、リーダーボードに表示します。 デプロイの推奨モデルがページの上部に表示されます。 この(または他の)モデルをリーダーボードからモデルレジストリに直接登録できます。 モデルが登録されたら、デプロイを作成して、予測の実行と監視を開始することができます。
学習リソース
モデルの登録方法について説明します。
デプロイ情報ページでは、提供されたデータ(トレーニングデータ、予測データ、実測値など)に基づいて、現在のデプロイが持つ機能の概要が示されます。 トレーニングデータ、推論データ、モデル、および結果データに関する詳細を入力するためのフィールドが用意されています。
学習リソース
デプロイの設定方法について説明します。
4:モデルの再トレーニングと置換を設定する¶
DataRobotは、大規模な手作業を行うことなくデプロイ後のモデルのパフォーマンスを維持するために、デプロイに対して自動再トレーニング機能を提供しています。 AIカタログに登録された再トレーニングデータセットを指定すると、各デプロイで最大5つの再トレーニングポリシーを定義できます。各再トレーニングポリシーは、トリガー、モデリング戦略、モデリング設定、および置換アクションで構成されます。 トリガーされると、再トレーニングによりこれらの設定に基づいて新しいモデルが作成され、そのモデルのプロモーションを検討するように通知されます。 必要であれば、デプロイされたモデルを手動で置き換えることができます。
学習リソース
再トレーニングと置換の設定方法について説明します。
5:モデルのパフォーマンスを監視する¶
モデルを信頼してミッションクリティカルな操作を強化するには、モデルデプロイのすべての側面が信頼できるものである必要があります。 モデルモニタリングは、本番環境でのMLモデルのパフォーマンスを詳細に追跡し、ビジネスに影響を及ぼす前に潜在的な問題を特定します。 監視の範囲は、サービスがタイムリーにエラーなく確実に予測を提供しているかどうかから、予測そのものが信頼できるものであるかどうかまで多岐にわたります。 DataRobotは、モデルデプロイを自動的にモニタし、可能な限り早急に誤差およびモデル精度の低下を検知する中心的なハブを提供します。 各デプロイに対して、DataRobotはステータスバナーを提供します。モデル固有の情報は、デプロイのインベントリページでも入手できます。

学習リソース
モデルのパフォーマンスを監視する方法について説明します。