予測モデリングの基礎¶
DataRobotは、生成AIソリューションと予測AIソリューションの両方を提供します。
ClassicとNextGenの両方のエクスペリメントで利用可能な_生成AI_は、Automated Machine Learning(AutoML)を使用して、ドメインと業界の実際の問題を解決するモデルを構築します。 提供されたデータを取得し、複数の機械学習(ML)モデルを生成し、使用するのに最適なモデルを推奨します。 DataRobotを使用してMLモデルを構築する上でデータサイエンティストである必要はありませんが、基本を理解すると、より優れたモデルを構築するのに役立ちます。 ドメイン知識とDataRobotのAI専門知識により、速度と精度を使用して問題を解決できるようになります。
DataRobotは、教師あり学習、教師なし学習、時系列モデリング、セグメント化モデリング、マルチモーダルモデリングなど、MLモデリングへのさまざまなアプローチをサポートしています。 このセクションでは、これらのアプローチについて説明し、デプロイに最適なモデルを分析および選択するためのヒントも伝授します。
_生成AI(GenAI)_はDataRobotのNextGenワークベンチで使用可能で、エンタープライズグレードの生成AIソリューションを、自信を持って構築、管理、運用できます。 このソリューションは、クラウド環境全体で、選択した最高のコンポーネント(LLM、ベクターデータベース、埋め込みモデル)を使用して、迅速に革新し、適応する自由を提供します。 DataRobot GenAIは以下のことを行います。
- LLMを拡張し、生成AIエクスペリメントのコストをリアルタイムで監視することで、独自のデータを保護します。
- 本番環境での安全で、高品質な生成AIアプリケーションとソリューションの作成、デプロイ、および保全を通じて保護します。
- 予期しない動作や不要な動作を迅速に検出して防止できるようにします。
このセクションでは、DataRobotの予測ソリューションについて説明します。生成関連のツールとオプションの操作に関する完全なドキュメントについては、 GenAIのセクションを参照してください。
予測モデリングの方法¶
ログイン方法
組織でシングルサインオンに外部のアカウント管理システムが使用されている場合:
- LDAPが使用されている場合、ユーザー名は登録済みのEメールアドレスではない場合があります。 必要な場合は、DataRobot管理者に連絡してユーザー名を取得してください。
- SAMLベースのシステムが使用されている場合、ログインページの資格情報入力ボックスは無視してください。代わりに、シングルサインオンをクリックして、表示されるページに認証情報を入力します。
MLモデリングとは、過去のデータの例で学習するアルゴリズムを開発するプロセスです。 これらのアルゴリズムは、結果を予測し、簡単に識別できないパターンを明らかにします。 DataRobotは、さまざまなモデリング方法をサポートしており、それぞれが特定のタイプのデータおよび問題タイプに適しています。
教師あり学習と教師なし学習¶
機械学習の最も基本的な形式は 教師あり学習です。

教師あり学習では、「ラベル付けされた」データを提供します。 データセット内のラベルは、アルゴリズムがデータから学習するのに役立つ情報を提供します。 ターゲットとも呼ばれるラベルは、予測対象としているものです。
-
連続値エクスペリメントの場合、ターゲットは数値です。 連続値モデルは、入力変数のリストが与えられた場合に連続的な従属変数を推定します(別名特徴量または列)。 連続値問題の例には、財務予測、時系列予測、メンテナンスのスケジューリング、および気象分析などがあります。
-
分類エクスペリメントでは、ターゲットはカテゴリーです。 分類モデルは、特定のクラスの共通の特性を識別することにより、観測値をカテゴリーにグループ化します。 これらの特性を分類しているデータと比較し、観測値が特定のクラスに属する可能性を推定します。 分類エクスペリメントは二値(2つのクラス)または多クラス(3つ以上のクラス)に分けることができます。 分類については、DataRobotはターゲット特徴量に可変数のクラスまたはラベルがある多ラベルモデリングもサポートしています。データセットの各行は、単一、複数、またはゼロのラベルに関連付けられています。
機械学習のもう1つの形式は、教師なし学習です。

教師なし学習では、データセットにラベルが付けられておらず、アルゴリズムでデータのパターンを推測する必要があります。
-
異常検知エクスペリメントでは、アルゴリズムがデータセット内の異常なデータポイントを検出します。 ユースケースには、不正なトランザクションの検出、ハードウェアの障害、およびデータ入力中の人為的エラーが含まれます。
-
クラスタリングエクスペリメントでは、アルゴリズムはデータセットを類似性に応じてグループに分割します。 クラスタリングは、データの直感的理解に役立ちます。 クラスターは、データセットに教師あり学習方法を使用できるように、データのラベル付けにも役立ちます。
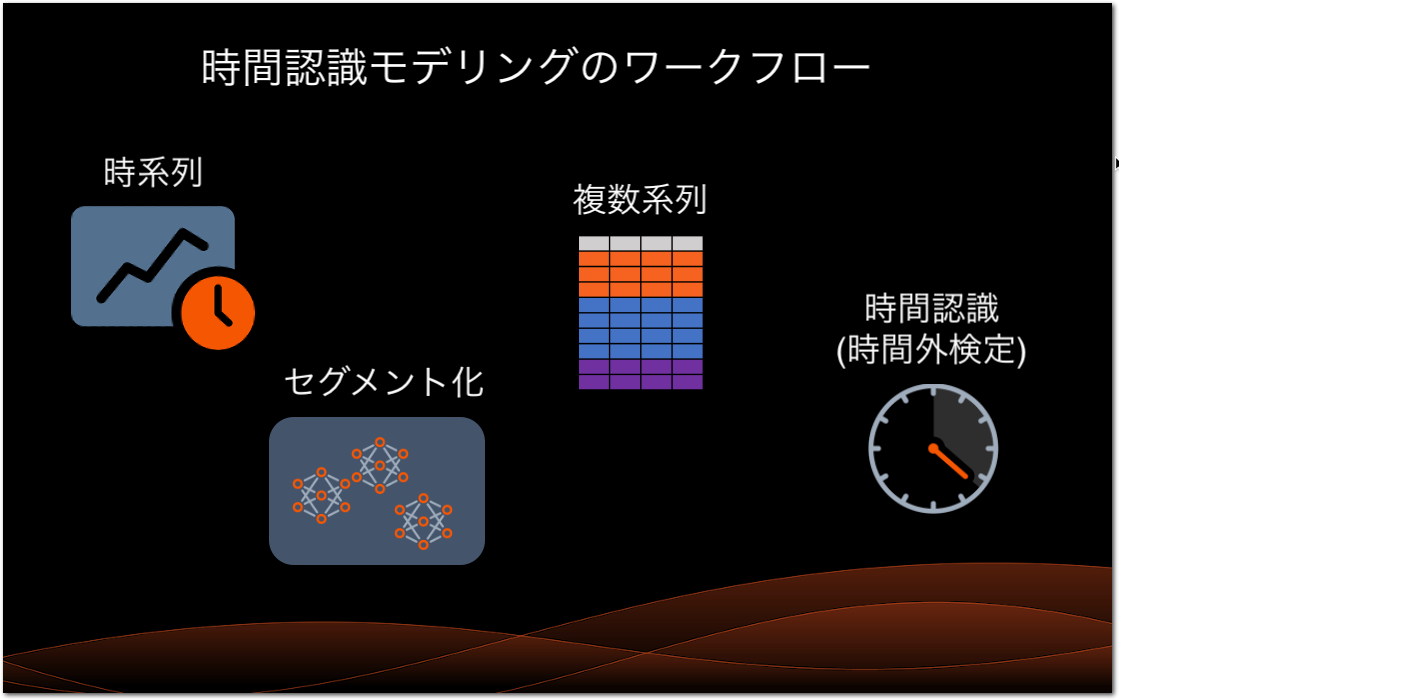
時間認識モデリング¶
時間データは、予測問題を解決する上で重要な要素です。 時間に関連するデータを使用するモデルは、行単位の予測、時系列予測、または現在値の予測である「ナウキャスト」を作成します。 データが適切で、分割手法が日付/時刻に設定されている場合、エクスペリメントは時間認識になります。
-
時系列モデリングを使用して、将来の一定期間の一連の予測を生成できます。 過去のデータで時系列モデルをトレーニングして、将来のイベントを予測します。 将来の値の範囲を予測するか、ナウキャストを使用して現在の時点での予測を行います。 時系列モデリングのユースケースには、金融、ヘルスケア、小売などのドメイン、つまり問題に時間要素があるドメインでの価格設定と需要の予測が含まれます。
-
単一の系列を含むデータセットの時系列モデリングを使用できますが、複数系列を含むデータセットのモデルを構築することもできます。 このタイプの複数系列エクスペリメントでは、1つの特徴量が系列識別子として機能します。 例としては、データセットを場所ごとに1つずつ、複数系列に基本的に分割する「店舗の場所」識別子があります。 したがって、4つの店舗(パリ、ミラノ、ドバイ、東京)と、モデリング用に4つの系列がある可能性があります。
-
複数系列エクスペリメントでは、セグメント化されたモデリングを使用して各系列のモデル生成を選択できます。 この場合、DataRobotは各セグメントに最適なモデルを使用してデプロイを作成します。
-
解決しようとしている問題のデータセットに日付と時刻の情報が含まれている場合がありますが、時系列モデリングのように予測生成を行う代わりに、各行のターゲット値を予測します。 このアプローチは時間外検証(OTV)と呼ばれます。
これらの戦略の詳細については、時間認識モデリングとはを参照してください。
特殊なモデリングワークフロー¶
DataRobotは、さまざまな問題に対処するのに役立つ特殊なワークフローを用意しています。

-
Visual Artificial Intelligence (AI)(Classicのみ)を使用すると、データセットの特徴量として画像を含めることができます。 画像データを他のデータ型と一緒に使用して、連続値、分類、異常検知、クラスタリングなど、さまざまなタイプのモデリングエクスペリメントの結果を改善します。
-
編集可能なブループリントを使用すると、DataRobotの前処理とモデリングのアルゴリズム、および独自のモデルを組み込んだ、独自のML ブループリントを作成および編集できます。
-
データのテキスト特徴量については、ワードクラウド やテキストマイニングなどのText AIインサイトを使用して、テキスト特徴量の影響を把握してください。
-
Location AI(Classicのみ)はモデリングデータの地理空間分析をサポートします。 地理空間特徴量を使用すると、モデリングの前後にインタラクティブマップを使用してインサイトを取得しデータを視覚化できます。
ワークベンチのモデリングのワークフロー¶
このセクションでは、DataRobotモデリングエクスペリメントを実装するための手順を説明します。
-
モデリングプロセスを開始するには、 データをインポート、または データをラングリングして、モデリング用のデータにアクセスして変換する、シームレスで、スケーラブルで、安全な方法を提供します。

-
DataRobotは探索的データ解析(EDA1)の第1段階を実施し、データ特徴量を分析します。 登録が完了すると、データプレビュータブにヒストグラムやサマリー統計などの特徴量の詳細が表示されます。
-
次に、教師ありモデリングでは、ターゲットを選択し、必要に応じて他の基本または高度なエクスペリメント設定を変更します。 次に、 モデリングを開始します。
DataRobotは特徴量セットを生成し、そこからモデルを構築します。 デフォルトでは、最も有用な特徴量を含む特徴量セットを使用します。 または、生成済みのさまざまな特徴量セットを選択、または 独自に作成できます。
-
DataRobotはEDA2中にデータをさらに評価して、どの特徴量がターゲットに相関しているか(特徴量の有用性)、その他の情報の中でどの特徴量が有用であるかなどを判断します。
アプリケーションはエクスペリメントタイプと選択した設定に応じて、特徴量セットの変換、生成、および削減を行う特徴量エンジニアリングを実行します。
-
DataRobotはエクスペリメントタイプに基づいて、ブループリントを選択し、候補モデルを構築します。
モデルの分析と選択¶
DataRobotはモデルを自動生成し、リーダーボードに表示します。 最も精度の高いモデルが選択され、データの100%でトレーニングされ、デプロイの準備済み****バッジでマークされます。
モデルの分析と選択を行うには:
-
指標ドロップダウンから 最適化指標を選択して、モデルを比較します。
-
構築しているモデルのタイプに最適な視覚化ツールを使用して、モデルを分析します。 単一のユースケース内のエクスペリメントに対して モデル比較を使用します。
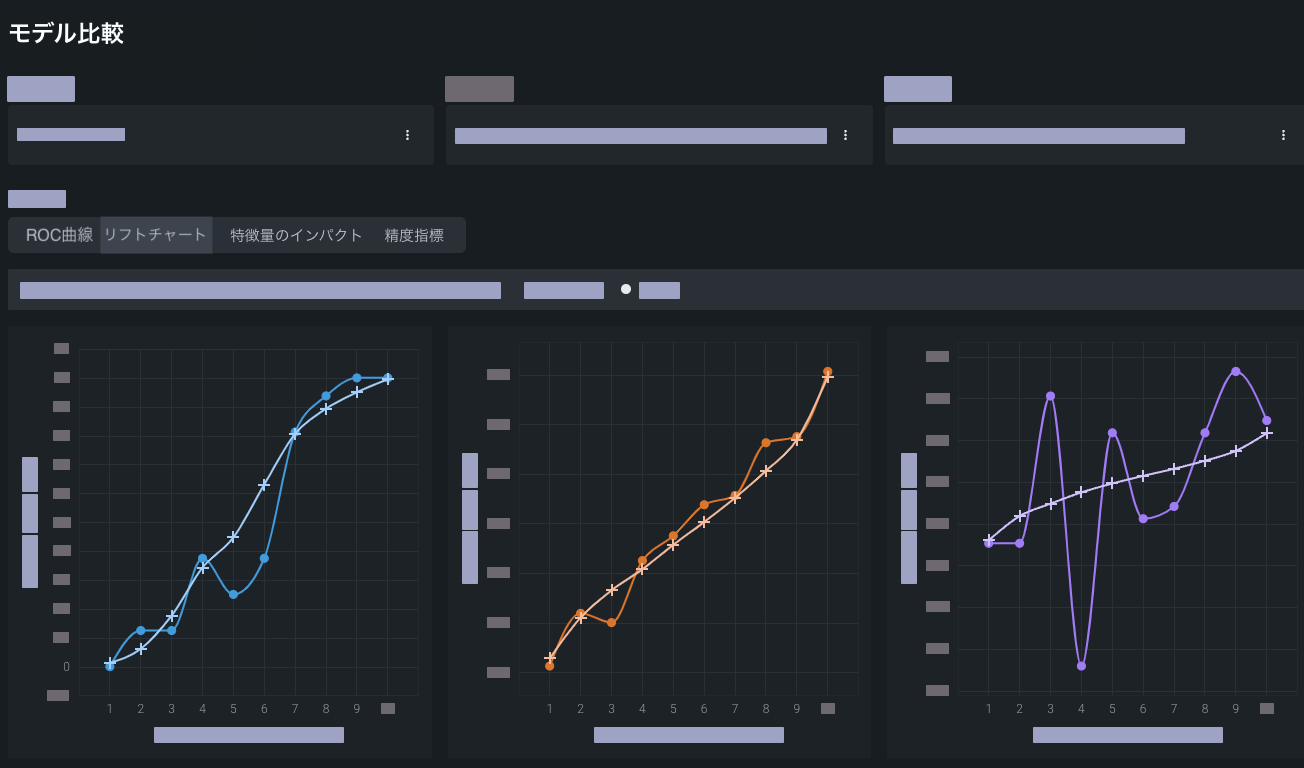
以下のエクスペリメントタイプと関連する視覚化のリストを参照してください。
-
さまざまなモデリング設定を試して、モデルの精度を向上させてください。 別の特徴量セットまたはモデリングモードを使用して モデリングを再実行してみることができます。
-
モデルを分析した後、最適なモデルを選択して レジストリに送信し、デプロイ可能なモデルパッケージを作成します。
ヒント
デプロイする前に予測をテストすることをお勧めします。 結果に満足できない場合は、モデリングプロセスを再検討し、特徴量セットと最適化設定を使用してさらに試してみてください。 また、より有用なデータ特徴量を収集することで結果を改善できる場合もあります。
-
デプロイプロセスの一環として、 予測を作成します。 定期的なバッチ予測ジョブを設定することもできます。
-
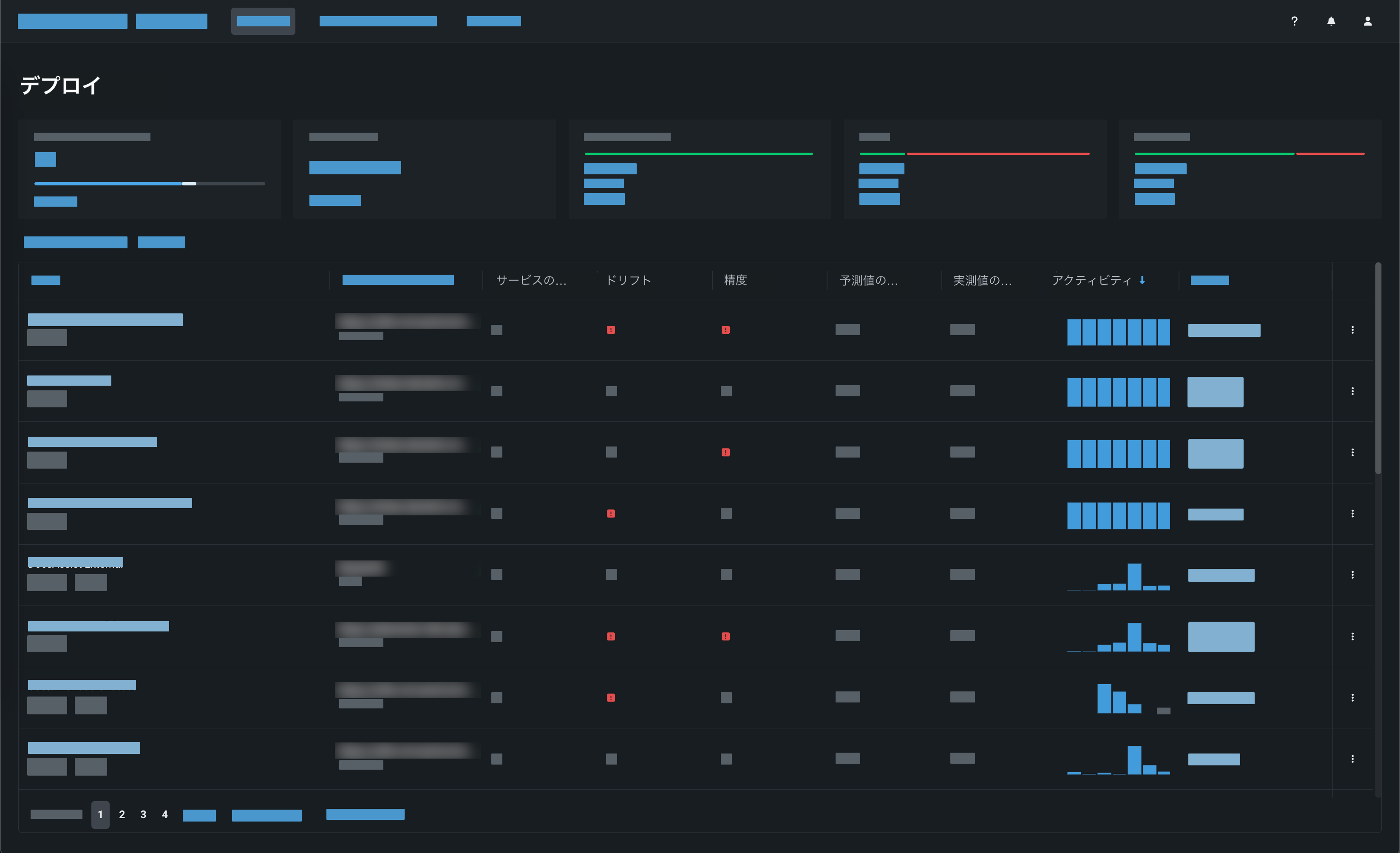
DataRobotでは、さまざまな指標を使用してデプロイを 監視します。 アプリケーションの視覚化を使用して、データ(特徴量)ドリフト、精度、 バイアス、サービス正常性などを追跡します。 通知を設定すると、モデルのステータスが定期的に通知されます。
ヒント
エンドツーエンドのワークフローを自動化するために、自動再トレーニングの有効化を検討してください。 自動再トレーニングにより、DataRobotはチャレンジャーモデルを現在の最良のモデル(チャンピオンモデル)に対して定期的にテストし、チャレンジャーがそれを上回った場合、チャンピオンを置き換えます。
どの視覚化を使用する必要がありますか?¶
DataRobotは、モデルの分析に多くの視覚化を用意しています。 すべての視覚化ツールがすべてのモデリングエクスペリメントに適用できるわけではありません。アクセスできる視覚化は、エクスペリメントの種類によって異なります。 次の表に、エクスペリメントの種類と、それらの分析に適した視覚化の例を紹介します。
| エクスペリメントタイプ | 分析ツール |
|---|---|
| すべてのモデル | |
| 連続値 | |
| 分類 |
|
| 時間認識モデリング(時系列と時間外検定) |
|
| 複数系列 | 系列のインサイト:系列固有の情報のヒストグラムと表を提供します。 |
| セグメント化されたモデリング | セグメンテーションタブ:統合されたモデルの各セグメントに関するデータを表示します。 |
| 多ラベルモデリング(Classic) | 特徴量の統計:多ラベル特性を持つデータセットの評価を支援し、ペア単位の行列を提供して、特徴量ペアの相関、同時確率、および条件付き確率を視覚化できるようにします。 |
| Visual Artificial Intelligence (AI)の画像(Classic) |
|
| Text AI | |
| 地理空間AI(Classic) | |
| クラスタリング |
|
| 異常検知 |